[手寫系列]Go手寫db — — 第二版
第一版文章:[手寫系列]Go手寫db — — 完整教程
整體項目Github地址:https://github.com/ziyifast/ZiyiDB- 請大家多多支持,也歡迎大家star??和共同維護這個項目~
本文主要介紹如何在 ZiyiDB 第一版的基礎上,實現更多新功能,給大家提供更多的實現思路,以及實現的流程,后續更多關鍵字以及字段類型的支持,大家可以參考著實現。
一、功能列表
- 新增對 FLOAT 和 DATETIME 字段類型的支持
- 新增對 BETWEEN AND 關鍵字的支持
- 新增對注釋符的支持
- 新增對 >=、<=、!= 操作符的支持
二、實現細節
1. 新增對 FLOAT 和 DATETIME 字段類型的支持
實現思路
為了支持 FLOAT 和 DATETIME 類型,我們需要在詞法分析器、語法分析器和存儲引擎中進行相應修改。
token.go新增常量 -> lexer.go詞法分析器新增對Float、時間的解析 -> ast.go抽象語法樹新增FloatLiteral、DatetimeLiteral -> parser.go語法解析器中新增對Float、時間類型數據的解析,并構建為語法樹 -> memory.go存儲引擎新增對Float、時間類型的insert、update操作(解析語法樹)
- lexer/token.go中新增FLOAT、DATETIME const常量

- lexer/lexer.go的NextToken中新增對時間、數字的解析
- 對時間的解析:是字符串,且能被轉換為時間格式
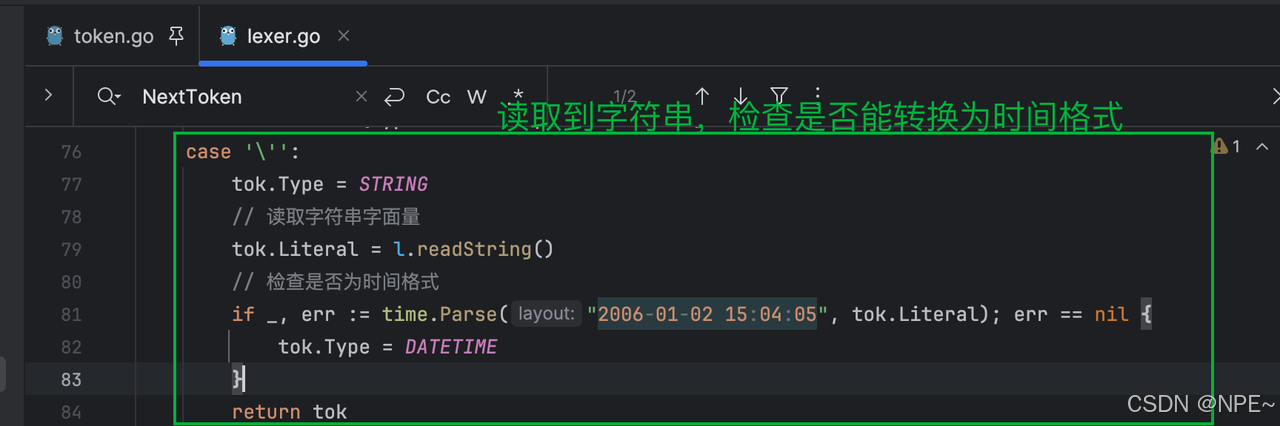
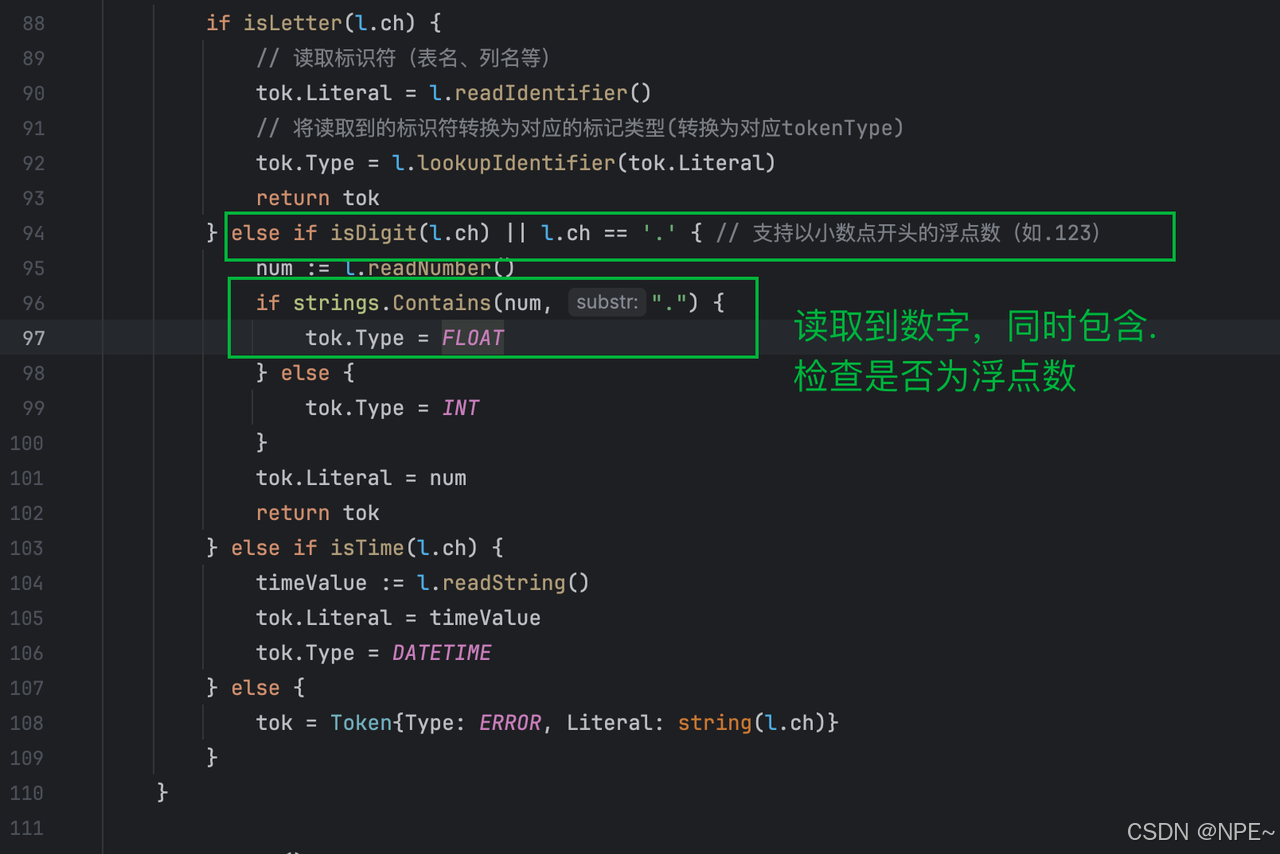
- 對浮點數數字的解析:是數字,且包含
.
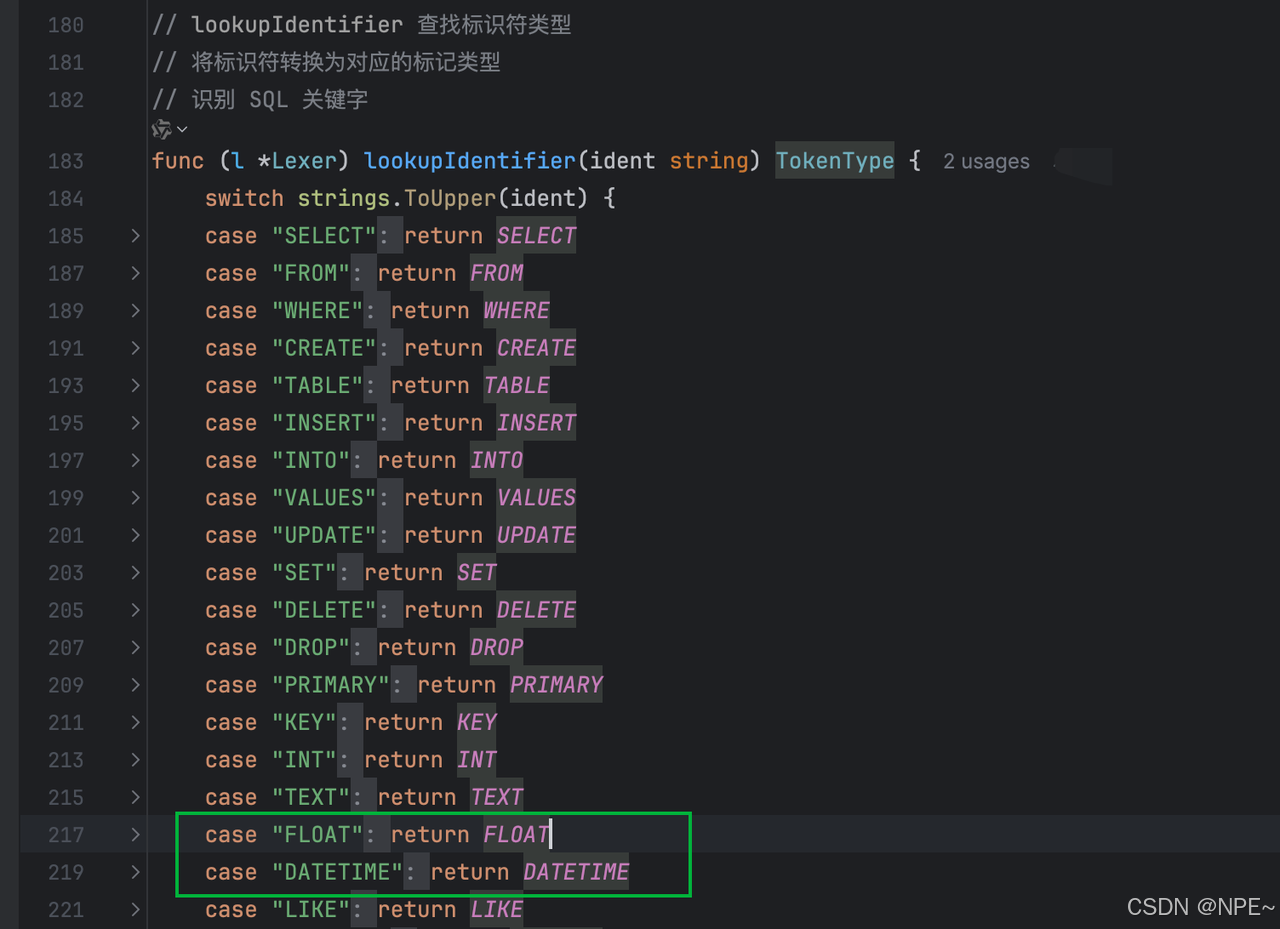
- internal/lexer/lexer.go的lookupIdentifier方法中新增標識符類型,用于解析關鍵字
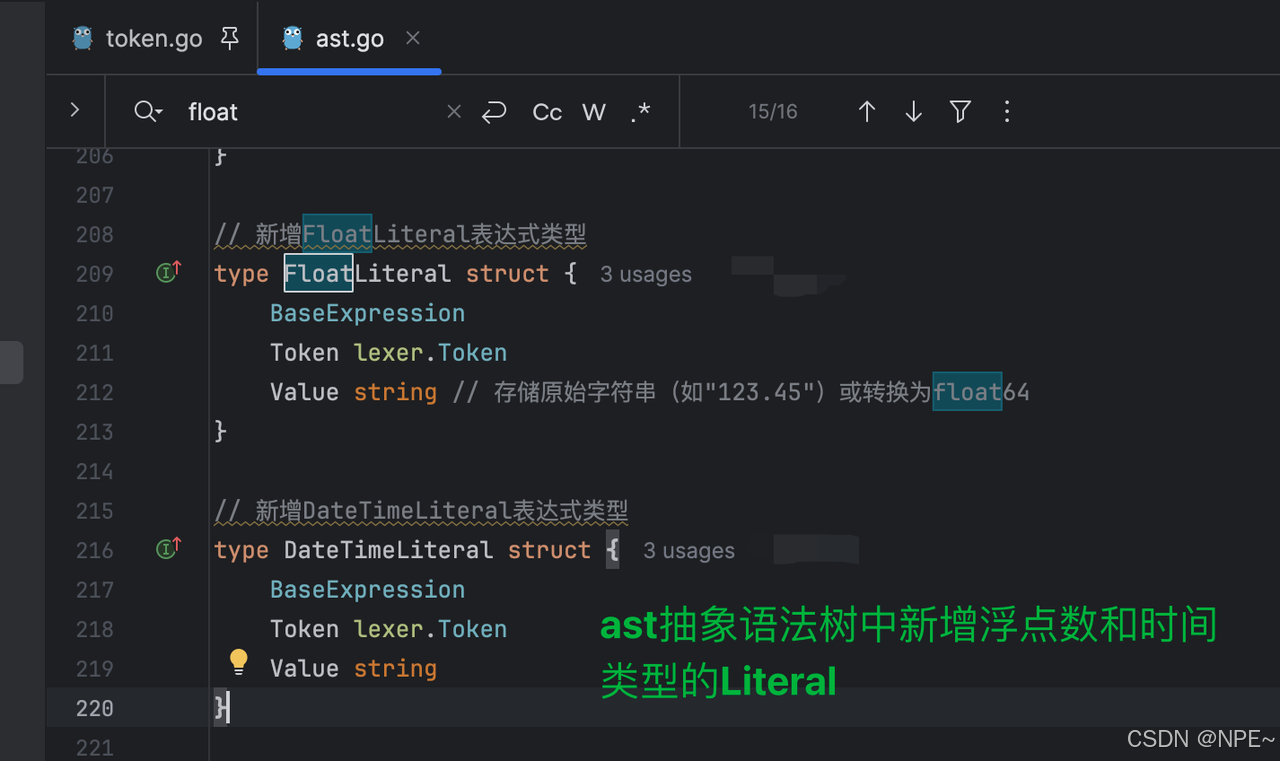
- internal/ast/ast.go中為后續構建抽象語法樹,新增FloatLiteral、DateTimeLiteral以及在Cell結構體中新增FloatValue和TimeValue存儲該類型值
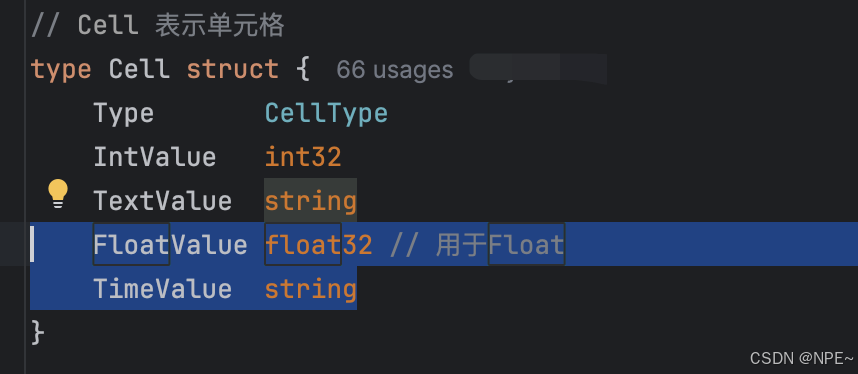
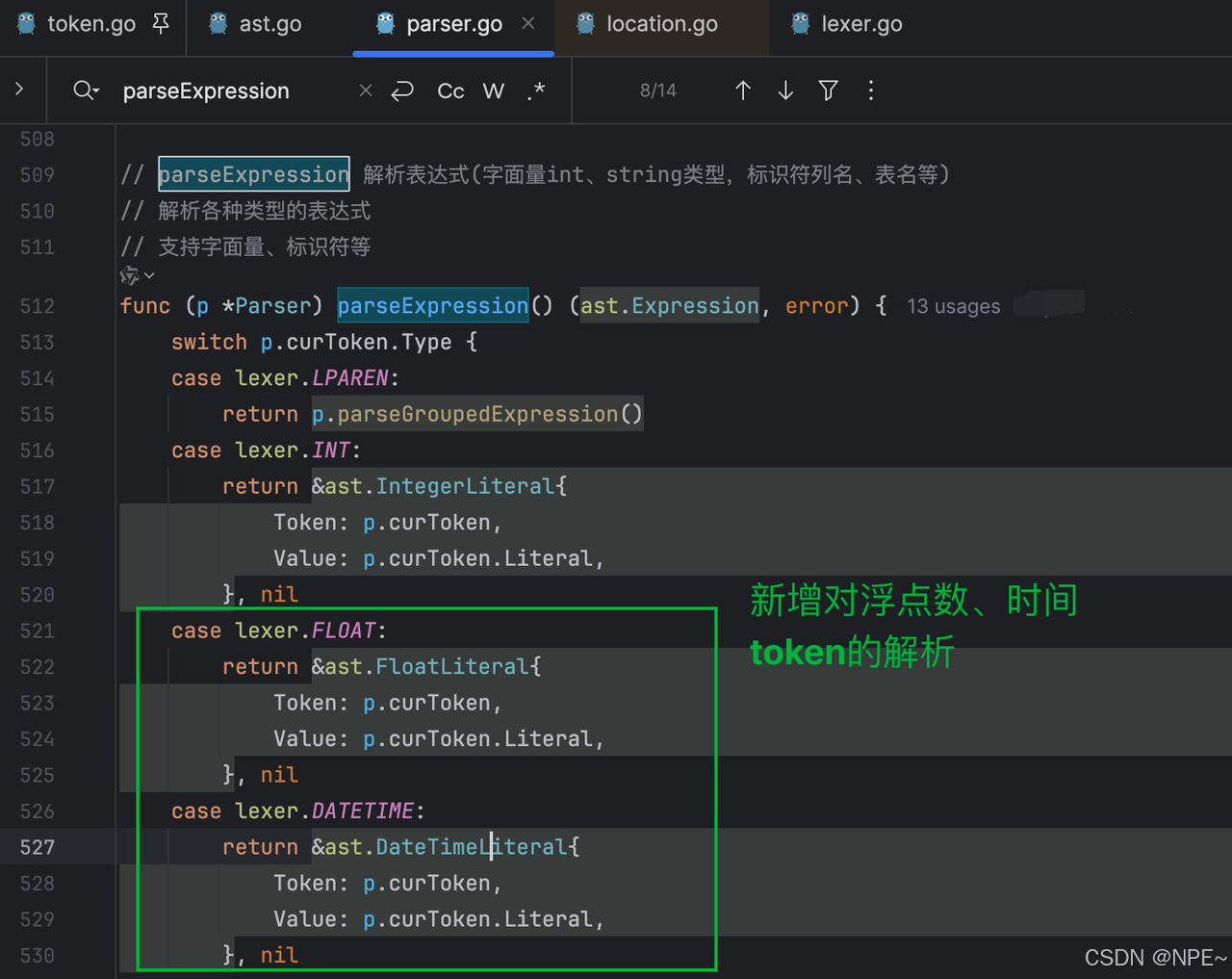
- internal/parser/parser.go解析器中新增對Float浮點數、DATETIME時間的解析,將解析出來的數據構建為抽象語法樹的結構
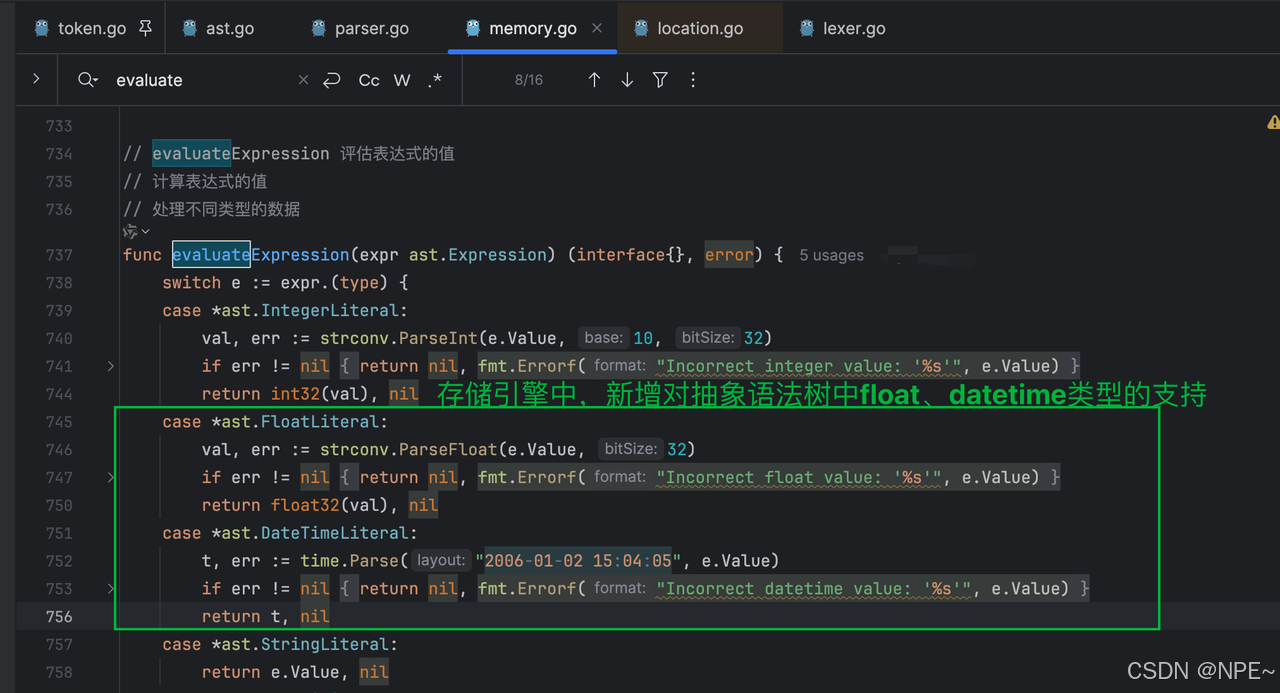
- internal/storage/memory.go存儲引擎中新增對*ast.FloatLiteral、*ast.DateTimeLiteral的解析,將其轉換為原始類型
- 更新evaluateExpression函數:
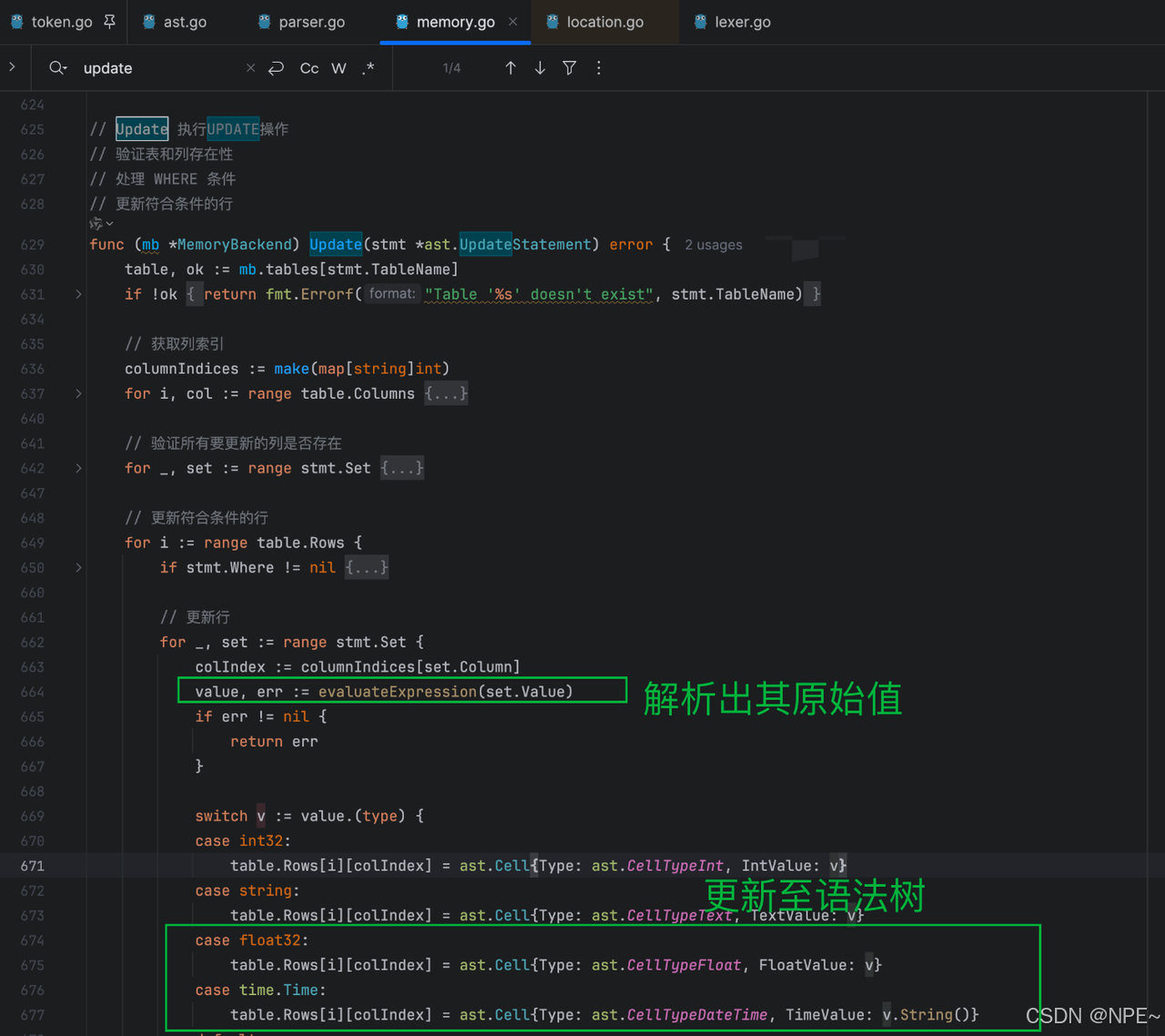
- 更新Update函數:將抽象語法樹中的datetime、float Literal字面量解析至原始類型并更新至Cell中
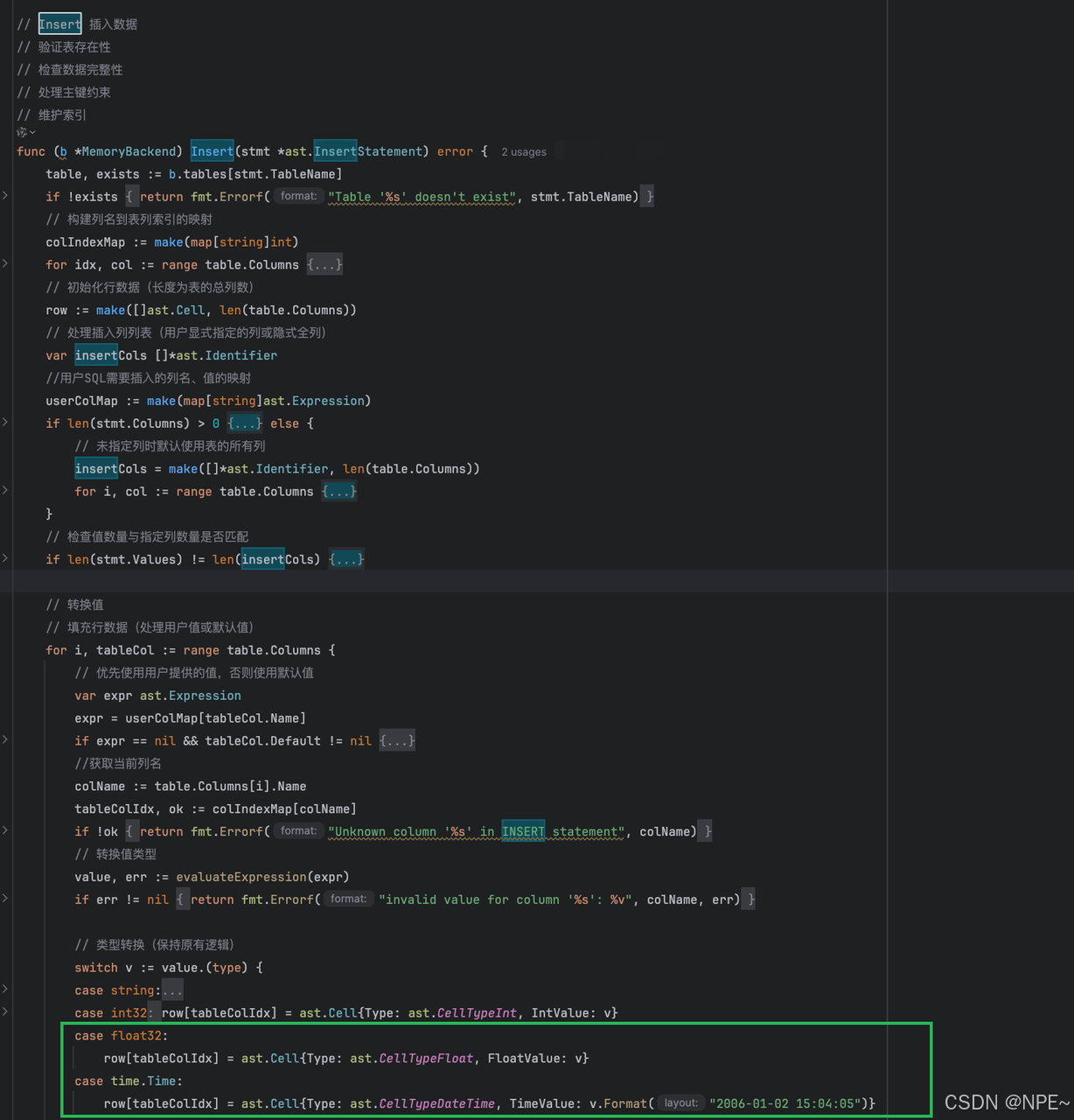
- 更新Insert函數:將抽象語法樹中的datetime、float Literal字面量解析至原始類型并添加至Cell中。
PS:
①ast.Literal 是用戶輸入的表達,ast.Cell 是實際存儲的數據,將Cell struct放在ast.go中不合理,后續會進行優化
②各類Literal,比如:FloatLiteral這里的Value可以存儲原本的值,而非統一用String存儲,避免重復轉換,增加開銷
- 大家可以自己嘗試在原代碼的基礎上進行優化,當做練手
代碼實現
①在詞法分析器中添加新類型
// internal/lexer/token.go
const (// ... 其他標記類型FLOAT TokenType = "FLOAT"DATETIME TokenType = "DATETIME"// ... 其他標記類型
)// internal/lexer/lexer.go
func (l *Lexer) NextToken() Token {var tok Tokenl.skipWhitespace()// ... 其他代碼switch l.ch {// ... 其他casecase '\'':tok.Type = STRINGtok.Literal = l.readString()// 檢查是否為時間格式if _, err := time.Parse("2006-01-02 15:04:05", tok.Literal); err == nil {tok.Type = DATETIME}return tok// ... 其他case}// 處理數字(包括浮點數)if isDigit(l.ch) || l.ch == '.' {num := l.readNumber()if strings.Contains(num, ".") {tok.Type = FLOAT} else {tok.Type = INT}tok.Literal = numreturn tok}// ... 其他代碼
}// internal/lexer/lexer.go
func (l *Lexer) readNumber() string {var num bytes.BufferhasDecimal := falsefor (isDigit(l.ch) || (l.ch == '.' && !hasDecimal)) && l.ch != 0 {if l.ch == '.' {hasDecimal = true}num.WriteRune(l.ch)l.readChar()}return num.String()
}// internal/lexer/lexer.go
func (l *Lexer) lookupIdentifier(ident string) TokenType {switch strings.ToUpper(ident) {// ... 其他casecase "FLOAT":return FLOATcase "DATETIME":return DATETIME// ... 其他case}return IDENT
}
②在 AST 中添加新表達式類型
// internal/ast/ast.go
// 新增FloatLiteral表達式類型
type FloatLiteral struct {BaseExpressionToken lexer.TokenValue string
}// 新增DateTimeLiteral表達式類型
type DateTimeLiteral struct {BaseExpressionToken lexer.TokenValue string
}// 在 Cell 結構體中添加新字段
type Cell struct {Type CellTypeIntValue int32TextValue stringFloatValue float32TimeValue string
}const (CellTypeInt CellType = iotaCellTypeTextCellTypeFloatCellTypeDateTime
)
③在解析器中處理新類型
// internal/parser/parser.go
func (p *Parser) parseExpression() (ast.Expression, error) {switch p.curToken.Type {// ... 其他casecase lexer.FLOAT:return &ast.FloatLiteral{Token: p.curToken,Value: p.curToken.Literal,}, nilcase lexer.DATETIME:return &ast.DateTimeLiteral{Token: p.curToken,Value: p.curToken.Literal,}, nil// ... 其他case}
}
④在存儲引擎中處理新數據類型
// internal/storage/memory.go
// 修改 evaluateExpression 函數以處理新類型
func evaluateExpression(expr ast.Expression) (interface{}, error) {switch e := expr.(type) {// ... 其他casecase *ast.FloatLiteral:val, err := strconv.ParseFloat(e.Value, 32)if err != nil {return nil, fmt.Errorf("Incorrect float value: '%s'", e.Value)}return float32(val), nilcase *ast.DateTimeLiteral:t, err := time.Parse("2006-01-02 15:04:05", e.Value)if err != nil {return nil, fmt.Errorf("Incorrect datetime value: '%s'", e.Value)}return t, nil// ... 其他case}
}// 在 Insert 方法中處理新類型
func (b *MemoryBackend) Insert(stmt *ast.InsertStatement) error {// ... 其他代碼// 類型轉換(保持原有邏輯)switch v := value.(type) {// ... 其他casecase float32:row[tableColIdx] = ast.Cell{Type: ast.CellTypeFloat, FloatValue: v}case time.Time:row[tableColIdx] = ast.Cell{Type: ast.CellTypeDateTime, TimeValue: v.Format("2006-01-02 15:04:05")}// ... 其他case}// ... 其他代碼
}// 在 getColumnValue 中處理新類型
func getColumnValue(expr ast.Expression, row []ast.Cell, columns []ast.ColumnDefinition) (interface{}, error) {switch e := expr.(type) {// ... 其他casecase *ast.FloatLiteral:val, err := strconv.ParseFloat(e.Value, 32)if err != nil {return nil, fmt.Errorf("Incorrect float value: '%s'", e.Value)}return float32(val), nilcase *ast.DateTimeLiteral:val, err := time.Parse("2006-01-02 15:04:05", e.Value)if err != nil {return nil, fmt.Errorf("Incorrect datetime value: '%s'", e.Value)}return val, nil// ... 其他case}
}
測試
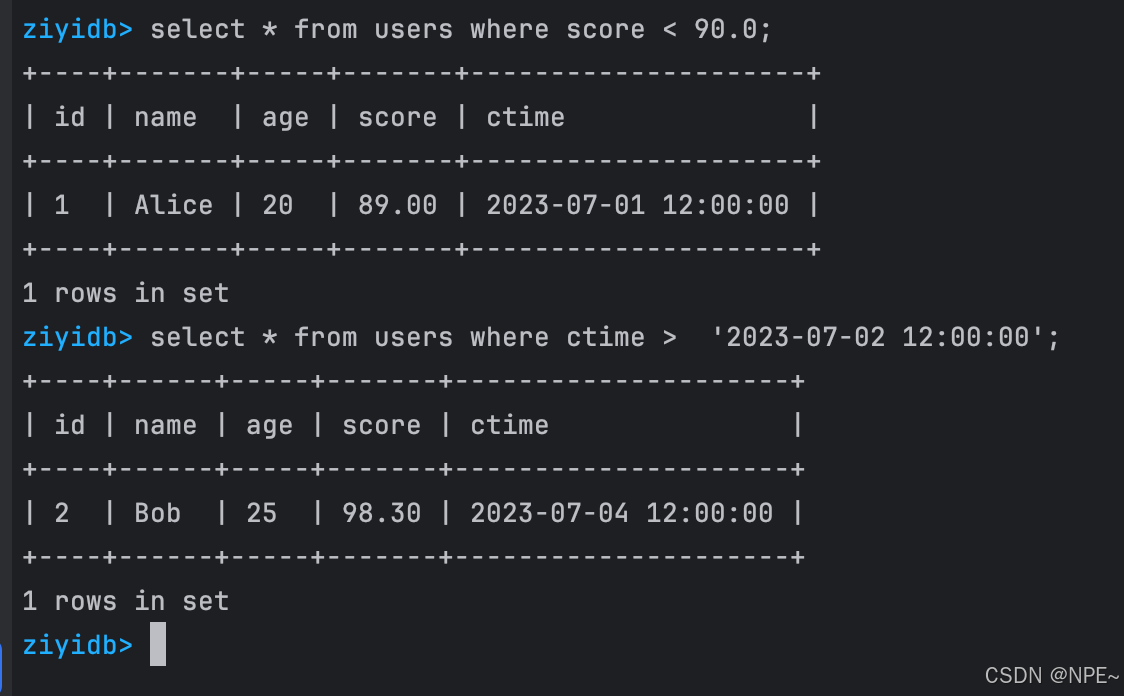
測試SQL:
CREATE TABLE users (id INT PRIMARY KEY,name text,age INT,score FLOAT, ctime DATETIME );
INSERT INTO users VALUES (1, 'Alice', 20,89.0, '2023-07-01 12:00:00');
INSERT INTO users VALUES (2, 'Bob', 25,98.3, '2023-07-04 12:00:00');select * from users where score < 90.0;
select * from users where ctime > '2023-07-02 12:00:00';
drop table users;
效果:
2. 新增對 BETWEEN AND 關鍵字的支持
實現思路
BETWEEN AND 是一個用于范圍查詢的操作符。我們需要在詞法分析器中識別這兩個關鍵字,在 AST 中添加新的表達式類型,在解析器中處理這種語法結構,并在存儲引擎中實現相應的查詢邏輯。
- lexer/token.go中新增BETWEEN、AND的TokenType常量

- lexer/lexer.go中的lookupIdentifier方法新增對BETWEEN、AND關鍵字的讀取,將用戶的字符輸入轉換為TokenType

- ast/ast.go抽象語法樹中新增BetweenExpression struct,用于將between and內容構建到語法樹中

- parser/parser.go語法解析器:
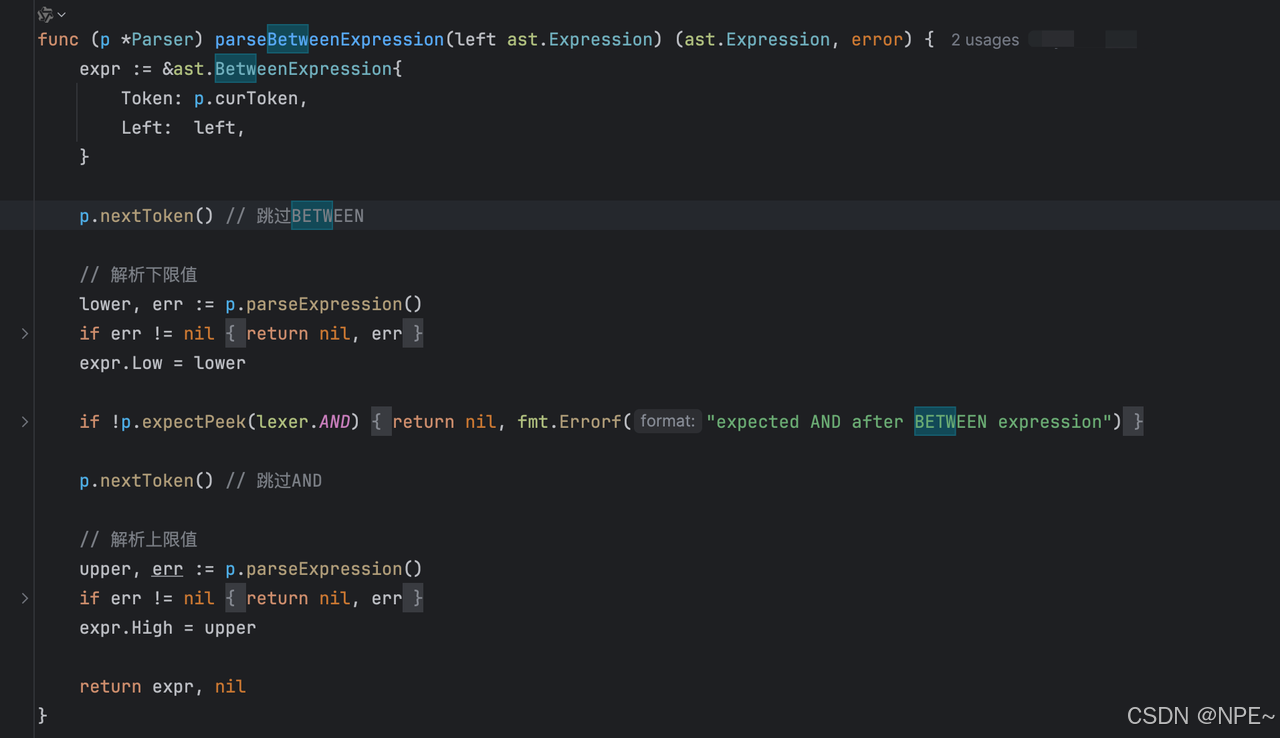
- 新增parseBetweenExpression函數,用于將用戶輸入的between and部分解析為ast.BetweenExpression
- 各語法的Statement部分新增對between and的處理(比如select、delete、update語句…)
例:parseSelectStatement部分(構建select的抽象語法樹)新增對between and關鍵字的處理,將其轉換為where條件部分
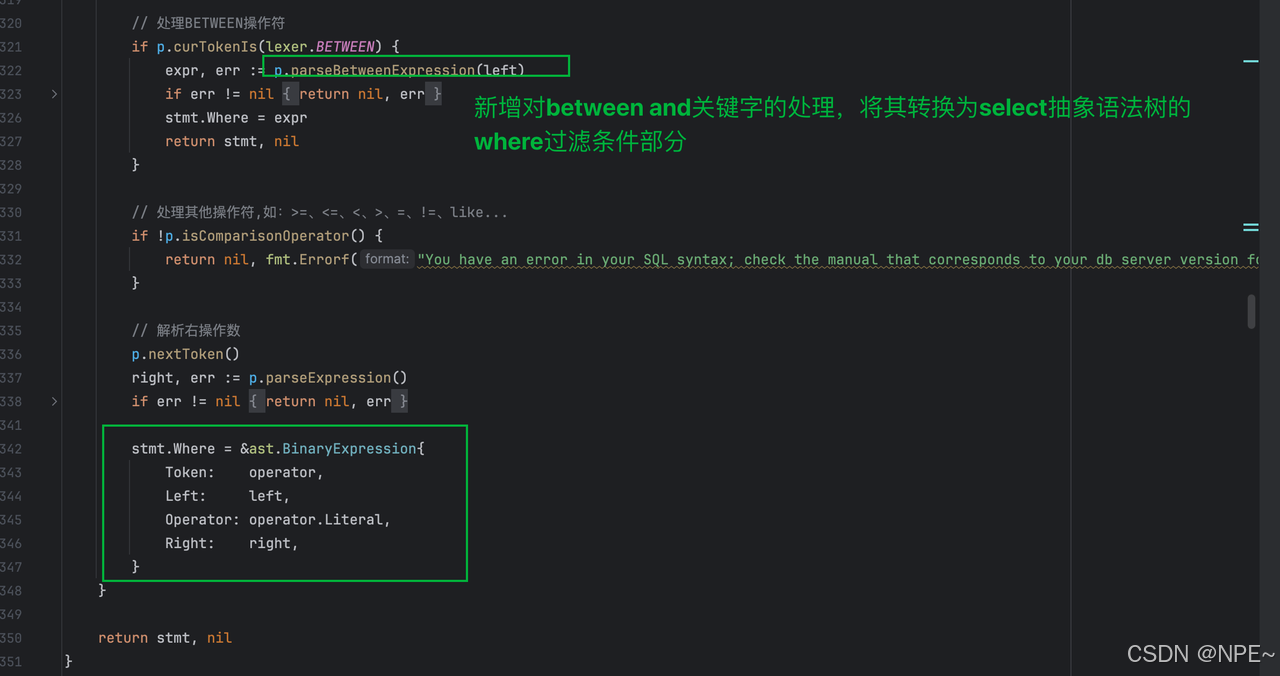
- storage/memory.go中新增對*ast.BetweenExpression的處理,判斷當前數據是否滿足between and過濾條件
代碼實現
①在詞法分析器中添加關鍵字
// internal/lexer/token.go
const (// ... 其他標記類型BETWEEN TokenType = "BETWEEN"AND TokenType = "AND"// ... 其他標記類型
)// internal/lexer/lexer.go
func (l *Lexer) lookupIdentifier(ident string) TokenType {switch strings.ToUpper(ident) {// ... 其他casecase "BETWEEN":return BETWEENcase "AND":return AND// ... 其他case}return IDENT
}
②在 AST 中添加 BETWEEN 表達式
// internal/ast/ast.go
// BetweenExpression 表示 BETWEEN AND 表達式
type BetweenExpression struct {Token lexer.Token // BETWEEN 標記Left Expression // 左操作數(列名或表達式)Low Expression // 下限值High Expression // 上限值
}func (be *BetweenExpression) expressionNode() {}
func (be *BetweenExpression) TokenLiteral() string { return be.Token.Literal }
③在解析器中處理 BETWEEN 語法
// internal/parser/parser.go
// 在 parseSelectStatement、parseUpdateStatement 和 parseDeleteStatement 中添加處理邏輯
func (p *Parser) parseSelectStatement() (*ast.SelectStatement, error) {// ... 其他代碼// 解析WHERE子句if p.peekTokenIs(lexer.WHERE) {p.nextToken()p.nextToken()// 解析左操作數(列名)if !p.curTokenIs(lexer.IDENT) {return nil, fmt.Errorf("You have an error in your SQL syntax; check the manual that corresponds to your db server version for the right syntax to use near '%s'", p.curToken.Literal)}left := &ast.Identifier{Token: p.curToken,Value: p.curToken.Literal,}// 解析操作符p.nextToken()operator := p.curToken// 處理BETWEEN操作符if p.curTokenIs(lexer.BETWEEN) {expr, err := p.parseBetweenExpression(left)if err != nil {return nil, err}stmt.Where = exprreturn stmt, nil}// ... 其他代碼}// ... 其他代碼
}// 解析BETWEEN表達式
func (p *Parser) parseBetweenExpression(left ast.Expression) (ast.Expression, error) {expr := &ast.BetweenExpression{Token: p.curToken,Left: left,}p.nextToken() // 跳過BETWEEN// 解析下限值lower, err := p.parseExpression()if err != nil {return nil, err}expr.Low = lowerif !p.expectPeek(lexer.AND) {return nil, fmt.Errorf("expected AND after BETWEEN expression")}p.nextToken() // 跳過AND// 解析上限值upper, err := p.parseExpression()if err != nil {return nil, err}expr.High = upperreturn expr, nil
}
④在存儲引擎中實現 BETWEEN 查詢邏輯
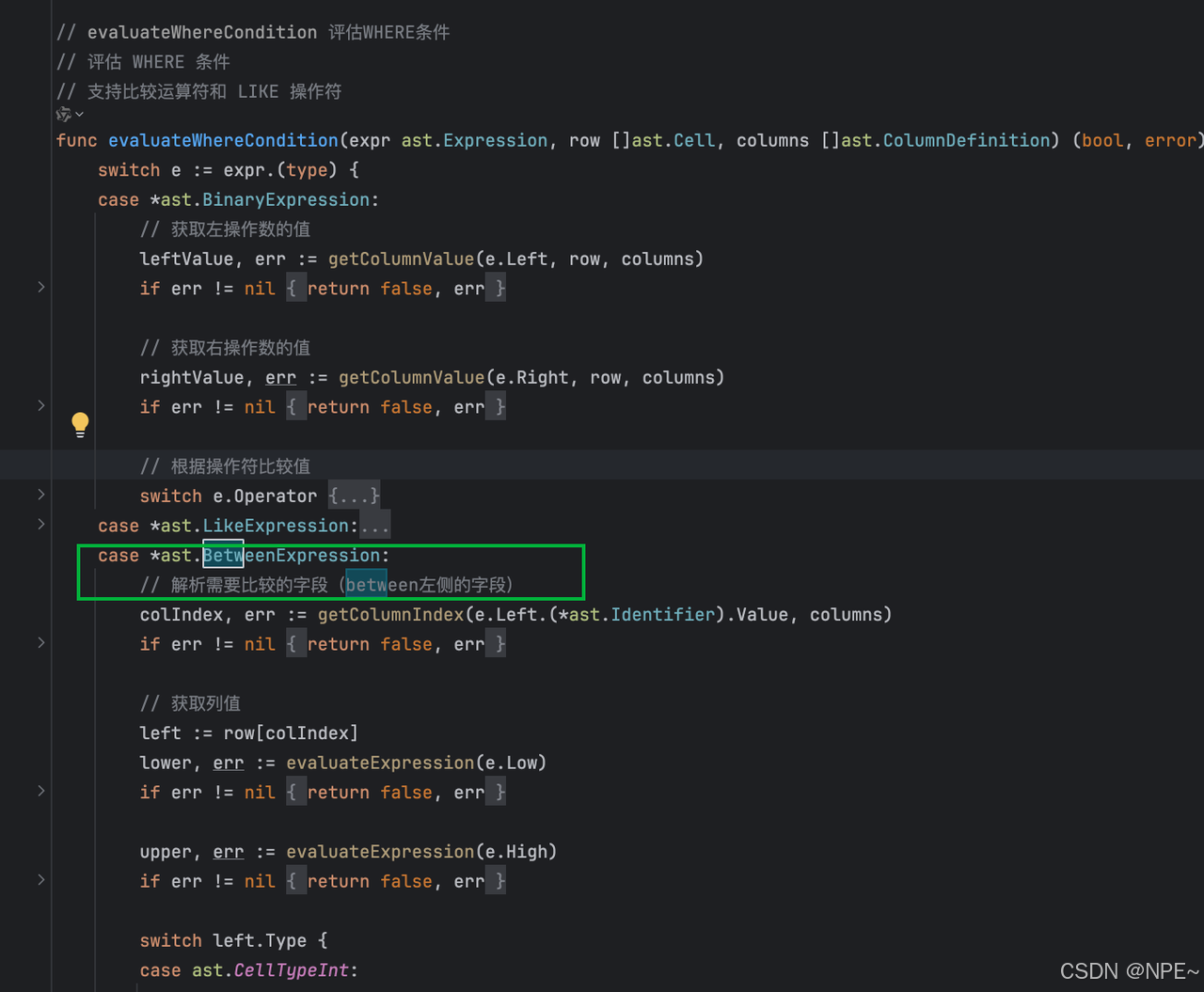
// internal/storage/memory.go
// 在 evaluateWhereCondition 中處理 BETWEEN 表達式
func evaluateWhereCondition(expr ast.Expression, row []ast.Cell, columns []ast.ColumnDefinition) (bool, error) {switch e := expr.(type) {// ... 其他casecase *ast.BetweenExpression:// 獲取列值colIndex, err := getColumnIndex(e.Left.(*ast.Identifier).Value, columns)if err != nil {return false, err}left := row[colIndex]lower, err := evaluateExpression(e.Low)if err != nil {return false, err}upper, err := evaluateExpression(e.High)if err != nil {return false, err}switch left.Type {case ast.CellTypeInt:leftVal := left.IntValuelowerVal, lok := lower.(int32)upperVal, uok := upper.(int32)if !lok || !uok {return false, fmt.Errorf("type mismatch in BETWEEN expression")}return leftVal >= lowerVal && leftVal <= upperVal, nilcase ast.CellTypeFloat:leftVal := left.FloatValuelowerVal, lok := lower.(float32)upperVal, uok := upper.(float32)if !lok || !uok {return false, fmt.Errorf("type mismatch in BETWEEN expression")}return leftVal >= lowerVal && leftVal <= upperVal, nilcase ast.CellTypeDateTime:val := left.TimeValueleftVal, err := time.Parse("2006-01-02 15:04:05", val)if err != nil {return false, err}lowerVal, lok := lower.(time.Time)upperVal, uok := upper.(time.Time)if !lok || !uok {return false, fmt.Errorf("type mismatch in BETWEEN expression")}return (leftVal.After(lowerVal) || leftVal.Equal(lowerVal)) &&(leftVal.Before(upperVal) || leftVal.Equal(upperVal)), nildefault:return false, fmt.Errorf("unsupported type in BETWEEN expression")}// ... 其他case}
}
測試
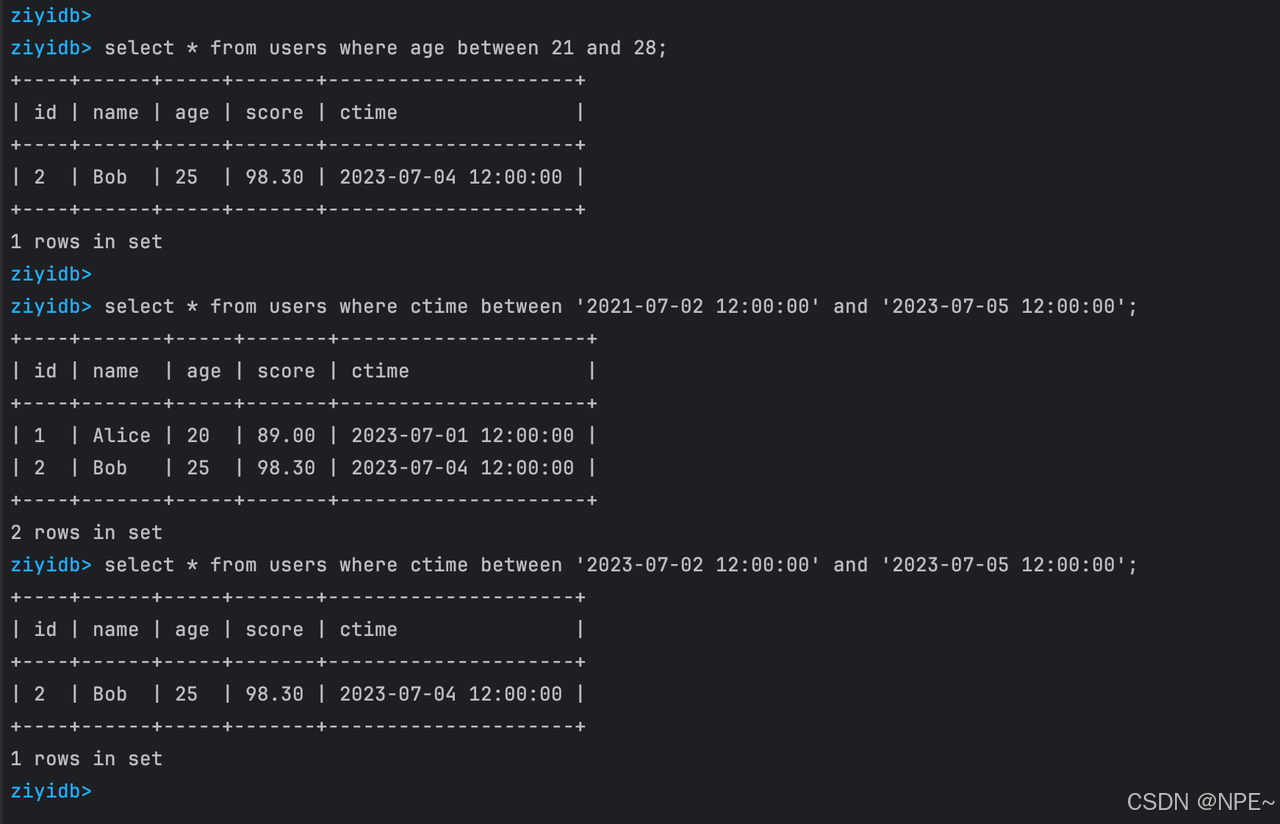
測試SQL:
CREATE TABLE users (id INT PRIMARY KEY,name text,age INT,score FLOAT, ctime DATETIME ); INSERT INTO users VALUES (1, 'Alice', 20,89.0, '2023-07-01 12:00:00');
INSERT INTO users VALUES (2, 'Bob', 25,98.3, '2023-07-04 12:00:00');select * from users where age between 21 and 28;
select * from users where ctime between '2021-07-02 12:00:00' and '2023-07-05 12:00:00';
select * from users where ctime between '2023-07-02 12:00:00' and '2023-07-05 12:00:00';
drop table users;
效果:
3. 新增對注釋符的支持
實現思路
SQL 注釋以--開頭,直到行尾。我們需要在詞法分析器中識別注釋并跳過它們,在解析器中忽略注釋標記。
- lexer/token.go中新增注釋符標識
--,用于匹配用戶輸入。

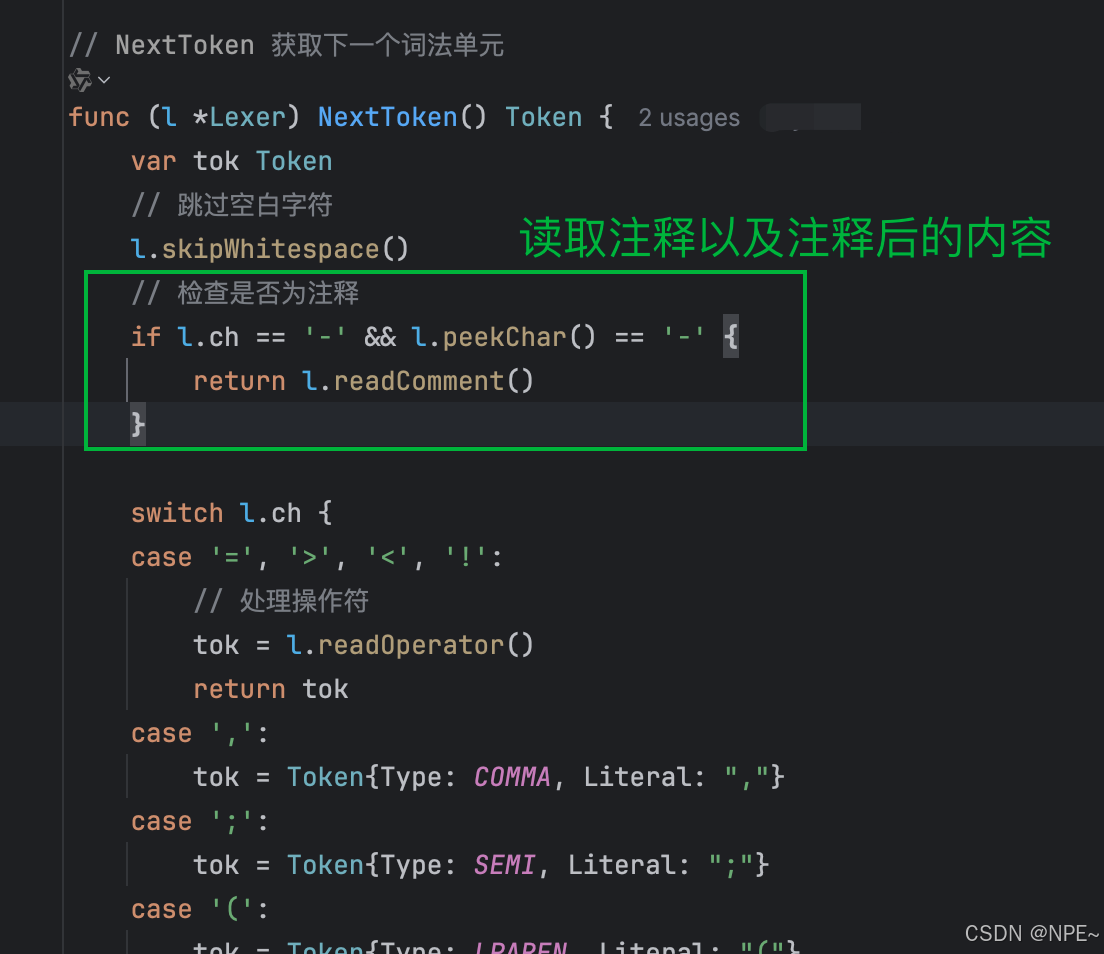
- lexer/lexer.go詞法分析器中,讀取注釋即注釋后的內容
效果:
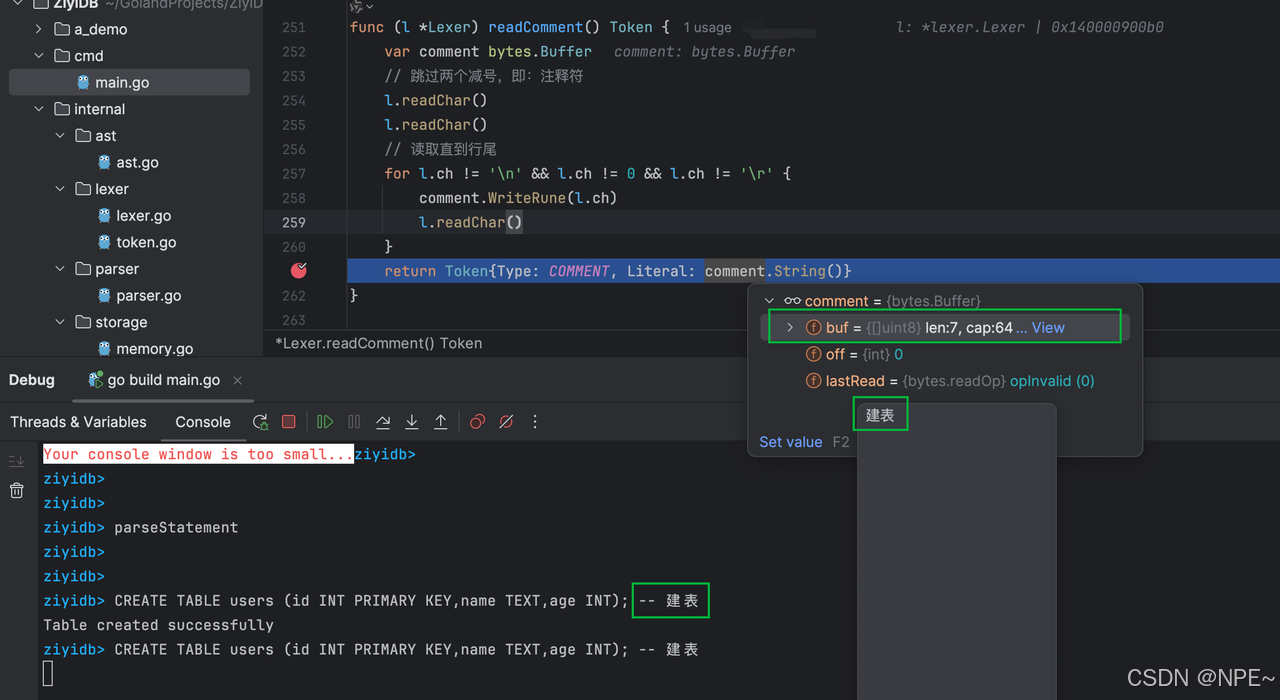
- parser/parser.go語法解析器中的ParseProgram、parseStatement忽略注釋符之后的內容,遇到注釋符即跳過
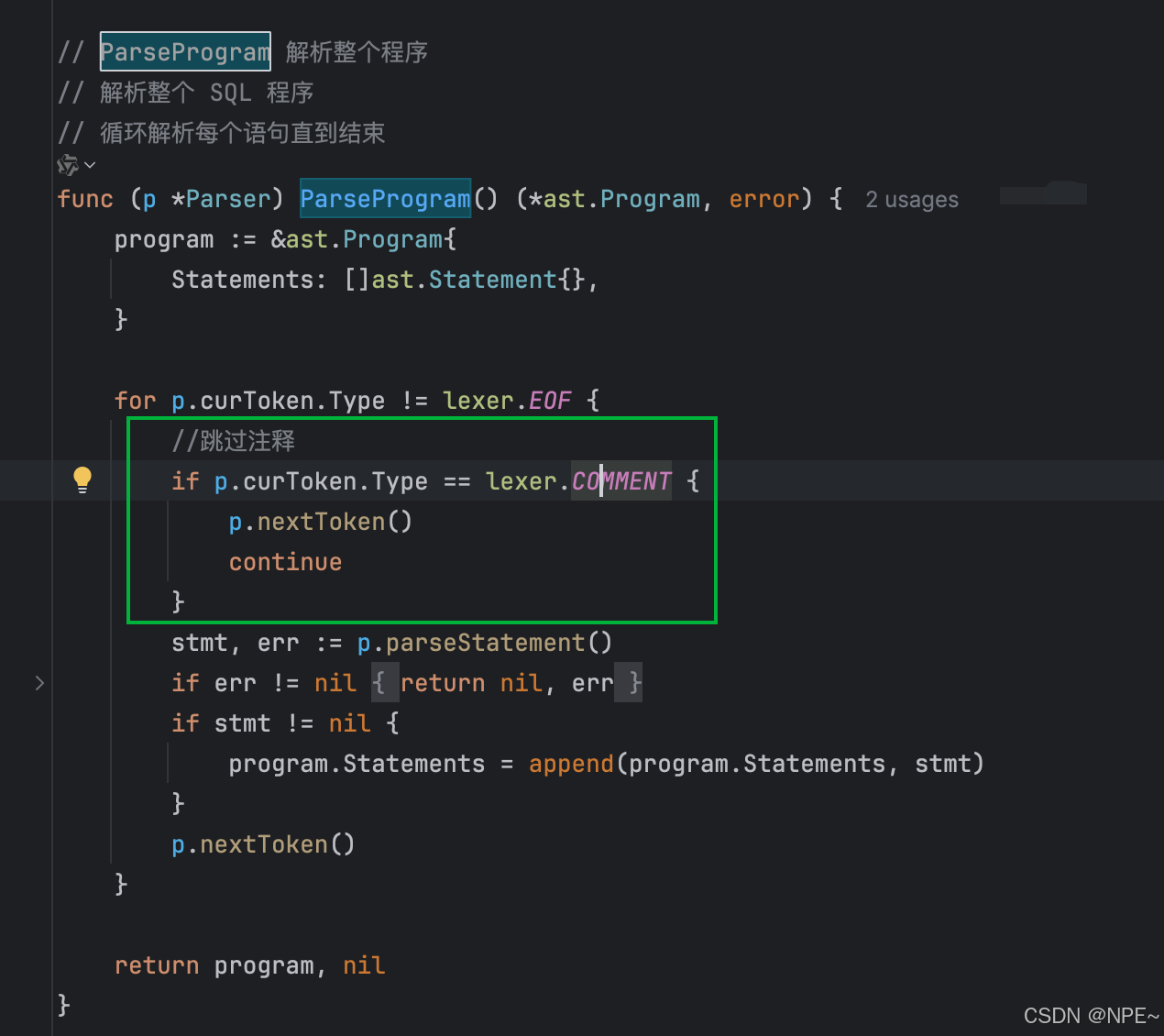
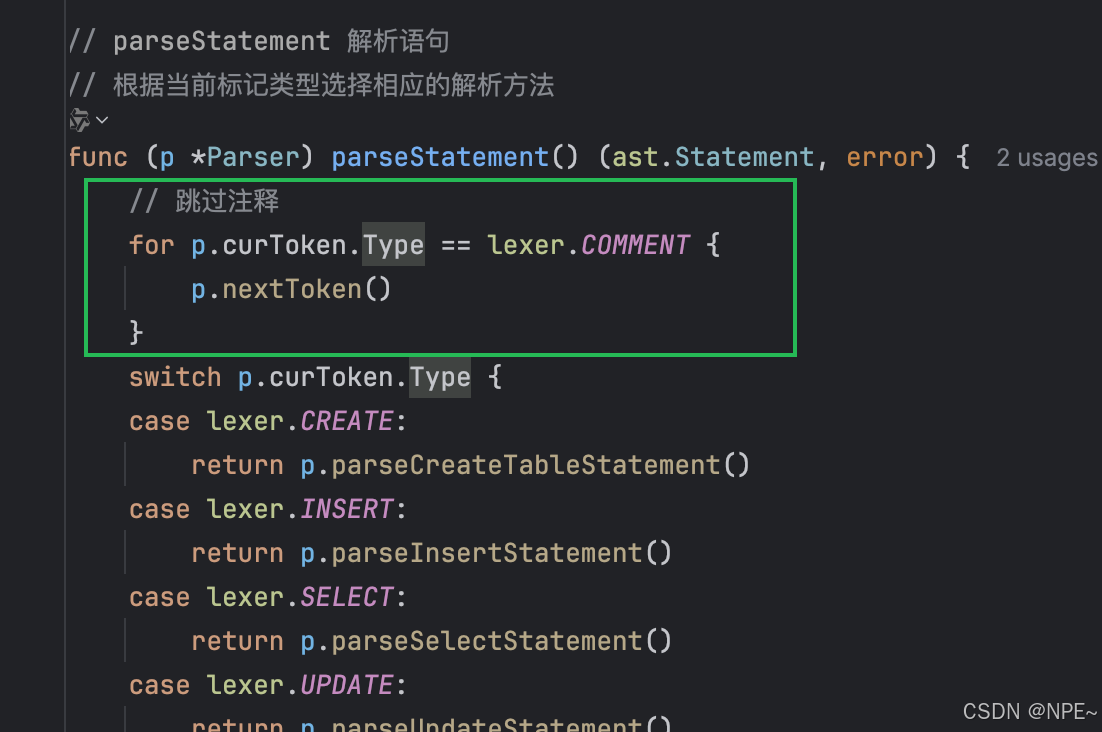
代碼實現
①在詞法分析器中添加注釋支持
// internal/lexer/token.go
const (// ... 其他標記類型COMMENT TokenType = "--"// ... 其他標記類型
)// internal/lexer/lexer.go
func (l *Lexer) NextToken() Token {var tok Tokenl.skipWhitespace()// 檢查是否為注釋if l.ch == '-' && l.peekChar() == '-' {return l.readComment()}// ... 其他代碼
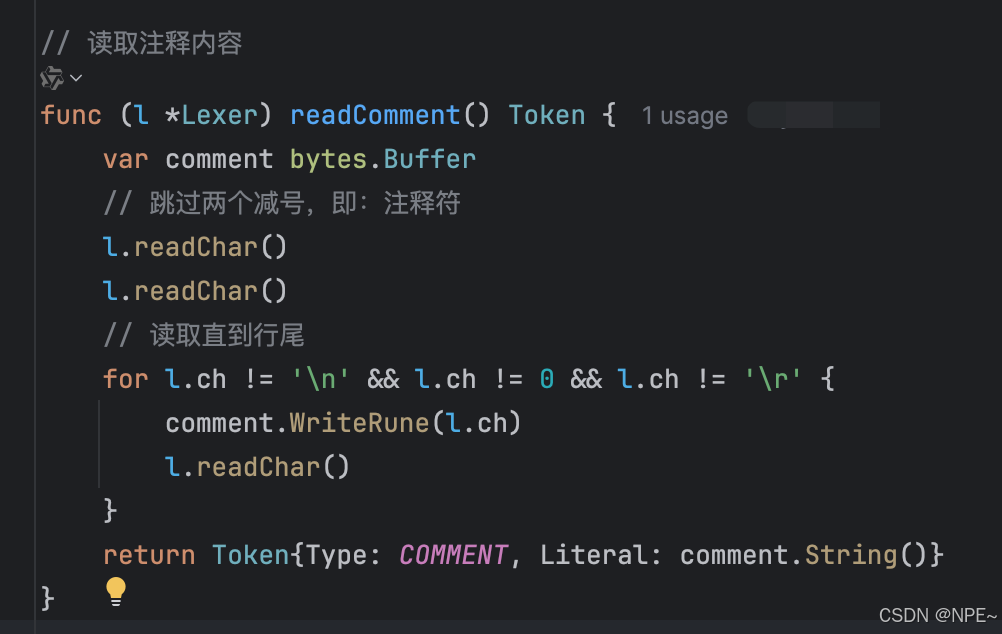
}// 讀取注釋內容
func (l *Lexer) readComment() Token {var comment bytes.Bufferl.readChar() // 跳過第一個 '-'l.readChar() // 跳過第二個 '-'// 讀取直到行尾for l.ch != '\n' && l.ch != 0 && l.ch != '\r' {comment.WriteRune(l.ch)l.readChar()}return Token{Type: COMMENT, Literal: comment.String()}
}
②在解析器中忽略注釋
// internal/parser/parser.go
func (p *Parser) ParseProgram() (*ast.Program, error) {program := &ast.Program{Statements: []ast.Statement{},}for p.curToken.Type != lexer.EOF {// 跳過注釋if p.curToken.Type == lexer.COMMENT {p.nextToken()continue}stmt, err := p.parseStatement()if err != nil {return nil, err}if stmt != nil {program.Statements = append(program.Statements, stmt)}p.nextToken()}return program, nil
}// parseStatement 中也跳過注釋
func (p *Parser) parseStatement() (ast.Statement, error) {// 跳過注釋for p.curToken.Type == lexer.COMMENT {p.nextToken()}// ... 其他代碼
}
測試
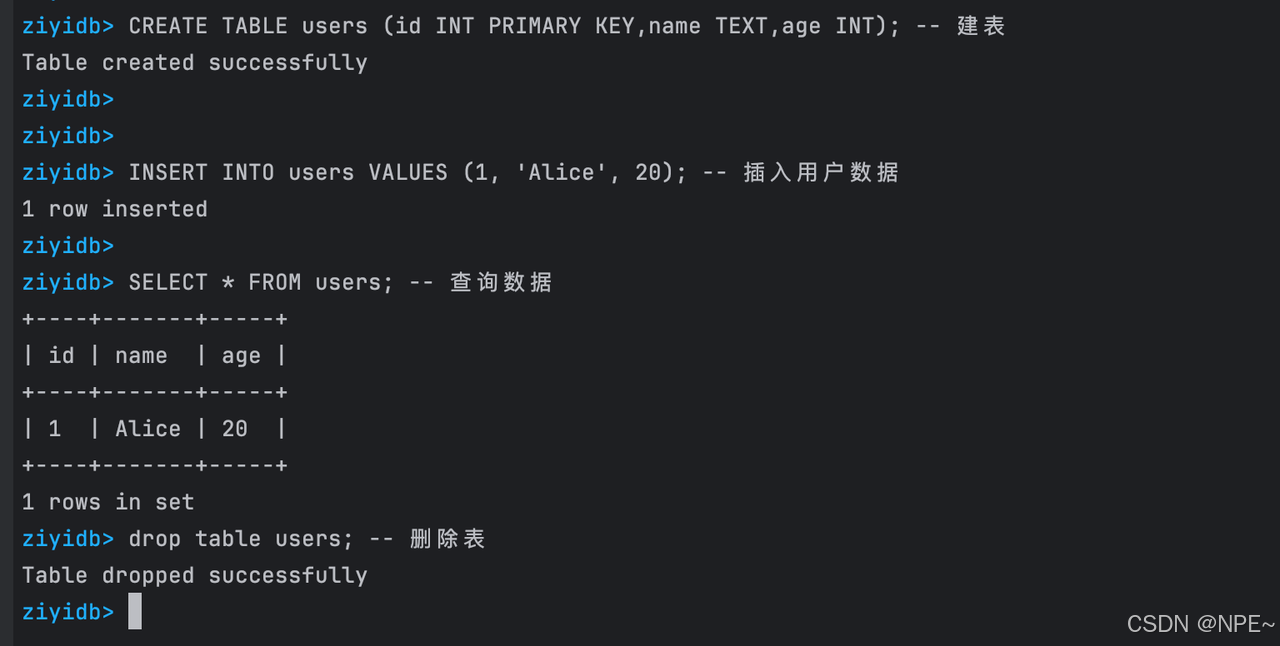
測試SQL:
CREATE TABLE users (id INT PRIMARY KEY,name TEXT,age INT); -- 建表
INSERT INTO users VALUES (1, 'Alice', 20); -- 插入用戶數據
SELECT * FROM users; -- 查詢數據
drop table users; -- 刪除表
效果:
4. 新增對 >=、<=、!= 操作符的支持
實現思路
我們需要在詞法分析器中識別這些新的操作符,在解析器中處理它們,并在存儲引擎中實現相應的比較邏輯。
- lexer/token.go中新增>=、<=、!=
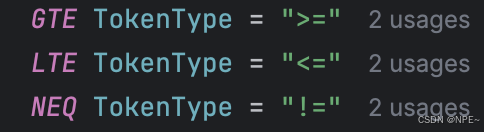
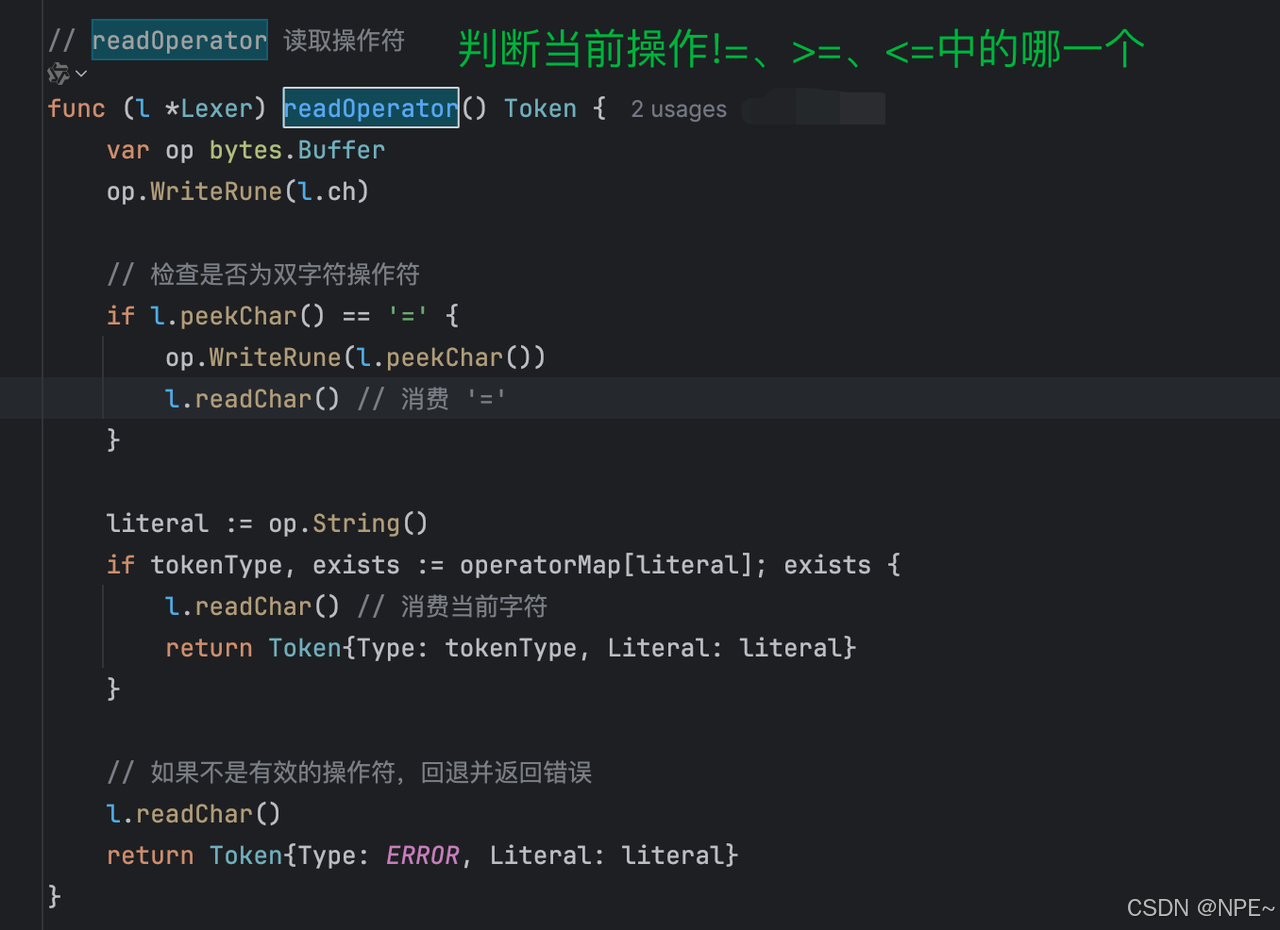
- lexer/lexer.go詞法分析器中新增對!=、>=、<=操作符的識別,將字符映射為對應的token
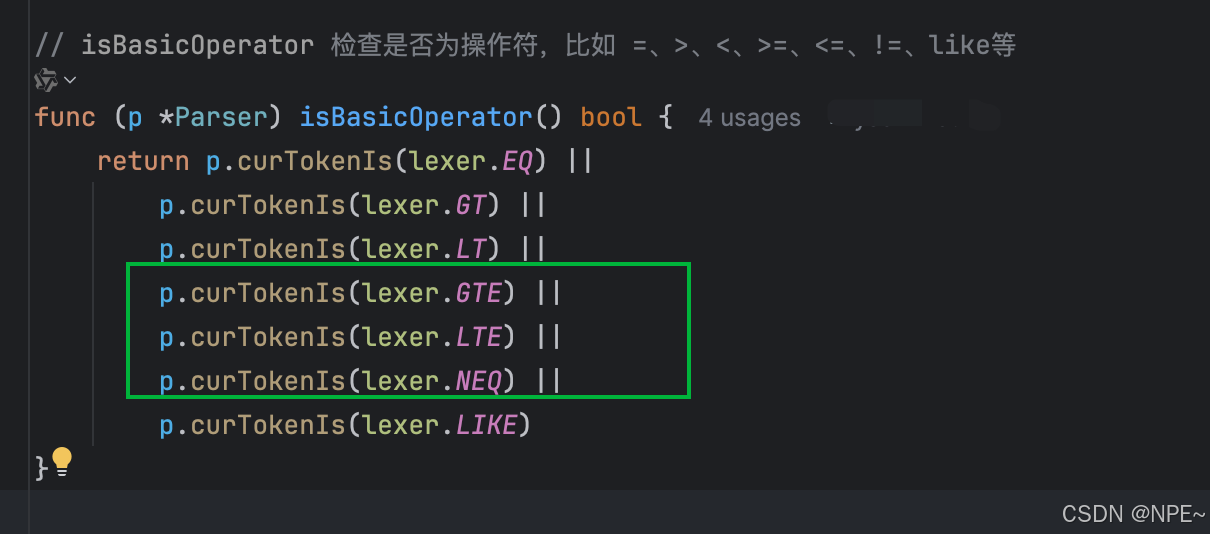
- parser/parser.go語法解析器中isBasicOperator操作符判斷中新增<=、>=、!=,用于檢查是否屬于SQL操作符
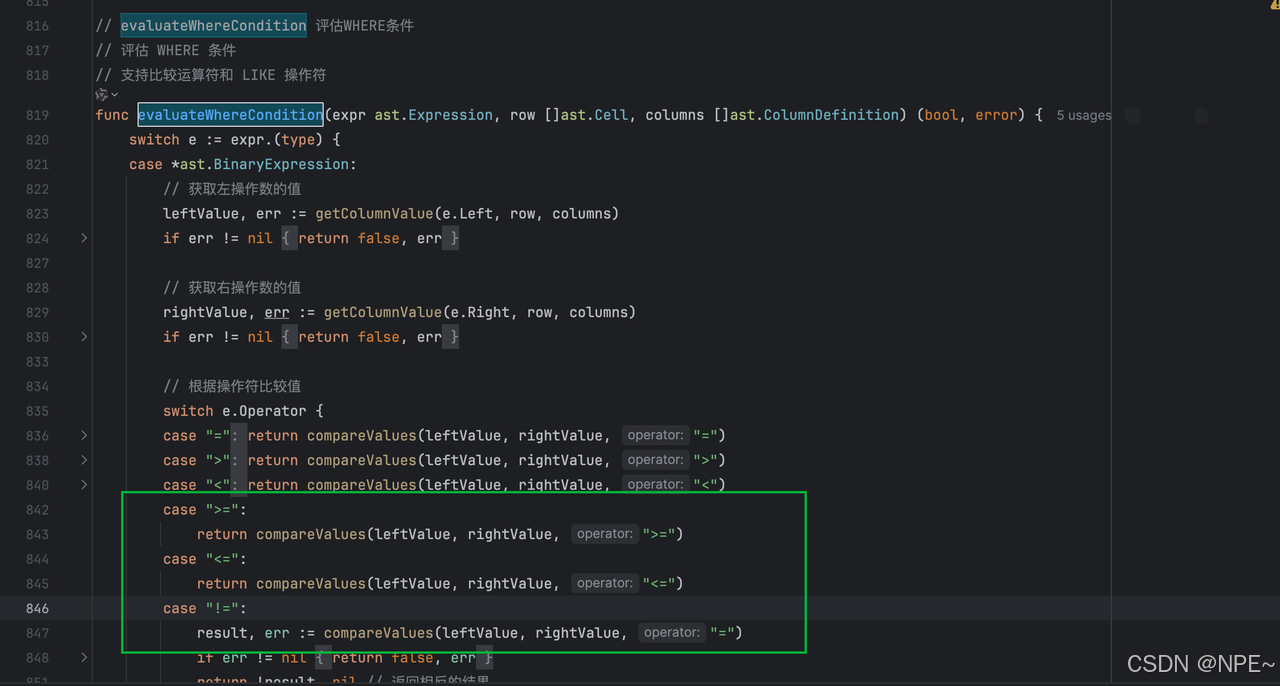
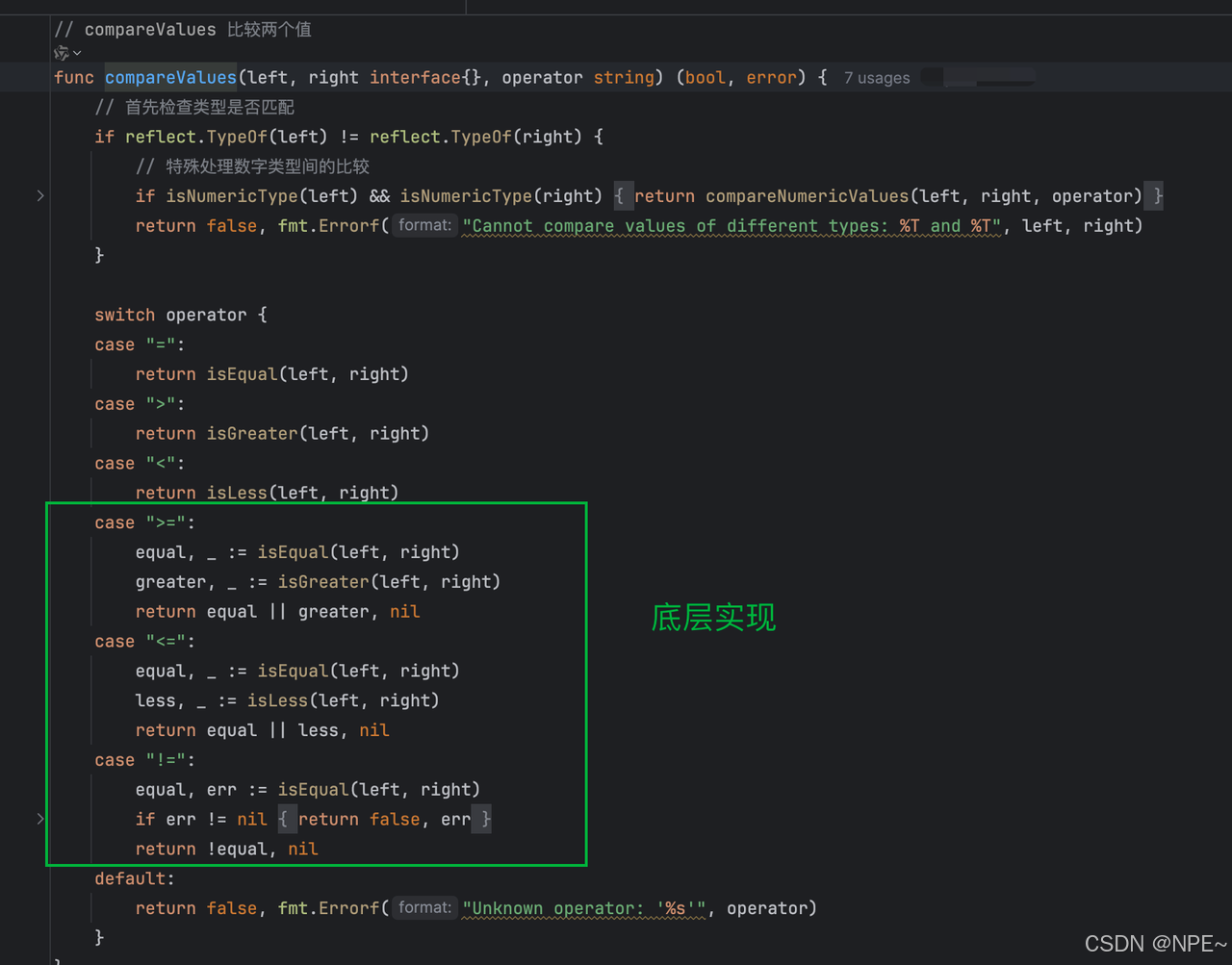
- storage/memory.go存儲引擎中的evaluateWhereCondition、compareValues方法中實現對>=、<=、!=的底層邏輯
代碼實現
①在詞法分析器中添加新操作符
// internal/lexer/token.go
const (// ... 其他標記類型GTE TokenType = ">=" // >=LTE TokenType = "<=" // <=NEQ TokenType = "!=" // !=// ... 其他標記類型
)// internal/lexer/lexer.go
var operatorMap = map[string]TokenType{"=": EQ,">": GT,"<": LT,">=": GTE,"<=": LTE,"!=": NEQ,
}func (l *Lexer) readOperator() Token {var op bytes.Bufferop.WriteRune(l.ch)// 檢查是否為雙字符操作符if l.peekChar() == '=' {op.WriteRune(l.peekChar())l.readChar() // 消費 '='}literal := op.String()if tokenType, exists := operatorMap[literal]; exists {l.readChar() // 消費當前字符return Token{Type: tokenType, Literal: literal}}// 如果不是有效的操作符,回退并返回錯誤l.readChar()return Token{Type: ERROR, Literal: literal}
}
②在解析器中處理新操作符
// internal/parser/parser.go
// isBasicOperator 檢查是否為操作符,比如 =、>、<、>=、<=、!=、like等
func (p *Parser) isBasicOperator() bool {return p.curTokenIs(lexer.EQ) ||p.curTokenIs(lexer.GT) ||p.curTokenIs(lexer.LT) ||p.curTokenIs(lexer.GTE) ||p.curTokenIs(lexer.LTE) ||p.curTokenIs(lexer.NEQ) ||p.curTokenIs(lexer.LIKE)
}
③在存儲引擎中實現新操作符的比較邏輯
// internal/storage/memory.go
// 在 evaluateWhereCondition 中處理新操作符
func evaluateWhereCondition(expr ast.Expression, row []ast.Cell, columns []ast.ColumnDefinition) (bool, error) {switch e := expr.(type) {case *ast.BinaryExpression:// 獲取左操作數的值leftValue, err := getColumnValue(e.Left, row, columns)if err != nil {return false, err}// 獲取右操作數的值rightValue, err := getColumnValue(e.Right, row, columns)if err != nil {return false, err}// 根據操作符比較值switch e.Operator {case "=":return compareValues(leftValue, rightValue, "=")case ">":return compareValues(leftValue, rightValue, ">")case "<":return compareValues(leftValue, rightValue, "<")case ">=":return compareValues(leftValue, rightValue, ">=")case "<=":return compareValues(leftValue, rightValue, "<=")case "!=":result, err := compareValues(leftValue, rightValue, "=")if err != nil {return false, err}return !result, nil // 返回相反的結果default:return false, fmt.Errorf("Unknown operator: '%s'", e.Operator)}// ... 其他case}
}// 在 compareValues 中處理新操作符
func compareValues(left, right interface{}, operator string) (bool, error) {// ... 其他代碼switch operator {case "=":return isEqual(left, right)case ">":return isGreater(left, right)case "<":return isLess(left, right)case ">=":equal, _ := isEqual(left, right)greater, _ := isGreater(left, right)return equal || greater, nilcase "<=":equal, _ := isEqual(left, right)less, _ := isLess(left, right)return equal || less, nilcase "!=":equal, err := isEqual(left, right)if err != nil {return false, err}return !equal, nildefault:return false, fmt.Errorf("Unknown operator: '%s'", operator)}
}
測試
測試SQL:
CREATE TABLE users (id INT PRIMARY KEY,name TEXT,age INT);INSERT INTO users VALUES (1, 'Alice', 20);
INSERT INTO users VALUES (2, 'Bob', 25);
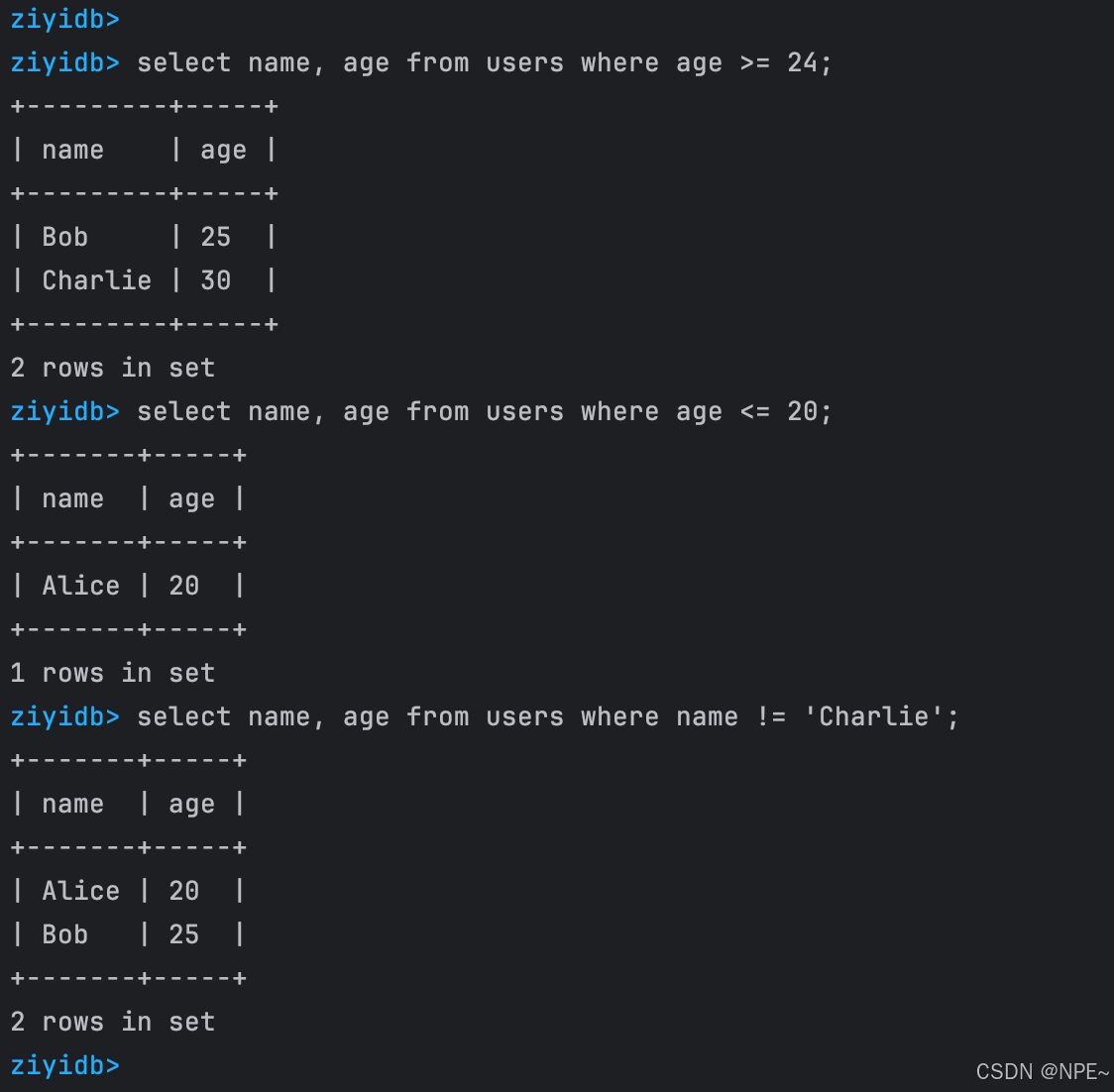
INSERT INTO users VALUES (3, 'Charlie', 30);select name, age from users where age >= 24;
select name, age from users where age <= 20;
select name, age from users where name != 'Charlie';drop table users;
效果:



-記錄實戰教程及問題的解決方法-(day3-3)完善菜品分頁查詢功能)






-> styleSheet)



8.27)




