引言
2025年4月,Meta正式發布了全新的Llama 4系列模型,這標志著Llama生態系統進入了一個全新的時代。Llama 4不僅是Meta首個原生多模態模型,還采用了混合專家(MoE)架構,并提供了前所未有的上下文長度支持。本文將詳細介紹Llama 4的主要特性、技術創新以及社區對這次更新的相關評測結果,幫助您全面了解這一AI領域的重大突破。
Llama 4系列模型概覽

Meta此次推出了Llama 4系列的三個主要模型:
-
Llama 4 Scout:擁有17B活躍參數和16個專家,總參數量為109B。它是同類中最佳的多模態模型,可以在單個NVIDIA H100 GPU上運行,并提供業界領先的1000萬token上下文窗口。
-
Llama 4 Maverick:擁有17B活躍參數和128個專家,總參數量為400B。它在多項廣泛報告的基準測試中擊敗了GPT-4o和Gemini 2.0 Flash,同時在推理和編碼方面與新的DeepSeek v3取得了相當的結果,但活躍參數不到后者的一半。
-
Llama 4 Behemoth:擁有288B活躍參數和16個專家,總參數量接近2萬億。作為Meta最強大的LLM,它在多項STEM基準測試中優于GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro。目前該模型仍在訓練中,尚未公開發布。
值得注意的是,雖然Llama 4 Maverick的總參數量為400B,但在處理每個token時,實際參與計算的"活躍參數"始終是17B。這大大降低了推理和訓練的延遲。
技術創新與突破
混合專家(MoE)架構:效率與性能的完美平衡
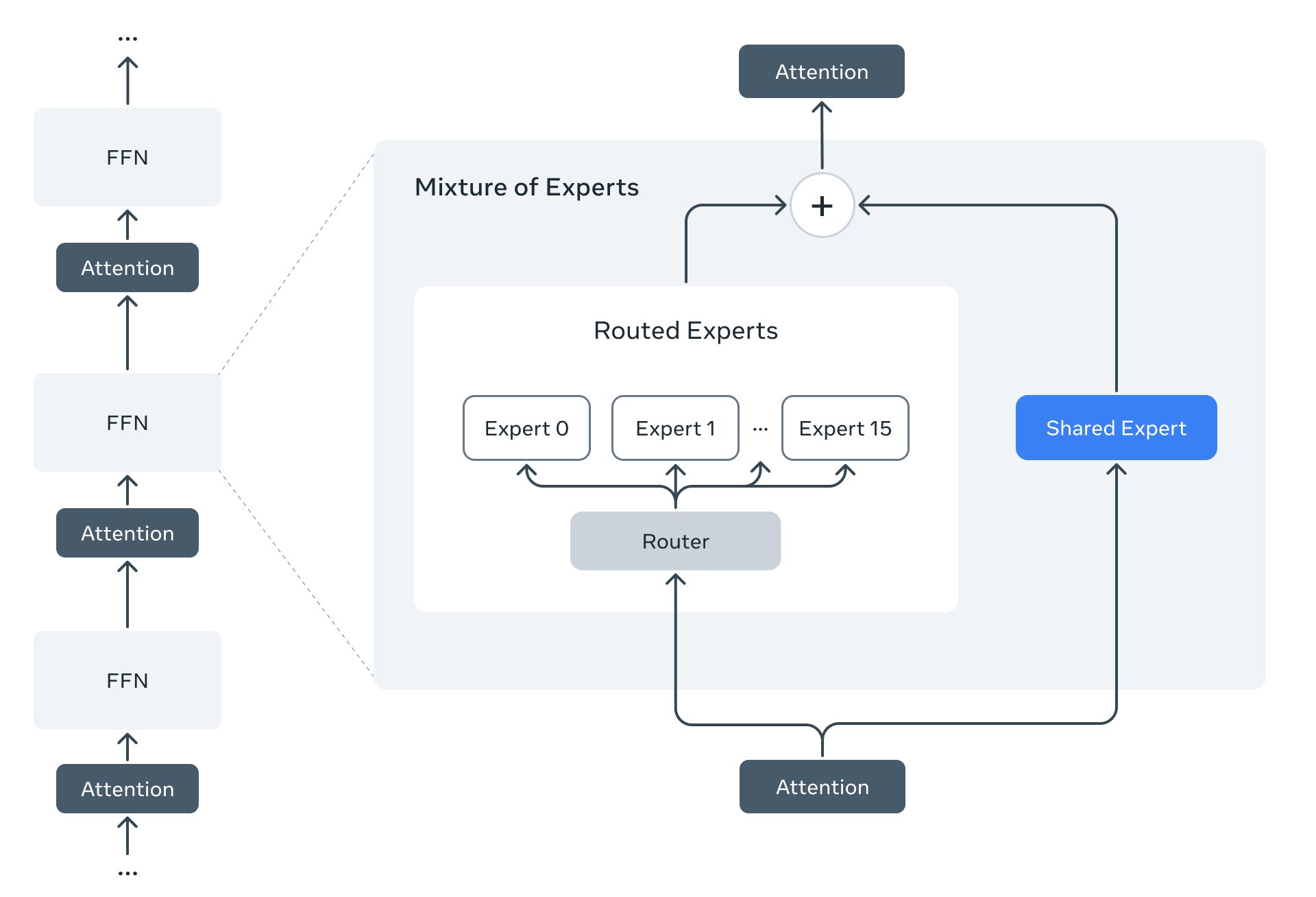
Llama 4是Meta首次使用混合專家(MoE)架構的模型。在MoE模型中,單個token只激活總參數的一小部分。這種架構在訓練和推理方面更加計算高效,與固定訓練FLOP預算相比,能夠提供更高的質量。
例如,Llama 4 Maverick模型有17B活躍參數和400B總參數。它使用交替的密集層和混合專家(MoE)層來提高推理效率。MoE層使用128個路由專家和一個共享專家。每個token都會被發送到共享專家和128個路由專家中的一個。因此,雖然所有參數都存儲在內存中,但在提供這些模型服務時,只有一部分總參數被激活。
原生多模態能力:視覺與文本的無縫融合
Llama 4模型設計具有原生多模態性,通過早期融合將文本和視覺token無縫集成到統一的模型主干中。早期融合是一個重大進步,因為它使模型能夠用大量未標記的文本、圖像和視頻數據聯合預訓練。
這些模型在各種圖像和視頻幀上進行了訓練,以提供廣泛的視覺理解能力,包括時間活動和相關圖像。這使得模型能夠輕松處理多圖像輸入和文本提示,用于視覺推理和理解任務。模型在預訓練階段支持多達48張圖像,并在后訓練階段測試中顯示出良好的結果,最多支持8張圖像。
超長上下文支持:突破性的1000萬token容量
Llama 4 Scout將支持的上下文長度從Llama 3的128K大幅增加到業界領先的1000萬token。這開啟了許多可能性,包括:
- 多文檔摘要生成
- 解析大量用戶活動進行個性化任務
- 對龐大代碼庫的深度推理
- 長文本理解與分析
技術實現:Llama 4 Scout在預訓練和后訓練階段都使用了256K上下文長度,這使基礎模型具備了先進的長度泛化能力。Llama 4架構的一個關鍵創新是使用交替注意力層(無位置嵌入)。此外,還采用了推理時間注意力溫度縮放來增強長度泛化。這種架構被稱為iRoPE,其中"i"代表"交替"注意力層,突出了支持"無限"上下文長度的長期目標,而"RoPE"指的是大多數層中使用的旋轉位置嵌入。
訓練方法與優化
預訓練創新:MetaP超參數設置技術
Meta開發了一種新的訓練技術,稱為MetaP,它允許可靠地設置關鍵模型超參數,如每層學習率和初始化比例。這些超參數在不同的批量大小、模型寬度、深度和訓練token上都能很好地遷移。
Llama 4通過在200種語言上進行預訓練來支持開源微調工作,其中超過100種語言的token超過10億個,總體上比Llama 3多10倍的多語言token。
此外,Meta還專注于高效的模型訓練,使用FP8精度,同時不犧牲質量并確保高模型FLOP利用率。在使用FP8和32K GPU預訓練Llama 4 Behemoth模型時,每個GPU達到了390 TFLOP。總體數據混合訓練包含超過30萬億個token,是Llama 3預訓練混合的兩倍多,包括多樣化的文本、圖像和視頻數據集。
后訓練優化:創新的三階段訓練流程
Meta為Llama 4 Maverick模型采用了全新的后訓練流程:
- 輕量級監督微調(SFT)
- 在線強化學習(RL)
- 輕量級直接偏好優化(DPO)
關鍵發現:SFT和DPO可能會過度約束模型,限制在線RL階段的探索,導致次優精度,特別是在推理、編碼和數學領域。
解決方案:Meta通過使用Llama模型作為評判標準,移除了超過50%被標記為"簡單"的數據,并對剩余的更難數據集進行輕量級SFT。在隨后的多模態在線RL階段,通過仔細選擇更難的提示,實現了性能的大幅提升。
模型評測與性能對比
Llama 4系列官方評測結果
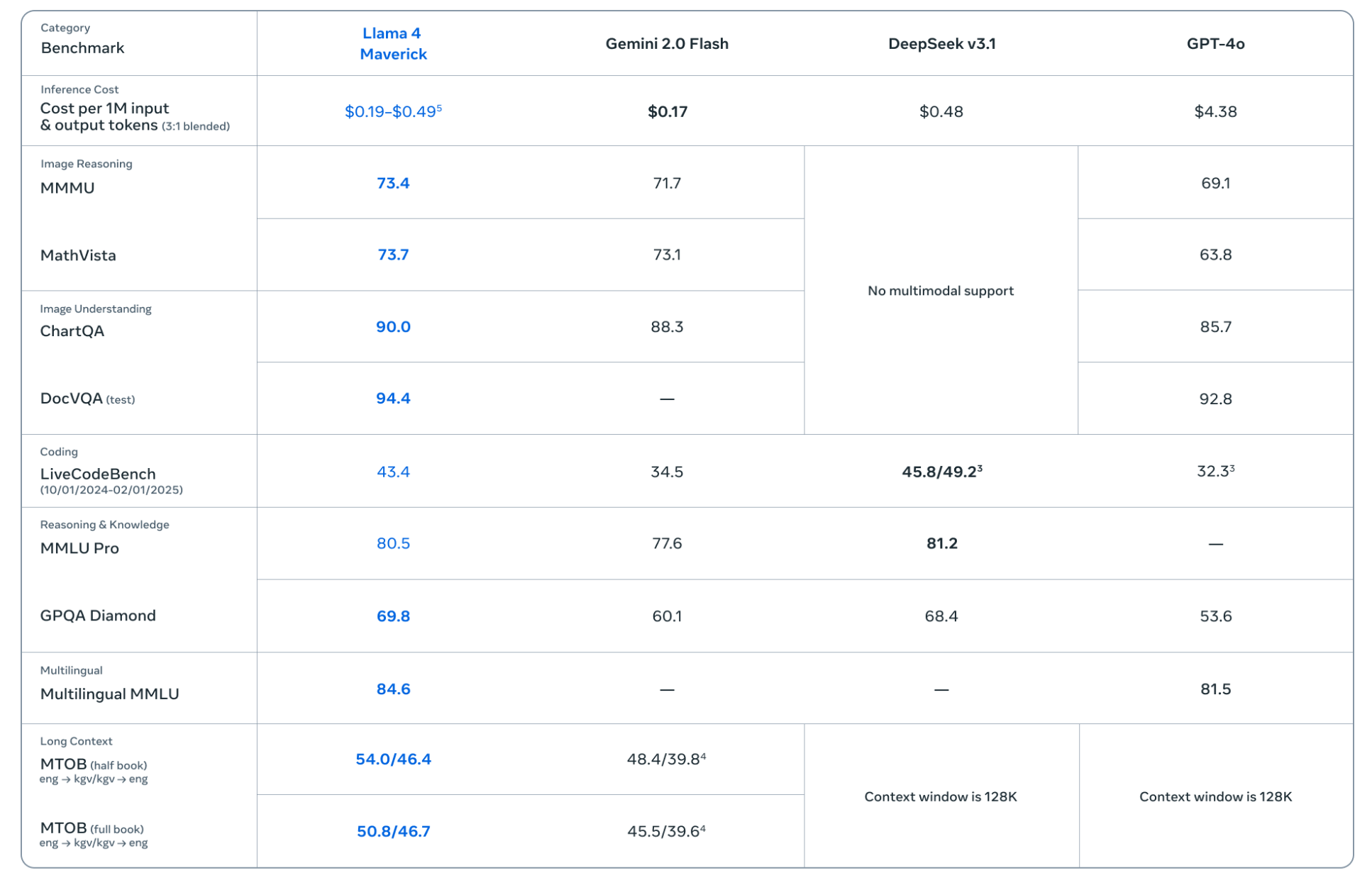
從Meta官方給出的評測結果可以看出,Llama 4 Maverick主要是全面對標GPT-4o和Gemini 2.0 Flash,同時作為開源模型,也與DeepSeek v3進行了對比。
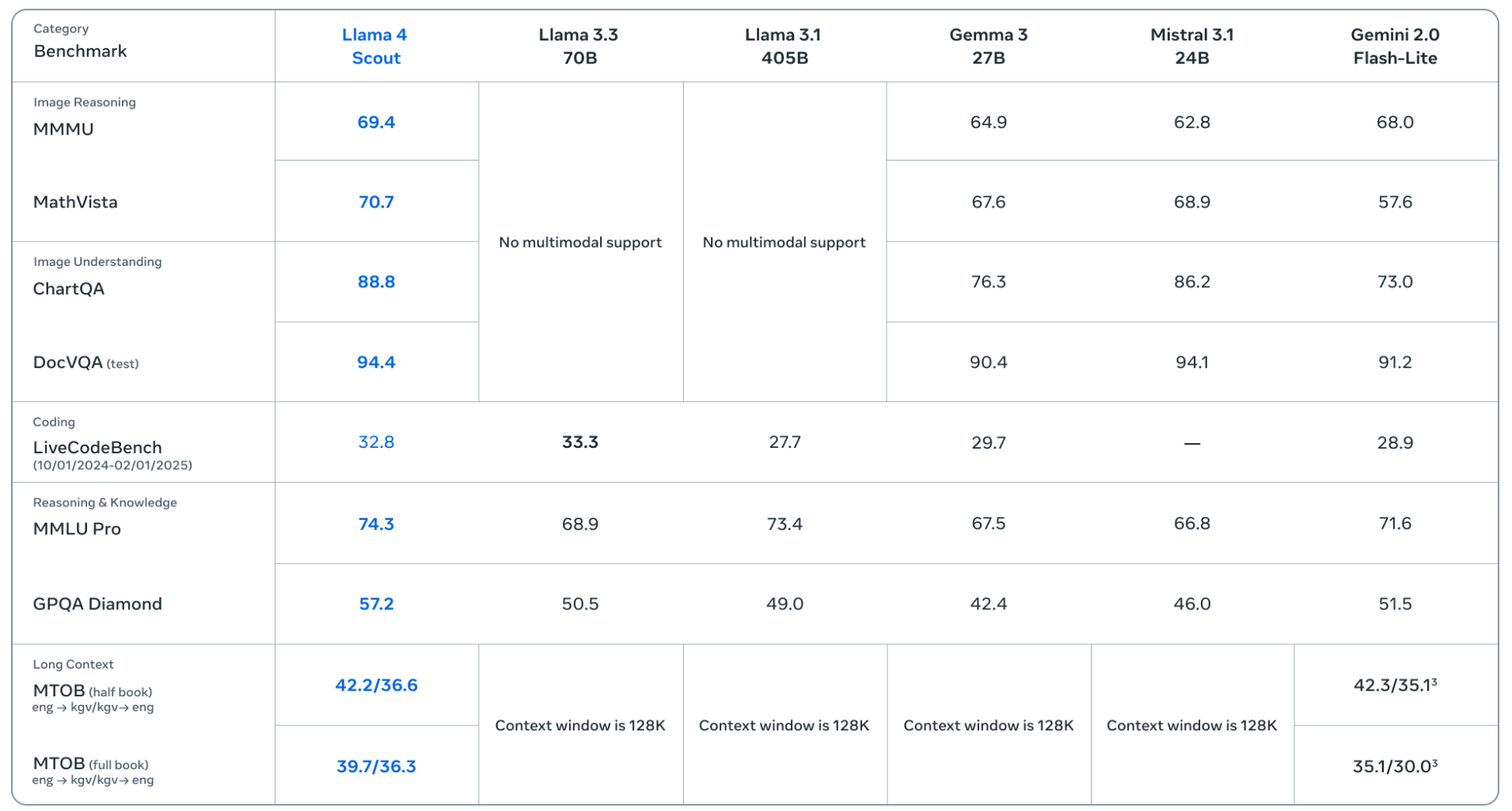
而Llama 4 Scout則主要對標輕量級的模型,比如Gemma 3、Gemini 2.0 Flash-Lite等。
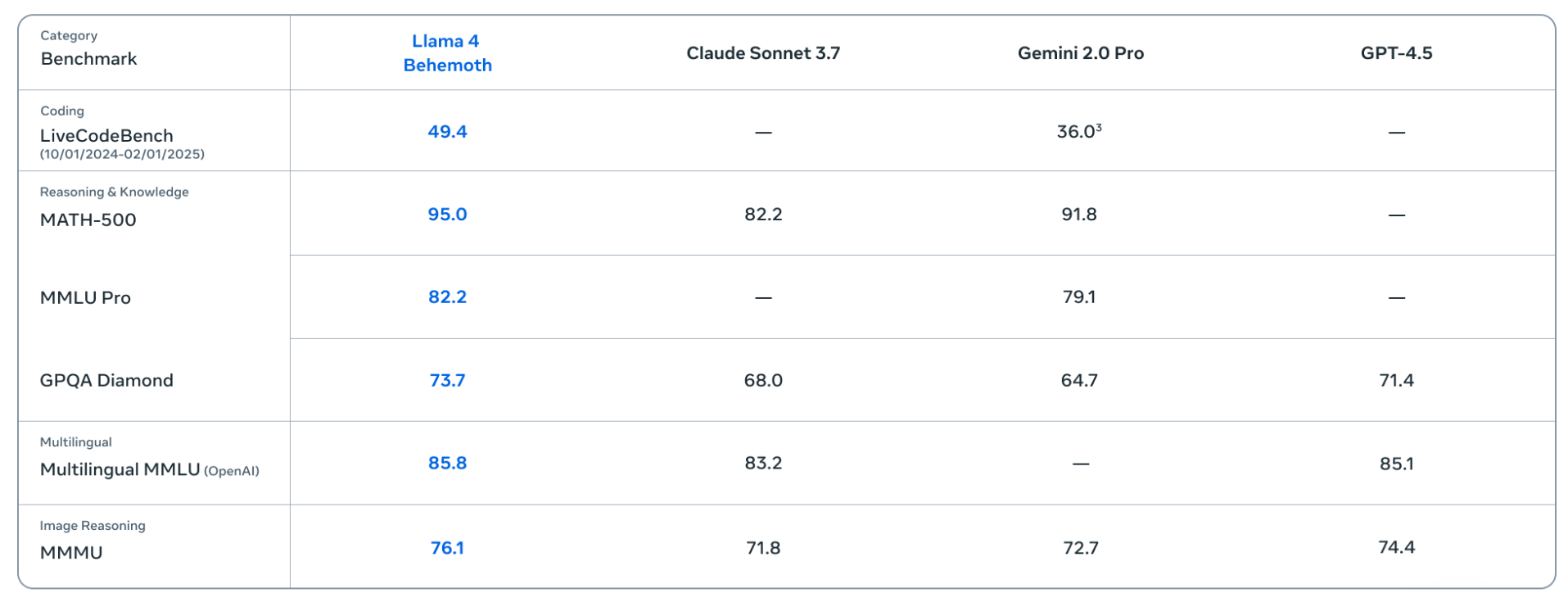
尚未發布的最強模型Llama 4 Behemoth,從數據上顯著優于Claude 3.7 Sonnet和Gemini 2.0 Pro。
社區獨立評測結果
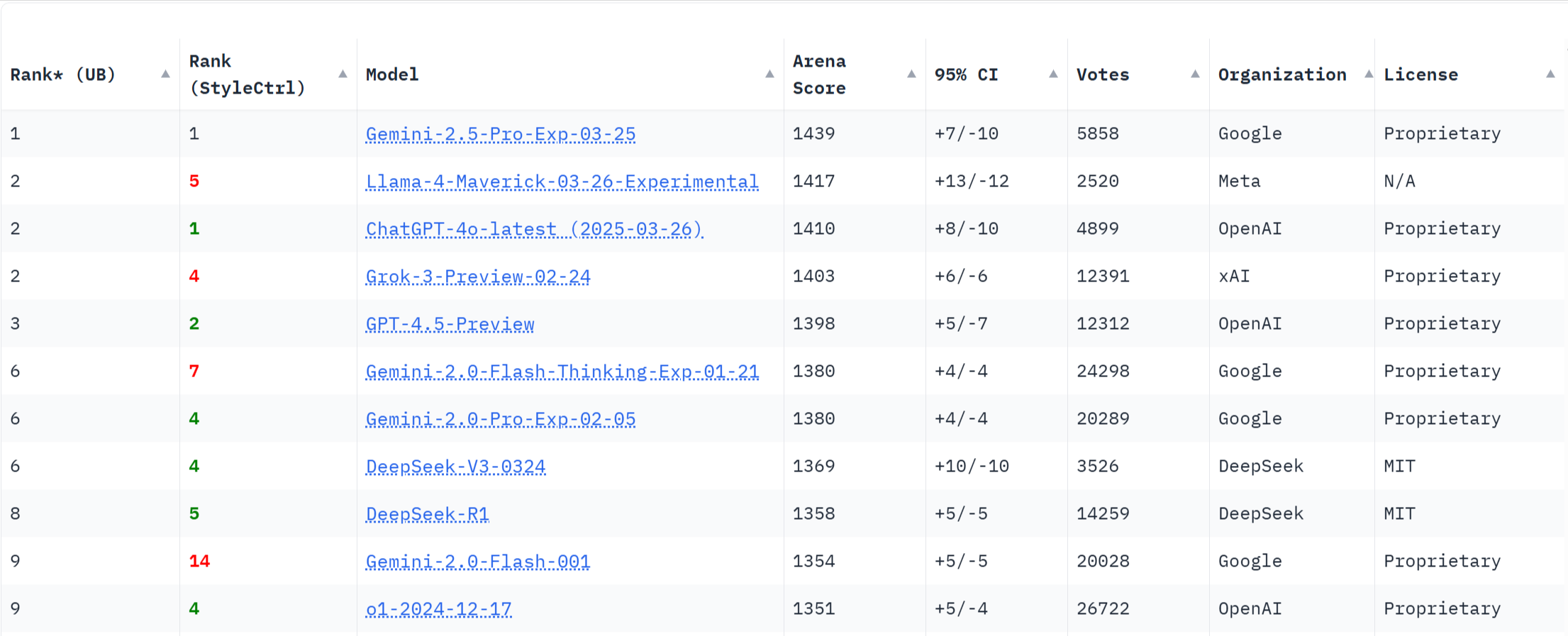
官方評測自然只是一家之言,社區評測則更為客觀。以下是來自LMArena的評測結果,可以看到,Llama 4 Maverick僅次于Google剛發布不久的Gemini-2.5-Pro,位居第二。
編碼能力與Agent能力評測
對于AI研究者和開發者來說,編碼能力和Agent能力是評判大語言模型實用性的重要指標。
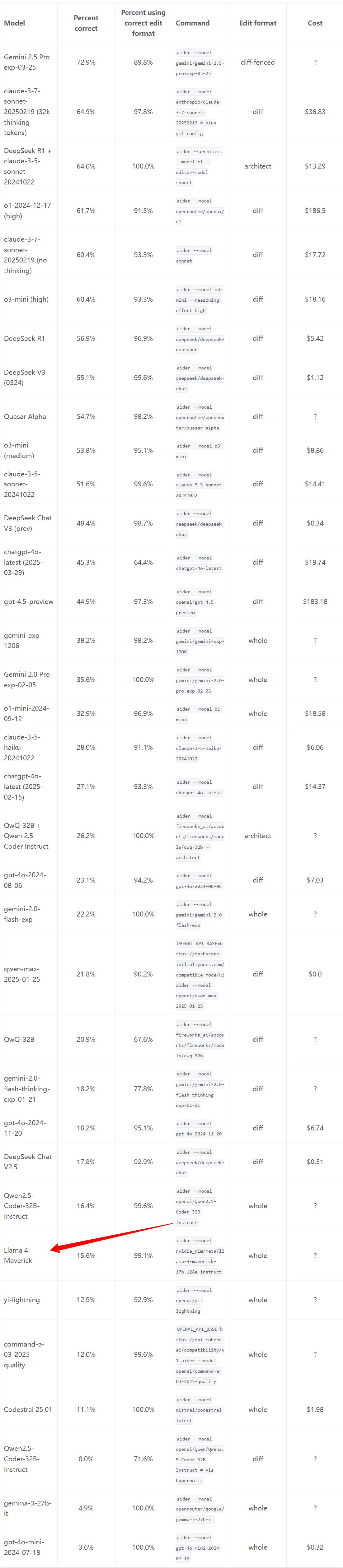
編碼能力評測:從Aider Polyglot leaderboard的結果來看,即使是Llama 4 Maverick,在編碼能力上也排名相當靠后,基本就是DeepSeeK V2.5的水平,這與預期有一定差距。
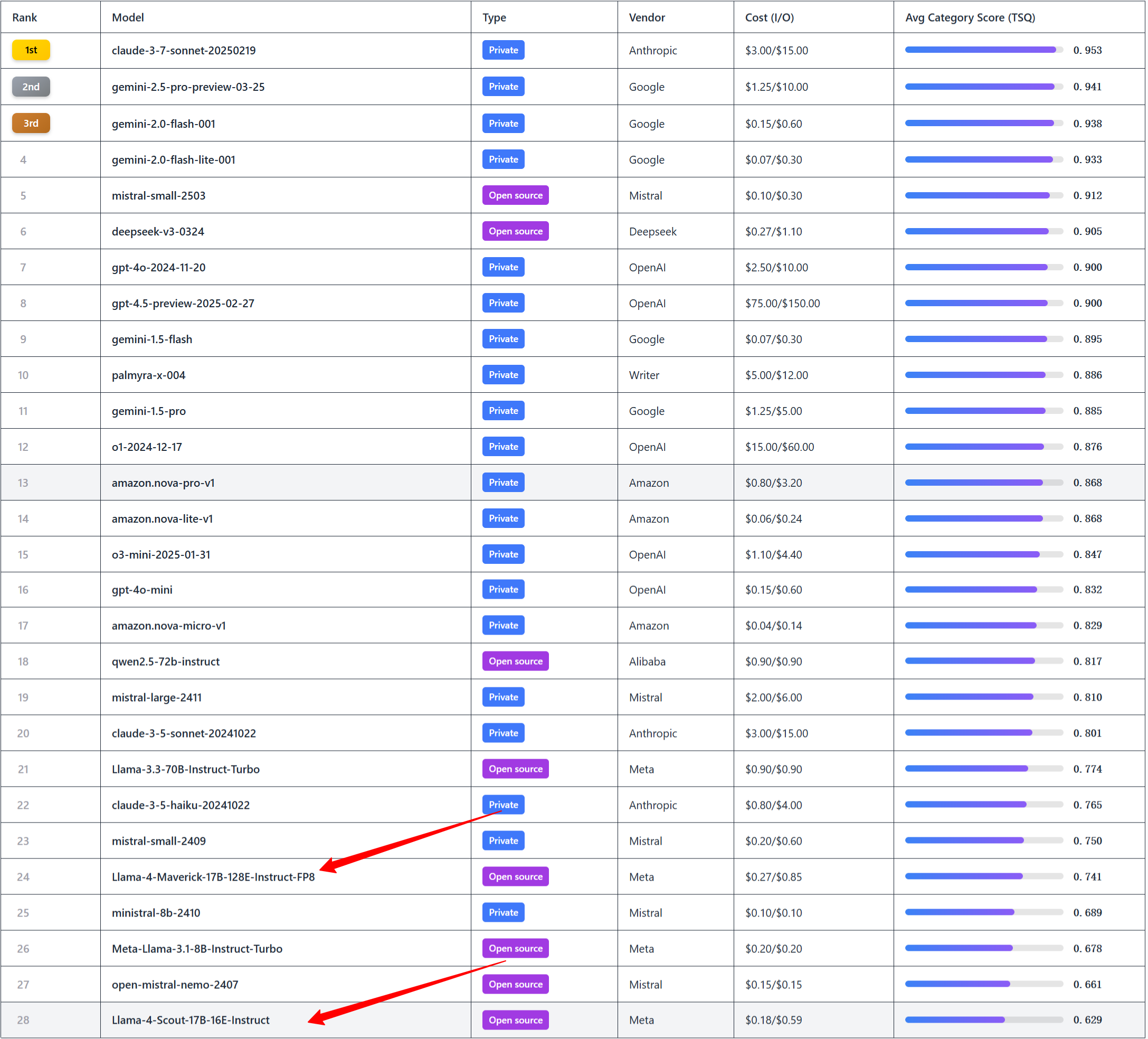
Agent能力評測:在huggingface agent leaderboard中,Llama 4 Maverick甚至連前20都排不進去。不僅與商業模型相比有差距,就是與開源的Qwen和DeepSeek相比,也略顯不足,甚至不如自家上一代的Llama-3.3,這一點令人意外。
這兩項特別關鍵的評測中,Llama 4的表現都不盡如人意,期待官方之后能繼續優化或對測試結果做出合理解釋。
總結
總體來說,Llama 4系列模型在技術上實現了多項創新:
- 首次采用MoE架構,大幅提升計算效率
- 原生多模態能力,實現文本與視覺的深度融合
- 突破性的1000萬token超長上下文支持
- 創新的訓練方法與優化技術
然而,在實際社區評測中,特別是在編碼能力和Agent能力方面,Llama 4系列的表現還有待提高。作為Meta新一代的開源模型,Llama 4理應在各方面取得更好的評測結果,但目前看來,距離預期還有一定差距。
應用前景:作為問答模型,Llama 4表現尚可,但作為智能體的大腦,還需進一步優化。目前的表現似乎更適合考試場景,而非實戰應用,暫時還未能進入我的AI智能體大腦候選列表。




:探尋構造函數的幽微之境)
)



)

![[Bond的雜貨鋪] CKS 證書也到貨咯](http://pic.xiahunao.cn/[Bond的雜貨鋪] CKS 證書也到貨咯)
 之 多線程編程 上)
)



UDP 為什么大小不能超過 64KB?)

