參考代碼:SASRec.pytorch
可參考資料:SASRec代碼解析
前言:文中有疑問的地方用?表示了。可以通過ctrl+F搜索’?'。
環境
conda create -n SASRec python=3.9
pip install torch torchvision
因為我是mac運行的,所以device是
mps
下面的代碼可以測試mps是否可以正常運行python # 進入python環境 >>> import torch >>> print(torch.backends.mps.is_available()) # 輸出為True則說明可以正常運行
測試
python main.py --device=mps --dataset=ml-1m --train_dir=default --state_dict_path='ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth' --inference_only=true --maxlen=200
### average sequence length: 163.50
### ............................................................test (NDCG@10: 0.5662, HR@10: 0.8056)
main.py
str2bool
def str2bool(s):if s not in {'false', 'true'}:raise ValueError('Not a valid boolean string')return s == 'true'
將字符串’true’轉化為邏輯1,字符串’false’轉化為邏輯0,其他字符串輸入則拋出錯誤。
這個函數用于命令行解析。
命令行解析:argparse.ArgumentParser()
# 1.導入argparse模塊
import argparse
# 2.創建一個解析對象
parser = argparse.ArgumentParser()
# 3.向對象parser中添加要關注的命令行參數和選項
# 參數名前加'--'表示這是“關鍵詞參數”(不同于位置參數)
parser.add_argument('--dataset', required=True) # 必選項:數據集dataset
parser.add_argument('--train_dir', required=True) # 必選項
parser.add_argument('--batch_size', default=128, type=int) # type的參數:會將str類型轉化為對應的type類型
parser.add_argument('--lr', default=0.001, type=float)
parser.add_argument('--maxlen', default=50, type=int)
parser.add_argument('--hidden_units', default=50, type=int)
parser.add_argument('--num_blocks', default=2, type=int)
parser.add_argument('--num_epochs', default=201, type=int)
parser.add_argument('--num_heads', default=1, type=int)
parser.add_argument('--dropout_rate', default=0.5, type=float)
parser.add_argument('--l2_emb', default=0.0, type=float)
parser.add_argument('--device', default='cpu', type=str)
parser.add_argument('--inference_only', default=False, type=str2bool)
parser.add_argument('--state_dict_path', default=None, type=str)
# 4.調用parse_args()方法進行解析
args = parser.parse_args()
命令行輸入
python main.py --device=mps --dataset=ml-1m --train_dir=default --state_dict_path='ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth' --inference_only=true --maxlen=200時調用
結果:
dataset: ml-1m
train_dir: default
batch_size: 128(默認)
lr: 0.001(默認)
maxlen: 200
hidden_units: 50(默認)
num_blocks: 2(默認)
num_epochs: 201(默認)
num_heads: 1(默認)
dropout_rate: 0.5(默認)
l2_emb: 0.0
device: mps
inference_only: True
state_dict_path: ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth
PS:
1.命令行參數解析模塊:解析命令行代碼的參數。
參考:argparse.ArgumentParser()用法解析
2.關鍵詞參數設定的時候需要--,在命令行中也需要。但是在代碼中使用時候不需要。即:
- 向對象parser中添加
關鍵詞參數:parser.add_argument('--dataset', required=True)- 命令行傳參:
python main.py --device=mps --dataset=ml-1m- 代碼中使用:
args.dataset
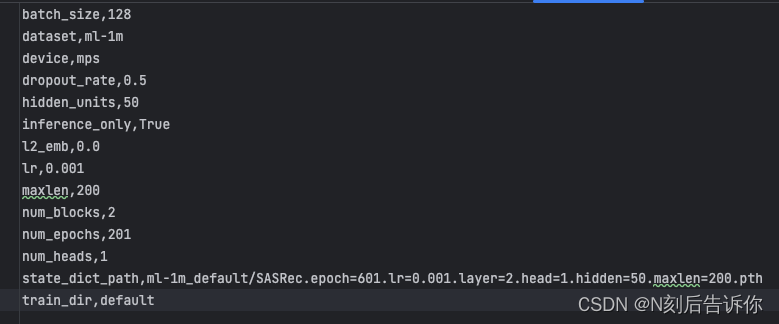
參數寫入args.txt
# args.dataset + '_' + args.train_dir如果不是現有目錄就創建
if not os.path.isdir(args.dataset + '_' + args.train_dir):os.makedirs(args.dataset + '_' + args.train_dir)
# 拼接上面的目錄和args.txt路徑,并打開對應文件'寫入'
# vars返回對象的__dict__屬性
with open(os.path.join(args.dataset + '_' + args.train_dir, 'args.txt'), 'w') as f:f.write('\n'.join([str(k) + ',' + str(v) for k, v in sorted(vars(args).items(), key=lambda x: x[0])]))
# f.close()不需要,因為上面使用的是with open
以上面的測試為例
args.dataset =ml-1m
args.train_dir=default
這行代碼的目的是將args參數按行逐個寫入到ml-1m-default/args.txt文件中。
PS:
vars返回對象的__dict__屬性。可以參考:Python vars函數
dict.items()返回視圖對象:將字典轉化為元組的列表。
sorted(vars(args).items(), key=lambda x: x[0])# 根據元組的第一個元素升序
[str(k) + ',' + str(v) for k, v in sorted(vars(args).items(), key=lambda x: x[0])]:列表生成器
str.join(iterable):返回一個由 iterable 中的字符串拼接而成的字符串,str作為中間的分隔符。
下面開始是main的主要內容(以下都用測試的代碼的參數為例)。
參數列表:
batch_size,128
dataset,ml-1m
device,mps
dropout_rate,0.5
hidden_units,50
inference_only,True
l2_emb,0.0
lr,0.001
maxlen,200
num_blocks,2
num_epochs,201
num_heads,1
state_dict_path,ml-1m_default/SASRec.epoch=601.lr=0.001.layer=2.head=1.hidden=50.maxlen=200.pth
train_dir,default
數據集劃分
# 利用utils.data_partition函數對數據集進行劃分
from utils import data_partitiondataset = data_partition(args.dataset) # 傳參"ml-1m"
[user_train, user_valid, user_test, usernum, itemnum] = dataset
num_batch = len(user_train) // args.batch_size # 計算訓練批次
# 計算平均sequence長度
cc = 0.0
for u in user_train:cc += len(user_train[u])
print('average sequence length: %.2f' % (cc / len(user_train)))f = open(os.path.join(args.dataset + '_' + args.train_dir, 'log.txt'), 'w')
這部分主要是進行數據集劃分,得到訓練集、驗證集、測試集
關于data_partition需要看utils.py文件
結果:
user_train:{1: [1,2,3,4…], 2:[80, 81,…], …}
user_valid:{1: [78], 2:[137], 3:[248], …}
user_test:{1: [79], 2: [138], 3: [249], …}
usernum: 6040
itemnum: 3416
num_batch: 47
average sequence length: 163.50
疑問:這里代碼注釋里寫了
tail? + ((len(user_train) % args.batch_size) != 0),是否需要考慮不足batch_size的部分?
雖然創建log.txt文件,但是后面并沒有用到,意義不明?
采樣
sampler = WarpSampler(user_train, usernum, itemnum, batch_size=args.batch_size, maxlen=args.maxlen, n_workers=3)
實例化WarpSampler類。這個類主要是用來通過采樣用戶,生成數據的。
模型類實例化
model = SASRec(usernum, itemnum, args).to(args.device) # no ReLU activation in original SASRec implementation?
模型訓練
# 將模型設置為訓練模式,確保”Batch Normalization”和“Dropout“正常工作model.train()epoch_start_idx = 1if args.state_dict_path is not None:try:model.load_state_dict(torch.load(args.state_dict_path, map_location=torch.device(args.device)))tail = args.state_dict_path[args.state_dict_path.find('epoch=') + 6:]epoch_start_idx = int(tail[:tail.find('.')]) + 1except: # in case your pytorch version is not 1.6 etc., pls debug by pdb if load weights failedprint('failed loading state_dicts, pls check file path: ', end="")print(args.state_dict_path)print('pdb enabled for your quick check, pls type exit() if you do not need it')import pdb; pdb.set_trace()utils.py
fun: data_partition
from collections import defaultdictdef data_partition(fname):usernum = 0itemnum = 0User = defaultdict(list) # 創建key-list的字典user_train = {}user_valid = {}user_test = {}# assume user/item index starting from 1f = open('data/%s.txt' % fname, 'r')# 構建"user-對應item的列表"的字典,獲得usernum, itemnumfor line in f:u, i = line.rstrip().split(' ') # rstrip():去掉右邊的空格,split(' '): 根據空格拆分得到字符串列表u = int(u) # str->inti = int(i)usernum = max(u, usernum) # usernum記錄user的最大值,即user數itemnum = max(i, itemnum) # itemnum記錄item的最大值,即item數User[u].append(i) # User的key是user的index,value是item的index組成的list# 構建user_train, user_valid, user_testfor user in User: nfeedback = len(User[user]) # 計算user對應的item數量# item數量<3的user, 則對應的item列表直接作為user_train[user]的value# item數量>=3的user,對應的item列表的# 最后一個item作為user_test[user]的value# 倒數第二個item作為user_valid[user]的value# 剩下前面的item作為user_train[user]的valueif nfeedback < 3:user_train[user] = User[user]user_valid[user] = []user_test[user] = []else:user_train[user] = User[user][:-2]user_valid[user] = []user_valid[user].append(User[user][-2])user_test[user] = []user_test[user].append(User[user][-1])return [user_train, user_valid, user_test, usernum, itemnum]
實際調用:
dataset = data_partition('ml-1m')
1.data_partition目的是將data/fname.txt文件中的user-item對轉化為user-item列表字典,最終返回了[user_train, user_valid, user_test, usernum, itemnum]。
2.user_train形如{1: [1, 2, 3, 4, …], 2:[…], …}, user_valid形如{1: [78], 2: [137], …}, user_test形如{1: [79], 2: [138], …}
PS:
1.defaultdict創建的字典,傳入的”工廠函數"可以表明字典value的類型和默認值,這使得這種字典很方便地將(鍵-值)序列轉化為對應的字典。具體可以參考:
python中defaultdict用法詳解
defaultdict 例子
2.事實上,經過測試,"m1-1m"這個例子里面,并沒有某個user的對應item列表數量小于3。
class: WarpSampler
from multiprocessing import Process, Queueclass WarpSampler(object):def __init__(self, User, usernum, itemnum, batch_size=64, maxlen=10, n_workers=1):self.result_queue = Queue(maxsize=n_workers * 10) # 創建一個最多存放n_workers*10個數據的消息隊列,用于支持進程之間的通信self.processors = [] # 存放子進程的列表# 列表中添加進程操作對象,其中,sample_function作為任務交給子進程執行,執行要用到的參數是argsfor i in range(n_workers):self.processors.append(Process(target=sample_function, args=(User,usernum,itemnum,batch_size,maxlen,self.result_queue,np.random.randint(2e9))))self.processors[-1].daemon = True # 設置進程為守護進程(必須在進程啟動前設置)self.processors[-1].start() # 創建進程def next_batch(self):return self.result_queue.get() # 從消息隊列中取出數據并返回def close(self):for p in self.processors:p.terminate() # 殺死進程p.join() # 等待進程結束
實際調用:
sampler = WarpSampler(user_train, usernum, itemnum, batch_size=128, maxlen=200, n_workers=3)
中間要用到sample_function,遇到可以跳轉查看sample_function講解。
WarpSampler類:
初始化:生成大小為30的消息隊列,創建3個子進程,每個子進程生成一批數據,并存入消息隊列
next_batch方法:從消息隊列中取數據
close方法:殺死所有子進程
PS:
1.關于守護進程,可以參考:守護進程 - 《Python零基礎到全棧系列》。具體地:p.daemon默認值為False,如果設為True,代表p為后臺運行的守護進程,當p的父進程終止時,p也隨之終止,并且設定為True后,p不能創建自己的新進程,p.daemon必須在p.start()之前設置。
fun: sample_function
import numpy as npdef sample_function(user_train, usernum, itemnum, batch_size, maxlen, result_queue, SEED):# 采樣def sample():user = np.random.randint(1, usernum + 1) # 隨機返回1-usernum之間的一個整數# 如果user_train的序列長度小于等于1,則重新隨機取1-usernum之間的一個整數while len(user_train[user]) <= 1: user = np.random.randint(1, usernum + 1) seq = np.zeros([maxlen], dtype=np.int32) # 長為maxlen的ndarraypos = np.zeros([maxlen], dtype=np.int32) neg = np.zeros([maxlen], dtype=np.int32)nxt = user_train[user][-1] # 最后一個item序號idx = maxlen - 1 # 199ts = set(user_train[user]) for i in reversed(user_train[user][:-1]):seq[idx] = ipos[idx] = nxtif nxt != 0: neg[idx] = random_neq(1, itemnum + 1, ts)nxt = i # 當前輪次的i,實際上是下一輪次的nxtidx -= 1 # 輪次加1,索引-1if idx == -1: break # 意味著item序列長度超出maxlen,索引溢出,跳出循環return (user, seq, pos, neg)np.random.seed(SEED) # 設置隨機數種子while True:one_batch = []for i in range(batch_size):one_batch.append(sample()) # one_batch是元組(user, seq, pos, neg)的列表result_queue.put(zip(*one_batch)) # 結果寫入消息隊列
實際調用:
sample_function(user_train, usernum, itemnum, batch_size=128, maxlen=200, self.result_queue, np.random.randint(2e9))
中間要用到random_neq,遇到可以跳轉查看random_neq講解。
sample的目的是:采樣,返回某user的id,并根據其user_train序列生成對應的輸入序列seq,正例序列pos,反例序列neg
sample_function的目的是:多次采樣,并組合得到一批次的數據。同時,它將在WarpSampler類中作為進程活動的方法。
這里找個例子:user=1, user_train=[1, 2, 4, 6]
則初始:nxt=6,idx=199,reversed(user_train[user][:-1])=[4, 2, 1]
第1次循環:i=4,seq[199]=i=4,pos[199]=nxt=6,neg[199]=100,nxt=i=4,idx=idx-1=198
第2次循環:i=2,seq[198]=i=2,pos[198]=nxt=4,neg[198]=200,nxt=i=2,idx=idx-1=197
第3次循環:i=1,seq[197]=i=4,pos[197]=nxt=2,neg[197]=300,nxt=i=1,idx=idx-1=196
此時seq=[0, 0, ..., 1, 2, 4]
此時pos=[0, 0, ..., 2, 4, 6]
此時neg=[0, 0, ..., 300, 200, 100]
PS:
1.sample中的if nxt != 0似乎沒有用?因為nxt一定不會等于0
2.zip(*one_batch)是將元組(user, seq, pos, neg)中的對應元素組成元組,即user和user組成元組。具體可以參考:一文看懂Python(十)-- zip與zip(*)函數
fun: random_neq
def random_neq(l, r, s):t = np.random.randint(l, r)while t in s:t = np.random.randint(l, r)return t
實際調用:
random_neq(1, itemnum + 1, ts),其中ts是用戶對應的item集合
random_neq的目的是:在所有item序號中,找一個沒有出現在用戶的item集合中的item作為反例item序號。
model.py
class: SASRec
主體結構:
class SASRec(torch.nn.Module):def __init__(self, user_num, item_num, args):...def log2feats(self, log_seqs):...def forward(self, user_ids, log_seqs, pos_seqs, neg_seqs): # for training...def predict(self, user_ids, log_seqs, item_indices): # for inference...
SASRec.__init__
def __init__(self, user_num, item_num, args):super(SASRec, self).__init__()self.user_num = user_numself.item_num = item_numself.dev = args.device# TODO: loss += args.l2_emb for regularizing embedding vectors during training# https://stackoverflow.com/questions/42704283/adding-l1-l2-regularization-in-pytorch# 構造item的embedding表,pos的embedding表# padding_idx=0,說明索引0對應的embedding不參與梯度運算,不在訓練時更新self.item_emb = torch.nn.Embedding(self.item_num+1, args.hidden_units, padding_idx=0)self.pos_emb = torch.nn.Embedding(args.maxlen, args.hidden_units)self.emb_dropout = torch.nn.Dropout(p=args.dropout_rate)self.attention_layernorms = torch.nn.ModuleList()self.attention_layers = torch.nn.ModuleList()self.forward_layernorms = torch.nn.ModuleList()self.forward_layers = torch.nn.ModuleList()self.last_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)for _ in range(args.num_blocks):new_attn_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)self.attention_layernorms.append(new_attn_layernorm)new_attn_layer = torch.nn.MultiheadAttention(args.hidden_units,args.num_heads,args.dropout_rate)self.attention_layers.append(new_attn_layer)new_fwd_layernorm = torch.nn.LayerNorm(args.hidden_units, eps=1e-8)self.forward_layernorms.append(new_fwd_layernorm)new_fwd_layer = PointWiseFeedForward(args.hidden_units, args.dropout_rate)self.forward_layers.append(new_fwd_layer)# self.pos_sigmoid = torch.nn.Sigmoid()# self.neg_sigmoid = torch.nn.Sigmoid()
實際調用:
model = SASRec(usernum, itemnum, args).to(args.device)
PS:
1.torch.nn.Embedding:生成Embedding實例,該實例作用在tensor上,會對其中的每個元素做embedding。
詳細可參考: 無腦入門pytorch系列(一)—— nn.embedding
2.torch.nn.Dropout:生成Dropout實例,該實例作用在tensor上,會以一定概率使輸出變0。
詳細可參考:torch.nn.Dropout官網
3.torch.nn.ModuleList:存放子模塊的列表
4.torch.nn.LayerNorm:生成LayerNorm實例,該實例作用在tensor上,以最后一個/幾個維度求均值和標準差,最后做layer norm。
詳細可參考:torch.nn.LayerNorm官網
5.torch.nn.MultiheadAttention:生成多頭注意力實例。由于沒有設置"batch_first=True",所以要求輸入的維度是(seq, batch, feature)。
詳細可參考:torch.nn.MultiheadAttention官網;torch.nn.MultiheadAttention的使用和參數解析
SASRec.log2feats
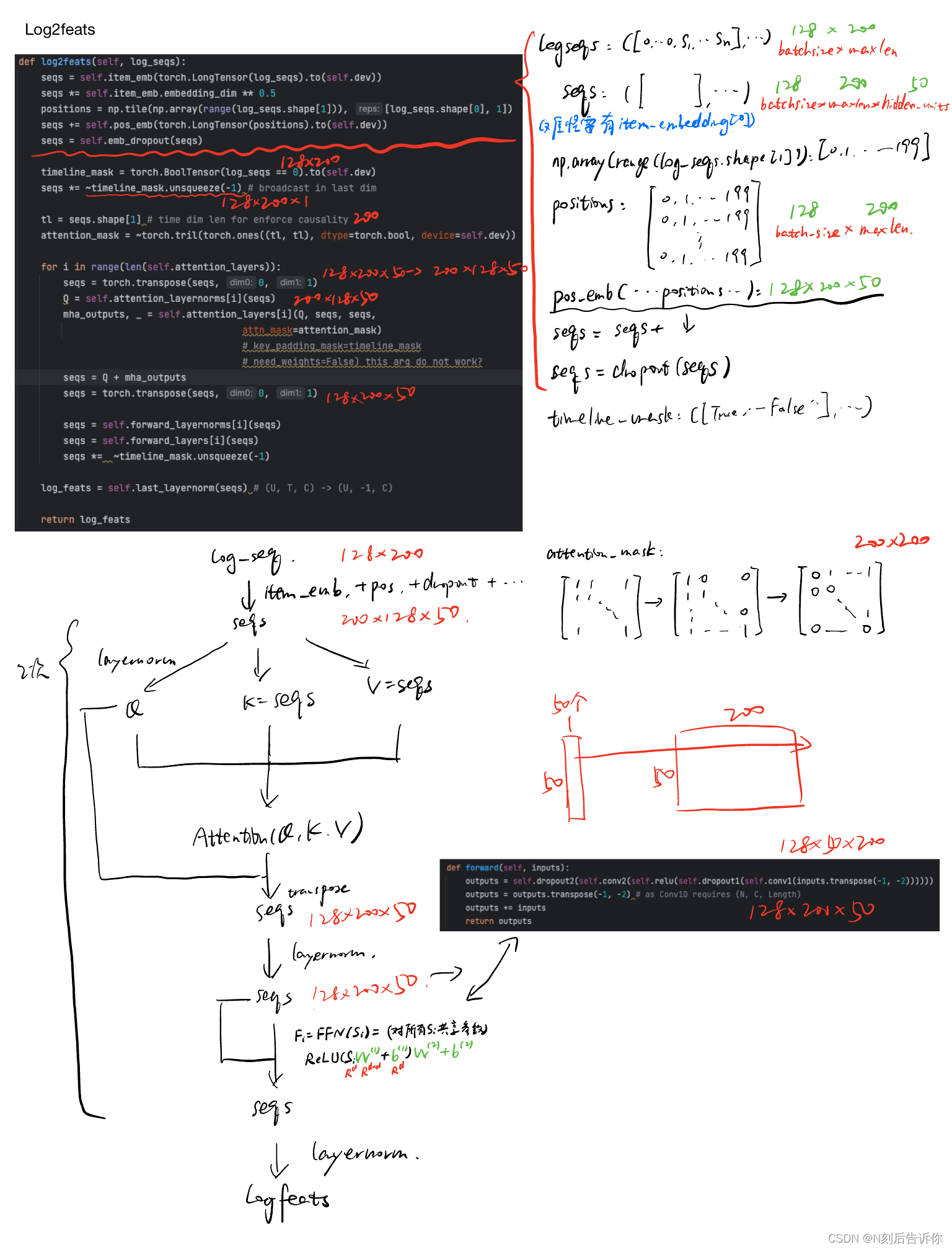
import numpy as npdef log2feats(self, log_seqs):# 這部分將輸入序列embedding,并加入了位置embedding,最后應用了dropoutseqs = self.item_emb(torch.LongTensor(log_seqs).to(self.dev))seqs *= self.item_emb.embedding_dim ** 0.5 # 為何要乘以根號d?positions = np.tile(np.array(range(log_seqs.shape[1])), [log_seqs.shape[0], 1])seqs += self.pos_emb(torch.LongTensor(positions).to(self.dev))seqs = self.emb_dropout(seqs)# seq列表中0對應的embeeding全部置于0timeline_mask = torch.BoolTensor(log_seqs == 0).to(self.dev)seqs *= ~timeline_mask.unsqueeze(-1) # broadcast in last dimtl = seqs.shape[1] # time dim len for enforce causalityattention_mask = ~torch.tril(torch.ones((tl, tl), dtype=torch.bool, device=self.dev))for i in range(len(self.attention_layers)):# 為了匹配MultiheadAttention,所以需要換維度seqs = torch.transpose(seqs, 0, 1)Q = self.attention_layernorms[i](seqs)mha_outputs, _ = self.attention_layers[i](Q, seqs, seqs, attn_mask=attention_mask)# key_padding_mask=timeline_mask# need_weights=False) this arg do not work?seqs = Q + mha_outputsseqs = torch.transpose(seqs, 0, 1)seqs = self.forward_layernorms[i](seqs)seqs = self.forward_layers[i](seqs)seqs *= ~timeline_mask.unsqueeze(-1)log_feats = self.last_layernorm(seqs) # (U, T, C) -> (U, -1, C)return log_feats
輸入
log_seqs是形如:([0, 0, 3, ...], ..., [0, 2, ...])的元組,元素是某個user_id對應的seq列表(seq列表見sample_function的例子),size為batch_size*maxlen
log2feats里基本包含了模型主體網絡的構建,包括embedding,attention,ffn等。
PS:
0.源代碼seqs *= self.item_emb.embedding_dim ** 0.5,為什么要乘以根號d。一種解釋是nn.embedding使用xavier init初始化,方差為 1 / d 1/\sqrt{d} 1/d?,為了方便收斂所以要乘以根號d。
詳細參考:Transformer 3. word embedding 輸入為什么要乘以 embedding size的開方
1.torch.LongTensor是Pytorch的一個數據類型,用于表示包含整數(整型數據)的張量(tensor)。其元素都是整數。需要注意的是,torch.LongTensor 在 PyTorch 1.6 版本之后被棄用,推薦使用 torch.tensor 并指定 dtype=torch.long 來創建相同類型的張量。如torch.tensor(data, dtype=torch.long)。
詳細參考:torch.LongTensor使用方法
2.np.tile(A, reps)的作用是將沿指定軸重復數組A。
詳細參考:Numpy|np.tile|處理數組復制擴展小幫手
3.torch.tensor.unsqueeze(dim):在指定的位置增加一個維度。
詳細參考:pytorch中tensor的unsqueeze()函數和squeeze()函數的用處
4.torch.tril():返回下三角矩陣。
詳細參考:pytorch中tril函數介紹
5.torch.nn.MultiheadAttention的實例的forward方法中,有key_padding_mask參數和attn_mask參數,前者作用是”屏蔽計算注意力時key的填充位置“,后者的作用是”屏蔽自注意力計算時query的未來位置“。
詳細參考:pytorch的key_padding_mask和參數attn_mask有什么區別?;PyTorch的Transformer
疑問:為什么這里不需要key_padding_mask?這里,似乎是利用
~timeline_mask.unsqueeze(-1)將padding的序列遮蓋。
SASRec.forward
def forward(self, user_ids, log_seqs, pos_seqs, neg_seqs): # for training log_feats = self.log2feats(log_seqs) # user_ids hasn't been used yetpos_embs = self.item_emb(torch.LongTensor(pos_seqs).to(self.dev))neg_embs = self.item_emb(torch.LongTensor(neg_seqs).to(self.dev))pos_logits = (log_feats * pos_embs).sum(dim=-1)neg_logits = (log_feats * neg_embs).sum(dim=-1)# pos_pred = self.pos_sigmoid(pos_logits)# neg_pred = self.neg_sigmoid(neg_logits)return pos_logits, neg_logits # pos_pred, neg_pred
輸入:
user_ids:(1, 2, ...),元素是user_id
log_seqs:([0, 0, 3, ...], ..., [0, 2, ...])∈ R 128 × 200 \in R^{128\times 200} ∈R128×200,元素是某user_id對應的item序列。
pos_seqs:([78], ..., [137])∈ R 128 × 1 \in R^{128\times 1} ∈R128×1,元素是某user_id對應的item序列的預測值正例
neq_seqs:([79], ..., [138])∈ R 128 × 1 \in R^{128\times 1} ∈R128×1,元素是某user_id對應的item序列的預測值反例
PS:
1.user_ids并沒有被用到
class:PointWiseFeedForward
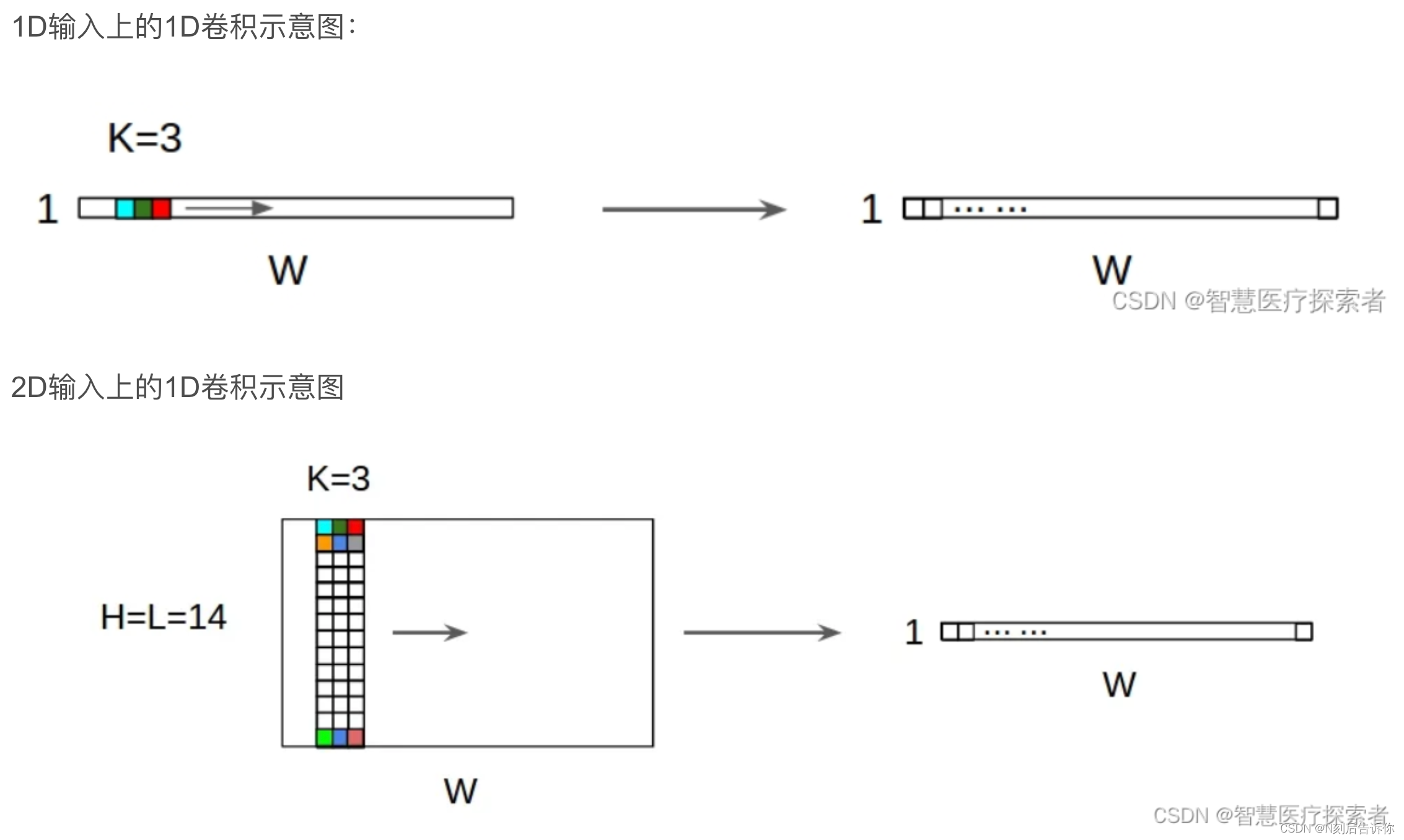
class PointWiseFeedForward(torch.nn.Module):def __init__(self, hidden_units, dropout_rate):super(PointWiseFeedForward, self).__init__()self.conv1 = torch.nn.Conv1d(hidden_units, hidden_units, kernel_size=1)self.dropout1 = torch.nn.Dropout(p=dropout_rate)self.relu = torch.nn.ReLU()self.conv2 = torch.nn.Conv1d(hidden_units, hidden_units, kernel_size=1)self.dropout2 = torch.nn.Dropout(p=dropout_rate)def forward(self, inputs):outputs = self.dropout2(self.conv2(self.relu(self.dropout1(self.conv1(inputs.transpose(-1, -2))))))outputs = outputs.transpose(-1, -2) # as Conv1D requires (N, C, Length)outputs += inputsreturn outputs
實際調用:
PointWiseFeedForward(args.hidden_units, args.dropout_rate)
PS:
1.Conv1d:一維卷積。這里用了d個一維卷積,本質上是一個帶共享權重的d*d矩陣的線性層。
詳細可參考:pytorch之nn.Conv1d詳解
2.input.transpose(dim0, dim1)等價于torch.transpose(input, dim0, dim1):將這兩個給定維度互換。
詳細可參考:torch.transpose()
插入排序)














)
1)
)
:模型數據 以及 視圖和視圖解析器)
