文章目錄
- 1. 各模塊解決
- 1.1 輸入部分
- 1.2 多頭注意力(作者使用8個頭)
- 1.3 殘差和LayerNorm
- 1.4 Decoder部分
- 2.Transformer經典問題
- 2.1 tranformer為何使用多頭注意力機制?
- 2.2 Transformer相比CNN的優缺點
- 2.3 Encoder和decoder的區別?兩者感受野是否一致?
Tranformer現如今無論是在CV還是NLP,甚至現在非常或的LLM領域都非常重要!該架構是谷歌在2017年《Attention is all you need》中提出的,下面將分析本人對各個模塊的理解+算法面試中的常見問題。
1. 各模塊解決
參考如下:
Transformer從零詳細解讀(可能是你見過最通俗易懂的講解)
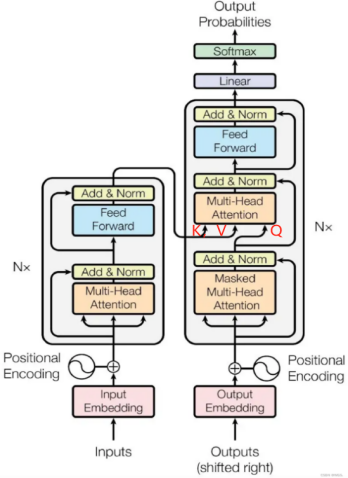
其基本架構如上如所示,圖中的N在論文中等于6。
編碼器與解碼器之間的數據傳遞如下圖所示:
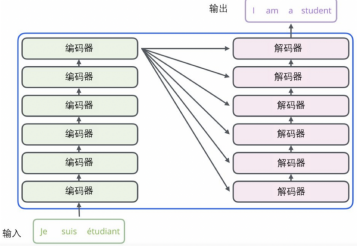
下面將詳解各模塊:
1.1 輸入部分
(1)Embedding

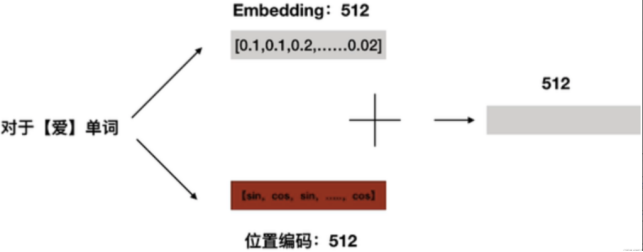
一般是采用Embedding方式對輸入進行編碼,如上圖所示,
即:使用特定維度來表達一個單詞,如:
‘我’: 就使用一個512維度的向量來表示,
‘愛’: 也使用一個512維度的向量來表示;
(2)位置編碼
詳見本人博客:舉例理解transformer中的位置編碼
1)明白為什么要使用位置編碼?
因為Transformer的多頭注意力機制是并行化的,所有單詞是可以一起處理的。(而不想RNN那種一次輸入一個詞,輸入本身就帶有時序關系, 注意RNN中的梯度消失:RNN的梯度是總的梯度和,它的梯度消失不是梯度變為0,而是因為它的梯度被近距離梯度主導,被遠距離梯度忽略不計)
Transformer的并行化可以提高速度,但缺少了位置信息,所以需要位置編碼!
2)編碼過程
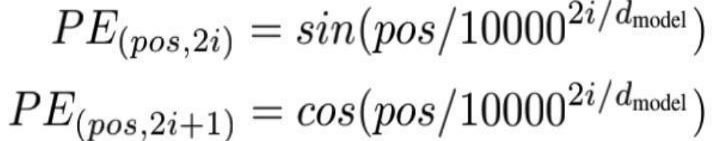
上式中,pos表示單詞在句子中的位置,2i和2i+1要整體看,2i表示向量的偶數位置,2i+1表示向量的奇數位置。如圖所示:
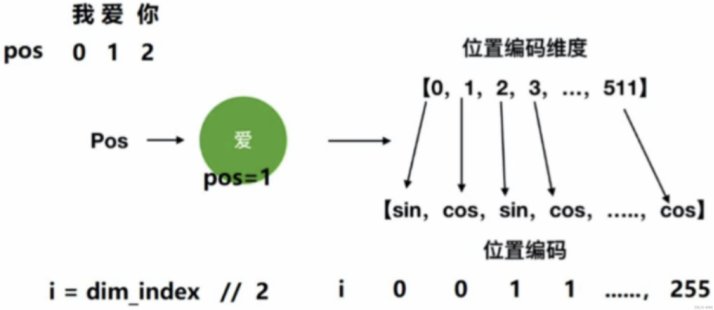
這樣,每個單詞都能有一個唯一的512維位置編碼,然后將其和Embedding相加:
注:單個的位置只能表示絕對位置信息!然后由于三角函數的特性,他們之間還可以表現出相對位置信息,具體分析如下:
3)為什么位置嵌入是有用的?
因為借助三角函數的性質,可以表現出單詞與單詞之間的相對位置信息。

如上圖所示,位置為:pos+k的單詞可以分別用位置為pos和k的來計算出來,這樣就表現出相對位置信息了。
4)為什么使用sin 和 cos?
1.sin cos 函數是無限延長的,適合單詞序列的長短變化
2.sin cos 是具有周期性的,pos + k的單詞可以分別用位置為pos和k的來計算出來
1.2 多頭注意力(作者使用8個頭)
以下是注意力機制的公式:
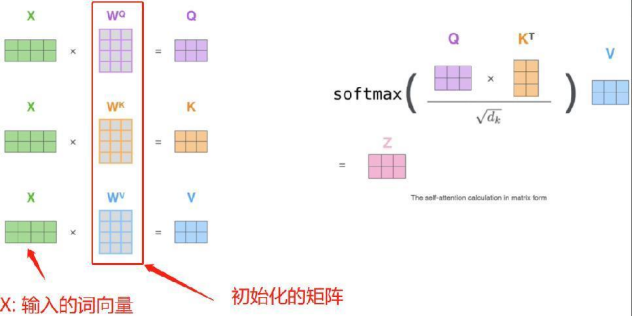
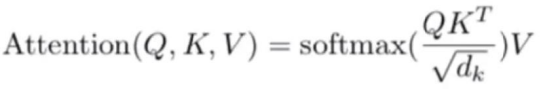 其中Q,K,V分別是有輸入詞向量和初始化生成的三個矩陣相乘得來的,dk表示詞向量維度,如上面的512。計算過程如下所示:
其中Q,K,V分別是有輸入詞向量和初始化生成的三個矩陣相乘得來的,dk表示詞向量維度,如上面的512。計算過程如下所示:
多頭注意力機制,則表示使用多套不同的WQ,WK,WV去求注意力,如下圖所示:
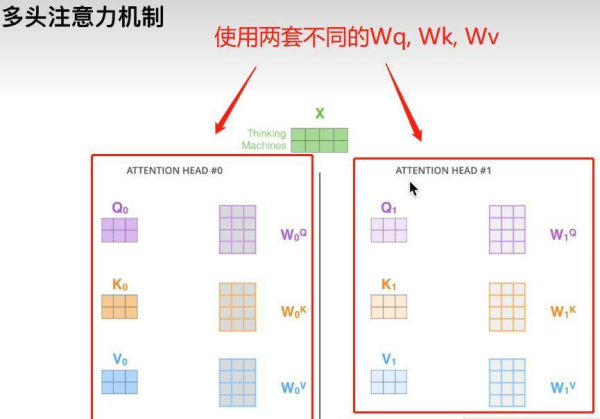
每個頭最后經公式都會得出一個注意力Z矩陣,將其合起來,即可得到多頭注意的輸出。
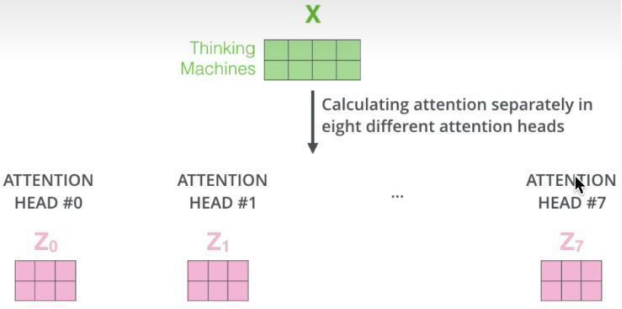
使用多頭注意力機制的目的在于:將原始信息映射到不同空間,保證可以捕捉到更多信息。
(1)為什么要除以根號dk?
①控制梯度大小:除以根號d可以控制注意力分數的大小,防止梯度爆炸問題。在內積操作中,兩個向量之間的相似度隨著向量維度的增加而增大,這可能導致梯度變得非常大,外面有還有Softmax,如果某一點太大,softmax會讓那一點更趨近于1,而其他點則更趨近于0,從而影響訓練的穩定性。通過除以根號d,可以使注意力分數的范圍相對穩定,從而減輕梯度爆炸的問題。
②平衡不同維度的注意力權重:在注意力機制中,注意力分數的大小會影響不同鍵的重要性。通過除以根號d,可以確保不同維度的注意力權重在計算時有更平衡的影響,避免某些維度過大而影響模型的性能。
(2)為什么除以的數值是根號下dk,而不是其他數值?
因為q和k是兩個獨立(而非相同)的隨機變量, 假設兩個輸入向量 q 和 k 的每一維都具有零均值和單位方差、并且假設每一維都互相獨立,那么這個除 sqrt(dk)的操作可以使得運算結果仍然保持零均值和單位方差,因而有利于模型訓練的穩定性。
1.3 殘差和LayerNorm
多頭注意力后就會進行殘差連接和LayerNorm,如下圖所示:
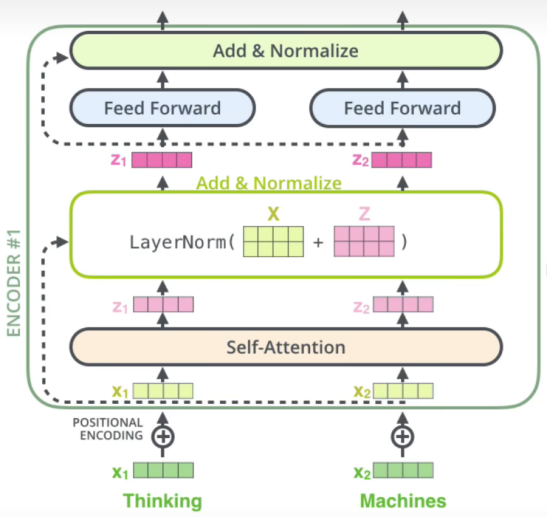
(1)殘差連接為什么有用?
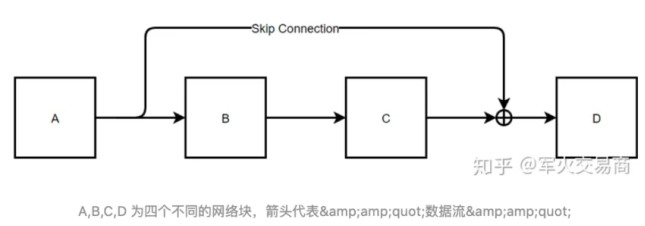
如上圖,表示一個殘差網絡結構圖,在進行反向傳播時,有如下推導:
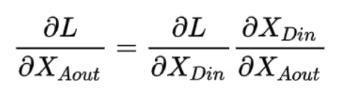
而有:
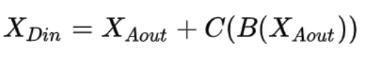
所以:
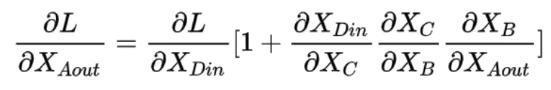
由式子可知,即使后面的連乘接近0,由于前面有個1,所以導數不會為0,這就是殘差網絡能很深的原因,因為殘差網絡緩解了梯度消失。
(2)BatchNorm的優缺點和使用場景
BatchNorm的計算可以參考:pytorch中對BatchNorm2d()函數的理解
BN的理解重點在于它是針對整個Batch中的樣本在同一維度特征做處理!!!如下圖所示:
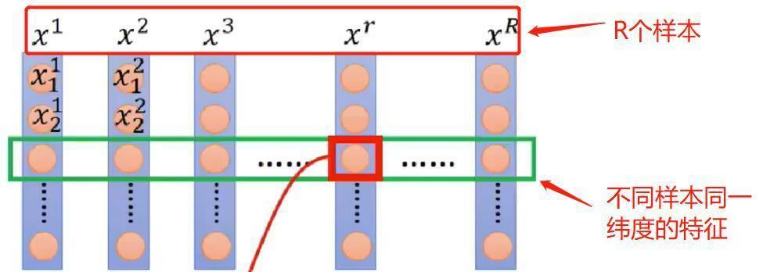
x 1 、 x 2 , ? ? ? , x R x^1、x^2,···,x^R x1、x2,???,xR 表示R個樣本,BatchNorm是作用在不同樣本同一維度上的。
1)BN的優點
①解決內部協變量偏移
簡單來說,在訓練過程中,各樣本之間可能分布不同,增大了學習難度,BN通過對各樣本同一維度進行歸一化緩解了這個問題。也有說,BN使損失平面更加更滑,從而加快收斂。
②緩解了梯度飽和問題,加快收斂。
2)BN的缺點
①batch_size較小時,效果較差
BN的過程,使用整個batch中樣本的均值和方差來模擬全部數據的均值和方差,在batch_size 較小的時候,效果肯定不好。
②對文本這種輸入維度不一致的不友好
如圖所示:
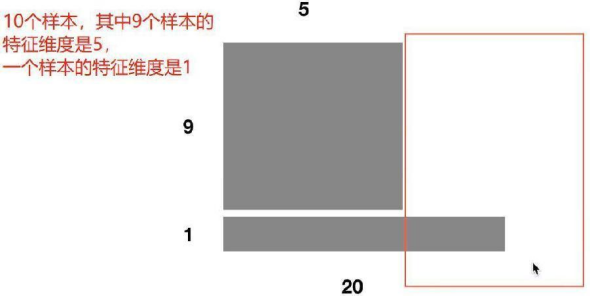
舉個最簡單的例子,比如 batch_size 為10,也就是我有10個樣本,其中9個樣本長度為5,第10個樣本長度為20。
那么問題來了,前五個單詞的均值和方差都可以在這個batch中求出來從而模型真實均值和方差。但是第6個單詞到底20個單詞怎么辦?
只用這一個樣本進行模型的話,不就是回到了第一點,batch太小,導致效果很差。
3)BN的使用場景
BN在MLP和CNN上使用的效果較好,在RNN這種動態文本模型上使用的比較差。
為啥BN在NLP中效果差:
BN的使用場景不適合RNN這種動態文本模型,有一個原因是因為batch中的長度不一致,導致有的靠后面的特征的均值和方差不能估算。
這個問題其實不是個大問題,可以緩解。我們可以在數據處理的時候,使句子長度相近的在一個batch,就可以了。所以這不是為啥NLP不用BN的核心原因。
BN在MLP中的應用,BN是對每個特征在batch_size上求的均值和方差。記住,是每個特征。比如說身高,比如說體重等等。這些特征都有明確的含義。
但是我們想象一下,如果BN應用到NLP任務中,對應的是對什么做處理?是對每一個單詞!也就是說,我現在的每一個單詞是對應到了MLP中的每一個特征。也就是默認了在同一個位置的單詞對應的是同一種特征,比如:“我/愛/中國/共產黨”和“今天/天氣/真/不錯”
如何使用BN,代表著認為 "我"和“今天”是對應的同一個維度特征,這樣才可以去做BN。
大家想一下,這樣做BN,會有效果嗎?
不會有效果的,每個單詞表達的特征是不一樣的,所以按照位置對單詞特征進行縮放,是違背直覺的。
(3)LayerNorm在Transformer中的應用
layner-norm 的特點是什么?layner-norm 做的是針對每一個樣本,做特征的縮放。換句話講,保留了N維度,在C/H/W維度上做縮放。
也就是,它認為“我/愛/中國/共產黨”這四個詞在同一個特征之下,所以基于此而做歸一化。
這樣做,和BN的區別在于,一句話中的每個單詞都可以歸到一個名字叫做“語義信息”的一個特征中(我自己瞎起的名字,大家懂就好),也就是說,layner-norm也是在對同一個特征下的元素做歸一化,只不過這里不再是對應N(或者說batch size),而是對應的文本長度。
上面這個解釋,有一個細節點,就是,為什么每個單詞都可以歸到“語義信息”這個特征中。大家這么想,如果讓你表達一個句子的語義信息,你怎么做?
最簡單的方法就是詞語向量的加權求和來表示句子向量,這一點沒問題吧。(當然你也可以自己基于自己的任務去訓練語義向量,這里只是說最直覺的辦法)。
1.4 Decoder部分
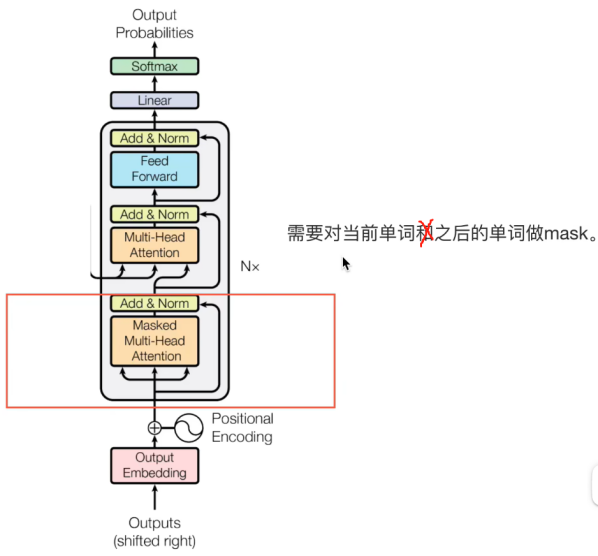
需要對當前時刻之后的信息進行musk,那么為什么需要mask呢?
(1)為什么需要mask?
需要提前知道的是:
在訓練過程,Output(Shifted right) 表示的是GroundTruth;
在test過程,Output(Shifted right) 表示之前自己預測的序列。
這里探討的是訓練過程為什么需要Mask?
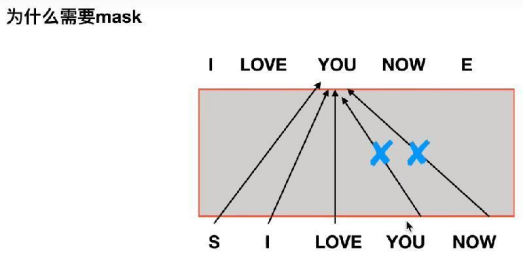
我的理解是,當我們的需要翻譯是句子是:
“我現在愛你”,其Label為:“I LOVE YOU NOW”.
當前時刻是已經預測了“I LOVE”, 正在預測“YOU”。此時我們就需要把Label中的“YOU NOW”給mask掉。
其原因就是在推理時,是沒有Label的,所以我們要訓練和推理過程之間沒有gap,才能得到較好的結果。
而mask就是將從代碼角度講,就是把當前時刻之后所有單詞mask掉就好了。
(2)decoder部分(和Encoder交互的部分)的輸入
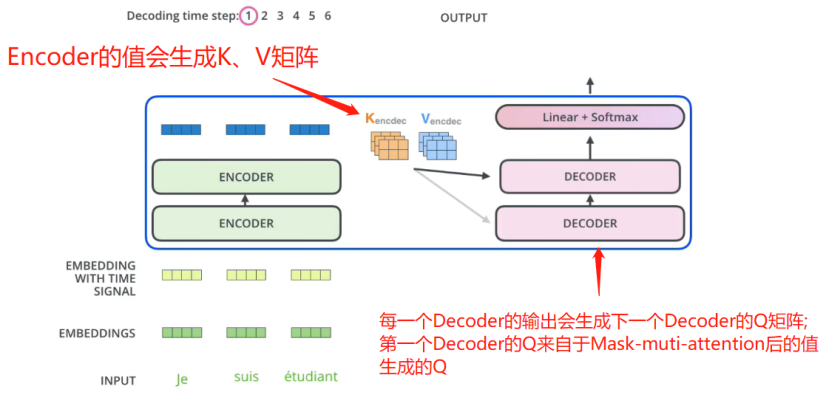
如上圖所示,每個Encoder會接受Q,K,V矩陣,其中,K,V來自與Encoder,Q來自與上一個Decoder.
之后就沒什么好講了。但需要明白的是:
在訓練過程,Output(Shifted right) 表示的是GroundTruth;
在test過程,Output(Shifted right) 表示之前自己預測的序列。
2.Transformer經典問題
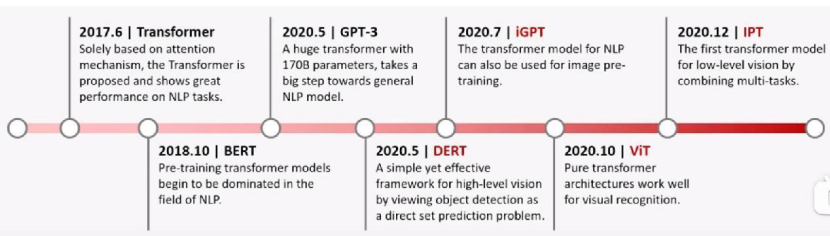
基于Transformer經典模型的發家史:
2.1 tranformer為何使用多頭注意力機制?
(1)多頭保證了transformer可以注意到不同子空間的信息,捕捉到更加豐富的特征信息。
(2)每個并行計算注意力權重,提高計算效率(參數總量和總計算量沒有減少)
(3)由于多頭注意力機制能夠從多個角度學習輸入數據的特征,它有助于提高模型的泛化能力,使其能夠更好地處理未見過的數據或任務。
(4)在自然語言處理中,句子中的詞語往往與距離較遠的其他詞語存在依賴關系。多頭注意力機制允許模型在不同的頭中關注序列的不同部分,從而更有效地捕獲這些長距離依賴。
2.2 Transformer相比CNN的優缺點

CNN感受野相對更小,所以需要搭建很多層CNN,才能注意到全局信息。而transformer的全局感受能力更強。
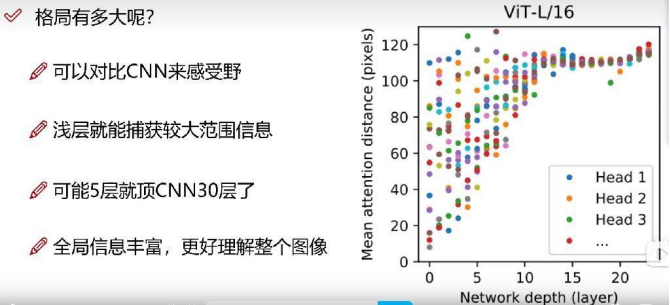
Transformer全局信息更加豐富,僅用幾層就能達到很大的感受野。
2.3 Encoder和decoder的區別?兩者感受野是否一致?
(1)Encoder只有一個Multi-Head Attention層,而Decoder有兩個,且Decoder的第一個Multi-Head Attention采用了mash操作;
(2)decoder第二個 Multi-Head Attention 層的K, V矩陣使用 Encoder 的編碼信息矩陣C進行計算,而Q使用上一個 Decoder block 的輸出計算。
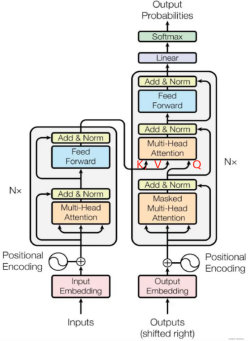
(3)功能性來說:encoder的功能是將輸入序列編碼成高維表示;而Decoder則將高維表示轉化為目標序列,方便下游任務;
(4)感受野: Encoder的感受野是輸入序列中某個位置的上下文信息;而Decoder同時關注輸入序列和已生成的序列。
本文完結,撒花!
歡迎交流討論!


—— SpeechRecognition)










)





