Normalization無非就是這樣一個操作:
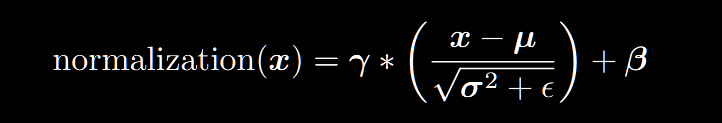
其中x是輸入數據,維度為(B,T,C),其中B是batchsize,T是序列長度,C是embedding維度;括號內是標準化操作,γ和β是仿射變換參數。
BN和LN的不同,僅僅在于均值和方差的計算方式而已,下面給出計算公式:
1.Batch Normalization
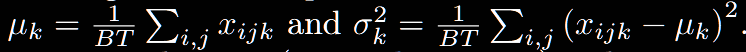
2.Layer Normalization
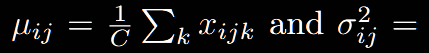
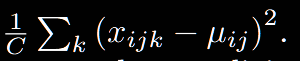
可以發現,BN是對前2個維度進行統計計算,LN是對最后一個維度進行統計計算。公式很簡單,怎么理解呢?
先看LN。可以理解為:對于每個樣本(batch)中的每個token,都分別統計其自身所包含的所有特征維度,作為歸一化的依據。在大語言模型中,輸入序列的長度通常是不固定的,因此對每個 token 單獨進行歸一化,是一種更合理、靈活的方式。
再來看 BN,它更常用于固定長度的序列或圖像任務中。以等長序列為例,BN 的歸一化是對所有 batch 中相同位置(如第一個 token、第二個 token 等)上的特征維度進行統計。因此,它統計的是同一維度在不同樣本、不同 token 上的分布。由于序列長度一致,數據結構規整,就不需要像 LN 那樣對每個 token 單獨歸一化。
參考鏈接
https://arxiv.org/abs/2503.10622
LockRelease常規鎖釋放流程分析)









)


)

)
Day16!!!C/C++)


