一、磁盤
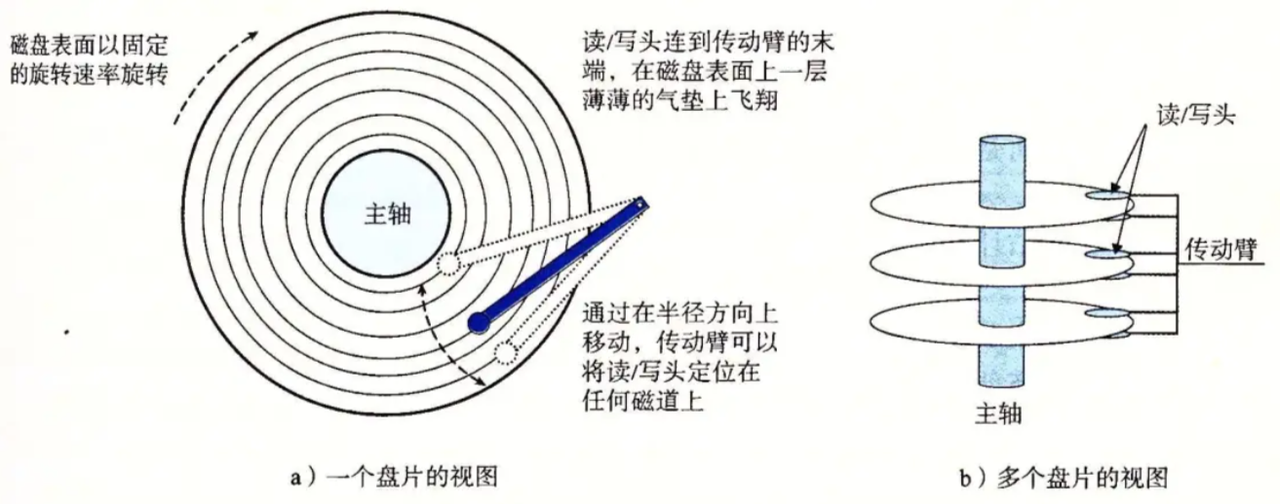
1.磁盤的物理結構

2.磁盤的存儲結構
- 盤片:是機械硬盤存儲數據的主要介質,一般由鋁合金或玻璃等材料制成,表面涂有一層磁性材料。數據通過磁頭在盤片的磁性涂層上進行磁化來記錄,磁化的不同方向代表二進制的 0 和 1。
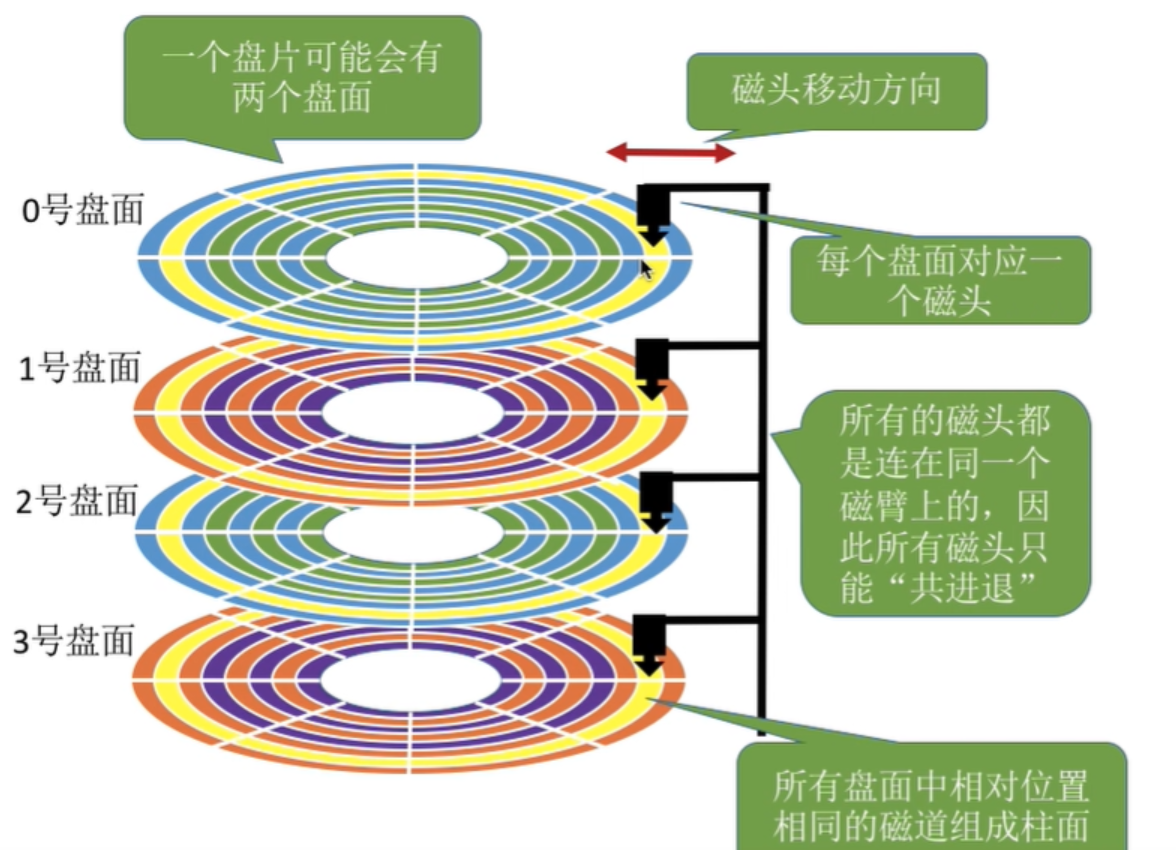
- 盤面:機械硬盤通常包含多個盤片,每個盤片有上下兩個盤面,數據可以存儲在這些盤面上。盤面是磁盤存儲數據的實際表面,磁頭通過在盤面上移動來讀寫數據。
- 盤面編號:在機械硬盤中,為了方便對多個盤面進行管理和區分,會對每個盤面進行編號。一般來說,最上面的盤面編號為 0,然后依次向下遞增。例如,一個有 2 個盤片的機械硬盤,就會有 0、1、2、3 共 4 個盤面。
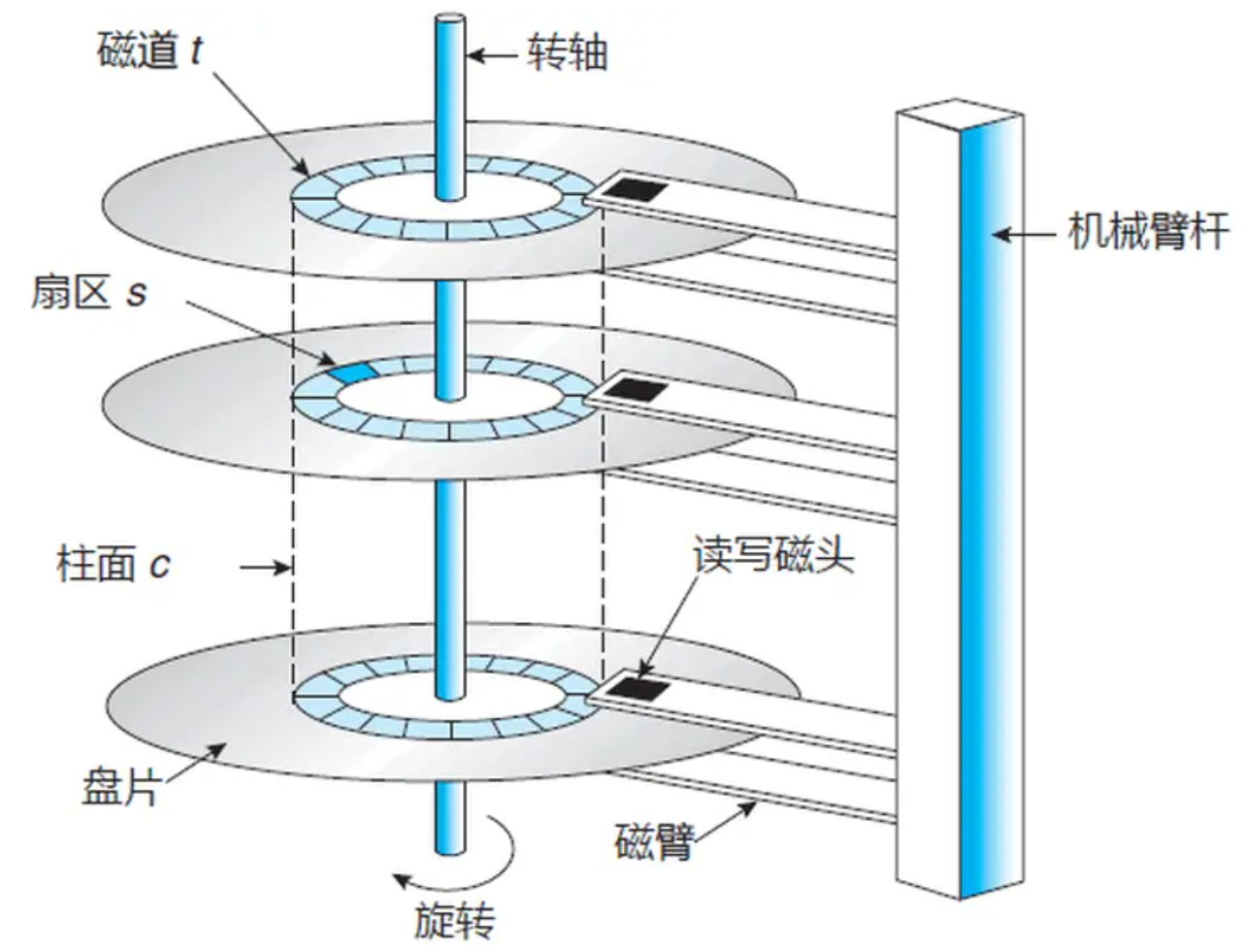
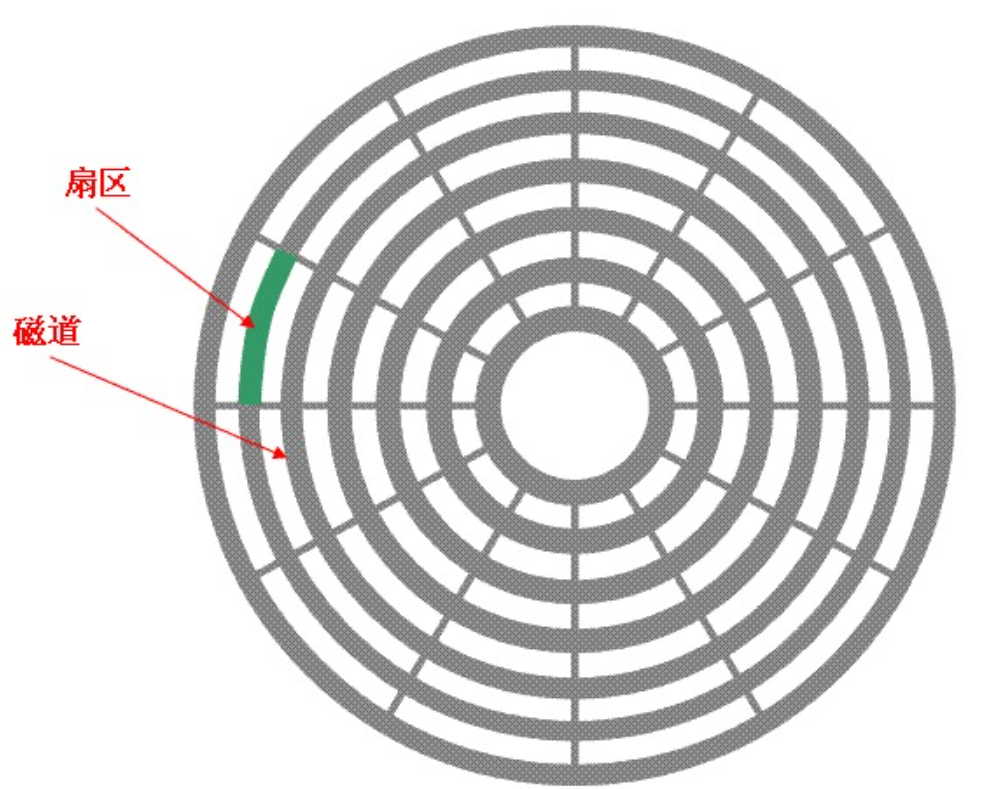
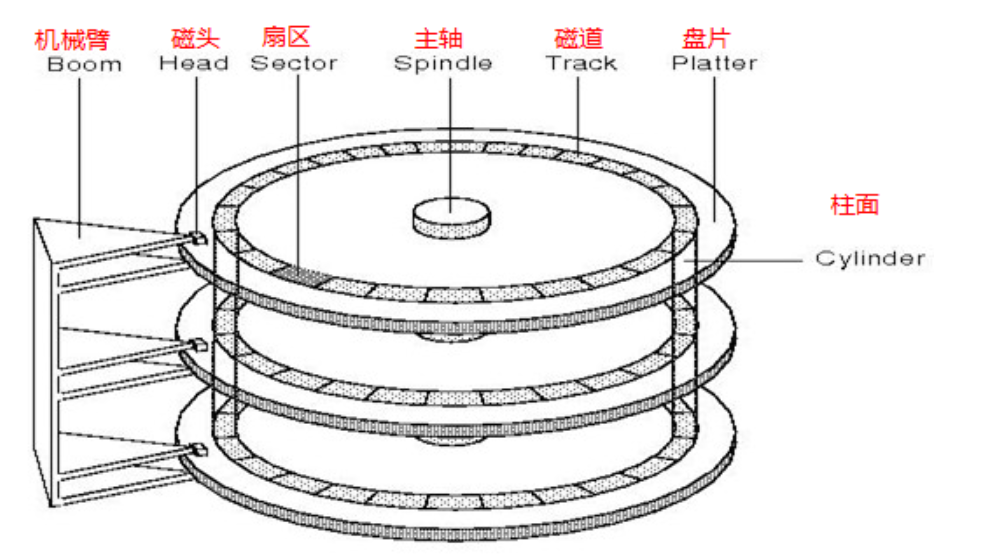
- 磁道:盤片上的圓形軌跡,每個盤片通常有大量的磁道,從盤片的中心向外邊緣輻射。磁道是數據存儲的基本單位之一,數據按順序存儲在磁道上。
- 磁道編號:磁道是盤面上的圓形軌跡,從盤片的中心向外邊緣分布。為了準確地定位和訪問數據,每個磁道都有一個唯一的編號。通常,最靠近盤片中心的磁道編號為 0,然后隨著磁道從內向外依次遞增。磁道編號是操作系統和磁盤控制器用于定位數據的重要依據,通過指定磁道編號,磁頭可以快速地移動到相應的磁道上進行數據讀寫操作。
- 扇區:是磁道的進一步劃分,每個磁道被劃分為若干個扇區。扇區是磁盤進行數據讀寫的最小單位,通常每個扇區的大小為 512 字節或 4096 字節等。
- 扇區編號:扇區編號是從磁道的某個起始位置開始,按順時針方向依次遞增。不同的磁盤格式和文件系統可能對扇區編號的具體規則有所不同,但一般都是連續編號。扇區編號與磁道編號、盤面編號等一起,構成了磁盤數據存儲的完整地址信息,操作系統和應用程序通過這些編號來準確地定位和讀寫磁盤上的數據。
- 柱面:由不同盤片上相同位置的磁道組成,在進行數據讀寫時,磁頭可以在同一柱面上的不同盤片的磁道之間快速切換,提高數據訪問效率。
- 柱面編號:柱面編號與磁道編號相對應,因為同一柱面上的磁道在不同盤面上的位置是相同的,所以柱面編號實際上也是從內向外依次遞增,最內側的柱面編號為 0。在進行數據讀寫時,操作系統和磁盤控制器可以通過指定柱面編號,同時對多個盤面上的同一柱面的磁道進行操作,提高數據傳輸效率。例如,在讀取大量連續數據時,可能會先在一個柱面的所有磁道上讀取數據,然后再移動到下一個柱面,這樣可以減少磁頭的移動距離和尋道時間。
- 磁頭:負責在盤片上進行數據的讀寫操作,通過電磁感應原理,將電信號轉換為磁信號記錄在盤片上,或者將盤片上的磁信號轉換為電信號讀取出來。
- 傳動臂:傳動臂是機械硬盤中的一個重要部件,它的一端連接著磁頭,另一端由電機和控制電路驅動。傳動臂的磁頭是共進退的。

在虛擬機上磁盤位置:/dev/sda
在云服務器上磁盤位置:/dev/vda
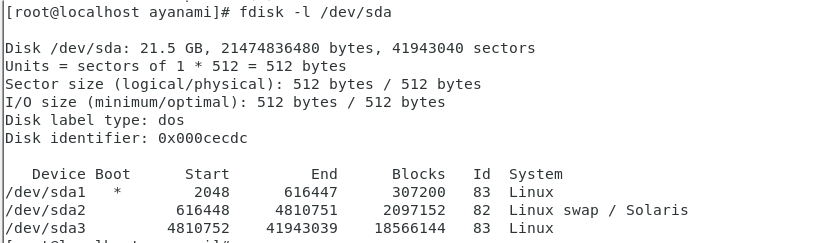
命令:fdisk -l /dev/sda,查看磁盤信息,需要root權限
- 磁盤基本信息:
- 磁盤?
/dev/sda?大小為 21.5GB ,總字節數是 2147483648 ,總扇區數 41943040 。- 扇區大小邏輯和物理均為 512 字節 ,I/O 最小和最佳大小也都是 512 字節 。
- 磁盤標簽類型為?
dos?,磁盤標識符為?0x000cecdc。- 分區信息:
/dev/sda1?分區:是啟動分區(有?*?標識),起始扇區為 2048 ,結束扇區為 616647 ,塊數 307200 ,分區 ID 為 83 ,系統類型為?Linux。/dev/sda2?分區:起始扇區為 616648 ,結束扇區為 4810751 ,塊數 2097152 ,分區 ID 為 82 ,系統類型為?Linux swap / Solaris(交換分區)。/dev/sda3?分區:起始扇區為 4810752 ,結束扇區為 41943039 ,塊數 18566144 ,分區 ID 為 83 ,系統類型為?Linux?。
3.CHS尋址
文件=內容+屬性,都是數據,無非就是占用幾個扇區的事,如果定位某個扇區,就能定位某些數據。
通過柱面(cylinder)->? 磁頭(head) ->? 扇區(sector),顯然就可以定位數據了,這種數據定位的方式稱之為CHS尋址方式,這是物理結構上的尋址。
CHS的局限性:由于系統對磁頭地址(8bit,可表示 2? = 256 個磁頭)、柱面地址(10bit,可表示 21? = 1024 個柱面)、扇區地址(6bit,可表示 2? = 63 個扇區 )的存儲位數限制,結合每個扇區 512Byte 的大小,導致其支持的硬盤最大容量有限。按二進制換算(1MB = 1048576B)為 256 * 1024 * 63 * 512B = 8064MB;按十進制換算(1MB=1000000B) 則是 8.4GB。
4.磁盤的邏輯結構與LBA地址
我們熟知的磁帶上面可以存儲數據,我們可以把磁帶“拉直”,形成線性結構。
磁盤在邏輯上也可以想象成“拉直”,形成線性結構;以每個扇區作為元素,組成一個數組,這樣線性地址其實就是數組下標,這種地址叫做LBA。
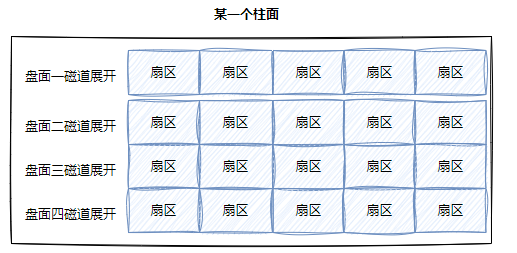
柱面屬于邏輯上的概念,其實每一面都是由相同半徑的磁道邏輯上構成柱面。磁盤物理上分了很多面,但在邏輯結構上,可以認為磁盤整體是由柱面卷起來的。
柱面展開:
整盤展開:
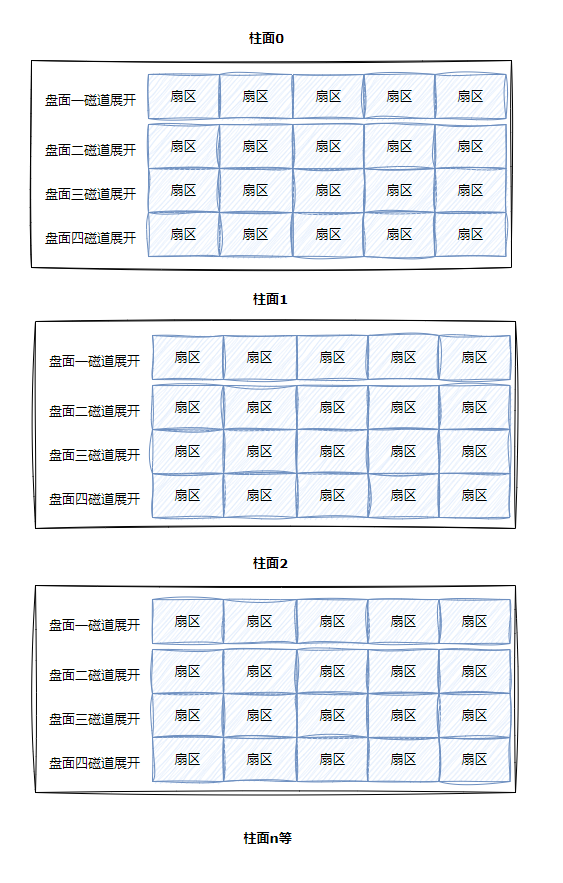
?所以尋址一個扇區,先找到哪一個柱面C,再確定柱面內哪一個磁道H,再確定扇區S,所以就有了CHS。
對于邏輯上的三維數組,實際上可以合為一個維度,變成一維數組:

所以每一個扇區都有一個下標,我們叫做LBA(Logical Block Address)地址,其實就是線性地址,LBA屬于邏輯上的地址。
LBA 將硬盤上的所有扇區從 0 開始進行線性編號,把存儲設備看作是一個連續的線性存儲空間,不再像 CHS(柱面 - 磁頭 - 扇區)尋址那樣依賴磁盤的物理結構。操作系統和軟件通過這些編號來訪問特定的扇區,簡化了對存儲設備的操作。
OS
5.CHS與LBA的轉換
CHS -->? LBA:
- LBA = 柱面編號C * 單個柱面的扇區總數(磁頭數 * 每個磁道扇區數) +? 磁頭編號H * 每個磁道扇區數 + 扇區號 - 1
- 扇區號通常是從1開始,在LBA中,地址是從0開始的
- 柱面和磁道都是從0開始編號的
LBA -->? CHS:
- 柱面編號C = LBA // 單個柱面的扇區總數(磁頭數 * 每個磁道扇區數)注://:表示取整除
- 磁頭編號H = LBA % 單個柱面的扇區總數(磁頭數 * 每個磁道扇區數)
- 扇區編號S = LBA % 每個磁道扇區數 + 1?
OS只需要直接使用LBA與磁盤數據交互,LBA與CHS互相轉化由磁盤自己來做(硬件電路,伺服系統) ,所以磁盤使用者需要注意的是LBA地址即可,對于使用者和OS來說,磁盤現在就是一個元素為扇區的一維數組,數組的下標就是每一個扇區的LBA地址,OS使用磁盤時就可以用一個數字訪問磁盤扇區了。
二、文件系統
1.塊
其實硬盤是典型的“塊”設備,操作系統讀取硬盤數據的時候,其實是不會一個個扇區地讀取,這樣效率太低,而是一次性連續讀取多個扇區,即一次性讀取一個”塊”(block)。
硬盤的每個分區是被劃分為一個個的”塊”。一個”塊”的大小是由格式化的時候確定的,并且不可以更改,最常見的是4KB,即連續八個扇區(512KB)組成一個”塊”。”塊”是文件存取的最小單位。
命令:
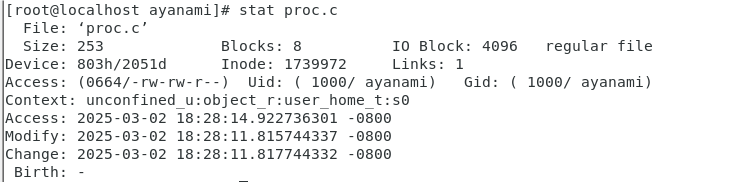
stat命令用于顯示文件或文件系統的詳細狀態信息。stat [選項] 文件或目錄-c:指定輸出格式,可自定義顯示的信息字段。 -f:顯示文件系統的狀態信息,而不是文件本身的信息。 -L:跟隨符號鏈接,顯示符號鏈接所指向的目標文件的狀態信息。 -t:以簡潔的表格形式輸出信息。
- 文件基本信息
- File:文件名。
- Size:文件大小,以字節為單位。
- Blocks:文件實際占用的磁盤塊數。
- IO Block:文件系統的輸入 / 輸出塊大小(塊是文件存取的最小單位)。
- 文件權限和屬性
- Device:文件所在設備的編號。
- Inode:文件的 inode 編號,用于在文件系統中唯一標識文件。
- Links:文件的硬鏈接數。
- Access:文件的訪問權限,以八進制和字符形式表示。
- Uid:文件所有者的用戶 ID。
- Gid:文件所有者的組 ID。
- 時間戳
- Access:文件的最后訪問時間。
- Modify:文件內容的最后修改時間。
- Change:文件的元數據(如權限、屬性等)的最后更改時間。
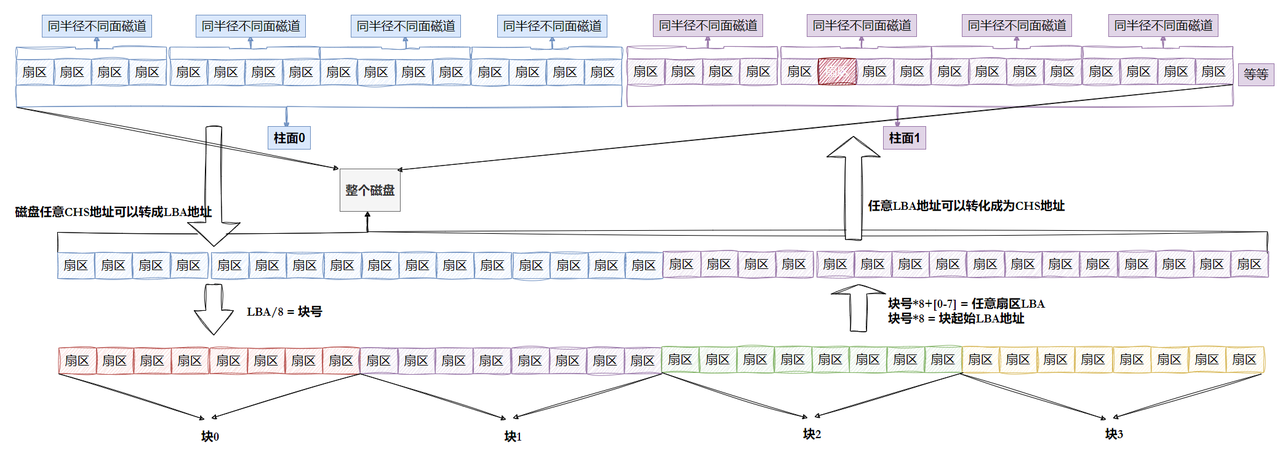
把磁盤的三維數組看出一維數組,數組下標就是LBA,每一個元素都是扇區,8個扇區一個塊,那么每一個塊的地址我們也能算出來:
- 知道LBA : 塊號 = LBA / 8
- 知道塊號:LBA = 塊號 * 8 + n(n是塊號第幾個扇區)
?2.分區
其實磁盤是可以被分成多個分區(partition)的,以Windows觀點來看,你可能會有一塊磁盤并且將它分區成C,D,E盤。那個C,D,E就是分區。分區從實質上說就是對硬盤的一種格式化。
Linux 分區是對存儲設備(如硬盤、固態硬盤)進行邏輯劃分的過程。通過分區,可將存儲設備分割成多個獨立區域,便于數據分類存儲、系統安裝、提高管理效率和保障數據安全。
分區類型:
- 主分區
- 定義:主分區是硬盤上直接可以使用的分區,它可以用來安裝操作系統,也可以用來存儲用戶的數據文件等。
- 特點:每個硬盤最多可以劃分 4 個主分區。主分區具有獨立的引導記錄,計算機在啟動時可以直接從主分區加載操作系統,從而引導系統啟動。比如我們通常將 Windows 系統安裝在 C 盤,這個 C 盤一般就是一個主分區。
- 擴展分區
- 定義:擴展分區是一種特殊的分區,它不能直接用來存儲數據和安裝操作系統,其主要作用是為了突破主分區數量的限制,為創建更多的邏輯分區提供空間。
- 特點:一個硬盤上最多只能有一個擴展分區。擴展分區可以被看作是一個容器,它可以進一步劃分成多個邏輯分區。
- 邏輯分區
- 定義:邏輯分區是在擴展分區內創建的分區,它是從擴展分區中劃分出來的邏輯區域。
- 特點:邏輯分區可以像主分區一樣用于存儲數據和安裝一些軟件等。邏輯分區的數量沒有嚴格限制,用戶可以根據自己的需求在擴展分區內創建多個邏輯分區,例如 D 盤、E 盤等通常可以是邏輯分區。
分區表:
- 定義:分區表是存儲在硬盤上的一種數據結構,它記錄了硬盤上各個分區的相關信息,如分區的起始位置、大小、類型等。
- 特點:分區表對于操作系統識別和訪問硬盤上的分區至關重要。常見的分區表格式有 MBR(Master Boot Record)和 GPT(GUID Partition Table)。
- MBR(主引導記錄)
- 傳統分區表格式,位于硬盤第一個扇區,包含分區信息和引導程序。
- 最大支持 2TB 硬盤容量,最多創建 4 個主分區或 3 個主分區加 1 個擴展分區。
- GPT(全局唯一標識分區表)
- 較新的分區表格式,支持更大硬盤容量(理論上無上限),可創建更多分區。
- 具備更好的容錯性和數據安全性,是現代大容量硬盤常用分區表格式。
分區操作流程:
- 查看磁盤信息:命令 sudo fdisk -l,列出系統中所有磁盤設備及其分區信息。
- 進入分區操作界面:命令sudo fdisk /dev/sda,進入fdisk交互界面。
- 創建分區:在交互界面輸入n創建新分區;選擇分區類型(主分區或擴展分區),按提示設置分區起始和結束位置(設置的位置都是以扇區為單位計量的,并且是閉區間)。
- 設置分區類型:輸入t,選擇分區號后輸入對應代碼設置分區類型,如:Linux文件系統(83),swap交換分區(82);
- 保存分區設置:輸入w保存分區設置并退出fdisk。
- 格式化分區:創建分區后,需格式化為合適的文件系統,如將/dev/sda1格式化為ext4:
sudo mkfs.ext4 /dev/sda1
3.inode
使用命令 ls -l 時,可以看見文件名,還能看見文件元數據(屬性):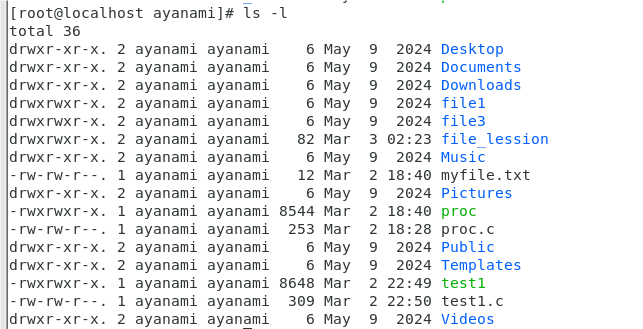
從左到右的共七列:模式、硬鏈接數、文件所有者、組、大小、最后修改時間、文件名
ls -l是讀取存儲在磁盤上的文件信息,然后顯示出來。除此之外,還有剛才介紹的stat命令能看到更多的信息
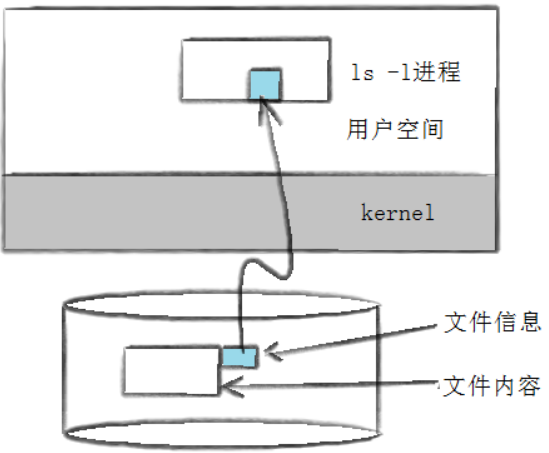
文件數據都儲存在“塊”中,那么很顯然,我們還必須找到一個地方儲存文件的元信息(屬性信息),比如文件的創建者、文件的創建日期、文件的大小等等。這種儲存文件元信息的區域就叫做inode,中文譯名為”索引節點”。
命令ls的選項-i,可以查看每個文件對應的inode,里面包含了與該文件有關的一些信息。
- Linux下文件的存儲是屬性和內容分離存儲的。
- Linux下,保存文件屬性的集合叫做inode,一個文件對應一個inode,inode內有一個唯一的標識符,叫做inode號。
- 文件名屬性并沒有在inode數據結構內部!!!
- indoe的大小一般是128字節或者256字節,下面統一128字節
- 任何文件的內容大小可以不同,但是屬性大小一定是相同的
ext2_inode源碼:
struct ext2_inode {__le16 i_mode; /* 文件模式,存儲文件類型和訪問權限信息 */__le16 i_uid; /* 文件所有者的用戶ID,存儲低16位 */__le32 i_size; /* 文件大小,單位是字節 */__le32 i_atime; /* 文件的訪問時間 */__le32 i_ctime; /* 文件的創建時間或inode狀態變更的時間 */__le32 i_mtime; /* 文件內容最后一次被修改的時間 */__le32 i_dtime; /* 文件刪除時間 */__le16 i_gid; /* 文件所有者的組ID,存儲低16位 */__le16 i_links_count; /* 鏈接計數,指向該inode的硬鏈接數量 */__le32 i_blocks; /* 文件所占的塊數量,單位是512字節塊 */__le32 i_flags; /* 文件標志,標識文件的特定屬性 */union {struct {__le32 l_i_reserved1;} linux1;struct {__le32 h_i_translator;} hurd1;struct {__le32 m_i_reserved1;} masix1;} osd1; /* 操作系統依賴的字段 */__le32 i_block[EXT2_N_BLOCKS]; /* 文件數據塊的指針數組 */__le32 i_generation; /* 文件版本,用于NFS */__le32 i_file_acl; /* 文件ACL */__le32 i_dir_acl; /* 目錄ACL */__le32 i_faddr; /* 片段地址 */union {struct {__u8 l_i_frag; /* 片段編號 */__u8 l_i_fsize; /* 片段大小 */__u16 i_pad1;__le16 l_i_uid_high;__le16 l_i_gid_high;__u32 l_i_reserved2;} linux2;struct {__u8 h_i_frag;__u8 h_i_fsize;__le16 h_i_mode_high;__le16 h_i_uid_high;__le16 h_i_gid_high;__le32 h_i_author;} hurd2;struct {__u8 m_i_frag;__u8 m_i_fsize;__u16 m_pad1;__u32 m_i_reserved2[2];} masix2;} osd2; /* 操作系統依賴的字段 */
};結構與內容:
- 基本信息:包括文件的類型(普通文件、目錄、字符設備文件、塊設備文件等)、權限(如讀寫執行權限)、所有者和所屬組。
- 時間戳:記錄文件的訪問時間(atime)、修改時間(mtime,文件內容被修改的時間)和狀態改變時間(ctime,inode 信息改變的時間,如權限修改)。
- 文件大小:以字節為單位的文件大小。
- 鏈接計數:硬鏈接的數量,即有多少個文件名指向這個 inode。
- 數據塊指針:指向存儲文件實際數據的磁盤塊的指針。根據文件大小不同,可能采用直接指針、間接指針或雙重間接指針等方式來定位數據塊。
作用:
- 文件系統管理:inode 為文件系統提供了一種高效的文件管理方式。通過 inode,文件系統可以快速定位和訪問文件的屬性信息以及文件的數據塊,從而實現對文件的各種操作,如文件的打開、關閉、讀寫等。
- 數據安全和完整性:inode 中記錄的文件權限、所有者等信息有助于保證系統的安全性和數據的完整性。系統可以根據 inode 中的權限信息來判斷用戶是否有權對文件進行相應的操作,防止非法訪問和數據篡改。
- 文件系統組織:inode 在文件系統的組織和布局中起著關鍵作用。它使得文件系統能夠以一種有序的方式存儲和管理大量的文件,方便用戶和系統對文件進行查找、分類和管理。
工作機制:
- 文件訪問:當用戶通過文件名訪問文件時,文件系統首先通過目錄項找到對應的 inode 號,然后根據 inode 號找到對應的 inode 結構,從 inode 中獲取文件的權限、數據塊位置等信息,進而讀取或寫入文件數據。
- 文件創建與刪除:創建文件時,文件系統會分配一個新的 inode,并在目錄中添加一個指向該 inode 的目錄項;刪除文件時,會減少 inode 的鏈接計數,如果鏈接計數變為 0,則釋放 inode 和相關的數據塊。
inode 號:
- 每個 inode 都有一個唯一的 inode 號,在整個文件系統中用于標識該 inode。文件系統通過 inode 號來查找和操作 inode,而不是文件名。文件名只是用戶方便識別和操作文件的一個標簽,真正在底層文件系統中進行數據處理和管理時,使用的是 inode 號。
與文件的特殊關系:
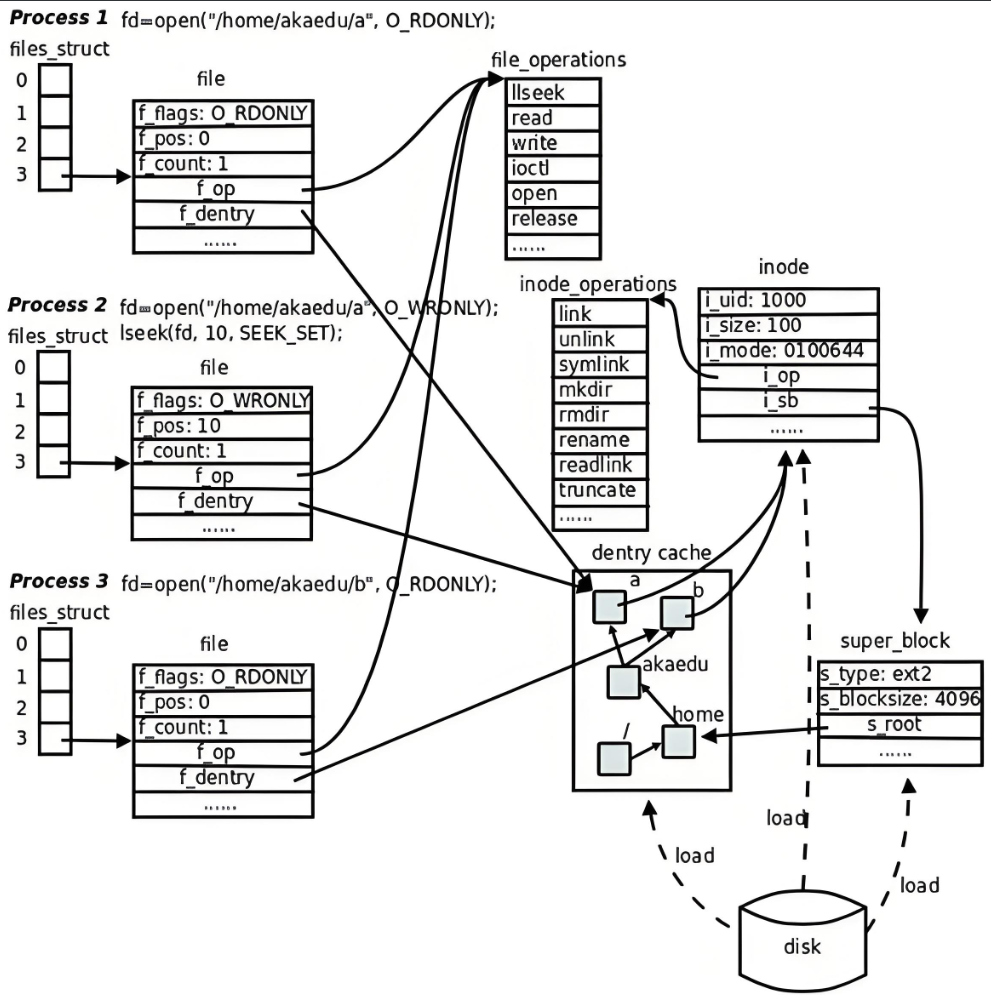
- 硬鏈接:多個文件名可以指向同一個 inode,這種情況被稱為硬鏈接。多個硬鏈接文件共享同一個 inode 及文件數據,對其中一個文件的修改會反映到其他硬鏈接文件上,因為它們本質上是同一個文件的不同名稱,都指向同一個 inode。
4.ext2文件系統
我們已經知道,硬盤是典型的“塊”設備,操作系統讀取硬盤數據的時候,讀取的基本單位是“塊”,”塊“同時也是硬盤的每個分區下的結構,那么”塊“在分區中是如何排布的?要通過什么方式找到”塊“呢?存儲文件屬性的inode又是以什么方式存在的?
文件系統就是為了組織管理這些的!
宏觀認識:
在硬盤上存儲文件,必須先把硬盤格式化為某種格式的文件系統才能存儲文件,文件系統的目的就是組織和管理硬盤中的文件的;在Linux中,最常見的是ext2系列的文件系統。
ext2文件系統將整個分區劃分成若干個同樣大小的塊組(Block Group),如下圖所示,只要能管理一個分區就能管理所有分區,也就能管理所有磁盤文件。
上圖中的啟動塊(Boot Block/Sector)的大小是確定的,為1KB,由PC標準規定,用來存儲磁盤 分區 信息和啟動信息,任何文件系統都不能修改啟動塊,啟動塊之后才是ext2文件系統的開始。
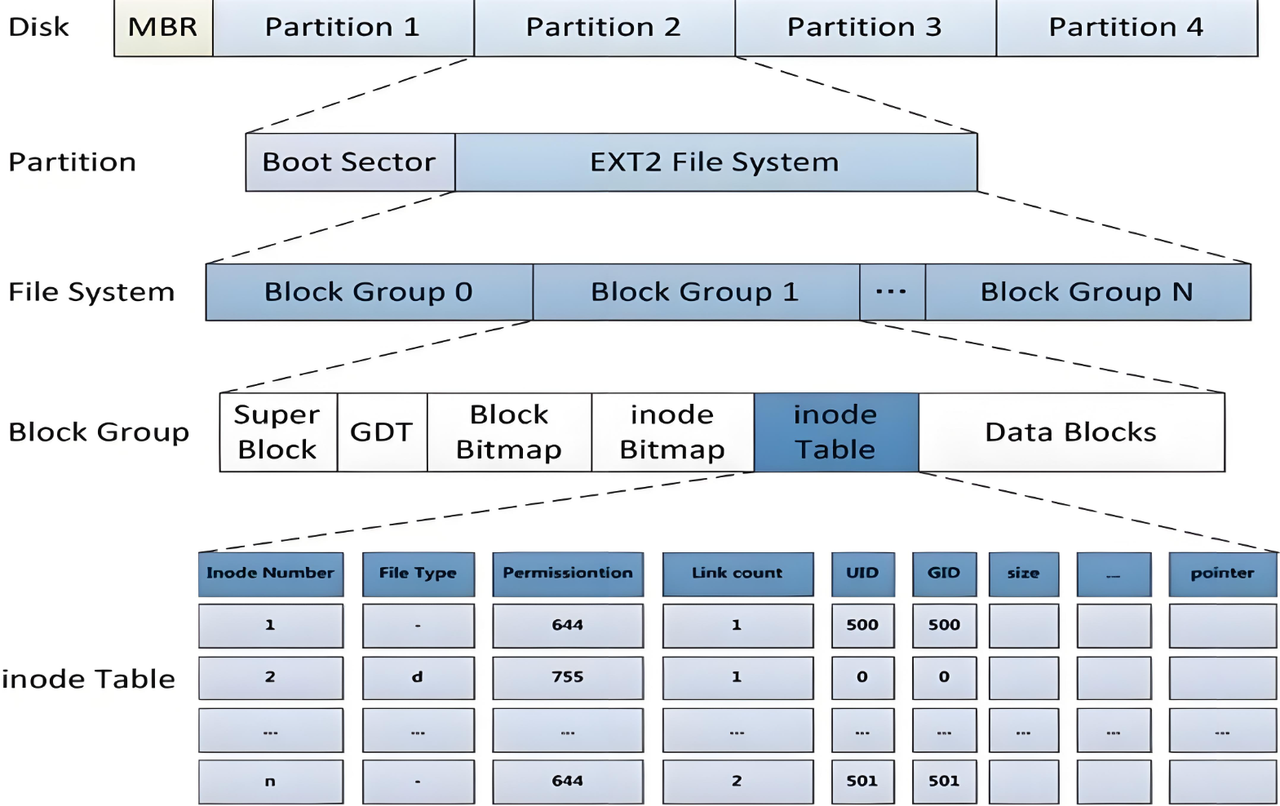
Block Group(塊組):?
ext2文件系統會根據分區的大小劃分若干個大小相同的塊組Block Group,而每個Block Group都有著相同的結構組成。
1.磁盤層面(Disk):
- MBR(主引導記錄):位于磁盤的第一個扇區,大小通常為 512 字節。它承擔著極其關鍵的雙重任務。一方面,包含了引導加載程序(Bootloader),這是計算機啟動時運行的第一段代碼,負責加載操作系統內核到內存中,從而啟動操作系統。例如常見的 GRUB(Grand Unified Bootloader),它就可以安裝在 MBR 中,支持多操作系統的啟動管理。另一方面,MBR 還包含了一個分區表,這個表記錄了磁盤上各個分區的起始位置、大小以及分區的類型等信息。不過,MBR 分區表最多只能記錄 4 個主分區的信息,如果需要更多分區,就需要使用擴展分區等方式來實現。圖中可以看到,在 MBR 之后緊接著就是 4 個分區,分別標記為 Partition 1 到 Partition 4 。
2.分區層面(Partition):
- 引導扇區(Boot Sector):每個分區的開頭部分就是引導扇區。它同樣包含了一小段引導代碼,其作用是在計算機啟動過程中,從該分區加載操作系統的引導程序。不同的操作系統可能會對引導扇區有不同的格式要求和使用方式。比如,Windows 系統和 Linux 系統的引導扇區在結構和功能上就存在一定差異。
- EXT2 文件系統區域:引導扇區之后就是 EXT2 文件系統占據的空間。EXT2 文件系統會將這部分空間進一步組織和管理,以實現對文件和目錄的存儲與訪問。
3.文件系統層面(File System):
- 塊組(Block Group)劃分:EXT2 文件系統把自身的存儲空間劃分為多個塊組,從圖中可以看到從 Block Group 0 到 Block Group N 。這樣做有幾個重要的好處。首先,每個塊組都包含了文件系統的一些關鍵元數據和數據存儲區域,當某個塊組出現損壞時,其他塊組的數據仍然有可能保持完整,從而提高了文件系統的可靠性。其次,在進行文件操作時,系統可以在相對較小的塊組范圍內查找和管理資源,減少了搜索整個文件系統的開銷,提高了操作效率。
4.塊組內部結構(Block Group):
- 超級塊(Super Block):存儲著關于整個文件系統的全局信息,是文件系統管理的核心數據結構之一。這些信息包括文件系統的塊大小(例如常見的 1KB、2KB 或 4KB ),這決定了數據存儲和讀取的基本單位;inode 的總數,它關系到文件系統能夠容納的文件和目錄數量;塊組的數量,用于文件系統的內部組織和管理;以及文件系統的狀態信息,如是否被正確卸載、是否需要進行一致性檢查等。
為了防止超級塊損壞導致整個文件系統無法訪問,超級塊會在多個塊組中進行備份,但并非所有塊組都有超級塊備份,主要是基于空間利用和實際需求的考量:一方面,每個超級塊內容相同,全部塊組都備份會造成大量空間浪費。另一方面,日常使用中,少量備份足以應對大部分損壞情況,如在部分塊組受損時,仍可從其他備份恢復。- 組描述符表(GDT,Group Descriptor Table):記錄了每個塊組的詳細屬性信息,比如塊位圖在塊組中的位置、inode 位圖的位置、inode 表的位置以及數據塊區域的起始位置等。通過組描述符表,文件系統可以快速定位和訪問各個塊組內的關鍵數據結構。
- 塊位圖(Block Bitmap):是一個二進制位序列,每一位對應一個數據塊。如果某一位的值為 0,表示對應的那個數據塊目前處于空閑狀態,可以被分配用來存儲文件數據;如果值為 1,則表示該數據塊已經被占用。文件系統在分配和釋放數據塊時,會通過更新塊位圖來記錄數據塊的使用情況。
- inode 位圖(inode Bitmap):與塊位圖類似,也是一個二進制位序列,每一位對應一個 inode。0 表示該 inode 未被使用,可以分配給新的文件或目錄;1 表示該 inode 已經被占用,對應著一個已存在的文件或目錄。inode 位圖幫助文件系統有效地管理 inode 的分配和回收。
- inode 表(inode Table):是一個包含了塊組內所有 inode 的表格。每個 inode 都是一個數據結構,用于存儲一個文件或目錄的詳細元數據信息。這些信息包括:
- inode 編號(Inode Number):在整個文件系統中唯一標識一個 inode ,用于快速定位和查找對應的 inode。
- 文件類型(File Type):指明該 inode 對應的是普通文件(用 “-” 表示)、目錄(用 “d” 表示)、字符設備文件、塊設備文件還是符號鏈接等。
- 權限(Permission):以數字或符號的形式表示文件或目錄的訪問權限,例如 644 表示所有者有讀寫權限,組用戶和其他用戶只有讀權限;755 表示所有者有讀寫執行權限,組用戶和其他用戶有讀執行權限。
- 鏈接計數(Link count):記錄了指向該 inode 的硬鏈接的數量。當創建一個硬鏈接時,鏈接計數會增加;刪除一個硬鏈接時,鏈接計數會減少,當鏈接計數為 0 時,文件系統會認為該文件沒有被引用,可以釋放相關的 inode 和數據塊資源。
- 用戶 ID(UID)和組 ID(GID):分別表示文件或目錄的所有者的用戶 ID 和所屬的組 ID,用于權限控制和資源管理。
- 文件大小(size):以字節為單位記錄文件的實際大小。
- 指針(pointer):指向存儲文件實際數據的數據塊。根據文件大小的不同,可能會有直接指針(直接指向數據塊)、間接指針(指向一個存儲數據塊地址的塊)甚至雙重間接指針、三重間接指針等,以適應不同大小文件的數據存儲需求。
- 數據塊(Data Blocks):是實際存儲文件和目錄內容的地方。文件的數據會被分割成若干個小塊,存儲在這些數據塊中。文件系統通過 inode 中的指針信息來定位和訪問這些數據塊,從而實現對文件的讀取和寫入操作。
需要注意:
- inode編號以分區為單位,整體劃分,不可以跨分區
- Block號按照分區劃分,不可跨分區
- 對于普通文件,文件的數據存儲在數據塊中
- 對于目錄,該目錄下的所有文件名和目錄名存儲在所在目錄的數據塊中,除了文件名外,ls -l命令看到的其他信息保存在該文件的inode中
inode與Data Block映射 :
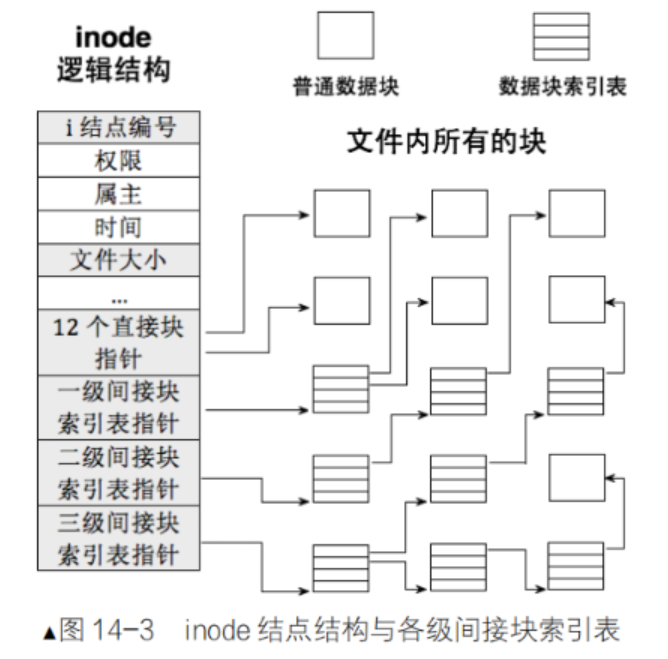
通過上面的介紹,我們知道文件系統通過inode中的指針信息來定位和訪問這些數據塊,從而實現對文件的讀取和寫入操作。inode內部存在下圖所示結構,就是用來進行inode和block映射的;其中的EXT2_N_BLOCKS = 15。根據文件大小的不同,可能會有直接指針(直接指向數據塊)、間接指針(指向一個存儲數據塊地址的塊)甚至雙重間接指針、三重間接指針等,以適應不同大小文件的數據存儲需求。
?1. 直接塊指針:
圖中 inode 結構包含 “12 個直接塊指針”。假設每個數據塊的大小為?B?字節(常見的塊大小有 1KB =?2^10?字節、 4KB =?2^12?字節等),那么通過這 12 個直接塊指針能管理的文件大小為?12×B?字節。例如,當塊大小?B = 4KB?時,直接塊能容納的文件大小是?12×4KB=48KB?,對于一些小型文本文件、簡單配置文件等,它們的數據量往往較小,可直接通過這 12 個指針快速定位到相應數據塊。
2. 一級間接塊索引表指針:
?
一級間接塊索引表指針指向的是一個特殊的數據塊,該數據塊用于存儲其他數據塊的指針。假設每個指針的大小為?P?字節(通常為 4 字節或 8 字節,在 64 位系統中常見為 8 字節 ),那么一個大小為?B?字節的數據塊能存放的指針數量為?B/P??個。這些指針再分別指向真正存儲文件數據的普通數據塊。所以,通過一級間接塊索引表能管理的文件大小為 B/P ?× B?字節。比如,在塊大小?B=4KB=2^12?字節,指針大小?P=4?字節的情況下,一級間接塊索引表能管理的文件大小為 (2^12) / 4? × 2^12 = 4MB?。3. 二級間接塊索引表指針:
二級間接塊索引表指針指向的塊中存儲的是指向一級間接塊索引表的指針。先由二級間接塊索引表指針指向的塊找到若干個一級間接塊索引表,每個一級間接塊索引表再指向普通數據塊。此時能管理的文件大小為?(B/P?)^2×B?字節。同樣以?B=4KB=2^12?字節,?P=4?字節為例,二級間接塊索引表能管理的文件大小為? [(2^12) /4]^2 × 2^12=4GB?。4. 三級間接塊索引表指針:
三級間接塊索引表指針指向的塊存儲著指向二級間接塊索引表的指針。能管理的文件大小為?(B/P?)^3×B?字節。若還是?B=4KB=2^12?字節,?P=4?字節,三級間接塊索引表能管理的文件大小為 [(2^12) /4]^3×2^12=4TB?。
- 分區之后的格式化操作,就是對分區進行分組,在每個分組中寫入SB、GDT、Block Bitmap、Inode Bitmap等管理信息,這些管理信息統稱為文件系統。
- 只要知道文件的inode號,就能在指定分區中確定是哪一個分組,進而在哪一個分組確定是哪一個indoe。
- 拿到inode文件屬性和內容就全部都有了
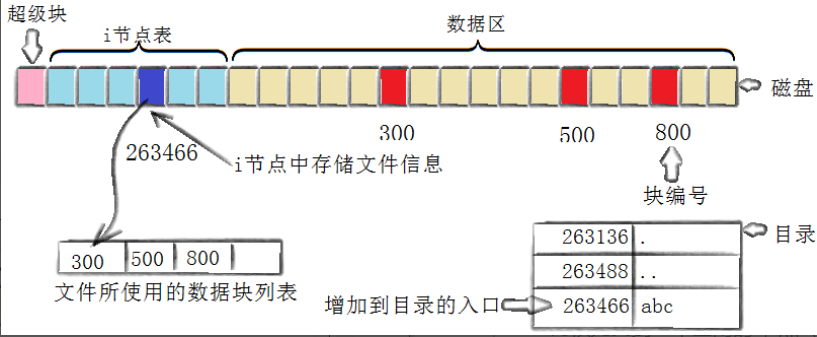
創建一個新文件主要有以下幾個操作:
- 存儲屬性:內核先找到一個空閑的i節點(這里是263466),內核把文件信息記錄到其中
- 存儲數據:該文件需要存儲在三個磁盤塊,內核找到了三個空閑塊:300,500,800,將內核緩沖區的第一塊復制到300,下一塊復制到500,以此類推
- 記錄分配情況:文件內容按順序300、500、800存放,內核在inode上的磁盤分布區記錄了上述塊列表?
- 添加文件名到目錄:新的文件名為abc,仔細想象linux如何在當前的目錄中記錄這個文件?內核將入口(263466,abc)的映射關系添加到目錄文件,文件名和inode之間的對應關系將文件名和文件的內容及屬性連接起來。
5.目錄與文件名
仔細想想我們訪問文件時,使用的是文件名,從來沒有使用過inode號?目錄為什么能保存文件?目錄也是文件嗎?
- 目錄也是文件,但磁盤上沒有目錄的概念,只有文件屬性+文件內容的概念
- 目錄的屬性不用多說,內容保存的是:文件名和inode號的映射關系
下面看一段代碼:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>int main(int argc, char *argv[]) {if (argc != 2) {fprintf(stderr, "Usage: %s <directory>\n", argv[0]);exit(EXIT_FAILURE);}DIR *dir = opendir(argv[1]);if (!dir) {perror("opendir");exit(EXIT_FAILURE);}struct dirent *entry;while ((entry = readdir(dir)) != NULL) {// Skip the "." and ".." directory entriesif (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0) {continue;}printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);}return 0;
}該代碼使用opendir函數打開指定目錄,若打開失敗則打印錯誤信息并退出;通過readdir函數循環讀取目錄中的每一項,跳過.(當前目錄)和..(上級目錄)這兩個特殊目錄項。對于其他目錄項,打印其文件名和對應的 inode 編號。
運行結構:
ayanami@ayanami-virtual-machine:~/file_lession$ ./proc /
Filename: sbin, Inode: 18
Filename: lib32, Inode: 15
Filename: bin, Inode: 13
Filename: lib64, Inode: 16
Filename: dev, Inode: 393217
Filename: lib, Inode: 14
Filename: swapfile, Inode: 12
Filename: opt, Inode: 917505
Filename: sys, Inode: 1048579
Filename: snap, Inode: 655362
Filename: usr, Inode: 262148
Filename: var, Inode: 786433
Filename: tmp, Inode: 917507
Filename: mnt, Inode: 655361
Filename: libx32, Inode: 17
Filename: root, Inode: 524290
Filename: run, Inode: 393218
Filename: srv, Inode: 917506
Filename: etc, Inode: 131073
Filename: cdrom, Inode: 918174
Filename: boot, Inode: 1048577
Filename: media, Inode: 262145
Filename: proc, Inode: 131075
Filename: lost+found, Inode: 11
Filename: home, Inode: 524289
所以訪問文件,必須打開當前目錄,根據文件名,獲取對應的inode號,然后進行文件訪問;必須知道當前工作目錄,本質是必須能打開當前工作目錄文件,查看目錄文件的內容。例如:要訪問proc.c,就必須打開當前目錄(file_lession),然后才能獲取proc.c對應的inode進而對文件進行訪問。
6.路徑解析
打開當前工作目錄文件,查看當前工作目錄文件的內容?當前工作目錄不也是文件嗎?我們訪問當前工作目錄不也是只知道當前工作目錄的文件名嗎?要訪問它,不也得知道當前工作目錄的inode嗎?
- 獲取當前工作目錄的inode就必須打開當前工作目錄的上級目錄,打開當前工作目錄的上級目錄,就需要它的inode,獲取上級工作目錄的inode就必須打開當前上級工作目錄的上級目錄...
- 這是類似”遞歸“的方式,需要把路徑中所有的目錄全部解析,出口是"/"根目錄。
- 所以任何文件都有路徑,訪問目標文件如:"/home/ayanami/file_lession/proc.c",都需要從根目錄開始,依次打開每一個目錄,根據目錄名,依次訪問每個目錄下指定的目錄,直到訪問到目標文件proc.c,這個過程叫做Linux路徑解析。
- 所以訪問文件,必須要有 目錄 + 文件名 = 路徑。
- 根目錄固定文件名和inode號,無需查找,系統開機之后就必須直到。
那么路徑由誰提供?
- 我們進行文件訪問時,都是指令/工具訪問,本質就是進程訪問,進程有CWD,進程提供路徑。
- 使用系統調用時,我們傳參也提供了路徑。
最開始的路徑從哪里來?
Linux提供了根目錄和家目錄,新建任何文件,都在你或者系統指定的目錄下新建,這就是最開始的路徑。所以 系統 + 用戶 共同構建Linux路徑結構。
7.路徑緩存
我們已經知道,Linux磁盤中,不存在目錄的概念,全部都是文件,只保存文件屬性 + 文件內容
我們訪問任何文件,都需要指明路徑,進行路徑解析,那么都要從根目錄/開始進行路徑解析嗎?
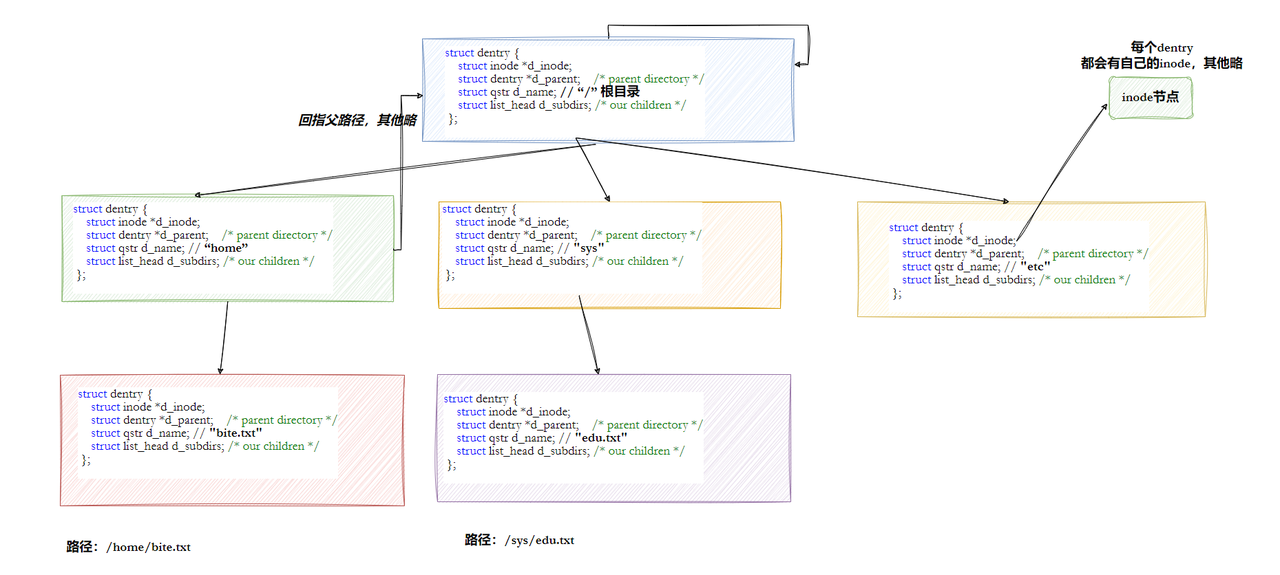
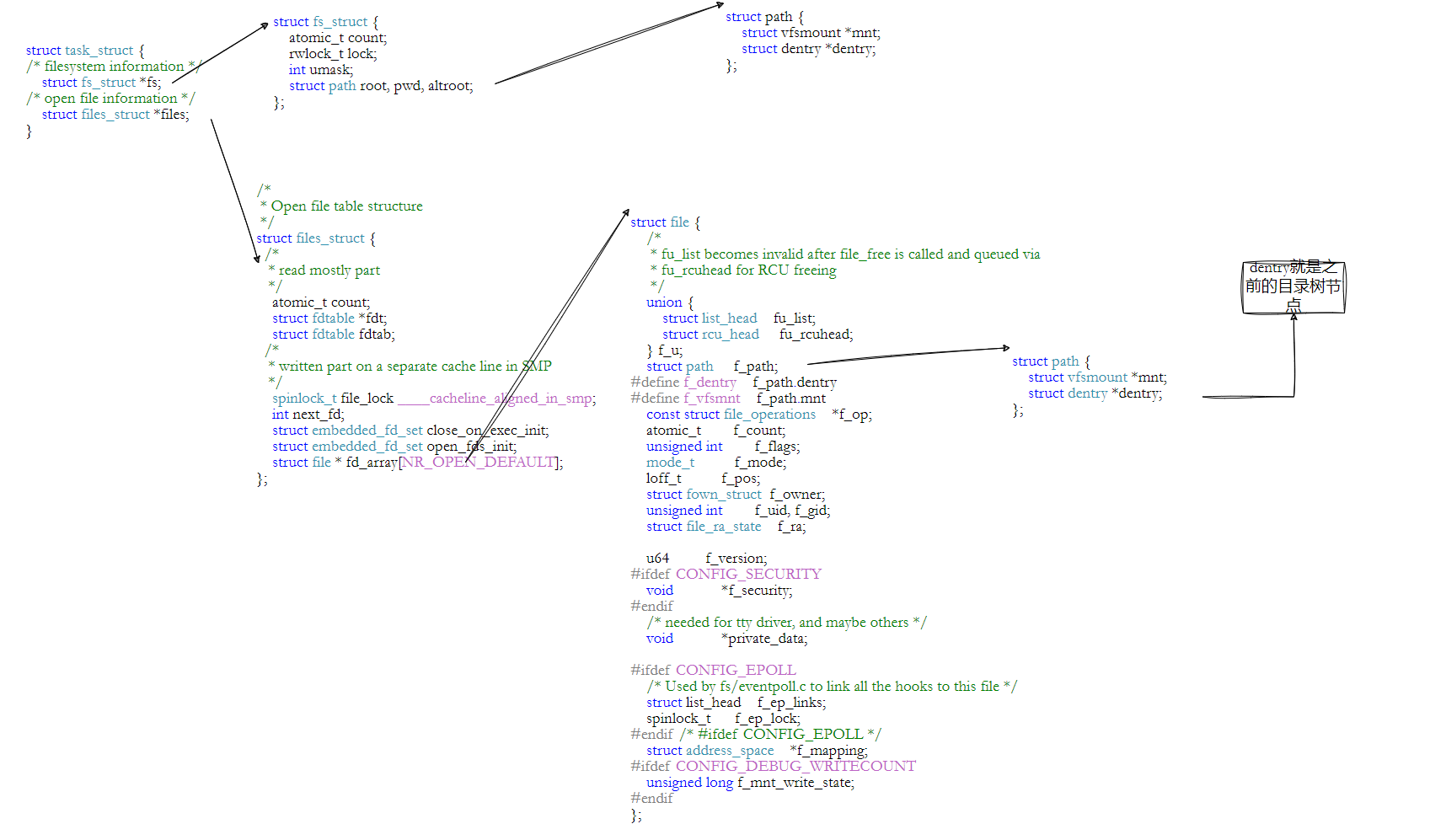
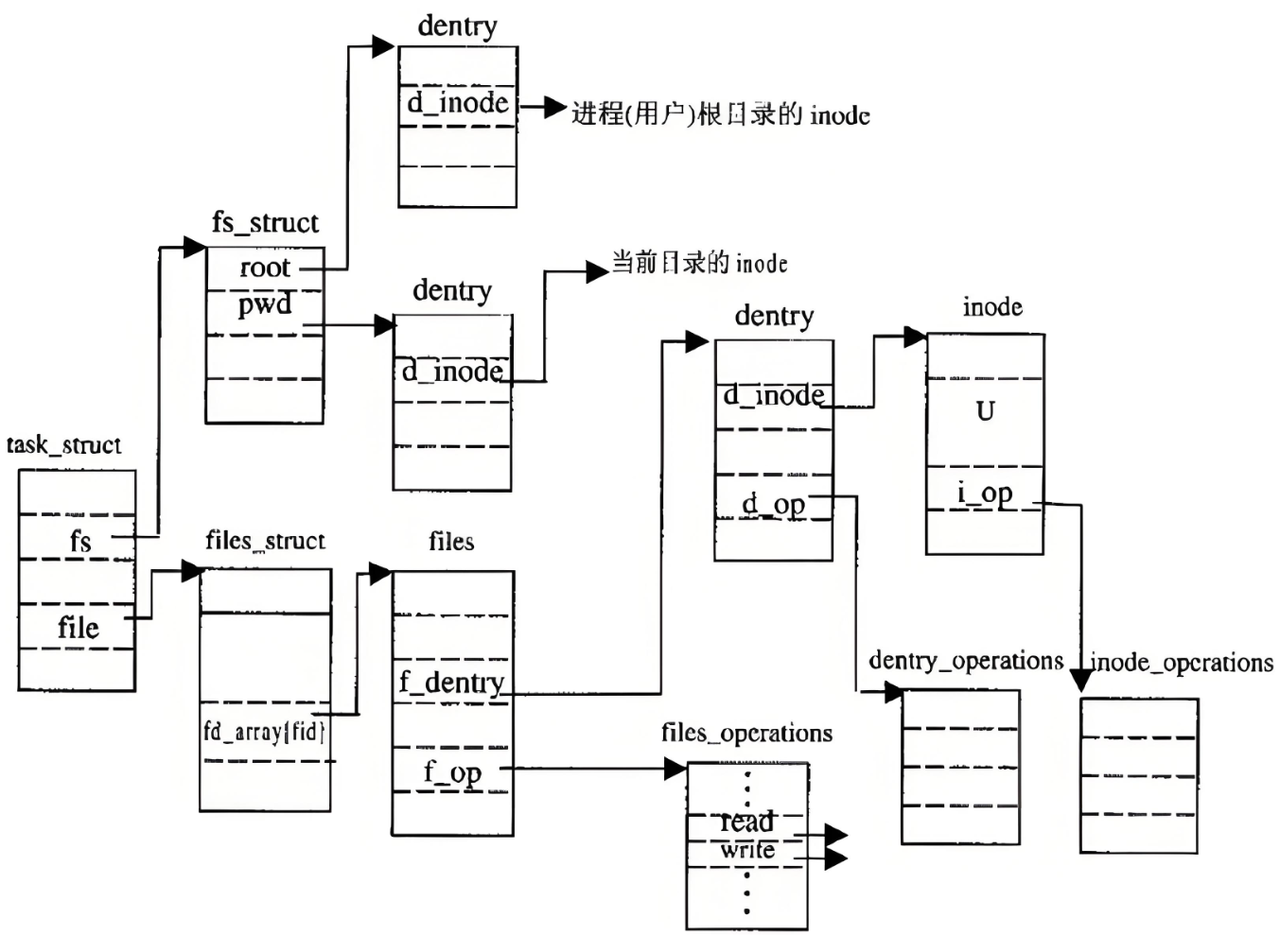
原則上是得從根目錄/開始解析,但這樣太慢了,所以Linux會緩存歷史路徑結構。在Linux中,內核中維護樹狀路徑結構的內核結構體叫做:struct dentry
- 每個文件都有對應的dentry結構,包括普通文件,這樣所有被打開的文件,就可以在內存中形成整個樹形結構。
- 整個樹形節點也同時會隸屬于LRU(Least Recently Used,最近最少使用)的結構中,進行節點淘汰。
- 整個樹形節點也會同時隸屬于Hash,方便快速查找。
- 更重要的是,這個樹形結構,整體構成了Linux的路徑緩存結構,打開訪問任何文件,都先在在這棵樹下根據路徑進行查找,找到就返回屬性inode和內容,沒找到就從磁盤加載路徑,添加dentry結構,緩存新路徑。
8.掛載分區
我們已經能夠根據inode號在指定分區找文件了,也已經能根據目錄文件內容找指定的inode了,在指定的分區內,我們可以為所欲為了。可是inode不是不能跨分區嗎?Linux不是可以有多個分區嗎?我怎么知道我在哪一個分區?
- 分區寫入文件系統,無法直接使用,需要和指定的目錄關聯,進行掛載才能使用。
- 所以可以根據訪問目標文件的”路徑前綴“準確判斷我在哪一個分區。
9.文件系統總結












)
--網頁結構)






