隨便記錄一下最近閱讀的幾篇論文
1. Does DINOv3 Set a New Medical Vision Standard?
第一章 動機 (Motivation)
自然圖像領域的成功范式:大型語言模型(LLMs)和視覺基礎模型(如 DINO 系列)證明,通過自監督學習(SSL)在海量無標注數據上進行預訓練,可以學習到極其強大且通用的表征能力,并遵循顯著的“縮放定律”(模型越大、數據越多,性能越好)。
醫學影像領域的獨特挑戰:
- 數據稀缺與獲取困難:醫學數據標注成本極高,且受隱私、法規限制,難以構建大規模數據集。
- 模態極度多樣化:包括 2D(X光、病理切片)、3D(CT、MRI)、灰度圖、RGB圖像等多種成像技術,每種都需要不同的視覺理解能力。
- 對細微特征敏感:診斷依賴于捕捉圖像中微小、細微的異常模式,因此對視覺表征的質量要求極高。
核心矛盾與問題: 醫學領域亟需一個強大的、現成的(off-the-shelf)視覺特征提取器,但受限于上述挑戰,很難從頭訓練一個大規模醫學視覺基礎模型。那么,一個直接的問題是:在自然圖像上訓練出的頂尖模型,其能力能否直接遷移到醫學領域? 這就引出了論文要探究的幾個根本性問題。
第二章 論文基準測試設置 (Benchmark Setup)
1. 2D醫學圖像分類 (2D Medical Image Classification)
任務描述:處理二維平面圖像進行診斷分類。
方法:直接將2D圖像輸入DINOv3編碼器,獲取圖像級特征后進行線性分類或更復雜的下游訓練。
使用的數據集與評估協議:
| 數據集 | 模態 | 內容與規模 | 任務 | 評估協議 |
|---|---|---|---|---|
| NIH-14 | 胸部X光 | 112,120張圖像,30,805名患者 | 14種胸廓疾病的多標簽分類 | 嚴格遵守官方提供的患者劃分 |
| RSNA-Pneumonia | 胸部X光 | 29,700張圖像 | 肺炎分類(二分類) | 遵循MGCA論文提出的標準化數據劃分方法 |
| Camelyon16 | 病理WSI (RGB) | 399張淋巴結切片 | 乳腺癌轉移檢測(腫瘤 vs. 正常) | 1. 官方劃分(270訓練/129測試) 2. 多折交叉驗證 on test set 3. 在Camelyon17上測試泛化能力(跨中心) |
| Camelyon17 | 病理WSI (RGB) | 多中心數據集,500張切片(100名患者) | 作為域外泛化測試集 | 使用其官方訓練集作為測試集(因官方測試標注未公開),評估從Camelyon16訓好的模型在Unseen子集上的表現 |
| BCNB | 病理WSI (RGB) | 1,058名患者的早期乳腺癌活檢切片 | 5項預測任務: - 腋窩淋巴結(ALN)轉移狀態 - 分子狀態(ER, PR, HER2, Ki67) | 5折交叉驗證,每折內按 7:1:2 劃分訓練/驗證/測試集。使用CLAM方法提取圖像塊(~968 patches/WSI) |
2. 3D醫學圖像分類 (3D Medical Image Classification)
- 任務描述:對三維體積數據(如CT、MRI)進行整體分類。 核心方法:采用 “切片級特征提取 + 聚合” 策略:
- 獨立處理:將3D體積的每一個2D切片分別輸入DINOv3 backbone,得到每個切片的特征嵌入(embedding)。
- 特征聚合:將所有切片的特征通過平均池化(Mean Pooling) 聚合為一個代表整個體積的特征向量。
- 下游分類:用聚合后的特征訓練分類器。
使用的數據集與評估協議:
| 數據集 | 模態 | 內容與規模 | 任務 | 評估協議 |
|---|---|---|---|---|
| CT-RATE | 非增強CT | 47,000個CT體積,20,000名患者 | 18種臨床異常的多標簽二分類 | 使用官方數據劃分。采用兩種下游評估方法: 1. 零樣本 k-NN 2. 線性探測(Linear Probing) |
3. 3D醫學圖像分割 (3D Medical Image Segmentation)
- 任務描述:在三維體積數據上進行體素級的預測,以分割解剖結構或病變。
- 核心方法:采用 “逐片特征提取 + 偽3D重構” 策略
- 逐片處理:將3D體積的每一個2D切片分別輸入DINOv3,并保留完整的2D特征圖(而非圖像級嵌入)。
- 構建偽3D特征體積:將所有2D特征圖沿切片方向堆疊,形成一個3D的特征體積
- 輕量級分割頭:將這個偽3D特征體積輸入一個輕量的3D分割頭(如UNet式 decoder),最終生成體素級預測。
使用的數據集與評估協議:
| 數據集 | 模態 | 內容與任務 | 評估協議 |
|---|---|---|---|
| Medical Segmentation Decathlon (MSD) | CT, MRI | 10個不同的3D分割任務,涵蓋腦腫瘤、心臟、肝臟、海馬體、前列腺、肺、胰腺、肝血管、脾臟和結腸 | 官方評估平臺已關閉,采用 5折交叉驗證。遵循此前工作的標準協議(體積標準化、隨機旋轉/翻轉等數據增強) |
| CREMI | 電子顯微鏡(EM) | 3個子集(A,B,C),難度遞增,用于神經元分割 | 每個子集:前100張切片訓練,后25張測試 |
| AC3/AC4 | 電子顯微鏡(EM) | 兩個密集標注的EM體積,用于神經元分割 | 在AC4(前80切片)上訓練,在AC3(前100切片)上測試 -> 測試域外泛化 |
| AutoPET-II | PET/CT | 1,014個全身PET/CT掃描,用于腫瘤病灶分割 | 使用官方劃分的訓練/驗證集。強度標準化,使用隨機旋轉/翻轉等數據增強 |
| HECKTOR 2022 | PET/CT | 882個頭頸部PET/CT掃描,用于原發灶(GTVp)和淋巴結(GTVn)腫瘤分割 | 遵循官方挑戰協議和預處理流程(圖像配準、強度標準化) |
實驗baseline model設置
| 模型 | 參數量 | 預訓練數據 | 數據類型 | 數據模態 | 學習范式 |
|---|---|---|---|---|---|
| BiomedCLIP | 86M | 1500萬圖像-文本對 | 2D 圖像-文本 | 多樣生物醫學圖像 | 文本監督 |
| CT-CLIP | 86M | 5萬體積+報告 | 3D 體積-文本 | 胸部CT | 文本監督 |
| UNI | 304M | 1億圖像塊 | 2D 圖像塊 | 頭部/腹部/胸部CT | 視覺自監督 |
| CONCH | 86M | 117萬 2D 塊-文本對 | 2D 塊-文本 | 病理學 | 文本監督 |
| DINOv3-S/B/L | 22M/86M/304M | 17億自然圖像 | 2D 圖像 | 自然圖像 | 視覺自監督 |
第三章 實驗結論分析
| 任務類別 | 具體任務與數據集 | 實驗結論 | 原因分析 |
|---|---|---|---|
| 2D分類 | 胸部X光分類 (NIH-14, RSNA-Pneumonia) | 表現出色,確立新基線。DINOv3-L在NIH-14上AUC 0.7865,超越醫學專用模型BiomedCLIP (0.7771)。在RSNA上與BiomedCLIP性能接近。 | DINOv3從自然圖像中學到的物體結構和形狀表征能力,與X光片中基于宏觀結構異常進行診斷的模式高度吻合。 |
| 2D分類 | 病理切片(WSI)分類 (Camelyon16, Camelyon17, BCNB) | 性能顯著落后。AUC (~0.84) 遠低于病理專用模型UNI和CONCH (AUC >0.96),僅與ResNet50相當。泛化能力差。 | 病理分析依賴細粒度的紋理和細胞模式,與DINOv3關注的“物體”級特征不匹配。表明領域專業化預訓練絕對必要。 |
| 3D分類 | 3D CT體積分類 (CT-RATE) | 性能卓越,顯著超越基線。DINOv3-B (線性探測) AUC 0.798,顯著高于專用基線CT-CLIP (0.731)。 | DINOv3的2D特征通過切片平均池化聚合后,能有效表征整個3D體積,捕捉與診斷相關的視覺模式。 |
| 3D分割 | 多器官分割 (MSD) | 都是物體級別特征,表現尚可但平庸。為自監督方法設立新SOTA基線,但整體性能(71% Dice)遠低于全監督nnU-Net (81.4% Dice)。在個別任務(肺、脾)上達到最佳。 | 簡單的“凍結主干+逐片處理”策略不足以擊敗端到端訓練的復雜3D架構。但其強大的2D特征是一個“不錯的起點”。 |
| 3D分割 | 神經元分割 (EM: CREMI, AC3/4) | 災難性失敗。誤差指標(VOI, ARAND)比經典方法高出十倍以上。 | DINOv3特征缺乏高頻紋理細節,無法描繪神經元間錯綜復雜的邊界。自然圖像與EM圖像領域差距過大。 |
| 3D分割 | 腫瘤分割 (PET/CT: AutoPET-II, HECKTOR) | 性能極差。Dice分數極低(<15%),遠低于現有模型(>50%)。 | DINOv3特征適用于解剖結構,但無法解讀PET數據中的功能性代謝信息。這是與自然圖像模式的根本性背離。 |
| 縮放定律 | 所有任務 | 縮放定律不一致且不可靠。性能不隨模型變大(S->B->L)或分辨率提高而單調增加。最佳模型規模因任務而異。 | 自然圖像與醫學圖像存在領域差距。簡單地堆砌計算資源不能解決所有問題,必須為不同任務仔細選擇模型規模和分辨率。 |
2. Training Language Models to Self-Correct via Reinforcement Learning(2024)
Google技術報告
任務定義: 大模型自我反思被定義為兩階段的問同一個問題,但是思考多次

主要方法以及實驗可以在下面表示:

主要方法的訓練過程: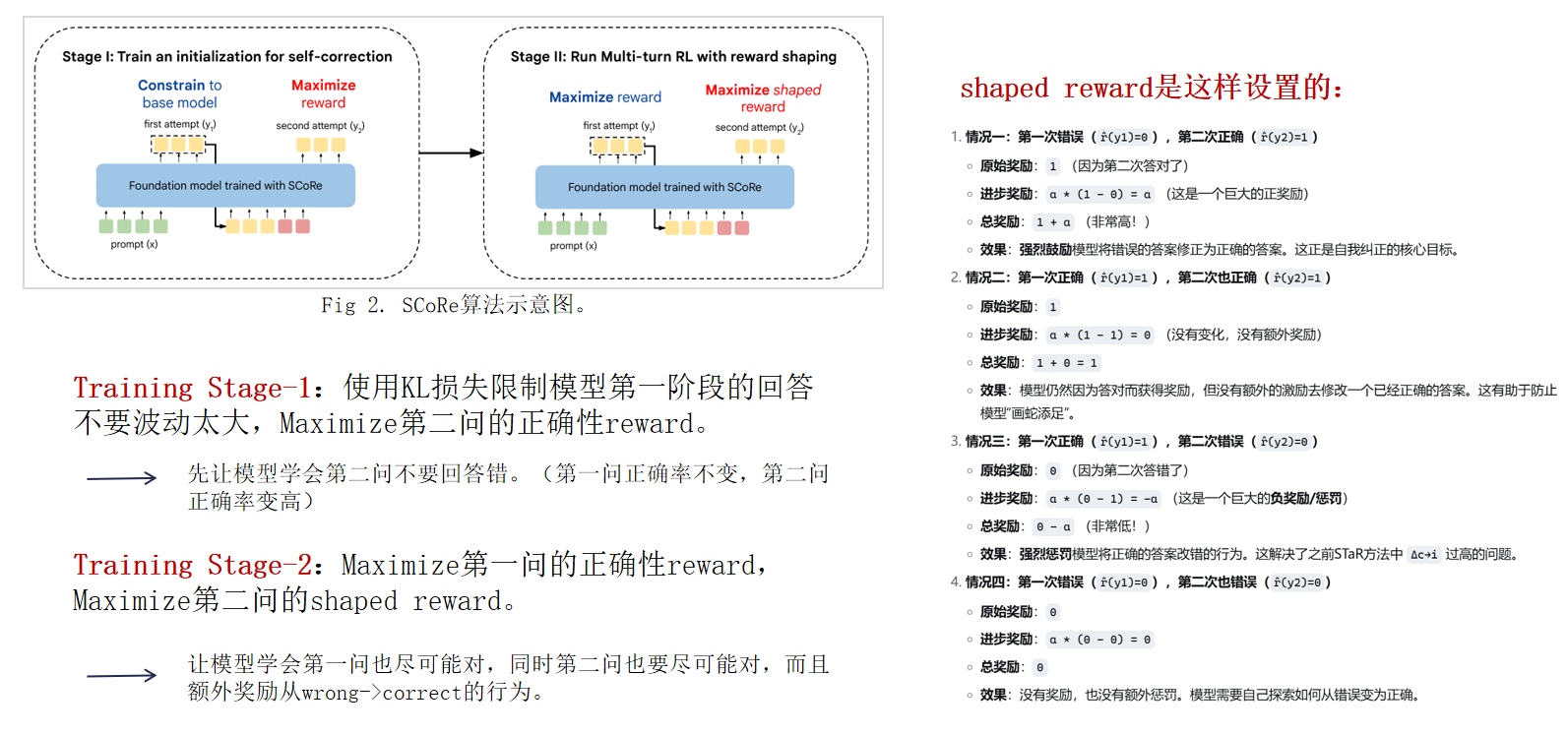


【進程/PCB】)





)



、列族設計、rowkey設計以及熱點問題處理)






