提前說一點:如果你是專注于Python開發,那么本系列知識點只是帶你入個門再詳細的開發點就要去看其他資料了,而如果你和作者一樣只是操作其他技術的Python API那就足夠了。
Python的流(I/O)操作,最簡單的其實就是輸入和輸出,輸出我們都知道使用輸出函數
print( str , end = '\n')
但是Python的輸入卻有兩個方法,一個是我們最常用的 input,但是其實Python還有一個raw_input函數也可以輸入,那么它們的區別在哪里呢?
raw_input([prompt]) 從標準輸入讀取一個行,就是鍵盤輸入的數據,并返回一個字符串(去掉結尾的換行符),prompt 是提示語句例如:str = raw_input("請輸入:")print "你輸入的內容是: ", str
結果:請輸入:Hello Python!你輸入的內容是: Hello Python!
但是input,這個函數除了支持raw_input同樣的功能之外,它還有一個特別的特點,它可以識別輸入數據中的Python代碼
str = input("請輸入:")
print "你輸入的內容是: ", str例如:輸入:[x*5 for x in range(2,10,2)]
結果:你輸入的內容是: [10, 20, 30, 40]
再向深層次學習流操作,那就要說說Python和其他語言一樣都有的操作文件API,且Python的文件API更加簡潔
open(name,mode,buffering) name是文件路徑,mode是訪問模式,該方法會返回一個文件對象,buffering是一個寄存區,也就是字符緩沖區的標識,如果 buffering 的值被設為 0,文件就不會被緩存。如果 buffering 的值取 1,訪問文件時會寄存行。如果將 buffering 的值設為大于 1 的整數,表明了這就是的寄存區的緩沖大小。如果取負值,寄存區的緩沖大小則為系統默認
mode模式支持如下的參數,常用的也就讀寫而已
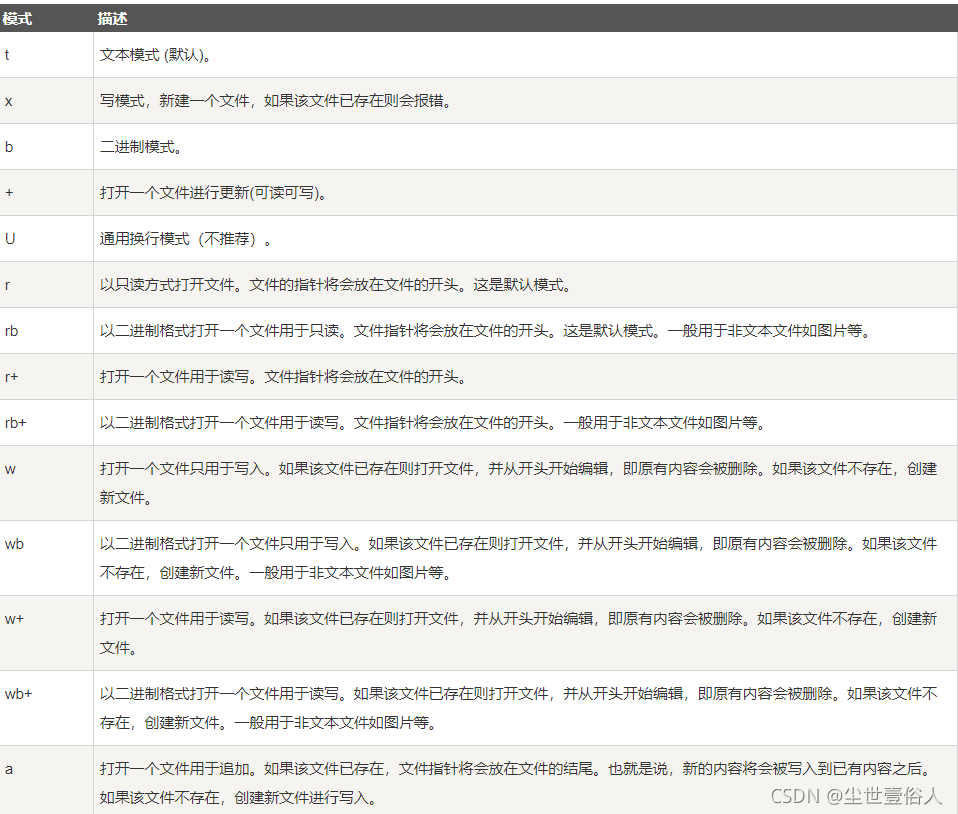
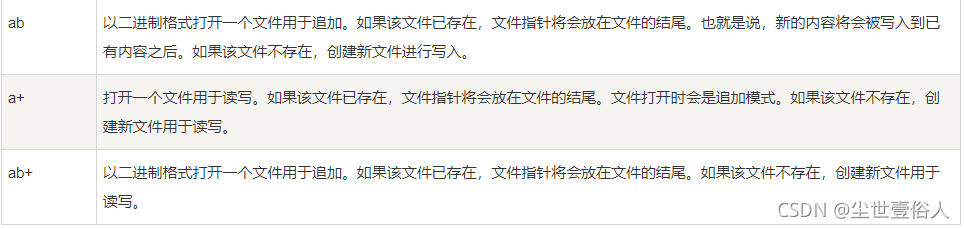
在菜鳥教程里面羅列了常用的幾個模式,并且使用圖例的方式進行直白的解釋
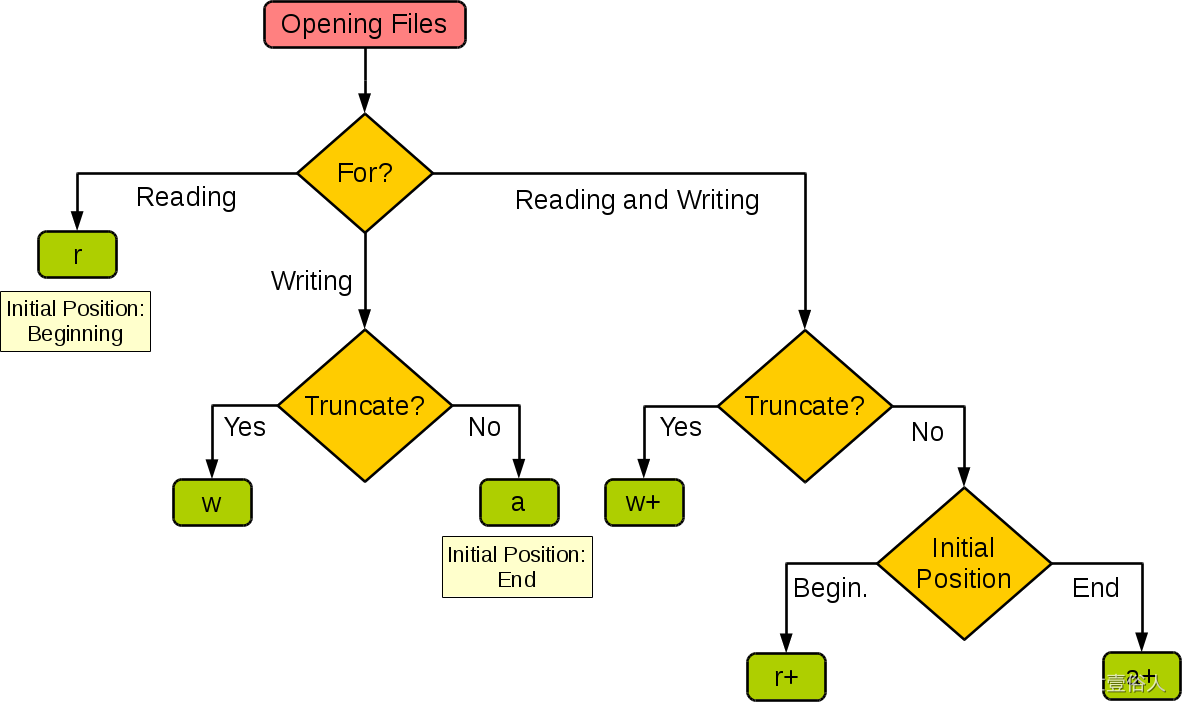
以及提供了下面這個表格,解釋了常用的幾個模式,可以實現哪些功能
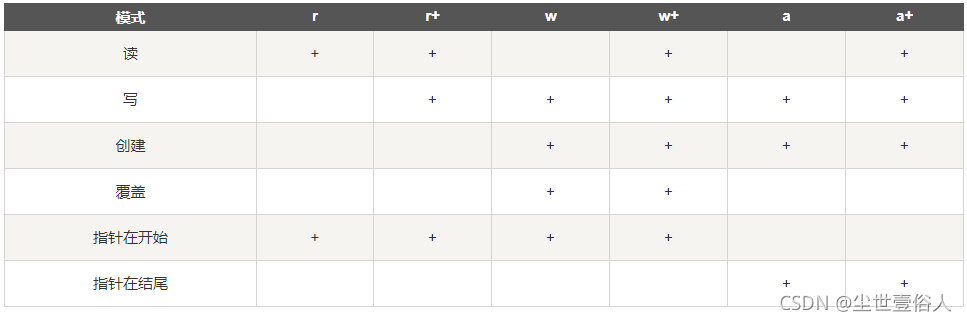
同時你可以知道根據open方法返回的對象,獲得如下信息
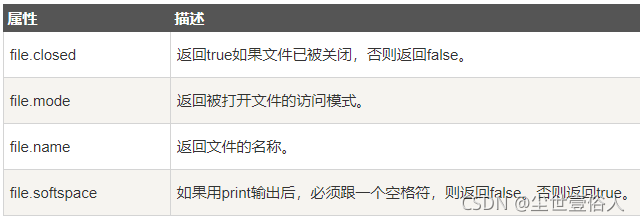
fo = open("foo.txt", "w")
print "文件名: ", fo.name
print "是否已關閉 : ", fo.closed
print "訪問模式 : ", fo.mode
print "末尾是否強制加空格 : ", fo.softspace
在打開一個文件,并使用結束后,一定要記住關閉它,不然你的內存會被大量占用
文件對象.close()
在調用了關閉流的方法后,Python會刷新緩存區里面的內容到文件中,之后就不能再操作寫入了
Pythond的文件對象還提供了,許多其他方法用來操作文件,比如寫方法
文件對象.write(str)
操作寫入方法的時候,要注意,流中的 str 不一定必須是字符串,可以是二進制數據,且該方法不會自動增加換行符號
# 打開一個文件
fo = open("foo.txt", "w")
fo.write( "www.runoob.com!\nVery good site!\n")# 關閉打開的文件
fo.close()在文件中會有如下內容:
www.runoob.com!
Very good site!
文件對象還提供了,讀取內容的方法,read()
文件對象.read(num) 讀取文件,num是字節個數,不寫時讀取所有內容# 打開一個文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "讀取的字符串是 : ", str
# 關閉打開的文件
fo.close()讀取的字符串是 : www.runoob
當然還有readline方法可以讀取一行,在你要讀取的文件很大的時候,就不在適合使用read了,且readline返回的字符串中包含換行符
file = open('foo.txt', 'r' )while True:text_line = file.readline()if text_line:print(text_line)else:break
readline函數還可以傳入一個參數,和read的num一樣意義的參數,控制讀取的字節大小,不過一般不用,畢竟只讀取一行數據
當然Python還有一個readlines函數,它的使用有些風險,因為它讀取的也是整個文件,不過他的返回結果是一個列表,把每一行數據包含換行符作為列表的每一個元素
文件內容:
1:www.runoob.com
2:www.runoob.com
3:www.runoob.com
4:www.runoob.com
5:www.runoob.comfo = open("runoob.txt", "r")
print "文件名為: ", fo.namefor line in fo.readlines(): #依次讀取每行 line = line.strip() #去掉每行頭尾空白 print "讀取的數據為: %s" % (line)# 關閉文件
fo.close()
說了讀取方法就不得不說,文件定位了,也就是光標讀取文件時的位置
tell()方法告訴你文件內的當前位置, 換句話說,下一次的讀寫會發生在文件開頭這么多字節之后。
seek(offset [,from])方法改變當前文件的位置。offset變量表示要移動的字節數。From變量指定開始移動字節的參考位置。如果from被設為0,這意味著將文件的開頭作為移動字節的參考位置。如果設為1,則使用當前的位置作為參考位置。如果它被設為2,那么該文件的末尾將作為參考位置。
# 打開一個文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print "讀取的字符串是 : ", str# 查找當前位置
position = fo.tell()
print "當前文件位置 : ", position# 把指針再次重新定位到文件開頭
position = fo.seek(0, 0)
str = fo.read(10)
print "重新讀取字符串 : ", str
# 關閉打開的文件
fo.close()結果:
讀取的字符串是 : www.runoob
當前文件位置 : 10
重新讀取字符串 : www.runoob
文件除了讀寫,最基本的還有重命名與刪除
import os , shutil
os.rename(current_file_name, new_file_name) 重命名方法的兩個參數,分別是帶文件名的新舊路徑os.remove(file_name) 刪除一個文件shutil.move() 移動文件
當然 我們導入的 os 模塊還有著相當多實用的方法
os.mkdir(newdir) 建立一個新的目錄,注意該方法只能新建目錄,想新建文件可以考慮open方法os.chdir(newdir) 這個方法用來設置當前程序操作的當前路徑,用的比較少os.getcwd() 該方法用來顯示當前路徑,對于Python程序來說叫做當前工作目錄os.rmdir(dirname) 該方法用來刪除一個目錄,但是注意刪除一個目錄前,它的子數據應該是被刪除的os.listdir(目錄) 獲取目錄下的所有文件名shutil模塊:是python內置的高級的文件、文件夾、壓縮包處理模塊shutil.copyfile(src,dst)
將src復制到dst中去,dst一定要具有讀寫權限,如果dst已經存在會被覆蓋,src和dst必須是文件,不可以是目錄。shutil.move(src,dst)
移動文件、目錄。或者文件、目錄重命名,如果dst存在,則不可覆蓋。shutil.copt(src,dst)
復制一個文件到一個文件或一個目錄,src必須是文件,dst是文件或者目錄shutil.copy2(src,dst)
在copy的基礎上再復制文件最后訪問時間和修改時間也復制過來,但是創建時間是不會和源文件一樣的。shutil.copytree(olddir,newdir,True/False)
把olddir拷貝一份newdir,如果第三個參數是True,則復制目錄時將保持文件夾下的符號鏈接,如果地3個參數時False,則將在復制的目錄下生成物理副本來代替符號連接
文件對象和我們上面導入的 os 模塊相互配合可以實現很多操作,用到時具體的大家可以在網上找找,推薦大家可以看看菜鳥教程的, 文件對象API --------- os 對象API


)




)





)





