文章目錄
- 1、定位慢查詢
- 2、慢查詢的原因分析
- 3、索引
- 3.1 數據結構選用:二叉樹 & 紅黑樹
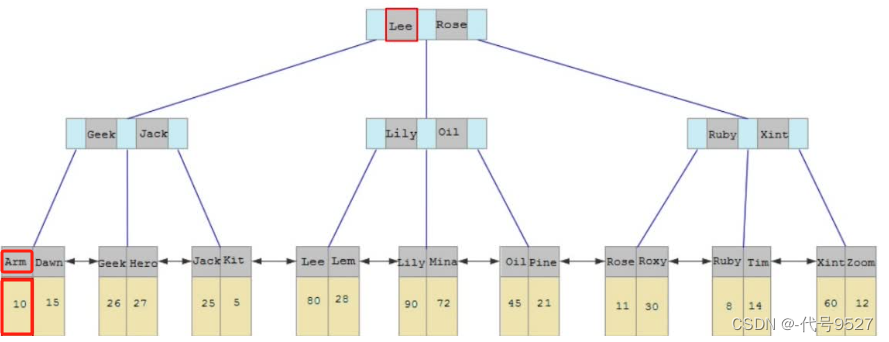
- 3.2 數據結構選用:B+樹
- 4、聚簇索引、非聚簇索引、回表查詢
- 4.1 聚簇索引、非聚簇索引
- 4.2 回表查詢
- 5、覆蓋索引、超大分頁優化
- 5.1 覆蓋索引
- 5.2 超大分頁處理
- 6、索引的創建
- 7、索引的失效
- 8、SQL優化的經驗
- 9、面試
1、定位慢查詢
- Arthas在線查看方法耗時
- 運維工具Prometheus
- 鏈路追蹤工具Skywalking、Zipkin、OpenTemplate

- MySQL自帶的慢日志:記錄執行超過n秒的SQL
//修改配置文件,文件位置
/etc/my.cnf//開啟慢查詢開關,生產環境不建議開啟,會損失部分性能
slow_query_log=1//設置超過2秒的SQL
long_query_time=2
慢SQL被記錄到/var/lib/mysql/localhost-slow.log

2、慢查詢的原因分析
慢SQL通常是因為:
- 聚合查詢
- 多表查詢
- 表數據量過大查詢
- 深度分頁查詢
前三種,可嘗試使用SQL執行計劃分析原因:
# SELECT語句前添加EXPLAIN或DESC,查看SQL語句執行情況的信息
EXPLAIN select * from t_table;
DESC select * from t_table;

此時SELECT返回的不是表數據,是一些執行信息:
- possible: key 當前sql可能會使用到的索引
- key: 當前sql實際命中的索引
- key_len: 索引占用的大小,key和key_len搭配,檢查是否存在索引失效
- Extra:額外的優化建議

- type:這條sql的連接的類型,性能由好到差為NULL、system、const、eq_ref、ref、range、index、all
system:查詢MySQL系統內置庫的表const:根據主鍵查詢eq_re:主鍵索引查詢或唯一索引查詢ref:索引查詢range:范圍查詢index:索引樹掃描,遍歷整個索引all:不走索引,全盤掃描
3、索引
一種用于高效查數據的數據結構,以某種方式指向表里的數據。如下表,不加索引,查age=45的數據,就是逐行對比 + 遍歷整個表直至最后一行,效率低下

如果去維護一個類似二叉樹的結構,再查age=45的數據,則直接從根節點開始? 45 > 36,去右側 ? 45 < 48 ?去左側 ? 查找完畢,如此,查找效率提升,這即索引的思想
3.1 數據結構選用:二叉樹 & 紅黑樹
MySQL索引底層的數據結構是B+樹。不選二叉樹是因為:
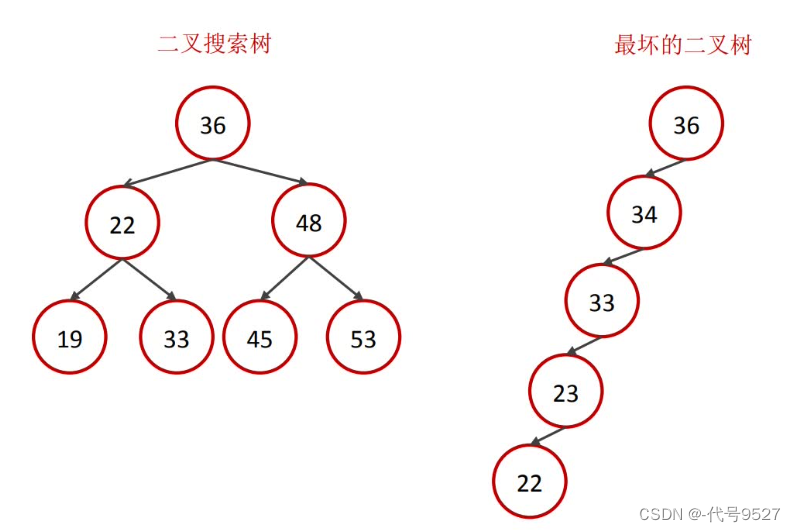
如果數據遞增或遞減,此時二叉樹變鏈表,即最壞情況的二叉樹效率很低。既然二叉樹有平衡性問題,那再考慮自平衡的二叉樹 ? 紅黑樹
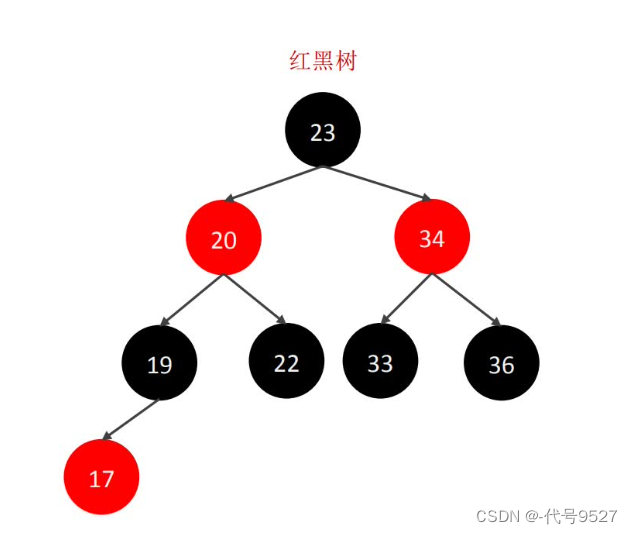
紅黑樹時間復雜度為O(log n),但其也是一個二叉樹,每個節點最多只能兩個分支,因此,大數據量下,紅黑樹會很高。 ? B樹,每個節點可以多個分支,是一種多叉路衡查找樹。以一顆5階B樹為例(最大度數mas-degree為5,每個節點最多存儲4個key)
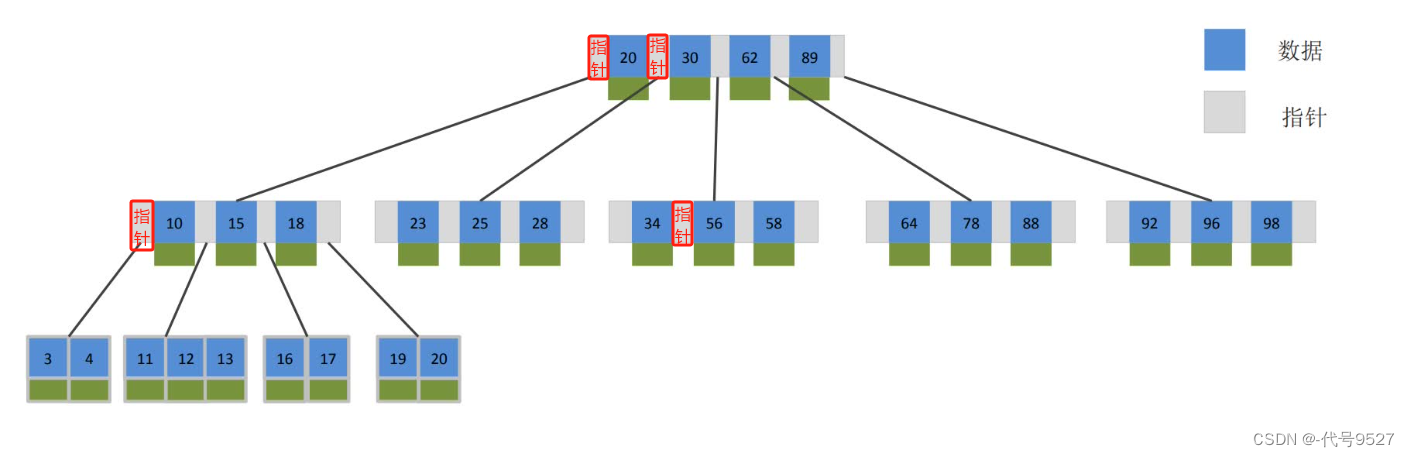
圖中的灰色部分,存儲指針,指向子節點。如20左側的指針,指向的就是20以內的數據,20和30之間的指針,則指向20~30之間的數據,以此類推。且綠色部分存儲的是對應的那條數據。
3.2 數據結構選用:B+樹
相比二叉樹,B樹是一種矮胖樹,B+樹則是B樹的一種優化,非葉子節點只存儲指針,不存儲數據。只有在葉子節點才去存儲對應的數據,前面的非葉子節點起一個導航的作用,非葉子節點上就匹配到的數據,在葉子節點上也能找到這個數。
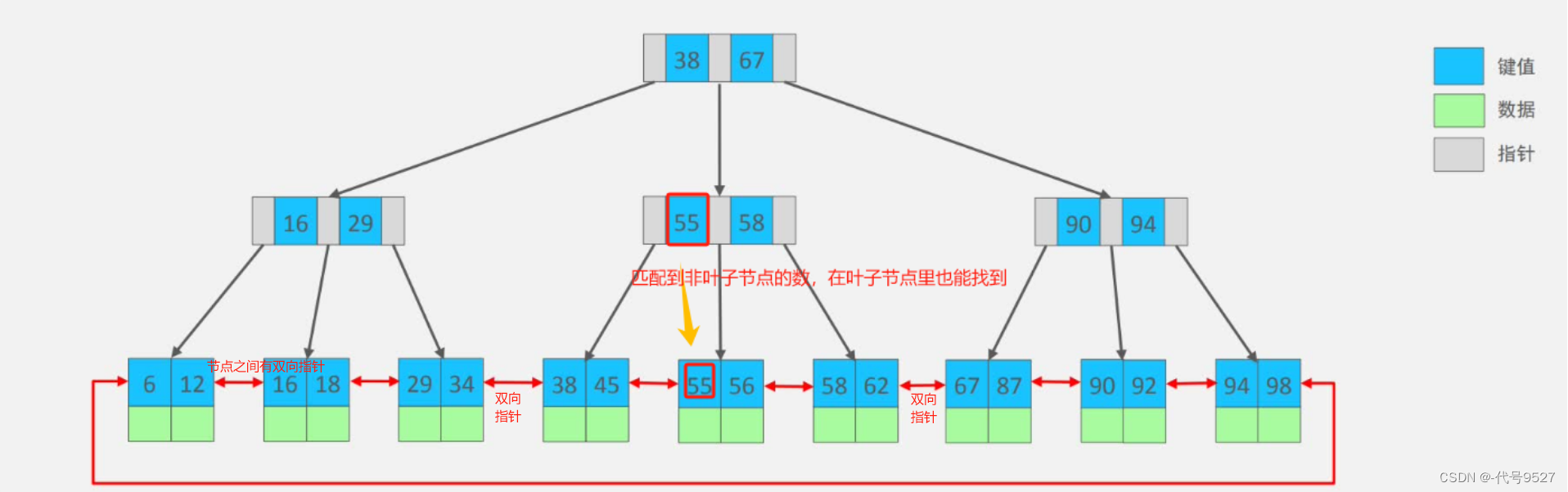
MySQL默認的存儲引擎InnoDB默認使用B+樹實現索引。相比B樹,B+樹:
- 磁盤讀寫代價更低(只有葉子節點存數據)
- 查詢效率更穩定(最后都要落到葉子節點)
- 適合于區間查詢(葉子節點之間的雙向指針,比如查6~34這個區間的數,先從根節點對比,走左邊,到16,再走左邊,到6,再跟雙向指針拿到6到34的數據,不需要再從根節點開始重新找一次)
4、聚簇索引、非聚簇索引、回表查詢
4.1 聚簇索引、非聚簇索引
聚簇索引(又叫聚集索引),即B+樹的葉子節點保存的是整行數據。非聚簇索引(又叫二級索引),即B+樹單獨葉子節點存儲的是那行數據對應的主鍵

聚簇索引選取規則:(節點里存哪個)
- 如果存在主鍵,主鍵索引就是聚集索引
- 如果不存在主鍵,將使用第一個唯一(UNIQUE)索引作為聚集索引
- 如果表沒有主鍵,或沒有合適的唯一索引,則InnoDB 會自動生成一個rowid 作為隱藏的聚集索引
如下:建立聚簇索引時,這張表有主鍵ID,因此,節點中存儲的是ID值,最后,葉子節點中存的那個row是整條數據值。
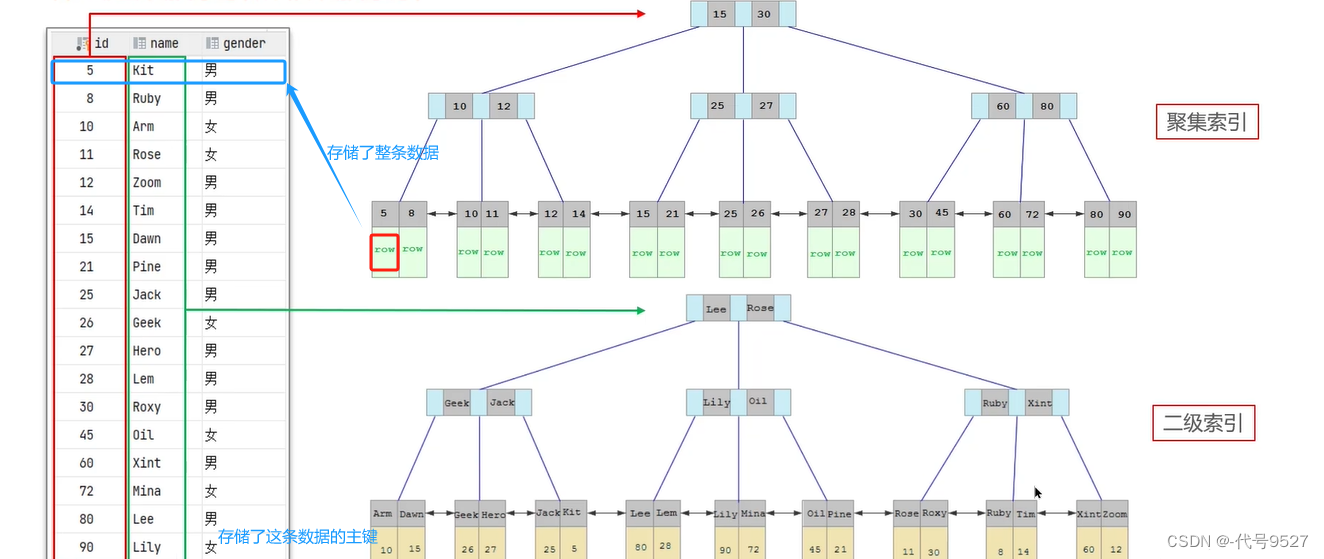
再比如給表的name字段建立非聚簇索引,節點存儲name的值,最后的葉子節點,存儲的是這條數據的主鍵值
4.2 回表查詢
select * form user where name = 'Arm';
給name字段加了非聚簇索引,因此,執行如上SQL,先根據name的非聚簇索引的B+樹 ? A小于L,走左邊,到G和J,再走左邊,找到Arm ? 因為是select *,而非聚簇索引的葉子節點存的是主鍵 ? 拿著主鍵,回到聚簇索引,從其根節點開始查 ? 聚簇索引的葉子節點存了整行數據,返回select * 的結果
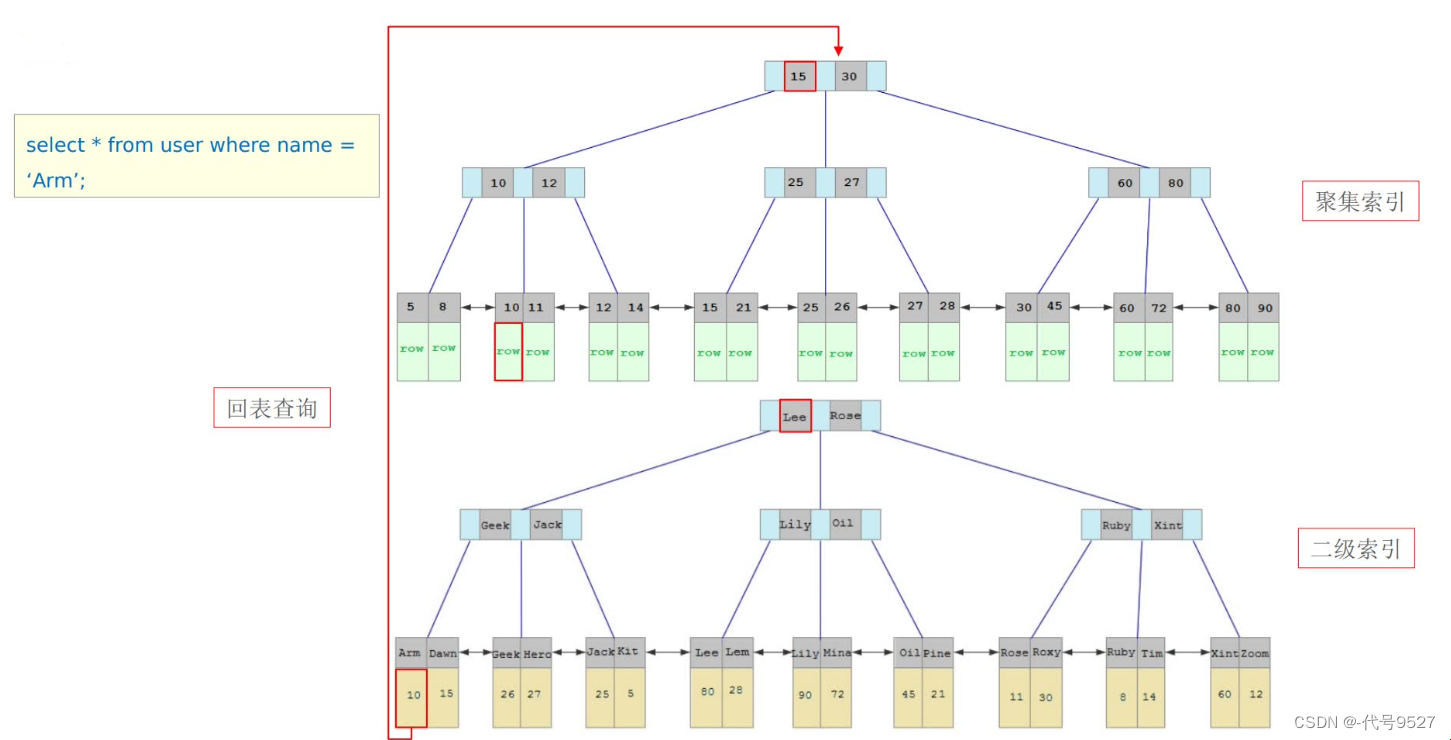
總之,回表查詢就是:先根據非聚簇索引找到主鍵值,再根據主鍵值到聚簇索引拿到整行數據
5、覆蓋索引、超大分頁優化
5.1 覆蓋索引
即查詢使用了索引,并且你需要返回的字段,在索引中能夠全部找到。
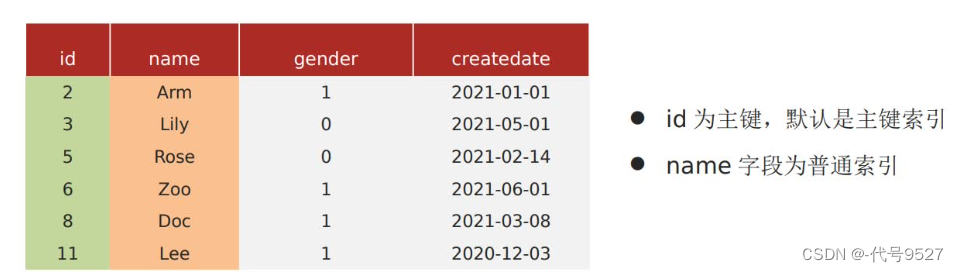
select * form tb_user where id = 1;
是覆蓋索引,雖然select * ,但其where是根據id過濾的,即用的是主鍵索引、聚簇索引,索引的葉子節點存了整行數據,需要返回的字段,在索引中能夠全部找到
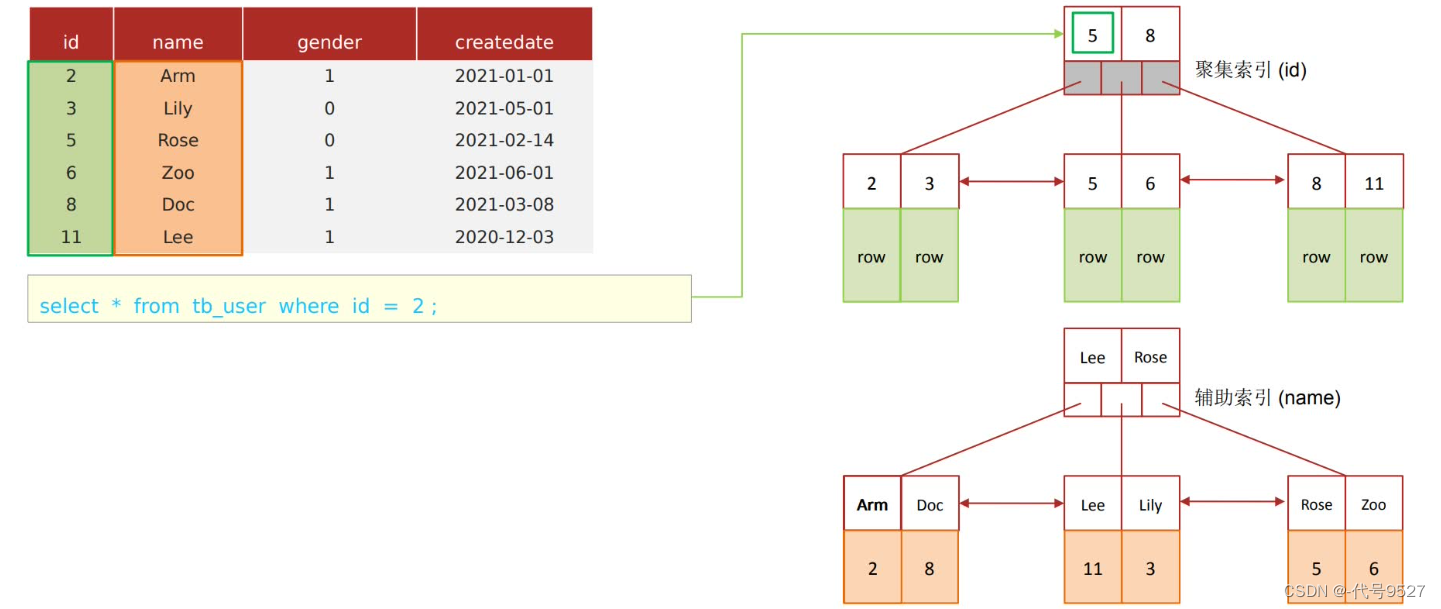
select id, name from tb_user where name = 'Arm';
是覆蓋索引,where根據name過濾,走name的非聚簇索引,最后葉子節點存了id,而最后需要返回的就是id和name
select id, name, gender from tb_user where name = 'Arm';
不是覆蓋索引,索引中拿不到gender值,需要回表查詢
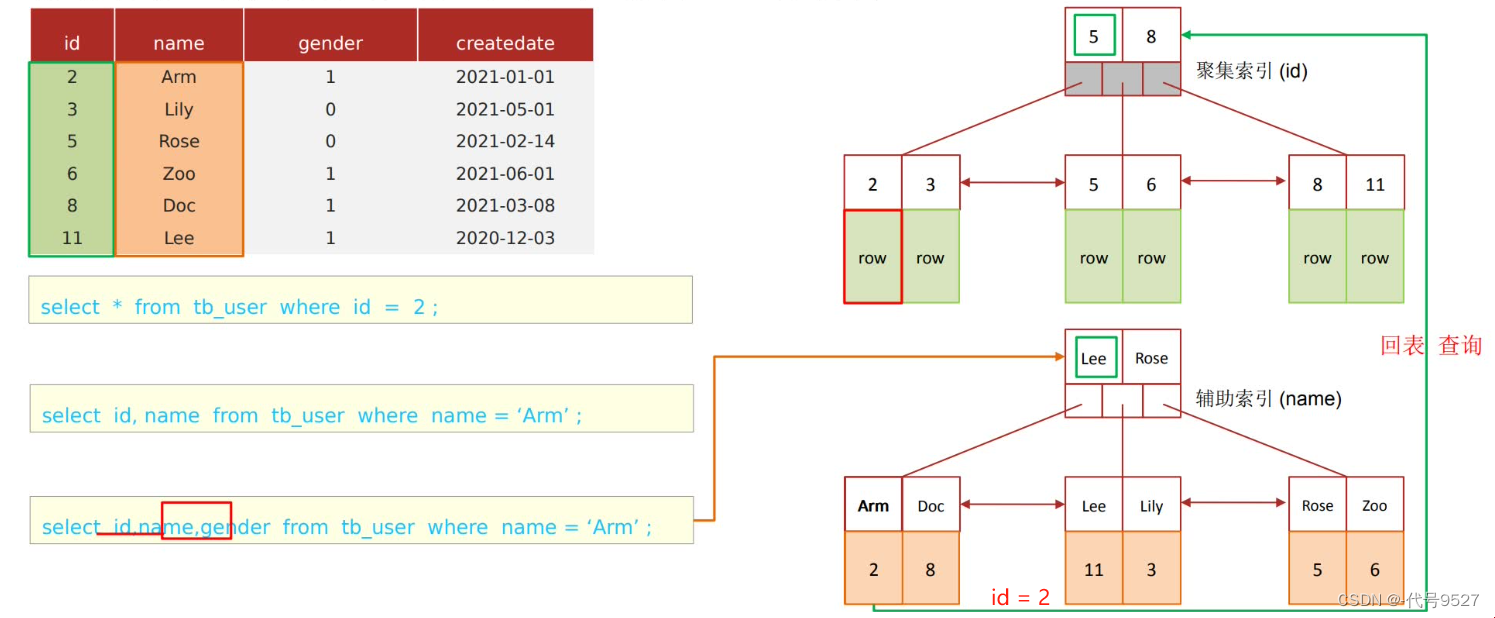
很明顯,能一次查詢出來的,符合覆蓋索引的,效率最高,走回表查詢的SQL,效率低
5.2 超大分頁處理
使用limit分頁查,需要對數據進行排序,數據量很大時,效率很低
比如,limit 900 0000,10,此時,需要排序前9000010行數據,再返回9000000到9000010行這10行:

解決方案是:覆蓋索引 + 子查詢

即先根據主鍵去分頁order by id ,不select *,而是select id,再和原來的表關聯查
6、索引的創建
需要創建索引的場景:
- 數據量大(單表超過10萬行),且查詢頻繁
- 給常作為
where、order by、group by操作的字段創建索引 - 如果字段是字符串類型,且長度很長,給其建立索引壓力大,可截取前幾個字,建立前綴索引

- 多用聯合索引,而不是單列索引。因為如果給A + B兩個字段建立了聯合索引,剛好又select A, B from table where A = 1;就是覆蓋索引,避免了回表,查詢效率更高。下圖即給name、status、address三個字段建了聯合索引

- 索引并不是越多越好,因為增刪改也要同步去維護索引,索引多了,會影響增刪改的效率
7、索引的失效
給表tb_seller的name,status,address字段創建聯合索引:

索引失效的場景:
1)違反最左前綴法則
最左前綴法則,即select后面的字段,必須從索引的最左前列開始,并且不跳過索引中的列。以下為索引不失效的寫法:

以下寫法索引失效:

以下寫法,中途跳過了聯合索引的某一列,只有最左側字段索引生效,從key_len的大小可以看出,其只命中了一個字段:

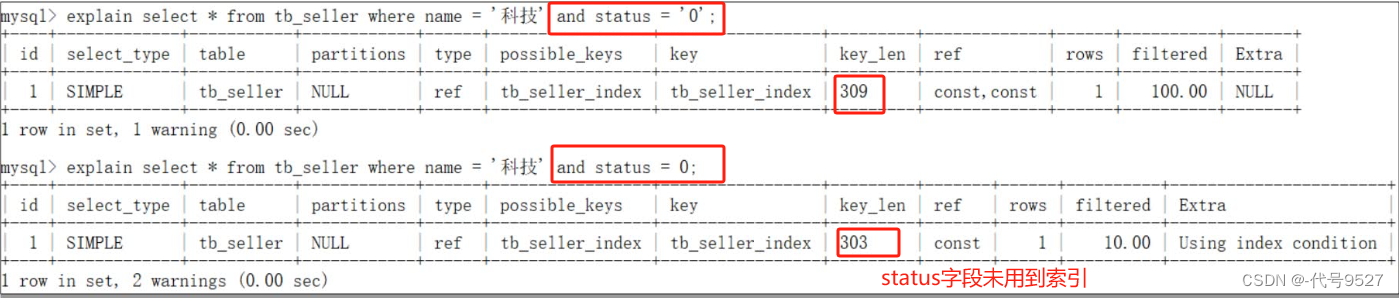
2)對status范圍查詢,則status右邊的列address沒有用到索引,但name,status還是走了索引了

3)在索引所在的列上進行運算,索引會失效
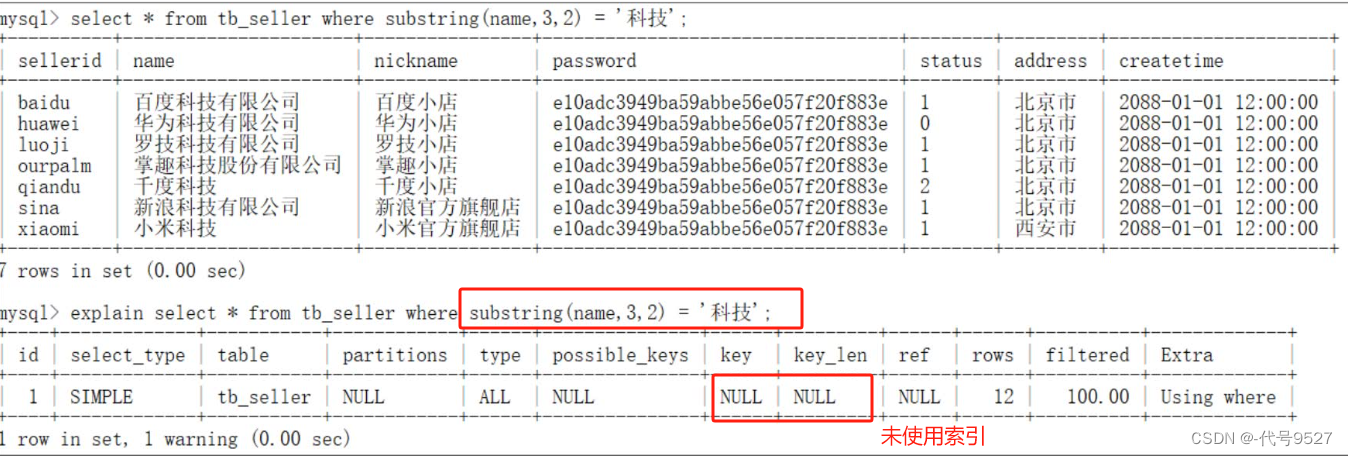
4)字符串不加單引號,索引失效
因為不對字符串類型加單引號,MySQL優化器會自動進行類型轉換,造成索引失效
5)以%開頭的Like模糊查詢,索引失效
注意:如果僅僅是末尾進行模糊查詢,索引不會失效

8、SQL優化的經驗
1)表設計優化:
- 設置合適的數值類型:tinyint、int、bigint
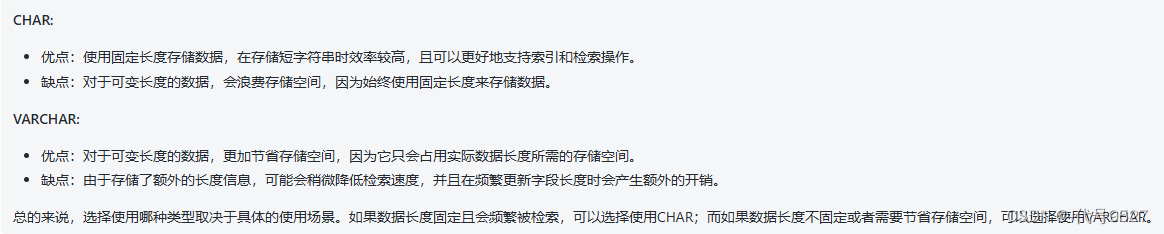
- 字符串類型,char和varchar,char定長、效率高,varchar長度靈活可變,根據字符串實際長度來,但效率稍低
2)SQL語句優化
- 避免select *
- 避免索引失效的寫法
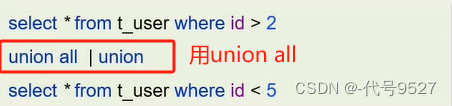
- 使用union all代替union,union會把兩個查詢的結果再做個去重
- 避免where中對字段進行計算操作
- join表時,能用inner join,不left join或者right join,業務必須要用時,可將小表(行數少的表)放外面。原因參考for循環嵌套,如下寫法,MySQL進行三次連接,每次連接進行1000次操作,反之就是進行1000次連接,每次連接進行3次操作(inner join 就會自動優化,把小表放外面。left join或right join就不會把小表放外面)

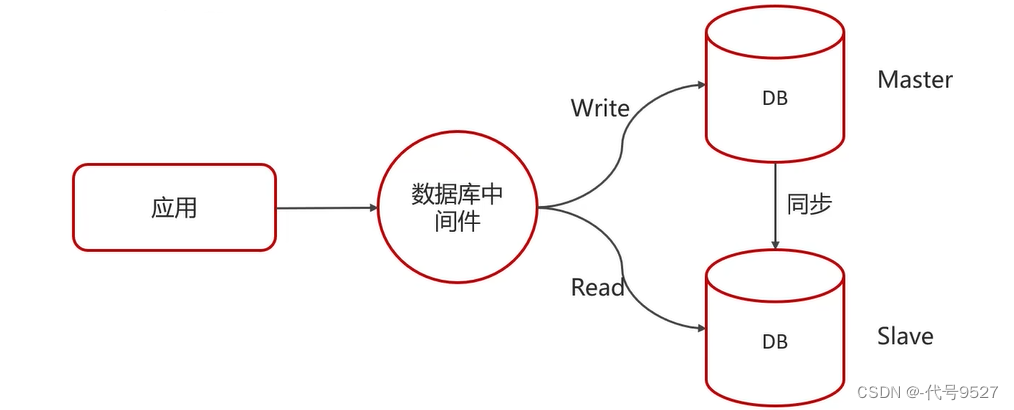
3)讀寫分離,主從復制
- 用于避免寫操作影響查詢效率
- 主庫寫,從庫讀
4)索引的創建和失效
5)分庫分表(見下篇)
9、面試






<C語言>)









)




)

)