目錄
- 一、實驗目的與要求
- 二、主要實驗過程
- 1、加載數據集
- 2、數據預處理
- 3、劃分數據集
- 4、創建模型估計器
- 5、模型擬合
- 6、模型性能評估
- 三、主要程序清單和運行結果
- 四、實驗體會
一、實驗目的與要求
1、目的:
??綜合運用所學知識,選取有實際背景的應用問題進行數據分析方案的設計與實現。要求明確目標和應用需求,涵蓋數據預處理、建模分析、模型評價和結果展示等處理階段,完成整個分析流程。
2、要求:
(1)應用Scikit-Learn庫中的邏輯回歸、SVM和kNN算法對Scikit-Learn自帶的乳腺癌(from sklearn.datasets import load_breast_cancer)數據集進行分類,并分別評估每種算法的分類性能。
(2)為了進一步提升算法的分類性能,能否嘗試使用網格搜索和交叉驗證找出每種算法較優的超參數。
二、主要實驗過程
1、加載數據集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
cancer.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
將數據集轉換為DataFram:
import pandas as pd
cancer_data=pd.DataFrame(cancer.data,columns=cancer.feature_names)
cancer_data['target']=cancer.target_names[cancer.target]
cancer_data.head(3).append(cancer_data.tail(3))
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.16220 | 0.66560 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | malignant |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.12380 | 0.18660 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | malignant |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.14440 | 0.42450 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | malignant |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 | malignant |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 | malignant |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 | benign |
6 rows × 31 columns
2、數據預處理
進行數據標準化:
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target
3、劃分數據集
將數據集劃分為訓練集和測試集:
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33)
4、創建模型估計器
(1)創建邏輯回歸模型估計器:
#創建邏輯回歸模型估計器
from sklearn.linear_model import LogisticRegression
lgr=LogisticRegression()
(2)創建SVM算法模型估計器:
#創建SVM算法模型估計器
from sklearn.svm import SVC
svc=SVC()
(3)創建kNN算法模型估計器:
#創建kNN算法模型估計器
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()
5、模型擬合
用訓練集訓練模型估計器estimator:
#訓練邏輯回歸模型估計器
lgr.fit(X_train,y_train)
#訓練SVM算法模型估計器
svc.fit(X_train,y_train)
#訓練kNN算法模型估計器
knn.fit(X_train,y_train)
6、模型性能評估
(1)邏輯回歸模型性能評估:
#用模型估計器對測試集數據做預測
y_pred=lgr.predict(X_test)#對模型估計器的學習效果進行評價
print("測試集的分類準確率為:",lgr.score(X_test,y_test))
(2)SVM算法模型性能評估:
#用模型估計器對測試集數據做預測
y_pred=svc.predict(X_test)#對模型估計器的學習效果進行評價
print("測試集的分類準確率為:",svc.score(X_test,y_test))
(3)kNN算法模型性能評估:
#用模型估計器對測試集數據做預測
y_pred=knn.predict(X_test)#對模型估計器的學習效果進行評價
print("測試集的分類準確率為:",knn.score(X_test,y_test))
三、主要程序清單和運行結果
1、邏輯回歸用于分類
#加載數據集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#對數據集進行預處理,實現數據標準化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#將數據集劃分為訓練集和測試集(要求測試集占25%,隨機狀態random state設置為33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #創建模型估計器estimator
from sklearn.linear_model import LogisticRegression
lgr=LogisticRegression()#用訓練集訓練模型估計器estimator
lgr.fit(X_train,y_train)#用模型估計器對測試集數據做預測
y_pred=lgr.predict(X_test)#對模型估計器的學習效果進行評價
#最簡單的評估方法:就是調用估計器的score(),該方法的兩個參數要求是測試集的特征矩陣和標簽向量
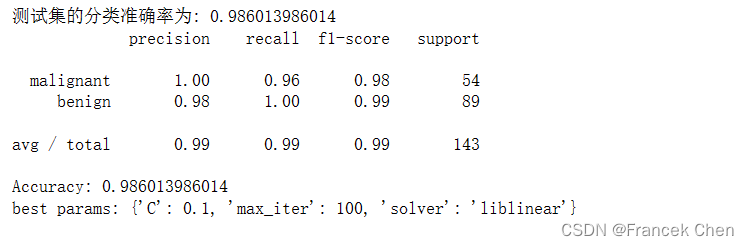
print("測試集的分類準確率為:",lgr.score(X_test,y_test))
from sklearn import metrics
#對于多分類問題,還可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names)) #網格搜索與交叉驗證相結合的邏輯回歸算法分類:
from sklearn.model_selection import GridSearchCV,KFold
params_lgr={'C':[0.01,0.1,1,10,100],'max_iter':[100,200,300],'solver':['liblinear','lbfgs']}
kf=KFold(n_splits=5,shuffle=False)grid_search_lgr=GridSearchCV(lgr,params_lgr,cv=kf)
grid_search_lgr.fit(X_train,y_train)
grid_search_y_pred=grid_search_lgr.predict(X_test)
print("Accuracy:",grid_search_lgr.score(X_test,y_test))
print("best params:",grid_search_lgr.best_params_)
2、支持向量用于分類
#加載數據集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#對數據集進行預處理,實現數據標準化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#將數據集劃分為訓練集和測試集(要求測試集占25%,隨機狀態random state設置為33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #創建模型估計器estimator
from sklearn.svm import SVC
svc=SVC()#用訓練集訓練模型估計器estimator
svc.fit(X_train,y_train)#用模型估計器對測試集數據做預測
y_pred=svc.predict(X_test)#對模型估計器的學習效果進行評價
#最簡單的評估方法:就是調用估計器的score(),該方法的兩個參數要求是測試集的特征矩陣和標簽向量
print("測試集的分類準確率為:",svc.score(X_test,y_test))
from sklearn import metrics
#對于多分類問題,還可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names))#網格搜索與交叉驗證相結合的SVM算法分類:
from sklearn.model_selection import GridSearchCV,KFold
params_svc={'C':[0.1,1,10],'gamma':[0.1,1,10],'kernel':['linear','rbf']}
kf=KFold(n_splits=5,shuffle=False)
grid_search_svc=GridSearchCV(svc,params_svc,cv=kf)
grid_search_svc.fit(X_train,y_train)
grid_search_y_pred=grid_search_svc.predict(X_test)
print("Accuracy:",grid_search_svc.score(X_test,y_test))
print("best params:",grid_search_svc.best_params_)

3、kNN用于分類
#加載數據集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#對數據集進行預處理,實現數據標準化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#將數據集劃分為訓練集和測試集(要求測試集占25%,隨機狀態random state設置為33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #創建模型估計器estimator
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()#用訓練集訓練模型估計器estimator
knn.fit(X_train,y_train)#用模型估計器對測試集數據做預測
y_pred=knn.predict(X_test)#對模型估計器的學習效果進行評價
#最簡單的評估方法:就是調用估計器的score(),該方法的兩個參數要求是測試集的特征矩陣和標簽向量
print("測試集的分類準確率為:",knn.score(X_test,y_test))
from sklearn import metrics
#對于多分類問題,還可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names))#網格搜索與交叉驗證相結合的kNN算法分類:
from sklearn.model_selection import GridSearchCV,KFold
params_knn={'algorithm':['auto','ball_tree','kd_tree','brute'],'n_neighbors':range(3,10,1),'weights':['uniform','distance']}
kf=KFold(n_splits=5,shuffle=False)
grid_search_knn=GridSearchCV(knn,params_knn,cv=kf)
grid_search_knn.fit(X_train,y_train)
grid_search_y_pred=grid_search_knn.predict(X_test)
print("Accuracy:",grid_search_knn.score(X_test,y_test))
print("best params:",grid_search_knn.best_params_)

四、實驗體會
??在本次實驗中,我使用了Scikit-Learn庫中的邏輯回歸、支持向量機(SVM)和k最近鄰(kNN)算法對乳腺癌數據集進行分類,并對每種算法的分類性能進行了評估。隨后,我嘗試使用網格搜索和交叉驗證來找出每種算法的較優超參數,以進一步提升其分類性能。
??首先,我加載了乳腺癌數據集,并將其劃分為訓練集和測試集。然后,我分別使用邏輯回歸、SVM和kNN算法進行訓練,并在測試集上進行評估。評估指標包括準確率、精確率、召回率和F1-score等。通過這些指標,我能夠了解每種算法在乳腺癌數據集上的分類性能。
??接著,我嘗試使用網格搜索(Grid Search)和交叉驗證(Cross Validation)來找出每種算法的較優超參數。網格搜索是一種通過在指定的超參數空間中搜索最佳參數組合來優化模型的方法。而交叉驗證則是一種評估模型性能和泛化能力的方法,它將數據集分成多個子集,在每個子集上輪流進行訓練和測試,從而得到更穩健的性能評估結果。
??在進行網格搜索和交叉驗證時,我根據每種算法的參數范圍設置了不同的參數組合,并使用交叉驗證來評估每種參數組合的性能。最終,我選擇了在交叉驗證中性能最優的參數組合作為最終的超參數,并將其用于重新訓練模型。
??通過這次實驗,我學到了如何使用Scikit-Learn庫中的機器學習算法進行分類任務,并了解了如何通過網格搜索和交叉驗證來優化算法的超參數,提升其分類性能。同時,我也意識到了在實際應用中,選擇合適的算法和調優超參數對于獲得良好的分類效果至關重要。這次實驗為我提供了寶貴的實踐經驗,對我的機器學習學習之旅有著重要的意義。







——分布式計算)
![BUUCTF靶場[Web] [極客大挑戰 2019]Havefun1、[HCTF 2018]WarmUp1、[ACTF2020 新生賽]Include](http://pic.xiahunao.cn/BUUCTF靶場[Web] [極客大挑戰 2019]Havefun1、[HCTF 2018]WarmUp1、[ACTF2020 新生賽]Include)


:常用基本命令)


)


 —— 序列流、內存流)

