
深度解析TorchVision_Maskrcnn:基于PyTorch的實例分割實戰指南
- 技術背景與核心原理
- Mask R-CNN架構解析
- 項目特點
- 完整實戰流程
- 環境準備
- 硬件要求
- 軟件依賴
- 數據準備與標注
- 1. 圖像采集
- 2. 數據標注
- 3. 數據格式轉換
- 模型構建與訓練
- 1. 模型初始化
- 2. 數據加載器配置
- 3. 訓練優化策略
- 關鍵技術挑戰與解決方案
- 1. GPU內存不足問題
- 2. 多GPU訓練問題
- 3. COCO評估接口問題
- 性能優化技巧
- 學術研究與擴展閱讀
- 關鍵論文
- 最新進展
- 項目應用與展望
實例分割是計算機視覺領域的重要任務,它不僅要檢測圖像中的每個目標,還要精確描繪出每個目標的輪廓。本文將全面剖析一個基于PyTorch TorchVision實現的Mask R-CNN項目——TorchVision_Maskrcnn,從原理到實戰應用,為讀者提供一份詳盡的實例分割技術指南。
技術背景與核心原理
Mask R-CNN架構解析
Mask R-CNN是在Faster R-CNN基礎上發展而來的兩階段實例分割算法,其核心創新點包括:
- RoIAlign層:解決了Faster R-CNN中RoIPooling的量化誤差問題,實現了更精確的特征對齊
- 并行預測分支:在原有邊界框回歸和分類分支基礎上,新增了掩碼預測分支
- 全卷積網絡設計:掩碼預測采用FCN結構,保持了空間信息
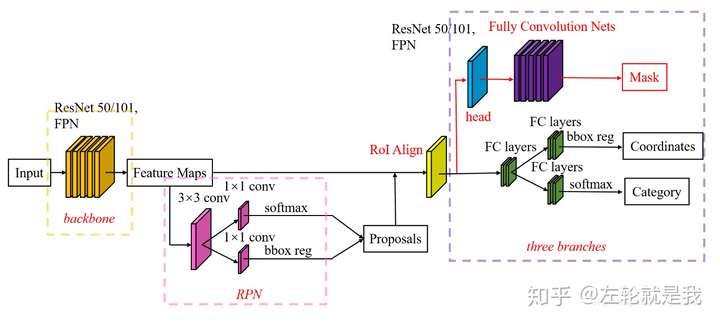
圖:Mask R-CNN網絡架構示意圖(圖片來源:知乎)
項目特點
TorchVision_Maskrcnn項目具有以下顯著特點:
- 輕量級實現:基于PyTorch官方TorchVision庫,無需從頭實現
- 遷移學習支持:提供預訓練模型微調方案
- 實戰導向:包含完整的數據準備、模型訓練和優化流程
- 資源友好:針對普通GPU(如GTX1660)進行了優化適配
完整實戰流程
環境準備
硬件要求
- GPU:推薦NVIDIA顯卡(顯存≥6GB)
- CPU:支持AVX指令集
- 內存:建議≥8GB
軟件依賴
conda create -n maskrcnn python=3.7
conda activate maskrcnn
pip install torch torchvision opencv-python labelme pycocotools
數據準備與標注
1. 圖像采集
建議使用多樣化場景的圖像數據,每類至少200-300張樣本。可使用批量下載工具:
# 示例:使用ImageCyborg API下載圖像
import requestsurl = "https://imagecyborg.com/api/download"
params = {"query": "street cars","count": 100
}
response = requests.get(url, params=params)
2. 數據標注
使用LabelMe進行實例級標注:
labelme # 啟動標注工具
標注完成后,目錄結構應如下:
dataset/
├── img1.jpg
├── img1.json
├── img2.jpg
└── img2.json
3. 數據格式轉換
項目提供了轉換腳本:
python new_json_to_dataset.py /path/to/labelme/data
python copy.py
關鍵修改點:
# 在new_json_to_dataset.py中定義類別映射
NAME_LABEL_MAP = {'_background_': 0,"car": 1,"person": 2
}
模型構建與訓練
1. 模型初始化
import torchvision
from torchvision.models.detection import maskrcnn_resnet50_fpn# 加載預訓練模型
model = maskrcnn_resnet50_fpn(pretrained=True)# 凍結骨干網絡參數
for param in model.parameters():param.requires_grad = False# 修改預測頭
num_classes = 3 # 包括背景
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask, 256, num_classes)
2. 數據加載器配置
from torchvision.transforms import functional as Fclass CustomDataset(torch.utils.data.Dataset):def __init__(self, root, transforms=None):self.root = rootself.transforms = transformsself.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImages"))))self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasks"))))def __getitem__(self, idx):img_path = os.path.join(self.root, "PNGImages", self.imgs[idx])mask_path = os.path.join(self.root, "PedMasks", self.masks[idx])img = Image.open(img_path).convert("RGB")mask = Image.open(mask_path)mask = np.array(mask)# 實例編碼處理obj_ids = np.unique(mask)obj_ids = obj_ids[1:] # 去除背景masks = mask == obj_ids[:, None, None]# 邊界框計算boxes = []for i in range(len(obj_ids)):pos = np.where(masks[i])xmin = np.min(pos[1])xmax = np.max(pos[1])ymin = np.min(pos[0])ymax = np.max(pos[0])boxes.append([xmin, ymin, xmax, ymax])# 轉換為Tensorboxes = torch.as_tensor(boxes, dtype=torch.float32)labels = torch.ones((len(obj_ids),), dtype=torch.int64)masks = torch.as_tensor(masks, dtype=torch.uint8)target = {}target["boxes"] = boxestarget["labels"] = labelstarget["masks"] = masksif self.transforms is not None:img, target = self.transforms(img, target)return img, target
3. 訓練優化策略
# 優化器配置
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005, momentum=0.9, weight_decay=0.0005)# 學習率調度器
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)# 訓練循環
for epoch in range(10):train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)lr_scheduler.step()evaluate(model, data_loader_test, device=device)
關鍵技術挑戰與解決方案
1. GPU內存不足問題
現象:訓練過程中出現CUDA out of memory錯誤
解決方案:
- 減小batch_size(建議從1開始嘗試)
- 使用梯度累積:
optimizer.zero_grad() for i, (images, targets) in enumerate(data_loader):loss_dict = model(images, targets)losses = sum(loss for loss in loss_dict.values())losses.backward()if (i+1) % 4 == 0: # 每4個batch更新一次optimizer.step()optimizer.zero_grad() - 使用混合精度訓練:
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler() with autocast():loss_dict = model(images, targets)
2. 多GPU訓練問題
現象:在Windows上多GPU訓練失敗
解決方案:
- 使用單GPU訓練:
model = model.to('cuda:0') - Linux下可嘗試DataParallel:
model = torch.nn.DataParallel(model)
3. COCO評估接口問題
現象:出現TypeError: object of type <class 'numpy.float64'> cannot be safely interpreted as an integer
解決方案:
修改cocoeval.py文件:
# 原代碼
self.iouThrs = np.linspace(.5, 0.95, np.round((0.95 - .5) / .05) + 1, endpoint=True)
# 修改為
self.iouThrs = np.linspace(.5, 0.95, int(np.round((0.95 - .5) / .05) + 1), endpoint=True)
性能優化技巧
-
骨干網絡替換:對于移動端部署,可將ResNet替換為MobileNetV2:
backbone = torchvision.models.mobilenet_v2(pretrained=True).features backbone.out_channels = 1280 model = MaskRCNN(backbone, num_classes=2) -
錨框配置優化:根據目標尺寸調整anchor生成器:
anchor_sizes = ((32,), (64,), (128,), (256,), (512,)) # 針對小目標檢測 aspect_ratios = ((0.5, 1.0, 2.0),) * len(anchor_sizes) -
RoIAlign參數調優:
roi_pooler = MultiScaleRoIAlign(featmap_names=['0', '1', '2', '3'], # 使用更多特征層output_size=7,sampling_ratio=4 # 提高采樣率 )
學術研究與擴展閱讀
關鍵論文
-
Faster R-CNN:
- Ren S, et al. “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.” NeurIPS 2015
-
Mask R-CNN:
- He K, et al. “Mask R-CNN.” ICCV 2017
-
RoIAlign改進:
- Dai J, et al. “Deformable Convolutional Networks.” ICCV 2017
最新進展
- PointRend:將圖像分割視為渲染問題,實現更精確的邊緣分割
- CondInst:條件卷積實現實例分割,避免顯式的RoI操作
- SOLOv2:基于實例掩碼的直接預測框架
項目應用與展望
TorchVision_Maskrcnn項目可應用于多個實際場景:
- 醫學影像分析:細胞實例分割
- 自動駕駛:道路場景理解
- 工業檢測:缺陷定位與分割
- 增強現實:實時對象分割與替換
未來發展方向包括:
- 模型輕量化(知識蒸餾、量化)
- 實時性優化(TensorRT加速)
- 半監督學習(減少標注依賴)
通過本文的詳細指南,讀者可以快速掌握基于TorchVision的Mask R-CNN實現方法,并能夠針對具體應用場景進行定制化開發和優化。該項目不僅提供了實例分割的完整實現,更為深度學習在實際問題中的應用提供了優秀范例。




)



)










)