在數據庫性能優化領域,TPC-H 測試集是一個經典的基準測試工具,常用于評估數據庫系統的查詢性能。本文將基于 TPCH 測試集中的第 20個查詢,結合 PawSQL 自動化優化工具,詳細分析如何通過 SQL 重寫和索引設計,將查詢性能從 321 秒提升到 0.2 秒,性能提升高達1541倍。
1. 背景介紹:一個典型的多表關聯分析查詢
TPC-H作為業界公認的數據庫性能測試基準,其第20號查詢(Q20)是一個極具挑戰性的復雜分析查詢。這個查詢的業務場景是:識別阿爾及利亞('ALGERIA')地區庫存充足的供應商,具體條件是這些供應商提供的綠色('green%')零件的庫存量(ps_availqty)超過該零件在過去一年內訂單總量的一半。
原始SQL語句如下:
select?s_name, s_address
from?supplier, nation
where?s_suppkey?in?(select?ps_suppkeyfrom?partsuppwhere?ps_partkey?in?(select?p_partkeyfrom?partwhere?p_name?like?'green%')and?ps_availqty?>?(select?0.5?*?sum(l_quantity)from?lineitemwhere?l_partkey?=?ps_partkeyand?l_suppkey?=?ps_suppkeyand?l_shipdate?>=?date?'1997-01-01'and?l_shipdate?<?date?'1997-01-01'?+?interval?'1'?YEAR)
)
and?s_nationkey?=?n_nationkey?
and?n_name?=?'ALGERIA'
order?by?s_name在實際測試環境中,這個查詢的執行時間達到了驚人的321秒,完全無法滿足業務系統的要求。
2. 性能瓶頸分析:為什么這么慢?
?
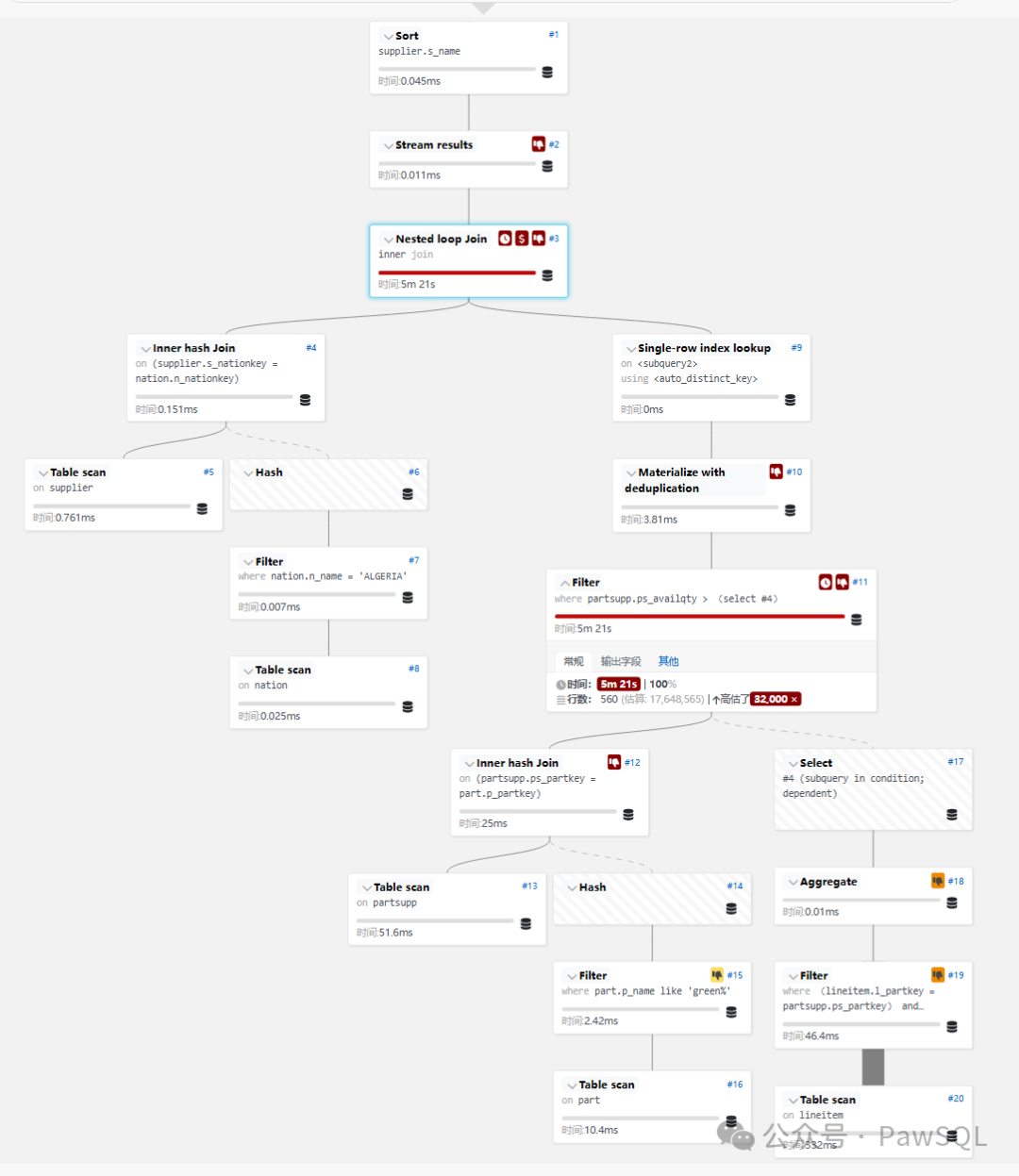
從執行計劃可以看出主要性能問題:
-
子查詢執行次數多:相關子查詢被執行了848次,每次耗時約378ms
-
表掃描泛濫:對partsupp、part和lineitem表進行了全表掃描
-
嵌套循環效率低:對lineitem表的訪問在嵌套循環最內層
-
排序操作代價高:最后需要對結果集進行排序
3. PawSQL的優化方案:系統性解決方案
PawSQL作為專業的SQL優化工具,針對上述問題提供了一套完整的優化方案:
3.1?SQL重寫:從IN到EXISTS
將IN子查詢轉換為EXISTS形式,在有合適索引的情況下,這種改寫通常能讓優化器生成更高效的執行計劃:
where exists (select /*QB_1*/ partsupp.ps_suppkeyfrom partsupp, (...)where exists (select /*QB_4*/ part.p_partkeyfrom partwhere part.p_name like 'green%' and part.p_partkey = partsupp.ps_partkey)and partsupp.ps_availqty > SQ_1742975670803.null_and partsupp.ps_suppkey = supplier.s_suppkeyand SQ_1742975670803.l_partkey = partsupp.ps_partkeyand SQ_1742975670803.l_suppkey = partsupp.ps_suppkey)?
3.2?SQL重寫:提前聚合計算
將lineitem的聚合計算從子查詢中提取出來,預先計算每個(零件,供應商)組合的總量:
select?0.5?*?sum(l_quantity)?as?null_, l_partkey,l_suppkey
from?lineitem
where?l_shipdate?>=?date?'1997-01-01'and?l_shipdate?<?date?'1997-01-01'?+?interval?'1'?YEAR
group?by?l_partkey, l_suppkey3.3 智能索引設計
除了SQL重寫外,PawSQL還為優化后的SQL推薦了一系列索引,這些索引的創建為查詢性能的提升提供了有力支持。
-- 加速lineitem表的聚合計算
CREATE INDEX PAWSQL_IDX1406058528 ON lineitem(l_shipdate,l_quantity,l_partkey,l_suppkey);-- 優化nation表查詢
CREATE INDEX PAWSQL_IDX0006674720 ON nation(n_name,n_nationkey);-- 支持supplier表的排序和連接
CREATE INDEX PAWSQL_IDX1461825654 ON supplier(s_name,s_address,s_nationkey);
CREATE INDEX PAWSQL_IDX1670284145 ON supplier(s_nationkey,s_name,s_address);-- 加速part和partsupp表的連接
CREATE INDEX PAWSQL_IDX0450194419 ON part(p_partkey,p_name);
CREATE INDEX PAWSQL_IDX1262756509 ON partsupp(ps_partkey,ps_suppkey,ps_availqty);3.4 謂詞下推
將過濾條件盡可能下推到數據訪問層,減少中間結果集:
-
nation.n_name = 'ALGERIA' -
part.p_name like 'green%' -
lineitem.l_shipdate范圍條件
3.5. 避免排序
通過創建包含s_name的索引,直接利用索引的有序性避免排序操作。
4. 優化效果:性能提升1541倍
?
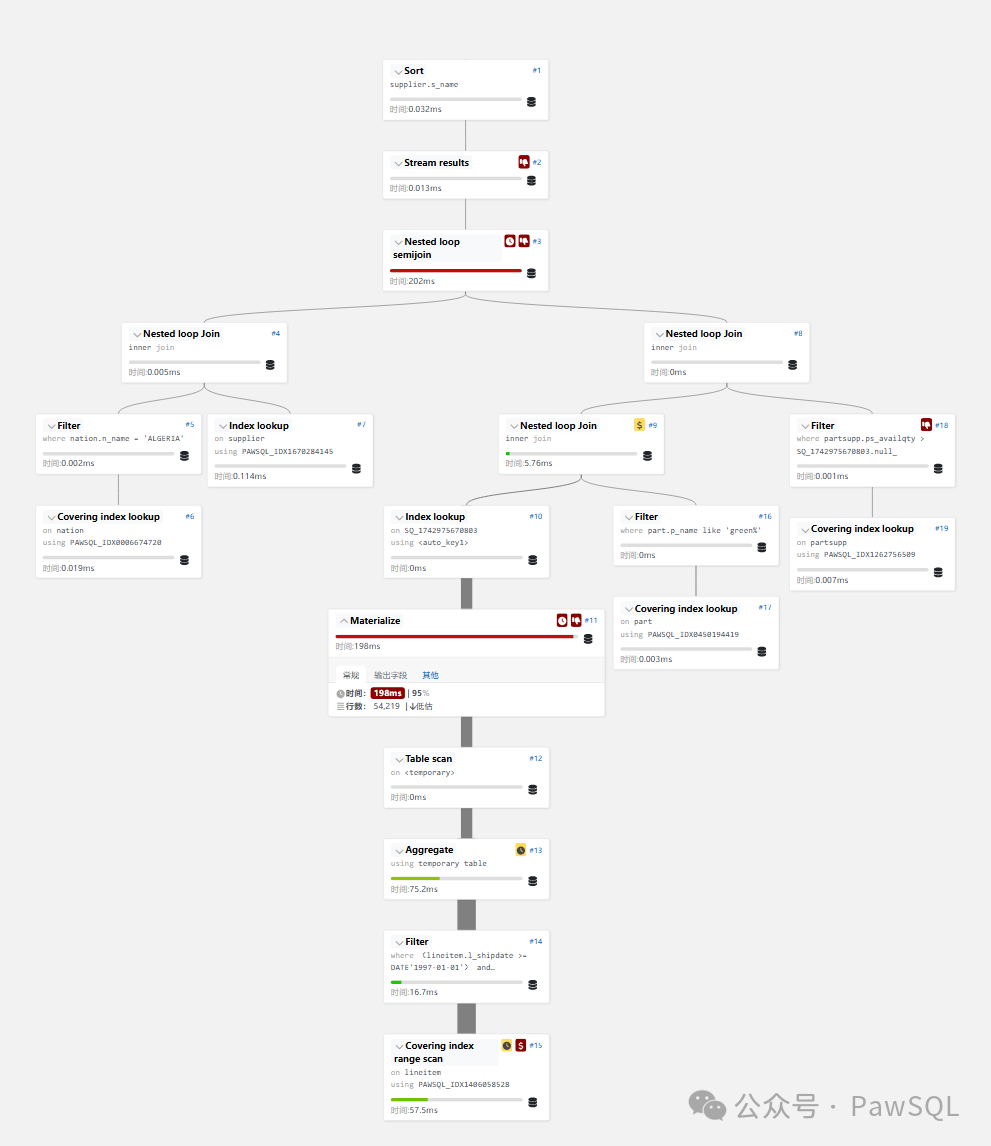
優化前后的對比令人震撼:
| 指標 | 優化前 | 優化后 | 提升幅度 |
|---|---|---|---|
| 執行時間 | 321秒 | 0.208秒 | 154,124% |
| lineitem表掃描次數 | 848次 | 1次 | - |
| lineitem表掃描行數 | 509,285,056行 | 90,514行 | - |
| 排序操作 | 需要顯式排序 | 利用索引避免排序 | - |
執行計劃對比:
-
優化前:全表掃描→嵌套循環→重復計算
-
優化后:索引查找→哈希連接→物化視圖
5. 經驗總結:SQL優化最佳實踐
通過這個案例,我們可以總結出以下SQL優化經驗:
-
避免關聯子查詢:特別是重復執行的關聯子查詢,考慮改寫為JOIN或提前物化
-
索引設計:盡量減少表掃描,同時兼顧避免回表操作
-
利用索引有序性:讓索引順序與ORDER BY一致可以避免排序操作
-
聚合計算預優化:對于重復的聚合計算,考慮提前計算并存儲
-
專業工具輔助:使用PawSQL等專業工具可以快速定位問題并提供優化方案
這個案例生動展示了:即使是極其復雜的分析查詢,通過系統性的優化方法,也能實現從分鐘級到亞秒級的性能飛躍。
🌐 關于PawSQL
PawSQL專注于數據庫性能優化自動化和智能化,提供的解決方案覆蓋SQL開發、測試、運維的整個流程,廣泛支持包括MySQL/PostgreSQL/Oracle /openGauss/TDSQL/Oceanbase/達夢DM/金倉等各種主流商用和開源數據庫,為開發者和企業提供一站式的創新SQL優化解決方案。
?
?
)



![[ctfshow web入門] web37](http://pic.xiahunao.cn/[ctfshow web入門] web37)




)









