1 概述
1.1 案例介紹
本案例演示如何在華為開發者空間云主機上搭建Open WebUI環境,結合DeepSeek-R1模型進行數據分析、統計建模、數據可視化和業務洞察挖掘等實際數據科學任務。
1.2 適用對象
- 數據分析師
- 業務分析師
- 數據科學工程師
- 市場研究人員
- 統計學專業學生
1.3 案例時長
預計 90 分鐘
1.4 案例流程
- 開啟華為開發者空間云主機
- 安裝Docker和Open WebUI
- 部署Ollama和DeepSeek-R1模型
- 配置數據分析環境
- AI分析業務數據集實戰
1.5 資源總覽
| 資源名稱 | 規格 | 單價(元) | 時長(分鐘) |
|---|---|---|---|
| 開發者空間–云主機 | 4 vCPUs 8 GB Ubuntu 24.04 Server 定制版 | 0 | 90 |
| Open WebUI | Docker容器化部署 | 0 | — |
| Ollama 本地模型服務 | DeepSeek-R1(本地部署) | 0 | — |
| 數據分析環境 | Python + Pandas + Matplotlib | 0 | — |
2 環境配置
2.1 開發者空間
華為開發者空間,是為全球開發者打造的專屬開發者空間,致力于為每位開發者提供一臺云主機(點擊免費領取)、一套開發工具和云上存儲空間,匯聚昇騰、鴻蒙、鯤鵬、GaussDB、歐拉等華為各項根技術的開發工具資源,并提供配套案例指導開發者 從開發編碼到應用調測,基于華為根技術生態高效便捷的知識學習、技術體驗、應用創新。
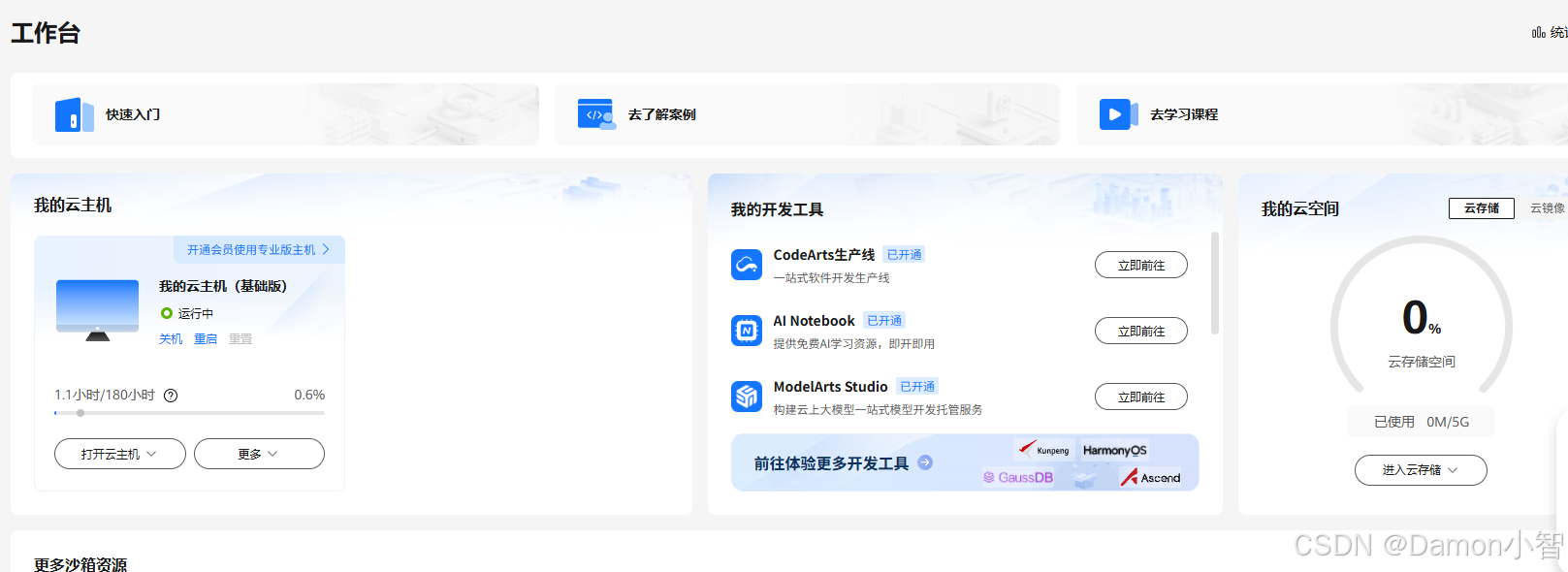
點擊我的云主機,選擇“打開云主機”,并進入桌面。云主機默認系統為 Ubuntu 24.04 Server 定制版。
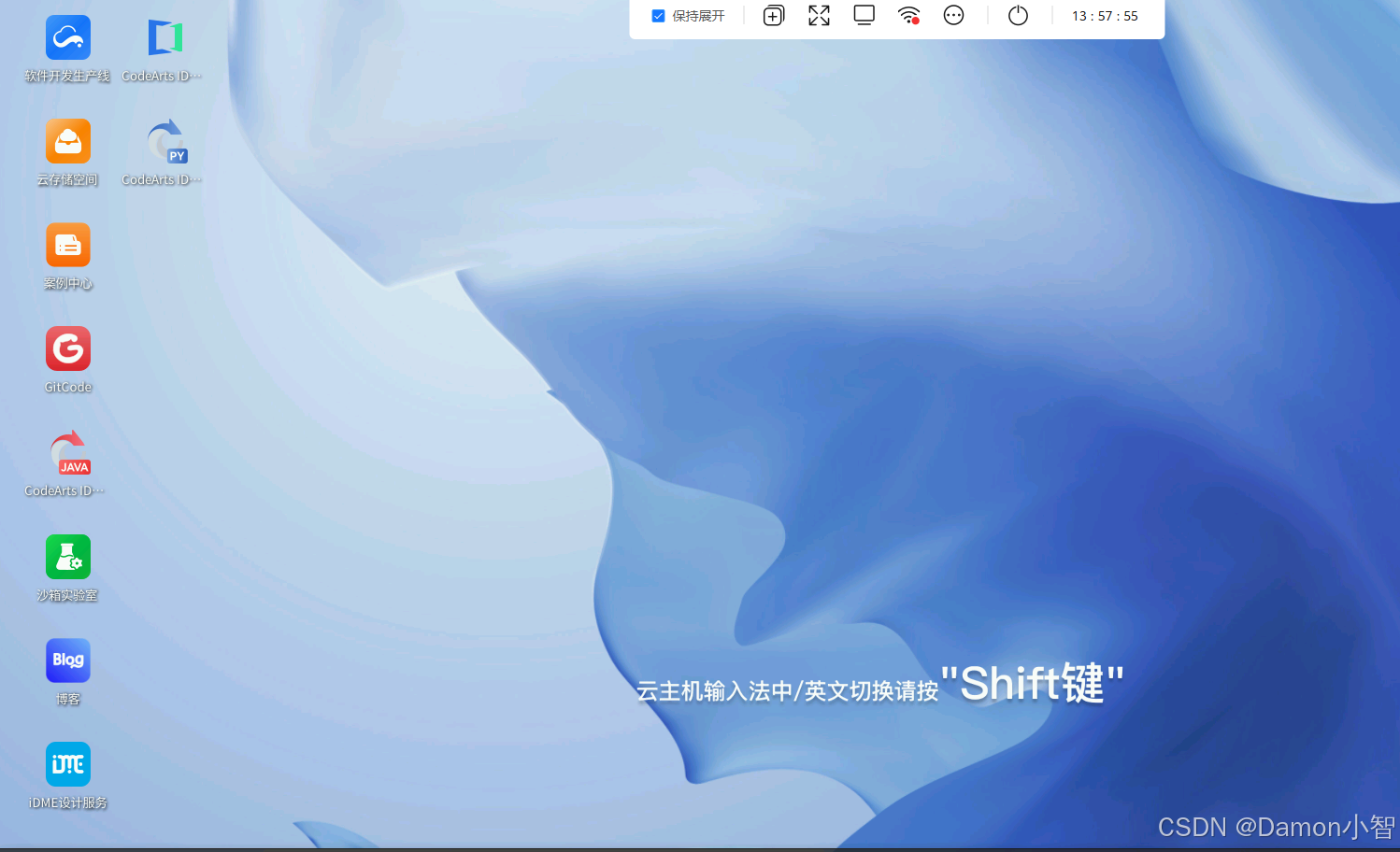
2.2 安裝Docker環境
2 環境配置
2.1 開發者空間
華為開發者空間,是為全球開發者打造的專屬開發者空間,致力于為每位開發者提供一臺云主機(點擊免費領取)、一套開發工具和云上存儲空間,匯聚昇騰、鴻蒙、鯤鵬、GaussDB、歐拉等華為各項根技術的開發工具資源,并提供配套案例指導開發者 從開發編碼到應用調測,基于華為根技術生態高效便捷的知識學習、技術體驗、應用創新。
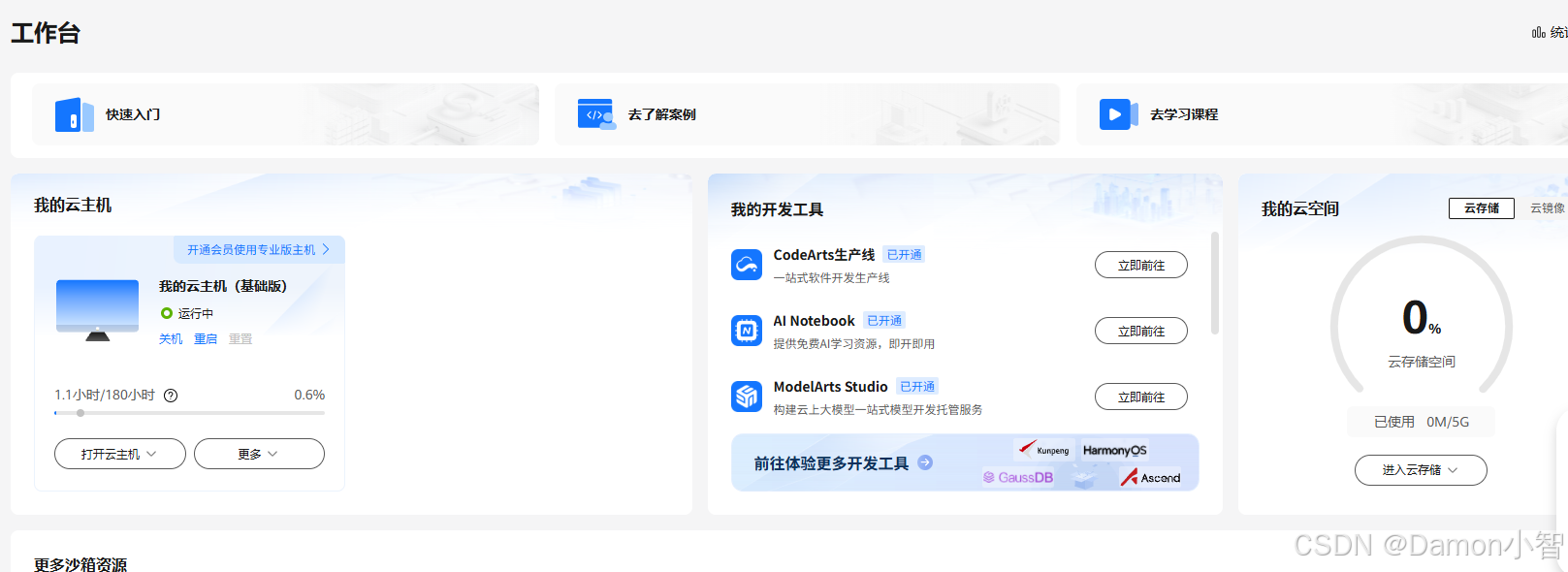
點擊我的云主機,選擇“打開云主機”,并進入桌面。云主機默認系統為 Ubuntu 24.04 Server 定制版。
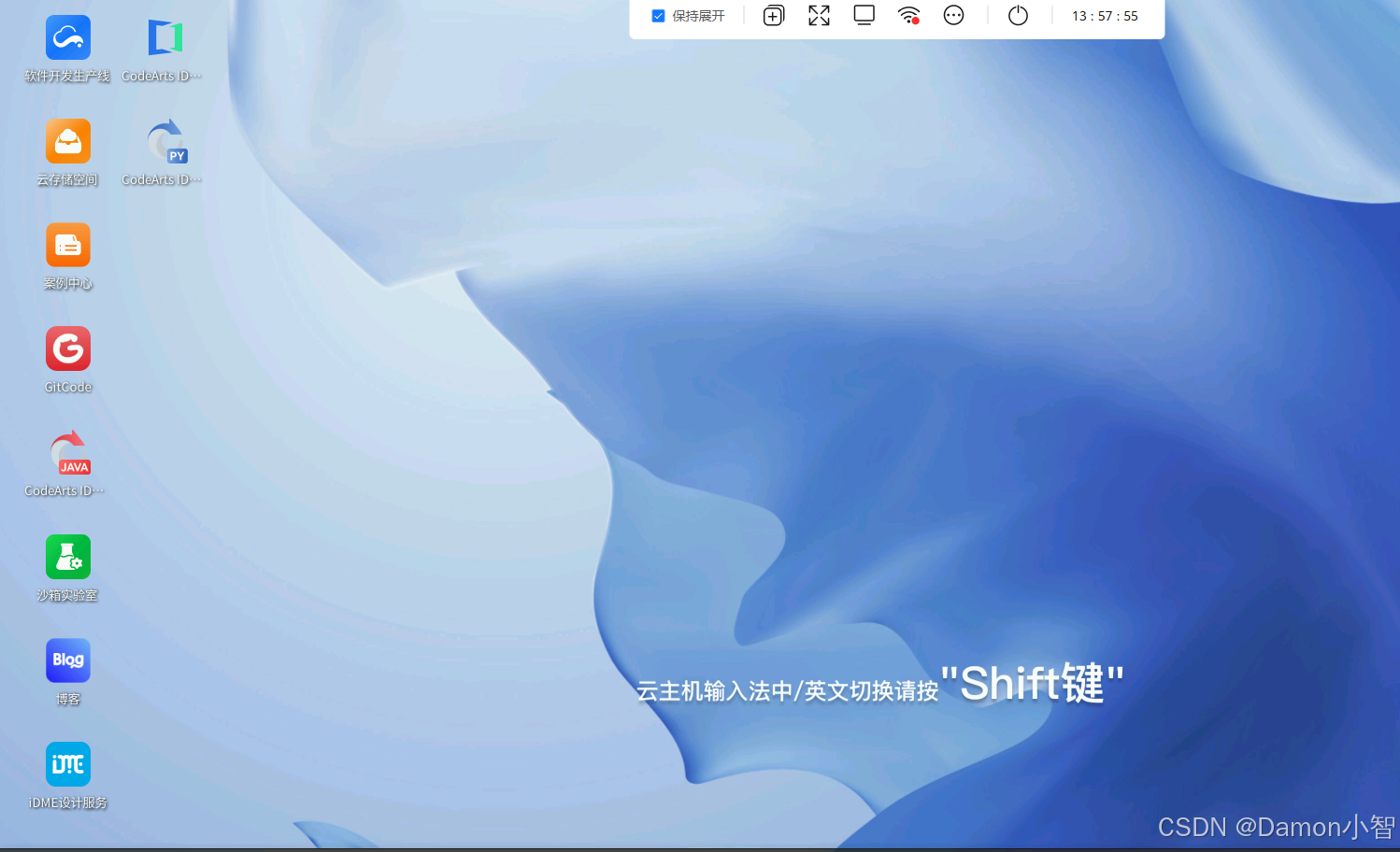
2.2 安裝 Ollama
Ollama 是一個強大的開源工具,旨在幫助用戶輕松地在本地運行、部署和管理大型語言模型(LLMs)。它提供了一個簡單的命令行界面,使用戶能夠快速下載、運行和與各種預訓練的語言模型進行交互。Ollama 支持多種模型架構,并且特別適合那些希望在本地環境中使用 LLMs 的開發者和研究人員。
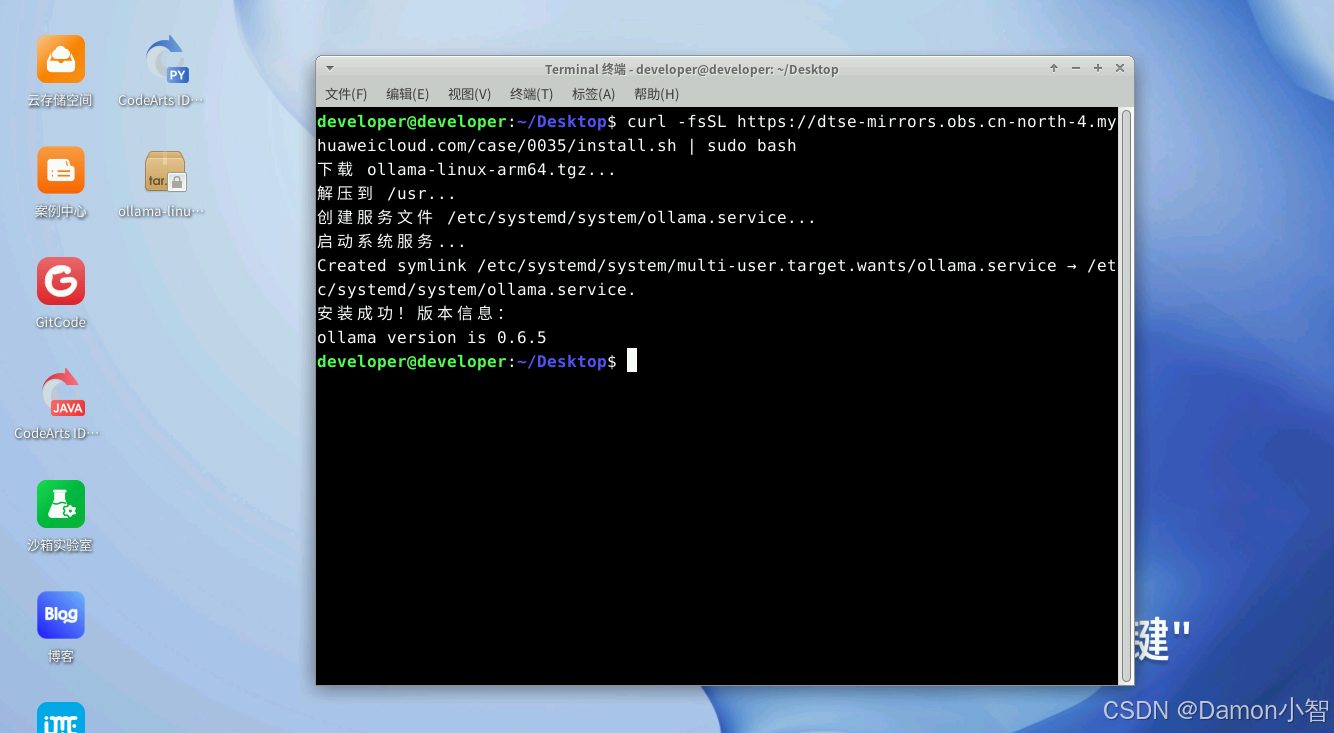
# 安裝 Ollama 腳本
curl -fsSL https://dtse-mirrors.obs.cn-north-4.myhuaweicloud.com/case/0035/install.sh | sudo bash
設置并啟動 Ollama 服務。
sudo systemctl enable ollama
sudo systemctl start ollama
接下來可以根據需要,借助 Ollama 工具來部署大模型。
2.3 安裝 Open WebUI
打開云主機命令行窗口輸入以下命令,更新軟件包。
sudo apt update
sudo apt upgrade -y
卸載舊版本Docker(如果已安裝)。
sudo apt-get remove docker docker-engine docker.io containerd runc
安裝必要的依賴。
sudo apt install apt-transport-https ca-certificates curl software-properties-common
添加Docker的官方GPG密鑰。
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -

添加Docker的APT源。
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
更新APT包索引。
sudo apt update
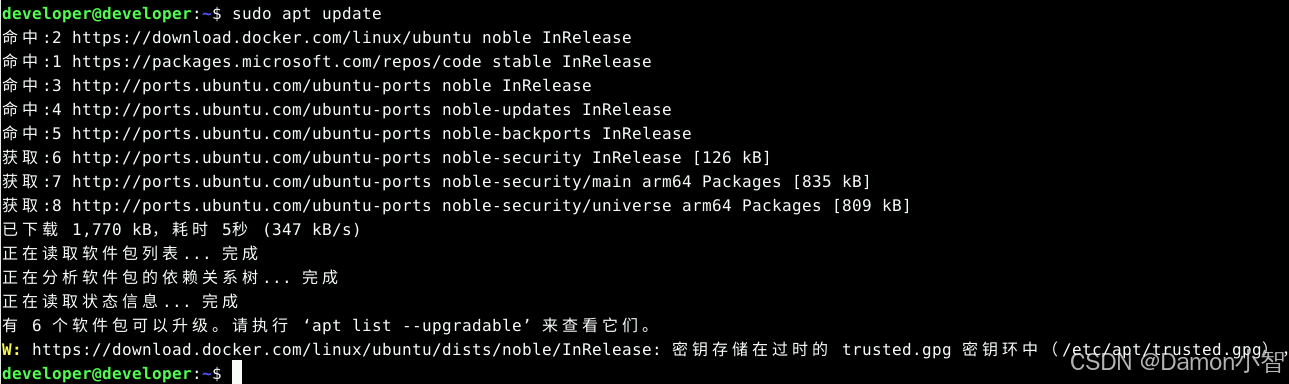
安裝Docker CE。
sudo apt install docker-ce
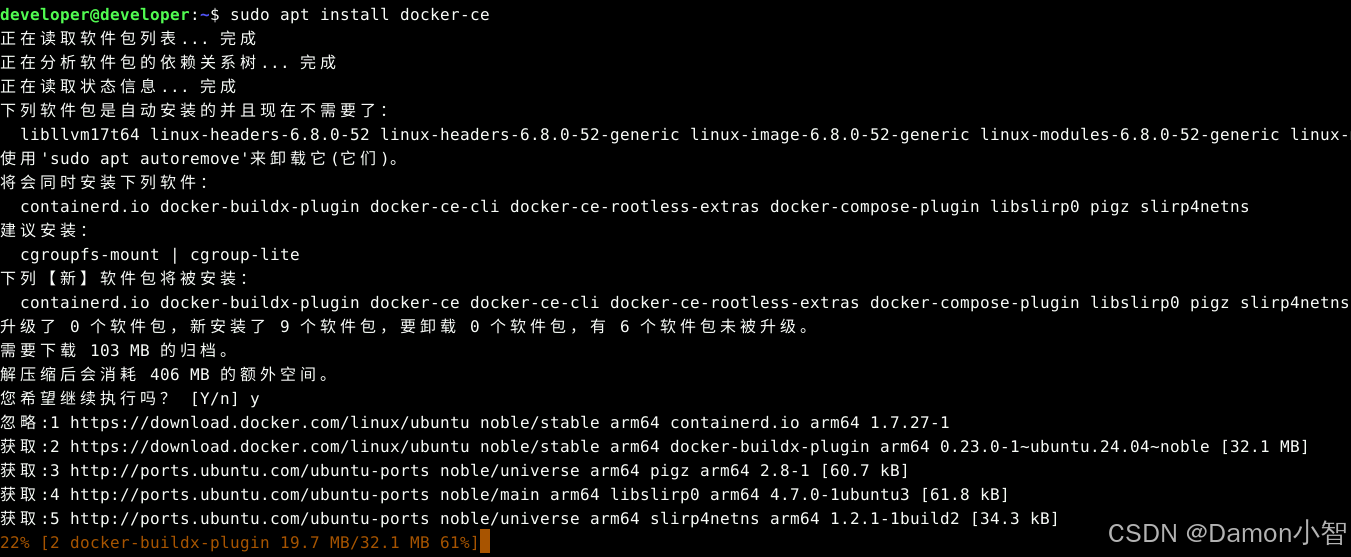
驗證Docker是否安裝成功。
sudo systemctl status docker
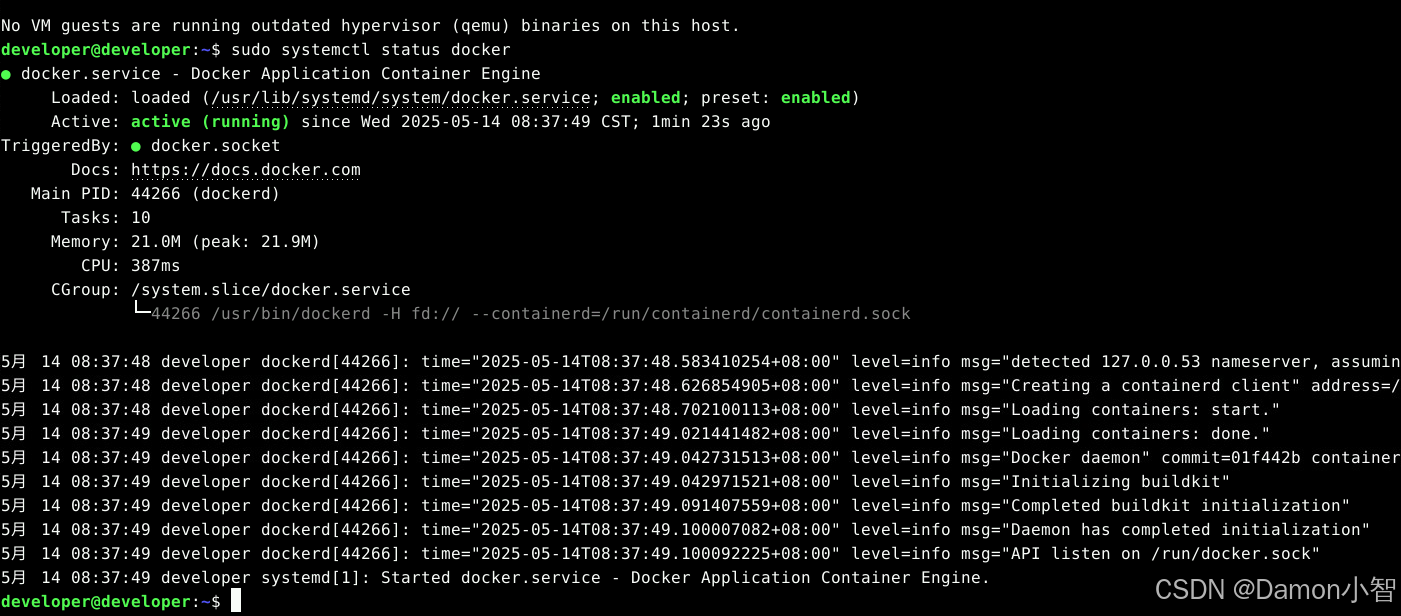
設置Docker自動啟動。
sudo systemctl enable docker

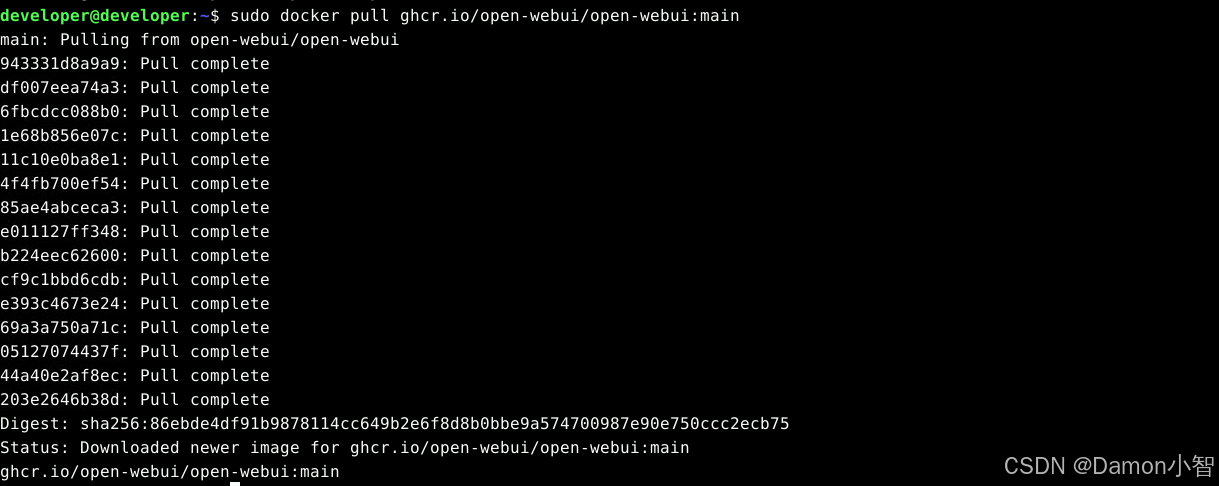
安裝 Open WebUI。
sudo docker pull ghcr.io/open-webui/open-webui:main
運行 Open WebUI 容器。
sudo docker run -d --network host -v open-webui:/app/backend/data --name open-webui --restart always -e OLLAMA_BASE_URL=http://localhost:11434 ghcr.io/open-webui/open-webui:main

大概等待兩分鐘,容器可以啟動完成。
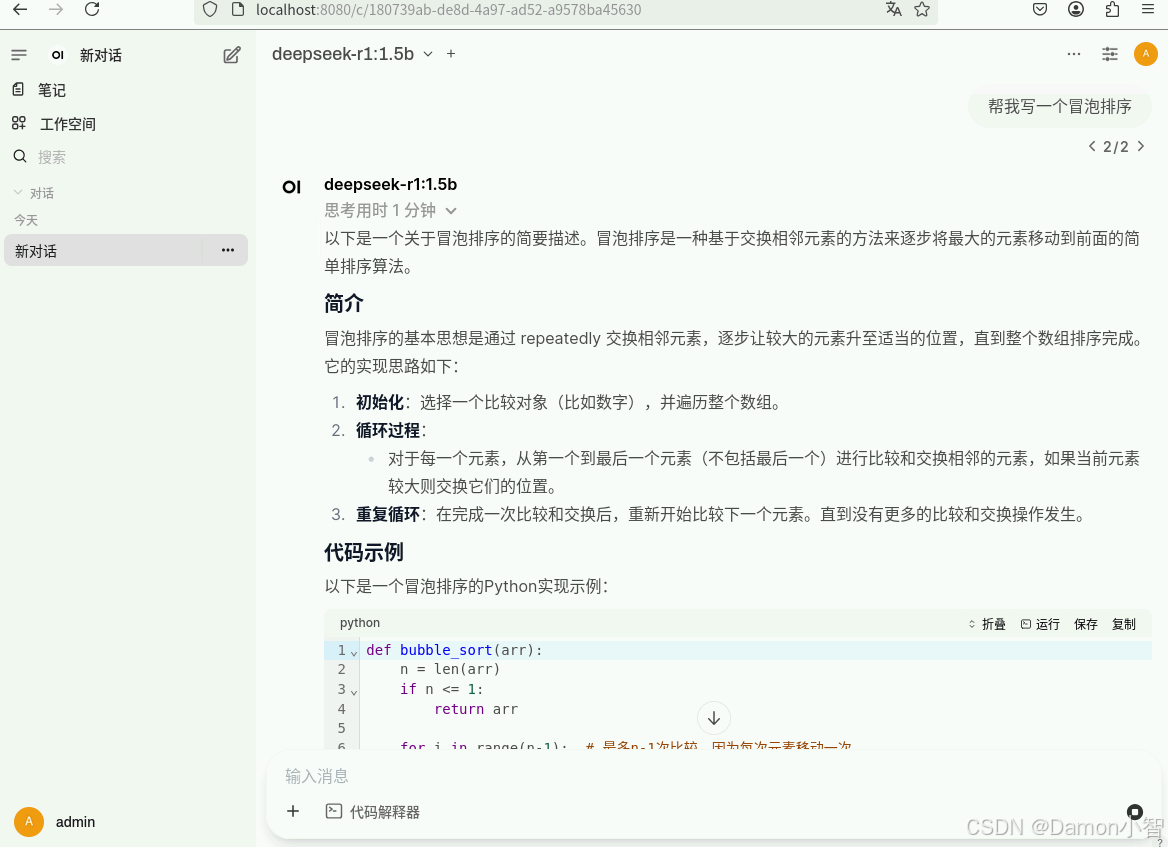
向deepseek-r1模型提問,比如:“幫我寫一個冒泡排序”。
如果訪問失敗,可以輸入下面命令查看日志。
# 查看容器狀態
sudo docker ps -a | grep open-webui# 檢查日志
sudo docker logs open-webui
2.4 準備數據分析環境
# 安裝Python數據分析庫
sudo apt install python3-pip -y
pip3 install pandas numpy matplotlib seaborn plotly jupyter# 創建數據分析工作目錄
mkdir -p ~/data-analysis-project
cd ~/data-analysis-project
3 實戰項目
3.1 創建業務數據集
創建一個電商銷售數據集用于分析:
# 創建銷售數據CSV文件
cat > sales_data.csv << 'EOF'
date,product_category,product_name,sales_amount,quantity,customer_age,customer_gender,region,promotion_type
2024-01-15,Electronics,Smartphone,899.99,1,25,Female,North,None
2024-01-15,Electronics,Laptop,1299.99,1,32,Male,South,Discount_10
2024-01-16,Clothing,T-Shirt,29.99,2,28,Female,East,None
2024-01-16,Electronics,Tablet,499.99,1,45,Male,West,Bundle_Deal
2024-01-17,Books,Novel,15.99,1,35,Female,North,None
2024-01-17,Electronics,Headphones,199.99,1,22,Male,South,Flash_Sale
2024-01-18,Clothing,Jeans,79.99,1,30,Female,East,Discount_20
2024-01-18,Home,Coffee_Maker,89.99,1,40,Male,West,None
2024-01-19,Electronics,Phone_Case,19.99,3,26,Female,North,Bundle_Deal
2024-01-19,Books,Textbook,89.99,1,20,Male,South,Student_Discount
2024-01-20,Clothing,Jacket,149.99,1,38,Female,East,Seasonal_Sale
2024-01-20,Electronics,Smart_Watch,299.99,1,33,Male,West,None
2024-01-21,Home,Vacuum_Cleaner,199.99,1,42,Female,North,Discount_15
2024-01-21,Electronics,Wireless_Mouse,39.99,2,29,Male,South,None
2024-01-22,Books,Cookbook,24.99,1,36,Female,East,None
2024-01-22,Clothing,Sneakers,119.99,1,24,Male,West,Flash_Sale
2024-01-23,Electronics,Power_Bank,49.99,1,31,Female,North,Bundle_Deal
2024-01-23,Home,Lamp,69.99,1,44,Male,South,None
2024-01-24,Clothing,Dress,89.99,1,27,Female,East,Discount_25
2024-01-24,Electronics,Bluetooth_Speaker,79.99,1,34,Male,West,None
EOF# 創建客戶信息數據
cat > customer_data.csv << 'EOF'
customer_id,registration_date,total_orders,lifetime_value,satisfaction_score,preferred_category
C001,2023-06-15,12,2400.50,4.5,Electronics
C002,2023-07-20,8,1200.75,4.2,Clothing
C003,2023-08-10,15,3200.25,4.8,Electronics
C004,2023-09-05,6,800.60,3.9,Books
C005,2023-10-12,10,1800.40,4.3,Home
C006,2023-11-08,18,4500.80,4.7,Electronics
C007,2023-12-03,7,950.35,4.0,Clothing
C008,2024-01-14,5,600.25,3.8,Books
C009,2024-01-20,9,1650.90,4.4,Home
C010,2024-01-25,11,2100.55,4.6,Electronics
EOF# 創建產品庫存數據
cat > inventory_data.csv << 'EOF'
product_id,product_name,category,cost_price,selling_price,stock_quantity,supplier,last_restocked
P001,Smartphone,Electronics,650.00,899.99,45,TechCorp,2024-01-10
P002,Laptop,Electronics,800.00,1299.99,23,CompuMax,2024-01-08
P003,T-Shirt,Clothing,12.00,29.99,120,FashionHub,2024-01-12
P004,Tablet,Electronics,300.00,499.99,35,TechCorp,2024-01-09
P005,Novel,Books,8.00,15.99,80,BookWorld,2024-01-11
P006,Headphones,Electronics,80.00,199.99,67,AudioPro,2024-01-07
P007,Jeans,Clothing,35.00,79.99,55,DenimCo,2024-01-13
P008,Coffee_Maker,Home,45.00,89.99,30,KitchenMax,2024-01-06
P009,Phone_Case,Electronics,8.00,19.99,200,AccessoryPlus,2024-01-14
P010,Textbook,Books,45.00,89.99,25,EduBooks,2024-01-05
EOF
3.2 訪問Open WebUI并創建分析對話
瀏覽器訪問 http://localhost:8080,創建管理員賬戶并登錄。
開始數據分析對話。
3.3 探索性數據分析
對話1:數據概覽分析
我是一名數據分析師,需要對電商銷售數據進行全面分析。我有三個數據文件:
1. sales_data.csv - 銷售交易數據
2. customer_data.csv - 客戶信息數據
3. inventory_data.csv - 產品庫存數據請幫我生成Python代碼來進行初步的探索性數據分析,包括:
1. 數據加載和基本信息查看
2. 數據質量檢查(缺失值、異常值)
3. 描述性統計分析
4. 數據分布可視化請提供完整的可執行代碼。
預期AI回答示例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')# 設置中文字體和圖表風格
plt.rcParams['font.sans-serif'] = ['DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
sns.set_style("whitegrid")def load_and_explore_data():"""加載數據并進行初步探索"""# 1. 數據加載print("=== 數據加載 ===")sales_df = pd.read_csv('sales_data.csv')customer_df = pd.read_csv('customer_data.csv')inventory_df = pd.read_csv('inventory_data.csv')print(f"銷售數據形狀: {sales_df.shape}")print(f"客戶數據形狀: {customer_df.shape}")print(f"庫存數據形狀: {inventory_df.shape}")# 2. 數據基本信息print("\n=== 銷售數據基本信息 ===")print(sales_df.info())print("\n銷售數據前5行:")print(sales_df.head())# 3. 數據質量檢查print("\n=== 數據質量檢查 ===")print("銷售數據缺失值:")print(sales_df.isnull().sum())# 4. 描述性統計print("\n=== 描述性統計 ===")print(sales_df.describe())# 5. 數據可視化fig, axes = plt.subplots(2, 3, figsize=(18, 12))# 銷售金額分布axes[0,0].hist(sales_df['sales_amount'], bins=20, alpha=0.7, color='skyblue')axes[0,0].set_title('銷售金額分布')axes[0,0].set_xlabel('銷售金額')axes[0,0].set_ylabel('頻次')# 產品類別銷售分布category_sales = sales_df.groupby('product_category')['sales_amount'].sum()axes[0,1].pie(category_sales.values, labels=category_sales.index, autopct='%1.1f%%')axes[0,1].set_title('產品類別銷售占比')# 地區銷售分布region_sales = sales_df.groupby('region')['sales_amount'].sum()axes[0,2].bar(region_sales.index, region_sales.values, color='lightgreen')axes[0,2].set_title('地區銷售分布')axes[0,2].set_xlabel('地區')axes[0,2].set_ylabel('銷售金額')# 客戶年齡分布axes[1,0].hist(sales_df['customer_age'], bins=15, alpha=0.7, color='orange')axes[1,0].set_title('客戶年齡分布')axes[1,0].set_xlabel('年齡')axes[1,0].set_ylabel('頻次')# 促銷類型效果promo_sales = sales_df.groupby('promotion_type')['sales_amount'].mean()axes[1,1].bar(promo_sales.index, promo_sales.values, color='lightcoral')axes[1,1].set_title('促銷類型平均銷售額')axes[1,1].set_xlabel('促銷類型')axes[1,1].set_ylabel('平均銷售額')axes[1,1].tick_params(axis='x', rotation=45)# 性別銷售分布gender_sales = sales_df.groupby('customer_gender')['sales_amount'].sum()axes[1,2].pie(gender_sales.values, labels=gender_sales.index, autopct='%1.1f%%')axes[1,2].set_title('性別銷售分布')plt.tight_layout()plt.savefig('eda_analysis.png', dpi=300, bbox_inches='tight')plt.show()return sales_df, customer_df, inventory_df# 執行分析
sales_data, customer_data, inventory_data = load_and_explore_data()
3.4 深度數據分析
對話2:銷售趨勢分析
基于上面的數據,請幫我進行更深入的銷售趨勢分析:1. 時間序列分析 - 銷售趨勢變化
2. 相關性分析 - 各變量之間的關系
3. 客戶細分分析 - RFM分析模型
4. 產品性能分析 - 銷售排行和利潤分析
5. 異常值檢測 - 識別異常交易請提供詳細的分析代碼和解釋。
3.5 統計建模與預測
對話3:預測模型構建
現在需要構建預測模型來支持業務決策:1. 銷售額預測模型 - 基于歷史數據預測未來銷售
2. 客戶流失預測 - 識別可能流失的客戶
3. 庫存優化模型 - 預測最優庫存水平
4. 價格敏感性分析 - 分析價格對銷售的影響請使用Python機器學習庫(如scikit-learn)構建這些模型,并提供模型評估指標。
3.6 數據可視化儀表板
對話4:交互式儀表板
請幫我創建一個交互式的數據可視化儀表板,使用Plotly或Dash庫,包含以下組件:1. 實時銷售指標面板
2. 產品類別業績對比圖
3. 地區銷售熱力圖
4. 客戶年齡與消費行為散點圖
5. 促銷活動效果分析圖表
6. 庫存預警提醒面板請提供完整的代碼實現。
3.7 業務洞察挖掘
對話5:業務智能分析
基于所有的數據分析結果,請幫我生成一份綜合的業務洞察報告,包括:1. 關鍵業務指標總結
2. 主要發現和洞察
3. 存在的問題和風險
4. 改進建議和行動計劃
5. 預測和趨勢展望請以管理層可以理解的商業語言表述,避免過多技術細節。
3.8 自動化報告生成
對話6:報告自動化
請幫我創建一個自動化的數據分析和報告生成系統,要求:1. 定期自動處理新的數據文件
2. 自動更新分析結果和圖表
3. 生成PDF格式的分析報告
4. 設置異常情況預警通知
5. 支持多種數據源接入請提供Python腳本實現這個自動化流程。
3.9 高級分析技術
對話7:機器學習應用
請展示如何在這個電商數據集上應用高級分析技術:1. 聚類分析 - 客戶群體細分
2. 關聯規則挖掘 - 購物籃分析
3. 時間序列預測 - ARIMA模型
4. 推薦系統 - 協同過濾算法
5. 異常檢測 - 孤立森林算法每種技術請提供具體的代碼實現和業務應用場景。
4 驗證和測試
4.1 執行數據分析代碼
# 創建分析腳本
cd ~/data-analysis-project# 安裝所需庫
pip3 install scikit-learn plotly dash# 運行分析腳本
python3 eda_analysis.py# 查看生成的圖表
ls -la *.png
4.2 模型性能驗證
# 創建模型驗證腳本
cat > model_validation.py << 'EOF'
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
import pandas as pd
import numpy as npdef validate_sales_prediction_model():"""驗證銷售預測模型性能"""# 加載數據sales_df = pd.read_csv('sales_data.csv')# 特征工程sales_df['date'] = pd.to_datetime(sales_df['date'])sales_df['day_of_week'] = sales_df['date'].dt.dayofweeksales_df['month'] = sales_df['date'].dt.month# 編碼分類變量categorical_features = ['product_category', 'customer_gender', 'region', 'promotion_type']sales_encoded = pd.get_dummies(sales_df, columns=categorical_features)# 準備特征和目標變量feature_cols = [col for col in sales_encoded.columns if col not in ['date', 'product_name', 'sales_amount']]X = sales_encoded[feature_cols]y = sales_encoded['sales_amount']# 分割數據X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 訓練模型model = RandomForestRegressor(n_estimators=100, random_state=42)model.fit(X_train, y_train)# 預測和評估y_pred = model.predict(X_test)mse = mean_squared_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)print(f"模型性能評估:")print(f"均方誤差 (MSE): {mse:.2f}")print(f"R2分數: {r2:.3f}")# 特征重要性feature_importance = pd.DataFrame({'feature': feature_cols,'importance': model.feature_importances_}).sort_values('importance', ascending=False)print("\n特征重要性排名:")print(feature_importance.head(10))return model, feature_importance# 運行驗證
model, importance = validate_sales_prediction_model()
EOFpython3 model_validation.py
4.3 儀表板部署測試
# 創建簡單的Dash儀表板
cat > dashboard.py << 'EOF'
import dash
from dash import dcc, html, Input, Output
import plotly.express as px
import pandas as pd# 加載數據
sales_df = pd.read_csv('sales_data.csv')# 創建Dash應用
app = dash.Dash(__name__)app.layout = html.Div([html.H1("電商銷售數據分析儀表板", style={'text-align': 'center'}),dcc.Dropdown(id='category-dropdown',options=[{'label': cat, 'value': cat} for cat in sales_df['product_category'].unique()],value=sales_df['product_category'].unique()[0],style={'width': '50%'}),dcc.Graph(id='sales-chart'),dcc.Graph(id='age-distribution')
])@app.callback([Output('sales-chart', 'figure'),Output('age-distribution', 'figure')],[Input('category-dropdown', 'value')]
)
def update_charts(selected_category):filtered_df = sales_df[sales_df['product_category'] == selected_category]# 銷售圖表sales_fig = px.bar(filtered_df.groupby('region')['sales_amount'].sum().reset_index(),x='region', y='sales_amount',title=f'{selected_category} 地區銷售分布')# 年齡分布圖age_fig = px.histogram(filtered_df, x='customer_age',title=f'{selected_category} 客戶年齡分布')return sales_fig, age_figif __name__ == '__main__':app.run_server(debug=True, host='0.0.0.0', port=8050)
EOF# 啟動儀表板(在后臺運行)
nohup python3 dashboard.py &echo "儀表板已啟動,訪問 http://localhost:8050 查看"
5 總結
通過本案例,您已經掌握了:
- 環境搭建:在華為開發者空間搭建Open WebUI + DeepSeek數據分析環境
- 數據探索:使用AI進行探索性數據分析和可視化
- 統計建模:構建預測模型和機器學習算法
- 業務洞察:從數據中挖掘有價值的商業洞察
- 自動化工具:創建自動化分析流程和交互式儀表板
- 模型驗證:評估模型性能和可靠性
這套數據分析工作流程可以應用到各種業務場景中,幫助企業做出數據驅動的決策。
通過閱讀本文,您將完成從環境搭建到深度實戰的全流程,能夠在 Open WebUI 中高效利用本地 DeepSeek-R1 服務,使用AI快速進行數據分析,并利用強大的可視化技術實現數據探索和洞察。
真香,是不是可以沒有YOLO和OCR了?)
)
)








——資料分析、數量(強化訓練))


- 坐標軸定制)




