人臉活體識別2:Pytorch實現人臉眨眼 張嘴 點頭 搖頭識別(含訓練代碼和數據集)
目錄
人臉活體識別2:Pytorch實現人臉眨眼 張嘴 點頭 搖頭識別(含訓練代碼和數據集)
1. 前言
2.人臉活體識別方法
(1)基于人臉動作的檢測??
(2)??基于紅外的活體識別??
(3)基于深度的活體識別??
3.人臉活體識別數據集
?(1)人臉活體識別數據集說明
4.人臉檢測模型
5.人臉活體識別模型訓練
(1)項目安裝
(2)準備數據
(3)人臉活體識別模型訓練(Pytorch)
(4) 可視化訓練過程
(5) 人臉活體識別效果
(6) 一些優化建議
(7) 一些運行錯誤處理方法
6.項目源碼下載
(1)訓練版本
(2)推理版本
7. C++實現人臉活體識別
8. Android實現人臉活體識別
1. 前言
人臉活體識別技術是確保人臉識別系統安全性的關鍵,主要用于區分真實人臉與偽造攻擊(如照片、視頻、3D面具等)。本項目基于深度學習技術,構建了一套高魯棒性的面部活體檢測系統,可精準識別眨眼(閉眼)、張嘴、點頭(低頭)、搖頭(側臉)等生物特征動作,可有效防范照片、視頻、3D面具等偽造攻擊等多種場景,??可應用于金融支付、遠程身份核驗(如銀行開戶)等場景。

本篇是項目《人臉活體識別》系列之《Pytorch實現人臉眨眼 張嘴 點頭 搖頭識別(含訓練代碼和數據集)》;項目基于深度學習框架Pytorch開發一個高精度,可實時的人臉活體識別算法;項目源碼支持模型有Resnet18, Resnet34,Resnet50,Mobilenet以及MobileVit等常見的深度學習模型,用戶也可以自定義自己的模型進行訓練;項目源碼配套了完整的訓練代碼和數據集,配置好開發環境,即可開始訓練。
準確率還挺高的,采用輕量級mobilenet_v2模型的人臉活體識別準確率也可以高達99.9661%左右,滿足業務性能需求。
| 模型 | input size | Test準確率 |
| Mobilenet | 112×112 | 99.9661 |
| Resnet18 | 112×112 | 99.9322 |
| MobileVit | 112×112 | 99.9322 |
先展示一下,Python版本的人臉活體識別Demo效果
 ? ??
? ?? ? ??
? ??
?【尊重原創,轉載請注明出處】https://blog.csdn.net/guyuealian/article/details/148774036
?更多人臉識別和活體識別文章,請參考:
- 人臉活體識別1:眨眼 張嘴 點頭 搖頭人臉數據集
- 人臉活體識別2:Pytorch實現人臉眨眼 張嘴 點頭 搖頭識別(含訓練代碼和數據集)
- 人臉活體識別3:C/C++實現人臉眨眼 張嘴 點頭 搖頭識別(可實時檢測)
- 人臉活體識別4:Android實現人臉眨眼 張嘴 點頭 搖頭識別(可實時檢測)
- 人臉識別2:InsightFace實現人臉識別Face Recognition(含源碼下載)
- 人臉識別3:C/C++ InsightFace實現人臉識別Face Recognition(含源碼)
- 人臉識別4:Android InsightFace實現人臉識別Face Recognition(含源碼)
2.人臉活體識別方法
人臉活體識別的方法有很多,如基于人臉動作的活體識別?,基于紅外的活體識別,基于深度的活體識別等等方法。
(1)基于人臉動作的檢測??
? ? 要求用戶配合完成隨機指令動作(如眨眼、點頭、張嘴、搖頭等),通過計算機視覺算法(如光流法、關鍵點跟蹤)分析動作的自然性和時序連貫性。
優點??:實現簡單,能有效抵御照片和靜態視頻攻擊。??
缺點??:依賴用戶配合,體驗較差;可能被高仿動態視頻(如Deepfake)欺騙。
(2)??基于紅外的活體識別??
??? ? ?利用紅外攝像頭捕捉人臉的紅外反射特性或熱輻射分布,如采用紅外光譜分析??,活體皮膚對特定波長紅外光的吸收/反射模式與非活體不同。??
優點??:無需用戶配合,可抵御照片、視頻及部分3D面具攻擊。
缺點??:設備成本較高;受環境溫度影響(如低溫可能降低檢測精度)。
(3)基于深度的活體識別??
? ? 通過3D深度攝像頭(如結構光、ToF)獲取人臉的三維幾何信息(如鼻梁高度、曲面曲率),非活體(照片、屏幕)缺乏真實的深度結構。??
優點??:防御能力最強,可識別高級3D頭套攻擊。
??缺點??:硬件成本高,需專用3D傳感器。
本項目實現方案是采用基于人臉動作的活體識別方法,即先采用通用的人臉檢測模型,進行人臉檢測定位人臉區域,然后按照一定規則裁剪人臉檢測區域,再訓練一個人臉活體識別分類器,完成人臉活體識別的任務。人臉動作主要包含:眨眼(閉眼)、張嘴、點頭(低頭)、搖頭(側臉)。
3.人臉活體識別數據集
?(1)人臉活體識別數據集說明
項目對人臉圖像進行人臉動作標注,人臉動作主要包含:眨眼(閉眼)、張嘴、點頭(低頭)、搖頭(側臉),標注工具:使用labelme或者AnyLabeling(推薦)進行圖片標注。關于人臉活體識別數據集的說明,請參考文章:https://blog.csdn.net/guyuealian/article/details/147820499
4.人臉檢測模型
本項目人臉檢測訓練代碼請參考:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB?
這是一個基于SSD改進且輕量化后人臉檢測模型,很slim,整個模型僅僅1.7M左右,在普通Android手機都可以實時檢測。人臉檢測方法在網上有一大堆現成的方法可以使用,完全可以不局限我這個方法。
當然可以基于YOLOv5訓練一個人臉檢測模型:人臉檢測和行人檢測2:YOLOv5實現人臉檢測和行人檢測(含數據集和訓練代碼)
 ?
?
5.人臉活體識別模型訓練
準備好人臉活體識別數據后,接下來就可以開始訓練活體識別分類模型了;項目模型支持Resnet18, Mobilenet以及MobileVit等常見的深度學習模型,考慮到后續我們需要將人臉活體識別模型部署到Android平臺中,因此項目選擇計算量比較小的輕量化模型mobilenet_v2;如果不用端上部署,完全可以使用參數量更大的模型,如resnet50等模型。
?整套工程項目基本結構如下:
.
├── classifier # 訓練模型相關工具
├── configs # 訓練配置文件
├── data # 訓練數據
├── libs
│ ├── convertor # 將模型轉換為ONNX、NCNN等工具
│ ├── detection # 人臉檢測
│ ├── face_detector.py # 人臉檢測demo
│ └── README.md
├── demo.py # demo
├── README.md # 項目工程說明文檔
├── requirements.txt # 項目相關依賴包
└── train.py # 訓練文件(1)項目安裝
推薦使用Python3.8或Python3.10,更高版本可能存在版本差異問題,?項目依賴python包請參考requirements.txt,使用pip安裝即可:
# python3.10
beautifulsoup4==4.13.4
bs4==0.0.2
easydict==1.13
imageio==2.37.0
imgaug==0.4.0
loguru==0.7.3
matplotlib==3.10.1
numpy==1.26.4
onnx==1.17.0
onnx-simplifier==0.4.36
onnxruntime==1.21.1
onnxruntime-gpu==1.21.1
opencv-contrib-python==4.11.0.86
opencv-python==4.11.0.86
opencv-python-headless==4.11.0.86
pandas==2.2.3
pillow==10.4.0
pyarrow==19.0.1
PyYAML==6.0.2
requests==2.32.3
scikit-image==0.25.2
scikit-learn==1.6.1
scipy==1.15.2
seaborn==0.13.2
tensorboardX==2.6.2.2
#torch
#torchaudio==2.1.0+cu121
#torchvision==0.16.0+cu121
tqdm==4.67.1
Werkzeug==3.1.3
xmltodict==0.14.2
basetrainer==0.9.5
pybaseutils
項目安裝教程請參考(初學者入門,麻煩先看完下面教程,配置好開發環境):
- 項目開發使用教程和常見問題和解決方法
- 視頻教程:1 手把手教你安裝CUDA和cuDNN(1)
- 視頻教程:2 手把手教你安裝CUDA和cuDNN(2)
- 視頻教程:3 如何用Anaconda創建pycharm環境
- 視頻教程:4 如何在pycharm中使用Anaconda創建的python環境
- 推薦使用Python3.8或Python3.10,更高版本可能存在版本差異問題
(2)準備數據
下載人臉活體識別數據集:Face-Gesture-v1,Face-Gesture-v2,Face-Gesture-v3和Face-Gesture-test,然后解壓
?關于人臉活體識別數據集的使用說明請參考我的一篇博客:?https://blog.csdn.net/guyuealian/article/details/147820499
(3)人臉活體識別模型訓練(Pytorch)
項目在《Pytorch基礎訓練庫Pytorch-Base-Trainer(支持模型剪枝 分布式訓練)》基礎上實現了人臉活體識別分類模型訓練和測試,整套訓練代碼非常簡單操作,用戶只需要將相同類別的圖片數據放在同一個目錄下,并填寫好對應的數據路徑,即可開始訓練了。
訓練框架采用Pytorch,整套訓練代碼支持的內容主要有:
- 目前支持的backbone有:resnet18,resnet34,resnet50, mobilenet_v2、googlenet以及mobilevit等常見的深度學習模型。其他backbone可以自定義添加
- 訓練參數可以通過(configs/config.yaml)配置文件進行設置
修改配置文件的數據路徑:configs/?config.yaml?:
- train_data和test_data修改為自己的數據路徑
- 注意數據路徑分隔符使用【/】,不是【\】
- 項目不要出現含有中文字符的目錄文件或路徑,否則會出現很多異常!
# 訓練數據集,可支持多個數據集
train_data:- '/path/to/Face-Gesture/Face-Gesture-v1/image'- '/path/to/Face-Gesture/Face-Gesture-v2/image'- '/path/to/Face-Gesture/Face-Gesture-v3/image'
# 測試數據集
test_data: '/path/to/Face-Gesture/Face-Gesture-test/image'
# 類別文件
class_name: [ "face","閉眼","張嘴","低頭","側臉" ]
data_type: "labelme"
train_transform: "train" # 訓練使用的數據增強方法
test_transform: "val" # 測試使用的數據增強方法
crop_scale: [ 1.2,1.2 ]
work_dir: "work_space/" # 保存輸出模型的目錄
net_type: "resnet18" # 骨干網絡,支持:resnet18/50,mobilenet_v2,googlenet,inception_v3,mobilevit,vit_l_16,vit_b_16
width_mult: 1.0
input_size: [ 112,112 ] # 模型輸入大小
rgb_mean: [ 0.5, 0.5, 0.5 ] # for normalize inputs to [-1, 1],Sequence of means for each channel.
rgb_std: [ 0.5, 0.5, 0.5 ] # for normalize,Sequence of standard deviations for each channel.
batch_size: 64
lr: 0.01 # 初始學習率
optim_type: "SGD" # 選擇優化器,SGD,Adam
loss_type: "CrossEntropyLoss" # 選擇損失函數:支持CrossEntropyLoss,LabelSmooth
momentum: 0.9 # SGD momentum
num_epochs: 120 # 訓練循環次數
num_warn_up: 10 # warn-up次數
num_workers: 8 # 加載數據工作進程數
weight_decay: 0.0005 # weight_decay,默認5e-4
scheduler: "multi-step" # 學習率調整策略:multi-step,cosine
milestones: [ 30,50,100 ] # 下調學習率方式
gpu_id: [ 0 ] # GPU ID
log_freq: 100 # LOG打印頻率
progress: True # 是否顯示進度條
pretrained: True # 是否使用pretrained模型
finetune: False # 是否進行finetune開始訓練,在終端輸入:?
python train.py -c configs/config.yaml
?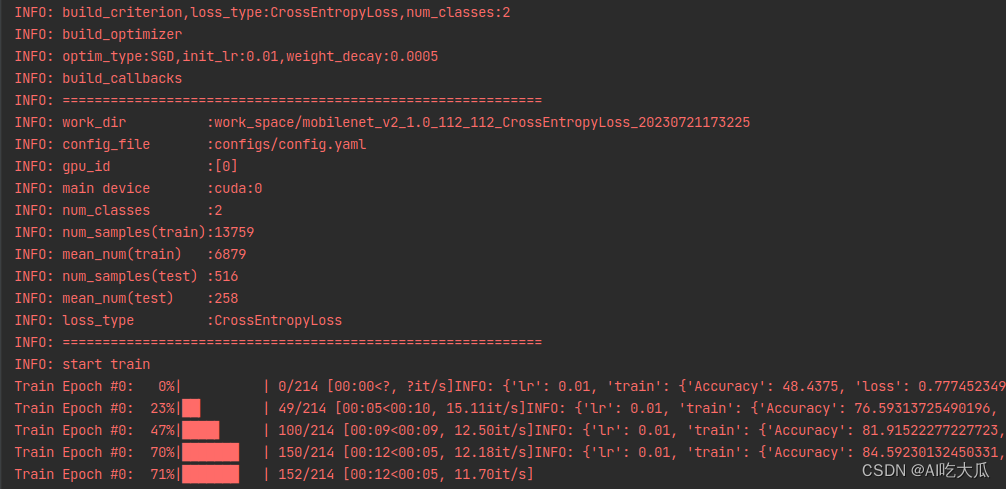 ??
??
訓練完成后,訓練集的Accuracy在99.0%以上,測試集的Accuracy在99.0%左右
(4) 可視化訓練過程
訓練過程可視化工具是使用Tensorboard,在終端(Terminal)輸入命令:
使用教程,請參考:項目開發使用教程和常見問題和解決方法
# 需要安裝tensorboard==2.5.0和tensorboardX==2.1
# 基本方法
tensorboard --logdir=path/to/log/
# 例如
tensorboard --logdir=tensorboard --logdir=/home/PKing/nasdata/release/tmp/PyTorch-Classification-Trainer/work_space/resnet18_1.0_112_112_CrossEntropyLoss_20250506_181748_8970/log可視化效果?
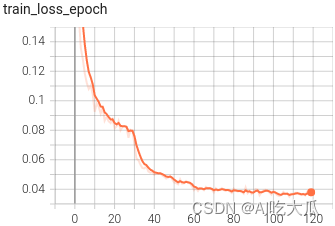 ?????
????? ?
?
?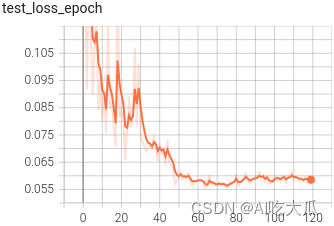 ?
? ?????
?????
(5) 人臉活體識別效果
訓練完成后,訓練集的Accuracy在99%以上,測試集的Accuracy在97.5%左右,下表給出已經訓練好的三個模型,其中mobilenet_v2的測試集準確率可以達到97.8682%,googlenet的準確率可以達到98.4496%,resnet18的準確率可以達到98.2558%
| 模型 | input size | Test準確率 |
| Mobilenet | 112×112 | 99.9661 |
| Resnet18 | 112×112 | 99.9322 |
| MobileVit | 112×112 | 99.9322 |
- 測試圖片文件
# 測試圖片文件(目錄)
python demo.py -c work_space/mobilenet_v2_1.0_112_112_CrossEntropyLoss_20250430_182131_2868/config.yaml -m work_space/mobilenet_v2_1.0_112_112_CrossEntropyLoss_20250430_182131_2868/model/best_model_119_99.9661.pth --image_dir data/test_images
- 測試視頻文件
# 測試視頻文件(path/to/video.mp4 測試視頻文件,如*.mp4,*.avi等)
python demo.py -c work_space/mobilenet_v2_1.0_112_112_CrossEntropyLoss_20250430_182131_2868/config.yaml -m work_space/mobilenet_v2_1.0_112_112_CrossEntropyLoss_20250430_182131_2868/model/best_model_119_99.9661.pth --video_file data/test-video.mp4
- 測試攝像頭
# 測試攝像頭(video_file填寫USB攝像頭ID)
python demo.py -c work_space/mobilenet_v2_1.0_112_112_CrossEntropyLoss_20250430_182131_2868/config.yaml -m work_space/mobilenet_v2_1.0_112_112_CrossEntropyLoss_20250430_182131_2868/model/best_model_119_99.9661.pth --video_file 0
? ??


(6) 一些優化建議
?如果想進一步提高模型的性能,可以嘗試:
- ??增加訓練的樣本數據: 建議根據自己的業務場景,采集相關數據,比如采集多個人的活體識別的數據,提高模型泛化能力;
- 使用參數量更大的模型: 本教程使用的是mobilenet_v2模型,屬于比較輕量級的分類模型,采用更大的模型(如resnet50),理論上其精度更高,但推理速度也較慢。
- 嘗試不同數據增強的組合進行訓練
- 增加數據增強: 已經支持: 隨機裁剪,隨機翻轉,隨機旋轉,顏色變換等數據增強方式,可以嘗試諸如mixup,CutMix等更復雜的數據增強方式
- 樣本均衡: 原始數據活體識別類別數據并不均衡,類別face的樣本數據偏多,而其他類別數據偏少,這會導致訓練的模型會偏向于樣本數較多的類別。建議進行樣本均衡處理。
- 清洗數據集:原始數據已經進行人工清洗了,但依然存在一些模糊的,低質的,模棱兩可的樣本;建議你,在訓練前,再次清洗數據集,不然會影響模型的識別的準確率。
- 調超參: 比如學習率調整策略,優化器(SGD,Adam等)
- 損失函數: 目前訓練代碼已經支持:交叉熵,LabelSmoothing,可以嘗試FocalLoss等損失函數
(7) 一些運行錯誤處理方法
-
大部分異常都可以看這里解決:項目開發使用教程和常見問題和解決方法?
-
項目不要出現含有中文字符的目錄文件或路徑,否則會出現很多異常!!!!!!!!?
6.項目源碼下載
如需下載項目源碼,請WX關注【AI吃大瓜】,回復【活體識別】即可下載
(1)訓練版本
提供人臉活體識別數據集:Face-Gesture-v1,Face-Gesture-v2,Face-Gesture-v3和Face-Gesture-test,總數50000+的人臉活體識別數據。
支持自定義數據集進行訓練
- 提供人臉活體識別模型訓練代碼:train.py
- 提供人臉活體識別模型測試代碼:demo.py,支持眨眼(閉眼)、張嘴、點頭(低頭)、搖頭(側臉)動作識別,識別準確率可以高達99.9661%左右
- Demo支持圖片,視頻和攝像頭測試
- 項目支持模型:resnet18,resnet34,resnet50, mobilenet_v2、googlenet以及mobilevit等常見的深度學習模型。
- 項目源碼自帶訓練好的模型文件,無需重新訓練,可直接運行測試: python?demo.py
- 在普通電腦CPU/GPU上可以實時檢測和識別
(2)推理版本
推理版本不含訓練代碼和數據集
- 提供人臉活體識別模型測試代碼:demo.py,支持眨眼(閉眼)、張嘴、點頭(低頭)、搖頭(側臉)動作識別,識別準確率可以高達99.9661%左右
- Demo支持圖片,視頻和攝像頭測試
- 項目支持模型:resnet18,resnet34,resnet50, mobilenet_v2、googlenet以及mobilevit等常見的深度學習模型。
- 項目源碼自帶訓練好的模型文件,無需重新訓練,可直接運行測試: python?demo.py
- 在普通電腦CPU/GPU上可以實時檢測和識別
7. C++實現人臉活體識別
參考文章:人臉活體識別3:C/C++實現人臉眨眼 張嘴 點頭 搖頭識別(可實時檢測)
8. Android實現人臉活體識別
參考文章:人臉活體識別4:Android實現人臉眨眼 張嘴 點頭 搖頭識別(可實時檢測)
 ? ?
? ?

)

















