引言:知識邊界的突破與重構
在人工智能技術快速發展的今天,大型語言模型(LLMs)已經展現出強大的文本生成和理解能力。然而,這些模型在實際應用中仍面臨著知識時效性、事實準確性和可溯源性等核心挑戰。檢索增強生成(Retrieval-Augmented Generation,RAG)技術應運而生,通過將外部知識庫與生成模型相結合,有效地拓展了大模型的知識邊界。
RAG技術的核心理念在于將參數化知識(存儲在模型參數中)與非參數化知識(存儲在外部數據庫中)有機融合,從而實現了知識的動態更新和精準檢索。這種創新架構不僅解決了傳統大模型的固有局限,更為人工智能系統開辟了全新的知識獲取和應用模式。
RAG技術的核心原理與架構演進
基礎架構與工作機制
RAG系統采用"檢索-增強-生成"的三階段工作流程,首先將用戶查詢轉換為向量表示,然后在外部知識庫中檢索相關文檔,最后將檢索結果作為上下文輸入到語言模型中生成回答。這種架構巧妙地結合了信息檢索的精確性和生成模型的靈活性,為知識密集型任務提供了強有力的技術支撐。
向量檢索作為RAG系統的核心組件,通過計算查詢與文檔間的語義相似度來獲取最相關的信息。現代RAG實現通常使用FAISS等高性能向量索引庫進行近似最近鄰搜索,實現了海量數據下的快速檢索。
import numpy as np
import faiss
from transformers import AutoTokenizer, AutoModel
from typing import List, Dict, Tuple
import torchclass RAGSystem:"""檢索增強生成系統核心實現"""def __init__(self, model_name="sentence-transformers/all-MiniLM-L6-v2"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.encoder = AutoModel.from_pretrained(model_name)self.knowledge_base = []self.embeddings = Noneself.index = Nonedef encode_text(self, texts: List[str]) -> np.ndarray:"""將文本編碼為向量表示"""inputs = self.tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)with torch.no_grad():outputs = self.encoder(**inputs)# 使用平均池化獲取句子嵌入embeddings = outputs.last_hidden_state.mean(dim=1)return embeddings.numpy()def build_knowledge_base(self, documents: List[str]):"""構建知識庫和向量索引"""print(f"正在構建知識庫,文檔數量: {len(documents)}")# 保存原始文檔self.knowledge_base = documents# 生成文檔嵌入self.embeddings = self.encode_text(documents)# 構建FAISS索引dimension = self.embeddings.shape[1]self.index = faiss.IndexFlatIP(dimension) # 內積相似度# 標準化嵌入向量faiss.normalize_L2(self.embeddings)self.index.add(self.embeddings)print(f"知識庫構建完成,索引維度: {dimension}")def retrieve_documents(self, query: str, k: int = 5) -> List[Tuple[str, float]]:"""檢索最相關的文檔"""if self.index is None:raise ValueError("知識庫尚未構建,請先調用build_knowledge_base")# 編碼查詢query_embedding = self.encode_text([query])faiss.normalize_L2(query_embedding)# 檢索top-k相似文檔scores, indices = self.index.search(query_embedding, k)results = []for i, (score, idx) in enumerate(zip(scores[0], indices[0])):if idx < len(self.knowledge_base):results.app
技術演進的三個階段
RAG技術的發展經歷了從Naive RAG到Advanced RAG,再到Modular RAG的演進過程。Naive RAG采用簡單的向量相似度檢索和基礎生成流程,適用于簡單問答場景但在復雜任務中表現有限。Advanced RAG引入了查詢重寫、混合檢索和結果重排等優化策略,顯著提升了檢索質量和生成準確性。
最新的Modular RAG采用高度模塊化的設計理念,支持自適應檢索和多階段檢索,能夠處理多模態復雜任務。這種演進體現了RAG技術從簡單拼接向深度融合的發展趨勢,為構建更智能、更可靠的知識系統奠定了基礎。

性能優勢的量化分析
通過對比傳統LLM與不同RAG范式的性能表現,可以清晰地看到RAG技術帶來的顯著提升。在準確率方面,Modular RAG相比傳統LLM提升了19個百分點,達到91%的高水平。相關性和事實性維度的改善更為顯著,分別提升了26和27個百分點。
?
RAG技術演進性能對比雷達圖
這些數據充分證明了RAG技術在重構大模型知識邊界方面的核心價值。通過引入外部知識源,RAG不僅彌補了傳統模型的知識局限,還為實時知識更新和領域特化應用提供了可行路徑。
RAG與其他技術方法的對比分析
知識更新能力的根本優勢
在知識更新能力方面,RAG技術展現出壓倒性優勢,評分高達95分,遠超微調(30分)和提示工程(40分)等傳統方法。這種優勢源于RAG系統可以通過更新外部知識庫來獲取最新信息,而無需重新訓練整個模型。微調雖然能產生高質量輸出,但知識更新成本極高,需要完整的模型重訓練過程。
提示工程雖然實施簡單、成本低廉,但無法有效添加新知識,只能在現有參數知識范圍內進行優化。混合方法結合了RAG和微調的優勢,在生成質量上表現最佳,但相應地增加了實施復雜度和計算成本。
?
RAG與其他技術方法的多維度對比
計算效率與實施復雜度平衡
RAG技術在計算成本和實施復雜度之間取得了良好平衡,為實際部署提供了可行方案。相比于微調的高計算成本(90分)和提示工程的低復雜度(15分),RAG以中等的成本投入(60分)和復雜度(70分)實現了優異的性能表現。
這種平衡使得RAG特別適合于需要頻繁知識更新的應用場景,如新聞問答、企業知識管理和專業領域咨詢等。研究表明,RAG系統可以將較小的語言模型提升至接近大模型的性能水平,同時保持12倍的成本效率和3倍的速度優勢。
RAG在多元化應用場景中的實踐效果
跨行業應用的顯著成效
RAG技術在不同行業應用中都展現出顯著的效果提升。在客戶服務領域,RAG系統實現了42%的準確率提升,響應時間控制在120毫秒以內,用戶滿意度高達91%。這種優異表現主要歸因于RAG能夠實時檢索相關產品信息和常見問題解答,為客戶提供準確及時的服務支持。
教育輔導應用中,RAG取得了45%的準確率提升,為個性化學習提供了強有力的技術支撐。通過整合教材、學術文獻和教學資源,RAG系統能夠為學生提供針對性的學習指導和答疑解惑。
?
RAG技術在不同領域的應用效果對比
法律咨詢和醫療診斷等專業領域同樣受益于RAG技術。法律RAG系統通過整合法規、判例和解釋文件,實現了38%的準確率提升。醫療RAG應用通過整合醫學文獻和臨床指南,為醫生提供基于最新研究的決策支持,準確率提升達31%。
專業領域的深度應用
在專業垂直領域,RAG技術展現出強大的領域適應能力。醫療健康領域的MedRAG系統通過整合多源醫學知識庫,在醫學問答基準上實現了18%的性能提升,甚至將某些模型的表現提升至GPT-4水平。這種提升主要來源于RAG系統能夠獲取最新的醫學研究成果和臨床指南。
法律領域的HyPA-RAG系統針對復雜法律文本進行了專門優化,采用查詢復雜度分類器進行自適應參數調優,結合密集、稀疏和知識圖譜的混合檢索策略。實驗結果表明,該系統在法律文本解釋的正確性、忠實性和上下文精確度方面都有顯著提升。
RAG技術面臨的核心挑戰
技術層面的關鍵瓶頸
盡管RAG技術取得了顯著進展,但仍面臨多重技術挑戰。檢索質量問題是最關鍵的挑戰之一,重要性評分高達90分,主要表現為檢索不相關和結果排序不準確等問題。這些問題直接影響下游生成的質量,需要通過混合檢索、查詢重寫和重排序算法來解決。
生成質量挑戰的重要性評分為85分,包括內容不一致、事實錯誤和重復冗余等問題。解決這些問題需要綜合運用提示工程、后處理技術和事實檢驗機制。系統性能問題雖然重要性相對較低(75分),但在實際部署中不容忽視,主要涉及延遲過高、內存占用大和擴展性差等方面。
?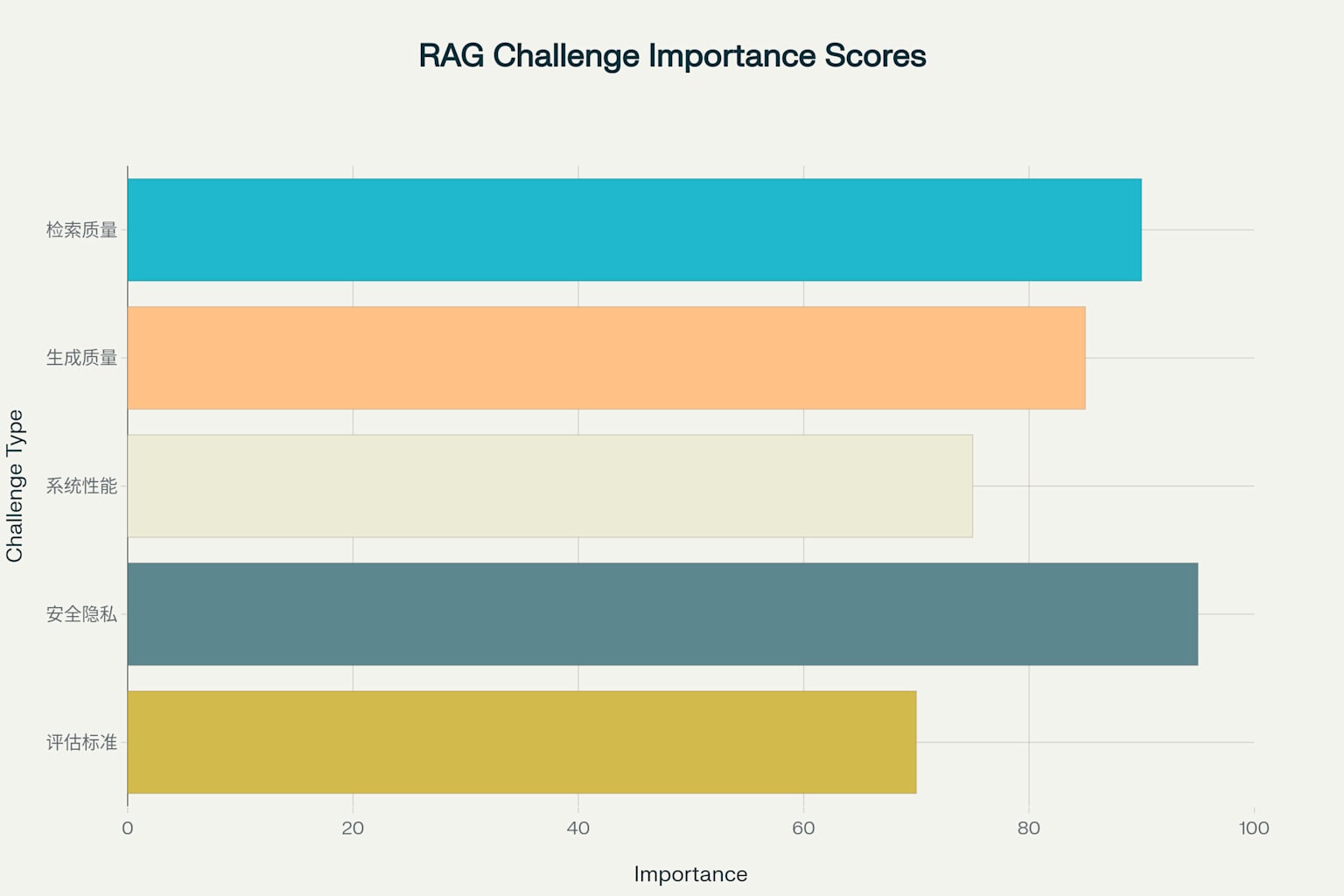
RAG技術面臨的主要挑戰重要性評估
安全隱私的嚴峻挑戰
安全隱私問題被評為最嚴峻的挑戰,重要性評分達到95分。數據投毒攻擊可能通過注入惡意內容影響RAG系統的回答質量,研究表明,未經保護的RAG系統可能被提取超過70%的私有知識庫信息。
為應對這些安全威脅,研究者提出了多種防護措施。聯邦學習技術允許在不共享原始數據的情況下訓練和優化模型。差分隱私技術可以在保護個人隱私的同時保持數據的分析價值。訪問控制和查詢篩選機制則能夠防止惡意查詢對系統的攻擊。
RAG技術的未來發展趨勢
多模態與實時更新的技術前沿
RAG技術的未來發展將主要集中在多模態和實時知識更新兩個方向。多模態RAG通過整合文本、圖像、音頻等多種數據形式,預計在2025年達到技術成熟,商業價值評分高達90分。這類系統在工業診斷和視覺問答方面已展現出顯著優勢,相比純文本RAG系統準確率提升15%-23%。
實時知識更新技術將解決知識時效性問題,使RAG系統能夠持續獲取最新信息。雖然技術難度評分達到90分,但其商業價值同樣很高(85分),預期在2026年實現成熟應用。這種技術對于新聞媒體、金融分析和科研應用等時效性要求高的領域具有重要意義。

邊緣計算與聯邦技術的創新應用
邊緣計算RAG和聯邦RAG代表了技術發展的長期方向。邊緣計算RAG預計在2027年成熟,將解決隱私保護和低延遲需求,特別適合移動設備和資源受限環境。聯邦RAG作為技術難度最高的發展方向(95分),有望在2028年實現成熟應用。
C-FedRAG等系統已經展示了聯邦學習在RAG中的應用潛力,通過機密計算技術實現了跨組織的安全知識共享。這些技術的成熟將為構建更大規模、更安全的知識系統提供技術基礎。
技術發展的時間軸與里程碑
RAG技術從2020年概念提出到2025年多模態應用,經歷了快速發展過程。2020年的概念提出標志著技術起點,論文數量僅為15篇,技術成熟度為20%。2023年Advanced RAG的出現使技術成熟度躍升至70%,論文數量達到280篇。2024年Modular RAG的成熟使技術成熟度進一步提升至85%,年度論文數量達到450篇的峰值。
?
RAG技術發展時間線:論文產出與技術成熟度演進
預計2025年多模態RAG將成為主要發展方向,雖然論文數量可能回落至320篇,但技術成熟度將達到90%的高水平。這種趨勢表明RAG技術正從理論探索向實際應用轉變,技術重點也從基礎架構向專業應用和性能優化轉移。
RAG系統的實施策略與最佳實踐
完整的實施流程體系
成功實施RAG系統需要遵循科學的流程體系,包括需求分析、技術選型、數據準備、系統開發、測試評估和部署運維六個關鍵階段。需求分析階段需要明確應用場景和目標用戶,評估現有數據資源和質量,確定性能要求和約束條件。技術選型階段則需要選擇合適的嵌入模型、確定向量數據庫方案、選擇生成模型和架構。
數據準備階段是RAG系統成功的關鍵,需要進行數據清洗和預處理、構建高質量的知識庫、設計合理的文檔分塊策略。系統開發階段需要實現檢索模塊、集成生成模塊、優化端到端流程。測試評估和部署運維階段則確保系統的穩定運行和持續優化。
性能優化與質量保證
RAG系統的性能優化需要從多個維度進行綜合考慮。M-RAG等多分區方法通過將知識庫劃分為多個分區,實現了文本摘要11%、機器翻譯8%和對話生成12%的性能提升。Reward-RAG通過獎勵驅動的監督學習,使用CriticGPT訓練專用獎勵模型,顯著改善了生成回答的相關性和質量。
Invar-RAG等先進架構通過兩階段微調和不變性損失,有效解決了LLM在檢索任務中的特征局部性問題。這些創新方法在開放域問答數據集上都展現出明顯的性能優勢,為RAG系統的工程實踐提供了重要參考。
結論:重構知識邊界的新紀元
RAG技術通過將檢索與生成相結合,成功重構了大型語言模型的知識邊界,開創了人工智能與知識交互的新范式。從技術演進的角度看,RAG已從簡單的檢索-生成流程發展為復雜的模塊化系統,在準確率、相關性和事實性方面都實現了顯著提升。
在應用層面,RAG技術已在客戶服務、教育輔導、法律咨詢和醫療診斷等多個領域展現出強大的實用價值。相比于傳統的微調和提示工程方法,RAG在知識更新能力方面具有壓倒性優勢,為構建動態、準確的知識系統提供了可行路徑。
面向未來,多模態RAG、實時知識更新和聯邦RAG等前沿技術將進一步拓展RAG的應用邊界。隨著這些技術的成熟,RAG將在更廣泛的場景中發揮作用,真正實現知識的民主化和智能化。盡管仍面臨安全隱私、檢索質量和系統性能等挑戰,但通過持續的技術創新和工程實踐,RAG必將成為下一代人工智能系統的核心技術基礎。
)








)


)






