集成學習通過組合多個弱學習器構建強學習器,常見框架包括Bagging(裝袋)、Boosting(提升)?和Stacking(堆疊)
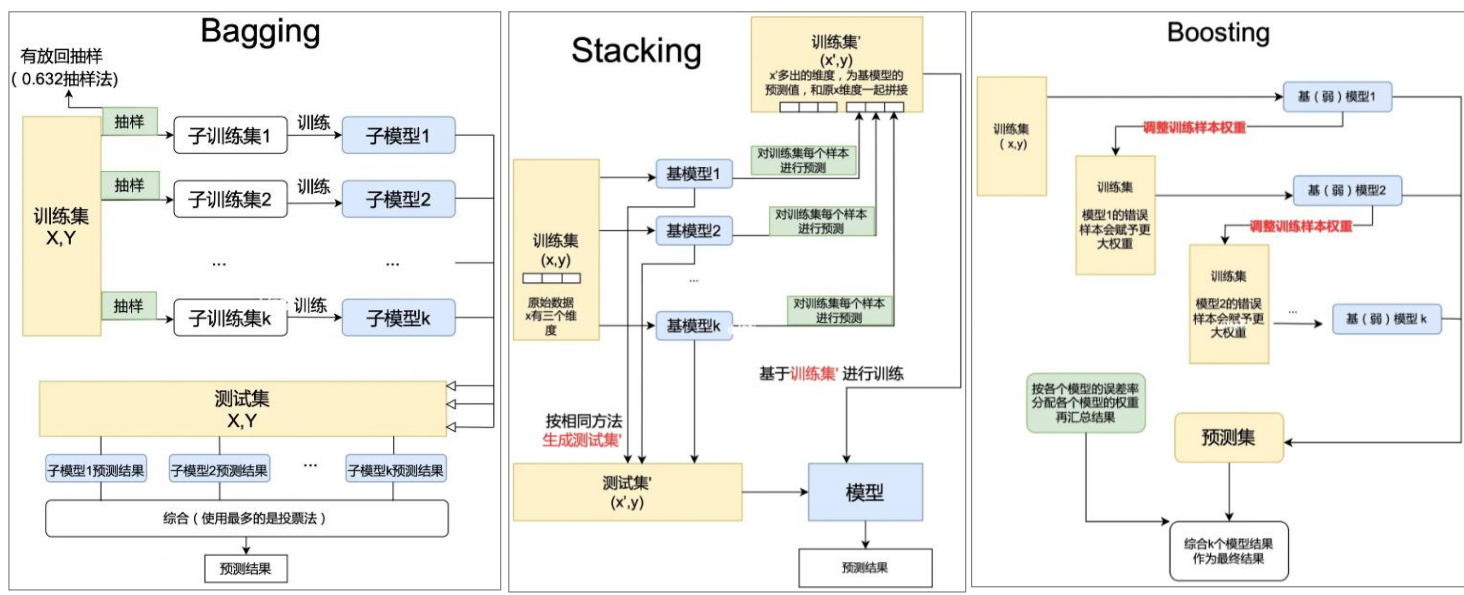
一、Bagging(自助裝袋法)
核心思想
- 從原始數據中通過有放回抽樣生成多個子集,每個子集訓練一個基學習器,最終通過投票(分類)或平均(回歸)?整合結果。
- 典型代表:隨機森林(Random Forest)。
關鍵特點
- 并行訓練:基學習器可獨立訓練,計算效率高。
- 降低方差:通過樣本擾動減少模型對特定數據的過擬合,提升泛化能力。
- 對噪聲不敏感:適合處理高方差模型(如決策樹)。
應用場景
- 分類與回歸任務(如房價預測、文本分類)。
二、Boosting(提升法)
核心思想
- 串行訓練基學習器,逐步優化前一個學習器的錯誤:給錯誤樣本更高權重,迫使后續學習器重點關注難分樣本,最終通過加權組合提升整體性能。
- 典型代表:AdaBoost、GBDT、XGBoost、LightGBM。
關鍵特點
- 串行訓練:基學習器依賴前序結果,計算復雜度較高。
- 降低偏差:通過迭代優化,逐步逼近真實模型,適合處理復雜任務。
- 對噪聲敏感:若基學習器過擬合,易放大噪聲影響。
應用場景
- 高精度預測任務(如金融風險評估、推薦系統)。
三、Stacking(堆疊法)
核心思想
- 通過兩層學習結構整合基學習器:
- 第一層用原始數據訓練多個基學習器,生成預測結果;
- 第二層以第一層的預測結果為輸入,訓練一個元學習器(如邏輯回歸),最終由元學習器輸出結果。
關鍵特點
- 層次化整合:可捕獲基學習器之間的互補信息,靈活性高。
- 需避免過擬合:第二層訓練數據為第一層的預測值,需注意數據量和正則化。
應用場景
- 競賽場景(如 Kaggle)或需要高精度集成的復雜任務。


)








)

 第10章擬合回歸模型10.9節思考題10.1 R語言解題)





