目錄
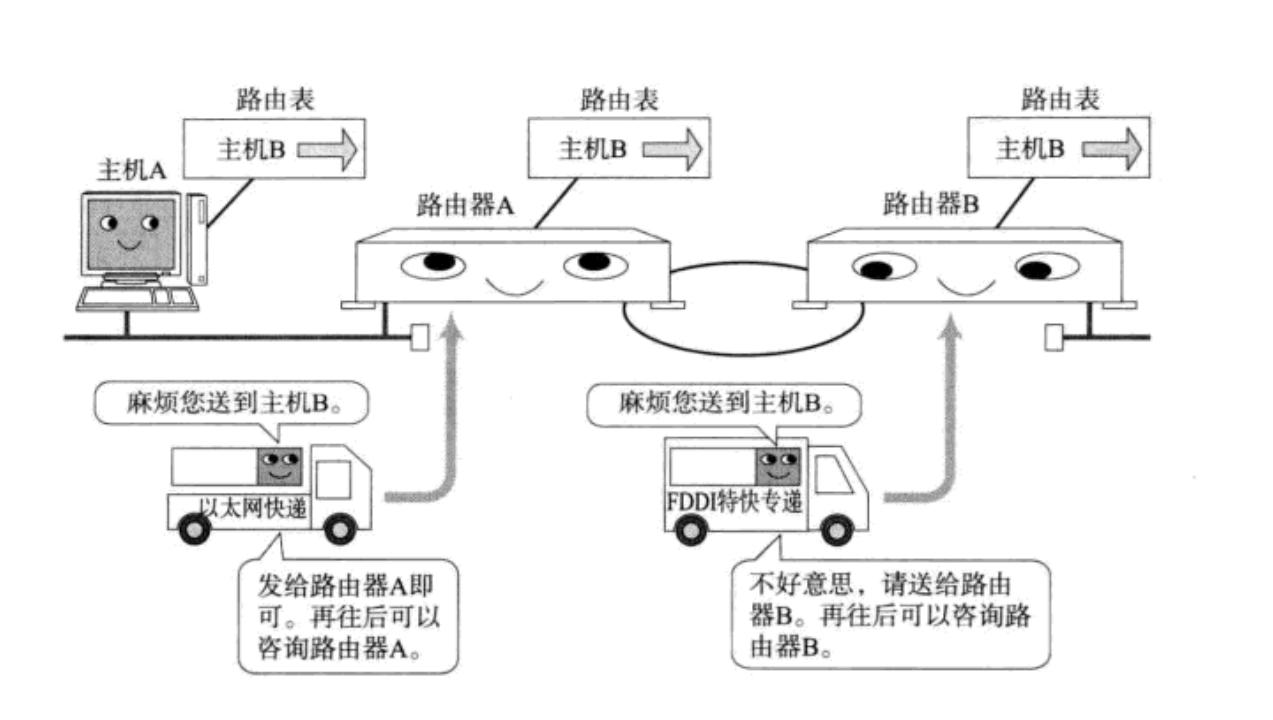
1.再談網絡轉發
2.路由
舉個例子
3.分片和組裝
IP 層
[Linux#67][IP] 報頭詳解 | 網絡劃分 | CIDR無類別 | DHCP動態分配 | NAT轉發 | 路由器
1.再談網絡轉發
我們在上一篇文章中知道了路由器的功能有:
- 轉發
- DHCP | 組建局域網
- NAT
組建局域網功能表現:在路由器里配無線網絡,設置網絡名稱+密碼。
組件局域網只能使用內網IP。路由器分為家用路由器、企業級路由器。
- 一般家用路由器用的是192.168.* 開頭的內網IP
- 企業級路由器用的10. *
- 172.16-172.31開頭的內網IP
- 下面再看運營商對應的情況
每個家都有自己的路由器,家里局域網構建好了,使用的IP地址是以192.168開頭。 - 家里在入網的時候都是要用到運營商的網絡,所以家里的路由器是直接通過網線連接家里附近的運營商
- 所以你家里的路由器一定橫跨了兩個子網,一個是你自己家里的子網,一個是運營商路由器組建的子網。
所以不要認為你的數據從你家路由器出去了就直接到公網上了,可能是到了運營商的子網,然后繼續向上轉發。
- 你家里的路由器橫跨了兩個子網,一個是對內連接你自己家里的子網,一個是對外連接運營商路由器組建的子網
- 所以路由器一般會配有兩個IP,一個是子網IP(LAN口IP)(對內)表示的是這個是路由器自己構建的子網并且屬于這個子網內第一臺主機。
- 并且這個路由器對外連接是運營商給它構建的子網,所以配置另一個WAN口IP(對外)。
運營商自己的路由器也配有LAN口IP(對內)配置的是內網IP,WAN口IP(對外)配置的是公網IP直接連接到公網上了。
- 換句話說,我們的數據包在從主機出來的時候是先給家用路由器然后再交給運營商路由器做運營商自己的內網轉發,當轉發到一定程度,再把數據包轉到公網
- 再由公網IP轉給對應的提供服務的企業。當回來的時候也是用的WAN口IP。
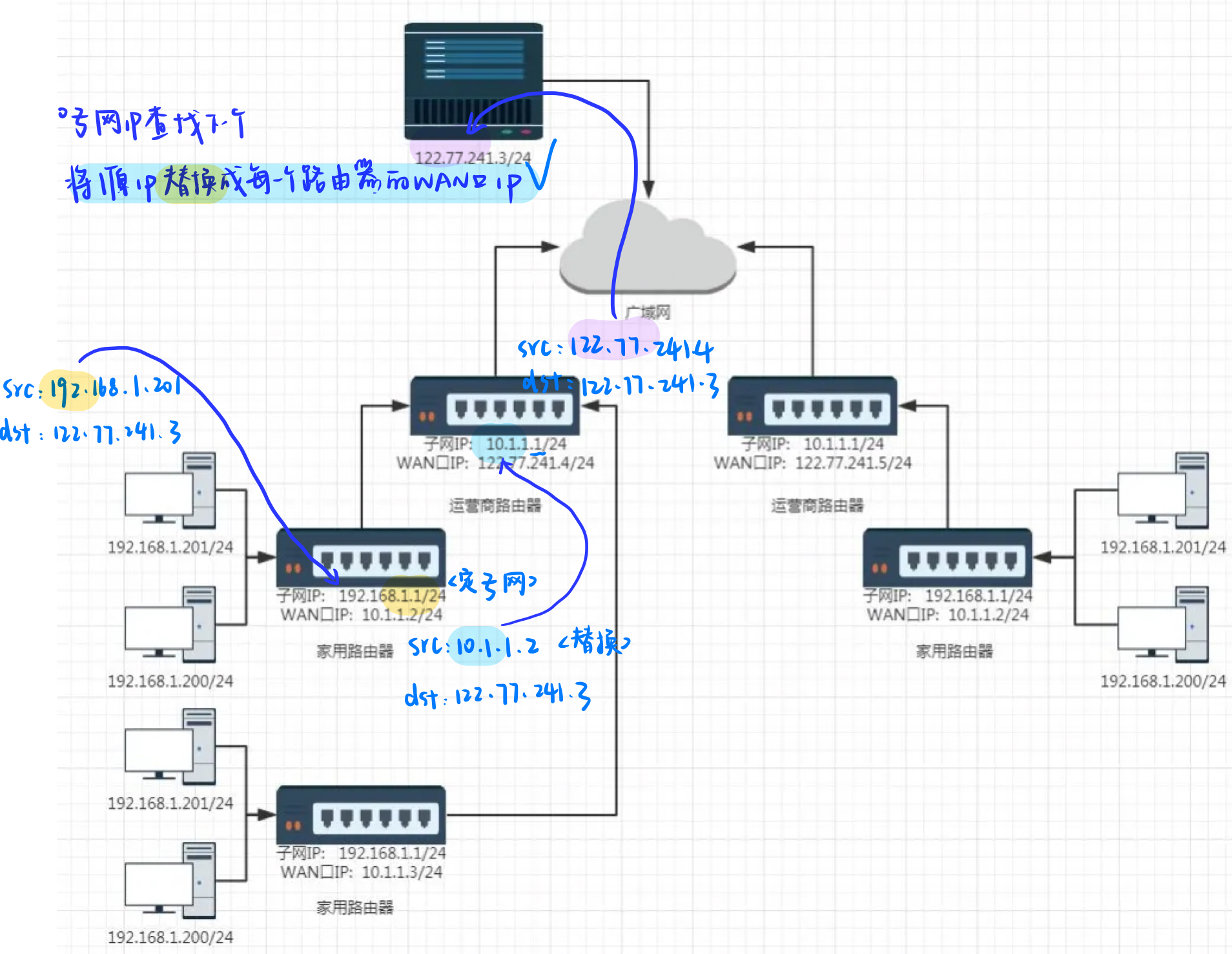
我們再看看數據包轉發流程:
不同局域網私有IP是可以重復的,只要保證局部性的唯一性。這樣就可以用重復的IP入網了,所以它可以用來解決了IP不足的問題。
- 但是現在就有問題了,雖然不同局域網但用的是同樣的IP,假設去訪問抖音,首先判斷這個請求不是屬于同一個局域網的,然后就把請求給家用路由器等等,一路最終給了抖音,最后抖音怎么知道應該把服務給誰。是給那個局域網的192.168.1.201?回不來了?
- 所以就需要一種技術支持,經過路由器的時候要把當前請求的源IP替換自己路由器的WAN口IP。然后就知道把服務轉到哪里了。
我們把經過路由器不斷的在做源IP和WAN口IP替換的這種技術叫做NAT。
那現在怎么回來呢?這個問題,我們后面說。
我們現在可以知道的就是:
- 一個路由器可以配置兩個IP地址, 一個是WAN口IP, 一個是LAN口IP(子網IP).
- 路由器LAN口連接的主機, 都從屬于當前這個路由器的子網中.
- 不同的路由器, 子網IP其實都是一樣的(通常都是192.168.1.1). 子網內的主機IP地址不能重復. 但是子網之間的IP地址就可以重復了.
- 每一個家用路由器, 其實又作為運營商路由器的子網中的一個節點. 這樣的運營商路由器可能會有很多級, 最外層的運營商路由器, WAN口IP就是一個公網IP了.
- 子網內的主機需要和外網進行通信時, 路由器將IP首部中的IP地址進行替換(替換成WAN口IP), 這樣逐級替換, 最終數據包中的IP地址成為一個公網IP. 這種技術稱為NAT(Network Address Translation,網絡地址轉換).
- 如果希望我們自己實現的服務器程序, 能夠在公網上被訪問到, 就需要把程序部署在一臺具有外網IP的服務器上. 這樣的服務器可以在阿里云/騰訊云上進行購買.
現在我們有公網/內網(子網/局域網),子網劃分的概念,我們畫圖建立一個宏觀的網絡拓撲結構。
- 簡單點就以比特位劃分網絡,比如說從美國發一個請求目的ip是湖北武漢。
- 一看這個目的IP結合子網掩碼一查發現不是自己國家的網絡就發送到國際之間的路由器,一查發現是中國的,就轉發給中國,然后我國國際路由器在根據結合自己的子網掩碼一看,發現是湖北的就轉發給湖北。
- 再由湖北這里的服務器結合ip和路由器的子網掩碼一查發現是武漢的,就轉給武漢了。
這是我們構建起來的公網,可是你會發現一個問題,IP地址再分不夠了。
沒關系,到地方上不是有很多的本地運營商嗎?此時在由本地運營商劃分不同的子網。然后弄一個公網入口路由器。
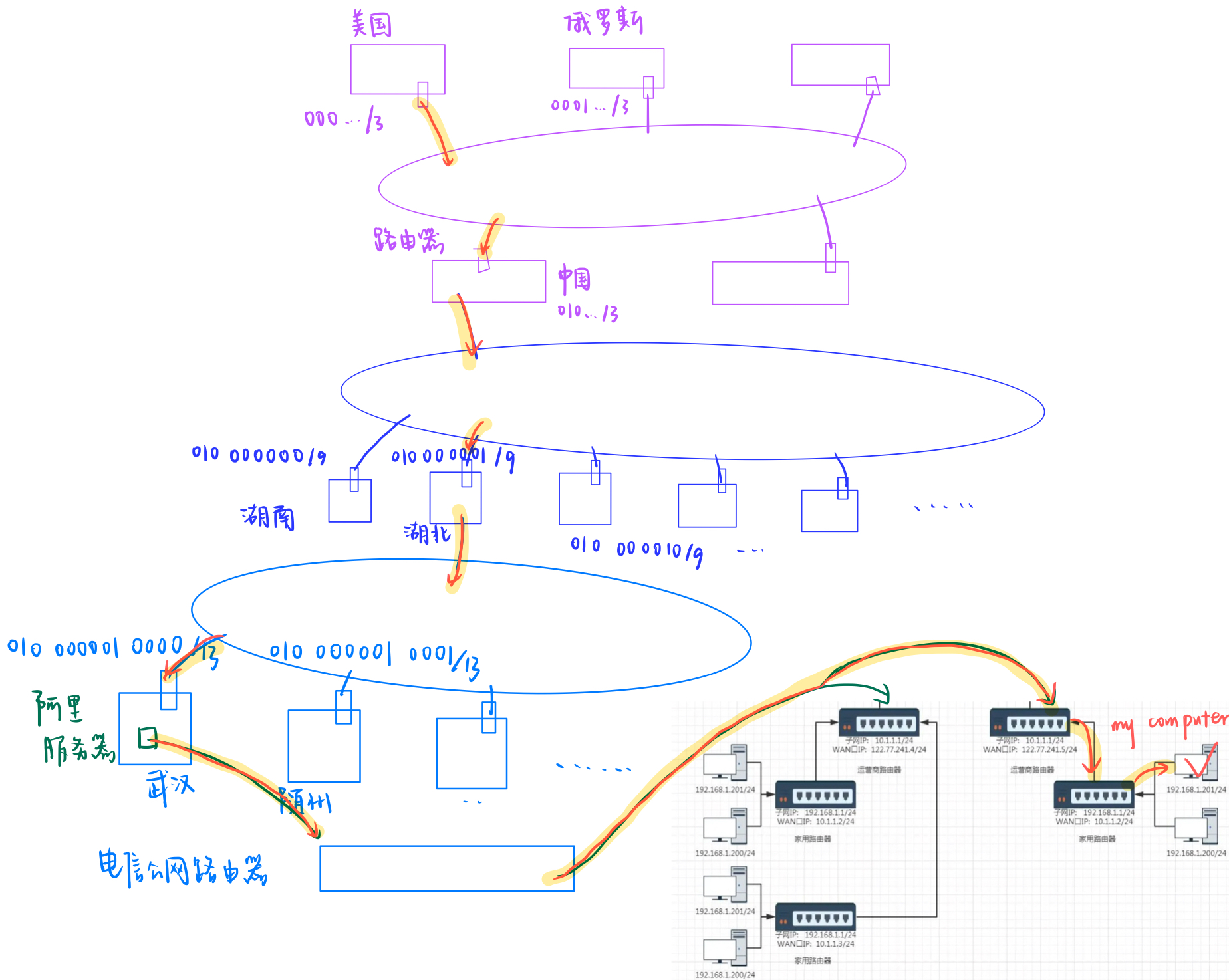
我們就可以理解成整個網絡拓撲結構就類似這種的。真實網絡更復雜!
2.路由
我們并不談路由表是怎么形成的,這涉及到路由器和路由器之間通信的問題我們不考慮。
我們只考慮兩點
- 來了一個數據包到了中間節點路由器中它應該如何路由
- 第二一個路由器中的路由器的構成應該是什么樣子的。
我們在路由的時候,一定要告訴要經歷的路由器你要去哪里。
- 也就是說目的IP是什么,我們知道IP = 目標網絡 + 目標主機 ,所以大部分路由都是拿著目的IP,然后先找這個目標主機所在的子網。
- 所以在查找的時候一定有一張對應的路由表來查,這個路由表能夠從我的數據報文的目的IP配上對應的子網掩碼進行提取目的網絡。
- 在通過查找子網的過程經過路由之后找到目標主機所在的子網,然后再子網中進行內網轉發把數據交給目標主機。
舉個例子
下面一個簡單例子理解一下這個找的過程。
- 假如我剛下火車想要去清華大學,不考慮其他方法,只能問人然后根據別人的指示進行下一步動作。
- 你出火車站碰到一個大爺,問大爺我去清華大學該怎么走。
日常你問別人路怎么走無非就得到下面幾種結果
- 1. 我不知道,別問我。
- 2. 我自己不清楚,但是我知道有人知道,你看到那個掃地大媽沒有她在這里生活20年了她肯定知道,你去問她把。
- 3. 大爺知道怎么走,你先這樣走,在那樣走,然后再問別人。
- 4. 大爺說這里就是你要去的地方。
在剛才的例子里,我就是一個數據包
- 我涵蓋了一個目的地址(清華大學),大爺或者大媽以及你未來可能遇見要問路的人就是一個一個路由器
- 當你在問大爺的時候,他肯定要動腦子想,該怎么走或者其他的。
- 而大爺腦海里這種全局的或者局部的路徑情況我們稱為路由器中的路由表,當你問大爺而大爺在思考的過程就是在查路由表的過程,給你反饋怎么走就是查找得到的結果。
在回到上面故事,看大爺給我的反饋,你問大爺大爺說我不知道別問我,現實生活中確實可能遇到這種情況,但是現在是一個數據包千里迢迢送到一個路由器,路由器說不要問我,我不知道,我也不知道誰知道,這是不合理的!
- 這是查找邏輯出現了問題,一個路由器怎么能拒絕報文了,它應該全心全意幫報文找到目標網絡
- 現實生活中存在的在網絡中是不存在的,一般一個路由器會想辦法竭盡全力幫助這個報文。
- 即便它不知道也要想辦法仍給下一個路由器去。所以第一種情況不存在。
第二種情況,大爺說我不知道但是我知道那個掃地的大媽知道。
- 所以路由器自己不知道這個報文去哪里,但是它必須知道在自己不確定的路徑下它自己要有一個默認路由,大媽就是那個默認路由(下一跳默認網關)。
第三種情況,大爺告訴你怎么走,然后到了地方你在去問別人。
- 這叫做大爺明確知道你要去哪里的,方向沒有錯,但是更多細節大爺就不知道了。路由器把報文轉發到下一跳路由器。
一般在路上問人的時候無非就是這三種場景,而在網絡中轉發報文時常見的就是第二,第三種。
- 第四種場景是經過不斷的查找最終你遇到了清華大學門口保安大爺,你問大爺清華大學怎么走,大爺說這就是清華大學。你很高興。
- 但是你想想你真的要來清華大學嗎,實際上你要去的是清華大學(目標網絡) 19號宿舍樓(目標主機)。
- 于是你問大爺請問19號樓怎么走,所以門口保安大爺說你這樣走那么走就到了,所以你很快就找到了19號宿舍樓。
- 至此這就是你找到了目標網絡所在的目標主機。門口保安大爺叫做該子網入口的路由器。
所以當實際在進行路由轉發的時候,永遠要經歷的是先在路上進行路由,然后到達目標子網之后,在經過目標子網的入口路由器進行內網轉發將數據送達目標主機。
- 路上路由時我們只看目標網絡,到達目標網絡之后在結合入口路由器將數據發送目標主機。
- 路由的過程, 就是這樣一跳一跳(Hop by Hop) “問路” 的過程.
所謂 “一跳” 就是數據鏈路層中的一個區間. 具體在以太網中指從源MAC地址到目的MAC地址之間的幀傳輸區間.
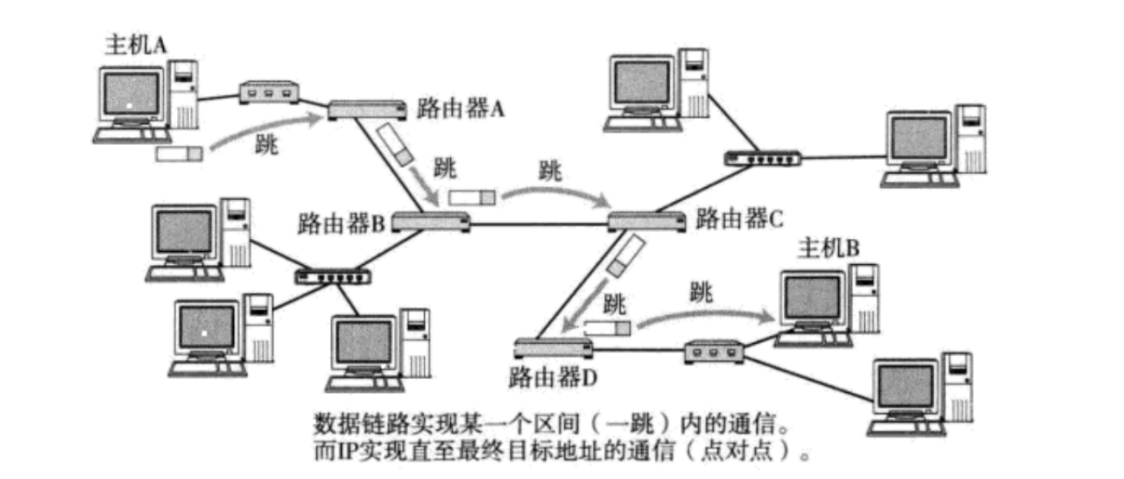
IP數據包的傳輸過程也和問路一樣.
- 當IP數據包, 到達路由器時, 路由器會先查看目的IP;
- 路由器決定這個數據包是能直接發送給目標主機, 還是需要發送給下一個路由器;
- 依次反復, 一直到達目標IP地址;
那么如何判定當前這個數據包該發送到哪里呢? 這個就依靠每個節點內部維護一個路由表;
- 路由表可以使用route命令查看

- Destination: 目標網絡(和我這個路由器直接相連的子網)
Gateway: 下一跳路由器
Genmask: 子網掩碼
Use Iface: 發送接口
這里的default就是默認網關,確實這個目的IP不是我同一個網段,是哪里也不清楚,就把它扔到默認網關里。
假設某主機上的網絡接口配置和路由表如下:
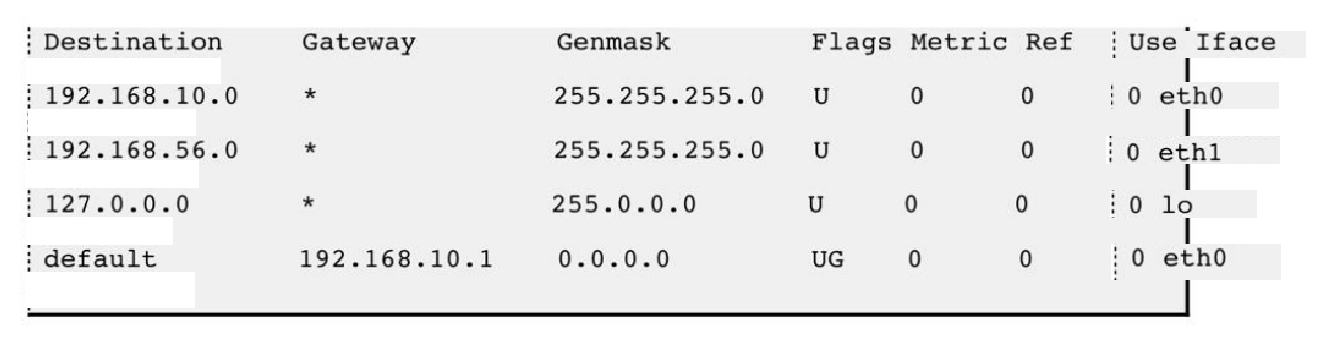
- 這臺主機有兩個網絡接口,一個網絡接口連到192.168.10.0/24網絡,另一個網絡接口連到192.168.56.0/24網絡;
- 路由表的Destination是目的網絡地址,Genmask是子網掩碼,Gateway是下一跳地址,Iface是發送接口
Flags中的U標志表示此條目有效(可以禁用某些 條目)
- G標志表示此條目的下一跳地址是某個路由器的地址
- 沒有G標志的條目表示目的網絡地址是與本機接口直接相連的網絡,不必經路由器轉發
轉發步驟
- 遍歷路由器
- 目的IP & 路由表中配置的Getmask,確定該報文要去的網絡
- 對比結果 和 Destination
- 通過Iface接口發出報文!
轉發過程例1: 如果要發送的數據包的目的地址是192.168.56.3
- 跟第一行的子網掩碼做與運算得 到192.168.56.0,與第一行的目的網絡地址不符
- 再跟第二行的子網掩碼做與運算得 到192.168.56.0,正是第二行的目的網絡地址,因此從eth1接口發送出去;
- 由于192.168.56.0/24正 是與eth1 接口直接相連的網絡,因此可以直接發到目的主機,不需要經路由器轉發;
轉發過程例2: 如果要發送的數據包的目的地址是202.10.1.2
- 依次和路由表前幾項進行對比, 發現都不匹配;
- 按缺省路由條目, 從eth0接口發出去, 發往192.168.10.1路由器;
- 由192.168.10.1路由器根據它的路由表決定下一跳地址;
其實我們說的子網掩碼是配置進路由器的,路由器一定要及連一個或多個子網,所以每個子網對應的網絡號和它這子網所配套的子網掩碼都是路由器的條目
所以報文到達時拿著目的IP與對應條目的子網掩碼 查路由表發現直接連接的子網號,三位一體就可以將我們的報文進行轉發。
問:當進行數據包轉發時,我們要去的目標網絡號會不會變化?
會的。最終的網絡號是確定的!因為每個路由器配置的子網掩碼都不一樣,所有網絡號也在變化。
- 但只要子網掩碼越來越長,那就意味著我們要去的網絡號越來越具體,意味著淘汰網絡越來越多,主機號越來越短,距離目標主機距離越來越短。
- 只有最終到了入口路由器,已經沒有子網了,直接就是目標主機所在的子網,接下來進行內網轉發。
路由表可以由網絡管理員手動維護(靜態路由), 也可以通過一些算法自動生成(動態路由).
例如距離向量算法, LS算法, Dijkstra算法等.這里可以自己了解一下。
3.分片和組裝
IP報頭我們認識的差不多了,還是剩下三個字段。
- 這是要結合下一層數據鏈路層來學習,不過我們可以先看結論。

真正在路由器上轉發的確實是IP報文 - 但真正的在網線上跑的是MAC幀!
數據鏈路層,有一個MAC幀協議,它規定:自己的有效載荷不能超過 1500 字節(MTU,是可以修改的),也就是說上層傳遞下來的單個IP報文(IP報頭+IP報文的有效載荷)不能超過1500字節。
MAC說IP你不能給我每次報文超過1500字節。但是IP能決定單個報文大小嗎?
- 不能,它只是負責路由轉發。那誰能?
- 真正在網絡中決定單個報文大小的是TCP
- (TCP是傳輸控制協議,它規定什么時候發,發多少。。。)
那TCP怎么控制呢?以前學TCP我們知道滑動窗口=min(擁塞窗口,對方接收能力),那為什么還要在滑動窗口里分一個一個報文呢?
- 為什么不直接把數據打包成一個直接發送出去呢?原因就在于數據鏈路層不允許發這么大。具體后面說。
- 那TCP就是給IP3000字節報文讓它發,MAC說每次就是不能超過1500字節,那IP只能自己想辦法了。IP想出了一個辦法分片與組裝。不過IP分片和組裝不是主流情況!大部分TCP會考慮IP的感受。
所以IP就有上面三個字段來支持分片和組裝。
IP 層
分片:在自己的IP層,組裝:對端的IP層。
TCP和MAC并不關心IP進行分片。
如何分片?如何組裝?
分片不能單獨分片還要考慮對端組裝的問題。靈魂五連問,我們要相信計算機設計中,有問題就有答案
- 你怎么知道一個報文被分片了?
- 同一個報文的分片怎么都能被識別出來?
- 哪一個是第一個,哪一個是最后一個,有沒有收全或者丟失?
- 那個在前,那個在后,如何正確的進行組裝?
- 怎么保證我合起來的報文是正確的
我們先認識這三個字段,然后再回到上面的問題。
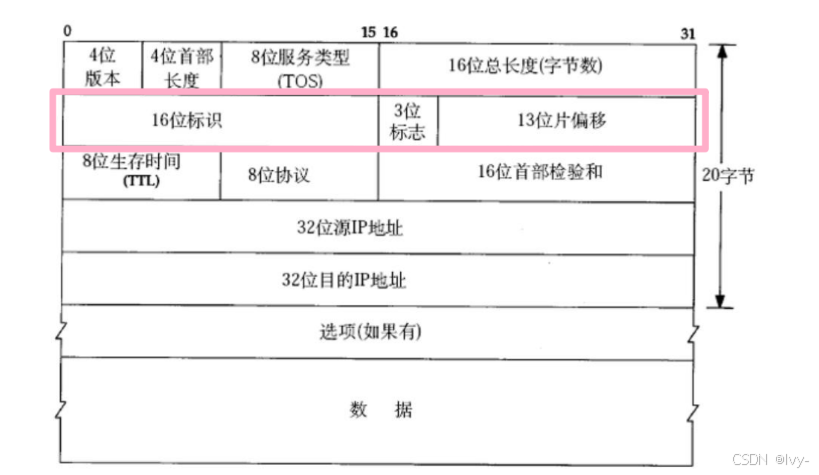
16位標識(id):
- 唯一的標識主機發送的報文.
- 如果因為數據鏈路層規則而導致IP被分片了, 那么每一個分片里面的這個id都是相同的.
3位標志字段:
- 有三個比特位
- 第一位保留(保留的意思是現在不用, 但是還沒想好說不定以后要用到).
- 第二位置為1表示禁止分片, 這時候如果報文長度超過MTU, IP模塊就會丟棄報文.
- 第三位表示"更多分片"
- 如果分片了的話, 是最后一個分片該位置會被置為0, 類似于一個結束標記。
- 如果分片后面還有分片該位置被置為1,表示后面還有分片. (一個IP報文被分片后,每一分片報文也都必須要有IP報頭,因為每一個分片本質也是一個獨立的報文)
13位分片偏移(framegament offset):
- 是分片相對于原始IP報文開始處的偏移. 其實就是在表示當前分片在原報文中處在哪個位置. 實際偏移的字節數是這個值 * 8(==32/4) 得到的.
- 因此, 除了最后一個報文之外, 其他報文的長度必須是8的整數倍(否則報文就不連續了).
這三個字段就能支持分片和組裝。
怎么知道一個報文被分片了?
- 1.如果更多分片是1,就證明該標識的報文分片了
2.如果更多分片是0 && 片偏移量>0,說明是分片了( 為最后一個分片~),否則不是!
同一個報文的分片怎么都能被識別出來?
- 16位標識!
哪一個是第一個,哪一個是最后一個,有沒有收全或者丟失?
- 更多分片是1 && 片偏移是0 —> 第一個
更多分片是0 && 片偏移>0 —> 最后一個
有沒有收全或者丟失保證不了,但沒關系排序后,只要保證當前報文的起始位置+自身長度=下一個報文中填充的偏移量。這樣即使出錯了哪一個報文丟了也知道。
那個在前,那個在后,如何正確的進行組裝?
- 只要按照片偏移量進行升序排序即可!
怎么保證我合起來的報文是正確的!
- TCP和IP有校驗和
1.分片好嗎?
不好!
2.對TCP和UDP包括IP本身有什么影響?
- 一個報文被拆成了多個,任意一個報文分片丟失,就會造成拼接組裝失敗,進而導致對端對整個報文進行重傳。因為TCP并不知道IP進行分片了。
其次一個數據包不丟包概率99%,分成3片,99%*99%*99% < 99% ,所以分片會增加丟包概率。
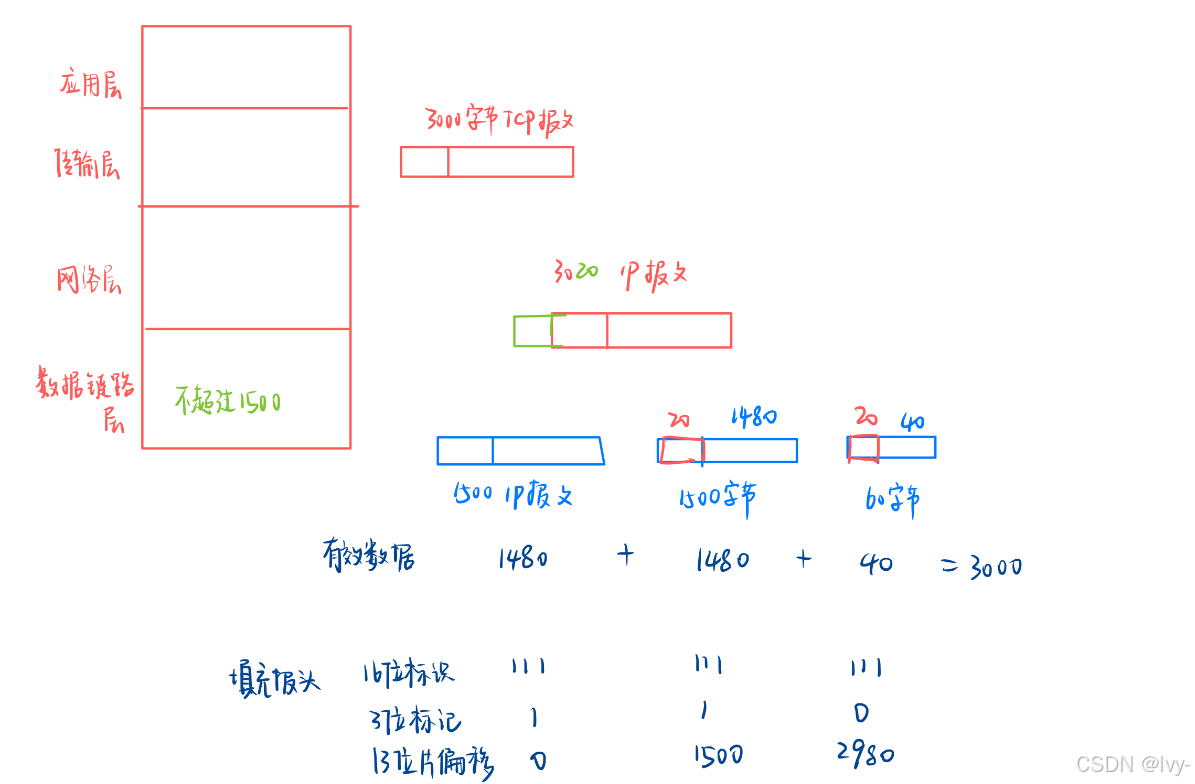
接下來我們自己試著分一下
- 傳輸層給網絡層3000字節的 TCP 報文,但是數據鏈路層要求每個報文最大不超過1500字節。
- 到了網絡層加上IP報頭,IP報文3020字節。現在怎么分片呢?
首先無腦拿前面1500字節,注意這1500字節是包含原始IP報文的報頭的!
然后3020-1500還剩下1520字節,可是這1520字節可是純數據
- 將來再分的分片也要添加報頭,因此只能從1520字節拿1480個字節,然后在添加20字節的IP報頭,組成1500字節IP報文。
- 現在1520-1480還剩下40字節,在添加20字節IP報頭,組成60字節IP報文。
實際上發送的有效數據 1480、1480、40 組裝完成后,正好是TCP報文長度。
現在這些過程應該越來越清晰了。
- 從應用層調用send/write把數據拷貝到tcp發送緩沖區
- 然后tcp以滑動窗口方式進行發送到IP層
- 加上IP報頭,可能會分片。
下一篇文章,我們將開始學習 數據鏈路層~
子網掩碼
子網掩碼的存在就像「快遞分揀」和「小區門禁」的結合,核心是為了解決三個問題:節省地址資源、提升尋址效率和實現靈活管理。舉個生活中的例子解釋:
1?? 為什么不能只用IP?—— 快遞分揀的視角
假設你有一個IP地址 192.168.1.100,如果直接用它找目標主機,就像快遞員要記住全國每個家庭的具體地址才能送快遞,效率極低。而子網掩碼(如 255.255.255.0)的作用是:
- ? 劃分區域層級:掩碼把IP拆成「網絡號+主機號」(比如
192.168.1.0是小區,.100是門牌號)。路由器只需先找到「小區」,再找「門牌號」,效率暴增。 - ? 沒有掩碼會怎樣?如果全網只有主機號,路由表會像一本全國所有家庭的地址簿,大到無法存儲和查詢。
2?? 子網掩碼的靈活性—— 可變長的「小區劃分」
傳統的IP分類(A/B/C類)像固定大小的「小區」:
- C類小區(掩碼
255.255.255.0)只有254戶(比如小公司),但若某公司有300臺設備,C類不夠用,B類又浪費6萬多個地址。 - ? 子網掩碼的魔法:通過調整掩碼長度(如
255.255.254.0),可以把一個B類大區切割成多個「可變大小的小區」,按需分配,避免浪費。
3?? 安全與管理—— 小區里的「門禁系統」
子網掩碼還像小區的圍墻:
- ? 隔離廣播域:同一個子網內的設備廣播(比如ARP請求)不會干擾其他子網,減少網絡擁堵。
- ? 獨立策略:IT管理員可以針對不同子網設置防火墻規則(比如財務部子網禁止訪問外網)。
🌰 總結比喻
- IP地址 = 國家+省份+城市+街道+門牌號(但長度固定不靈活)
- 子網掩碼 = 一把可伸縮的尺子,自由決定哪部分算「城市」,哪部分算「街道」,讓尋址既高效又省資源。








)


)
)






