作為一家位于英國的前沿生物科技公司,Extracellular 專注于細胞培養產品的規模化制造,致力于通過優化生物工藝流程,加速細胞類產品從實驗室走向大規模生產的落地。為了實現這一目標,他們需要一個穩定、高效、可擴展的數據平臺,能夠支撐實時監控、過程優化和合規留存等關鍵需求。本文將分享他們在搭建數據平臺過程中積累的經驗與實踐。
生物工藝的數據難題:從設備到決策的“最后一公里”
在細胞培養過程中,生物反應器會源源不斷地產生大量時序數據,例如溫度、pH 值、溶解氧、營養物濃度等。這些數據不僅要實時采集、展示,還要用于后續的過程優化與合規審計。
Extracellular 面臨的關鍵挑戰包括:
-
支持實驗員和科學家使用實時儀表板進行過程分析與監控
-
通過 MQTT 協議,實現與設備的高頻數據采集
-
快速訪問歷史數據,驅動機器學習模型和工藝優化
-
從實驗室走向工廠,系統需具備良好的橫向擴展能力
-
支持本地部署和云端運行,避免廠商鎖定
為什么最終選擇 TDengine?對比評測給出了答案
在選型過程中,Extracellular 對比評估了市面上幾款主流時序數據庫,重點考察了以下幾個工業場景下的核心指標:
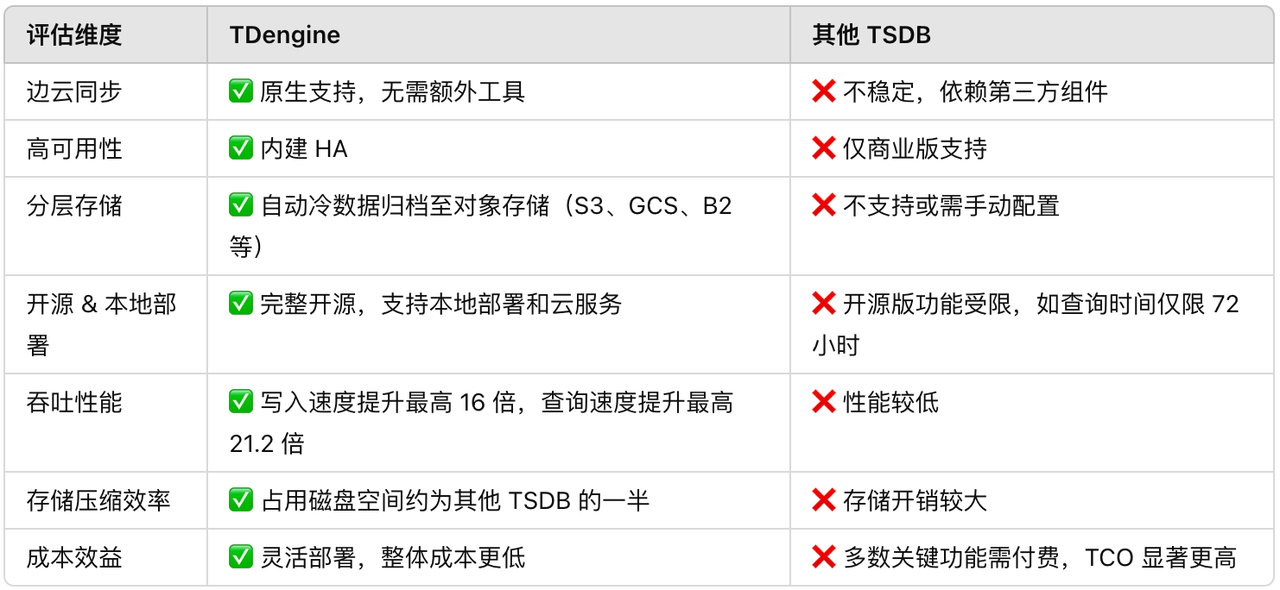
對 Extracellular 來說,邊云同步能力是影響調研決策的關鍵因素。其他時序數據庫需要借助第三方工具才能實現邊緣端與云端的數據同步,相比之下,TDengine 原生支持、部署簡單、運行穩定,極大降低了工程復雜度。
此外,在開源能力上,TDengine 提供了集群開源,真正可用于工業生產環境。而其他時序數據庫的開源版本常常存在功能缺失,比如不支持集群部署、查詢歷史受限等,根本無法滿足長期分析和數據沉淀的需求。
“TDengine 對我們來說是一次顛覆性的選擇。它針對工業場景所提供的邊云同步、高可用、流式處理等功能遠超預期,性能表現同樣出色,無論是在云端還是邊緣側運行都非常穩健。而 TDengine 團隊的技術支持也非常到位,從部署開始就一路護航,幫助我們順利落地。” —— Alex Tolenaar,Extracellular 技術專家
天生為工業場景而生:TDengine 的內建能力
作為工業級生物技術公司,Extracellular 對數據平臺提出了三項“硬性要求”:
? 邊云同步:保障各站點數據實時同步、不間斷運行
? 高可用性(HA):確保系統穩定運行,數據永不丟失
? 分層存儲:自動歸檔歷史數據至云端對象存儲,降低成本
而這些功能,TDengine 原生支持、即裝即用,無需像其他時序數據庫一樣東拼西湊額外組件。
部署路線圖:從云到邊,再到高可用
Extracellular 的 TDengine 部署路徑分為三個階段,兼顧集中管理、邊緣智能與系統可靠性:
第 1 階段:云端部署,統一管理
-
先部署 TDengine Cloud,將實驗室與生產基地數據統一收集至云端
-
實現各站點與云端的數據同步,便于統一監控與管理
-
通過 Grafana 接入實時儀表板與歷史數據分析
第 2 階段:邊緣部署,實時決策
-
在實驗室和生產現場本地部署 TDengine,實現就地采集與計算
-
即使斷網,也能本地持續運行,保障系統穩定性
-
本地數據緩沖后同步上云,實現低延遲的邊緣分析能力
第 3 階段:高可用部署,保障可靠性
-
部署 TDengine 的 HA 模式,防止單點故障導致的數據丟失
-
多節點自動復制,提升系統容錯能力
-
歷史數據自動分層存儲至對象云存儲(如 S3、GCS、B2 等),長期保存更省錢
結語:從細胞工廠到智能制造,數據基礎決定未來
選擇 TDengine 后,Extracellular 搭建起了一套真正適用于工業場景的時序數據平臺,實現了:
-
邊緣與云端無縫協作,免除第三方組件依賴
-
實時與歷史數據并存,支撐工藝優化與決策分析
-
自主掌控數據資產,無需被云廠商“鎖死”
-
節省高昂許可費用,顯著降低整體成本
未來,Extracellular 計劃進一步將 TDengine 應用于數據科學、AI 驅動的工藝優化及多站點智能協同,助力細胞制造真正邁入智能化時代。在生物制造這條高速發展的賽道上,TDengine 正逐漸成為 Extracellular 的“數字引擎”,為其未來發展持續賦能。







通信(使用示例為SD2068))

中,無法直接使用 continue 或 break 語句的解決辦法)
Spring 6.x 響應式編程模型)








