在當今的互聯網應用開發中,MySQL 作為可靠的關系型數據庫,與 Redis 這一高性能的緩存系統常常協同工作。然而,如何確保它們之間的數據一致性,成為了開發者們面臨的重要挑戰。本文將深入探討 MySQL 與 Redis 緩存一致性的相關問題,從不同的方案分析到實際項目的代碼實現,為你呈現全面的技術解析。
一、理論知識:探尋一致性方案的基石
(一)不佳的方案
- 先寫 MySQL,再寫 Redis
在高并發場景下,當多個請求同時進行數據更新時,若請求 A 先寫 MySQL,接著在寫 Redis 過程中出現延遲,而請求 B 快速完成了 MySQL 和 Redis 的數據更新操作,就會導致數據不一致。
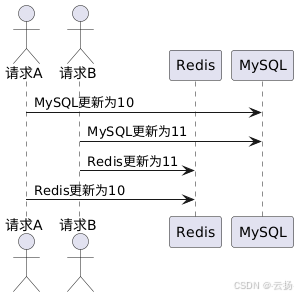
這是一幅描述在高并發場景下,“先寫 MySQL,再寫 Redis” 方案可能出現數據不一致問題的時序圖 ,具體過程如下:- 初始狀態:假設數據在 MySQL 和 Redis 中的初始值未明確提及,但后續操作是將其從某個值更新為 10 再到 11 。
- 請求 A 操作:請求 A 先對 MySQL 進行寫操作,將 MySQL 中的數據更新為 10 。之后請求 A 在向 Redis 寫數據時出現卡頓(延遲) 。
- 請求 B 操作:請求 B 在請求 A 寫 MySQL 之后開始操作。請求 B 先將 MySQL 中的數據更新為 11 ,接著順利將 Redis 中的數據也更新為 11 。
- 請求 A 后續操作:請求 A 卡頓結束后,繼續執行向 Redis 寫數據的操作,將 Redis 中的數據更新為 10 。這就導致 Redis 中的數據與 MySQL 中的數據(此時 MySQL 中為 11 )不一致 。
這種情況產生的原因在于高并發環境下,請求執行順序和延遲導致寫 Redis 操作的先后出現差異,使得最終 MySQL 和 Redis 中的數據狀態不一致。如果此時有讀請求,按照先讀 Redis 若沒有再讀 DB 且讀請求不回寫 Redis 的規則,就可能讀到不一致的數據 。
-
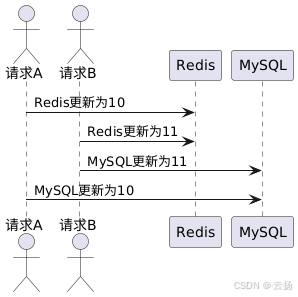
先寫 Redis,再寫 MySQL
此方案與先寫 MySQL 再寫 Redis 類似,在高并發情況下,由于操作順序的原因,極易出現數據不一致的問題。例如,當 Redis 寫入成功但 MySQL 寫入失敗時,后續的讀操作可能會讀取到 Redis 中已更新但 MySQL 中未更新的數據,從而產生不一致。
-
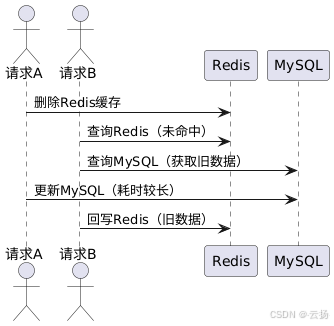
先刪除 Redis,再寫 MySQL
當存在更新請求 A 和讀請求 B 時,請求 A 先刪除 Redis 緩存,若此時更新 MySQL 的操作耗時較長,而請求 B 的讀請求快速執行,并且讀請求會回寫 Redis,那么在請求 A 的 MySQL 更新尚未完成時,請求 B 可能會將舊數據回寫到 Redis 中,導致數據不一致。
(二)可靠的方案
-
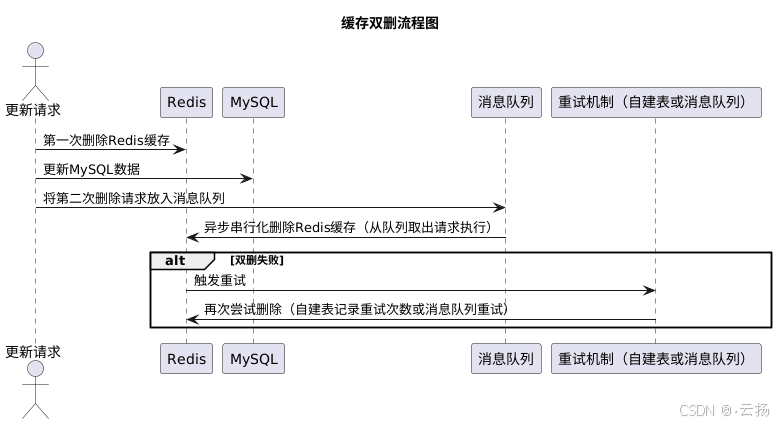
先刪除 Redis,再寫 MySQL,再刪除 Redis(緩存雙刪)
為解決先刪除 Redis 再寫 MySQL 帶來的不一致問題,緩存雙刪方案應運而生。即先刪除 Redis 緩存,然后更新 MySQL 數據,最后再次刪除 Redis 緩存。為確保最后一次刪除操作在回寫緩存之后執行,不建議采用簡單的等待固定時間(如 500ms)的方式,推薦使用異步串行化刪除,將刪除請求放入隊列中,這樣既能保證異步操作不影響線上業務,又能通過串行化處理在并發情況下正確刪除緩存。若雙刪失敗,可借助消息隊列的重試機制,或者自建表記錄重試次數來實現重試。
-
先寫 MySQL,再刪除 Redis
對于一些對一致性要求不是極高的業務場景,此方案下存在的短暫不一致是可以接受的。比如在秒殺、庫存服務等對一致性要求嚴格的業務中,這種方案可能不太適用。出現不一致的情況需要滿足緩存剛好自動失效,且請求 B 從數據庫查出舊數據回寫緩存的耗時比請求 A 寫數據庫并刪除緩存的時間更長,這種情況發生的概率相對較小。
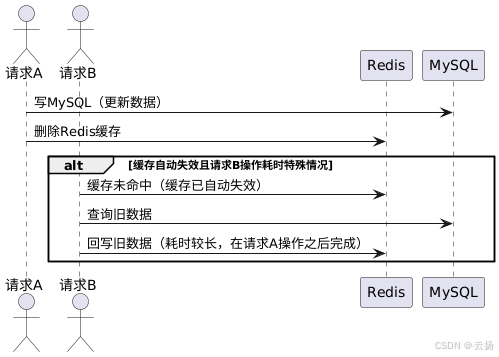
-
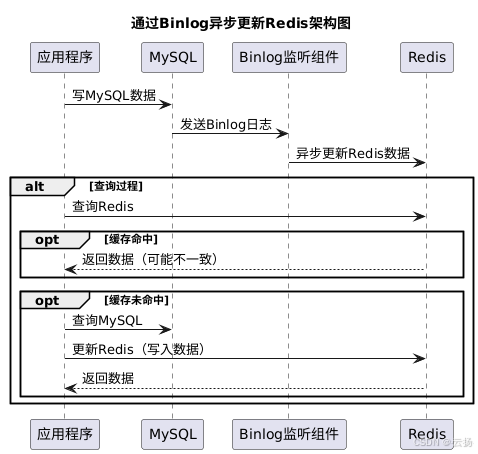
先寫 MySQL,通過 Binlog,異步更新 Redis
該方案通過監聽 MySQL 的 Binlog 日志,以異步的方式將數據更新到 Redis 中。它能保證 MySQL 和 Redis 的最終一致性,但無法保證實時性。在查詢過程中,若緩存中無數據,則直接查詢 DB;若緩存中有數據,也可能存在數據不一致的情況。
二、方案比較:抉擇最優解
- 先寫 Redis,再寫 MySQL:若數據庫出現故障,而數據僅存在于緩存中,會導致嚴重的數據不一致問題,且寫數據庫失敗后對 Redis 的逆操作若失敗,處理起來較為復雜,因此不建議使用。
- 先寫 MySQL,再寫 Redis:適用于并發量和一致性要求不高的項目。當 Redis 不可用時,需要及時報警并進行線下處理。
- 先刪除 Redis,再寫 MySQL:實際應用中使用較少,不推薦采用該方案。
- 先刪除 Redis,再寫 MySQL,再刪除 Redis:雖然方案可行,但實現較為復雜,需要借助消息隊列來實現異步刪除 Redis 的操作。
- 先寫 MySQL,再刪除 Redis:此方案較為推薦,刪除 Redis 失敗時可進行多次重試,若重試無效則報警。在實時性方面表現較好,適用于高并發場景。
- 先寫 MySQL,通過 Binlog,異步更新 Redis:適用于異地容災、數據匯總等場景,結合 binlog 和 kafka 可使數據一致性達到秒級,但不適合純粹的高并發場景,如搶購、秒殺等。
| 方案 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 先寫Redis,再寫MySQL | 無明顯優點 | 數據庫掛掉時,數據存在緩存但未寫入數據庫,會造成數據不一致;寫數據庫失敗后對Redis的逆操作若失敗,處理復雜 | 不推薦用于任何場景 |
| 先寫MySQL,再寫Redis | 實現簡單 | 高并發時易出現數據不一致;Redis不可用時需線下處理 | 并發量和一致性要求不高的項目 |
| 先刪除Redis,再寫MySQL | 無明顯優點 | 出現數據不一致的概率較大,實際應用中較少使用 | 不推薦用于任何場景 |
| 先刪除Redis,再寫MySQL,再刪除Redis | 能解決部分數據不一致問題 | 實現復雜,需借助消息隊列異步刪除Redis | 對一致性要求極高,且能接受復雜實現的場景 |
| 先寫MySQL,再刪除Redis | 實時性較好,刪除Redis失敗可重試,適用于高并發場景 | 存在短暫不一致的情況,對強一致性要求的業務不適用 | 對一致性要求不是特別強的高并發場景,如一般的電商商品展示等 |
| 先寫MySQL,通過Binlog,異步更新Redis | 能保證最終一致性,適用于異地容災、數據匯總等場景 | 無法保證實時性,不適合高并發場景 | 異地容災、數據匯總等對實時性要求不高的場景 |
三、項目實戰:代碼實現的精彩呈現
假設我們有一個簡單的博客文章管理系統,需要保證文章標簽數據在 MySQL 和 Redis 中的一致性。采取先寫 MySQL,再刪除 Redis方案,以下是相關的代碼實現示例:
(一)數據更新
- 寫操作:
○ 優先操作MySQL:通過事務保證數據庫更新原子性。
○ 同步刪除Redis緩存:若刪除失敗觸發事務回滾(需結合業務驗證),防止臟數據。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import redis.clients.jedis.Jedis;public class DataUpdate {private static final String DB_URL = "jdbc:mysql://localhost:3306/blog";private static final String DB_USER = "root";private static final String DB_PASSWORD = "password";public static void updateArticleTags(String articleId, String newTags) {Connection conn = null;PreparedStatement pstmt = null;Jedis jedis = new Jedis("localhost", 6379);try {// 連接數據庫conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);// 開啟事務conn.setAutoCommit(false);// 更新 MySQL 數據String sql = "UPDATE articles SET tags =? WHERE id =?";pstmt = conn.prepareStatement(sql);pstmt.setString(1, newTags);pstmt.setString(2, articleId);pstmt.executeUpdate();// 刪除 Redis 緩存jedis.del("article:" + articleId + ":tags");// 提交事務conn.commit();} catch (SQLException e) {try {// 回滾事務if (conn != null) {conn.rollback();}} catch (SQLException ex) {ex.printStackTrace();}e.printStackTrace();} finally {// 關閉資源if (pstmt != null) {try {pstmt.close();} catch (SQLException e) {e.printStackTrace();}}if (conn != null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}jedis.close();}}
}
(二)數據獲取
- 讀操作:
○ 先查緩存:命中則直接返回數據。
○ 未命中查DB:查詢結果回寫Redis并設置過期時間,避免緩存穿透。
import redis.clients.jedis.Jedis;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;public class DataRetrieval {private static final String DB_URL = "jdbc:mysql://localhost:3306/blog";private static final String DB_USER = "root";private static final String DB_PASSWORD = "password";public static String getArticleTags(String articleId) {Jedis jedis = new Jedis("localhost", 6379);String tags = jedis.get("article:" + articleId + ":tags");if (tags == null) {Connection conn = null;PreparedStatement pstmt = null;ResultSet rs = null;try {// 連接數據庫conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);String sql = "SELECT tags FROM articles WHERE id =?";pstmt = conn.prepareStatement(sql);pstmt.setString(1, articleId);rs = pstmt.executeQuery();if (rs.next()) {tags = rs.getString("tags");// 將數據寫入 Redis 緩存,并設置過期時間(例如 60 秒)jedis.setex("article:" + articleId + ":tags", 60, tags);}} catch (SQLException e) {e.printStackTrace();} finally {// 關閉資源if (rs != null) {try {rs.close();} catch (SQLException e) {e.printStackTrace();}}if (pstmt != null) {try {pstmt.close();} catch (SQLException e) {e.printStackTrace();}}if (conn != null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}}}}return tags;}
}
四、總結
通過對 MySQL 與 Redis 緩存一致性的多種方案的分析和實際項目的代碼實現,我們了解到不同方案的優缺點和適用場景。在實際開發中,應根據項目的具體需求,如并發量、一致性要求、業務場景等,選擇合適的方案來保證數據的一致性。希望本文能為你在處理 MySQL 與 Redis 緩存一致性問題時提供有益的參考和幫助。


列表練習題)






)




—— 僅服務端模塊和快照)




