目錄
- 利用多模態表示提升淘寶展示廣告效果:挑戰、方法與洞察
- 摘要
- 1 引言
- 2 預備知識
- 推薦模型中的ID特征
- 基于ID的模型結構
- 3 多模態表示的預訓練
- 3.1 語義感知對比學習
- 3.2 預訓練數據集的構建
- 3.3 優化
- 4 與推薦模型的集成
- 4.1 觀察和見解
- 4.2 方法一:SimTier
- 4.3 方法二:多模態知識提取器(MAKE)
- 多模態相關參數的多輪訓練
- 知識利用
- 5 在線部署的工業設計
- 6 實驗
- 6.1 實驗設置
- 6.1.1 數據集
- 6.1.2 對比預訓練方法
- 6.1.3 對比推薦方法
- 6.1.4 評估指標
- 6.2 預訓練數據集上的性能
- 6.2.1 使用準確率評估預訓練表示有效性的基本原理
- 6.2.2 語義感知對比學習的重要性
- 6.3 CTR預測數據集上的性能
- 6.3.1 不同集成策略的性能
- 6.3.2 MAKE不同訓練輪次的性能
- 6.3.3 罕見物品的性能
- 6.4 在線性能
- 7 相關工作
- 8 結論與討論
利用多模態表示提升淘寶展示廣告效果:挑戰、方法與洞察
Sheng Xiang-Rong, Yang Feifan, Gong Litong, Wang Biao, Chan Zhangming, Zhang Yujing, Cheng Yueyao, Zhu Yong-Nan, Ge Tiezheng, Zhu Han, Jiang Yuning, Xu Jian, Zheng Bo
摘要
盡管多模態數據在提升模型準確性方面的潛力已得到認可,但包括淘寶展示廣告系統在內的許多大規模工業推薦系統,仍主要依賴模型中的稀疏ID特征。在這項工作中,我們探索了利用多模態數據提升推薦準確性的方法。我們首先確定了在工業系統中高效且經濟地采用多模態數據的關鍵挑戰。為應對這些挑戰,我們引入了一個兩階段框架,包括:1)預訓練多模態表示以捕捉語義相似性,2)將這些表示與現有基于ID的模型集成。此外,我們詳細介紹了生產系統的架構,該架構旨在促進多模態表示的部署。自2023年中期集成多模態表示以來,淘寶展示廣告系統的性能顯著提升。我們相信,我們收集到的見解將為尋求在其系統中利用多模態數據的從業者提供寶貴的資源。
1 引言
傳統上,淘寶展示廣告系統中使用的推薦模型,與許多其他工業系統一樣,主要依賴離散的ID作為特征。盡管基于ID的模型被廣泛使用,但它們存在固有缺陷,例如無法捕捉多模態數據中包含的語義信息。
為解決這些問題,某些工業系統已嘗試將多模態數據納入基于ID的模型中[26,29]。通常,這些方法采用兩階段框架,包括:1)通過通用或特定場景的預訓練獲取多模態表示,2)將這些表示集成到推薦模型中。
盡管取得了這些進展,但許多工業系統仍然完全依賴ID特征。這通常是因為擔心多模態數據帶來的性能提升可能無法補償其部署成本。這些成本包括預訓練多模態編碼器、為新物品增量生成表示,以及對在線服務器和近線訓練系統進行其他必要升級。因此,多模態表示的成功集成取決于能否在提升性能優勢的同時,最大限度地降低部署成本。
為實現這兩個關鍵目標,需要解決三個實際挑戰:
- 預訓練任務的設計:多模態表示在提升性能方面的有效性取決于它們能否提供有意義的語義信息,而這是ID特征難以捕捉的。設計預訓練任務以確保多模態表示能夠封裝此類語義信息至關重要。
- 多模態表示的集成:ID特征與多模態表示之間的固有差異(例如訓練輪次的不同),需要采用能夠有效將多模態表示納入基于ID的模型的方法。這些方法應利用每種特征類型的優勢,以提升模型的整體性能。
- 生產系統的設計:整個生產工作流程,包括為新物品生成多模態表示并將其最新應用于下游任務,都應設計為高效的。
為應對這些挑戰,我們采用了如圖1所示的兩階段框架。具體而言,在預訓練階段,我們提出了語義感知對比學習(SCL)方法。在此階段,我們利用用戶的搜索查詢和后續的購買行為來構建語義相似的樣本對,捕捉電子商務場景中與用戶最相關的語義相似維度。對于負樣本,我們從一個大型內存庫中提取。SCL方法使多模態表示能夠有效衡量物品之間的語義相似性。
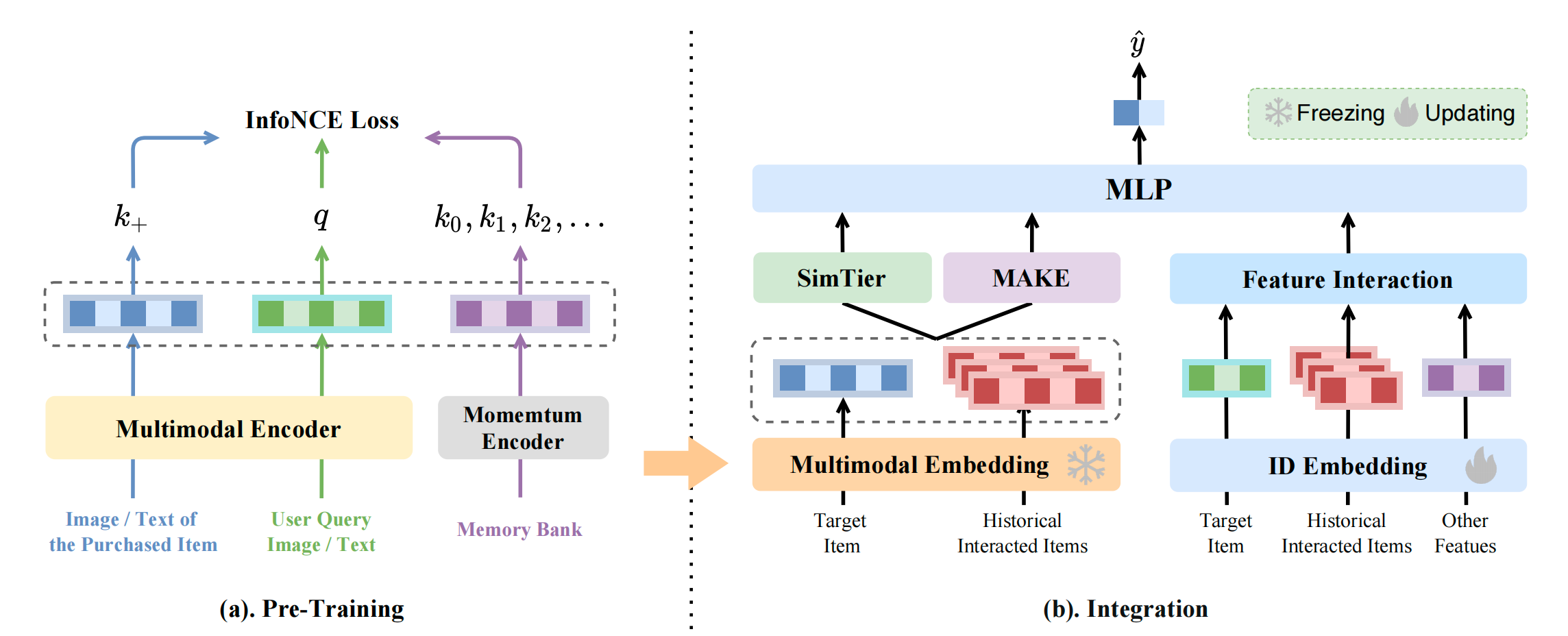
在獲得高質量的多模態表示后,我們提出了兩種將這些表示納入現有基于ID的模型的方法。首先,我們開發了一種名為SimTier的方法,用于衡量目標物品與用戶先前交互過的物品之間的相似程度。生成的SimTier向量隨后與其他嵌入連接,并輸入到后續層中。此外,為解決多模態表示與ID嵌入之間訓練輪次的差異,我們引入了多模態知識提取器(MAKE)模塊。MAKE模塊將與多模態表示相關的參數優化與基于ID的模型的參數優化分離,從而能夠更有效地學習與多模態表示相關的參數。
我們還介紹了便于多模態表示部署的生產系統設計。具體而言,該系統為新引入的物品實時生成多模態表示,并確保這些表示可立即用于訓練基礎設施和在線預測服務器。這種設計實現了極短的延遲——從物品引入到模型使用其多模態表示僅需幾秒鐘。自2023年中期以來,多模態表示已在淘寶展示廣告系統中部署,帶來了顯著的性能提升。
2 預備知識
在深入探討細節之前,我們首先介紹工業系統不同階段(包括檢索[15,38]、預排序[27,34]和排序階段[1,3,7,10,36])中使用的典型基于ID的模型結構。
推薦模型中的ID特征
常見的推薦模型在包含數十億ID特征的大規模數據集上進行訓練[16,32]。這些ID特征用于表示用戶畫像、用戶歷史交互物品、目標物品(待預測)和上下文信息。例如,我們可以用物品ID和類別ID表示目標物品,用一系列對應的物品ID和類別ID表示用戶歷史交互物品。
基于ID的模型結構
基于ID的推薦模型采用嵌入和多層感知機(MLP)架構,通常包含歷史行為建模模塊[35,36]。首先,所有ID特征都轉換為嵌入。然后,歷史行為建模模塊通過分析目標物品嵌入與用戶歷史交互物品嵌入之間的相關性,衡量用戶對目標物品的興趣。具體而言,這些模塊通過聚合目標物品和歷史交互物品的嵌入生成固定長度的向量。這些向量隨后與其他ID嵌入連接,形成后續MLP的輸入,MLP產生最終預測。
3 多模態表示的預訓練
關于多模態數據,其利用可以改善歷史行為建模。具體而言,多模態數據可用于衡量目標物品與用戶歷史交互物品之間的語義相似性。以物品圖像為例,它們可用于衡量目標物品圖像與歷史交互物品圖像之間的視覺相似性。直觀地說,語義相似性越高,表明目標物品與用戶歷史行為的相似性越強,用戶感興趣的可能性就越高。這一見解強調了設計預訓練任務以確保多模態表示能夠有效辨別物品對之間語義相似性的重要性。
3.1 語義感知對比學習
為了獲得能夠辨別語義相似性的表示,我們提出了語義感知對比學習(SCL)方法,該方法吸引語義相似的樣本對,排斥不相似的樣本對。為此,必須定義用于監督的語義相似和不相似對。為了理解這一點的重要性,考慮圖5所示的示例,三個枕頭幾乎相同,但存在細微差異,如圖案不同或外觀略有不同。如果語義相似對的定義不充分,表示可能無法捕捉到這些細微差異。事實上,這些細微差別經常被專注于捕捉一般概念的表示所忽略。

下面,我們將詳細闡述針對電子商務場景的預訓練數據集構建和對比學習過程的優化策略。
3.2 預訓練數據集的構建
在電子商務環境中,用戶的搜索查詢和后續的購買行為通常表明查詢與購買物品之間存在很強的語義相似性。例如,如果用戶搜索枕頭的圖像并隨后購買了一個枕頭,這一系列動作表明兩個圖像(查詢圖像和購買物品的圖像)在語義上足夠相似,能夠滿足用戶的購買意圖。因此,如表1所示,在訓練文本編碼器時,我們將用戶搜索查詢的文本與他們最終購買物品的標題配對,作為語義相似對。同樣,對于圖像模態,用戶的圖像查詢(從淘寶的圖像搜索場景獲得)與后續購買物品的圖像配對。這種配對策略自然捕捉了電子商務場景中與用戶最相關的語義相似維度,反映了影響他們購買決策的因素。

對于每個語義相似對,我們將所有其他樣本視為潛在的不相似樣本,這可以通過使用當前小批量中的樣本作為負樣本來實現。為了進一步提高模型性能,我們旨在增加訓練期間可用的負樣本數量。具體而言,我們從MoCo[12]中獲得靈感,采用一種通過動量更新模型的技術,便于從更大的內存庫中采樣更多負樣本。構建負對的更復雜策略,例如識別硬負樣本[23],將在6.1.2節中詳細闡述。
3.3 優化
我們使用備受認可的InfoNCE損失[19]作為損失函數。給定一個編碼后的查詢q及其對應的編碼正樣本k,以及表示內存庫中編碼樣本表示集合的 k 0 , k 1 , . . . , k K k_{0}, k_{1}, ..., k_{K} k0?,k1?,...,kK? (其中K表示內存庫大小[12]),InfoNCE損失使用點積來衡量相似性(所有表示均進行L2歸一化)。如公式1所示,當查詢q與指定的正樣本k緊密匹配且與內存庫中的所有其他樣本不同時,損失值會降低。
L InfoNCE = ? log ? exp ? ( q ? k + ) / τ ∑ i = 0 K exp ? ( q ? k i ) / τ L_{\text{InfoNCE}} = -\log \frac{\exp \left( q \cdot k_+ \right) / \tau}{\sum_{i=0}^{K} \exp \left( q \cdot k_i \right) / \tau} LInfoNCE?=?log∑i=0K?exp(q?ki?)/τexp(q?k+?)/τ?
通過這種方式,SCL方法使表示能夠辨別可比物品之間的細微差異,這對于推薦模型至關重要。
4 與推薦模型的集成
將多模態表示集成到基于ID的推薦模型中的一種直接方法是將這些多模態表示與目標物品和用戶過去交互物品的ID嵌入連接[9,29]。連接后,使用用戶行為建模模塊,隨后將其輸入MLP進行最終預測。盡管這種方法簡單,但我們發現性能提升有限。為了調查這一問題,我們分享了我們的觀察和見解。
4.1 觀察和見解
我們首先分享關于納入多模態表示的觀察和見解。
觀察1:簡化多模態表示的使用可提高性能。我們的研究表明,將多模態表示直接集成到基于ID的模型中并未獲得最佳性能,6.3節將對此進行更詳細的解釋。出現此問題的原因是,在與ID嵌入聯合訓練期間,與多模態表示相關的參數(例如與多模態表示連接的MLP參數)未得到充分學習[29]。相比之下,簡化多模態表示使用的策略(例如將其轉換為語義ID(從而用ID表示嵌入向量))[26,29]似乎能提供更好的性能。
多模態信息整合的方式
- 直接整合:將多模態信息作為特征直接輸入推薦模型。此方法操作簡單,但因多模態信息的embedding空間與推薦模型學習的參數空間存在一致性差異,往往效果不佳。
- 間接整合:先通過小模型對多模態信息進行微調,再將微調后的embedding信息輸入推薦模型。該方式借助小模型對齊多模態信息的embedding空間與推薦模型的學習空間,提升了兩者的一致性,非常重要,優化了整合效果。
通過對比可見,間接整合在協調空間一致性上更具優勢,為多模態信息與推薦模型的融合提供了更有效的路徑。
觀察2:基于ID的模型和基于多模態的模型存在訓練輪次差異。在工業場景中,基于ID的模型通常僅訓練一個輪次以避免過擬合[33]。相比之下,計算機視覺和自然語言處理領域的模型通常經過多個輪次的訓練。一個自然的問題是:基于多模態的推薦模型的理想訓練輪次是多少?為了回答這個問題,我們開發了一個僅使用多模態表示作為輸入特征(不使用任何ID特征)的推薦模型,并分析了其性能隨訓練輪次的變化情況。
詳細的收斂曲線如圖3所示。我們發現,利用多模態數據的模型在同一數據集上進行多個輪次的訓練時受益,其性能隨著輪次的增加而顯著提升。相比之下,基于ID的模型存在單輪過擬合現象,模型性能在第二輪訓練開始時急劇下降[33]。結果表明,與多模態表示相關的參數需要更多輪次才能正確收斂,這與基于ID的模型的行為形成對比。因此,當將多模態表示納入基于ID的模型并僅訓練一個輪次時,存在與多模態相關的參數可能未得到充分訓練的風險。

4.2 方法一:SimTier
觀察1表明需要簡化多模態表示的使用。為此,我們提出了一種簡單而有效的方法SimTier。如圖2(a)所示,SimTier首先計算目標候選物品的多模態表示 v c v_{c} vc? 與用戶歷史交互物品的多模態表示 { v i } i = 1 L \{v_{i}\}_{i=1}^{L} {vi?}i=1L? 之間的點積相似性:
s i = v i ? v c , ? i ∈ { 1 , … , L } . (2) s_{i} = v_{i} \cdot v_{c}, \quad \forall i \in \{1, \ldots, L\} \,. \tag{2} si?=vi??vc?,?i∈{1,…,L}.(2)
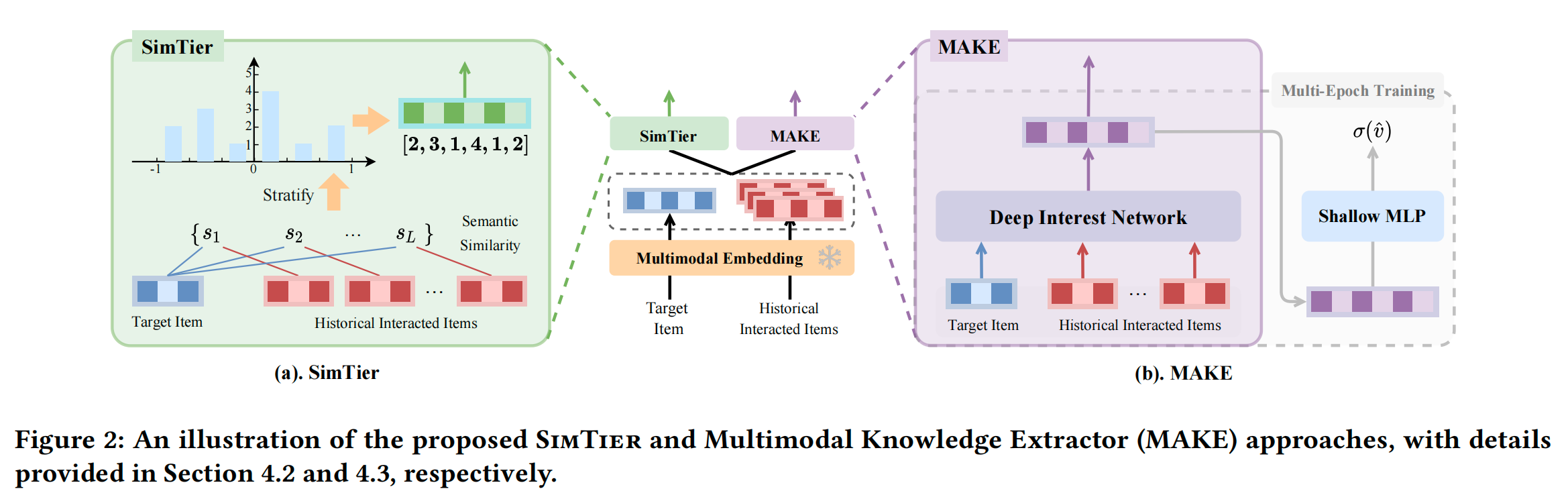
在計算相似性分數后,我們將[-1.0,1.0]的分數范圍劃分為N個預定義的層級。在每個層級中,我們計算落入該對應范圍的相似性分數的數量。因此,我們獲得一個N維向量,每個維度表示對應層級中相似性分數的數量。這樣,SimTier有效地將一組高維多模態表示轉換為一個N維向量,該向量封裝了目標物品與用戶歷史交互之間的相似程度。獲得的N維向量隨后與其他嵌入連接,并輸入到后續的MLP中。我們在算法1中提供了SimTier的偽代碼。
4.3 方法二:多模態知識提取器(MAKE)
為解決ID特征與多模態表示所需訓練輪次的差異,我們引入了多模態知識提取器(MAKE)模塊,將與多模態相關的參數優化與ID特征的參數優化分離。
多模態相關參數的多輪訓練
MAKE模塊的目標是通過多個輪次的訓練對與多模態表示相關的參數進行預訓練,以確保其收斂。在實踐中,我們利用CTR預測任務作為推薦預訓練任務。如圖2(b)所示,我們首先開發了一個基于DIN的用戶行為建模模塊[36]。該模塊處理目標物品和歷史交互物品的預訓練多模態表示,生成輸出 v M A K E v_{MAKE} vMAKE? :
v MAKE = DIN ( { v i } i = 0 L , v c ) . (3) v_{\text{MAKE}} = \text{DIN}\left( \left\{ v_i \right\}_{i=0}^{L}, v_c \right) \,. \tag{3} vMAKE?=DIN({vi?}i=0L?,vc?).(3)
然后, v M A K E v_{MAKE} vMAKE? 被輸入到一個四層多層感知機( M L P M M A K E MLP M_{MAKE} MLPMMAKE? )中,并生成對數幾率 v ^ \hat{v} v^ :
v ^ = MLP MAKE ( v MAKE ) . (4) \hat{v} = \text{MLP}_{\text{MAKE}}\left( v_{\text{MAKE}} \right) \,. \tag{4} v^=MLPMAKE?(vMAKE?).(4)
知識利用
獲取向量 v M A K E v_{MAKE} vMAKE? 后,后續步驟是將其集成到下游推薦任務中。實際上,我們將 v M A K E v_{MAKE} vMAKE? 和 M L P M A K E MLP_{MAKE} MLPMAKE? 的中間輸出與其他嵌入連接,并將此組合數據輸入到后續層中。MAKE模塊多輪訓練的實現調和了ID嵌入和多模態表示所需的訓練輪次差異,從而實現了更好的性能。
5 在線部署的工業設計
在工業環境中,新物品(包括廣告)不斷創建。為了維持對這些新物品的預測準確性,推薦模型實時獲取新物品的多模態表示至關重要。這需要能夠持續為新物品生成多模態表示,并由近線訓練器和在線服務器實時利用。我們的在線系統示意圖如圖4所示。

為了實現多模態表示的實時生成,在引入新物品后,系統會自動向預訓練的多模態編碼器發起請求,以計算這些新物品的多模態表示。一旦推斷完成,這些表示將被發送到多模態索引表。在此步驟之后,下游訓練系統和推理服務器能夠從索引表中檢索多模態表示,從而實現近線訓練和實時在線預測功能。這一過程確保了從物品引入到模型使用其多模態表示之間的延遲極小——僅需幾秒鐘。
6 實驗
在本節中,我們深入研究了一個將圖像表示集成到CTR預測模型中的案例研究,旨在提供全面的分析。值得注意的是,我們的方法具有通用性,能夠容納多種模態類型(如文本和視頻),并可應用于推薦系統的不同階段。
6.1 實驗設置
6.1.1 數據集
我們首先詳細介紹預訓練階段和下游集成階段使用的數據集。
- 預訓練數據集:在預訓練數據集中,每個樣本包含一個查詢(用戶的圖像查詢)和一個正樣本(購買物品的圖像)。為了進一步提高性能,我們還添加了一個硬負樣本(由正樣本觸發的點擊物品的圖像)。預訓練數據集的一個案例如圖5所示。
- CTR預測數據集:CTR預測數據集來自淘寶展示廣告系統,使用一周的展示日志。
6.1.2 對比預訓練方法
我們采用了一系列廣泛使用的預訓練方法進行比較。
- CLIP-O:CLIP-O指的是使用通用數據集預訓練的CLIP視覺編碼器(CLIP-ViTB/16)[21]。
- CLIP-E:CLIP-E是基于CLIP-O模型在電子商務場景中使用對齊的物品描述和物品圖像進行微調的版本。
- SCL:提出的語義感知預訓練方法。SCL方法采用動量對比(MoCo)來擴展負樣本集。此外,SCL對每個<查詢,正樣本,負樣本>三元組應用三元組損失[23],以有效辨別硬負樣本。我們的實驗分析調查了排除三元組損失和MoCo的影響,以評估它們對整體性能的貢獻。
6.1.3 對比推薦方法
我們采用了一系列廣泛使用的集成方法進行比較。
- 基于ID的模型(生產基線):基線是支撐我們在線系統的基于ID的模型。
- Vector:Vector方法將預訓練的多模態表示用作每個物品的輔助信息,并在模型中將其與其他ID嵌入連接。
- SimScore:相似性分數(SimScore)可以視為Vector方法的簡化版本。每個歷史交互物品與目標物品的語義相似性分數用作輔助信息。
- SimTier和MAKE:提出的SimTier和MAKE方法。
6.1.4 評估指標
我們評估了所提出方法的預訓練性能和CTR預測性能。
- 評估預訓練方法:在我們的大量實驗中,我們發現Top-N準確率(Acc@N)與下游推薦模型的性能密切相關。具體而言,Acc@N指標量化了表示識別語義相似物品的能力:
其中,D表示測試集的大小。術語 q i q_{i} qi? 和 p i p_{i} pi? 分別對應第i個樣本的查詢和正樣本。 S = { p o s i } i = 1 D S = \{pos_{i}\}_{i=1}^{D} S={posi?}i=1D? 表示包含所有正樣本的集合, T o p N Top_{N} TopN? 是一個函數,利用集合S中的多模態表示為每個查詢檢索前N個結果。符號 I ( ? ) I(\cdot) I(?) 表示指示函數,當第i個 p i p_{i} pi? 在 q i q_{i} qi? 的檢索結果中時,其值為1,否則為0。
- 評估推薦方法:我們使用AUC和組AUC(GAUC)指標評估CTR預測模型的有效性,其中更高的AUC/GAUC值表示更好的排名能力[25,36,37]。
6.2 預訓練數據集上的性能
6.2.1 使用準確率評估預訓練表示有效性的基本原理
衡量預訓練表示有效性的最精確方法是測量集成多模態表示后推薦準確性的提升。然而,這種評估過程對于預訓練方法的迭代可能很漫長,因此需要一個中間指標來快速評估預訓練的多模態表示。
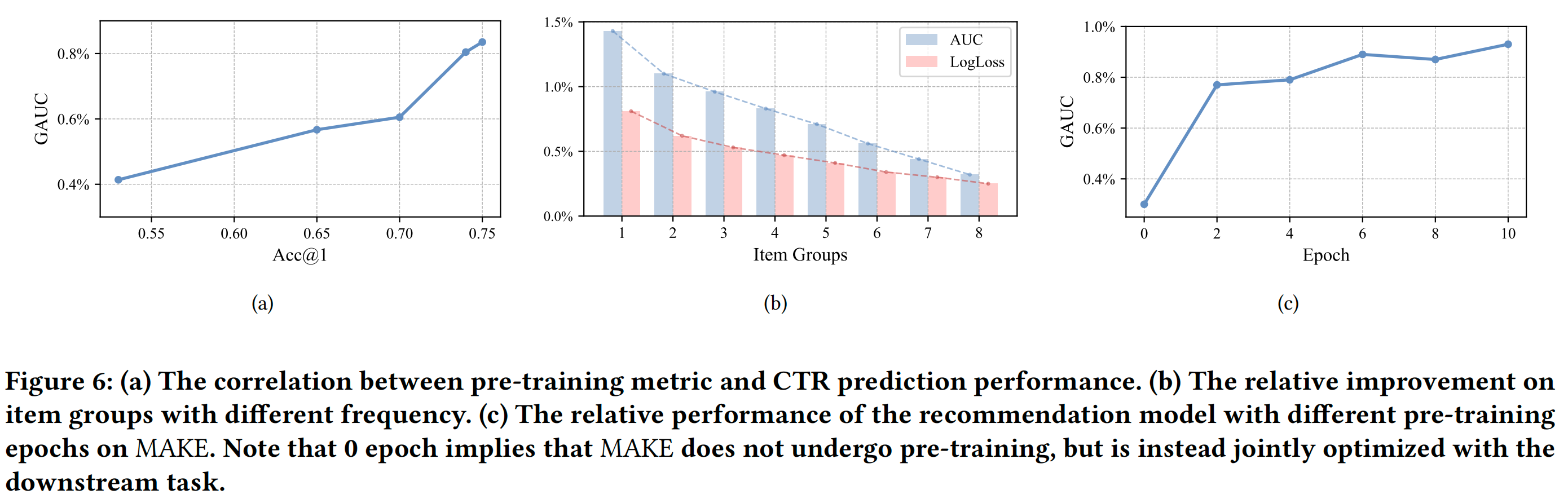
在我們的研究中,我們觀察到預訓練準確率的提升與推薦性能的提升之間存在很強的相關性。我們在圖6(a)中說明了這種關系,從中可以看出,Acc@1的提升與GAUC的提升一致。因此,我們主要依靠預訓練準確率來確定多模態表示的質量。探索其他潛在的中間指標來評估預訓練的多模態表示仍然是未來工作的一個有趣課題。
6.2.2 語義感知對比學習的重要性
為了研究不同預訓練任務如何影響多模態表示的質量,我們進行了一系列實驗。結果如表2所示,提供了兩個重要觀察結果。首先,提出的SCL預訓練方法優于其他語義相似性不可知的方法,強調了語義感知學習的必要性。其次,結合動量對比(MoCo)[12]和三元組損失[23]等技術進一步提升了多模態表示的質量,表明負樣本的選擇對性能有重大影響。
6.3 CTR預測數據集上的性能
6.3.1 不同集成策略的性能
在CTR預測數據集上,我們將提出的SimTier和MAKE與其他方法進行了評估。總體結果如表3所示,從中可以注意到兩個觀察結果。首先,SimTier和MAKE顯著優于其他方法。其次,SimTier和MAKE的組合可以進一步提升性能,與基于ID的模型相比,GAUC提高1.25%,AUC提高0.75%。上述結果證明了所提出方法在將多模態表示集成到基于ID的模型中的有效性。
6.3.2 MAKE不同訓練輪次的性能
為了探索MAKE的多輪預訓練對最終推薦性能的影響,我們進行了實驗,其中MAKE在集成到推薦模型之前進行了不同輪次的預訓練。結果如圖6(c)所示。請注意,0輪表示MAKE不進行預訓練,而是與下游任務聯合優化。結果表明,隨著MAKE預訓練輪次的增加,最終推薦模型的性能也隨之提高。這表明MAKE的多輪訓練有效地提升了模型性能。
6.3.3 罕見物品的性能
為了檢驗多模態表示對長尾物品的泛化能力,我們評估了按出現頻率分類的物品組的相對提升。我們將所有物品分為八組,第1組包含訓練數據中頻率最低的物品,第8組包含頻率最高的物品。然后,我們計算每組的AUC相對提升為 ∣ A U C M M ? A U C I D ∣ / A U C I D |AUC_{MM} - AUC_{ID}| / AUC_{ID} ∣AUCMM??AUCID?∣/AUCID? ,其中MM表示SimTier和MAKE方法的組合,ID表示基于ID的生產基線模型。我們還計算LogLoss的相對提升為 ∣ L o g L o s s M M ? L o g L o s s I D ∣ / L o g L o s s I D |LogLoss_{MM} - LogLoss_{ID}| / LogLoss_{ID} ∣LogLossMM??LogLossID?∣/LogLossID? 以衡量校準能力[11,24]。圖6(b)中的結果表明,多模態表示在所有組中均表現出顯著提升,證明了我們的模型對不同類型物品的有效性。同時,我們看到低頻物品的提升更為顯著。結果表明,多模態表示可以解決基于ID的模型在長尾物品上的不足,提高預測準確性。
6.4 在線性能
自2023年中期以來,多模態表示已集成到淘寶展示廣告系統的預排序、排序和重排序模型中,帶來了顯著的性能提升。例如,在CTR預測模型中納入圖像表示后,整體CTR提高了3.5%,RPM提高了1.5%,ROI提高了2.9%。值得注意的是,對新廣告(最近24小時內創建的)的影響更為顯著,CTR提高了6.9%,RPM提高了3.7%,ROI提高了7.7%。新廣告的顯著提升也驗證了多模態數據在緩解冷啟動問題方面的有效性。
7 相關工作
目前,ID特征構成了工業推薦模型的核心[2,5,7,14,31,33,35,36]。盡管它們被廣泛采用,但ID特征存在顯著局限性,包括捕捉語義信息的挑戰和持續存在的冷啟動問題[9,18,22,28]。相比之下,多模態數據提供了豐富的語義信息,促使許多研究探索將其納入推薦模型。一些研究調查了在推薦模型訓練的同時以端到端方式學習多模態表示的潛力[4,8,30]。然而,此類過程所需的大量計算資源通常使其無法在工業系統中采用。因此,我們的重點是兩階段范式[6,9,13,17,20,26,29],并旨在分享我們的方法和寶貴見解。
8 結論與討論
基于多模態的推薦已引起關注數十年。然而,將多模態表示集成到工業系統中面臨許多艱巨挑戰,尤其是在表示質量、集成方法和系統實現領域——這些挑戰在大規模工業系統的背景下更為突出。
在本研究中,我們深入探討了這些挑戰,并分享了我們用于預訓練和納入多模態表示的方法。此外,我們提供了在線部署階段的經驗見解。我們相信,我們在這一過程中積累的策略和見解將為那些旨在加速工業系統中基于多模態推薦采用的人士提供寶貴的資源。

 的詳細分類、對比及解決方案)





![[Java微服務組件]注冊中心P3-Nacos中的設計模式1-觀察者模式](http://pic.xiahunao.cn/[Java微服務組件]注冊中心P3-Nacos中的設計模式1-觀察者模式)











