目錄
引言
1 HDFS高可用架構實現
1.1 基于QJM的NameNode HA架構
1.2 QJM vs NFS實現對比
2 故障切換流程與ZooKeeper作用
2.1 自動故障轉移流程
2.2 狀態轉換機制
3 數據恢復與副本管理
3.1 DataNode故障處理流程
4 快照與數據保護機制
4.1 HDFS快照架構
4.2 快照使用場景示例
5 HA配置參數示例
6 總結
引言
在大數據生產環境中,Hadoop分布式文件系統(HDFS)的高可用性(HA)和容錯能力是確保業務連續性的關鍵要素。
1 HDFS高可用架構實現
1.1 基于QJM的NameNode HA架構
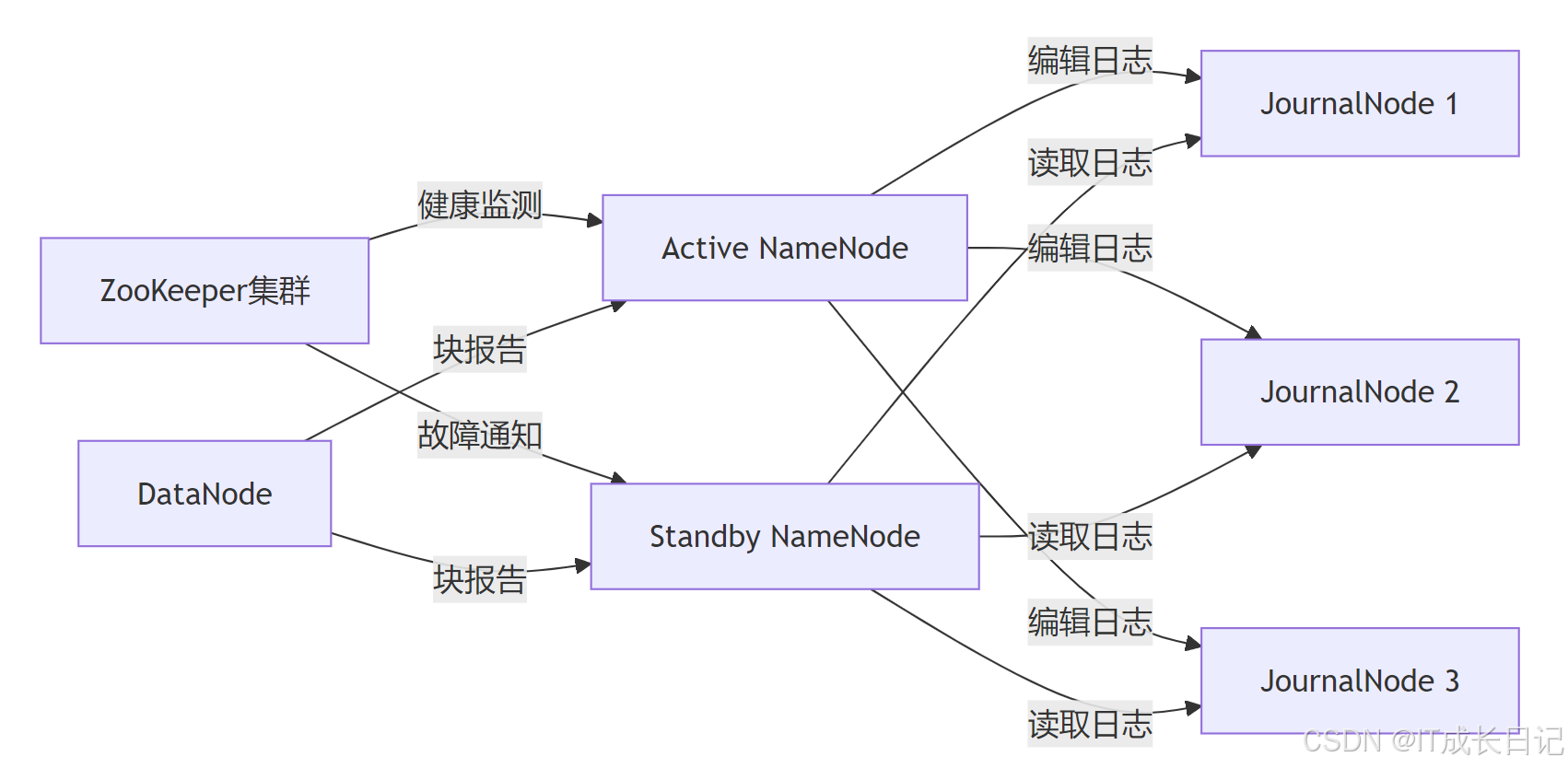
核心組件說明:
- Active/Standby NameNode:主備雙節點,共享元數據
- JournalNode集群:通常3個節點組成仲裁,存儲編輯日志(Edits)
- ZooKeeper集群:協調故障檢測和主備切換
- 共享存儲:QJM(Quorum Journal Manager)或NFS
1.2 QJM vs NFS實現對比
QJM優勢:
- 專用輕量級日志系統
- 消除單點故障
- 不需要額外硬件
- 支持多數寫成功即確認
2 故障切換流程與ZooKeeper作用
2.1 自動故障轉移流程
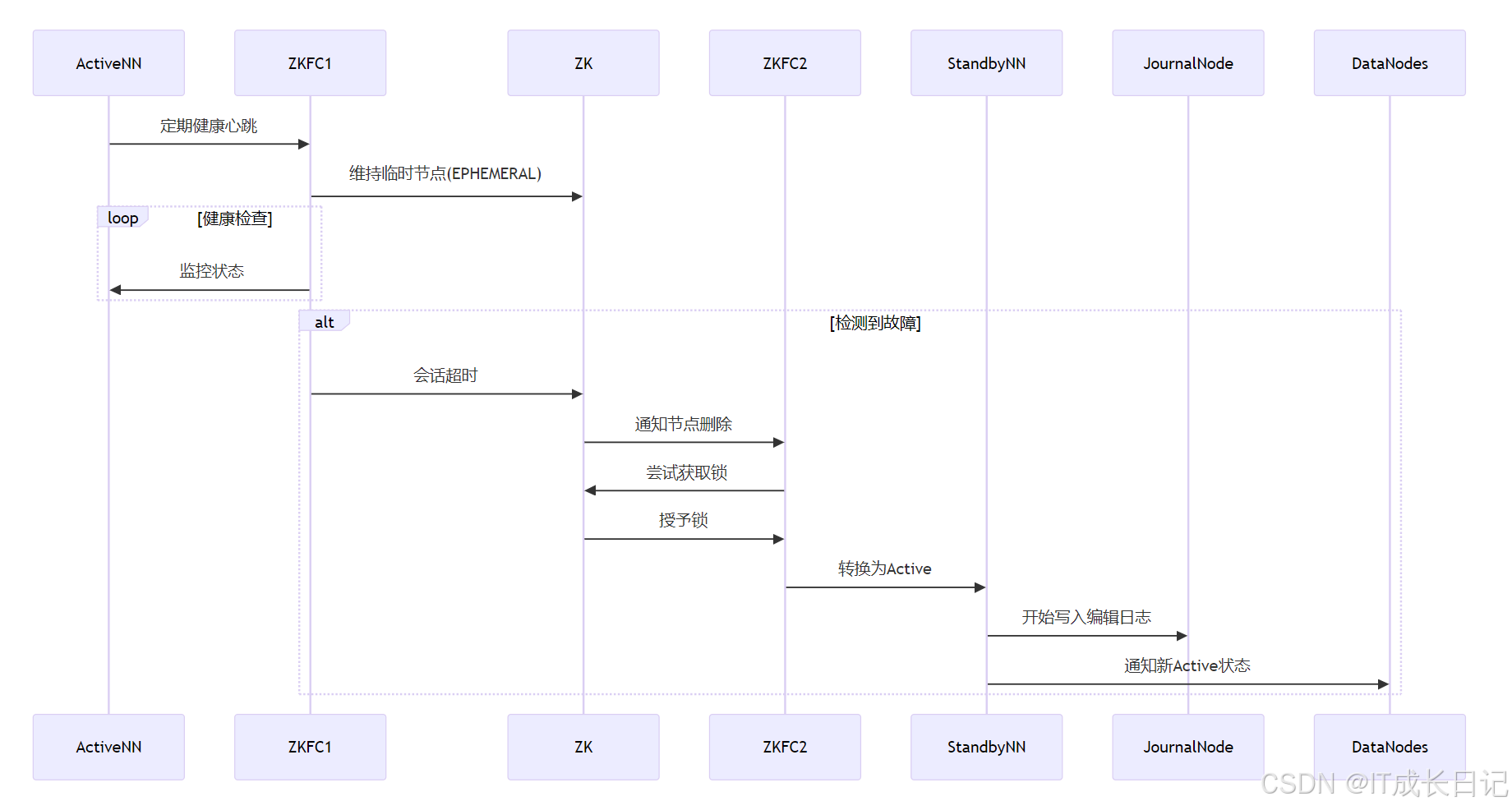
- 關鍵角色
ZKFC(ZooKeeper Failover Controller):每個NN的守護進程ZooKeeper:
- 維護活動NN的臨時節點
- 協調故障轉移鎖
- 通知狀態變更
2.2 狀態轉換機制
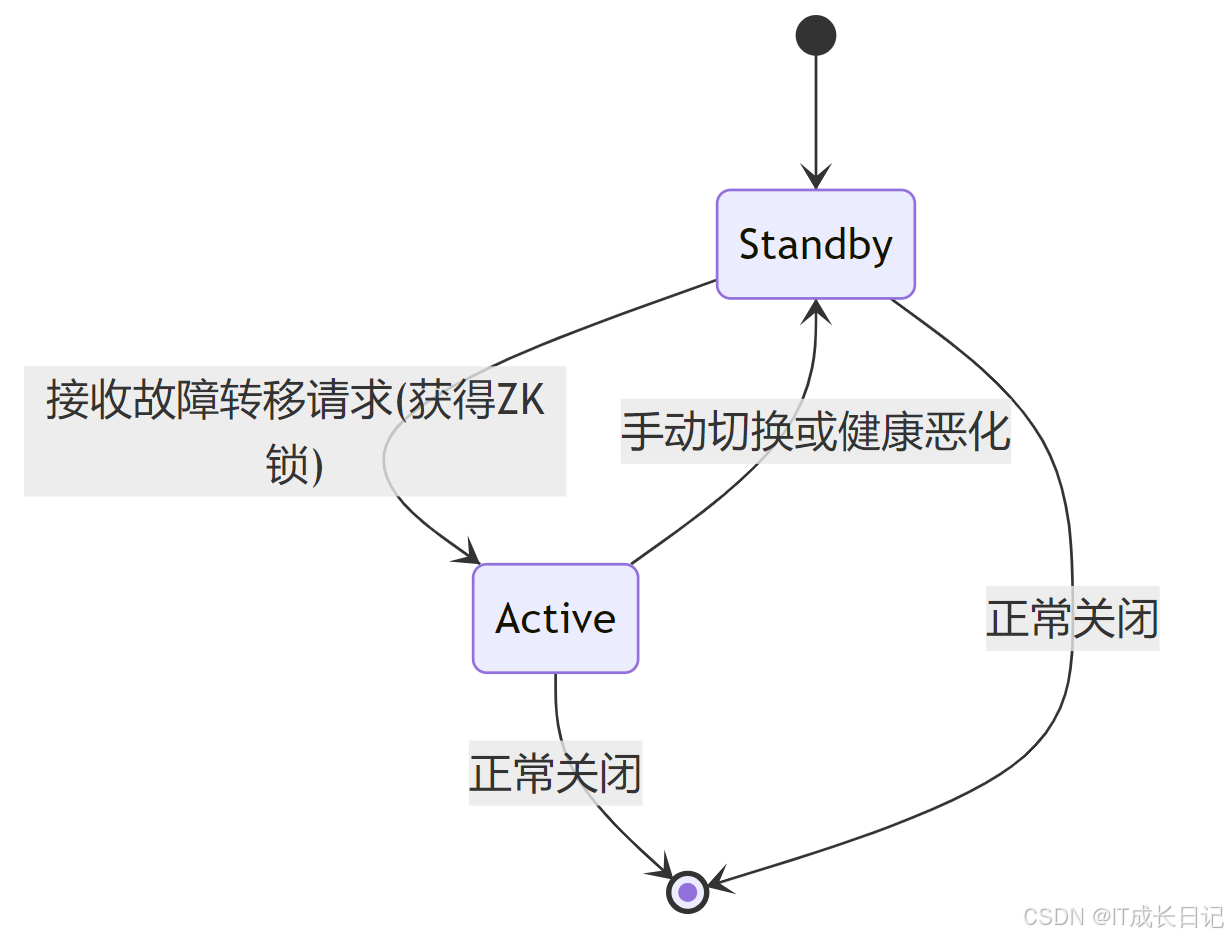
3 數據恢復與副本管理
3.1 DataNode故障處理流程

- 關鍵恢復策略:
副本重建:
- 優先選擇同一機架的存活副本
- 后臺線程控制復制速度
- 動態調整復制優先級
再平衡操作:
- 定期執行hdfs balancer
- 閾值控制(默認10%差異)
- 網絡帶寬限制參數
4 快照與數據保護機制
4.1 HDFS快照架構

快照特性:
- 瞬間創建(僅記錄差異)
- 目錄級別快照
- 只讀不可變
- 不影響正常操作
4.2 快照使用場景示例
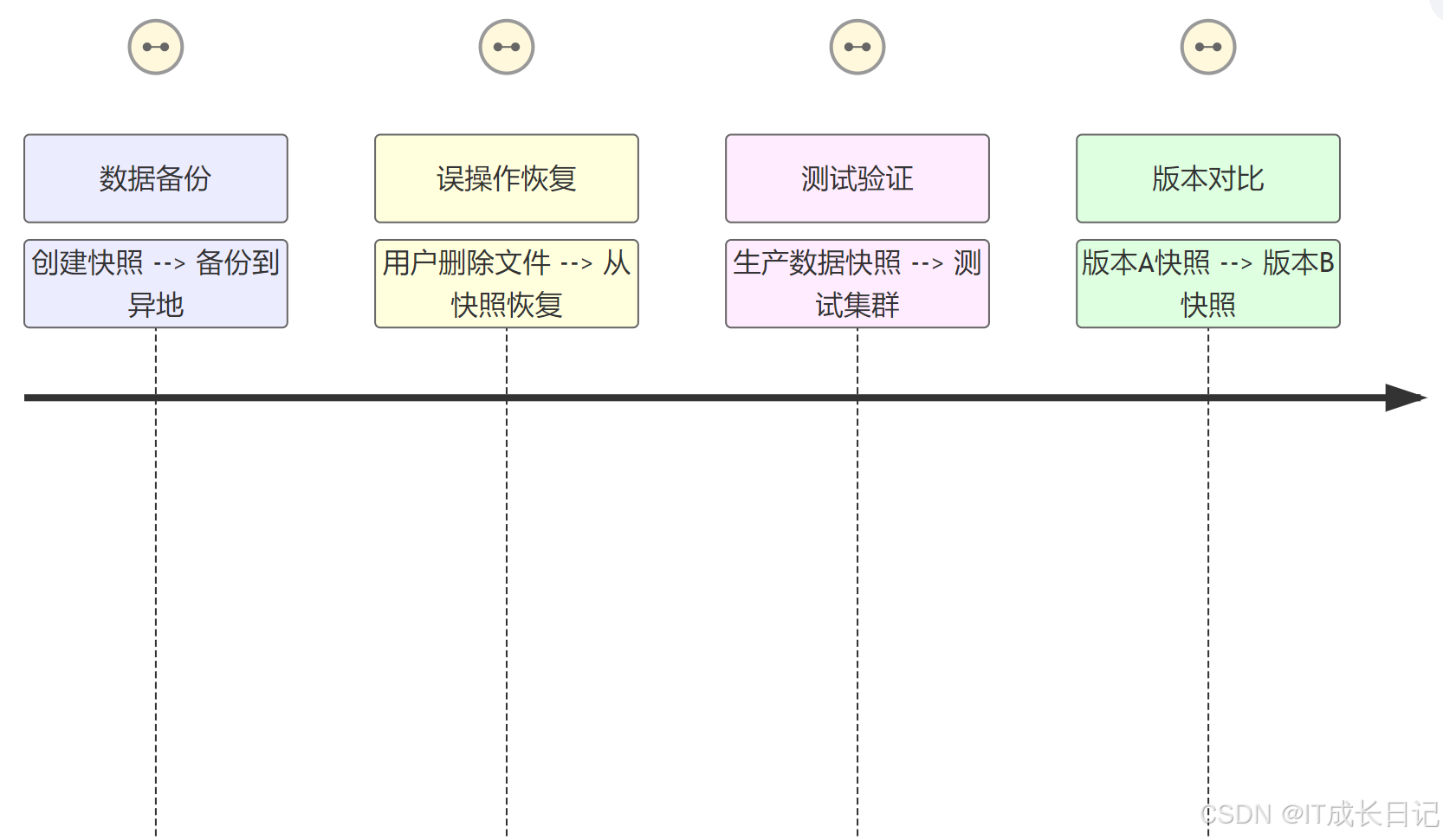
5 HA配置參數示例
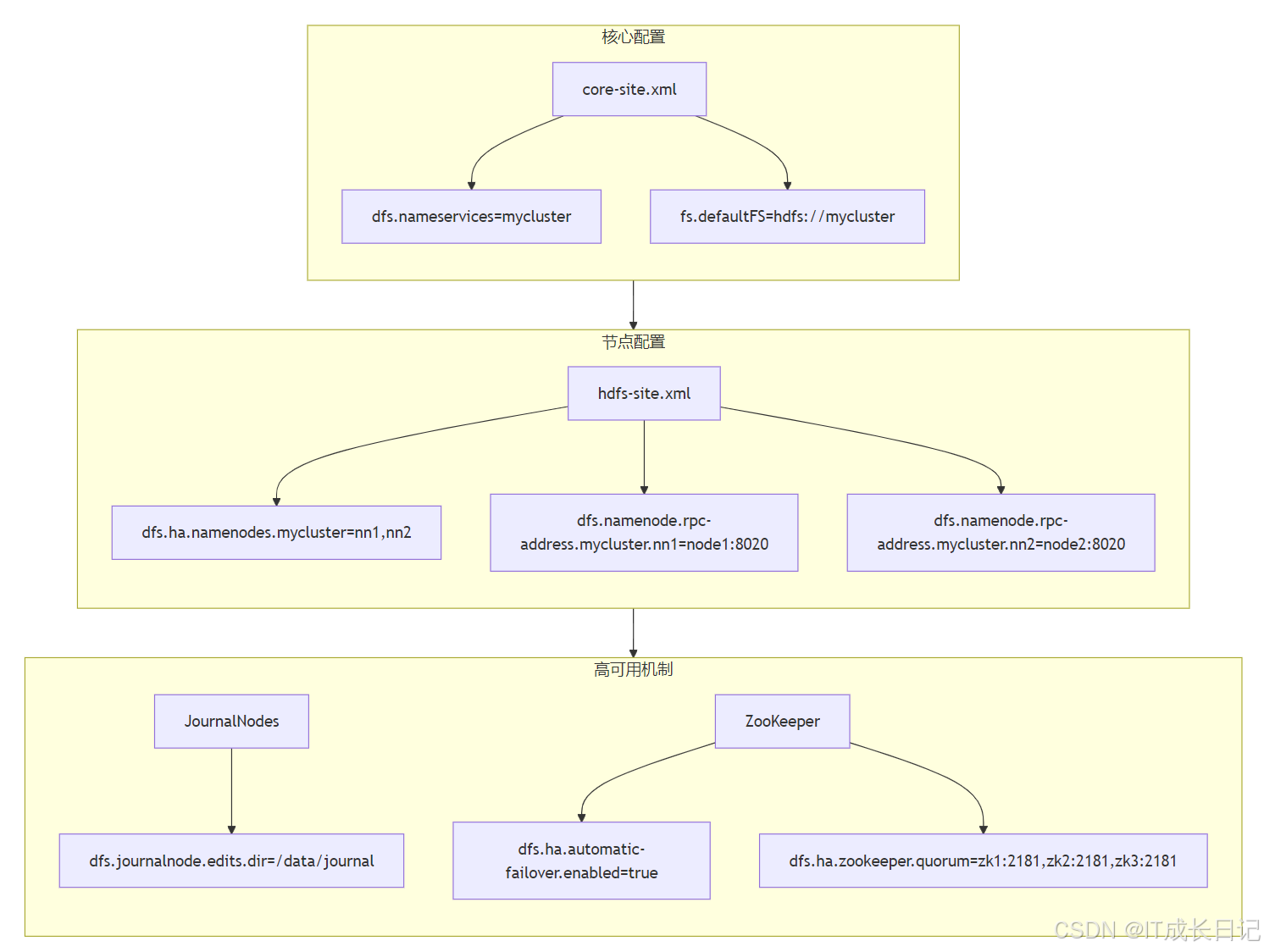
6 總結
HDFS通過多層次的高可用設計提供了企業級可靠性保障:
- 架構層:主備NameNode+QJM的優雅設計消除單點故障
- 流程層:基于ZooKeeper的自動故障轉移實現秒級切換
- 數據層:智能副本管理確保數據持久性
- 保護層:快照功能提供額外數據安全保障



















