目錄
JVM內部的優化邏輯
JVM的執行引擎
解釋執行器
即時編譯器
JVM采用哪種方式?
即時編譯器類型
JVM的分層編譯5大級別:
分層編譯級別:
熱點代碼:
如何找到熱點代碼?
java兩大計數器:
OSR 編譯(不重要,別糾結)
Code Cache
Code Cache的優化
Code Cache的查看
JDK9中的分段代碼緩存:
AOT和Graal VM
Graal VM
重新認知JVM
運行時優化
方法內聯
為什么會出現方法內聯呢?
內聯條件
逃逸分析
什么是“對象逃逸”?
什么是逃逸分析?
基于逃逸分析的優化
標量替換
棧上分配案例:
同步鎖消除
什么條件下會觸發逃逸分析?
TLAB(Thread Local Allocation Buffer)
TLAB分配的對象可以共享嗎?
JVM內部的優化邏輯
JVM的執行引擎
javac編譯器將Person.java源碼文件編譯成class文件[前期編譯],交給JVM運行,因為JVM只能識別class字節碼文件。同時在不同的操作系統上安裝對應版本的JDK,里面包含了各自屏蔽操作系統底層細節的JVM,這樣使得同一份class文件就能運行在不同的操作系統平臺之上。這也是Write Once,Run Anywhere的原因所在。
最終JVM需要把字節碼指令轉換為機器碼,可以理解為是0101這樣的機器語言,這樣才能運行在不同的機器上,那么由字節碼轉變為機器碼是誰來做的呢?即誰來執行這些字節碼指令的呢?這就是執行引擎
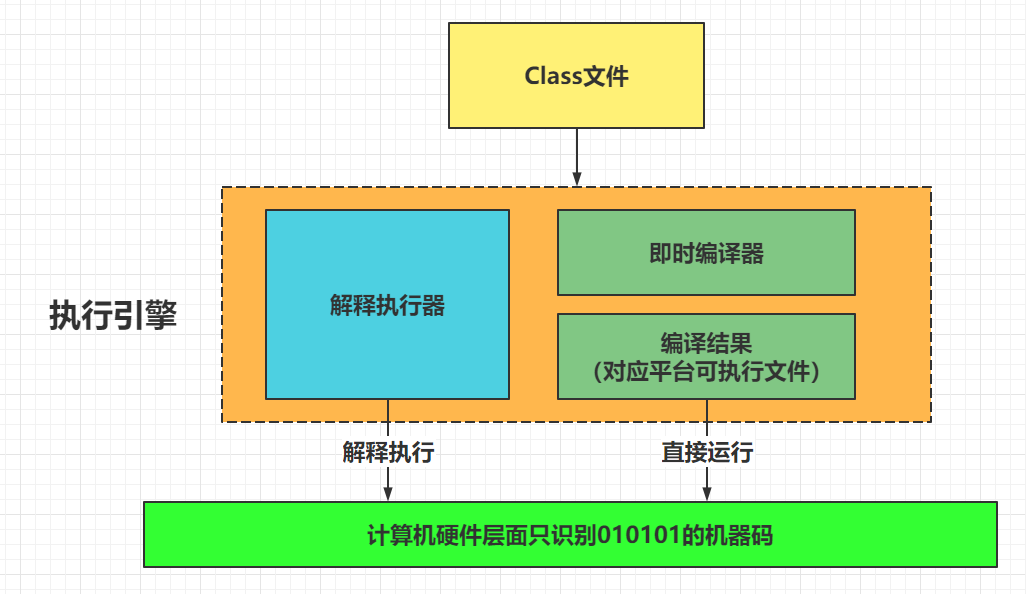
解釋執行器
Interpreter解釋器逐條把字節碼翻譯成機器碼并執行,跨平臺的保證。
剛開始執行引擎只采用了解釋執行的,但是后來發現某些方法或者代碼塊被調用執行的特別頻繁時,就會把這些代碼認定為“熱點代碼”。
即時編譯器
Just-In-Time compliation(JIT),即時編譯器先將字節碼編譯成對應平臺的可執行文件,運行速度快。即時編譯器會把這些熱點代碼編譯成與本地平臺關聯的機器碼,并且進行各層次的優化,保存到內存中。
JVM采用哪種方式?
JVM采取的是混合模式,也就是解釋+編譯的方式,對于大部分不常用的代碼,不需要浪費時間將其編譯成機器碼,只需要用到的時候再以解釋的方式運行;對于小部分的熱點代碼,可以采取編譯的方式,追求更高的運行效率。
即時編譯器類型
(1)HotSpot虛擬機里面內置了兩個JIT:C1和C2
C1也稱為Client Compiler,適用于執行時間短或者對啟動性能有要求的程序
C2也稱為Server Compiler,適用于執行時間長或者對峰值性能有要求的程序
(2)Java7開始,HotSpot會使用分層編譯的方式
分層編譯也就是會結合C1的啟動性能優勢和C2的峰值性能優勢,熱點方法會先被C1編譯,然后熱點方法中的熱點會被C2再次編譯
-XX:+TieredCompilation開啟參數
JVM的分層編譯5大級別:
0.解釋執行
1.簡單的C1編譯:僅僅使用我們的C1做一些簡單的優化,不會開啟Profiling
2.受限的C1編譯代碼:只會執行我們的方法調用次數以及循環的回邊次數(多次執行的循環體)Profiling的C1編譯
3.完全C1編譯代碼:我們Profiling里面所有的代碼。也會被C1執行
4.C2編譯代碼:這個才是優化的級別。
級別越高,我們的應用啟動越慢,優化下來開銷會越高,同樣的,我們的峰值性能也會越高
通常C2 代碼的執行效率要比 C1 代碼的高出 30% 以上
分層編譯級別:
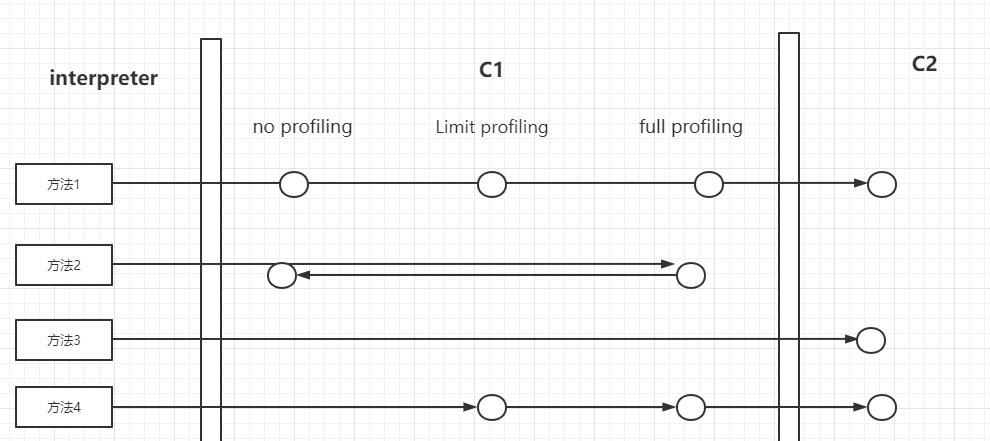
Java 虛擬機內置了 profiling。
profiling 是指在程序執行過程中,收集能夠反映程序執行狀態的數據。這里所收集的數據我們稱之為程序的 profile。
如果方法的字節碼數目比較少(如 getter/setter),而且 3 層的 profiling 沒有可收集的數據。
那么,Java 虛擬機斷定該方法對于 C1 代碼和 C2 代碼的執行效率相同。
在這種情況下,Java 虛擬機會在 3 層編譯之后,直接選擇用 1 層的 C1 編譯。(簡單的C1編譯)
由于這是一個終止狀態,因此 Java 虛擬機不會繼續用 4 層的 C2 編譯。
在 C1 忙碌的情況下,Java 虛擬機在解釋執行過程中對程序進行 profiling,而后直接由 4 層的 C2 編譯。
在 C2 忙碌的情況下,方法會被 2 層的 C1 編譯,然后再被 3 層的 C1 編譯,以減少方法在 3 層的執行時間。
Java 8 默認開啟了分層編譯。-XX:+TieredCompilation開啟參數
不管是開啟還是關閉分層編譯,原本用來選擇即時編譯器的參數 -client 和 -server 都是無效的。當關閉分層編譯的情況下,Java 虛擬機將直接采用 C2。
如果你希望只是用 C1,那么你可以在打開分層編譯的情況下使用參數 -XX:TieredStopAtLevel=1。在這種情況下,Java 虛擬機會在解釋執行之后直接由 1 層的 C1 進行編譯。
熱點代碼:
在運行過程中會被即時編譯的“熱點代碼” 有兩類,即:
-
被多次調用的方法
-
被多次執行的循環體
對于第一種,編譯器會將整個方法作為編譯對象,這也是標準的JIT 編譯方式。對于第二種是由循環體出發的,但是編譯器依然會以整個方法(而不是單獨的循環體)作為編譯對象,因為發生在方法執行過程中,稱為棧上替換(On Stack Replacement,簡稱為 OSR 編譯,即方法棧幀還在棧上,方法就被替換了)。
如何找到熱點代碼?
判斷一段代碼是否是熱點代碼,是不是需要觸發即時編譯,這樣的行為稱為熱點探測(Hot Spot Detection),探測算法有兩種,分別如下:
-
基于采樣的熱點探測(Sample Based Hot Spot Detection):虛擬機會周期的對各個線程棧頂進行檢查,如果某些方法經常出現在棧頂,這個方法就是“熱點方法”。好處是實現簡單、高效,很容易獲取方法調用關系。缺點是很難確認方法的 reduce,容易受到線程阻塞或其他外因擾亂。
-
基于計數器的熱點探測(Counter Based Hot Spot Detection):為每個方法(甚至是代碼塊)建立計數器,執行次數超過閾值就認為是“熱點方法”。優點是統計結果精確嚴謹。缺點是實現麻煩,不能直接獲取方法的調用關系。
HotSpot 使用的是第二種——基于計數器的熱點探測,并且有兩類計數器:方法調用計數器(Invocation Counter )和回邊計數器(Back Edge Counter )。
這兩個計數器都有一個確定的閾值,超過后便會觸發 JIT 編譯。
java兩大計數器:
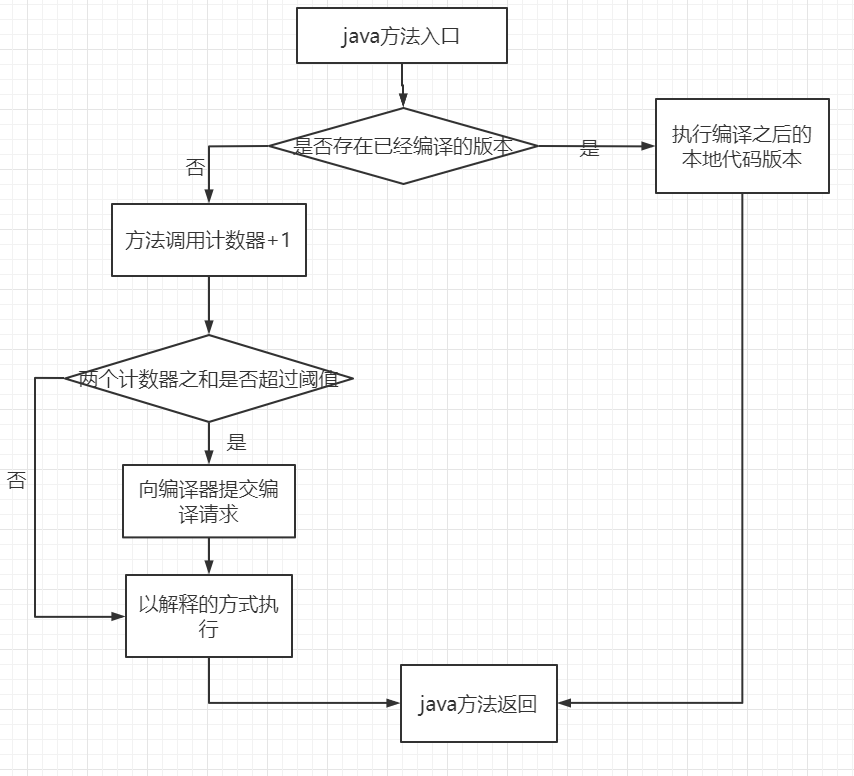
(1)首先是方法調用計數器 。Client 模式下默認閾值是 1500 次,在 Server 模式下是 10000次,這個閾值可以通過 -XX:CompileThreadhold 來人為設定。如果不做任何設置,方法調用計數器統計的并不是方法被調用的絕對次數,而是一個相對的執行頻率,即一段時間之內的方法被調用的次數。當超過一定的時間限度,如果方法的調用次數仍然不足以讓它提交給即時編譯器編譯,那么這個方法的調用計數器就會被減少一半,這個過程稱為方法調用計數器熱度的衰減(Counter Decay),而這段時間就成為此方法的統計的半衰周期( Counter Half Life Time)。進行熱度衰減的動作是在虛擬機進行垃圾收集時順便進行的,可以使用虛擬機參數 -XX:CounterHalfLifeTime 參數設置半衰周期的時間,單位是秒。整個 JIT 編譯的交互過程如下圖。
(2)第二個回邊計數器 ,作用是統計一個方法中循環體代碼執行的次數,在字節碼中遇到控制流向后跳轉的指令稱為“回邊”( Back Edge )。顯然,建立回邊計數器統計的目的就是為了觸發 OSR 編譯。
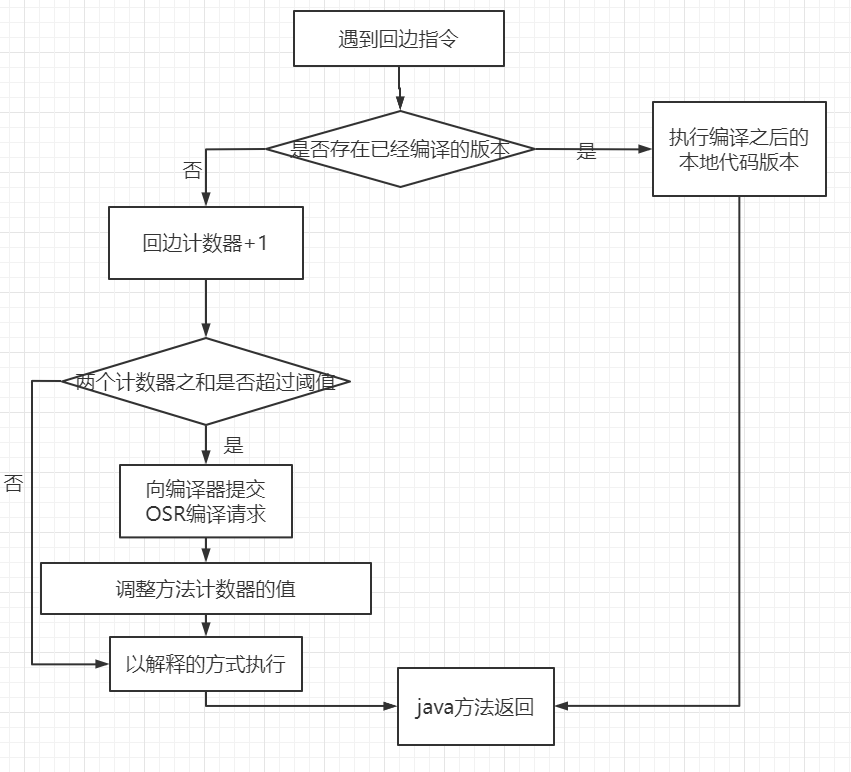
關于這個計數器的閾值, HotSpot 提供了 -XX:BackEdgeThreshold 供用戶設置,但是當前的虛擬機實際上使用了 -XX:OnStackReplacePercentage 來簡介調整閾值,計算公式如下:
-
在 Client 模式下, 公式為 方法調用計數器閾值(CompileThreshold)X OSR 比率(OnStackReplacePercentage)/ 100 。其中 OSR 比率默認為 933,那么,回邊計數器的閾值為 13995。
-
在 Server 模式下,公式為 方法調用計數器閾值(Compile Threashold)X (OSR 比率(OnStackReplacePercentage) - 解釋器監控比率(InterpreterProfilePercent))/100。 其中 onStackReplacePercentage 默認值為 140,InterpreterProfilePercentage 默認值為 33,如果都取默認值,那么 Server 模式虛擬機回邊計數器閾值為 10700 。
與方法計數器不同,回邊計數器沒有計數熱度衰減的過程,因此這個計數器統計的就是該方法循環執行的絕對次數。當計數器溢出的時候,它還會把方法計數器的值也調整到溢出狀態,這樣下次再進入該方法的時候就會執行標準編譯過程。
可以看到,決定一個方法是否為熱點代碼的因素有兩個:方法的調用次數、循環回邊的執行次數。即時編譯便是根據這兩個計數器的和來觸發的。為什么 Java 虛擬機需要維護兩個不同的計數器呢?
OSR 編譯(不重要,別糾結)
實際上,除了以方法為單位的即時編譯之外,Java 虛擬機還存在著另一種以循環為單位的即時編譯,叫做 On-Stack-Replacement(OSR)編譯。循環回邊計數器便是用來觸發這種類型的編譯的。
OSR 實際上是一種技術,它指的是在程序執行過程中,動態地替換掉 Java 方法棧楨,從而使得程序能夠在非方法入口處進行解釋執行和編譯后的代碼之間的切換。也就是說,我只要遇到回邊指令,我就可以觸發執行切換。
在不啟用分層編譯的情況下,觸發 OSR 編譯的閾值是由參數 -XX:CompileThreshold 指定的閾值的倍數。
該倍數的計算方法為:
(OnStackReplacePercentage - InterpreterProfilePercentage)/100
其中 -XX:InterpreterProfilePercentage 的默認值為 33,當使用 C1 時 -XX:OnStackReplacePercentage 為 933,當使用 C2 時為 140。
也就是說,默認情況下,C1 的 OSR 編譯的閾值為 13500,而 C2 的為 10700。
在啟用分層編譯的情況下,觸發 OSR 編譯的閾值則是由參數 -XX:TierXBackEdgeThreshold 指定的閾值乘以系數。
OSR 編譯在正常的應用程序中并不多見。它只在基準測試時比較常見,因此并不需要過多了解。
那么這些即時編譯器編譯后的代碼放哪呢?
Code Cache
JVM生成的native code存放的內存空間稱之為Code Cache;JIT編譯、JNI等都會編譯代碼到native code,其中JIT生成的native code占用了Code Cache的絕大部分空間,他是屬于非堆內存的。
簡而言之,JVM Code Cache (代碼緩存)是JVM存儲編譯成本機代碼的字節碼的區域。我們將可執行本機代碼的每個塊稱為 nmethod 。 nmethod 可能是一個完整的或內聯的Java方法。
即時( JIT )編譯器是代碼緩存區的最大消費者。這就是為什么一些開發人員將此內存稱為JIT代碼緩存。
Code Cache的優化
代碼緩存的大小是固定的。一旦它滿了,JVM就不會編譯任何額外的代碼,因為JIT編譯器現在處于關閉狀態。此外,我們將收到“ CodeCache is full… The compiler has been disabled ”警告消息。因此,我們的應用程序的性能最終會下降。為了避免這種情況,我們可以使用以下大小選項調整代碼緩存:
-
InitialCodeCacheSize –初始代碼緩存大小,默認為160K
-
ReservedCodeCacheSize –默認最大大小為48MB
-
CodeCacheExpansionSize –代碼緩存的擴展大小,32KB或64KB
增加ReservedCodeCacheSize可能是一個解決方案,但這通常只是一個臨時解決辦法。
幸運的是,JVM提供了一個 UseCodeCache 刷新選項來控制代碼緩存區域的刷新。其默認值為false。當我們啟用它時,它會在滿足以下條件時釋放占用的區域:
-
代碼緩存已滿;如果該區域的大小超過某個閾值,則會刷新該區域
-
自上次清理以來已過了特定的時間間隔
-
預編譯代碼不夠熱。對于每個編譯的方法,JVM都會跟蹤一個特殊的熱度計數器。如果此計數器的值小于計算的閾值,JVM將釋放這段預編譯代碼
Code Cache的查看
為了監控Code Cache(代碼緩存)的使用情況,我們需要跟蹤當前正在使用的內存的大小。
要獲取有關代碼緩存使用情況的信息,我們可以指定 –XX:+PrintCodeCache JVM選項。運行應用程序后,我們將看到類似的輸出:
或者直接設置 -XX:ReservedCodeCacheSize=3000k,然后重啟

讓我們看看這些值的含義:
-
輸出中的大小顯示內存的最大大小,與 ReservedCodeCacheSize 相同
-
used是當前正在使用的內存的實際大小 -
max_used是已使用的最大尺寸 -
free是尚未占用的剩余內存
JDK9中的分段代碼緩存:
從Java9開始,JVM將代碼緩存分為三個不同的段,每個段都包含特定類型的編譯代碼。更具體地說,有三個部分:
-XX:nonNMethoddeHeapSize
-XX:ProfiledCodeHeapSize
-XX:nonprofiedCodeHeapSize
這種新結構以不同的方式處理各種類型的編譯代碼,從而提高了整體性能。
例如,將短命編譯代碼與長壽命代碼分離可以提高方法清理器的性能——主要是因為它需要掃描更小的內存區域。
AOT和Graal VM
在Java9中,引入了AOT(Ahead-Of-Time)編譯器
即時編譯器是在程序運行過程中,將字節碼翻譯成機器碼。而AOT是在程序運行之前,將字節碼轉換為機器碼
優勢:這樣不需要在運行過程中消耗計算機資源來進行即時編譯
劣勢:AOT 編譯無法得知程序運行時的信息,因此也無法進行基于類層次分析的完全虛方法內聯,或者基于程序 profile 的投機性優化(并非硬性限制,我們可以通過限制運行范圍,或者利用上一次運行的程序 profile 來繞開這兩個限制)
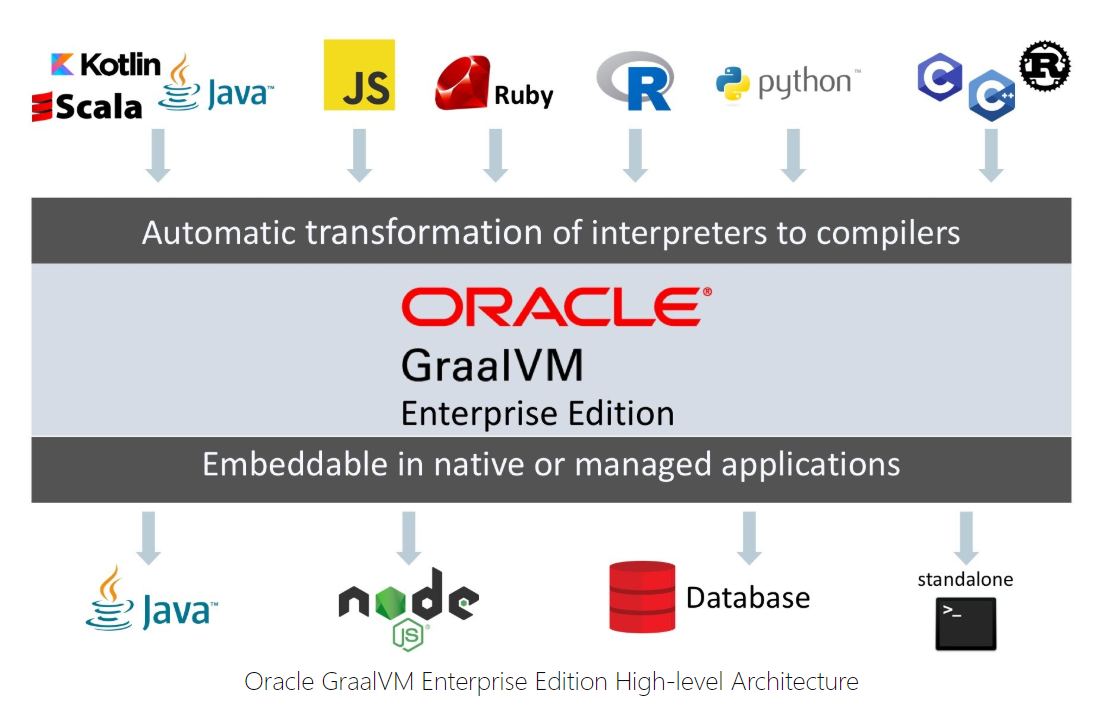
Graal VM
官網: GraalVM | OracleGraalVM core features include:
GraalVM Native Image, available as an early access feature –– allows scripted applications to be compiled ahead of time into a native machine-code binary
GraalVM Compiler –– generates compiled code to run applications on a JVM, standalone, or embedded in another system
Polyglot Capabilities –– supports Java, Scala, Kotlin, JavaScript, and Node.js
Language Implementation Framework –– enables implementing any language for the GraalVM environment
LLVM Runtime–– permits native code to run in a managed environment in GraalVM Enterprise
在Java10中,新的JIT編譯器Graal被引入
它是一個以Java為主要編程語言,面向字節碼的編譯器。跟C++實現的C1和C2相比,模塊化更加明顯,也更加容易維護。
Graal既可以作為動態編譯器,在運行時編譯熱點方法;也可以作為靜態編譯器,實現AOT編譯。
除此之外,它還移除了編程語言之間的邊界,并且支持通過即時編譯技術,將混雜了不同的編程語言的代碼編譯到同一段二進制碼之中,從而實現不同語言之間的無縫切換。
重新認知JVM
JVM Architecture: Getting Started with the G1 Garbage Collector
運行時優化
方法內聯
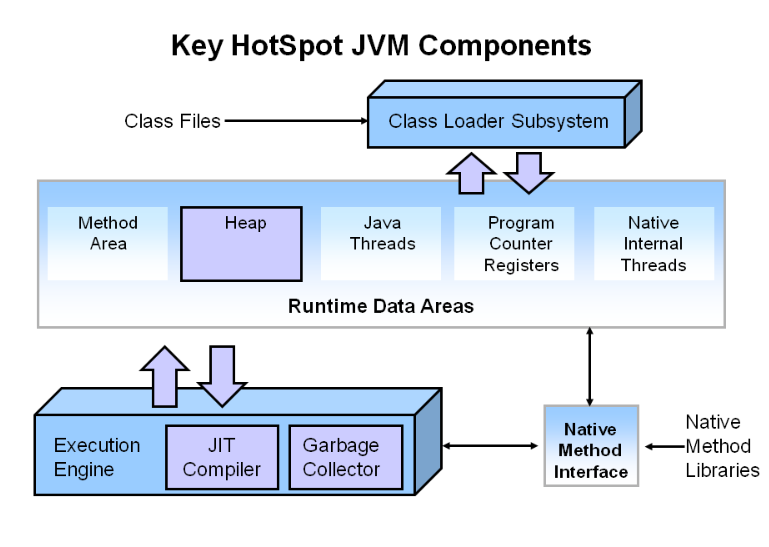
方法內聯,是指 JVM在運行時將調用次數達到一定閾值的方法調用替換為方法體本身 ,從而消除調用成本,并為接下來進一步的代碼性能優化提供基礎,是JVM的一個重要優化手段之一。
注:
C++的inline屬于編譯后內聯,但是java是運行時內聯
簡單通俗的講就是把方法內部調用的其它方法的邏輯,嵌入到自身的方法中去,變成自身的一部分,之后不再調用該方法,從而節省調用函數帶來的額外開支。
為什么會出現方法內聯呢?
之所以出現方法內聯是因為(方法調用)函數調用除了執行自身邏輯的開銷外,還有一些不為人知的額外開銷。 這部分額外的開銷主要來自方法棧幀的生成、參數字段的壓入、棧幀的彈出、還有指令執行地址的跳轉 。比如有下面這樣代碼:
public static void function_A(int a, int b){//do somethingfunction_B(a,b);}public static void function_B(int c, int d){//do something}public static void main(String[] args){function_A(1,2);}則代碼的執行過程如下:
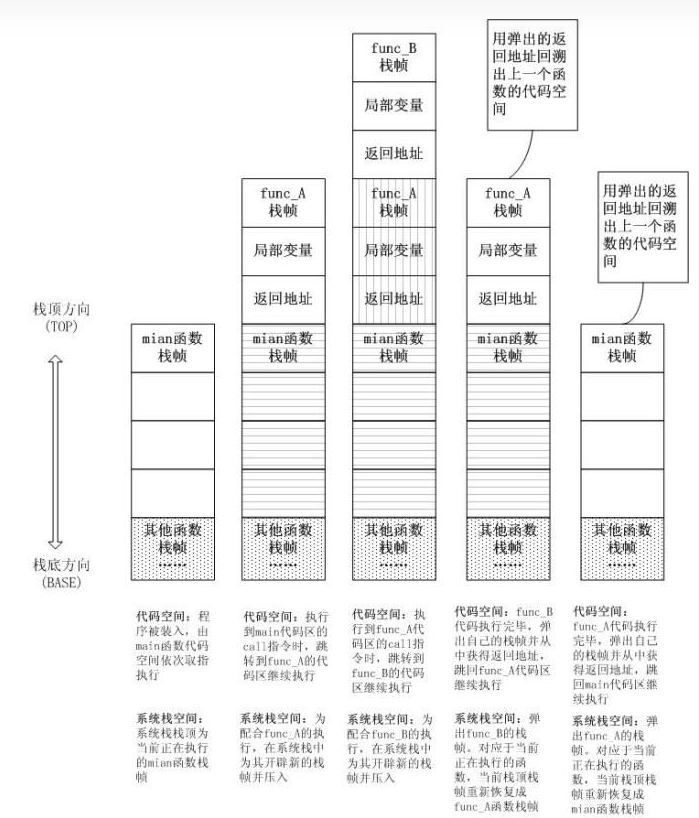
所以如果java中方法調用嵌套過多或者方法過多,這種額外的開銷就越多。
試想一下想get/set這種方法調用:
public int getI() {return i;}public void setI(int i) {this.i = i;}很可能自身執行邏輯的開銷還比不上為了調用這個方法的額外開鎖。如果類似的方法被頻繁的調用,則真正相對執行效率就會很低,雖然這類方法的執行時間很短。這也是為什么jvm會在熱點代碼中執行方法內聯的原因,這樣的話就可以省去調用調用函數帶來的額外開支。這里舉個內聯的可能形式:
public int add(int a, int b , int c, int d){return add(a, b) + add(c, d);}public int add(int a, int b){return a + b;}內聯之后:
public int add(int a, int b , int c, int d){return a + b + c + d;}內聯條件
一個方法如果滿足以下條件就很可能被jvm內聯。
-
熱點代碼。 如果一個方法的執行頻率很高就表示優化的潛在價值就越大。那代碼執行多少次才能確定為熱點代碼?這是根據編譯器的編譯模式來決定的。如果是客戶端編譯模式則次數是1500,服務端編譯模式是10000。次數的大小可以通過-XX:CompileThreshold來調整。
-
方法體不能太大。jvm中被內聯的方法會編譯成機器碼放在code cache中。如果方法體太大,則能緩存熱點方法就少,反而會影響性能。熱點方法小于325字節的時候,非熱點代碼35字節以下才會使用這種方式
-
如果希望方法被內聯, 盡量用private、static、final修飾 ,這樣jvm可以直接內聯。如果是public、protected修飾方法jvm則需要進行類型判斷,因為這些方法可以被子類繼承和覆蓋,jvm需要判斷內聯究竟內聯是父類還是其中某個子類的方法。
所以了解jvm方法內聯機制之后,會有助于我們工作中寫出能讓jvm更容易優化的代碼,有助于提升程序的性能。
逃逸分析
什么是“對象逃逸”?
對象逃逸的本質是對象指針的逃逸。
在計算機語言編譯器優化原理中,逃逸分析是指分析指針動態范圍的方法,它同編譯器優化原理的指針分析和外形分析相關聯。當變量(或者對象)在方法中分配后,其指針有可能被返回或者被全局引用,這樣就會被其他方法或者線程所引用,這種現象稱作指針(或者引用)的逃逸(Escape)。通俗點講,如果一個對象的指針被多個方法或者線程引用時,那么我們就稱這個對象的指針(或對象)的逃逸(Escape)。
什么是逃逸分析?
逃逸分析,是一種可以有效減少Java 程序中同步負載和內存堆分配壓力的跨函數全局數據流分析算法。通過逃逸分析,Java Hotspot編譯器能夠分析出一個新的對象的引用的使用范圍從而決定是否要將這個對象分配到堆上。 逃逸分析(Escape Analysis)算是目前Java虛擬機中比較前沿的優化技術了。
注意:逃逸分析不是直接的優化手段,而是代碼分析手段。
對象逃逸案例:
Xpublic User doSomething1() {User user1 = new User ();user1 .setId(1);user1 .setDesc("xxxxxxxx");// ......return user1 ;
}對象未逃逸:
public void doSomething2() {User user2 = new User ();user2 .setId(2);user2 .setDesc("xxxxxxxx");// ......
}基于逃逸分析的優化
當判斷出對象不發生逃逸時,編譯器可以使用逃逸分析的結果作一些代碼優化
-
棧上分配:將堆分配轉化為棧分配。如果某個對象在子程序中被分配,并且指向該對象的指針永遠不會逃逸,該對象就可以在分配在棧上,而不是在堆上。在的垃圾收集的語言中,這種優化可以降低垃圾收集器運行的頻率。
-
同步消除:如果發現某個對象只能從一個線程可訪問,那么在這個對象上的操作可以不需要同步。
-
分離對象或標量替換。如果某個對象的訪問方式不要求該對象是一個連續的內存結構,那么對象的部分(或全部)可以不存儲在內存,而是存儲在CPU寄存器中。
標量替換
標量:不可被進一步分解的量,而Java中基本數據類型就是標量(比如int,long等基本數據類型) 。
聚合量: 標量的對立就是可以被進一步分解的量,稱之為聚合量。 在Java中對象就是可以被進一步分解的聚合量。
標量替換:通過逃逸分析確定該對象不會被外部訪問,并且對象可以被進一步分解時,JVM不會創建該對象,而是將該對象成員變量分解若干個被這個方法使用的成員變量所代替,這些代替的成員變量在棧幀或寄存器上分配空間,這樣就不會因為沒有一大塊連續空間導致對象內存不夠分配。
棧上分配案例:
虛擬機參數:
-XX:+PrintGC -Xms5M -Xmn5M -XX:+DoEscapeAnalysis
-XX:+DoEscapeAnalysis表示開啟逃逸分析,JDK8是默認開啟的
-XX:+PrintGC 表示打印GC信息
-Xms5M -Xmn5M 設置JVM內存大小是5M
public static void main(String[] args){for(int i = 0; i < 5_000_000; i++){createObject();}
}public static void createObject(){new Object();
}運行結果是沒有GC。
把虛擬機參數改成 -XX:+PrintGC -Xms5M -Xmn5M -XX:-DoEscapeAnalysis。關閉逃逸分析得到結果的部分截圖是,說明了進行了GC,并且次數還不少。
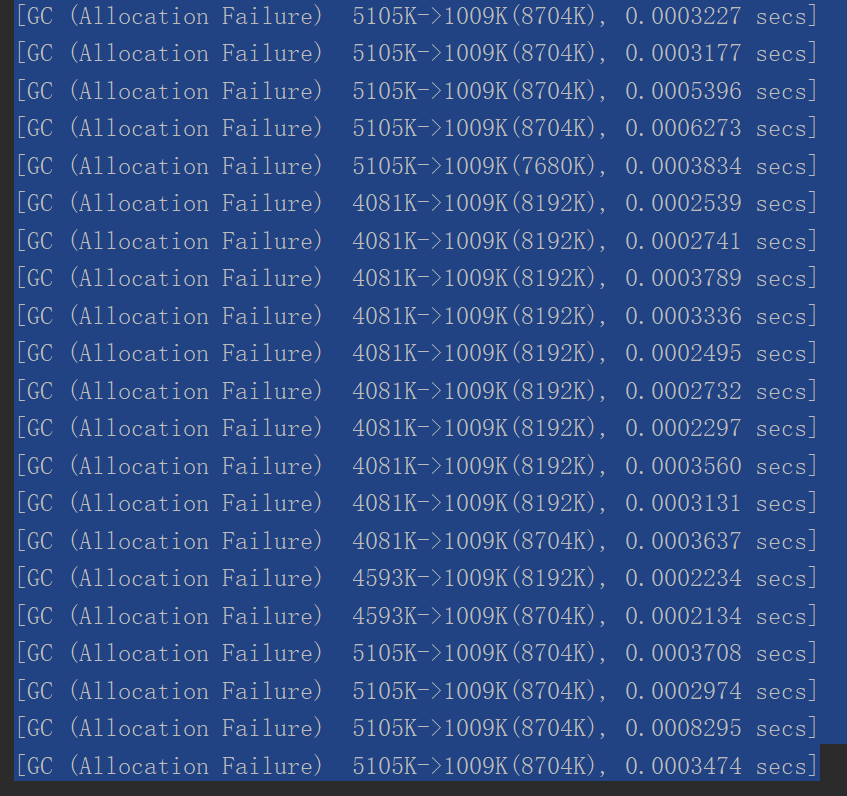
這說明了JVM在逃逸分析之后,將對象分配在了方法createObject()方法棧上。方法棧上的對象在方法執行完之后,棧楨彈出,對象就會自動回收。這樣的話就不需要等內存滿時再觸發內存回收。這樣的好處是程序內存回收效率高,并且GC頻率也會減少,程序的性能就提高了。
同步鎖消除
如果發現某個對象只能從一個線程可訪問,那么在這個對象上的操作可以不需要同步 。
虛擬機配置參數:-XX:+PrintGC -Xms500M -Xmn500M -XX:+DoEscapeAnalysis。配置500M是保證不觸發GC。
public static void main(String[] args){long start = System.currentTimeMillis();for(int i = 0; i < 5_000_000; i++){createObject();}System.out.println("cost = " + (System.currentTimeMillis() - start) + "ms");}public static void createObject(){synchronized (new Object()){}}運行結果
cost = 6ms
把逃逸分析關掉:-XX:+PrintGC -Xms500M -Xmn500M -XX:-DoEscapeAnalysis
運行結果
cost = 270ms
說明了逃逸分析把鎖消除了,并在性能上得到了很大的提升。這里說明一下Java的逃逸分析是方法級別的,因為JIT ( just in time )即時編譯器的即時編譯是方法級別。
什么條件下會觸發逃逸分析?
對象會先嘗試棧上分配,如果不能成功分配,那么就去TLAB,如果還不行,就判定當前的垃圾收集器悲觀策略,可不可以直接進入老年代,最后才會進入Eden。

Java的逃逸分析只發在JIT的即時編譯中,因為在啟動前已經通過各種條件判斷出來是否滿足逃逸,通過上面的流程圖也可以得知對象分配不一定在堆上,所以可知滿足逃逸的條件如下,只要滿足以下任何一種都會判斷為逃逸。
一、對象被賦值給堆中對象的字段和類的靜態變量。
二、對象被傳進了不確定的代碼中去運行。
對象逃逸的范圍有:全局逃逸、參數逃逸、沒有逃逸;
TLAB(Thread Local Allocation Buffer)
即線程本地分配緩存區,這是一個線程專用的內存分配區域。
由于對象一般會分配在堆上,而堆是全局共享的。因此在同一時間,可能會有多個線程在堆上申請空間。因此,每次對象分配都必須要進行同步(虛擬機采用CAS+失敗重試的方式保證更新操作的原子性),而在競爭激烈的場合分配的效率又會進一步下降。JVM使用TLAB來避免多線程沖突,在給對象分配內存時,每個線程使用自己的TLAB,這樣可以避免線程同步,提高了對象分配的效率。
每個線程會從Eden分配一大塊空間,例如說100KB,作為自己的TLAB。這個start是TLAB的起始地址,end是TLAB的末尾,然后top是當前的分配指針。顯然start <= top < end。
當一個Java線程在自己的TLAB中分配到盡頭之后,再要分配就會出發一次“TLAB refill”,也就是說之前自己的TLAB就“不管了”(所有權交回給共享的Eden),然后重新從Eden里分配一塊空間作為新的TLAB。所謂“不管了”并不是說就讓舊TLAB里的對象直接死掉,而是把那塊空間的控制權歸還給普通的Eden,里面的對象該怎樣還是怎樣。通常情況下,在TLAB中分配多次才會填滿TLAB、觸發TLAB refill,這樣使用TLAB分配就比直接從共享部分的Eden分配要均攤(amortized)了同步開銷,于是提高了性能。其實很多關注多線程性能的malloc庫實現也會使用類似的做法,例如TCMalloc。
到觸發GC的時候,無論是minor GC還是full GC,要收集Eden的時候里面的空間無論是屬于某個線程的TLAB還是不屬于任何TLAB都一視同仁,把Eden當作一個整體來收集里面的對象——把活的對象拷貝到survivor space(或者直接晉升到Old Gen)。在GC結束之后,每個Java線程又會重新從Eden分配自己的TLAB。周而復始。
TLAB分配的對象可以共享嗎?
答:只要是Heap上的對象,所有線程都是可以共享的,就看你有沒有本事訪問到了。在GC的時候只從root sets來掃描對象,而不管你到底在哪個TLAB中。




)
)


)


,與.NETCore對接(騰訊云))

)





