
MLA 結構
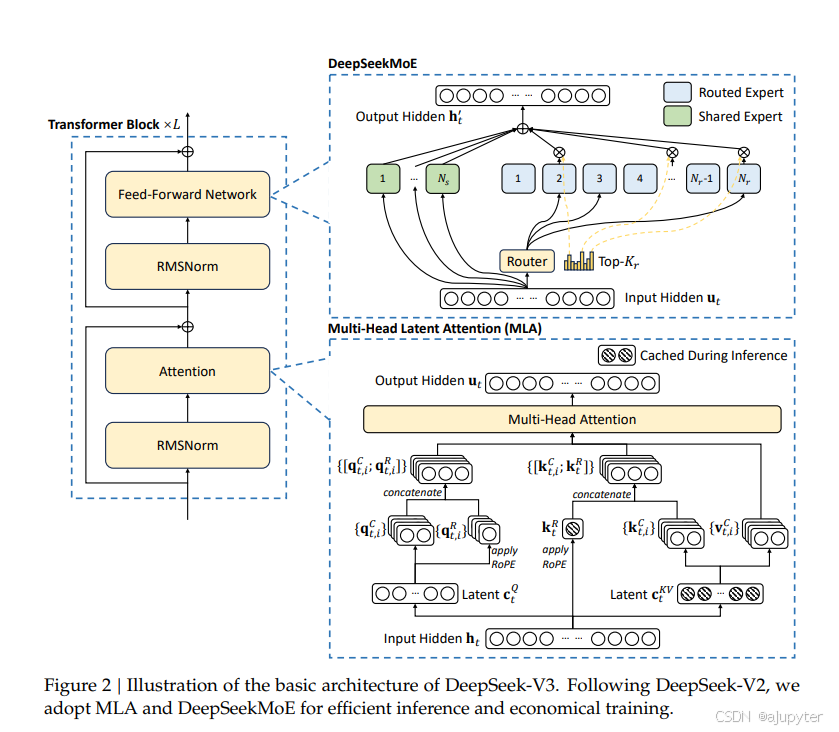
- 需要緩存
- KV 向量共用的壓縮隱特征
- K 向量多頭共享的帶位置編碼的向量
- 為什么帶有位置信息的 Q 向量來自于隱特征向量,而帶有位置的 K 向量來自于 H 向量且共享呢?
最好的方法肯定是從H向量直接計算并且不共享,但是會大大增加顯存使用和降低計算效率。原理上,基于隱向量計算ROPE肯定是有損的,共享也肯定犧牲了表達能力,所以做了一些權衡:
1、Q向量都基于潛向量生成RoPE向量而不共享,主要是為了增加計算效率。因為隱向量小所以計算更快,而且每次都要計算。不共享是為了保證表達能力。
2、K向量是從緩存中取的,不用每次計算,所以直接在H中計算就好。但是如果不共享將會讓每個頭都有一個RoPE向量,大大增加顯存占用,所以共享。
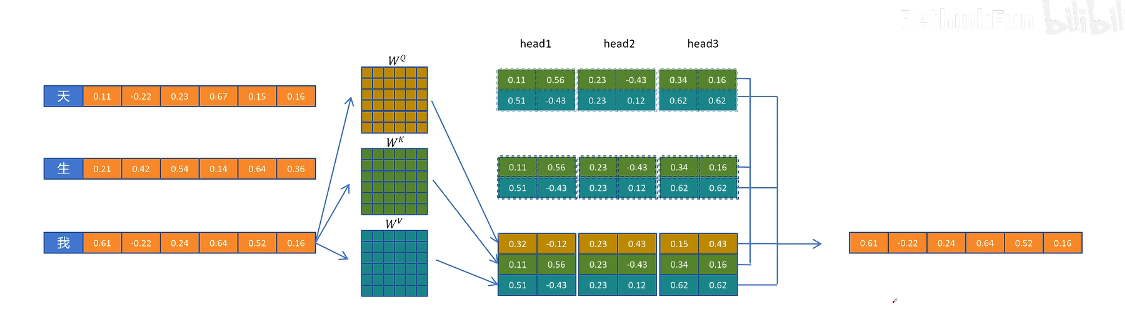
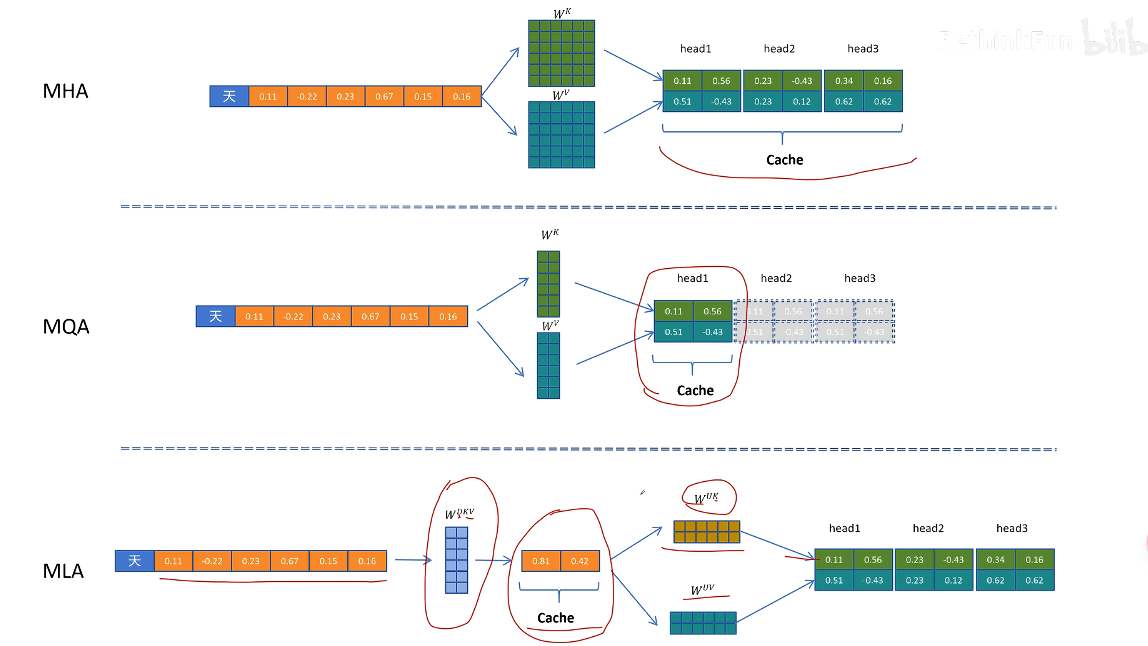
多頭注意力機制 MHA + KV cache
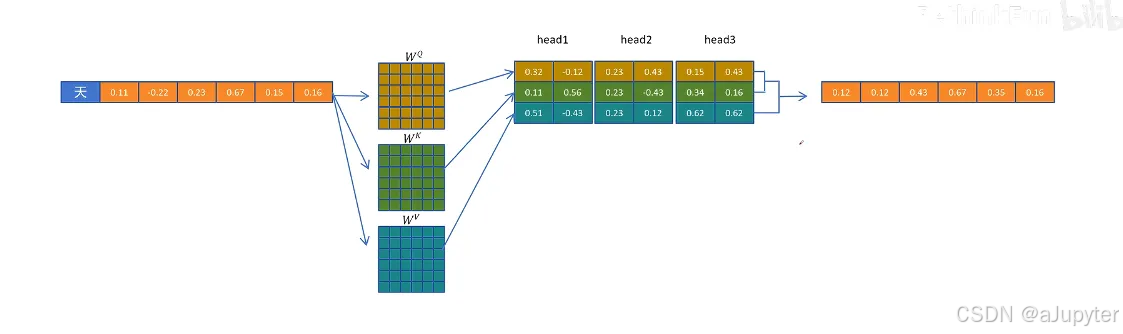
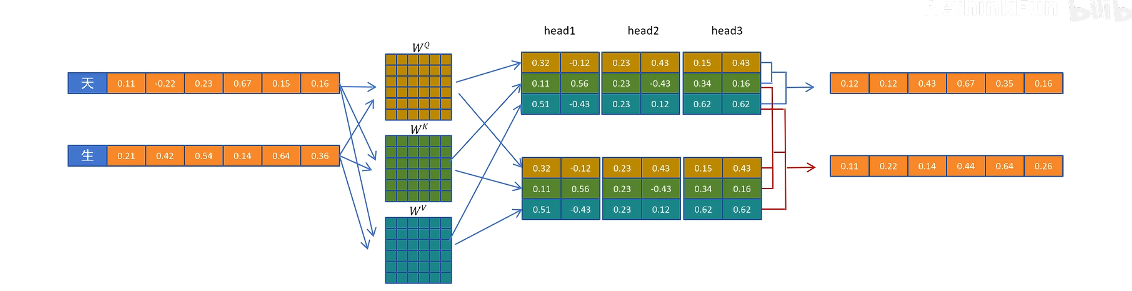
在生成第三個 token 的時候,第一個 token 進行的計算已經在生成第二個 token 的時候計算過了,重復計算。–》緩存第一個 token 計算的中間變量,并且只保留生成新 token 所需要的中間變量(KV cache)
有了 KV cache 后生成第三個 token 的過程
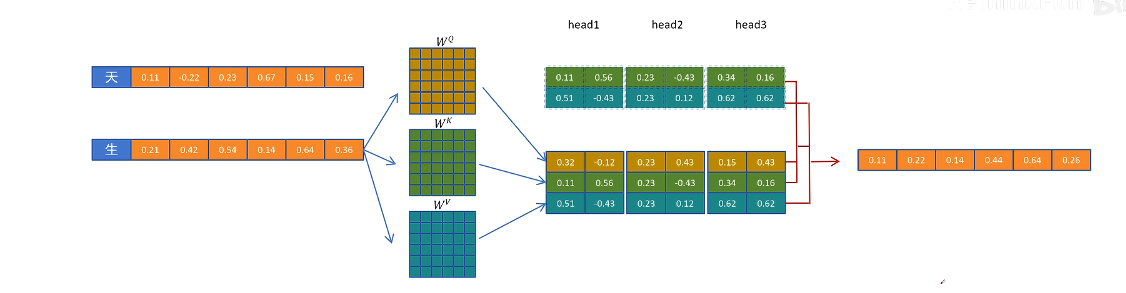
生成第四個 token

GQA/MQA
這里展示的是 MQA,生成 3 個 head 的 Q 向量,只生成 1 個 head 維度的 K 和 V 向量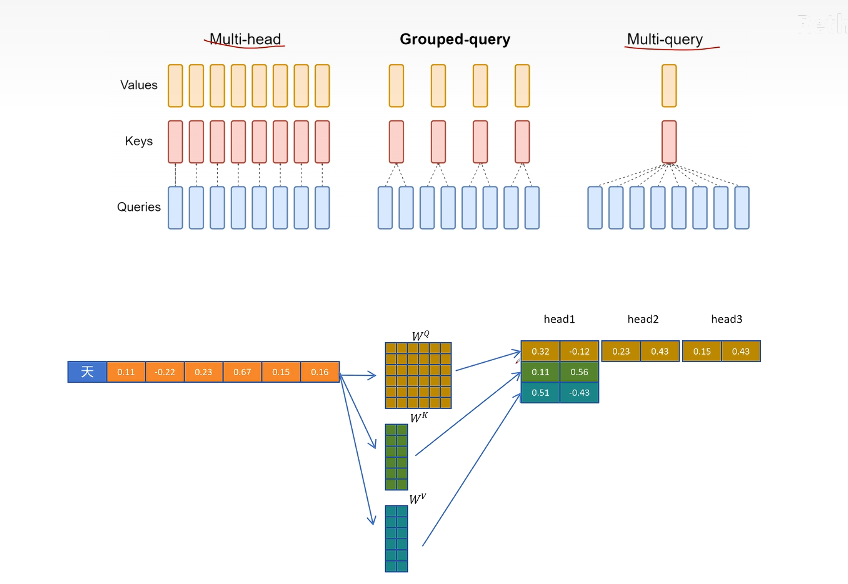
多頭間通過復制共享 query 向量一起來計算注意力,從而減少 kv cache,但會大大影響性能
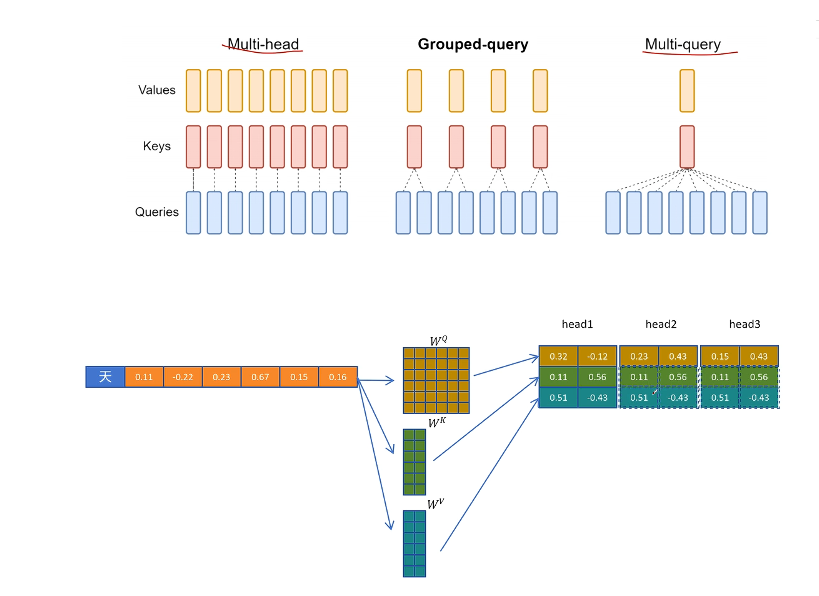
為了折中,提出了 GQA,每組 query 共享一個 k 和 v 向量
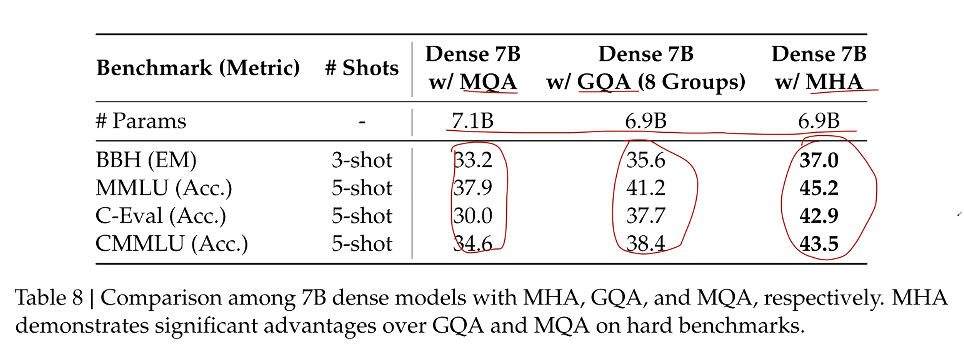
MLA-Multi-Head Latent Attention
多頭潛在注意力機制- 目的:減少 kv cache + 盡量不影響性能或者提高性能
- 原理:對 token 的特征向量進行壓縮轉換,緩存壓縮后的向量,在計算 attention 之后再解壓回原來的尺寸
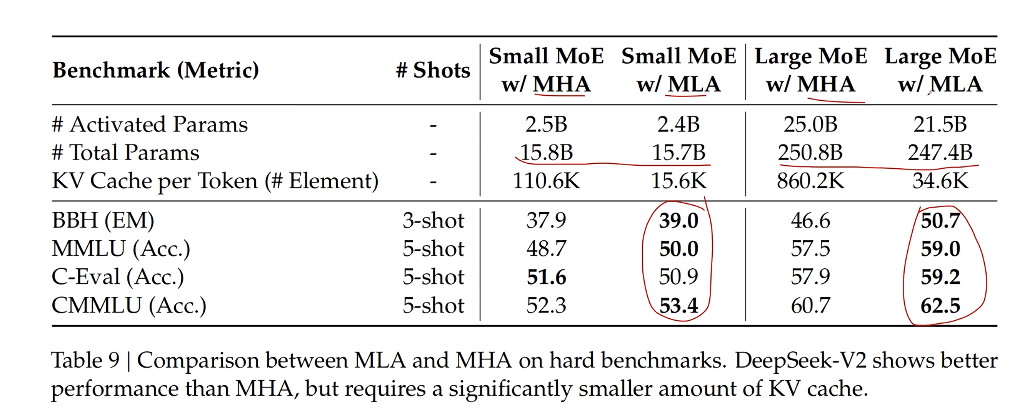
- 可以提效果,很不錯
壓縮 KV 向量
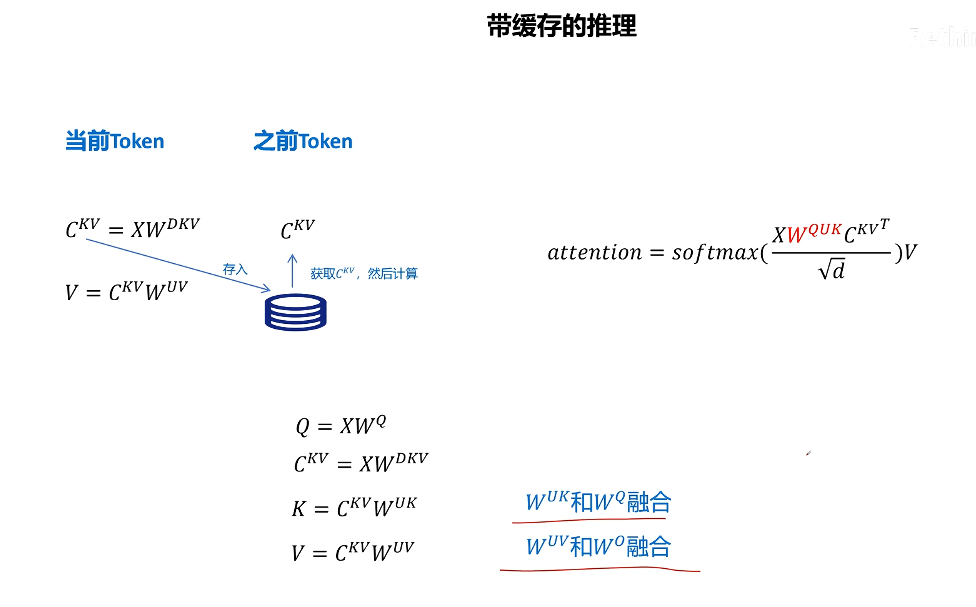
kv cache 本意是為了減少推理時對之前 token 的 k 和 v 向量的計算
MLA 因為緩存了壓縮的 kv cache,而減小了 kv cache 的顯存占用,但是在取出緩存后,k 和 v 不能直接使用,需要經過解壓計算才可以,引入了額外的計算,與 kv cache 初衷相悖
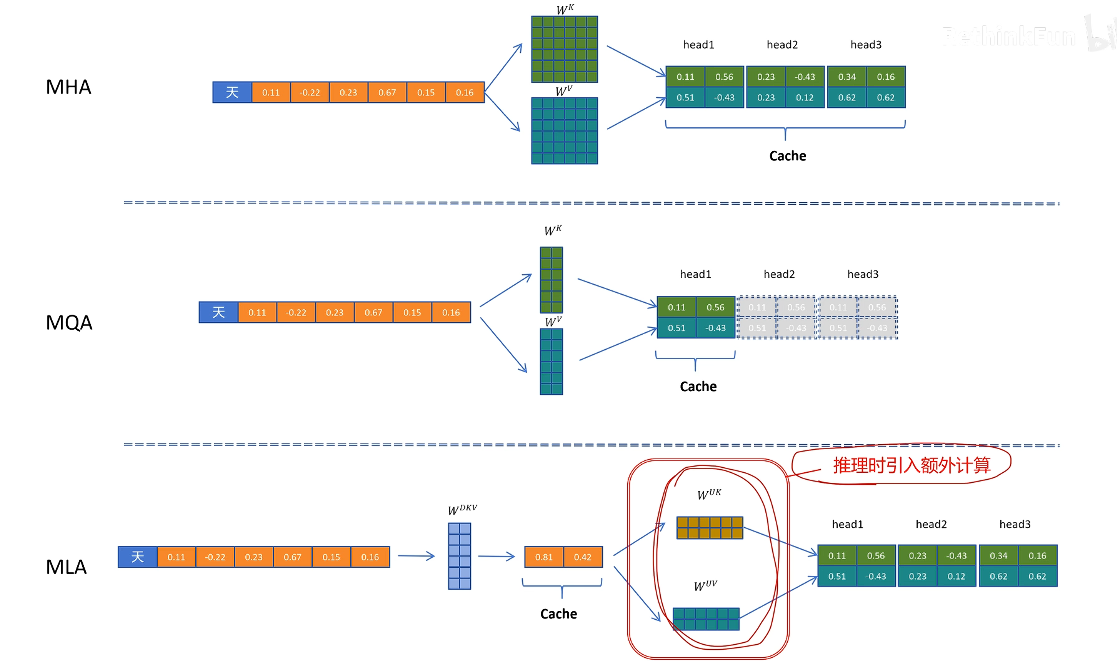
- 對 k 進行解壓操作的矩陣可以和 Wuq 矩陣進行融合,這個融合可以在推理之前算好,這樣在推理時就不用進行對 k 的額外解壓計算了【利用矩陣相乘的結合律,對矩陣提前進行融合,從而規避 MLA 引入的因解壓隱特征帶來的額外計算】
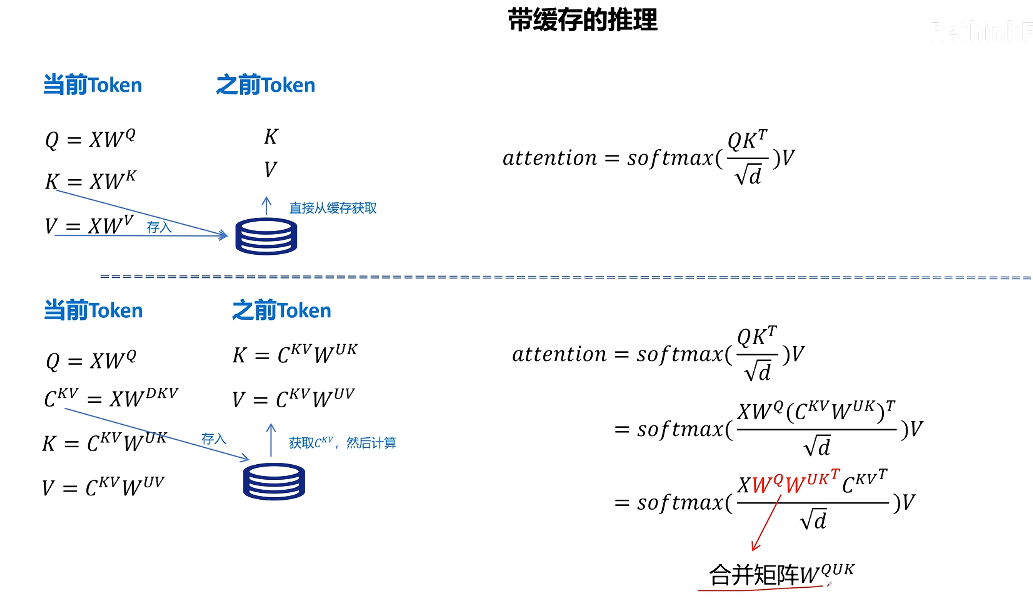
Wuv 同理,可以和 Wo 融合
壓縮 Q 向量
除了對 KV 向量進行壓縮外,對 Q 向量也進行了壓縮,好處是降低了參數量,而且可以提高模型性能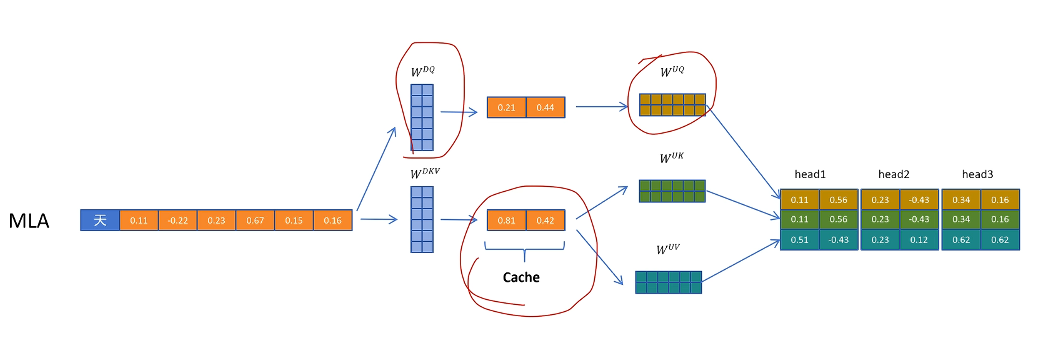
考慮 RoPE
RoPE 需要對每一層的 Q 向量和 K 向量進行旋轉,而且根據 token 位置的不同,旋轉矩陣的參數也是不同的。加入了 RoPE 的矩陣無法融合,因為中間兩個矩陣與 token 位置相關。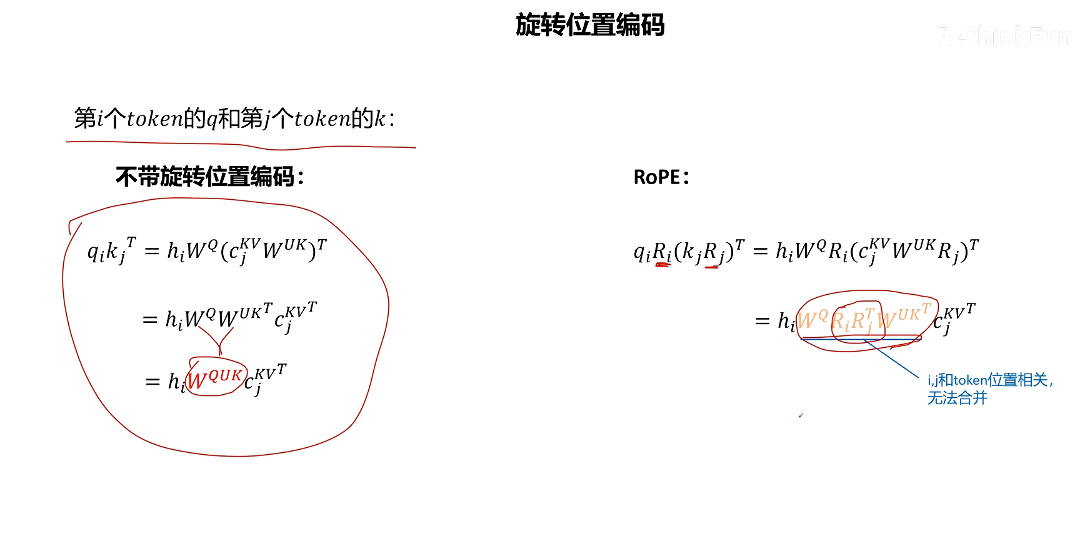
- 解決方案:為 Q 和 K 向量額外增加一些維度來表示位置信息
對于 Q 向量,通過 WQR 為每一個頭生成一些原始特征,然后通過 RoPE 增加位置信息,再把生成帶有位置信息的特征拼接到每個注意力頭的 Q 向量
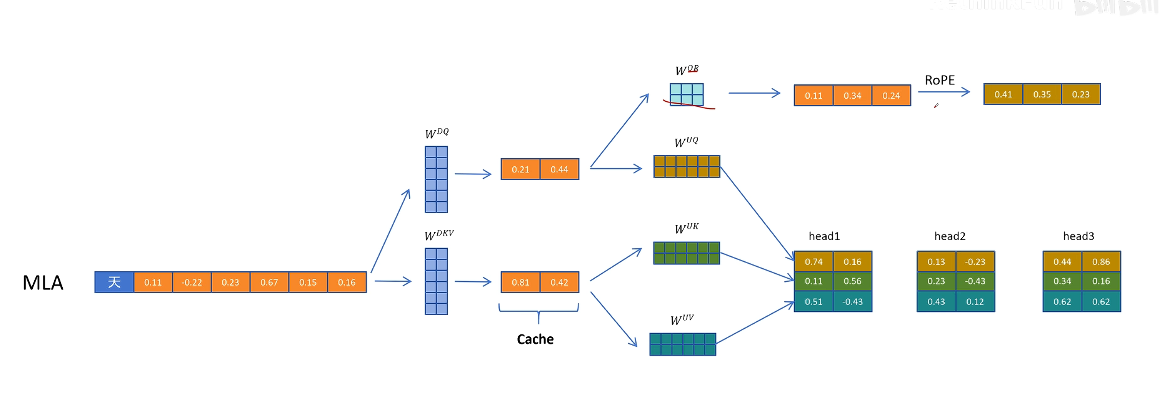
↓拼接
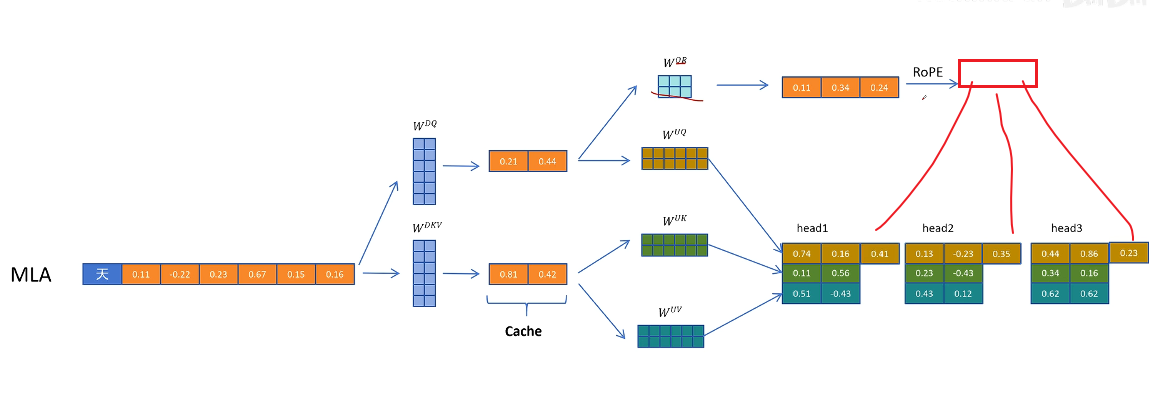
對于 K 向量,通過 WKR 矩陣生成一個頭共享的特征,然后通過 RoPE 增加位置信息,然后復制到多個頭共享位置信息。**這里多頭共享帶位置編碼的 K 向量,也需要被緩存,**以便在生成帶有位置信息的 K 向量時用到
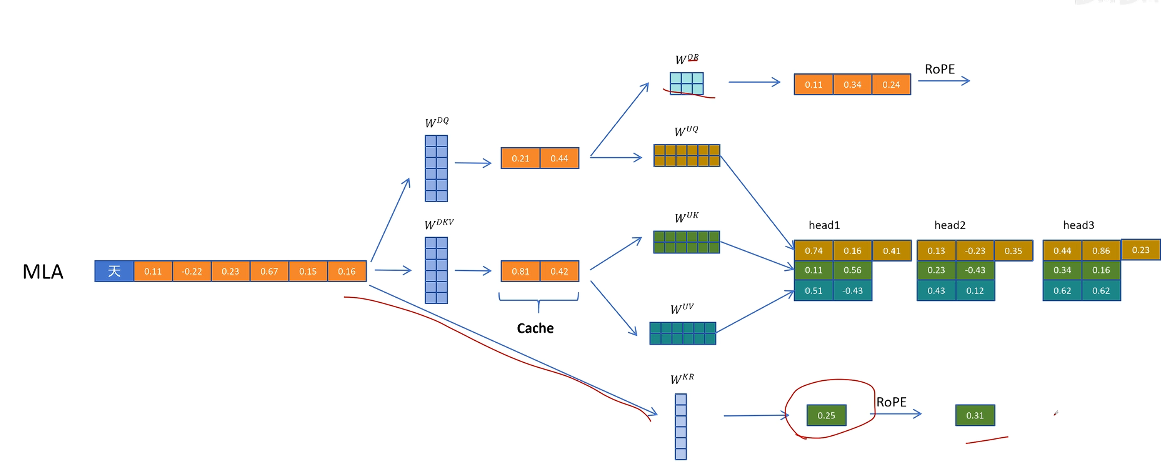
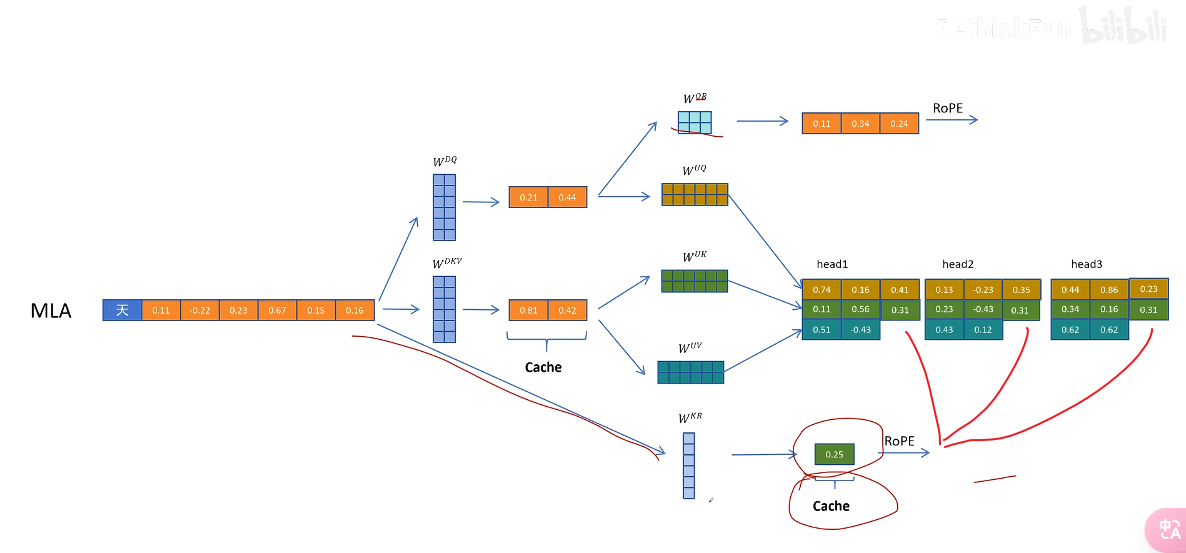
在推理時
- 不帶 RoPE 的 Q 向量和 K 向量進行點積運算(結果為數值),可以用融合的矩陣來消除解壓操作
- 帶 RoPE 的部分進行點積運算
將兩部分得到的兩個值進行逐元素相加:⊕ ,就相當于對拼接了位置信息的完整的 Q 和 K 向量進行點積操作的值。
參考
- https://www.bilibili.com/video/BV1BYXRYWEMj
- https://arxiv.org/pdf/2412.19437



![P1006 [NOIP 2008 提高組] 傳紙條 題解](http://pic.xiahunao.cn/P1006 [NOIP 2008 提高組] 傳紙條 題解)
(第三部分)—— 從基礎原理到實踐應用的深度探索)







)
)

)



