本文主要介紹近鄰算法原理及實踐demo。
一、原理
K近鄰算法(K-Nearest Neighbors,簡稱KNN)是一種基于距離的分類算法,其核心思想是距離越近的樣本點,其類別越有可能相似。以下是KNN算法的原理詳解:
1. 算法原理
KNN算法的工作原理是利用訓練數據對特征向量空間進行劃分,并將劃分結果作為最終算法模型。當輸入一個新的沒有標簽的數據后,將這個數據的每個特征與訓練集中的數據對應的特征進行比較,找出訓練集中與這個新數據特征最相近的K個樣本點(即K個最近鄰居),然后根據這K個鄰居的類別加權或投票,來預測新數據的類別。
2. K值的選擇
K的選擇對算法的精度有較大影響。K值較小時,模型對噪聲更敏感,容易過擬合;K值較大時,模型對異常值的魯棒性更強,但可能會引入噪聲,導致欠擬合。在實際應用中,K值的選擇通常通過交叉驗證等方法來確定最優的K值。
3. 距離度量
KNN算法中常用的距離度量是歐氏距離,但也可以采用曼哈頓距離、切比雪夫距離等其他距離度量方法。在進行距離度量之前,通常需要對每個屬性的值進行規范化,以保證不同特征具有相同的權重。
4. 特征歸一化
由于不同特征的量綱可能不同,如果不進行歸一化,那么在計算距離時,數值范圍大的特征會對距離計算產生較大的影響。因此,為了使每個特征具有同等的重要性,通常需要對特征進行歸一化處理。
5. 算法實現
KNN算法的實現通常包括以下幾個步驟:
- 導入數據并進行預處理。
- 確定K值和距離度量方法。
- 對于每一個測試數據點,計算其與訓練集中每個點的距離。
- 找出距離最近的K個訓練數據點。
- 根據這K個鄰居的類別,通過投票或加權的方式來預測測試點的類別。
6. 算法優勢與劣勢
KNN算法的優勢在于它簡單、直觀,對數據的分布沒有假設,因此可以用于非線性數據的分類。同時,KNN算法也可以用于回歸問題。不過,KNN算法的計算復雜度較高,尤其是在大數據集上,計算每個待分類點與所有訓練點之間的距離會非常耗時。
7. 應用場景
KNN算法適用于那些樣本容量較大的類域的自動分類問題,但在樣本容量較小的類域上使用時,容易產生誤分。此外,KNN對不平衡的數據集比較敏感,需要通過權重調整或其他方法來改進。
KNN算法是一種“懶惰學習”算法,它不會從訓練數據中學習到模型,而是直接存儲訓練數據,在預測時才進行計算,因此訓練時間復雜度為0,但分類時間復雜度為O(n)。
KNN算法是一種簡單、易于實現的分類算法,但在使用時需要注意K值的選擇、距離度量、特征歸一化等關鍵因素,以提高算法的準確性和效率。
二、舉個栗子
使用scikit-learn庫中的KNN分類器,并用一個合成的數據集來展示如何訓練模型和進行預測。
預期效果
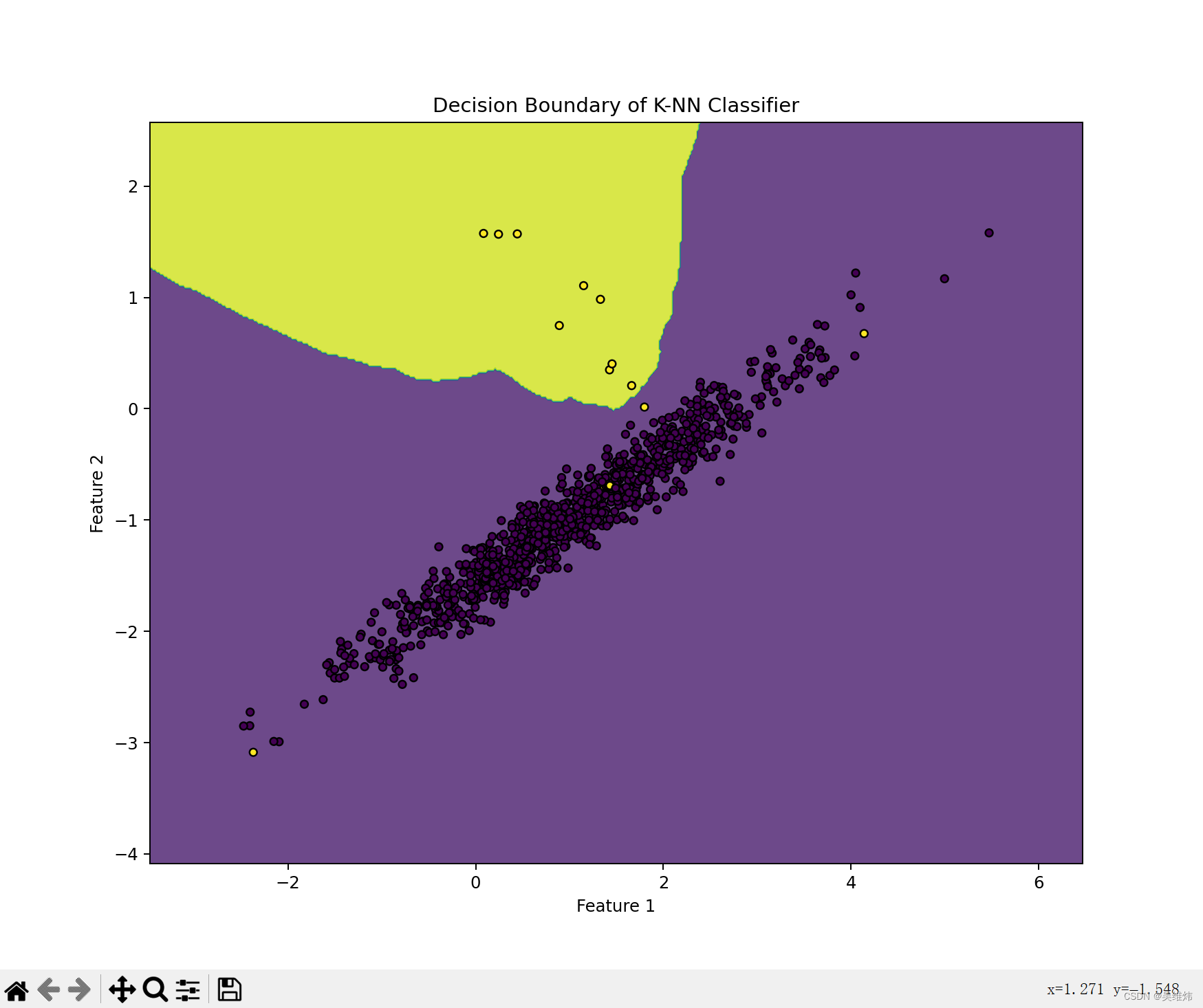
設計思路
- 使用make_classification函數創建了一個二分類的數據集。-
- 初始化了一個KNN分類器,并設置了鄰居數k。
- 使用訓練數據訓練了KNN模型。-
- 使用predict方法預測了網格上每個點的類別。
- 使用contourf函數繪制了決策邊界,并且繪制了訓練數據點。
核心代碼
# 導入必要的庫
import numpy as np # 導入numpy,并將其別名設置為np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt# 創建一個合成的分類數據集
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0,n_clusters_per_class=1, weights=[0.99],random_state=42)# 選擇K的值,這里我們選擇K=5
k = 5# 初始化KNN分類器
knn = KNeighborsClassifier(n_neighbors=k)# 訓練KNN模型
knn.fit(X, y)# 為了可視化,我們創建一個網格來繪制決策邊界
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),np.arange(y_min, y_max, .02))# 預測網格點所屬的類別
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])# 將預測結果繪制為彩色圖像
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z.reshape(xx.shape), alpha=0.8)# 繪制訓練點
plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor='k')
plt.title('Decision Boundary of K-NN Classifier')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
三、自定義實例
預期效果
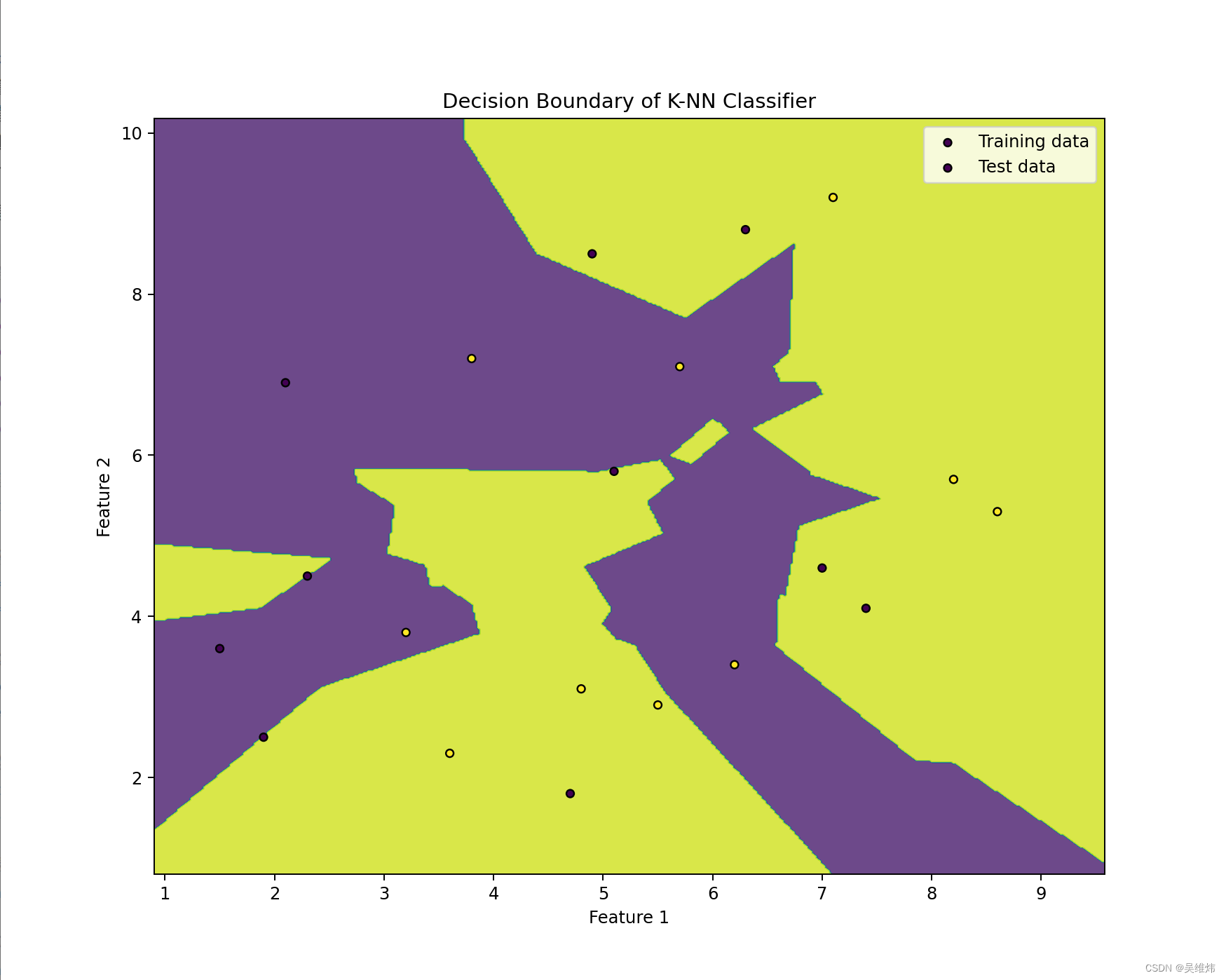
核心代碼
# 導入必要的庫
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt# 讀取CSV數據集
data = pd.read_csv('knnDemoDB.csv')# 假設CSV文件的最后一列是標簽
X = data.iloc[:, :-1].values # 所有行,除了最后一列的所有列
y = data.iloc[:, -1].values # 所有行,最后一列# 如果標簽是非數值型的,則進行編碼轉換
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)# 初始化KNN分類器
knn = KNeighborsClassifier(n_neighbors=5)# 訓練KNN模型
knn.fit(X_train, y_train)# 為了可視化,我們創建一個網格來繪制決策邊界
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),np.arange(y_min, y_max, .02))# 預測網格點所屬的類別
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])# 將預測結果繪制為彩色圖像
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z.reshape(xx.shape), alpha=0.8)# 繪制訓練點和測試點
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, s=20, edgecolor='k', label='Training data')
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, s=20, edgecolor='k', label='Test data')
plt.title('Decision Boundary of K-NN Classifier')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
數據源
knnDemoDB.csv
Feature1,Feature2,Label
1.5,3.6,Class_A
2.3,4.5,Class_A
3.6,2.3,Class_B
4.8,3.1,Class_B
5.1,5.8,Class_A
6.2,3.4,Class_B
7.4,4.1,Class_A
8.6,5.3,Class_B
2.1,6.9,Class_A
3.8,7.2,Class_B
4.9,8.5,Class_A
5.7,7.1,Class_B
6.3,8.8,Class_A
7.1,9.2,Class_B
1.9,2.5,Class_A
3.2,3.8,Class_B
4.7,1.8,Class_A
5.5,2.9,Class_B
7.0,4.6,Class_A
8.2,5.7,Class_B
四、解決方案
KNN算法可以應用于生活中的許多實際問題,因為它是一種簡單、直觀的分類算法。以下是一些解決方案例子,展示了如何使用KNN算法解決實際問題:
1. 推薦系統
在推薦系統中,KNN可以用來根據用戶的歷史行為(如購買、評分或瀏覽歷史)推薦商品或服務。通過將用戶的特征(如年齡、性別、興趣等)和他們之前的喜好作為輸入,KNN可以找出相似用戶群,并推薦那些用戶喜歡的產品。
2. 醫療診斷
在醫療領域,KNN可以用于輔助診斷。利用病人的一系列癥狀、體檢結果和病史作為特征,KNN可以預測可能的疾病。例如,基于病人的血糖水平、血壓和膽固醇水平,KNN可以預測心臟病的風險。
3. 圖像識別
KNN算法可以用于圖像識別任務,如手寫數字識別。每個圖像可以被轉換成一個特征向量,其中包含了圖像的紋理、邊緣和形狀信息。KNN根據這些特征向量將新的圖像分類到相應的類別。
4. 金融市場分析
在金融市場,KNN可以用于預測股票價格的變動或信用風險評估。通過分析歷史價格、交易量和市場趨勢,KNN可以幫助投資者做出更明智的投資決策。
5. 房地產市場
在房地產市場,KNN可以用來估算房屋價格。利用房屋的特征(如面積、位置、房間數量等)和近期售出的類似房屋價格作為訓練數據,KNN可以預測新房屋的市場價格。
6. 垃圾郵件檢測
KNN可以用于文本分類,如垃圾郵件檢測。通過分析郵件內容中的關鍵詞和短語,KNN可以將郵件分類為垃圾郵件或非垃圾郵件。
7. 交通流量預測
在智能交通系統(ITS)中,KNN可以用于預測交通流量和擁堵情況。利用歷史交通數據和實時傳感器數據,KNN可以預測特定路段的交通狀況。
應用實例:房屋價格預測
假設我們想要使用KNN算法預測房屋價格。以下是基于前面提供的代碼模板,針對房屋價格預測問題的示例:
# 導入必要的庫
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestRegressor
import numpy as np
import matplotlib.pyplot as plt# 讀取CSV數據集,這里假設CSV文件包含了房屋的特征和價格
data = pd.read_csv('house_prices.csv')# 假設CSV文件中包含了多個特征列和一個價格標簽列
features = data.drop('Price', axis=1).values # 所有行,除了價格列的所有列
price = data['Price'].values # 所有行,價格列# 如果特征中包含非數值型數據,則進行編碼轉換
# 這里假設所有數據已經是數值型的# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(features, price, test_size=0.2, random_state=42)# 初始化KNN回歸器
knn = KNeighborsClassifier(n_neighbors=5)# 訓練KNN模型
knn.fit(X_train, y_train)# 預測測試集的價格
y_pred = knn.predict(X_test)# 評估模型性能
print('Predictions:', y_pred)
print('Actual prices:', y_test)# 如果需要可視化,可以繪制預測價格與實際價格的關系
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, color='blue', label='Predicted prices')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.xlabel('Actual Price')
plt.ylabel('Predicted Price')
plt.title('KNN Predicted vs Actual Prices')
plt.legend()
plt.show()



)











時顯示提示框的效果)



