2024 ?屆本科畢業論文(設計)
?基于Hadoop的地震預測的
分析與可視化研究
姓 ???名:____田偉情_________
系 ???別:____信息技術學院___
專 ???業:數據科學與大數據技術
學 ???號:__2011103094________
指導教師:_____王雙喜________
年 ??月 ??日
目 錄
1 緒論
2 ?相關技術與工具
2.1 ?大數據技術概述
2.2 ?hadoop介紹
3 地震數據分析
3.1 數據收集與處理
4 地震數據可視化
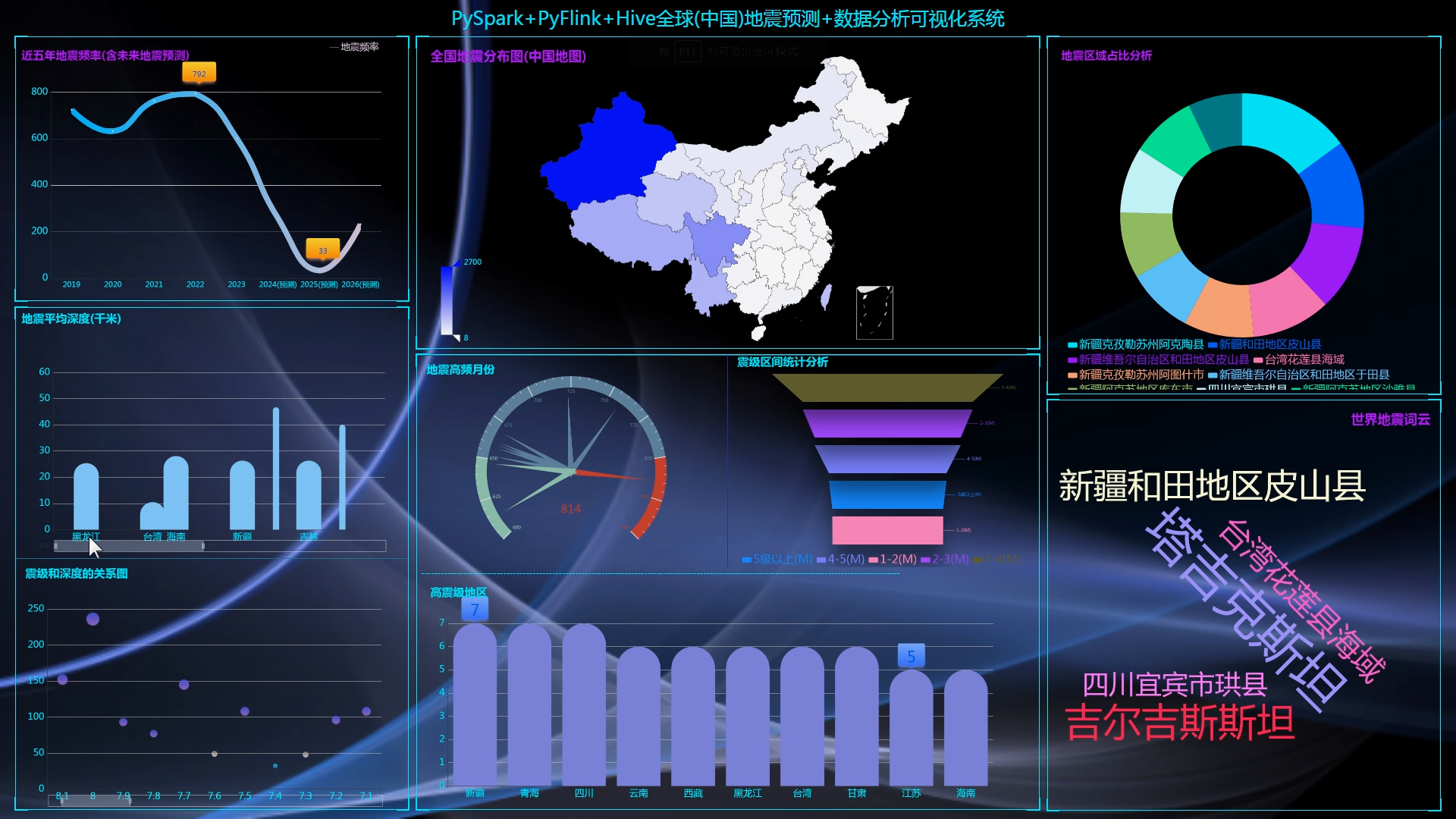
4.1 可視化技術概述
4.2 可視化設計原則
4.3 可視化實現與評估
5 系統設計與實現
5.1 登錄頁面
5.2
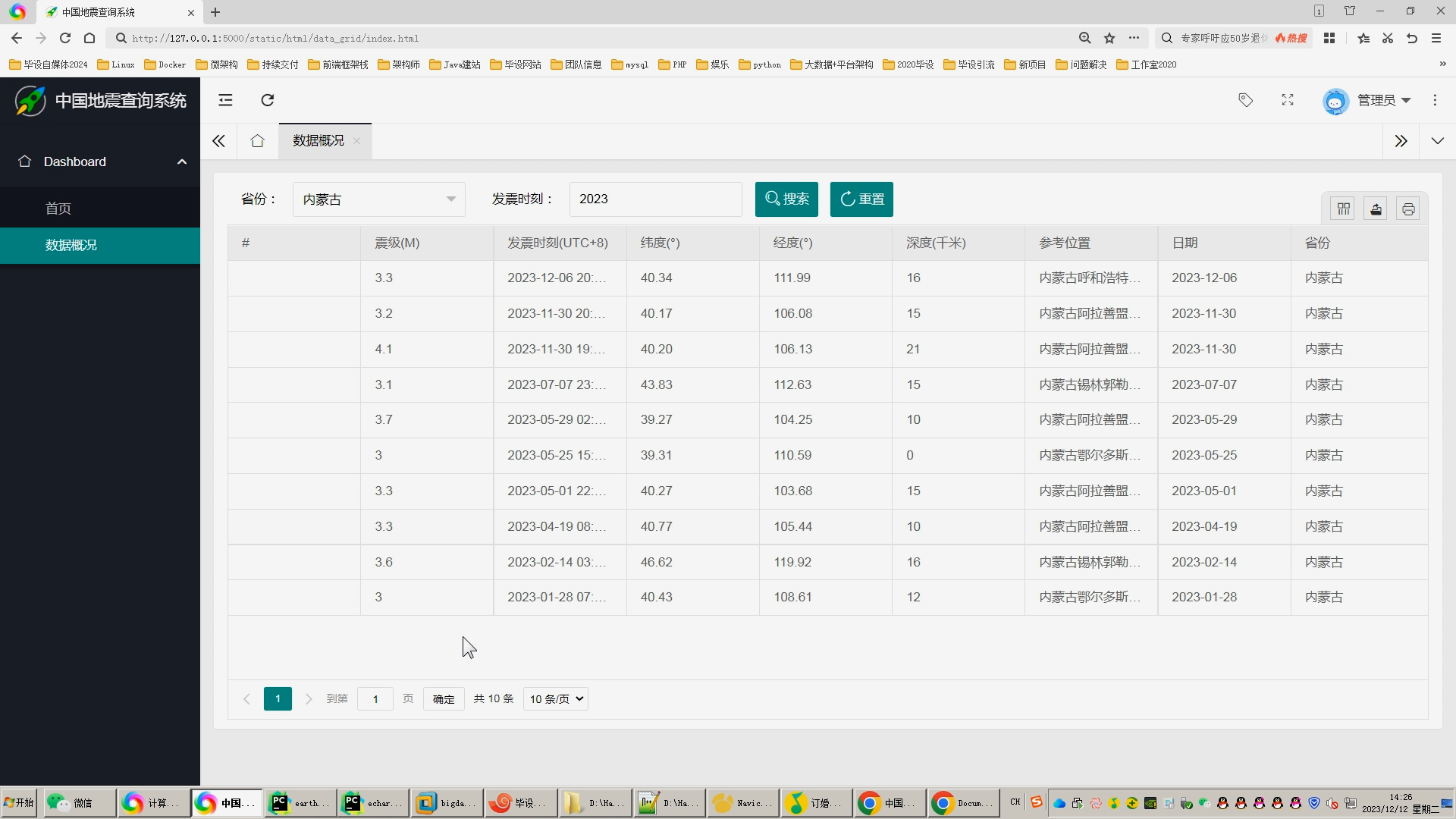
5.3 地震數據分析頁面
5.4 地震數據維護頁面
6 結果討論
6.1 結果總結
6.2 結果分析
6.3 存在問題
6.4 結果展望
參考文獻
致 謝
基于Hadoop的地震預測的分析與可視化研究
田偉情 ???指導教師:王雙喜
(商丘師范學院信息技術學院,河南商丘 ?476000) ??
??
摘 ?要:08年四川5·12汶川地震、10年青海玉樹地震、13年四川雅安地震,到23年甘肅積石山地震,大大小小的地震無數次的上演,帶給我們的不僅是肉體上的疼痛,還有無法治愈的心靈創傷。在睡夢中因地震而驚醒,轟隆隆的地裂聲還有那些肉眼可見的消失的村莊恐怕是無數遭遇地震的人的噩夢,也是所有人共同的悲哀。即使沒有親身經歷過,但新聞報道中倒坍的房屋,埋頭救人的官兵,隔著屏幕也能感受到疼痛。?因此,準確地預測地震的發生時間、地點和震級對于人們的生命安全和財產安全具有重要意義。然而,地震預測是一個復雜而困難的問題,受到多種因素的影響,如地質構造、地下水位變化、地殼運動等。傳統的地震預測方法往往依賴于經驗和專家判斷,準確度和效率有限。隨著大數據技術的快速發展,越來越多的地震數據被收集和存儲起來。大數據分析和處理技術能夠對這些海量的地震數據進行高效的分析和建模,為地震預測提供更準確的預測模型。然而,大數據在地震預測中的應用也面臨著一些挑戰。首先,地震數據具有高維度和復雜的特征,需要選擇合適的特征參數進行分析和建模。其次,地震數據的規模龐大,傳統的數據處理方法無法滿足實時性要求。此外,地震數據的可視化也是一個重要問題,如何將海量的地震數據以直觀的方式展示給用戶,提高地震預測的可理解性和可操作性,也是一個需要解決的問題。 因此,本研究基于Hadoop的大數據技術,對地震數據進行分析和可視化,提高地震預測的準確性和效率。具體而言,本研究將使用Hadoop框架對地震數據進行分析和建模,利用線性回歸預測算法構建地震預測模型。同時,本研究利用echarts的可視化技術和工具,將地震數據以直觀的方式展示給用戶,提高地震預測的可理解性和可操作性。
關鍵詞:地震、地震預測、Hadoop、線性回歸預測算法
Analysis and visualization of earthquake prediction based on Hadoop??????????
TIAN Weiqing??????Supervisor: WANG Shuangxi
(College of Information Technology, Shangqiu Normal University, Shangqiu 476000, China)
Abstract :The 5.12 Wenchuan earthquake in Sichuan in 08, the Yushu earthquake in Qinghai in 10, the Ya'an earthquake in Sichuan in 13, and the Jishishan earthquake in Gansu in 23 years, earthquakes of all sizes have been staged countless times, bringing us not only physical pain, but also incurable psychological wounds. Waking up in your sleep by the earthquake, the rumbling sound of the ground cracking, and the visible disappearance of the villages are probably the nightmare of countless people who have been hit by the earthquake, and it is also the sorrow shared by everyone. Even if you haven't experienced it yourself, you can feel the pain through the screen of the collapsed houses in the news reports and the officers and soldiers who buried their heads in saving people. Therefore, it is of great significance to accurately predict the time, place and magnitude of earthquakes for the safety of people's lives and property. However, earthquake prediction is a complex and difficult problem that is affected by a variety of factors, such as geological structure, changes in groundwater level, crustal movements, etc. Traditional earthquake prediction methods often rely on experience and expert judgment, and their accuracy and efficiency are limited. With the rapid development of big data technology, more and more seismic data is collected and stored. Big data analysis and processing technology can efficiently analyze and model these massive seismic data, and provide more accurate prediction models for earthquake prediction. However, the application of big data in earthquake prediction also faces some challenges. First of all, seismic data has high-dimensional and complex features, and it is necessary to select appropriate feature parameters for analysis and modeling. Secondly, the scale of seismic data is huge, and traditional data processing methods cannot meet the real-time requirements. In addition, the visualization of seismic data is also an important problem, and how to display massive seismic data to users in an intuitive way and improve the comprehensibility and operability of earthquake prediction is also a problem that needs to be solved. Therefore, this study analyzes and visualizes earthquake data based on Hadoop's big data technology to improve the accuracy and efficiency of earthquake prediction. Specifically, this study will use the Hadoop framework to analyze and model seismic data, and use the linear regression prediction algorithm to construct an earthquake prediction model. At the same time, this study uses the visualization technology and tools of ECHARTS to present earthquake data to users in an intuitive way, so as to improve the comprehensibility and operability of earthquake prediction.
Key words:earthquake, earthquake prediction、Hadoop、Linear regression prediction algorithm
核心算法代碼分享如下:
import csv
import random
import re
import time
import datetime
import pymysql
import requests
#將數據保存到mysql方便制作表格查詢
provinces = ['北京', '天津', '河北', '山西', '內蒙古', '遼寧', '吉林', '黑龍江', '上海', '江蘇', '浙江', '安徽','福建', '江西', '山東', '河南', '湖北', '湖南','廣東', '廣西', '海南', '重慶', '四川', '貴州', '云南', '西藏', '陜西', '甘肅', '青海', '寧夏','新疆', '香港', '澳門', '臺灣'
]
long_provinces = ['北京市', '天津市', '河北省', '山西省', '內蒙古自治區', '遼寧省', '吉林省', '黑龍江省', '上海市', '江蘇省', '浙江省', '安徽省','福建省', '江西省', '山東省', '河南省', '湖北省', '湖南省','廣東省', '廣西壯族自治區', '海南', '重慶市', '四川省', '貴州省', '云南省', '西藏自治區', '陜西省', '甘肅省', '青海省', '寧夏回族自治區','新疆維吾爾自治區', '香港特別行政區', '澳門特別行政區', '臺灣省'
]
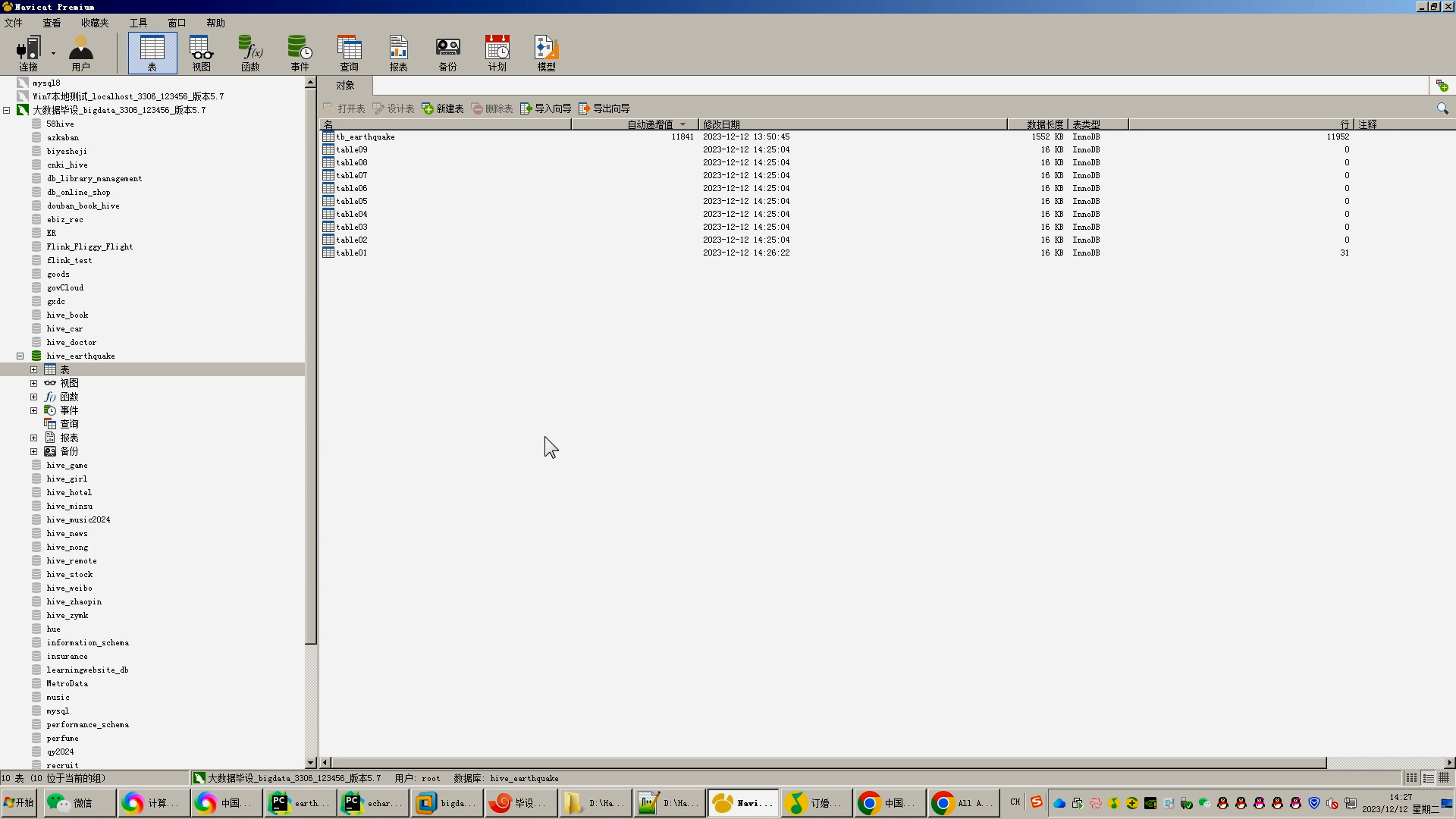
with open('./world.csv', 'r',encoding='utf-8') as world_file :world_reader = csv.reader(world_file)errors=0line=0for row in world_reader:#magnitude ,stime_long, latitude, longitude, depth, addr ,stime_short,provincemagnitude = row[0]stime_long = row[1]latitude = row[2]longitude = row[3]depth = row[4]addr = row[5]stime_short = row[6]stime_year = row[7]stime_month = row[8]stime_clock= row[9]data_type='外國'addr=addr.replace(',',',')for province in provinces:if province in addr:data_type=province# magnitude, stime_long, latitude, longitude, depth, addr, stime_short,data_typeprint(magnitude, stime_long, latitude, longitude, depth, addr, stime_short,data_type)#tb_earthquakeconn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_earthquake')cursor = conn.cursor()data = (magnitude, stime_long, latitude, longitude, depth, addr, stime_short,data_type)sql = "replace into tb_earthquake (magnitude, stime_long, latitude, longitude, depth, addr, stime_short,data_type) " \"values (%s,%s,%s,%s,%s,%s,%s,%s)"cursor.execute(sql,data)conn.commit()cursor.close()if data_type != '外國':for long_province in long_provinces:if data_type in long_province:earthquake_file = open("earthquake_hdfs.csv", mode="a+", newline='', encoding="utf-8")earthquake_writer = csv.writer(earthquake_file)earthquake_writer.writerow([magnitude, stime_long, latitude, longitude, depth, addr, stime_short,data_type,long_province,stime_year,stime_month,stime_clock])earthquake_file.close()else:earthquake_file = open("earthquake_hdfs.csv", mode="a+", newline='', encoding="utf-8")earthquake_writer = csv.writer(earthquake_file)earthquake_writer.writerow([magnitude, stime_long, latitude, longitude, depth, addr, stime_short,data_type,'無(外國)',stime_year,stime_month,stime_clock])earthquake_file.close()


-Dalvik vs ART-探秘Android虛擬機內在機制)


:打斷點的實現以及案例分析)






--使用Hystrix進行服務降級)
)





