文章目錄
- 1.1分鐘快覽
- 2.模型架構
- 2.1.Dense模型
- 2.2.MoE模型
- 3.預訓練階段
- 3.1.數據
- 3.2.訓練
- 3.3.評估
- 4.后訓練階段
- S1: 長鏈思維冷啟動
- S2: 推理強化學習
- S3: 思考模式融合
- S4: 通用強化學習
- 5.全家桶中的小模型訓練
- 評估
- 評估數據集
- 評估細節
- 評估效果
- 弱智評估和民間Arena
- 分析
- 展望
如果有格式或者想查看更多內容,可以訪問:Qwen系列之Qwen3解讀:最強開源模型的細節拆解查看詳情
1.1分鐘快覽
Qwen3發了什么?
- 發布了密集型和專家混合(Mixture-of-Experts, MoE)模型,參數數量從 0.6 億到 235 億不等,以滿足不同下游應用的需求。
- 將兩種不同的運行模式——思考模式和非思考模式——整合到單一模型中。這允許用戶在這些模式之間切換。集成了思考預算機制,為用戶提供了對模型在任務執行過程中推理長度的細粒度控制。
訓練里面的核心亮點是什么?
訓練過程:
- 三階段預訓練:36T的token訓練:先30T的4096長度的通用訓練,再5T的4096推理訓練帶衰減學習率,最后是千億長文本32768訓練。
- 后訓練:前兩個階段主要增強推理能力,后兩個階段做拒絕采樣和強化學習,增強通用能力
- S1: Long-Cot冷啟動:qwq32b造數據,qwen72B + 人工洗數據。
- S2: 推理強化學習:選用無leak的多樣性的難度適中的4k數據跑GRPO。
- S3: 思考模式融合SFT:通過一個specitoken,在prompt加/think和/no_think標志,然后訓練。混合著也學會了自動的短cot模式,很神奇。
- S4: 通用強化學習:涵蓋20多種不同任務,每個任務都有定制的評分標準,規則+模型(有無參考答案)。
- 蒸餾到小模型:logits蒸餾非數據蒸餾,效果更好。
2.模型架構
6個Dense模型:Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B 和 Qwen3-32B
2個MoE 模型:Qwen3-30B-A3B 和 Qwen3-235B-A22B。
2.1.Dense模型
- Grouped Query Attention (GQA, Ainslie et al., 2023)
- SwiGLU (Dauphin et al., 2017)
- Rotary Positional Embeddings (RoPE, Su et al., 2024)
- RMSNorm (Jiang et al., 2023) with pre-normalization.
- 移除了Qwen2中使用的 QKV 偏置,并在注意力機制中引入了 QK-Norm,以確保 Qwen3 的穩定訓練;
- 模型使用 Qwen的分詞器(Bai 等人,2023),該分詞器實現Byte-level byte-pair encoding(BBPE,Brown 等人,2020;Wang 等人,2020;Sennrich 等人,2016),詞匯量為 151,669。

2.2.MoE模型
- 與Qwen3 Dense模型共享相同的基本架構,參考Qwen2.5-MoE并實現細粒度專家分割(fine-grained expert segmentation)(Dai 等人,2024)。Qwen3 MoE 模型共有 128 個專家,每個 token 激活 8 個專家。
- 與 Qwen2.5-MoE 不同,Qwen3-MoE設計沒有使用共享專家。我們采用全局批處理負載均衡損失(lobal-batch load balancing loss)(Qiu 等人,2025)來鼓勵專家專業化。這些架構和訓練創新在下游任務中顯著提升了模型性能。關于負載均衡損失可以參考兩篇文章:關于 MoE 大模型負載均衡策略演進的回顧:坑點與經驗教訓 和 阿里云通義大模型新技術:MoE模型訓練專家平衡的關鍵細節

3.預訓練階段
3.1.數據
Qwen3 模型都在一個包含 119 種語言和方言的大型多樣化數據集上進行訓練,總共有 36 萬億個 token。這個數據集包括包括編碼、STEM(科學、技術、工程和數學)、推理任務、書籍、多語言文本和合成數據等各個領域的高質量內容。
值得注意的是用Qwen2.5-VL從大量 PDF 文檔中提取文本,識別出的文本隨后通過 Qwen2.5 模型(Yang 等人,2024b)進行優化,以提升其質量。我們還使用領域特定模型生成合成數據:Qwen2.5-Math用于數學內容,Qwen2.5-Coder用于代碼相關數據。
3.2.訓練
Qwen3模型通過三個階段進行預訓練:
(1) 一般階段 (S1):在第一個預訓練階段,所有Qwen3模型在超過30萬億個標記上進行訓練,序列長度為4,096個標記。在此階段,模型已在語言能力和一般世界知識上完成全面預訓練,訓練數據覆蓋119種語言和方言。
(2) 推理階段 (S2):為了進一步提高推理能力,我們通過增加STEM、編碼、推理和合成數據的比例來優化這一階段的預訓練語料庫。模型在序列長度為4,096個標記的情況下,進一步預訓練了約5T的高質量標記。我們還加快了這一階段的學習率衰減。
(3) 長文本階段(S3):在最終的預訓練階段,我們收集高質量的長文本語料庫,以擴展Qwen3模型的上下文長度。所有模型在數千億個標記上進行預訓練,序列長度為32,768個標記。長文本語料庫包括75%的文本長度在16,384到32,768 token,25%的文本長度在4,096到16,384 token。跟Qwen2.5相同,使用ABF技術(Xiong等,2023)將RoPE的基礎頻率從10,000提高到1,000,000。同時,引入YARN(Peng等,2023)和雙塊注意力(DCA,An等,2024),以推理過程中將序列長度能力提升四倍。
與Qwen2.5(Yang等,2024b)類似,我們基于上述三個預訓練階段開發了最佳超參數(例如,學習率調度和批量大小)預測的縮放法則。通過廣泛的實驗,我們系統地研究了模型架構、訓練數據、訓練階段與最佳訓練超參數之間的關系。最后,我們為每個密集模型或MoE模型設定了預測的最佳學習率和批量大小策略。
3.3.評估
- General Tasks:
- MMLU (Hendrycks et al., 2021a) (5-shot),
- MMLU-Pro (Wang et al., 2024) (5-shot, CoT),
- MMLU-redux (Gema et al., 2024) (5-shot),
- BBH (Suzgun et al., 2023) (3-shot, CoT),
- SuperGPQA (Du et al., 2025)(5-shot, CoT).
- Math & STEM Tasks:
- GPQA (Rein et al., 2023) (5-shot, CoT),
- GSM8K (Cobbe et al., 2021) (4-shot,CoT),
- MATH (Hendrycks et al., 2021b) (4-shot, CoT).
- Coding Tasks:
- EvalPlus (Liu et al., 2023a) (0-shot) (Average of HumanEval (Chen et al., 2021),
- MBPP (Austin et al., 2021),
- Humaneval+, MBPP+) (Liu et al., 2023a),
- MultiPL-E (Cassano et al.,2023) (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript),
- MBPP-3shot (Austin et al., 2021), CRUX-O of CRUXEval (1-shot) (Gu et al., 2024).
- Multilingual Tasks:
- MGSM (Shi et al., 2023) (8-shot, CoT),
- MMMLU (OpenAI, 2024) (5-shot),
- INCLUDE (Romanou et al., 2024) (5-shot)
評估結論:
- 與先前開源的密集和 MoE 基礎模型(如 DeepSeekV3 Base、Llama-4-Maverick Base 和 Qwen2.5-72B-Base)相比,Qwen3-235B-A22B-Base 在大多數任務中表現優于這些模型,且參數總數或激活參數顯著更少。
- 對于 Qwen3 MoE 基礎模型,我們的實驗結果表明:
- 使用相同的預訓練數據,Qwen3 MoE 基礎模型僅需 1/5 的激活參數即可達到與 Qwen3 密集基礎模型相似的性能。
- 由于 Qwen3 MoE 架構的改進、訓練 token 規模的擴大以及更先進的訓練策略,Qwen3 MoE 基礎模型可以用不到 1/2 的激活參數和更少的總參數超越 Qwen2.5 MoE 基礎模型。
- 即使只有 Qwen2.5 密集基礎模型 1/10 的激活參數,Qwen3 MoE 基礎模型也能達到相當的性能,這為我們的推理和訓練成本帶來了顯著優勢。
- Qwen3 Dense 基礎模型的整體性能在更高參數規模下與 Qwen2.5 基礎模型相當。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分別達到了與 Qwen2.5-3B/7B/14B/32B/72B-Base 相當的性能。特別是在 STEM、編程和推理基準測試中,Qwen3 密集基礎模型在更高參數規模下的性能甚至超越了 Qwen2.5 基礎模型。
詳細評估結果見原文。
4.后訓練階段

S1: 長鏈思維冷啟動
我們首先整理一個涵蓋廣泛類別的綜合數據集,包括數學、代碼、邏輯推理和一般STEM(STEM:即科學、技術、工程和數學)問題。數據集中的每個問題都配有經過驗證的參考答案或基于代碼的測試用例。
數據過濾:
- 數據集構建涉及嚴格的兩階段過濾過程:query過濾和answer過濾。
- query過濾:我們使用Qwen2.5-72B-Instruct識別并移除那些不易驗證的query,這包含多個子問題的query或要求生成一般文本的query。
- answer過濾:我們過濾掉那些Qwen2.5-72B-Instruct能夠在不使用鏈式推理的情況下正確回答的query。這有助于防止模型進行淺顯的推演,確保僅包含需要更深入推理的復雜問題。
- 我們使用Qwen2.5-72B-Instruct對每個query的domain(領域)進行標注,以保持數據domain(領域)表示的平衡。
數據處理:
在保留驗證query集后,我們使用QwQ-32B為每個query生成N個候選answer。如果QwQ-32B無法生成正確答案時,人工評估員會手動評估answer的準確性。對于N個候選存在正確結果的query,進一步嚴格的過濾標準被應用,以去除以下answer:
- 產生錯誤的最終答案;
- 包含明顯重復;
- 存在明顯猜測,但是缺乏足夠的推理;
- 思考與最終的summary內容之間不一致;
- 存在不當的語言混合(language mixing )或風格轉變(stylistic shifts);
- 跟驗證集很像的數據;
隨后,經過精心挑選的精煉數據集子集用于推理模式的初始冷啟動訓練。此階段的目標是向模型灌輸基礎推理模式,而不過分強調即時推理性能。這種方法確保模型的潛力不受限制,從而在隨后的強化學習(RL)階段提供更大的靈活性和改進。為了有效實現這一目標,最好在這一準備階段盡量減少訓練樣本和訓練步驟。
這里的N是多少?訓練數據是多少?文中沒提~
S2: 推理強化學習
在推理強化學習階段使用的 query-verifier對必須滿足以下四個標準:
- 在冷啟動階段未被使用;
- 對于冷啟動模型是可學習的;
- 盡可能具有挑戰性;
- 涵蓋廣泛的子領域。
我們最終收集了總共3,995個 query-verifier對,并采用GRPO(Shao等,2024)來更新模型參數。我們觀察到,使用較大的batch size,增加對每個query的rollouts次數,以及off-policy訓練以提高樣本效率,對訓練過程是有益的。我們還解決了如何通過控制模型的熵來平衡探索與利用,以實現穩步增加或保持不變。
感覺這里面的細節挺多的: 如何定義對冷啟模型是可學習的?如何定義是有挑戰的?
S3: 思考模式融合
思維模式融合階段的目標是將“非思維”能力整合到先前開發的“思維”模型中。這種方法使開發者能夠管理和控制推理行為,同時降低了為思維和非思維任務部署單獨模型的成本和復雜性。為此,我們對推理強化學習模型進行持續的監督微調,并設計一個chat模板以融合這兩種模式。此外,我們發現能夠熟練處理這兩種模式的模型在不同的思維預算下表現始終良好。
SFT數據的構建:SFT數據集結合了“思考”和“非思考”數據。為了確保第二階段模型的性能不受額外SFT的影響,“思考”數據是通過對第一階段的query并使用第二階段模型進行拒絕采樣生成的。“非思考”數據則經過精心設計,涵蓋包括編碼、數學、遵循指令、多語言任務、創意寫作、問答和角色扮演多樣化的任務。此外,我們使用自動生成的checklist來評估“非思考”數據的answer質量。為了提高低資源語言任務的表現,我們特別增加了翻譯任務的比例。
這里也有提到,使用了checklist的方案來評估"非思考"類數據的質量,這個是我們在問答場景做過比較詳細實驗的一種方案,確實很有效。
聊天模板設計:為了更好地整合這兩種模式并使用戶能夠動態切換模型的思維過程,我們為Qwen3設計了聊天模板,如下圖所示。具體而言,對于思維模式和非思維模式的樣本,我們在用戶query或系統消息中分別引入</think>和</no_think>標志。這使得模型能夠根據用戶的輸入選擇相應的思維模式。對于非思維模式樣本,我們在助手的answer中保留一個空的思維塊。該設計確保了模型內部格式的一致性,并允許開發者通過在聊天模板中連接一個空的思維塊來防止模型進行思考行為。默認情況下,模型在思維模式下運行,另外,我們添加了一些用戶query不包含</think>標志的思維模式訓練樣本。對于更復雜的多輪對話,我們隨機在用戶的query中插入多個</think>和</no_think>標志,模型的answer遵循最后遇到的標志。

思維預算:思維模式融合的一個額外優勢是,一旦模型學會在非思維和思維模式下answer,它自然會發展出處理中間情況的能力——基于不完整思維生成answer。這一能力為實施對模型思維過程的預算控制奠定了基礎。具體而言,當模型的思維長度達到用戶定義的閾值時,我們手動停止思維過程并插入停止思維指令:“Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n\</think>.\n\n” 插入此指令后,模型繼續生成基于其到該時刻為止的累積推理的最終answer。值得注意的是,這一能力并不是通過明確訓練獲得的,而是作為應用思維模式融合的結果自然出現的。具體的,從產品形態(chat.qwen.ai)上如下圖,達到字數后就插入上述指令后終止思考,開始summary部分生成。從最終結果上看,隨著長度調大,效果是越來越好的,詳見后文的分析章節。
S4: 通用強化學習
通用強化學習階段旨在廣泛增強模型在多種場景下的能力和穩定性。為此,我們建立了一個復雜的獎勵系統,涵蓋20多種不同任務,每個任務都有定制的評分標準。這些任務特別針對以下核心能力的提升:
-
指令遵循:該能力確保模型準確解讀并遵循用戶指令,包括與內容、格式、長度和結構化輸出相關的要求,提供符合用戶期望的answer。
-
格式遵循:除了明確的指令外,我們期望模型遵循特定的格式約定。例如,它應在思考和非思考模式中適當地使用
/think和/no_think標志,并始終使用指定的標記(例如,<think>和</think>)來分隔最終輸出中的思考和answer部分。 -
偏好對齊:對于開放式query,偏好對齊側重于提高模型的幫助性(helpfulness)、參與度(engagement)和風格(style),最終提供更自然和令人滿意的用戶體驗。
-
Agent能力:這涉及訓練模型通過指定接口正確調用工具。在強化學習rollout時,需要模型能夠進行完整的多輪交互,并獲得真實環境執行反饋,從而提高其在長期決策任務(long-horizon decision-making tasks)中的表現和穩定性。
-
特殊場景的能力:在更專業的場景中,我們設計了針對特定上下文的任務。例如,在檢索增強生成(RAG)任務中,我們引入獎勵信號,我們結合獎勵信號引導模型生成準確且符合上下文的response,從而降低幻覺風險。
rag場景的特殊獎勵防止幻覺,具體怎么做的?這里沒展開說~
為了為上述任務提供反饋,我們利用了三種不同類型的獎勵:
- 基于規則的獎勵:基于規則的獎勵在推理強化學習階段被廣泛使用,并且對一般任務如遵循指令(Lambert等,2024)和格式遵循也很有用。設計良好的基于規則的獎勵可以高精度地評估模型輸出的正確性,防止reward hacking等問題。
- 有參考答案情況下基于模型的獎勵:在這種方法中,我們為每個query提供一個參考答案,并提示Qwen2.5-72B-Instruct根據該參考答案對模型的answer進行評分。這種方法允許更靈活地處理多樣化的任務,而無需嚴格的格式,從而避免了純規則獎勵可能出現的假陰性。
- 無參考答案情況下基于模型的獎勵:利用人類偏好數據,我們訓練一個獎勵模型,為模型answer分配標量分數。這種不依賴于參考答案的方法可以處理更廣泛的query,同時有效提升模型的參與度和幫助性。
蝸牛說:
這里的實現細節還挺多的。
有參考答案情況下基于模型的獎勵,其實說白了就是用Qwen2.5寫個prompt進行評估,是經典的LLM-as-judger的方法。但是其實LLM-as-judger的維度可能是多樣的,不同任務可能都有至少一個甚至多個評估維度,20個任務那評估的體系是一個很復雜的系統,構建這樣的verifier系統是基于RL的后訓練優化的關鍵。
無參考答案情況下,只用了reward model進行打分。
5.全家桶中的小模型訓練
從強到弱的蒸餾流程專門設計用于優化輕量級模型,包括5個密集模型(Qwen3-0.6B、1.7B、4B、8B和14B)和一個MoE模型(Qwen3-30B-A3B)。這種方法在有效傳授強大的模式切換能力的同時,提升了模型性能。蒸餾過程分為兩個主要階段:
(1) 離線蒸餾:在這個階段,教師模型在 /think 和 /no_think 兩種模式下進行answer生成,并進行蒸餾。這有助于輕量級學生模型發展基本的推理能力和在不同思維模式之間切換的能力,為下一階段的在線訓練奠定堅實基礎。
(2) 在線蒸餾:在這個階段,學生模型生成on policy序列進行微調。prompt隨機情況下,學生模型選擇在 /think 或 /no_think 模式下生成answer。然后,通過將其logits與教師模型(Qwen3-32B或Qwen3-235B-A22B)的logits對齊,微調學生模型以最小化KL散度。
通過蒸餾的方式,帶來了更好的即時性能,如更高的 Pass@1 分數所示,同時也提升了模型的探索能力,體現在 Pass@64 結果的改善上。
對于較小的模型,我們利用大型模型的on-policy和off-policy方式,使用從強到弱的蒸餾方法來增強其能力。從比較強的teacher模型進行蒸餾,在性能和訓練效率方面顯著優于強化學習。這個結論在R1以及Qwen等多個大模型的技術報告中被多次證實了。
評估
評估數據集
通用任務:
- MMLU-Redux (Gema et al., 2024),
- GPQA-Diamond (Rein et al., 2023), sample 10 times for each query and report the averaged accuracy.
- C-Eval (Huang et al., 2023),
- LiveBench (2024-11-25) (White et al.,2024).
對齊任務:
- 指令遵循:IFEval (Zhou et al., 2023).
- 通用話題:Arena-Hard (Li et al., 2024) and AlignBench v1.1 (Liu et al., 2023b).
- 寫作/創作任務:Creative Writing V3 (Paech, 2024) and WritingBench (Wu et al., 2025)
數學與文本推理:
- 數學:MATH-500 (Lightman et al., 2023), AIME’24 and AIME’25(AIME, 2025)。對于 AIME 問題,每年的問題包括第一部分和第二部分,共計 30 道題。對于每道題,我們采樣 64 次,并取平均準確率作為最終得分。(沒記錯的話,AIME這里的方式跟R1里面的評估方法一致)
- 文本推理:ZebraLogic (Lin et al., 2025) and AutoLogi(Zhu et al., 2025).
- 智能體與編程:
- BFCLv3 (Yan et al., 2024), 對于 BFCL,所有 Qwen3 模型均使用 FC 格式進行評估,并使用 yarn 將模型部署到 64k 的上下文長度進行多輪評估。部分基線來自 BFCL 排行榜,取 FC 格式和 Prompt 格式的較高分數。對于排行榜上未報告的模型,則評估 Prompt 格式。
- LiveCodeBench (v5, 2024.10-2025.02) (Jain et al., 2024), 對于 LiveCodeBench,在非思考模式下,我們使用官方推薦的提示詞,而在思考模式下,我們調整提示詞模板以允許模型更自由地思考,通過移除“You will not return anything
except for the program.”的限制。 - Codeforces Ratings from CodeElo (Quan et al., 2025). 為評估模型與競賽編程專家之間的性能差距,我們使用 CodeForces 計算 Elo 評分。在我們的基準測試中,每個問題通過生成最多8個推理嘗試來解決。
多語言任務
- 指令遵循:Multi-IF (He et al., 2024), 該任務專注于 8 種關鍵語言。
- 知識評估:分為兩種類型: regional knowledg通過INCLUDE (Romanou et al.,2024)進行評估,涵蓋 44 種語言;通用知識使用 MMMLU(OpenAI,2024)進行評估,涵蓋 14 種語言,不包括未優化的約魯巴語。對于這兩個基準,我們僅采樣原始數據的 10%以提高評估效率。
- 數學任務: MT-AIME2024 (Son et al., 2025),涵蓋 55 種語言。 PolyMath (Wang et al.,2025),包含 18 種語言。
- 邏輯推理: MlogiQA 進行評估,涵蓋 10 種語言。
評估細節
- 思考模式:我們采用采樣溫度 0.6、top-p 值 0.95 和 top-k 值 20。此外,對于 Creative Writing v3 和 WritingBench,我們應用存在懲罰 1.5 以鼓勵生成更多多樣化的內容。
- 非思考模式:我們配置采樣超參數為溫度=0.7、top-p=0.8、top-k=20 和presence penalty=1.5。
- 對于思考模式和非思考模式,我們將最大輸出長度設置為 32,768 個 token。但 AIME’24 和 AIME’25 除外,我們將此長度擴展至 38,912 個 token 以提供足夠的思考空間。
評估效果
關鍵結論:
- 我們的旗艦模型 Qwen3-235B-A22B 在思考和非性思維模式下均表現出開源模型中的頂尖整體性能,超越了 DeepSeek-R1 和 DeepSeek-V3 等強基線模型。Qwen3-235B-A22B 在與 OpenAI-o1、Gemini2.5-Pro 和 GPT-4o 等閉源領先模型相比中也極具競爭力,展示了其深刻的推理能力和全面的通用能力。
- 我們的旗艦密集模型 Qwen3-32B 在大多數基準測試中超越了我們之前最強的推理模型 QwQ-32B,并且性能與閉源的 OpenAI-o3mini 相當,表明其具有令人信服的推理能力。Qwen3-32B 在非性思維模式下也表現出色,超越了我們之前旗艦的非推理密集模型 Qwen2.5-72B-Instruct。
- 我們的輕量級模型,包括 Qwen3-30B-A3B、Qwen3-14B 以及其他更小的密集模型,在參數數量相近或更大的開源模型中始終表現出更優越的性能,證明了我們強到弱蒸餾方法的成功。

Qwen3跟R1比起來,整體上是comparable,或者說是略強的。Gemini2.5-pro整體上還是比較強的,呈碾壓態勢。
弱智評估和民間Arena
挺有意思~
參考:阿里通義千問 Qwen3 系列模型正式發布,該模型有哪些技術點?
分析
思考預算的有效性
為驗證 Qwen3 能否通過增加思考預算來提升其智能水平,我們在數學、編程和 STEM 領域的四個基準測試中調整了分配的思考預算。Qwen3 表現出與分配的思考預算相關的可擴展且平滑的性能提升。

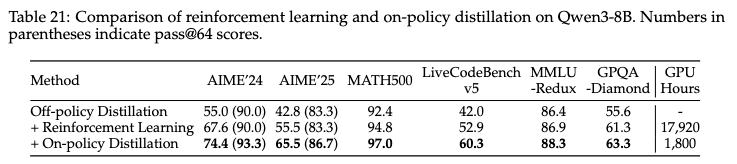
蒸餾的有效性和效率
- 蒸餾比強化學習顯著地實現了更好的性能,同時只需要大約 1/10 的 GPU 小時。
- 從教師 logits 進行蒸餾使學生模型能夠擴展其探索空間并增強其推理潛力,這一點通過蒸餾后 AIME’24 和 AIME’25 基準測試中 pass@64 分數的提高與初始檢查點相比得到證明。相比之下,強化學習并未導致 pass@64 分數的任何提高。這些觀察結果突出了利用更強的教師模型指導學生模型學習的優勢。
思考模式融合和通用強化學習的影響
為了評估在訓練后使用思考模式融合和通用強化學習(RL)的有效性,我們對 Qwen-32B 模型的各個階段進行評估。除了之前提到的數據集外,我們還引入了幾個內部基準來監控其他能力。這些基準包括:
- CounterFactQA:包含反事實問題,模型需要識別這些問題并非事實,并避免生成幻覺性答案。
- LengthCtrl:包括有長度要求的創意寫作任務;最終得分基于生成內容長度與目標長度的差異。
- ThinkFollow:涉及多輪對話,隨機插入/think 和/no think 標志,以測試模型能否根據用戶查詢正確切換思考模式。
- ToolUse:評估模型在單輪、多輪和多步工具調用過程中的穩定性。分數包括工具調用過程中意圖識別的準確性、格式準確性和參數準確性。
結論:
- 第三階段將非思考模式整合進模型,該模型在前兩個階段的訓練后已具備思考能力。ThinkFollow 基準測試分數為 88.7 表明,模型已初步發展了在不同模式間切換的能力,盡管偶爾仍會出錯。第三階段還增強了模型在思考模式下的泛化能力和指令跟隨能力,CounterFactQA 提升了 10.9 分,LengthCtrl 提升了 8.0 分。
- 第四階段進一步增強了模型在思考和非思考模式下的通用能力、指令跟隨能力和代理能力。值得注意的是,ThinkFollow 分數提升至 98.9,確保了模式的準確切換。
- 對于知識、STEM、數學和編程任務,思維模式融合和通用強化學習并沒有帶來顯著改進。相反,對于 AIME’24 和 LiveCodeBench 等具有挑戰性的任務,思維模式下的性能在這些兩個訓練階段后實際上會下降。我們推測這種退化是由于模型在更廣泛的通用任務上進行了訓練,這可能削弱了其處理復雜問題的專業能力。在 Qwen3 的開發過程中,我們選擇接受這種性能權衡,以增強模型的整體通用性。

展望
在不久的將來,我們的研究將集中在幾個關鍵領域。
- 我們將繼續通過使用質量和內容多樣性更高的數據來擴大預訓練規模。同時,我們將致力于改進模型架構和訓練方法,以實現有效壓縮、擴展到極長上下文等目標。
- 我們計劃增加強化學習的計算資源,特別關注從環境反饋中學習的基于智能體的 RL 系統。這將使我們能夠構建能夠處理需要推理時間擴展的復雜任務的智能體。














:自注意力機制)



---持續更新~~~~)

