[Linux]虛擬地址到物理地址的轉化
@水墨不寫bug

文章目錄
- 一、再次認識地址空間
- 二、頁表
- 1、頁表的結構設計
- 2、頁表節省了空間,省在哪里?
- 3、頁表的物理實現
一、再次認識地址空間
OS和磁盤交互的內存基本單位是4KB,這4KB通常被稱為內存塊。OS對內存管理的粒度精確到塊——4KB為單位。而與之相對的,用戶對內存管理的粒度精確到1byte。在物理內存上,每一個塊都有自己的地址——邏輯塊地址(Logical Block Address)。
這里的塊,和文件數據存儲的塊的大小是相同的。OS管理的不是連續的物理內存,物理地址被劃分為4KB為單位的塊,OS通過管理這些塊,間接管理內存。想要管理好這些塊,需要先描述,再組織。在內核中,每一個塊通過一個結構體來管理:
struct page {unsigned long flags; // 頁狀態標志位(核心字段)union {struct { // 頁緩存/匿名頁的通用字段struct list_head lru; // LRU鏈表(用于頁回收)void *mapping; // 關聯的地址空間(文件或匿名)pgoff_t index; // 頁在映射中的偏移或交換槽索引unsigned long private;// 私有數據(用途因場景而異)};struct { // Slab分配器專用字段union {struct list_head slab_list;struct { // Partial頁鏈表(用于slab)struct page *next;int pages; // 當前slab的剩余頁數int pobjects; // 剩余對象數};};struct kmem_cache *slab_cache; // 所屬的slab緩存void *freelist; // 空閑對象鏈表union {void *s_mem; // slab第一個對象的地址unsigned long counters; // 引用計數和狀態};};// 其他聯合體分支(如設備頁、大頁等)};atomic_t _refcount; // 引用計數atomic_t _mapcount; // 頁表映射計數unsigned long compound_head; // 復合頁(大頁)的頭頁unsigned int compound_order; // 復合頁的階數(2^order頁)// ... 其他體系結構相關字段
};
一整個物理內存,有4GB,共1048576個4KB,通過結構體數組來管理:
struct page memory[1048576];//每一個page都有下標
struct page內部都有哪些字段?分別有什么作用?
(1)_refcount-引用計數,表面這個page被多少個進程共享。如果多個進程共享這個page,一旦出現修改數據,需要進行寫時拷貝。
(2)unsigned long flags-標記,32位標識,表面這個頁的屬性:是否有效,是否是臟頁,是否被占用,是否被鎖定。
(3)lru-將頁連接到最近最少使用(LRU) 鏈表,用于頁回收(如kswapd)。LRU_ACTIVE:活躍頁鏈表(近期被訪問過)。LRU_INACTIVE:非活躍頁鏈表(候選回收頁)。
內存中的4KB被稱為頁框。文件數據的4KB被稱為頁幀。
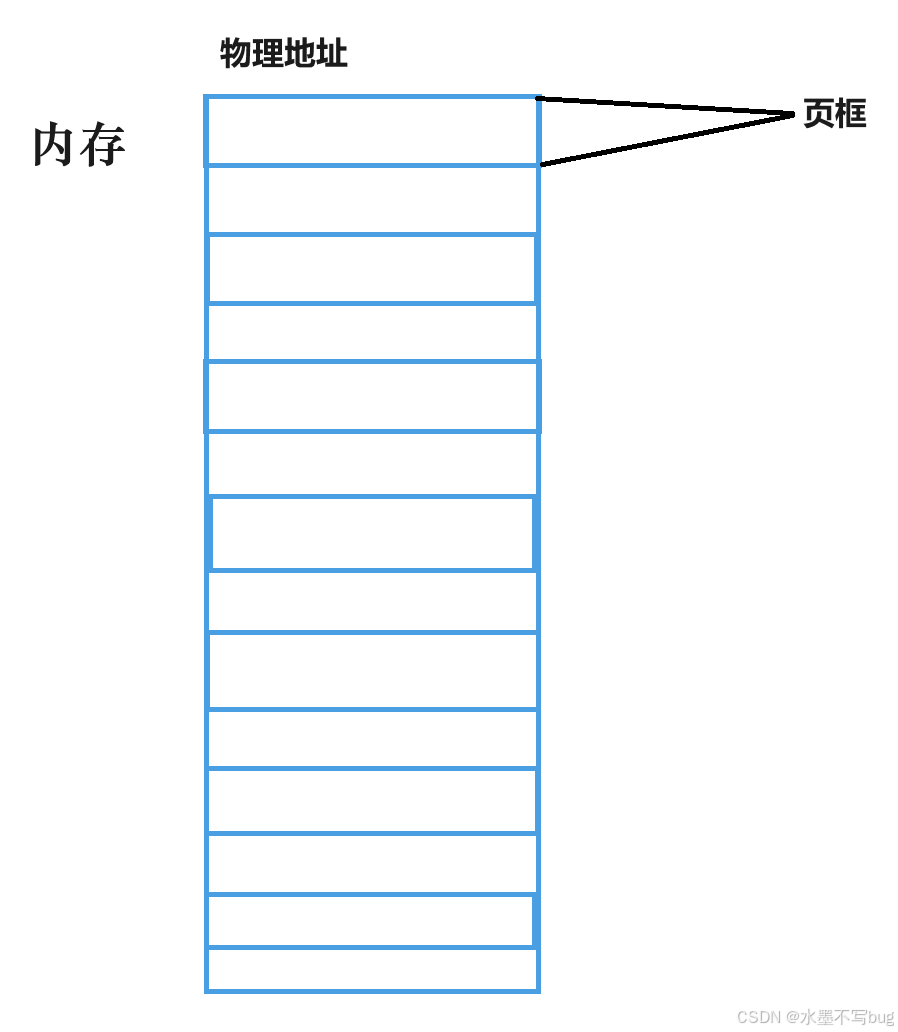
同時4KB的大小也方便了內存和磁盤進行存取以塊為單位的文件數據。內存和磁盤進行IO的基本單位理所當然就是4KB。
考慮下面的這幾個例子:
- (1)即使內存暫時只需要
1byte數據,OS也會直接把這1byte所在的4KB直接加載到內存。 - (2)父子進程對于只讀數據,是共享的;對于任意一方修改了一個全局變量,會發生
寫時拷貝。OS實際上不是僅僅拷貝了一個變量的大小,而是拷貝了這個變量所在的頁框(4KB)。 - (3)malloc進行申請空間的時候–malloc(10),底層不是只申請了10字節空間,而是4KB,多余的空間就交給了malloc函數進行維護。
- (4)
共享內存的大小最好就是4KB(4096bytes)的整數倍,如果申請4097bytes,則實際申請了8KB,但是我們用戶能夠使用的大小僅僅是4097bytes—這就造成了空間的浪費。(OS保守起見,多申請的空間不給我們使用) - (5)page可作為文件的內核級緩沖區,是通過字典樹來把page排序,使得存儲在不同的page內的文件可以方便的恢復。
根據局部性原理:這個時間點使用了這1byte,在后續時間點很有可能會使用這1byte附近的數據。 對一個全局變量修改了,很有可能以后要對附近的數據進行修改。所以拷貝4KB是合理的。申請內存一次性申請4KB也是用到了池化思想,提高了效率
二、頁表
1、頁表的結構設計
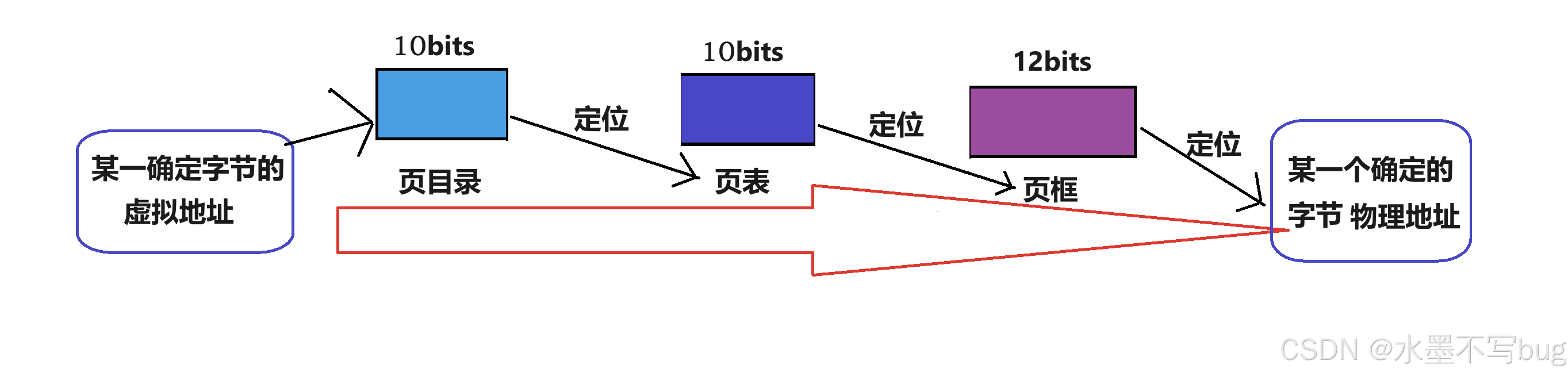
頁表是一個把進程虛擬地址轉化為物理地址的結構。在x86體系下,物理地址有4GB(2的32次方),如果按照通常的一對一的映射,一個4字節的虛擬地址映射一個4字節的物理地址,一共需要的內存比實際擁有的內存還要多,這十分不合理。所以頁表的映射不是簡單的一對一映射。
在x86體系結構下,一個虛擬地址有32位,這個虛擬地址被分為 10 + 10 + 12:
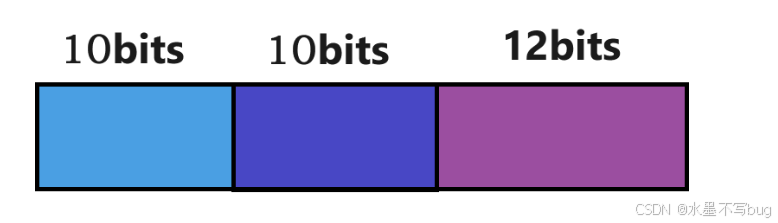
前10位 用于在頁目錄內部索引,中間10位用于在頁表中索引,后12位用于在一個頁框內偏移:
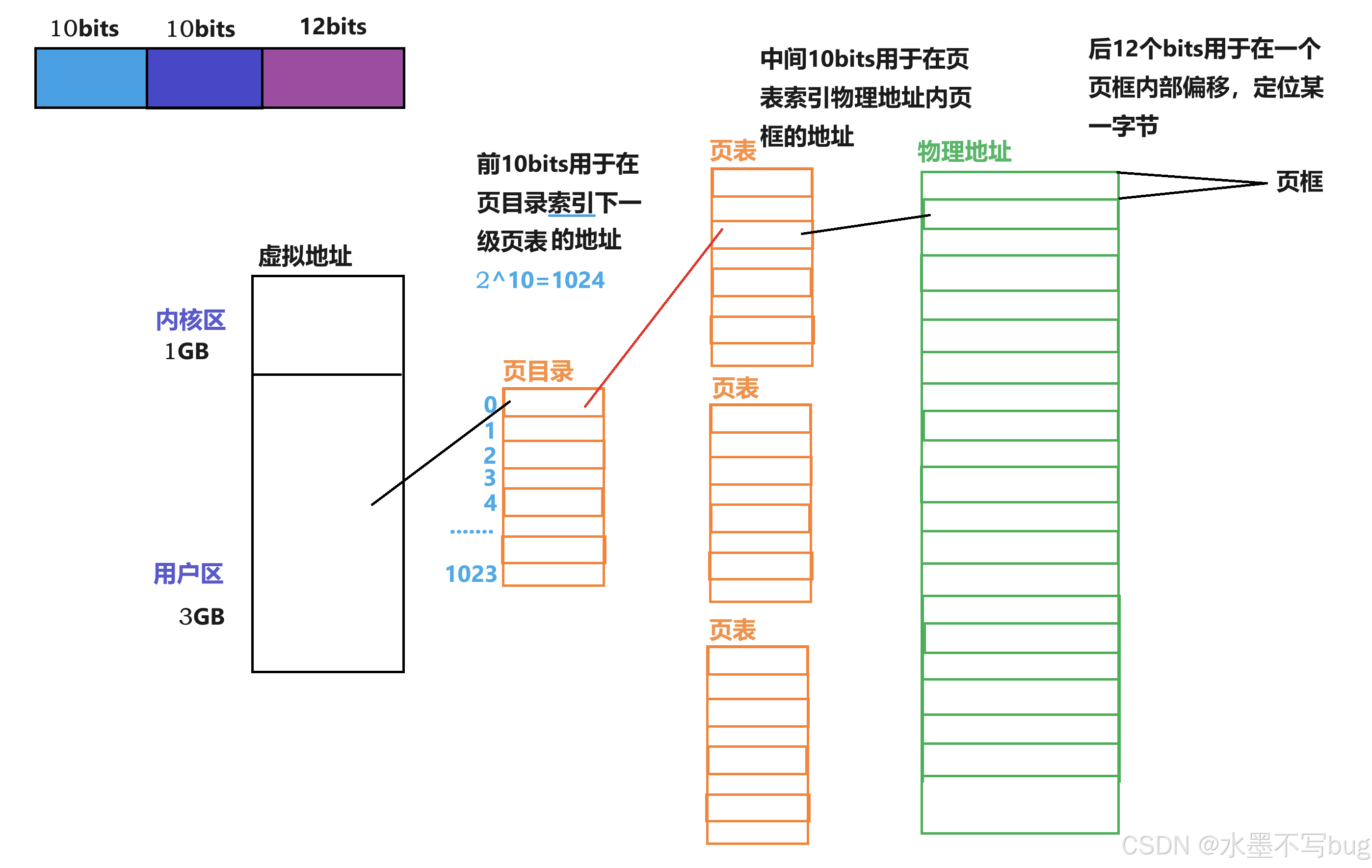
這樣,我任何一個虛擬地址,都可以通過頁表的機制,找到對應的物理地址!
在C/C++中,為什么只要獲取一個變量的首地址就能夠成功訪問這個變量?
因為這個變量還有對應的類型。
訪問一個變量,需要首先獲取虛擬地址,通過上述的轉換機制,把虛擬地址1字節轉換到物理地址具體某字節的地址。此外,變量類型在語言層面就告訴了編譯器,編譯器會編譯生成對應的匯編語句:
考慮下面這些語句:
int x = 1234;
int y = *(&x); // 通過首字節地址讀取值//對應的匯編語句可能就是
mov eax, [0x1000] ; 從地址 0x1000 開始讀取 4 字節到寄存器 eax
mov [0x2000], eax ; 將 eax 的值存儲到地址 0x2000
mov eax, [0x1000]:處理器根據地址 0x1000 開始讀取 4 字節(因為 eax 是 4 字節寄存器)。匯編層面會根據指令和寄存器的大小,自動決定讀取的數據寬度。
2、頁表節省了空間,省在哪里?
如果沒有頁表,直接一個物理地址對應一個虛擬地址這樣映射,頁表需要占用的空間就是(以x86為例,一個地址占用的空間為4bytes)(4+4)*4GB = 32GB,需要存儲頁表的空間就已經超過的整機的物理空間大小,顯然不合理。
頁表實際的大小為 頁目錄(4KB) + 所有頁表(4KB * 1024):
4KB+4MB=4100KB = 4.00390625MB
通過上面的計算,實際上就可以通過近乎4MB的空間大小來實現整個頁表結構。于是就把原來的32GB壓縮到了4MB。
3、頁表的物理實現
實際上CPU內部內置了MMU。MMU(內存管理單元,Memory Management Unit) 是計算機硬件中的一個核心組件,通常集成在 CPU 中,主要負責管理內存訪問和地址轉換。
上述的頁表的轉換流程就是MMU的工作流程。
CPU引入MMU后,讀取指令、數據需要訪問兩次內存:首先通過PC指針讀取下一條指針的虛擬地址,虛擬地址需要通過查詢頁表得到物理地址,然后訪問該物理地址讀取指令、數據。為了減少因為頻繁查頁表導致的CPU性能下降,MMU引入了TLB,TLB(Translation Lookaside Buffer)可翻譯為“地址轉換后援緩沖器”。TLB就是頁表的Cache,其中存儲了當前最可能(最近)被訪問到的頁表項,其內容是部分頁表項的一個副本。只有在TLB無法完成地址翻譯任務時,才會到內存中查詢頁表,這樣就減少了頁表查詢導致的處理器性能下降。
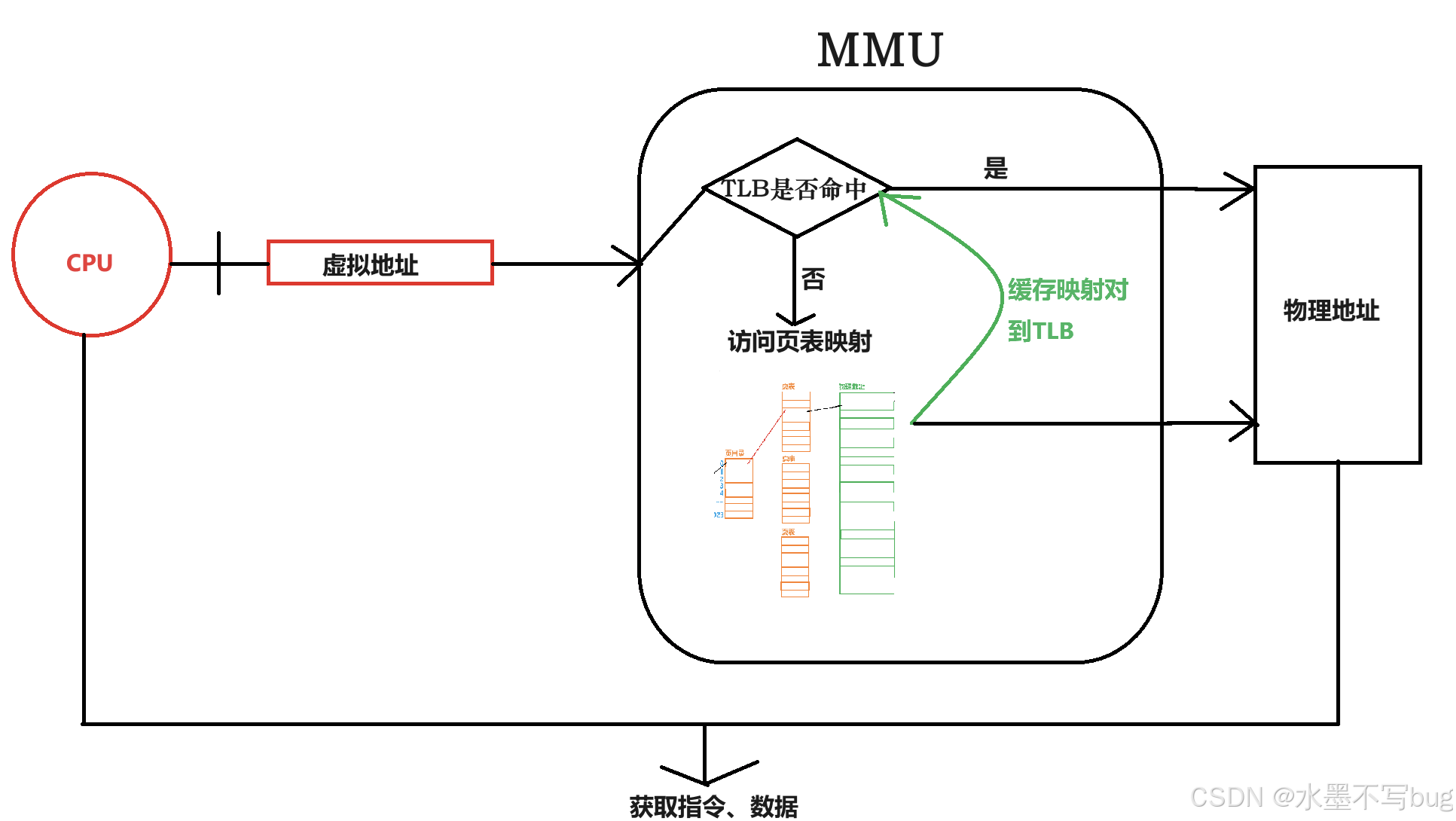
對整體過程而言: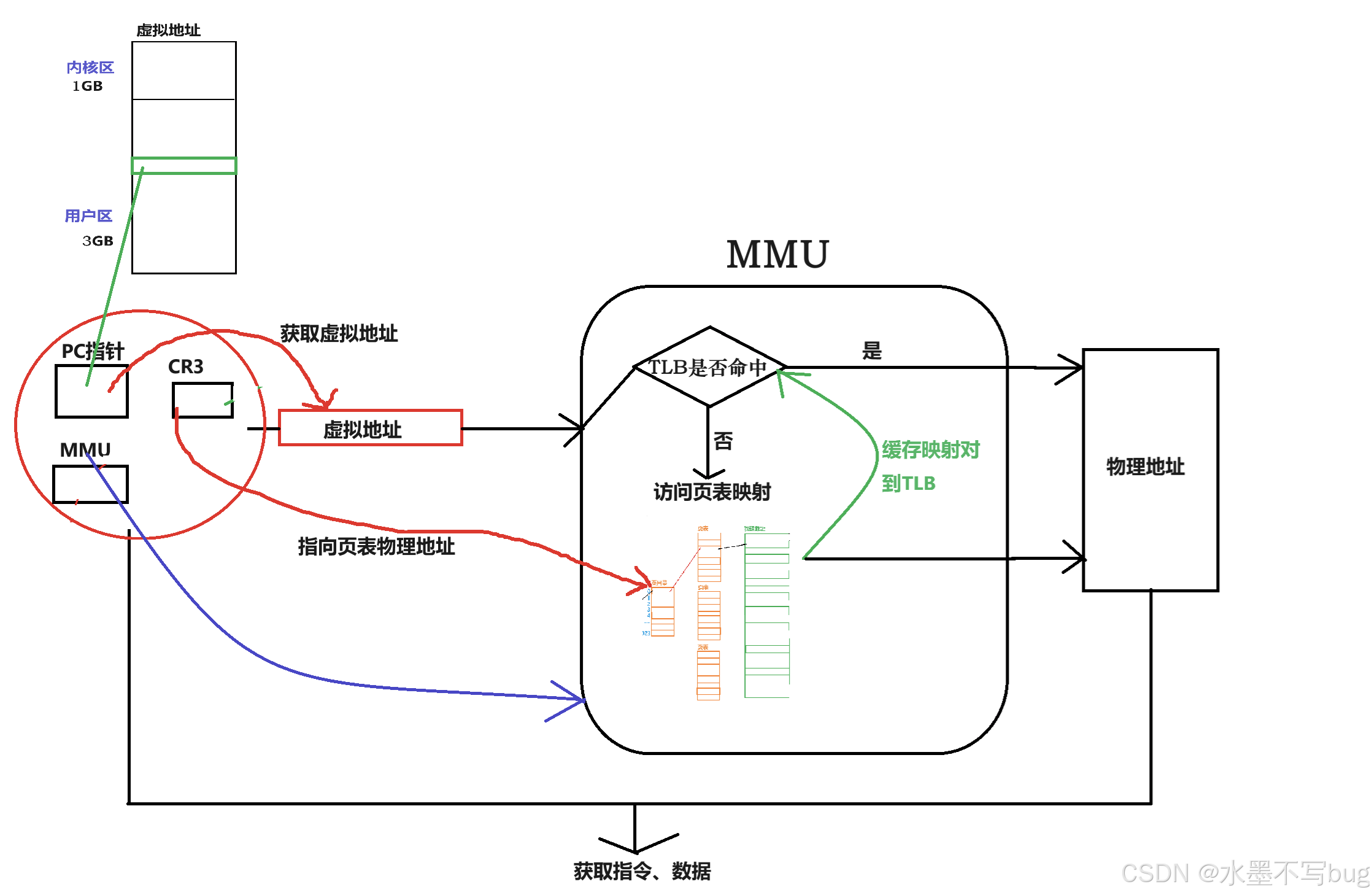
虛擬到物理地址轉換的詳細流程:
CPU通過PC指針獲取下條指令的虛擬地址,訪問MMU查詢TLB里面是否已經緩存了此次虛擬到物理的映射?如果是,則轉換結束;如果否,則需要訪問頁表。通過CR3寄存器獲取頁表物理地址,通過分級映射查找獲取物理地址,并同時把此次訪問的虛擬到物理的映射緩存到TLB,方便后續的再次映射(如果是循環邏輯,則后續訪問都不需要再次查頁表,十分高效)。
完~

核心架構解析與實用命令大全)





)






)


)


