萬字長文警告!!!
目錄
一、離線計算與流式計算
1.1 離線計算
1.1.1 離線計算的特點
1.1.2 離線計算的應用場景
1.1.3 離線計算代表技術
1.2 流式計算
1.2.1 流式計算的特點
1.2.2 流式計算的應用場景
1.2.3 流式計算的代表技術
二、Spark Streaming
2.1?什么是Spark Streaming
2.2 Spark Streaming的基本原理
2.3?Spark?Streaming的數據抽象
2.4?Spark Streaming與Storm的對比
2.4.1 什么是Storm
2.4.2?Spark Streaming與Storm的對比
2.4.3?從“Hadoop+Storm”架構轉向Spark架構
三、DStream操作概述
3.1?Spark Streaming工作機制
3.2?Spark Streaming程序的基本步驟
3.3?創建StreamingContext對象
四、基本輸入源
4.1?文件流
4.1.1?在pyspark中創建文件流
4.1.2?采用獨立應用程序方式創建文件流
4.2?套接字流
4.2.1?Socket工作原理
4.2.2?使用套接字流作為數據源
4.2.3?使用Socket編程實現自定義數據源
4.3?RDD隊列流
五、高級數據源
5.1?Kafka簡介
5.2?Kafka術語
5.3?Kafka消息隊列
5.4?Kafka核心API
5.5?Kafka準備工作
5.5.1?安裝Kafka
5.5.2 啟動Kafka
5.5.3 測試Kafka是否正常工作
5.6?Spark準備工作
5.6.1 添加相關jar包
5.6.2 修改Spark配置文件
5.7?編寫Spark Streaming程序使用Kafka數據源
六、轉換操作
6.1 DStream無狀態轉換操作
6.2?DStream有狀態轉換操作
6.2.1?滑動窗口轉換操作
6.2.2?updateStateByKey操作
七、輸出操作
7.1?把DStream輸出到文本文件中
7.2?把DStream寫入到MySQL數據庫中
一、離線計算與流式計算
1.1 離線計算
離線計算是指在數據處理和分析中,數據不是實時或即時處理的,而是先被收集和存儲起來,然后按照預定的時間間隔或基于特定事件觸發進行批量處理的過程。離線計算通常用于處理大數據,因為它允許系統在處理之前累積大量數據,從而提高數據處理的效率和準確性。
1.1.1 離線計算的特點
-
批量處理:離線計算通常涉及對大量數據的批量處理,而不是對單個數據記錄的即時響應。
-
時間間隔:數據處理按照一定的時間間隔進行,如每小時、每天或每周等。
-
資源利用:離線計算可以在計算資源非高峰時段執行,從而更有效地利用硬件資源。
-
容錯性:由于數據處理是批量進行的,離線計算通常具有更好的容錯性,因為錯誤或失敗可以在整個批次結束時進行處理。
-
復雜計算:離線計算可以執行更復雜的數據分析和機器學習算法,因為它們不需要即時響應。
1.1.2 離線計算的應用場景
-
數據分析:對歷史數據進行深入分析,生成報告和洞察。
-
數據倉庫:構建和管理數據倉庫,支持企業決策。
-
機器學習訓練:訓練機器學習模型,通常需要大量數據和計算資源。
-
數據備份和歸檔:定期備份重要數據,并將其歸檔到長期存儲中。
-
數據清洗和轉換:對收集的數據進行清洗、轉換和標準化,以便于分析。
1.1.3 離線計算代表技術
Sqoop批量導入數據、HDFS批量存儲數據、MapReduce批量計算數據、Hive批量計算數據
-
Sqoop: Apache Sqoop是一個用于在Hadoop和結構化數據存儲(如關系型數據庫)之間高效傳輸大量數據的工具。它主要用于兩個方向的數據遷移:
- Import:從關系型數據庫批量導入數據到Hadoop的HDFS(Hadoop Distributed File System)中。
- Export:將Hadoop HDFS中的數據批量導出到關系型數據庫中。
-
HDFS (Hadoop Distributed File System): HDFS是Hadoop的核心組件之一,它是一個高度可靠的分布式文件系統,設計用于存儲大量數據,并支持在廉價硬件上運行。HDFS允許批量存儲數據,它將文件分割成多個塊,并跨不同的節點存儲這些塊的副本,從而提供高吞吐量的數據訪問。
-
MapReduce: Apache MapReduce是一個分布式計算模型和編程范式,用于在Hadoop上進行批量計算。它通過兩個主要階段來處理數據:
- Map階段:處理輸入數據并生成鍵值對(key-value pairs)。
- Reduce階段:對Map階段的輸出進行匯總和歸納,生成最終結果。
MapReduce允許用戶編寫可以在分布式環境中并行運行的應用程序,以處理和分析大規模數據集。
-
Hive: Apache Hive是建立在Hadoop之上的一個數據倉庫工具,它提供了一個類似于SQL的查詢語言(HiveQL),用于在Hadoop上執行批量計算。Hive允許用戶執行以下操作:
- 創建、修改和管理存儲在HDFS或Hadoop兼容文件系統(如Amazon S3)中的大數據集。
- 執行批量數據查詢,這些查詢會被轉換成MapReduce作業來執行。
通過Hive,用戶可以無需編寫復雜的MapReduce代碼,就能進行數據匯總、查詢和分析。
1.2 流式計算
流計算是一種數據處理模式,它可以處理無限流式數據,而不是一次性處理一組固定大小的數據集。在流計算中,數據是持續產生和處理的,系統可以實時地對數據進行處理、分析和響應。這種處理方式對于需要及時反饋和實時決策的應用場景非常有用,如實時監控、實時分析、實時推薦等。流計算秉承一個基本理念,即數據的價值隨著時間的流逝而降低!
即:實時獲取來自不同數據源的海量數據,經過實時分析處理,獲得有價值的信息
1.2.1 流式計算的特點
-
實時性:流式計算能夠實時處理數據,通常在數據生成后不久就進行處理和分析。
-
連續性:數據被視為連續的流,而不是離散的批次。
-
無界性:與批處理不同,流式計算不假設數據集有明確的開始和結束。
-
容錯性:流式計算系統通常設計為容錯,即使在部分組件失敗的情況下也能繼續處理數據。
-
可伸縮性:流式計算框架能夠水平擴展以處理數據量的增減。
-
低延遲:流式計算系統旨在減少數據處理的延遲,快速產生結果。
-
窗口操作:流式計算通常涉及窗口操作,允許對數據的滑動窗口或固定窗口進行操作。
1.2.2 流式計算的應用場景
-
實時分析:如實時監控網絡流量、用戶行為分析等。
-
事件驅動系統:如股票交易平臺、在線廣告投放系統等。
-
物聯網(IoT):處理來自傳感器的實時數據流。
-
實時推薦系統:根據用戶行為實時更新推薦列表。
-
實時數據處理和監控:如日志處理、實時儀表板更新等。
1.2.3 流式計算的代表技術
Flume實時獲取數據、Kafka實時數據存儲、Storm/JStorm實時數據計算、Spark Streaming實時數據計算、Redis實時結果緩存、mysql持久化存儲
-
Flume:
用于實時數據獲取。Flume是Apache軟件基金會下的頂級項目,是一個分布式、可靠且可用的系統,用于有效收集、聚合和移動大量日志數據。它從各種源(如日志文件、網絡連接、消息隊列等)捕獲數據,并將數據傳輸到中央數據存儲系統。 -
Kafka:
用于實時數據存儲。Apache Kafka是一個分布式流處理平臺,主要用于構建實時數據管道和流式應用程序。它能夠高效地處理高吞吐量的數據,并支持消息發布和訂閱模型。Kafka充當消息隊列,可以存儲和傳輸這些數據,同時提供數據緩沖和流量控制。 -
Storm/JStorm:
用于實時數據計算。Apache Storm是一個開源的實時計算系統,適用于處理無限數據流的實時數據處理場景。JStorm是Storm的一個Java版本,它提供了更低的延遲和更高的吞吐量。這些系統可以對Kafka中的數據進行實時處理和分析。 -
Spark Streaming:
用于實時數據計算。Spark Streaming是Apache Spark項目的一個組件,它通過將數據流分割成一系列小批次,然后使用Spark的核心引擎對這些批次數據進行處理,從而實現了對數據流的批處理。 -
Redis:
用于實時結果緩存。Redis是一個開源的內存數據結構存儲系統,它可以用作數據庫、緩存和消息代理。在實時數據處理中,Redis常用于緩存計算結果,因為它提供極高的讀寫速度。 -
MySQL:
用于持久化存儲。MySQL是一個關系型數據庫管理系統(RDBMS),廣泛用于持久化存儲結構化數據。在實時數據處理架構中,MySQL可以用于存儲經過實時處理和分析后的數據,以便于后續的查詢、分析和報告。
流處理系統與傳統的數據處理系統有如下不同:
- 流處理系統處理的是實時的數據,而傳統的數據處理系統處理的是預先存儲好的靜態數據
- 用戶通過流處理系統獲取的是實時結果,而通過傳統的數據處理系統,獲取的是過去某一時刻的結果
- 流處理系統無需用戶主動發出查詢,實時查詢服務可以主動將實時結果推送給用戶
流計算的處理流程一般包含三個階段:數據實時采集、數據實時計算、實時查詢服務

二、Spark Streaming
2.1?什么是Spark Streaming
讓我們把視線移到官方文檔概述:
Spark Streaming 是核心 Spark API 的擴展,可實現縮放、高吞吐量、 實時數據流的容錯流處理。可以從多個來源引入數據,例如Kafka、Kinesis 或 TCP 套接字,并且可以使用復雜的高級函數表示的算法,如map,?reduce,?join和window.?最后,處理后的數據可以推送到文件系統、數據庫和實時儀表板。

一言以蔽之:Spark Streaming是構建在Spark上的實時計算框架

2.2 Spark Streaming的基本原理
Spark Streaming的基本原理是將實時輸入數據流以時間片(秒級)為單位進行拆分,然后經Spark引擎以類似批處理的方式處理每個時間片數據

2.3?Spark?Streaming的數據抽象
Spark Streaming最主要的抽象是DStream(Discretized Stream,離散化數據流),表示連續不斷的數據流。

在內部實現上,Spark Streaming的輸入數據按照時間片(如1秒)分成一段一段,每一段數據轉換為Spark中的RDD,這些分段就是Dstream,并且對DStream的操作都最終轉變為對相應的RDD的操作
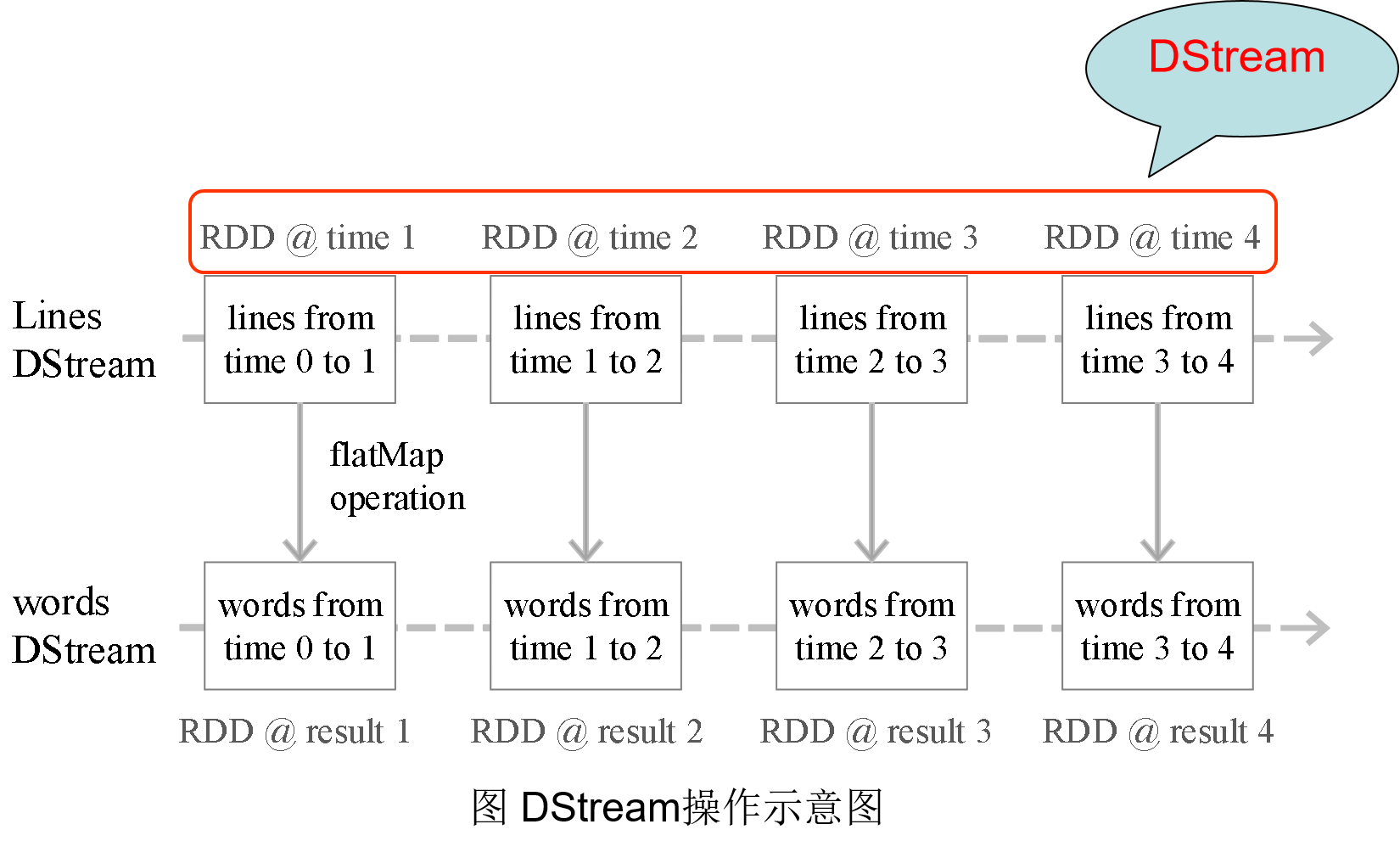
2.4?Spark Streaming與Storm的對比
2.4.1 什么是Storm
Apache Storm是一個開源的分布式實時計算系統,主要用于處理高吞吐量的數據流。它由Nathan Marz于2010年創建,并在2011年成為Twitter的一個開源項目。Storm的設計目標是能夠提供高可靠性、可擴展性以及容錯性,同時保證數據的準確性。
2.4.2?Spark Streaming與Storm的對比
- Spark Streaming和Storm最大的區別在于,Spark Streaming無法實現毫秒級的流計算,而Storm可以實現毫秒級響應
- Spark Streaming構建在Spark上,一方面是因為Spark的低延遲執行引擎(100ms+)可以用于實時計算,另一方面,相比于Storm,RDD數據集更容易做高效的容錯處理
- Spark Streaming采用的小批量處理的方式使得它可以同時兼容批量和實時數據處理的邏輯和算法,因此,方便了一些需要歷史數據和實時數據聯合分析的特定應用場合

2.4.3?從“Hadoop+Storm”架構轉向Spark架構


三、DStream操作概述
3.1?Spark Streaming工作機制

- 在Spark Streaming中,會有一個組件Receiver(接收數據),作為一個長期運行的task跑在一個Executor上
- 每個Receiver都會負責一個input DStream(比如從文件中讀取數據的文件流,比如套接字流,或者從Kafka中讀取的一個輸入流等等)
- Spark Streaming通過input DStream與外部數據源進行連接,讀取相關數據
3.2?Spark Streaming程序的基本步驟
- 1.通過創建輸入DStream來定義輸入源
- 通過對DStream應用轉換操作和輸出操作來定義流計算
- 用streamingContext.start()來開始接收數據和處理流程
- 通過streamingContext.awaitTermination()方法來等待處理結束(手動結束或因為錯誤而結束)
- 可以通過streamingContext.stop()來手動結束流計算進程
3.3?創建StreamingContext對象
如果要運行一個Spark Streaming程序,就需要首先生成一個StreamingContext對象,它是Spark Streaming程序的主入口,可以通過以下兩種方式其一進行創建:
- 通過SparkConf對象創建一個StreamingContext對象:
val ssc= new StreamingContext(conf,Durations.seconds(5)) - 在pyspark中通過SparkContext對象創建:
>>> from pyspark.streaming import StreamingContext >>> ssc = StreamingContext(sc, 1)
如果是編寫一個獨立的Spark Streaming程序,而不是在pyspark中運行,則需要通過如下方式創建StreamingContext對象:
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
conf = SparkConf()
conf.setAppName('TestDStream')
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 1)解釋:初始化一個 Spark 應用程序和一個 Spark Streaming 上下文,為接下來的實時數據流處理做準備
-
from pyspark import SparkContext, SparkConf: 導入?SparkContext 和 SparkConf 類,它們是 PySpark 中用于配置和管理 Spark 應用程序的關鍵類。 -
from pyspark.streaming import StreamingContext: 導入了StreamingContext 類,該類是 PySpark 中用于創建和管理實時流處理的主要類。 -
conf = SparkConf(): 創建一個 SparkConf 對象,用于配置 Spark 應用程序的屬性。 -
conf.setAppName('TestDStream'): 設置?Spark 應用程序的名稱為 "TestDStream"。應用程序名稱是在 Spark UI 中顯示的標識符。 -
conf.setMaster('local[2]'): 設置?Spark 應用程序的運行模式為本地模式,使用了兩個工作線程。本地模式是指應用程序將在本地計算機上運行,而不是在集群上運行。 -
sc = SparkContext(conf=conf): 創建一個 SparkContext 對象,使用之前創建的 SparkConf 對象來初始化。 -
ssc = StreamingContext(sc, 1): 創建一個 StreamingContext 對象,使用之前創建的 SparkContext 對象,并設置了批處理間隔為 1 秒。意味著 Spark Streaming 將每秒處理一次輸入數據流。
四、基本輸入源
4.1?文件流
4.1.1?在pyspark中創建文件流
mkdir -p sparksj/mycode/streaming/logfile
cd sparksj/mycode/streaming/logfile
進入pyspark創建文件流,打開一個終端窗口,啟動進入pyspark
# 導入 SparkContext 類
>>> from pyspark import SparkContext# 導入 StreamingContext 類
>>> from pyspark.streaming import StreamingContext# 使用 SparkContext 對象創建 StreamingContext 對象,設置批處理間隔為10秒
>>> ssc = StreamingContext(sc, 10)# 從文件系統中讀取文本文件流,文件路徑為 'file:///home/hadoop/sparksj/mycode/streaming/logfile'
>>> lines = ssc.textFileStream('file:///home/hadoop/sparksj/mycode/streaming/logfile')# 將每行文本按空格拆分成單詞
>>> words = lines.flatMap(lambda line: line.split(' '))# 對每個單詞進行映射為 (單詞, 1) 的鍵值對,然后根據鍵(單詞)進行聚合統計
>>> wordCounts = words.map(lambda x: (x, 1)).reduceByKey(lambda a, b: a + b)# 打印每個時間間隔內計算出的單詞統計結果
>>> wordCounts.pprint()# 啟動流式計算,開始接收數據并處理
>>> ssc.start()# 等待流式處理終止(手動或由于任何錯誤)
>>> ssc.awaitTermination()
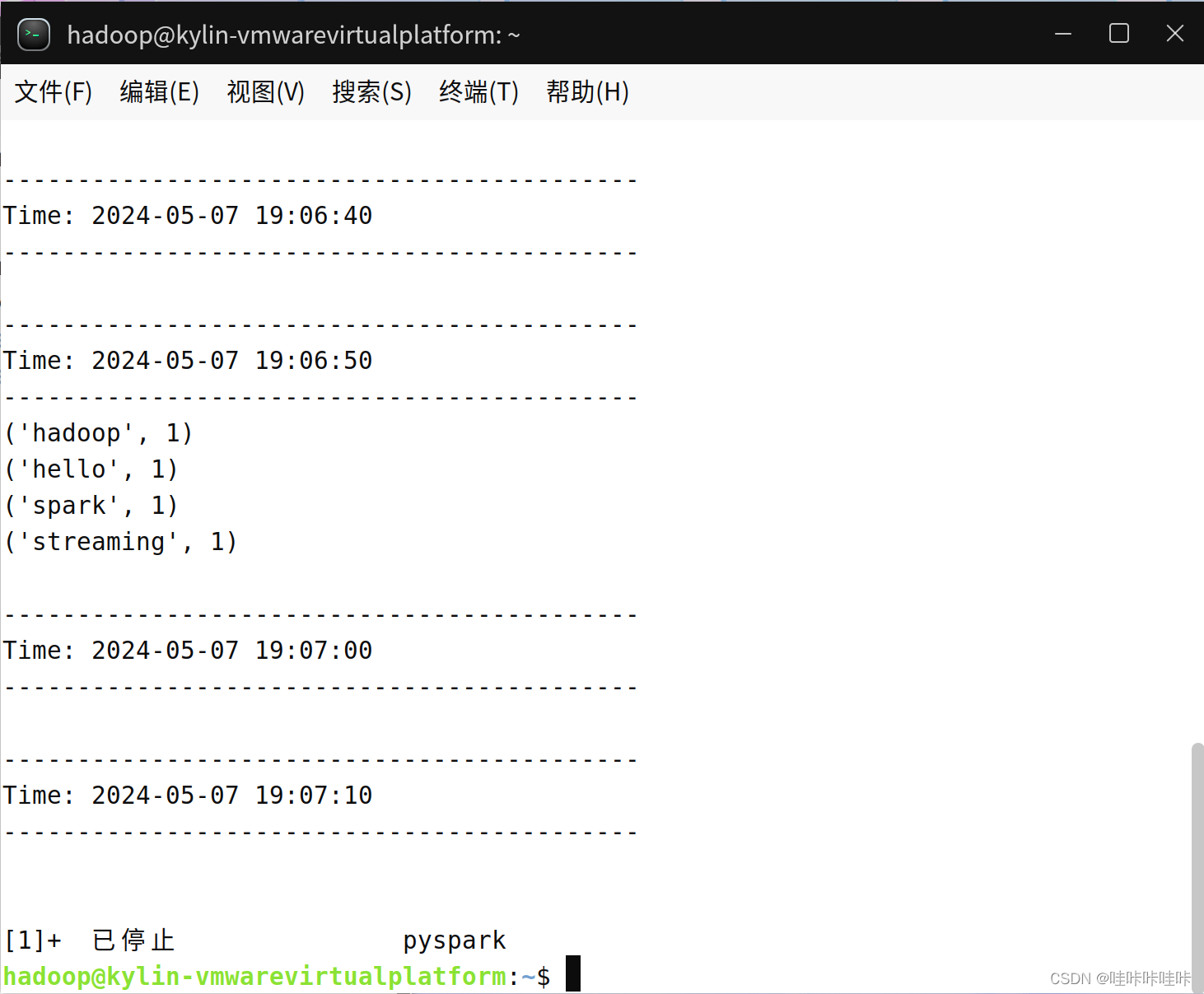
上面在pyspark中執行的程序,一旦你輸入ssc.start()以后,程序就開始自動進入循環監聽狀態,屏幕上會顯示一堆的信息,如下:
保持上述窗口正常運行(切勿關閉,保持打開狀態),在"/home/hadoop/sparksj/mycode/streaming/logfile"目錄下新建一個log.txt文件(文件名任意),就可以在監聽窗口中顯示詞頻統計結果:


如果讀者手速沒有那么快,因為屏幕上不斷輸出新的信息,導致讀者無法看清楚單詞統計結果是否已經被打印到屏幕上。所以現在必須停止這個監聽程序,否則它一直在pyspark窗口中不斷循環監聽,停止的方法是,按鍵盤Ctrl+Z,或者Ctrl+C。停止以后,就徹底停止,并且退出了pyspark狀態,回到了Shell命令提示符狀態。然后,讀者就可以看到屏幕上,在一大堆輸出信息中,可以找到打印出來的單詞統計信息。
!!!注意:
- 監聽程序只監聽"/home/hadoop/sparksj/mycode/streaming/logfile"目錄下在程序啟動后新增的文件,不會去處理歷史上已經存在的文件
- 處理后,對當前窗口中的文件所做的更改不會導致重新讀取該文件。 也就是說:更新將被忽略
4.1.2?采用獨立應用程序方式創建文件流
cd sparksj/mycode/streaming/logfile
vim FileStreaming.pyfrom pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContextconf = SparkConf()
conf.setAppName('TestDStream')
conf.setMaster('local[2]')
sc = SparkContext(conf = conf)
ssc = StreamingContext(sc, 10)
lines = ssc.textFileStream('file:///home/hadoop/sparksj/mycode/streaming/logfile')
words = lines.flatMap(lambda line: line.split(' '))
wordCounts = words.map(lambda x : (x,1)).reduceByKey(lambda a,b:a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
執行如下代碼啟動流計算(筆者已配置spark的環境變量,故無需進入spark安裝目錄執行"spark-submit FileStreaming.py"命令,若讀者未配置環境變量可執行以下命令運行(以spark安裝路徑為/usr/local/spark為例):"/usr/local/spark/bin/spark-submit FileStreaming.py"):
cd sparksj/mycode/streaming/logfile
spark-submit FileStreaming.py文件內容與運行結果如下(同理,要停止監聽按Ctrl+Z):

4.2?套接字流
Spark Streaming可以通過Socket端口監聽并接收數據,然后進行相應處理
4.2.1?Socket工作原理

TCP是一種面向連接的、可靠的、基于字節流的傳輸層通信協議。Socket是一種通信端點,它允許兩個設備上的程序通過網絡進行通信。以下是TCP服務器端和客戶端通過Socket建立和結束連接的步驟:
-
服務器端創建Socket(socket()):服務器首先需要創建一個Socket,這是通信的起點。
-
服務器端綁定(bind()):服務器將Socket綁定到一個IP地址和端口號上,這樣客戶端才能知道通過哪個地址和端口與服務器通信。
-
服務器監聽(listen()):服務器開始監聽綁定的端口,等待客戶端的連接請求。
-
客戶端創建Socket(socket()):客戶端也需要創建一個Socket。
-
客戶端連接(connect()):客戶端使用服務器的IP地址和端口號發起連接請求。
-
服務器接受連接(accept()):服務器接收到客戶端的連接請求后,通過
accept方法接受連接,此時TCP連接建立。 -
建立連接后的數據交換:
- 服務器向客戶端請求數據(write()):服務器可以向客戶端發送數據。
- 客戶端讀取數據(read()):客戶端讀取服務器發送的數據。
- 客戶端處理請求:客戶端對收到的數據進行處理。
- 客戶端回應數據(write()):客戶端可以向服務器發送響應數據。
- 服務器讀取數據(read()):服務器讀取客戶端發送的響應數據。
-
結束連接:
- 服務器關閉Socket(close()):服務器完成數據交換后,關閉Socket。
- 客戶端讀取剩余數據(read()):客戶端可能需要讀取服務器發送的任何剩余數據。
- 客戶端關閉Socket(close()):客戶端也關閉Socket,至此,TCP連接正式關閉。
這個過程也描述了TCP三次握手的過程,包括連接建立、數據傳輸和連接終止。三次握手確保了連接的可靠性,允許數據在客戶端和服務器之間安全地傳輸。
4.2.2?使用套接字流作為數據源
cd sparksj/mycode/streaming
mkdir socket
cd socket
vim NetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContextif __name__ == "__main__":# 檢查命令行參數是否正確if len(sys.argv) != 3:print("Usage: NetworkWordCount.py <hostname> <port>", file=sys.stderr)exit(-1)# 創建一個 SparkContext 對象,并設置應用程序名稱sc = SparkContext(appName="PythonStreamingNetworkWordCount")# 創建一個 StreamingContext 對象,設置批處理間隔為1秒ssc = StreamingContext(sc, 1)# 從指定的主機和端口創建一個文本套接字流lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))# 對每行文本按空格進行拆分,并映射為 (word, 1) 的鍵值對,然后根據鍵進行聚合統計counts = lines.flatMap(lambda line: line.split(" ")) \.map(lambda word: (word, 1)) \.reduceByKey(lambda a, b: a+b)# 打印每個時間間隔內計算出的單詞統計結果counts.pprint()# 啟動流式計算ssc.start()# 等待流式處理終止ssc.awaitTermination()

新打開一個窗口作為nc窗口,啟動nc程序:
nc -lk 9999再新建一個終端(記作“流計算終端”),執行如下代碼啟動流計算:
cd sparksj/mycode/streaming/socket
spark-submit NetworkWordCount.py localhost 9999可以在nc窗口中隨意輸入一些單詞,監聽窗口就會自動獲得單詞數據流信息,在監聽窗口每隔1秒(可自行設置"ssc = StreamingContext(sc, 1)",筆者在此設置的5秒以便輸入和查看)就會打印出詞頻統計信息,大概會在屏幕上出現類似如下的結果:

4.2.3?使用Socket編程實現自定義數據源
把數據源頭的產生方式修改一下,不要使用nc程序,而是采用自己編寫的程序產生Socket數據源:
cd sparksj/mycode/streaming/socket
vim DataSourceSocket.py
import socket
# 生成socket對象
server = socket.socket()
# 綁定ip和端口
server.bind(('localhost', 9999))
# 監聽綁定的端口
server.listen(1)
while 1:# 為了方便識別,打印一個“我在等待”print("我在等待連接...")# 這里用兩個值接受,因為連接上之后使用的是客戶端發來請求的這個實例# 所以下面的傳輸要使用conn實例操作conn,addr = server.accept()# 打印連接成功print("連接成功! 連接來自于 %s " % addr[0])# 打印正在發送數據print('正在發送數據...')conn.send('I love hadoop I love spark hadoop is good spark is fast'.encode())conn.close()print('連接關閉.')
執行如下命令啟動Socket服務端,啟動Socket服務端:
cd sparksj/mycode/streaming/socket
spark-submit DataSourceSocket.py
啟動客戶端,即?4.2.2?中的NetworkWordCount程序。新建一個終端(記作“流計算終端”),輸入以下命令啟動NetworkWordCount程序:
cd sparksj/mycode/streaming/socket
spark-submit NetworkWordCount.py localhost 9999

若運行時遇到端口號被占用的問題可參考:端口被其他進程占用:OSError: [Errno 98] Address already in use-CSDN博客
4.3?RDD隊列流
在調試Spark Streaming應用程序的時候,我們可以使用streamingContext.queueStream(queueOfRDD)創建基于RDD隊列的DStream
新建一個RDDQueueStream.py代碼文件,功能是:每隔1秒創建一個RDD,Streaming每隔2秒就對數據進行處理
cd /home/hadoop/sparksj/mycode/streaming
mkdir rddqueue
cd rddqueue
vim RDDQueueStream.py
# 導入所需的庫:time 用于延遲,SparkContext 用于創建 Spark 上下文,StreamingContext 用于創建 Spark 流上下文
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext# 創建 Spark 上下文 sc,并為應用程序命名 PythonStreamingQueueStream
# 創建一個流上下文 ssc,并指定批次間隔為 2 秒
if __name__ == "__main__":sc = SparkContext(appName="PythonStreamingQueueStream")ssc = StreamingContext(sc, 2)# 創建一個隊列,通過該隊列可以把RDD推給一個RDD隊列流# 初始化一個空的 RDD 隊列 rddQueue# 循環創建 5 個 RDD,每個 RDD 包含從 1 到 1000 的整數,并將這些 RDD 添加到 rddQueue 中# "parallelize([j for j in range(1, 1001)], 10)" 表示將 1000 個整數分成 10 個分區進行并行處理rddQueue = []for i in range(5):rddQueue += [ssc.sparkContext.parallelize([j for j in range(1, 1001)], 10)]time.sleep(1) # 在每次循環中,延遲 1 秒#創建一個RDD隊列流inputStream = ssc.queueStream(rddQueue) # 使用 queueStream 方法創建一個基于 rddQueue 的隊列流 inputStreammappedStream = inputStream.map(lambda x: (x % 10, 1)) # 對 inputStream 進行映射操作,創建一個鍵值對,其中鍵是 x % 10,值是 1。這一步將每個元素按它除以 10 的余數分組reducedStream = mappedStream.reduceByKey(lambda a, b: a + b) # 對 mappedStream 進行 reduceByKey 操作,將每個鍵對應的值相加。這一步按鍵聚合,將同樣的鍵的值相加reducedStream.pprint() # 打印 reducedStream 的輸出結果ssc.start() # 啟動流上下文 sscssc.stop(stopSparkContext=True, stopGraceFully=True) # 停止流上下文 ssc,并選擇關閉 Spark 上下文,同時確保以良好的方式停止(stopGraceFully=True)

cd sparksj/mycode/streaming/rddqueue
spark-submit RDDQueueStream.py
五、高級數據源
本節提醒:
根據官方文檔所述:Kafka 項目在 0.8 和 0.10 版本之間引入了一個新的使用者 API,因此有 2 個單獨的對應 Spark 流式處理包可用。0.8 集成與更高版本的 0.9 和 0.10 代理兼容,但 0.10 集成與早期的代理不兼容。
從 Spark 2.3.0 開始,不推薦使用 Kafka 0.8 支持。

故筆者建議使用新的api或降低pyspark版本來完成Spark Streaming程序使用Kafka數據源,在此筆者不過多贅述,有興趣的讀者可以查看以下資料與官方文檔:
No module named 'pyspark.streaming.kafka' - 木葉流云 - 博客園 (cnblogs.com)
Spark Streaming + Kafka Integration Guide - Spark 2.4.7 Documentation (apache.org)
Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher) - Spark 3.5.1 Documentation (apache.org)
基于PySpark整合Spark Streaming與Kafka_pyspark 集成kafka-CSDN博客
5.1?Kafka簡介
- Kafka基于 Zookeeper 的分布式消息流平臺,它同時也是一款開源的基于發布訂閱模式的消息引擎系統。
- Kafka可以同時滿足在線實時處理和批量離線處理
- Kafka可以通過Kafka Connect連接到外部系統(用于數據輸入/輸出),并提供了Kafka Streams——一個Java流式處理庫。
- 在公司的大數據生態系統中,可以把Kafka作為數據交換樞紐,不同類型的分布式系統(關系數據庫、NoSQL數據庫、流處理系統、批處理系統等),可以統一接入到Kafka,實現和Hadoop各個組件之間的不同類型數據的實時高效交換

5.2?Kafka術語
- Broker:Kafka集群包含一個或多個服務器,這種服務器被稱為broker 進行數據存儲
- Topic(主題):每條發布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然保存于一個或多個broker上,但用戶只需指定消息的Topic即可生產或消費數據而不必關心數據存于何處)
- Partition(分區):每個topic中的消息會被分為若干個partition,以提高消息的處理速度還有就是容錯能力
- Producer(消息生產者):負責發布消息到Kafka broker
- Consumer(消息消費者):消息消費者,向Kafka broker讀取消息的客戶端
- Consumer Group(消費者群組):每個Consumer屬于一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬于默認的group)

Kafka的運行依賴于Zookeeper。Topic、Consumer、Patition、Broker等注冊信息都存儲在ZooKeeper中。
5.3?Kafka消息隊列
Kafka的消息隊列分為兩種:
點對點模式(生產者的消息只由一個用戶來消費)

發布訂閱模式(一個生產者或者多個生產者對應一個或者多個消費者(消費者群組))

5.4?Kafka核心API

5.5?Kafka準備工作
5.5.1?安裝Kafka
安裝Kafka的步驟請參考:Ubuntu22.04下安裝kafka_2.12-2.6.0并運行簡單實例-CSDN博客
5.5.2 啟動Kafka
打開第一個終端,輸入下面命令啟動Zookeeper服務:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties千萬不要關閉這個終端窗口,一旦關閉,Zookeeper服務就停止了(Kafka工作運行完畢后不再使用時再關閉)

打開第二個終端,然后輸入下面命令啟動Kafka服務:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties千萬不要關閉這個終端窗口,一旦關閉,Kafka服務就停止了(Kafka工作運行完畢后不再使用時再關閉)

成功啟動所有服務后,讀者將擁有一個基本的 Kafka 環境,可供使用。
5.5.3 測試Kafka是否正常工作
主題(Topics)類似于文件系統中的文件夾,事件(events)是該文件夾中的文件。因此,在編寫第一個事件之前,必須創建一個主題。
再打開第三個終端,然后輸入下面命令創建一個自定義名稱為“wordsendertest”的Topic(主題):
cd /usr/local/kafka
# 創建一個名為 wordsendertest 的 Kafka 主題
./bin/kafka-topics.sh --create --topic wordsendertest --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
# 列出所有主題
./bin/kafka-topics.sh --list --bootstrap-server localhost:9092
# 描述特定主題的細節
./bin/kafka-topics.sh --describe --topic wordsendertest --bootstrap-server localhost:9092- kafka-topics.sh:?指定用于創建、列出和管理 Kafka 主題的腳本
- --create:表示創建一個新的主題
- --topic wordsendertest:指定要創建的主題名稱,這里是?wordsendertest
- --bootstrap-server localhost:9092:指定 Kafka 服務器的地址和端口。此處的localhost:9092表示本地的 Kafka 服務器,默認端口是9092
- --replication-factor 1:設置副本因子為 1,意味著數據只有一個副本(不容錯)
- --partitions 1:設置分區數為 1,意味著只有一個分區
- --describe:用于獲取某個主題的詳細信息

Kafka客戶端通過網絡與Kafka代理進行通信,以寫入(或讀取)事件。一旦收到事件,直到需要事件,代理程序都將以持久和容錯的方式存儲事件,甚至永遠。
下面用生產者(Producer)來產生一些數據,在主題中寫入一些事件。默認情況下,輸入的每一行都將導致一個單獨的事件寫入主題。請在第三個終端(記作“數據源終端”)內繼續輸入下面命令:
cd /usr/local/kafka
./bin/kafka-console-producer.sh --topic wordsendertest --bootstrap-server localhost:9092- kafka-console-producer.sh:這是 Kafka 提供的一個用于生產者的控制臺工具腳本
- --topic wordsendertest:指定要創建的主題名稱,這里是?wordsendertest
- --bootstrap-server localhost:9092:指定 Kafka 服務器的地址和端口。此處的localhost:9092表示本地的 Kafka 服務器,默認端口是9092
當執行這個命令后,控制臺會等待讀者輸入消息。每輸入一行消息,它就會將該消息發送到指定的主題中。讀者可以通過按下 Ctrl+C 來退出生產者控制臺。
上面命令執行后,就可以在當前終端內用鍵盤輸入一些英文單詞(也可以等消費者啟用后再輸入)
現在可以啟動一個消費者(Consumer),來查看剛才生產者產生的數據。請另外打開第四個終端,輸入下面命令:
cd /usr/local/kafka
./bin/kafka-console-consumer.sh --topic wordsendertest --from-beginning --bootstrap-server localhost:9092- kafka-console-consumer.sh:這是 Kafka 提供的一個用于消費者的控制臺工具腳本
- --topic wordsendertest:指定要創建的主題名稱,這里是?wordsendertest
- --from-beginning:?這個選項表示從該主題的起始位置開始消費消息。如果不指定這個選項,消費者將只會消費自啟動后發布的消息
- --bootstrap-server localhost:9092:指定 Kafka 服務器的地址和端口。此處的localhost:9092表示本地的 Kafka 服務器,默認端口是9092
執行這個命令后,控制臺將開始從 wordsendertest 主題中消費消息,并將其顯示在控制臺上。讀者可以通過按下 Ctrl+C 來退出消費者控制臺。
因為事件是持久存儲在Kafka中的,所以它們可以被任意多次讀取,也可以被任意多的消費者讀取。可以通過打開另一個終端會話并再次運行該命令來驗證這一點
? ?
?
-> 實例運行結束后可以Ctrl+Z或Ctrl+C停止進程 ~~~
5.6?Spark準備工作
5.6.1 添加相關jar包
Kafka和Flume等高級輸入源,需要依賴獨立的庫(jar文件),對于Spark 3.2.0版本,如果要使用Kafka,則需要下載spark-streaming-kafka-0-10_2.12-3.2.0.jar,現附上下載地址:
百度網盤下載地址:
鏈接:https://pan.baidu.com/s/121zVsgc4muSt9rgCWnJZmw?
提取碼:wkk6
官方下載地址:
Maven Repository: org.apache.spark ? spark-streaming-kafka-0-10_2.12 ? 3.2.0 (mvnrepository.com)

完成下載后將下載好的jar包放到虛擬機Ubuntu系統家目錄中的下載目錄下,放置好后接著進行以下操作:
cd /usr/local/spark/jars
mkdir kafka
cd ~/下載
cp ./spark-streaming-kafka-0-10_2.12-3.2.0.jar /usr/local/spark/jars/kafka繼續把Kafka安裝目錄的libs目錄下的所有jar文件復制到“/usr/local/spark/jars/kafka”目錄下:
cd /usr/local/kafka/libs
cp ./* /usr/local/spark/jars/kafka
5.6.2 修改Spark配置文件
cd /usr/local/spark/conf
vim spark-env.sh把Kafka相關jar包的路徑信息增加到spark-env.sh,修改后的spark-env.sh類似如下(請讀者依據自己的路徑進行配置):
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):$(/usr/local/hbase/bin/hbase classpath):/usr/local/spark/jars/hbase/*:/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
上述內容是在Spark 3.2.0使用Kafka數據源的基本思路,其他版本的Spark使用Kafka數據源基本思路亦是如此!!!
5.7?編寫Spark Streaming程序使用Kafka數據源
!!!正如本節開頭所述,0.10 集成與早期的代理不兼容,故使用Kafka數據源時會出現No module named 'pyspark.streaming.kafka'的報錯,讀者可以使用新的api或降低pyspark版本來實現Spark Streaming程序使用Kafka數據源,筆者在此不再顯示,只提供基本思路,讀者如有需要可參考本節開頭所給鏈接進行參考,見諒!!!
基本思路如下(Spark 2.4.0):
cd sparksj/mycode/streaming
mkdir kafka
cd kafka
vim KafkaWordCount.py
from __future__ import print_function # 使用 Python 3.x 的 print 函數特性import sys # 導入 sys 模塊,用于處理命令行參數
from pyspark import SparkContext # 導入 SparkContext 模塊
from pyspark.streaming import StreamingContext # 導入 StreamingContext 模塊
from pyspark.streaming.kafka import KafkaUtils # 導入 KafkaUtils 模塊,用于從 Kafka 中創建 DStreamif __name__ == "__main__":if len(sys.argv) != 3: # 檢查命令行參數數量是否正確print("Usage: KafkaWordCount.py <zk> <topic>", file=sys.stderr) # 打印使用說明exit(-1) # 退出程序sc = SparkContext(appName="PythonStreamingKafkaWordCount") # 創建 SparkContext,設置應用名ssc = StreamingContext(sc, 1) # 創建 StreamingContext,參數為 SparkContext 和批處理間隔(這里為1秒)zkQuorum, topic = sys.argv[1:] # 從命令行參數中獲取 ZooKeeper 地址和主題名kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1}) # 從 Kafka 中創建一個輸入數據流,參數分別為 StreamingContext、ZooKeeper 地址、消費者組、主題名和分區數量lines = kvs.map(lambda x: x[1]) # 將輸入數據流中的每個記錄轉換為其值(消息內容)counts = lines.flatMap(lambda line: line.split(" ")) \ # 將每個輸入行拆分為單詞,并轉換為 (word, 1) 鍵值對.map(lambda word: (word, 1)) \ # 將每個單詞映射為 (word, 1) 鍵值對.reduceByKey(lambda a, b: a+b) # 對相同鍵的值進行求和,即統計每個單詞的出現次數counts.pprint() # 打印每個批次的結果ssc.start() # 啟動 StreamingContextssc.awaitTermination() # 等待終止,直到手動終止或發生錯誤
?①打開第一個終端,輸入下面命令啟動Zookeeper服務:
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties千萬不要關閉這個終端窗口,一旦關閉,Zookeeper服務就停止了(Kafka工作運行完畢后不再使用時再關閉)
②打開第二個終端,然后輸入下面命令啟動Kafka服務:
cd /usr/local/kafka
./bin/kafka-server-start.sh config/server.properties千萬不要關閉這個終端窗口,一旦關閉,Kafka服務就停止了(Kafka工作運行完畢后不再使用時再關閉)
?③打開第三個終端(記作“數據源終端”)內輸入下面命令:
cd /usr/local/kafka
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic wordsendertest?④打開第四個終端(記作“流計算終端”),執行KafkaWordCount.py:
cd sparksj/mycode/streaming/kafka
spark-submit ./KafkaWordCount.py localhost:2181 wordsendertest時再切換到之前已經打開的“數據源終端”,用鍵盤手動敲入一些英文單詞
在流計算終端內就可以看到類似如下的詞頻統計動態結果:
-------------------------------------------
Time: 2024-5-10 10:40:42
-------------------------------------------
('hadoop', 1)
-------------------------------------------
Time: 2024-5-10 10:40:43
-------------------------------------------
('spark', 1)
六、轉換操作
6.1 DStream無狀態轉換操作
- map(func) :對源DStream的每個元素,采用func函數進行轉換,得到一個新的Dstream
- flatMap(func): 與map相似,但是每個輸入項可用被映射為0個或者多個輸出項
- filter(func): 返回一個新的DStream,僅包含源DStream中滿足函數func的項
- repartition(numPartitions): 通過創建更多或者更少的分區改變DStream的并行程度
- reduce(func):利用函數func聚集源DStream中每個RDD的元素,返回一個包含單元素RDDs的新DStream(相加)
- count():統計源DStream中每個RDD的元素數量
- union(otherStream): 返回一個新的DStream,包含源DStream和其他DStream的元素
- countByValue():應用于元素類型為K的DStream上,返回一個(K,V)鍵值對類型的新DStream,每個鍵的值是在原DStream的每個RDD中的出現次數
- reduceByKey(func, [numTasks]):當在一個由(K,V)鍵值對組成的DStream上執行該操作時,返回一個新的由(K,V)鍵值對組成的DStream,每一個key的值均由給定的recuce函數(func)聚集起來
- join(otherStream, [numTasks]):當應用于兩個DStream(一個包含(K,V)鍵值對,一個包含(K,W)鍵值對),返回一個包含(K, (V, W))鍵值對的新Dstream
- cogroup(otherStream, [numTasks]):當應用于兩個DStream(一個包含(K,V)鍵值對,一個包含(K,W)鍵值對),返回一個包含(K, Seq[V], Seq[W])的元組
- transform(func):通過對源DStream的每個RDD應用RDD-to-RDD函數,創建一個新的DStream。支持在新的DStream中做任何RDD操作
無狀態轉換操作實例: 之前“套接字流”部分介紹的詞頻統計,就是采用無狀態轉換,每次統計,都是只統計當前批次到達的單詞的詞頻,和之前批次無關,不會進行累計
- countByKey:根據key進行分組,統計每個分組下有多少個元素
- countByValue:根據value進行分組,統計相同value有多少個(會將列表中每一個元素看做是value)
>>> rdd1=sc.parallelize([('01','a'),('02','b'),('01','c')])
>>> rdd1.countByKey()
defaultdict(<class 'int'>, {'01': 2, '02': 1})
>>> rdd1.countByValue()
defaultdict(<class 'int'>, {('01', 'a'): 1, ('02', 'b'): 1, ('01', 'c'): 1})
>>> rdd2=sc.parallelize([1,2,1,4,4,5])
>>> rdd2.countByValue()
defaultdict(<class 'int'>, {1: 2, 2: 1, 4: 2, 5: 1})

- cogroup(otherStream, [numTasks]):當應用于兩個DStream(一個包含(K,V)鍵值對,一個包含(K,W)鍵值對),返回一個包含(K, Seq[V], Seq[W])的元組
>>> x=sc.parallelize([('a',1),('b',2),('a',3)])
>>> y=sc.parallelize([('a',2),('b',3),('b',5)])
>>> z=x.cogroup(y)
>>> z.collect()
[('a', (<pyspark.resultiterable.ResultIterable object at 0x7f6b02202e30>, <pyspark.resultiterable.ResultIterable object at 0x7f6b02202d70>)), ('b', (<pyspark.resultiterable.ResultIterable object at 0x7f6b02202c80>, <pyspark.resultiterable.ResultIterable object at 0x7f6af66c3be0>))]
>>> w=z.map(lambda x:(x[0],list(x[1][0]),list(x[1][1])))?? ??? ?#索引方式引用查看(x[0]:key,list(x[1][0]):value的第一個,list(x[1][1]):value的第二個)
>>> print(w.collect())
[('a', [1, 3], [2]), ('b', [2], [3, 5])]
>>> w.collect()
[('a', [1, 3], [2]), ('b', [2], [3, 5])]
6.2?DStream有狀態轉換操作
6.2.1?滑動窗口轉換操作
- 事先設定一個滑動窗口的長度(也就是窗口的持續時間)
- 設定滑動窗口的時間間隔(每隔多長時間執行一次計算),讓窗口按照指定時間間隔在源DStream上滑動
- 每次窗口停放的位置上,都會有一部分Dstream(或者一部分RDD)被框入窗口內,形成一個小段的Dstream
- 可以啟動對這個小段DStream的計算

一些窗口轉換操作的含義:
- window(windowLength, slideInterval):基于源DStream產生的窗口化的批數據,計算得到一個新的Dstream
- countByWindow(windowLength, slideInterval):返回流中元素的一個滑動窗口數
- reduceByWindow(func, windowLength, slideInterval):返回一個單元素流。利用函數func聚集滑動時間間隔的流的元素創建這個單元素流。函數func必須滿足結合律,從而可以支持并行計算
- countByValueAndWindow(windowLength, slideInterval, [numTasks]):當應用到一個(K,V)鍵值對組成的DStream上,返回一個由(K,V)鍵值對組成的新的DStream。每個key的值都是它們在滑動窗口中出現的頻率
- reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):應用到一個(K,V)鍵值對組成的DStream上時,會返回一個由(K,V)鍵值對組成的新的DStream。每一個key的值均由給定的reduce函數(func函數)進行聚合計算。注意:在默認情況下,這個算子利用了Spark默認的并發任務數去分組。可以通過numTasks參數的設置來指定不同的任務數
- reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]):更加高效的reduceByKeyAndWindow,每個窗口的reduce值,是基于先前窗口的reduce值進行增量計算得到的;它會對進入滑動窗口的新數據進行reduce操作,并對離開窗口的老數據進行“逆向reduce”操作。但是,只能用于“可逆reduce函數”,即那些reduce函數都有一個對應的“逆向reduce函數”(以InvFunc參數傳入)
下面來完成一個簡單的詞頻動態統計:
cd sparksj/mycode/streaming/dstream
vim WindowedNetworkWordCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContextif __name__ == "__main__":# 檢查命令行參數數量是否正確if len(sys.argv) != 3:print("Usage: WindowedNetworkWordCount.py <hostname> <port>", file=sys.stderr)exit(-1)# 創建 SparkContext 對象,設置應用程序名稱sc = SparkContext(appName="PythonStreamingWindowedNetworkWordCount")# 創建 StreamingContext 對象,設置批處理間隔為 10 秒ssc = StreamingContext(sc, 10)# 設置檢查點路徑,用于保存狀態信息,防止數據丟失ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpointwindow/checkpoint") # 創建一個從指定主機和端口接收數據的 DStream 對象lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))# 對接收到的數據進行處理:# 使用 flatMap 對每行文本進行單詞切分,并扁平化為一個單詞列表# 使用 map 將每個單詞映射為 (單詞, 1) 的鍵值對# 使用 reduceByKeyAndWindow 對窗口內的數據進行聚合操作,其中窗口長度為 30 秒,滑動間隔為 10 秒counts = lines.flatMap(lambda line: line.split(" "))\.map(lambda word: (word, 1))\.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)# 調用 pprint() 方法打印每個窗口的單詞計數結果counts.pprint()# 啟動流處理作業ssc.start()# 等待作業結束ssc.awaitTermination()
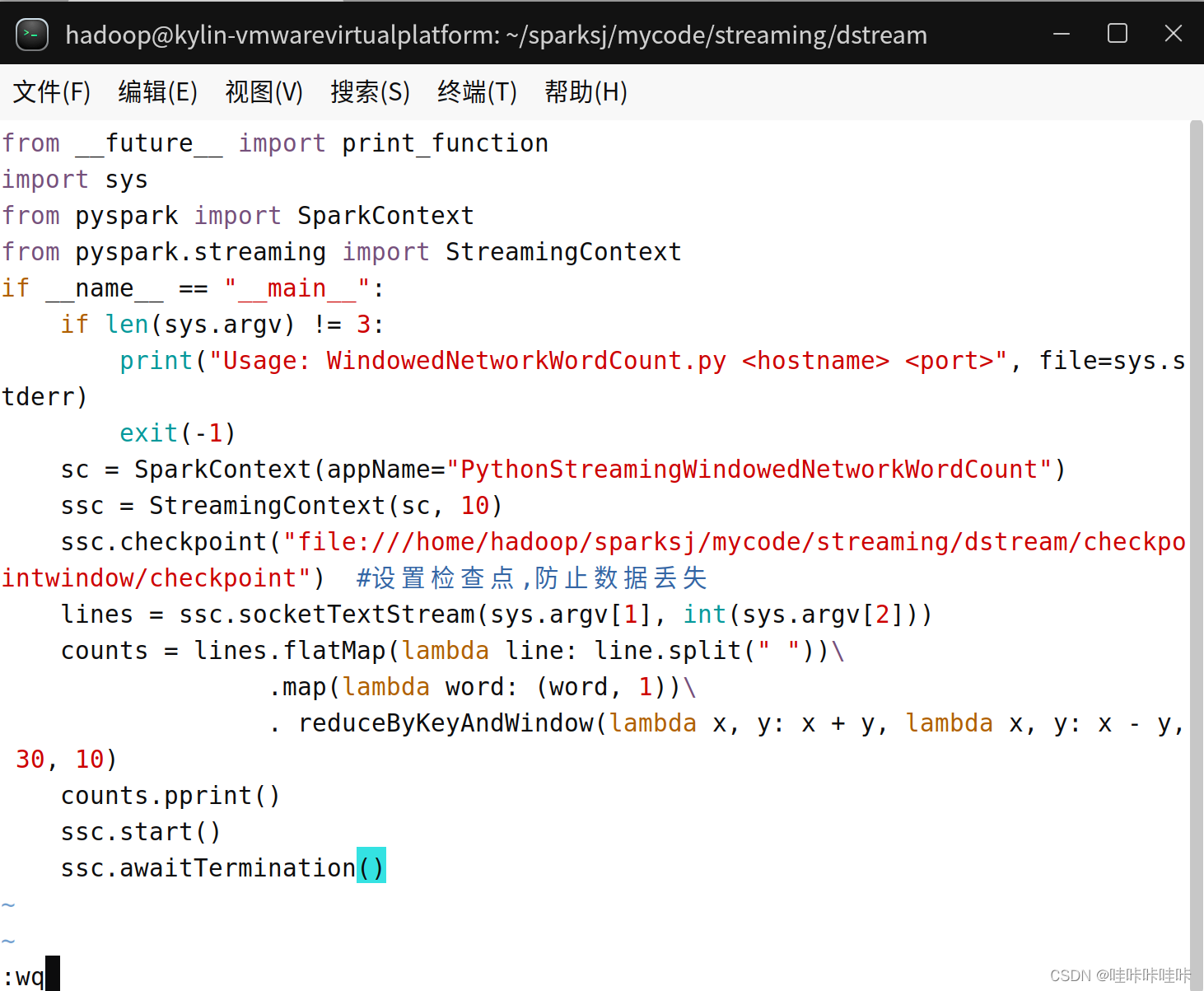
新建一個終端(記作“數據源終端”),執行如下命令運行nc程序:
nc -lk 9999再新建一個終端(記作“流計算終端”),運行客戶端程序WindowedNetworkWordCount.py:
cd sparksj/mycode/streaming/dstream
spark-submit WindowedNetworkWordCount.py localhost 9999
可以看到,隨著時間的流逝,詞頻統計結果會發生動態變化!!!
進入設置的檢查點目錄(/home/hadoop/sparksj/mycode/streaming/dstream/checkpointwindow/checkpoint)可以看到會出現很多文件

關鍵操作:

6.2.2?updateStateByKey操作
需要在跨批次之間維護狀態時,就必須使用updateStateByKey操作
詞頻統計實例:
對于有狀態轉換操作而言,本批次的詞頻統計,會在之前批次的詞頻統計結果的基礎上進行不斷累加,所以,最終統計得到的詞頻,是所有批次的單詞的總的詞頻統計結果
cd sparksj/mycode/streaming/dstream
vim NetworkWordCountStateful.py
from __future__ import print_functionimport sysfrom pyspark import SparkContext
from pyspark.streaming import StreamingContextif __name__ == "__main__":# 檢查命令行參數數量是否正確if len(sys.argv) != 3:print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr)exit(-1)# 創建 SparkContext 對象,并設置應用程序名稱sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")# 創建 StreamingContext 對象,并設置批處理間隔為 10 秒ssc = StreamingContext(sc, 10)# 設置檢查點路徑,用于保存狀態信息,防止數據丟失ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpoint")# 定義一個初始狀態的 RDD,包含 (key, value) 對initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])# 定義一個更新函數,用于更新狀態def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0)# 創建一個從指定主機和端口接收數據的 DStream 對象lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))# 對接收到的數據進行處理:# 使用 flatMap 對每行文本進行單詞切分,并扁平化為一個單詞列表# 使用 map 將每個單詞映射為 (單詞, 1) 的鍵值對# 使用 updateStateByKey 對狀態進行更新running_counts = lines.flatMap(lambda line: line.split(" "))\.map(lambda word: (word, 1))\.updateStateByKey(updateFunc, initialRDD=initialStateRDD)# 調用 pprint() 方法打印每個時間段內的計數結果running_counts.pprint()# 啟動流處理作業ssc.start()# 等待作業結束ssc.awaitTermination()

新建一個終端(記作“數據源終端”),執行如下命令啟動nc程序:
nc -lk 9999新建一個Linux終端(記作“流計算終端”),執行如下命令提交運行程序:
cd sparksj/mycode/streaming/dstream
spark-submit NetworkWordCountStateful.py localhost 9999
可以按Ctrl+C終止監聽或Ctrl+Z停止監聽
七、輸出操作
在Spark應用中,外部系統經常需要使用到Spark DStream處理后的數據,因此,需要采用輸出操作把DStream的數據輸出到數據庫或者文件系統中
7.1?把DStream輸出到文本文件中
編寫NetworkWordCountStatefulText.py實現把DStream輸出到文本文件中:
cd sparksj/mycode/streaming/dstream
vim NetworkWordCountStatefulText.py
from __future__ import print_function # 使 print 函數兼容 Python 2.ximport sys # 導入 sys 模塊,用于處理命令行參數from pyspark import SparkContext # 導入 SparkContext 類
from pyspark.streaming import StreamingContext # 導入 StreamingContext 類# 確保命令行參數數量正確
if __name__ == "__main__":if len(sys.argv) != 3:print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr)exit(-1)# 創建 SparkContext 對象,設置應用程序名稱為 "PythonStreamingStatefulNetworkWordCount"sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")# 創建 StreamingContext 對象,設置批處理間隔為 10 秒ssc = StreamingContext(sc, 10)# 設置檢查點目錄ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpointtotext/output")# 定義初始狀態 RDDinitialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])# 定義更新函數,用于更新狀態def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0)# 創建一個 DStream,從指定主機和端口接收文本數據流lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))# 對接收到的文本數據進行處理,將每行文本按空格拆分為單詞,并將每個單詞映射為 (word, 1) 的鍵值對# 然后使用 updateStateByKey 方法根據更新函數對狀態進行更新running_counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRDD)# 將結果保存到文件中running_counts.saveAsTextFiles("file:///home/hadoop/sparksj/mycode/streaming/dstream/totextoutput/output")# 在控制臺打印計數結果running_counts.pprint()# 啟動 StreamingContextssc.start()# 等待作業完成ssc.awaitTermination()
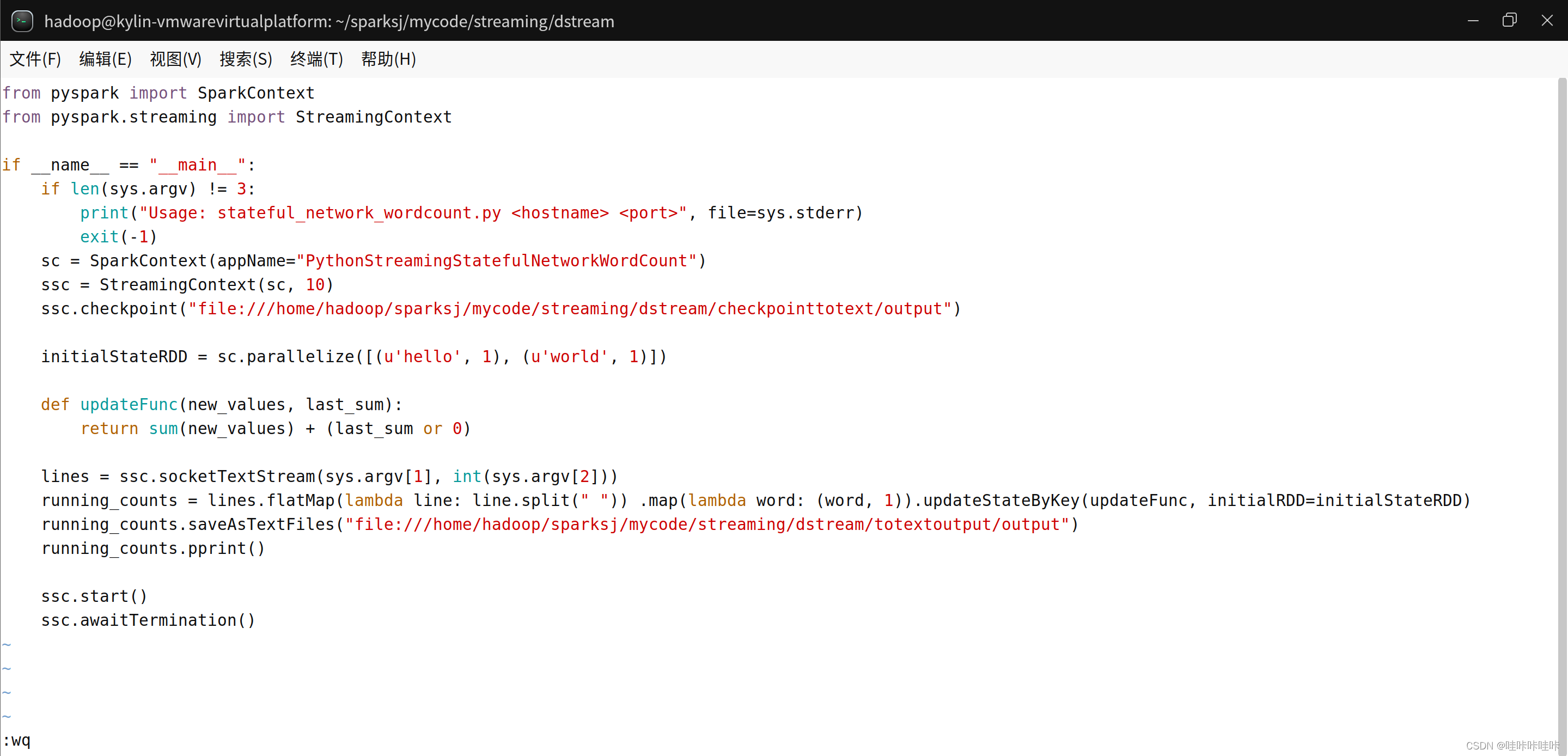
?新建一個終端(記作“數據源終端”),執行如下命令啟動nc程序:
nc -lk 9999新建一個Linux終端(記作“流計算終端”),執行如下命令提交運行程序:
cd sparksj/mycode/streaming/dstream
spark-submit NetworkWordCountStatefulText.py localhost 9999
可以進入結果保存目錄,查看每批次輸出的內容:

7.2?把DStream寫入到MySQL數據庫中
啟動MySQL數據庫:
service mysql start
mysql -u root -p創建數據庫與表:
create database spark;
use spark;
create table wordcount (word char(20), count int(4));
由于需要讓Python連接數據庫MySQL,所以,需要首先安裝Python連接MySQL的模塊PyMySQL,在Linux終端中執行如下命令:
sudo apt-get update
sudo apt-get install python3-pip
pip3 -V
sudo pip3 install PyMySQL筆者已經安裝過PyMySQL:

?編寫NetworkWordCountStatefulDB.py實現把DStream寫入到MySQL數據庫中:
cd sparksj/mycode/streaming/dstream
vim NetworkWordCountStatefulDB.pyfrom __future__ import print_function # 確保在 Python 2.x 中可以使用 print 函數import sys # 導入 sys 模塊,用于處理命令行參數
import pymysql # 導入 pymysql 模塊,用于連接 MySQL 數據庫
from pyspark import SparkContext # 導入 SparkContext 類
from pyspark.streaming import StreamingContext # 導入 StreamingContext 類if __name__ == "__main__":if len(sys.argv) != 3:print("Usage: stateful_network_wordcount.py <hostname> <port>", file=sys.stderr)exit(-1)# 創建 SparkContext 對象,設置應用程序名稱為 "PythonStreamingStatefulNetworkWordCount"sc = SparkContext(appName="PythonStreamingStatefulNetworkWordCount")# 創建 StreamingContext 對象,設置批處理間隔為 10 秒ssc = StreamingContext(sc, 10)# 設置檢查點目錄ssc.checkpoint("file:///home/hadoop/sparksj/mycode/streaming/dstream/checkpointdb")# 定義初始狀態 RDDinitialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])# 定義更新函數,用于更新狀態def updateFunc(new_values, last_sum):return sum(new_values) + (last_sum or 0)# 創建一個 DStream,從指定主機和端口接收文本數據流lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))# 對接收到的文本數據進行處理,將每行文本按空格拆分為單詞,并將每個單詞映射為 (word, 1) 的鍵值對# 然后使用 updateStateByKey 方法根據更新函數對狀態進行更新running_counts = lines.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).updateStateByKey(updateFunc, initialRDD=initialStateRDD)# 在控制臺打印計數結果running_counts.pprint()# 定義將結果寫入 MySQL 數據庫的函數def dbfunc(records):db = pymysql.connect(host='localhost', port=3306, user='root', passwd='123456', db='spark') # 連接 MySQL 數據庫cursor = db.cursor()# 定義執行插入操作的函數def doinsert(p):sql = "insert into wordcount(word,count) values (%s, %s)"try:cursor.execute(sql, (str(p[0]), p[1]))db.commit() # 提交事務except Exception as e:print("Error occurred:", e)db.rollback() # 回滾事務# 遍歷 RDD 中的每個元素,并執行插入操作for item in records:doinsert(item)cursor.close() # 關閉游標db.close() # 關閉數據庫連接# 定義將結果寫入數據庫的函數def func(rdd):repartitionedRDD = rdd.repartition(3) # 對 RDD 進行重新分區repartitionedRDD.foreachPartition(dbfunc) # 對每個分區應用 dbfunc 函數# 對計數結果應用寫入數據庫的函數running_counts.foreachRDD(func)# 啟動 StreamingContextssc.start()# 等待作業完成ssc.awaitTermination()
新建一個終端(記作“數據源終端”),執行如下命令啟動nc程序:
nc -lk 9999新建一個Linux終端(記作“流計算終端”),執行如下命令提交運行程序:
cd sparksj/mycode/streaming/dstream
spark-submit NetworkWordCountStatefulDB.py localhost 9999
foreachPartition 操作的介紹:
foreachPartition是Spark中的一個操作,它可以對RDD或DataFrame中的每個分區執行自定義的操作。它接收一個函數作為參數,該函數將作用于每個分區的迭代器上。foreachPartition操作通常用于對每個分區執行一些特定的計算或數據寫入等操作。使用foreachPartition操作時,可以在每個分區上進行批量操作,提高作業的性能。
關于RDD分區函數mapPartitions與foreachPartition解析可以參考:
RDD分區函數mapPartitions與foreachPartition解析_mappartions foreachpartition-CSDN博客文章瀏覽閱讀337次。總結: 建議在使用map和foreach的時候, 建議更換mapPartitions和foreachPartition, 尤其是在函數中存在一些與資源相關的操作, 比如說 數據庫的連接, IO操作。演示 foreach和foreachPartition函數。非分區函數: 作用在每個分區的每一個元素上。分區函數: 作用在每一個分區上。_mappartions foreachpartitionhttps://blog.csdn.net/manba_yqq/article/details/130882461


)











![[c++]多態的分析](http://pic.xiahunao.cn/[c++]多態的分析)

)


