目錄
前言
一、預處理符號
二、#define 定義常量
三、#define 定義宏
四、帶有副作用的宏參數
五、宏替換的規則
六、宏函數對比
七、# 和 ##
7.1? #運算符
7.2? ##運算符
八、命名約定
九、#undef
十、命令行定義
十一、條件編譯
十二、頭文件的包含
12.1? 頭文件被包含的方式
12.1.1? 本地文件包含
12.1.2? 庫文件包含
12.2? 嵌套文件包含
十三、其他預處理指令
? ? ? ? 注意:
總結
前言
????????在C語言開發中,預處理階段是編譯過程中不可或缺的關鍵環節,它通過宏替換、條件編譯和文件包含等機制,為代碼的靈活性和可維護性提供了強大的支持。預處理指令雖然不直接參與程序運行,卻在代碼組織、跨平臺適配以及性能優化等方面發揮著重要作用。深入理解預處理的工作原理與高級用法,不僅能幫助開發者規避潛在的宏陷阱,還能解鎖諸如代碼生成、調試控制等進階技巧。下面就讓我們正式開始吧!
一、預處理符號
? ? ? ? C語言設置了一些預定義符號,可以供我們直接使用,預定義符號也是在預處理期間處理的。
__FILE__ //進?編譯的源?件
__LINE__ //?件當前的?號
__DATE__ //?件被編譯的?期
__TIME__ //?件被編譯的時間
__STDC__ //如果編譯器遵循ANSI C,其值為1,否則未定義? ? ? ? 舉個使用的例子:
printf("file:%s line:%d\n", __FILE__, __LINE__);二、#define 定義常量
? ? ? ? 基本語法如下:
#define name stuff? ? ? ? 我們再來舉一些使用的例子:
#define MAX 1000 //定義一個常量MAX為1000
#define reg register //為 register這個關鍵字,創建?個簡短的名字
#define do_forever for(;;) //?更形象的符號來替換?種實現
#define CASE break;case //在寫case語句的時候?動把 break寫上。
// 如果定義的 stuff過?,可以分成??寫,除了最后??外,每?的后?都加?個反斜杠(續?
符)。
#define DEBUG_PRINT printf("file:%s\tline:%d\t \date:%s\ttime:%s\n" ,\__FILE__,__LINE__ , \__DATE__,__TIME__ )? ? ? ? 讓我們思考一下:在define定義標識符的時候,要不要在最后加上 “;”?
? ? ? ? 比如:
#define MAX 1000;
#define MAX 1000? ? ? ? 建議不要加上“;”,這樣容易導致問題。比如下面的場景:
if(condition)max = MAX;
elsemax = 0;? ? ? ? 如果是加了分號的情況,等替換之后,if和else之間就是2條語句,而沒有大括號的時候,if后邊只能有一條語句。因此這里會出現語法錯誤。
三、#define 定義宏
? ? ? ? #define 機制包括了一個規定,允許把參數替換到文本中,這種實現通常稱為宏(macro)或者定義宏(define macro)。
? ? ? ??以下是宏的申明方式:
#define name( parament-list ) stuff? ? ? ? 其中的 parament - list 是一個由逗號隔開的符號表,它們可能會出現在stuff中。
? ? ? ? 需要注意的是:參數列表的左括號必須與name緊鄰,如果兩者之間有任何的空白存在,參數列表就會被解釋為stuff的一部分。
? ? ? ? 下面我們依舊來舉個例子:
#define SQUARE( x ) x * x? ? ? ? 上面這個宏接收一個參數x,如果在上述聲明之后,我們把?SQUARE(5);? 置于程序中,預處理器就會用下面這個表達式替換上面的表達式:5 * 5。
? ? ? ? 注意:上面這個宏其實存在一個問題,我們先來觀察一下下面的代碼段:
int a = 5;
printf("%d\n" ,SQUARE( a + 1) );? ? ? ? 乍一看,你或許會覺得這段代碼將打印36,實際上它將打印11,這是為什么呢?
? ? ? ? 在替換文本的時候,參數x被替換成了a+1,所以這條語句實際上變成了:
printf ("%d\n",a + 1 * a + 1 );? ? ? ? 這樣就比較清晰了,由替換產生的表達式并沒有按照我們預想的次序進行求值。
? ? ? ? 不過,我們只需要在宏定義上加兩個括號,就可以輕松解決這個問題了:
#define SQUARE(x) (x) * (x)? ? ? ? 這樣預處理之后就產生了預期的效果:
printf ("%d\n",(a + 1) * (a + 1) );? ? ? ? 再來看下面這個宏定義:
#define DOUBLE(x) (x) + (x)? ? ? ? 在定義中我們使用了括號,想避免之前的問題,但是這個宏可能會出現新的錯誤:
int a = 5;
printf("%d\n" ,10 * DOUBLE(a));? ? ? ? 這將打印出什么值呢?看上去好像打印的會是100,但事實上并非如此,而是55。
? ? ? ? 我們可以發現在替換之后:
printf ("%d\n",10 * (5) + (5));? ? ? ? 乘法運算是優先于宏定義的加法的,所以最后出現了10 * 5 + 5 = 55。
? ? ? ? 要想解決這個問題,只需要在宏定義表達式兩邊加上一對括號:
#define DOUBLE(x) ( ( x ) + ( x ) )? ? ? ? 下面是一些提示:
? ? ? ? 用于對數值表達式進行求值的宏定義應當用這種方式加上括號,從而避免在使用宏的時候由于參數中的操作符或者鄰近操作符之間不可預料的相互作用。
四、帶有副作用的宏參數
? ? ? ? 當宏參數在宏的定義中出現超過一次的時候,如果參數帶有副作用,那么你將在使用這個宏的時候就可能出現危險,導致不可預測的后果。副作用就是表達式求值的時候出現的永久性效果。
? ? ? ? 例如:
x+1;//不帶副作?
x++;//帶有副作?? ? ? ? MAX宏可以證明具有副作用的參數所引起的問題:
#define MAX(a, b) ( (a) > (b) ? (a) : (b) )
...
x = 5;
y = 8;
z = MAX(x++, y++);
printf("x=%d y=%d z=%d\n", x, y, z);//輸出的結果是什么?? ? ? ? 我們經過分析后,可以知道預處理器處理之后的結果是:
z = ( (x++) > (y++) ? (x++) : (y++));? ? ? ? 所以輸出的結果為:x = 6 y? = 10 z = 9
五、宏替換的規則
? ? ? ? 在程序中擴展#define定義符號和宏時,需要涉及以下幾個步驟:
? ? ? ? 1.? 在調用宏的時候,首先要對參數進行檢查,看看是否包含任何由#define定義的符號。如果包含,它們就要首先被替換。
? ? ? ? 2.? 替換文本隨后被插入到程序中原來文本的位置。對于宏,參數名會被他們的值所替換。
? ? ? ? 3.? 最后,再次對結果文件進行掃描,看看它是否包含任何由#define定義的符號。如果是,就重復上述的處理過程。
? ? ? ? 注意:
? ? ? ? 1.? 宏參數和#define定義中可以出現其他#define定義的符號。但是對于宏,不能出現遞歸。
? ? ? ? 2.? 當預處理器搜索#define定義的符號的時候,字符串常量的內容并不被搜索。
六、宏函數對比
? ? ? ? 宏通常被應用于執行簡單的運算。
? ? ? ? 比如在兩個數中找出較大的一個時,寫成下面的宏,會更有優勢一些:
#define MAX(a, b) ((a)>(b)?(a):(b))? ? ? ? 那么為什么我們不用函數來完成這個任務呢?
? ? ? ? 原因有以下兩個:
? ? ? ? 1.? 用于調用函數和從函數返回的代碼可能比實際執行這個小型計算工作所需要的時間更多。所以宏比函數在程序的規模和速度方面更勝一籌。
? ? ? ? 2.? 更為重要的是函數的參數必須聲明為特定的類型。所以函數只能在類型合適的表達式上使用。反之這個宏也可以用于整型、長整型、浮點型等可以用于 > 來比較的類型。宏的函數是類型無關的。
? ? ? ? 宏和函數相比的劣勢:
? ? ? ? 1.? 每次使用宏的時候,一份宏定義的代碼將插入到程序中。除非宏比較短,否則可能大幅度增加程序的長度。
? ? ? ? 2.? 宏是沒辦法調試的。
? ? ? ? 3.? 宏由于類型無關,也就不夠嚴謹。
? ? ? ? 4.? 宏可能會帶來運算符優先級的問題,導致程序容易出現錯誤。
? ? ? ? 不過,宏有時候可以做到函數做不到的事情,比如,宏的參數可以出現類型,但是函數做不到。
#define MALLOC(num, type)\
(type )malloc(num sizeof(type))
...
//使?
MALLOC(10, int);//類型作為參數//預處理器替換之后:
(int *)malloc(10 sizeof(int));? ? ? ? 宏和函數的一個對比:
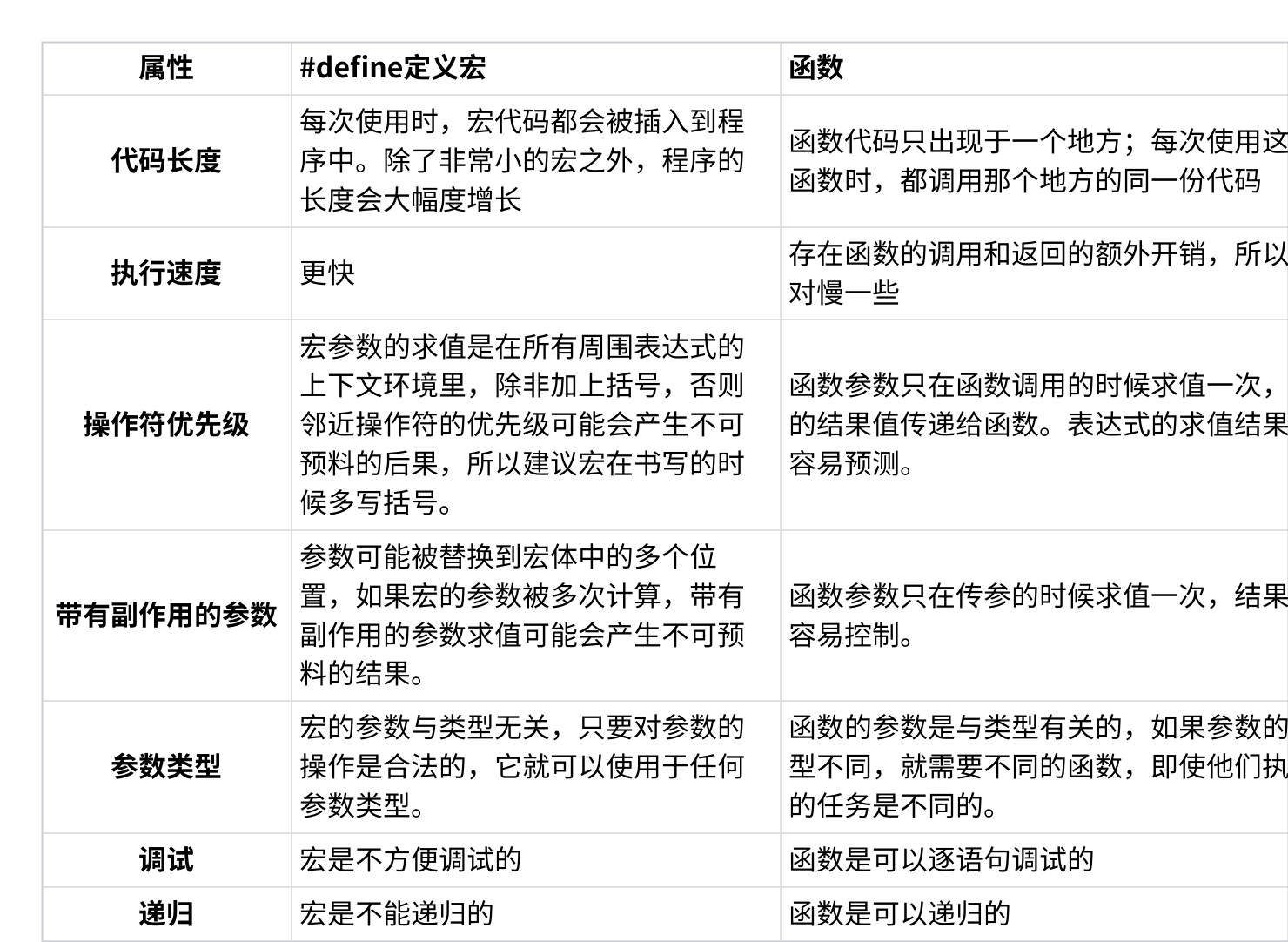
七、# 和 ##
7.1? #運算符
? ? ? ? #運算符將宏的一個參數轉換為字符串字面量。它僅允許出現在帶參數的宏的替換列表中。
? ? ? ? #運算符所執行的操作可以理解為“字符串化”。
? ? ? ? 當我們有一個變量 int a = 10;?的時候,我們想打印出:the value of a if 10,那么可以寫:
#define PRINT(n) printf("the value of "#n " is %d", n);? ? ? ? 當我們按照下面的方式調用的時候:
? ? ? ? PRINT(a);//當我們把a替換到宏的體內的時候,就出現了#a,而#a就是轉換為“a”,這時一個字符串代碼就會被預處理為:
printf("the value of ""a" " is %d", a);? ? ? ? 運行上述代碼就能在屏幕上打印:
the value of a is 107.2? ##運算符
? ? ? ? ##可以把位于它兩邊的符號合成為一個符號,它允許宏定義從分離的文本片段創建標識符。##被稱為記號粘合。
? ? ? ? 這樣的連接必須產生一個合法的標識符,否則其結果就是未定義的。
? ? ? ? 這里我們來想想,要寫一個函數求兩個數的較大值的時候,不同的數據類型就得寫不同的函數。如下所示:
int int_max(int x, int y)
{return x > y ? x : y;
} float float_max(float x, float y)
{return x > y ? x : y;
}? ? ? ? 但是這樣寫起來太繁瑣了,我們可以試試這樣寫:
//宏定義
#define GENERIC_MAX(type) \
type type##_max(type x, type y)\
{ \return (x>y?x:y); \
}? ? ? ? 這樣我們就可以使用宏來定義不同的函數:
GENERIC_MAX(int) //替換到宏體內后int##_max ?成了新的符號 int_max做函數名
GENERIC_MAX(float) //替換到宏體內后float##_max ?成了新的符號 float_max做函數名int main()
{//調?函數int m = int_max(2, 3);printf("%d\n", m);float fm = float_max(3.5f, 4.5f);printf("%f\n", fm);return 0;
}? ? ? ? 輸出結果如下所示:
3
4.500000? ? ? ? 在實際開發過程中,##使用的很少,這里我們就不過多舉例了。
八、命名約定
? ? ? ? 一般來說函數和宏的使用語法很相似,所以語言本身沒法幫我們區分二者。
? ? ? ? 那么我們一般有以下命名習慣:
- 把宏的命名全部大寫
- 函數名不要全部大寫
九、#undef
? ? ? ? 這條指令用于移除一個宏定義:
#undef NAME
//如果現存的?個名字需要被重新定義,那么它的舊名字?先要被移除。十、命令行定義
? ? ? ? 許多C的編譯器為我們提供了一種能力,允許我們在命令行中定義符號,用于啟動編譯過程。
? ? ? ? 例如:當我們根據同一個源文件要編譯出一個程序的不同版本的時候,這個特性有點用處。(假定某個程序中聲明了一個某個長度的數組,如果機器內存有限,我們需要一個很小的數組,但是另外一個機器的內存大些,我們需要一個數組能夠大些。)
? ? ? ? 來看一段代碼示例:
#include <stdio.h>
int main()
{int array [ARRAY_SIZE];int i = 0;for(i = 0; i< ARRAY_SIZE; i ++){array[i] = i;} for(i = 0; i< ARRAY_SIZE; i ++){printf("%d " ,array[i]);} printf("\n" );return 0;
}? ? ? ? 編譯指令如下:
//linux 環境演?
gcc -D ARRAY_SIZE=10 programe.c十一、條件編譯
? ? ? ? 在編譯一個程序的時候我們如果要將一條語句(一組語句)編譯或者放棄是很方便的,因為我們有條件編譯指令。
? ? ? ? 比如我們來看下面這段代碼:
#include <stdio.h>
#define __DEBUG__int main()
{int i = 0;int arr[10] = {0};for(i=0; i<10; i++){arr[i] = i;#ifdef __DEBUG__printf("%d\n", arr[i]);//為了觀察數組是否賦值成功。#endif //__DEBUG__} return 0;
}? ? ? ? 上述作為一段調試性的代碼,刪除又可惜,保留又礙事,那么我們就可以利用條件編譯指令來選擇性地編譯。
? ? ? ? 常見的條件編譯指令如下:
1.
#if 常量表達式//...#endif
//常量表達式由預處理器求值。
如:
#define __DEBUG__ 1
#if __DEBUG__//..
#endif2.多個分?的條件編譯
#if 常量表達式//...
#elif 常量表達式//...
#else//...
#endif3.判斷是否被定義
#if defined(symbol)
#ifdef symbol#if !defined(symbol)
#ifndef symbol4.嵌套指令
#if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();#endif#ifdef OPTION2unix_version_option2();#endif
#elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif
#endif十二、頭文件的包含
12.1? 頭文件被包含的方式
12.1.1? 本地文件包含
#include "filename"? ? ? ? 本地文件的查找策略:
? ? ? ? 先在源文件所在目錄下查找,如果該頭文件未被找到,編譯器就像查找庫函數頭文件一樣在標準位置查找頭文件。如果找不到就會提示編譯錯誤。
? ? ? ? Linux環境的標準頭文件的路徑:
/usr/include? ? ? ? VS環境的標準頭文件的路徑:
C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
//這是VS2013的默認路徑? ? ? ? 注意按照我們自己的安裝路徑去查找。
12.1.2? 庫文件包含
#include <filename.h>? ? ? ? 查找頭文件直接去標準路徑下查找,如果找不到就會提示編譯錯誤。
? ? ? ? 那么這樣是不是就可以說,對于庫文件我們也可以使用“ ”的形式來包含?
? ? ? ? 答案是肯定的。可以,但是這樣就會導致查找的效率變低,當然這樣也就不容易區分是庫文件還是本地文件了。
12.2? 嵌套文件包含
? ? ? ? 我們已經知道,#include 指令可以使得另外一個文件被編譯,就像它實際出現于#include指令的地方一樣。
? ? ? ? 這種替換的方式很簡單:預處理指令先刪除這條指令,并用包含文件的內容替換。
? ? ? ? 一個頭文件被包含10次,那就會實際被編譯10次,如果重復包含,那么對編譯的壓力就會比較大。
? ? ? ? 如下我們來展示兩個test.c和test.h文件:
//test.c
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"
#include "test.h"int main()
{return 0;
}//test.h
void test();
struct Stu
{int id;char name[20];
};? ? ? ? 如果我們直接這樣寫的話,test.c文件中將test.h包含5次,那么test.h文件的內容將會被拷貝5份在test.c中。
? ? ? ? 如果test.h文件比較大的話,預處理后的代碼量就會劇增。如果工程比較大,并且有公共使用的頭文件,能被大家使用,又不做任何的處理, 那么后果將會不堪設想。
? ? ? ? 那么我們如何解決頭文件被重復引入的問題呢?答案是:條件編譯。
? ? ? ? 我們可以在每個頭文件的開頭這樣寫:
#ifndef __TEST_H__
#define __TEST_H__
//頭?件的內容
#endif //__TEST_H__? ? ? ? 或者這樣寫:
#pragma once? ? ? ? 這兩種寫法都可以避免頭文件的重復引入。
? ? ? ? 注:博主在這給大家推薦《高質量C/C++編程指南》中附錄的考試試卷,里面有兩道筆試題非常值得大家仔細思考一下。
? ? ? ? 即:
? ? ? ? 1.? 頭文件中的ifdef/define/endif是干什么用的?
? ? ? ? 2.? #include <filename.h>和#include "filename.h"有什么區別?
十三、其他預處理指令
#error
#pragma
#line
...#pragma pack()在結構體部分介紹。| 預處理指令 | 作用描述 | 典型使用場景或示例 |
|---|---|---|
#error | 在編譯時產生一個錯誤信息,并立即終止編譯過程。 | 用于檢查不滿足的編譯條件,防止生成無效代碼。 示例: #ifndef __STDC__#error "This compiler is not ANSI C compliant!"#endif |
#pragma | 向編譯器發出特殊的命令或指示,用于設定編譯器的狀態或指定編譯器的特定操作。 (注意:其效果高度依賴于具體的編譯器) | 用于控制內存對齊、注釋庫文件、禁用特定警告等。 示例: #pragma once?// (非標準但廣泛支持) 用于頭文件防止重復包含#pragma pack(1)?// 設置結構體對齊為1字節#pragma warning(disable: 4996)?// (MSVC) 禁用編號為4996的警告 |
#line | 修改編譯器在編譯過程中記錄的當前行號和文件名。 | 主要用于代碼生成工具(如lex/yacc),使編譯器錯誤信息指向原始輸入文件,而不是生成的中間C文件。 示例: #line 42 "my_source.txt"?// 將下一行的行號設為42,文件名設為"my_source.txt" |
? ? ? ? 注意:
-
#error:是一個強制性的編譯停止指令,用于在預處理階段強制拋出錯誤。 -
#pragma:幾乎所有的功能都由具體的編譯器定義,不屬于C語言標準的一部分,因此需要查閱特定編譯器的文檔。_Pragma?操作符 (C99) 提供了另一種更類似于宏的方式來執行?#pragma?的功能。 -
#line:主要用于調整編譯器在報告錯誤和調試信息時使用的行號和文件名,對程序邏輯沒有影響。
? ? ? ? 要想深入了解這些預處理指令,可以參考書目《C語言深度解剖》來進行學習。
總結
? ? ? ? 以上就是本期博客的全部內容啦!本期也是博主C語言基礎系列專欄的最后一期博客,從下期開始,博主將正式開始更新數據結構的相關內容,敬請期待!
)














)



 - /供應鏈管理組件/fmcg-inventory-optimization)