博主介紹:?全網粉絲50W+,前互聯網大廠軟件研發、集結碩博英豪成立軟件開發工作室,專注于計算機相關專業項目實戰6年之久,累計開發項目作品上萬套。憑借豐富的經驗與專業實力,已幫助成千上萬的學生順利畢業,選擇我們,就是選擇放心、選擇安心畢業?
> 🍅想要獲取完整文章或者源碼,或者代做,拉到文章底部即可與我聯系了。🍅點擊查看作者主頁,了解更多項目!
🍅感興趣的可以先收藏起來,點贊、關注不迷路,大家在畢設選題,項目以及論文編寫等相關問題都可以給我留言咨詢,希望幫助同學們順利畢業?。🍅
1、畢業設計:2025年計算機專業畢業設計選題匯總(建議收藏)?
2、最全計算機專業畢業設計選題大全(建議收藏)?
1、項目介紹
技術棧:
python語言、Flask框架、Tensorflow深度學習、LSTM神經網絡算法股票價格預測、scikit-learn機器學習、東方財富、Echarts可視化、HTML
2、項目界面
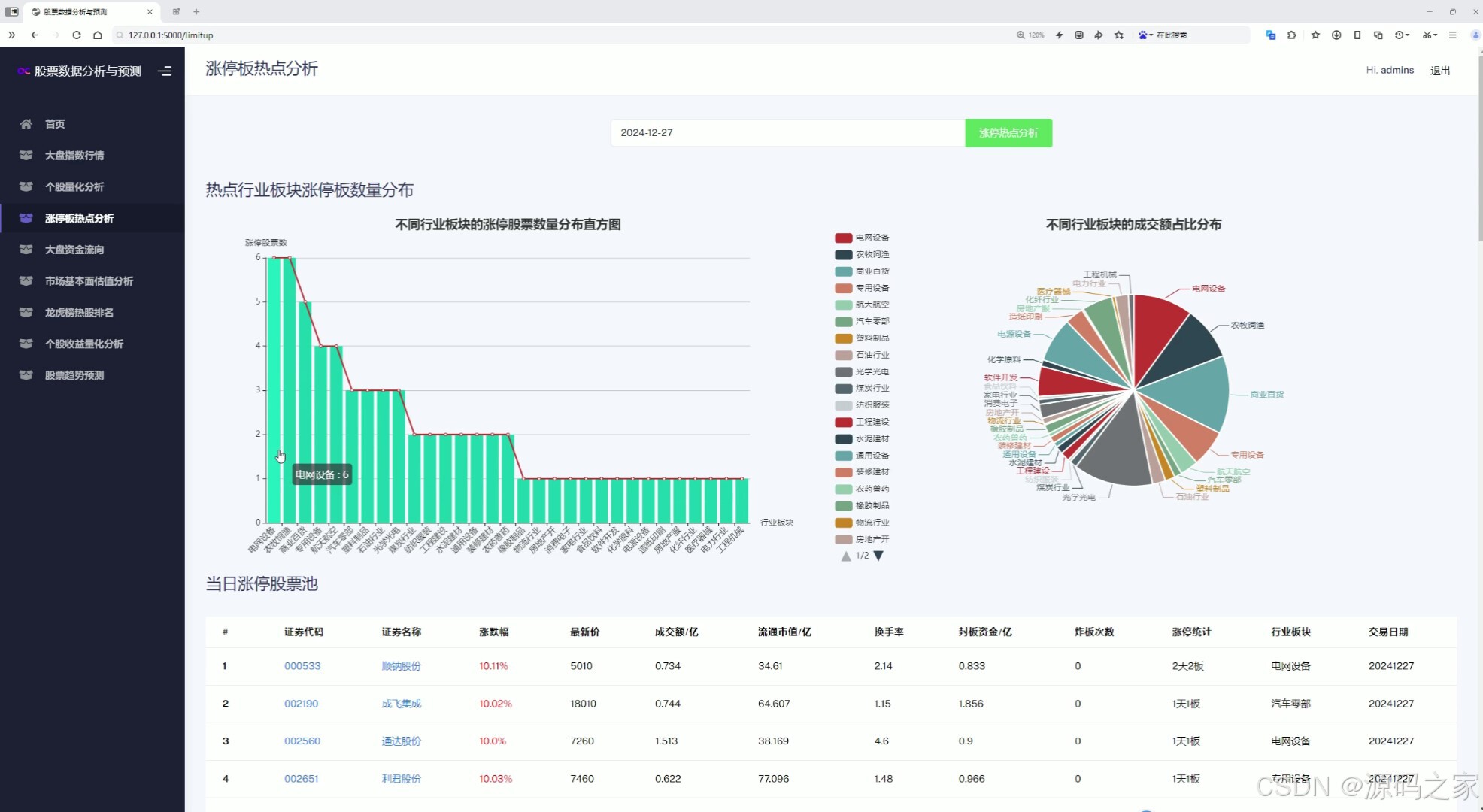
(1)漲停板熱點分析—熱點行業板塊漲停板數量分布直方圖、不同行業板塊的成交額占比分布、當日漲停股票池
(2)首頁—功能模塊介紹
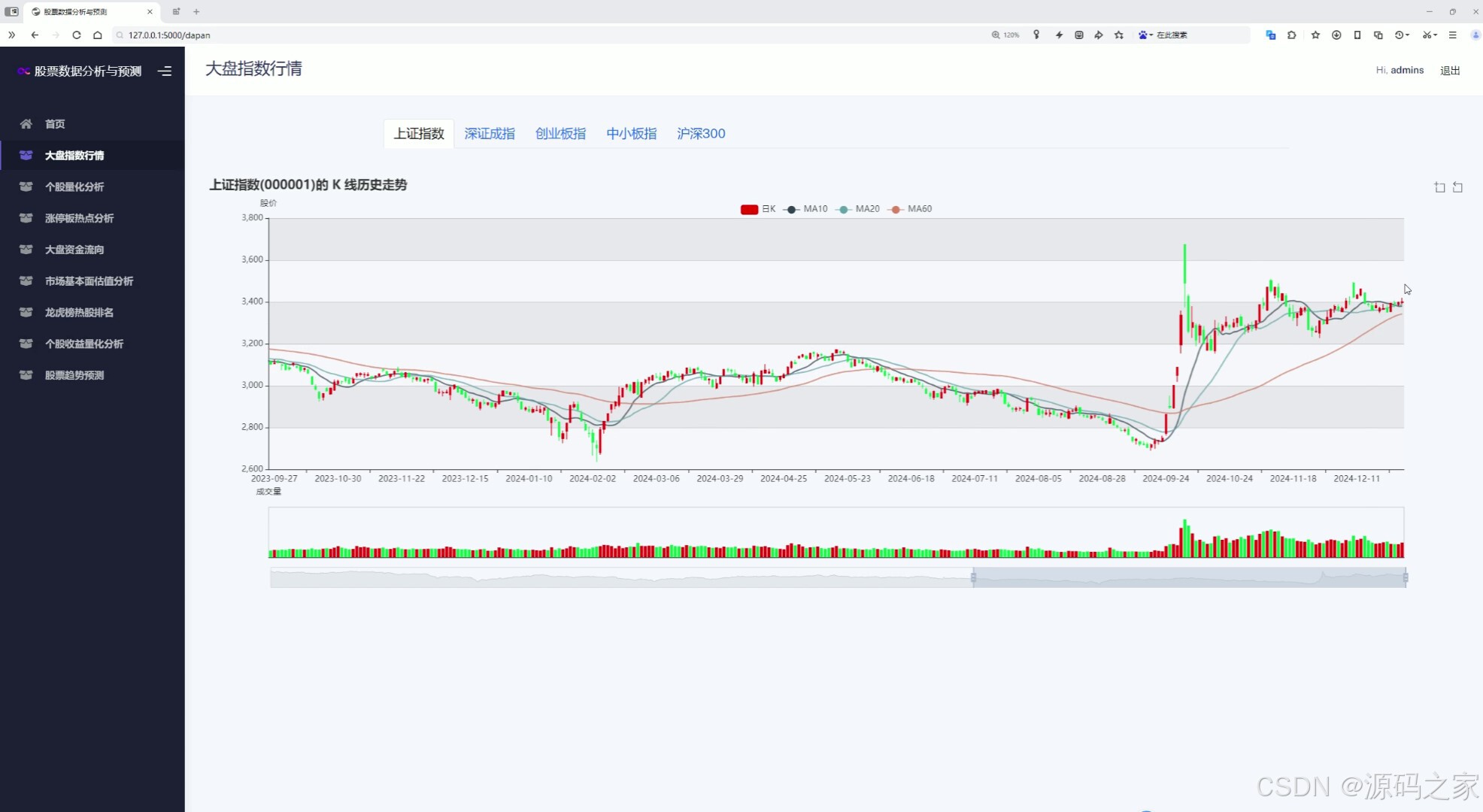
(3)大盤指數行情分析—上證、深證、創業板、中小指、滬深300指數K線圖
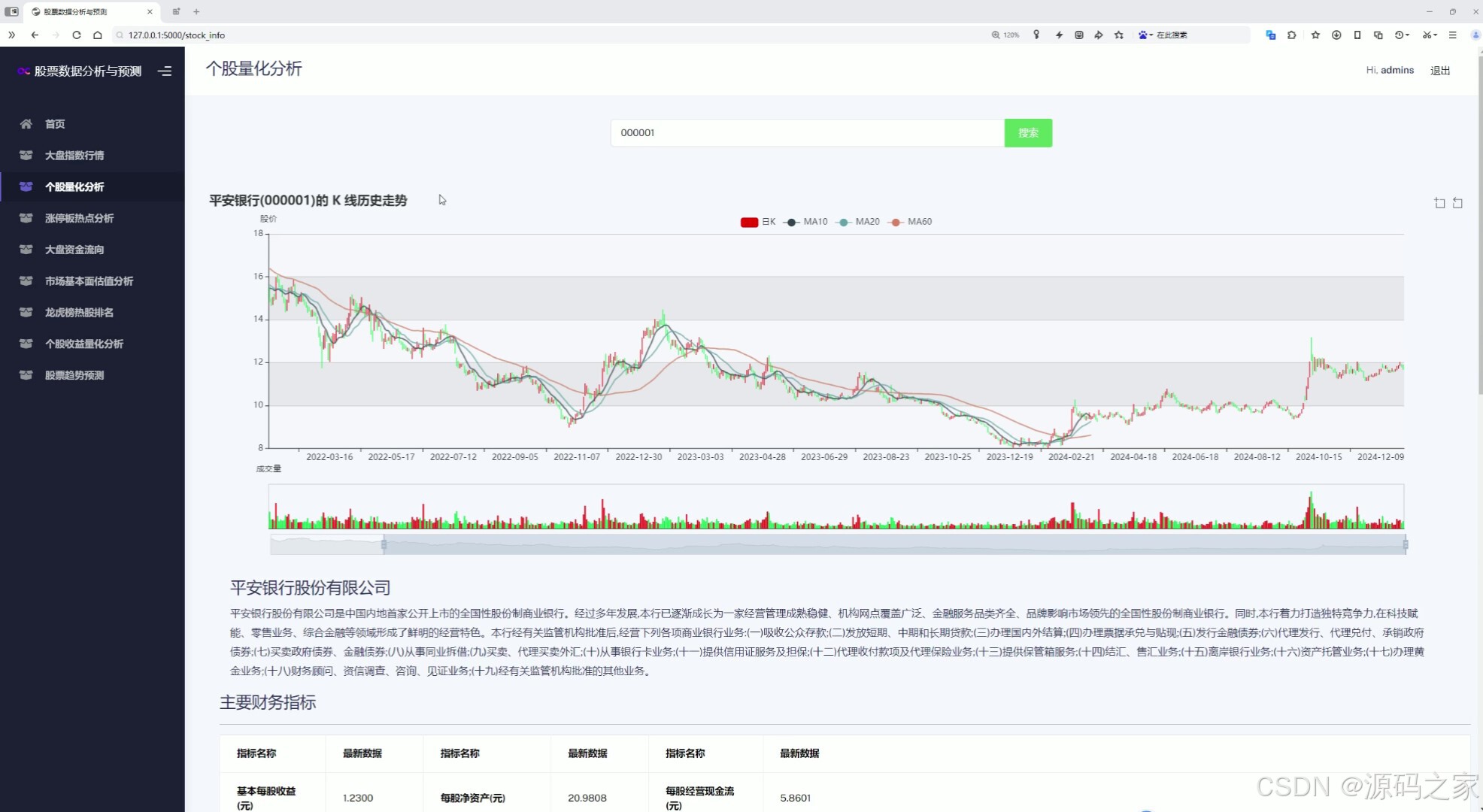
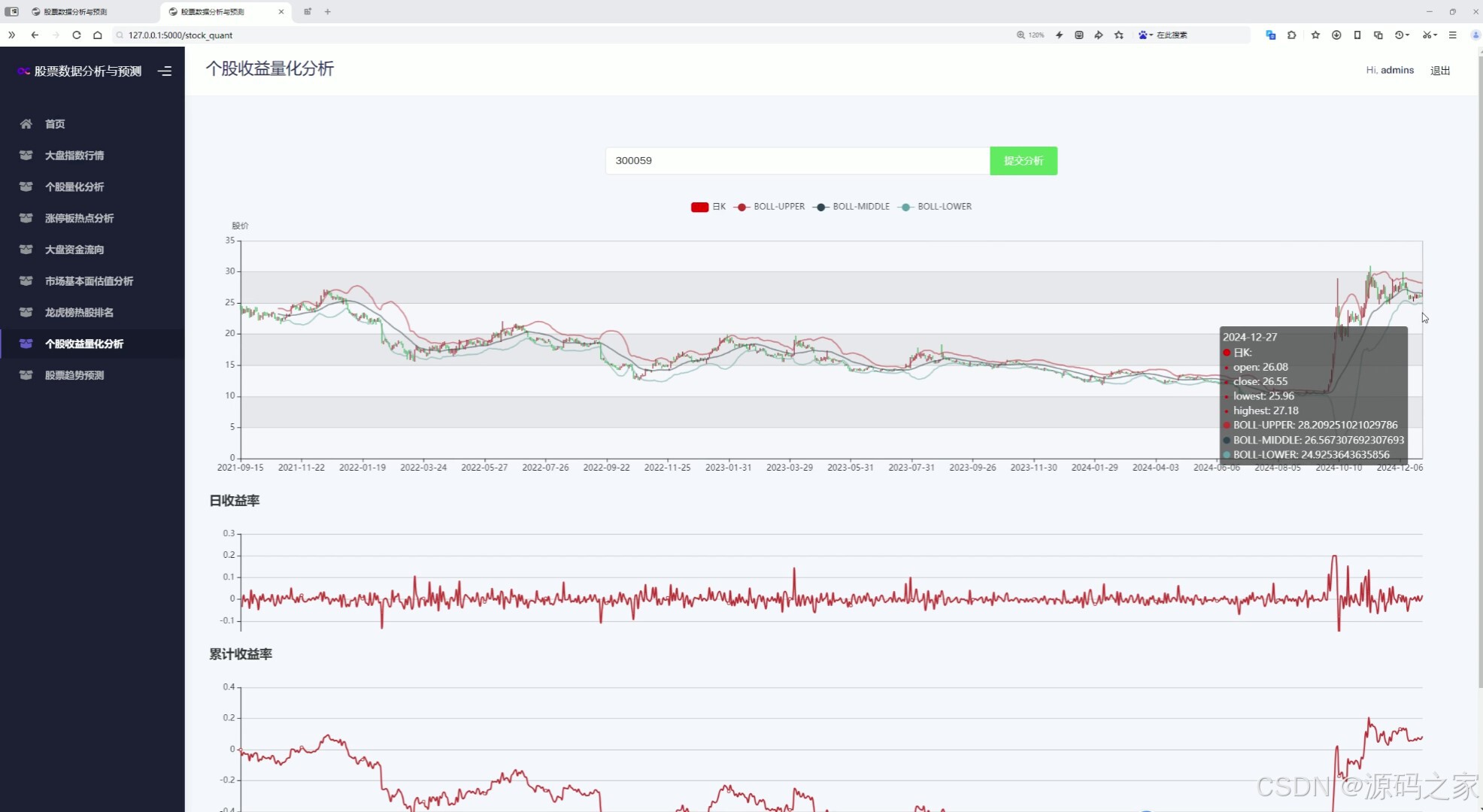
(4)個股量化分析—輸入股票代碼,全方位分析
(5)大盤資金流向分析—滬深兩市實時資金流向、南向實時資金流向
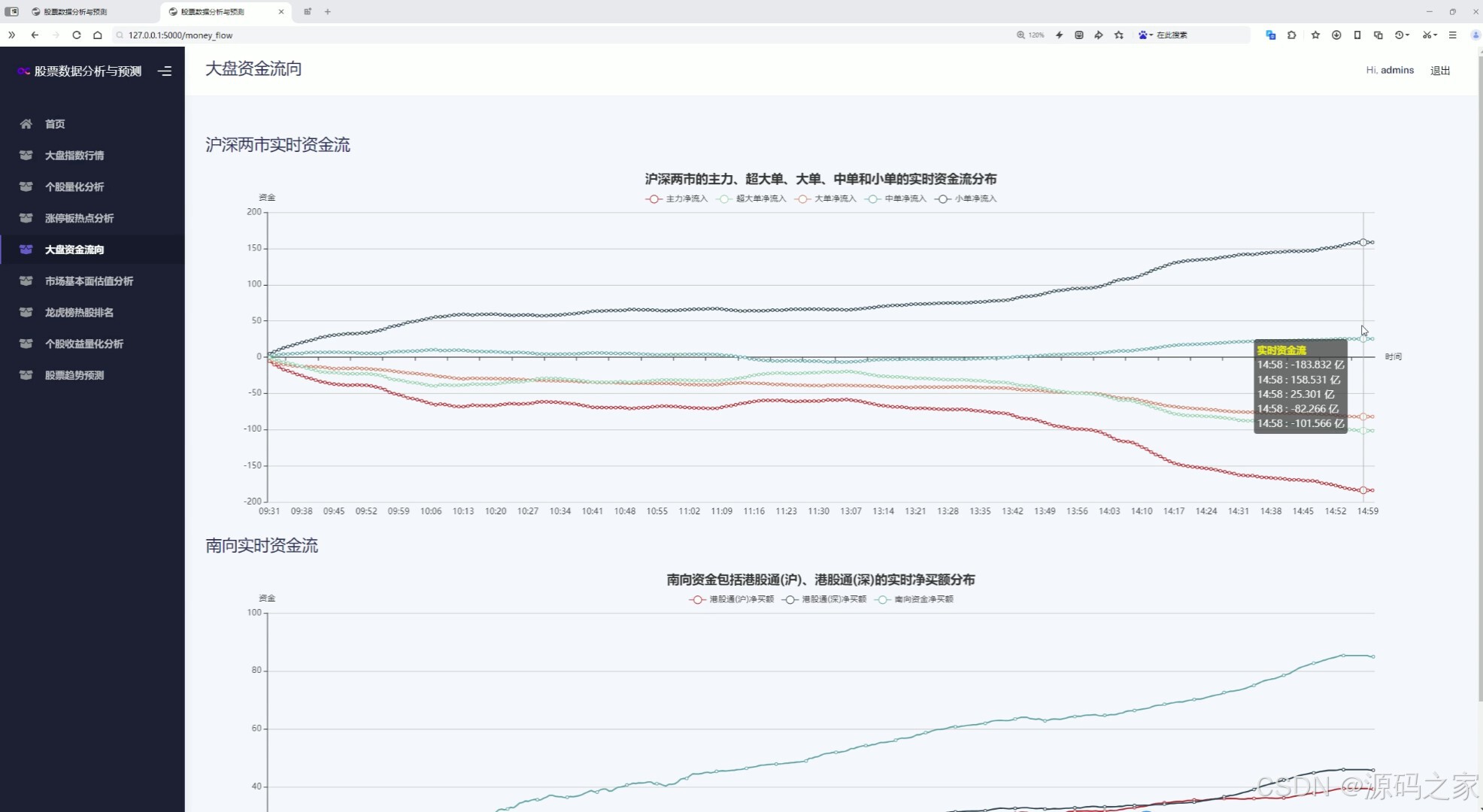
(6)大盤市場基本面估值分析----市盈率分布、市凈率分布
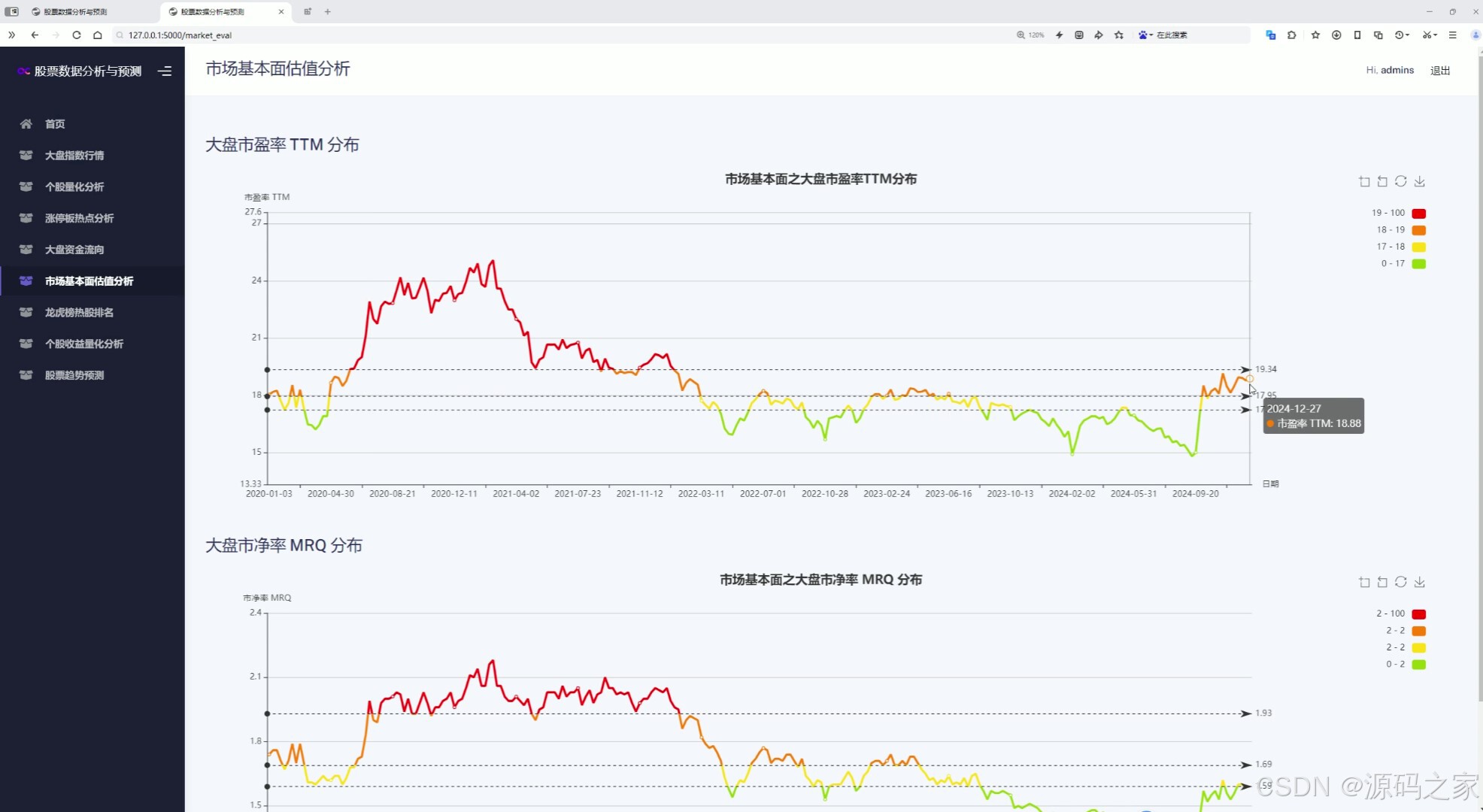
(7)個股收益量化分析—日收益率、月收益率、累計收益率
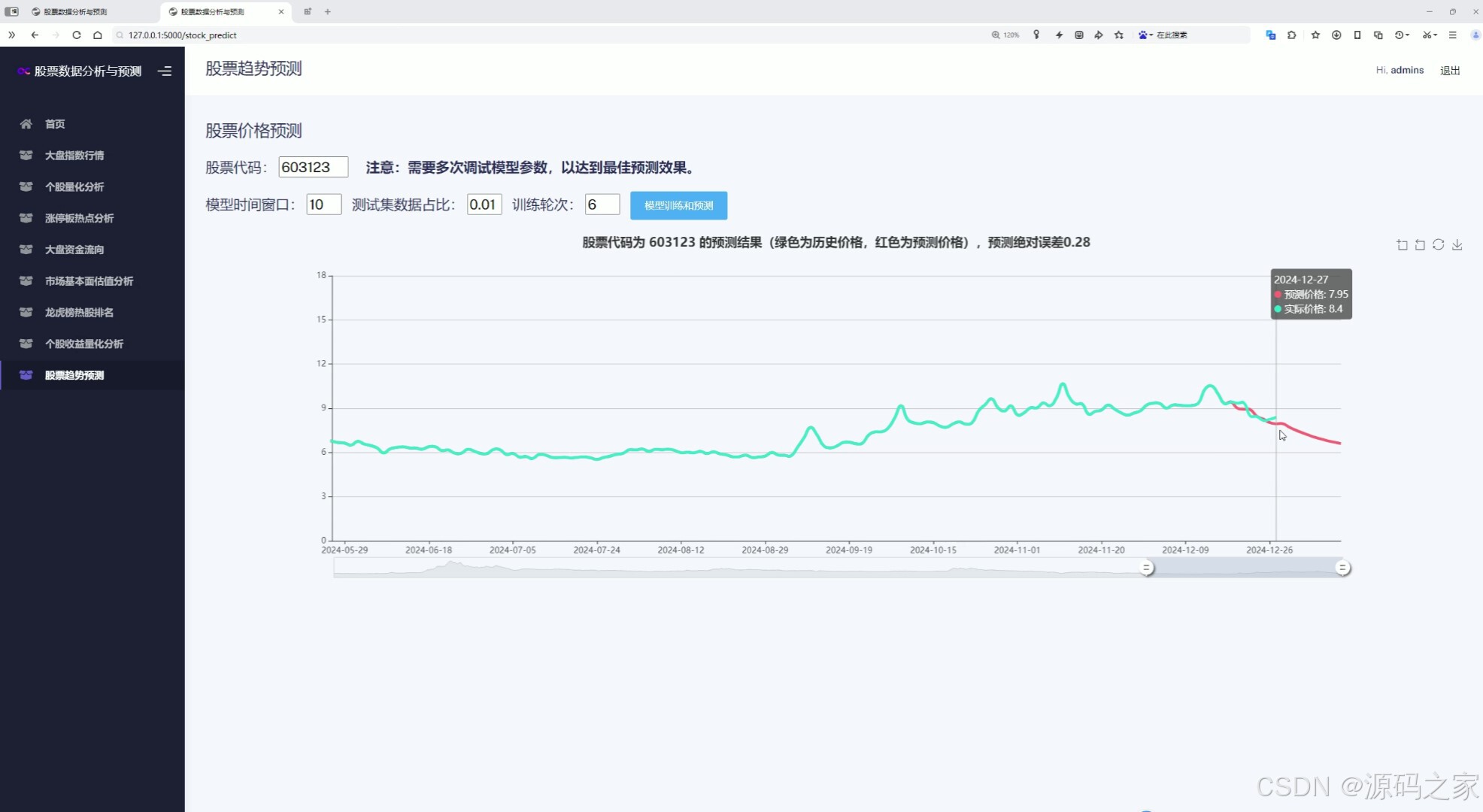
(8)股票價格預測----輸入特征值:股票代碼、模型時間窗口、測試集占比、訓練輪次
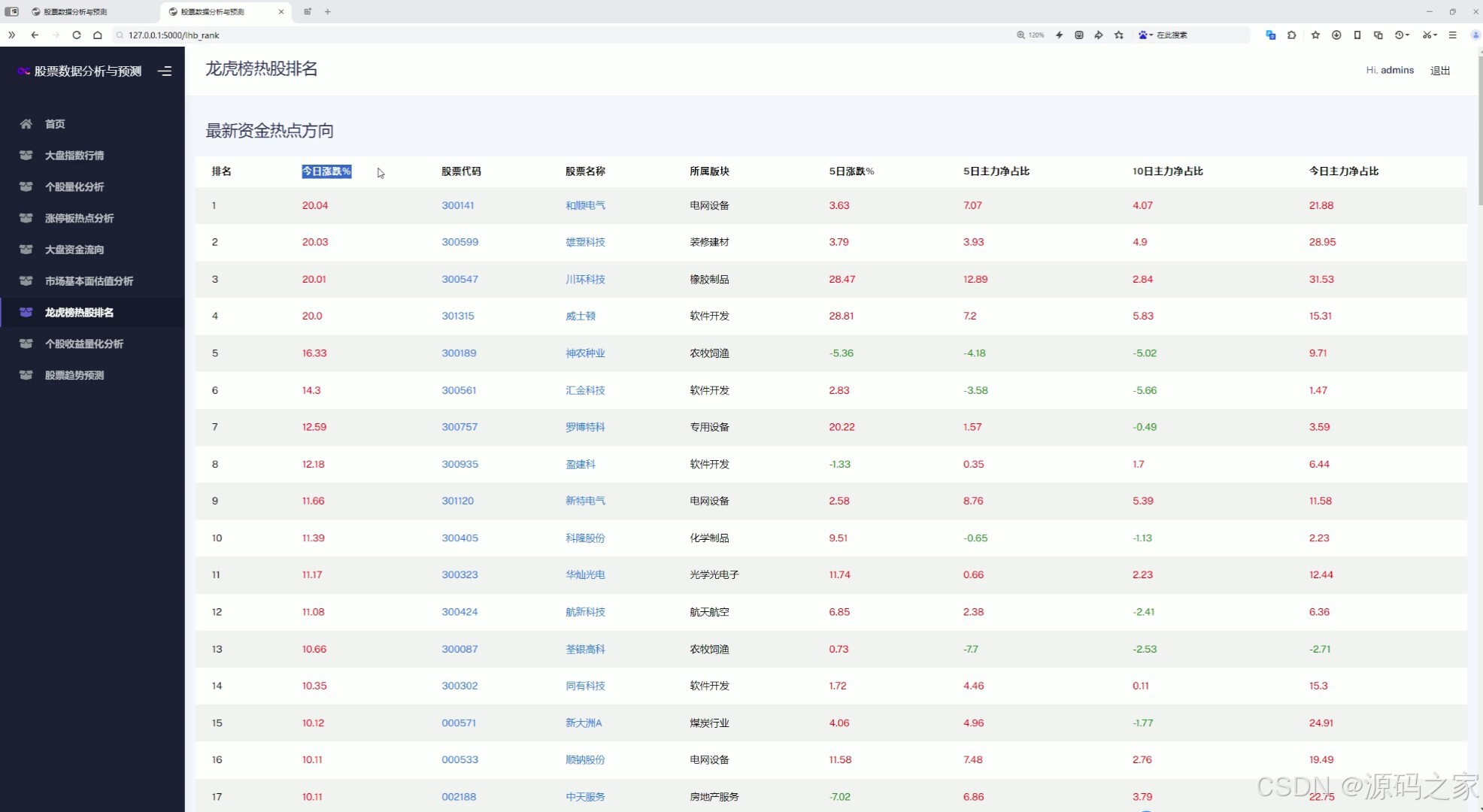
(9)龍虎榜熱股排名
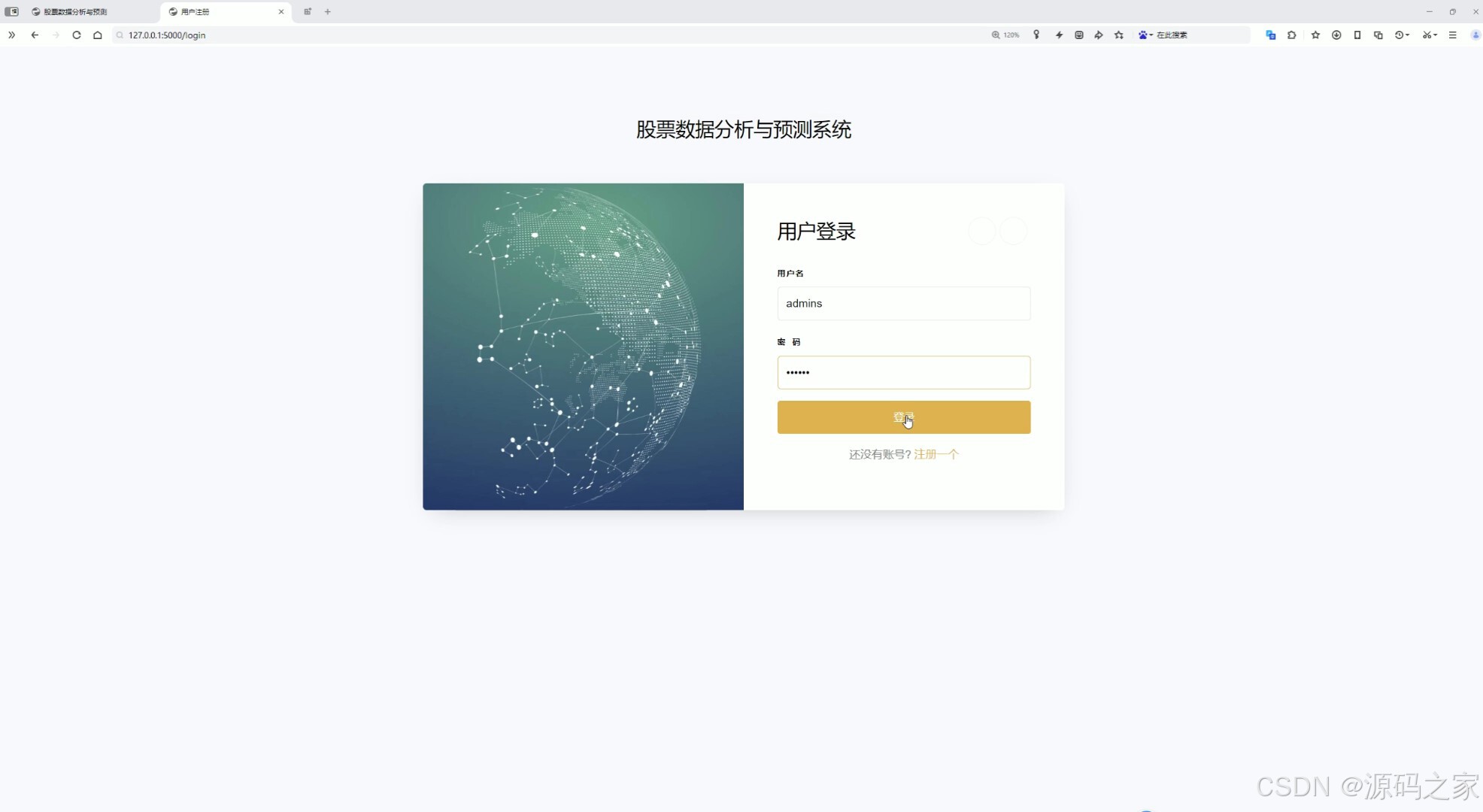
(10)注冊登錄模塊
3、項目說明
1. 漲停板熱點分析
- 熱點行業板塊漲停板數量分布直方圖:展示當前市場中各個行業板塊漲停板數量的分布情況,幫助用戶快速了解哪些行業板塊表現活躍。
- 不同行業板塊的成交額占比分布:分析各行業板塊的成交額占比,反映市場資金的流向和熱點板塊。
- 當日漲停股票池:列出當日漲停的股票及其相關信息,方便用戶關注熱門股票。
2. 首頁——功能模塊介紹
- 首頁通常會提供項目的整體介紹和各個功能模塊的入口。用戶可以通過首頁快速導航到感興趣的功能模塊,例如漲停板分析、大盤指數行情分析、個股量化分析等。
3. 大盤指數行情分析
- 展示上證、深證、創業板、中小指、滬深300等主要指數的K線圖。通過K線圖,用戶可以直觀地觀察指數的歷史走勢和當前趨勢,分析市場的整體表現。
4. 個股量化分析
- 用戶輸入股票代碼后,系統將對該股票進行全方位分析,包括:
- 技術指標分析:如均線、MACD、KDJ等,幫助用戶判斷股票的短期走勢。
- 基本面分析:如市盈率、市凈率、股息率等,評估股票的內在價值。
- 歷史數據展示:提供股票的歷史價格走勢和交易數據。
5. 大盤資金流向分析
- 滬深兩市實時資金流向:展示滬深兩市的資金流入流出情況,幫助用戶判斷市場的資金動向。
- 南向實時資金流向:分析南向資金的流向,反映外資對市場的態度。
6. 大盤市場基本面估值分析
- 市盈率分布:展示市場整體或特定板塊的市盈率分布情況,幫助用戶評估市場的估值水平。
- 市凈率分布:分析市凈率的分布,為投資者提供參考。
7. 個股收益量化分析
- 提供個股的日收益率、月收益率、累計收益率等數據,幫助用戶評估股票的投資收益情況。通過這些數據,用戶可以更好地了解股票的收益特征和風險水平。
8. 股票價格預測
- 功能描述:
- 用戶輸入股票代碼、模型時間窗口、測試集占比、訓練輪次等參數。
- 系統利用LSTM神經網絡模型對股票價格進行預測,輸出未來一段時間內的價格預測結果。
- 提供預測結果的可視化展示,幫助用戶直觀地了解預測趨勢。
- 技術實現:
- 使用 TensorFlow 框架構建 LSTM 模型。
- 通過機器學習算法(如 scikit-learn)進行數據預處理和特征提取。
- 使用歷史價格數據訓練模型,并對未來的股票價格進行預測。
9. 龍虎榜熱股排名
- 展示當前市場中龍虎榜上榜的熱門股票及其排名。龍虎榜數據通常反映了市場中機構和游資的關注焦點,對投資者具有一定的參考價值。
10. 注冊登錄模塊
- 功能描述:
- 提供用戶注冊和登錄功能,支持用戶名和密碼登錄。
- 后臺權限管理,限制非管理員身份登錄后臺,確保數據安全。
- 技術實現:
- 使用 Flask 框架搭建后端接口,處理用戶注冊和登錄請求。
- 使用 HTML 和前端技術實現注冊和登錄界面。
項目說明
基于LSTM神經網絡的股票價格預測
- 原理和流程:
- 數據收集:通過爬蟲技術從東方財富等金融數據源獲取股票的歷史K線數據。
- 數據預處理:對數據進行排序、歸一化處理,并劃分為訓練集和測試集。
- 創建數據集:將數據轉換為適合LSTM模型的輸入格式,例如時間序列數據。
- 構建模型:使用 TensorFlow 框架構建LSTM模型,包含LSTM層、Dropout層和輸出層。
- 訓練模型:使用訓練集數據對模型進行訓練,優化模型參數。
- 模型預測:使用訓練好的模型對測試集數據進行預測,并計算預測誤差。
- 結果輸出:將預測結果以可視化圖表(如Echarts)的形式展示給用戶。
這個項目通過整合 Python、Flask、TensorFlow、LSTM 等技術棧,實現了股票價格預測、市場分析、個股量化分析等多種功能,為投資者提供了一個全面、便捷的金融數據分析工具。
4、核心代碼
#!/usr/bin/python
# coding=utf-8
from flask import jsonify, Blueprint
import pandas as pd
import numpy as np
import json
from service.stock_spider import EastmoneySpider
from service import tech_util
import service.analysis_util as analysis_util
import random
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM, LSTM
from sklearn.metrics import mean_absolute_errorapi_blueprint = Blueprint('api', __name__)em_spider = EastmoneySpider()@api_blueprint.route('/search_stock_index/<stock_input>')
def search_stock_index(stock_input):"""搜索大盤指數或個股的行情數據"""market_type = Noneif stock_input == '上證指數':stock = {'code': '000001', 'name': '上證指數'}market_type = 1elif stock_input == '深證成指':stock = {'code': '399001', 'name': '深證成指'}elif stock_input == '中小板指':stock = {'code': '399005', 'name': '中小板指'}elif stock_input == '創業板指':stock = {'code': '399006', 'name': '創業板指'}elif stock_input == '滬深300':stock = {'code': '399300', 'name': '滬深300'}elif stock_input == '北證50':stock = {'code': '899050', 'name': '北證50'}else:stock = em_spider.stock_index_search(stock_input)# 獲取該股票的歷史數據,前端繪制 K 線圖# 獲取歷史K線數據stock_df = em_spider.get_stock_kline_factor_datas(security_code=stock['code'], period='day', market_type=market_type)stock_df = stock_df[['date', 'open', 'close', 'low', 'high', 'volume']]stock_df.sort_values(by='date', ascending=True, inplace=True)kline_data = stock_df.values.tolist()# 計算 MA 指標stock_df['MA5'] = tech_util.MA(stock_df['close'], N=5)stock_df['MA10'] = tech_util.MA(stock_df['close'], N=10)stock_df['MA20'] = tech_util.MA(stock_df['close'], N=20)stock_df['MA60'] = tech_util.MA(stock_df['close'], N=60)stock_df.fillna('-', inplace=True)return jsonify({'name': '{}({})'.format(stock['name'], stock['code']),'dates': stock_df['date'].values.tolist(),'klines': kline_data,'volumes': stock_df['volume'].values.tolist(),'tech_datas': {'MA5': stock_df['MA5'].values.tolist(),'MA10': stock_df['MA10'].values.tolist(),'MA20': stock_df['MA20'].values.tolist(),'MA60': stock_df['MA60'].values.tolist()}})@api_blueprint.route('/query_jibenmian_info/<stock_input>')
def query_jibenmian_info(stock_input):"""獲取基本面信息"""stock = em_spider.stock_index_search(stock_input)zyzb_table, jgyc_table, gsjj, gsmc = em_spider.get_ji_ben_mian_info(stock['code'])# 股票的核心題材concept_boards = em_spider.get_stock_core_concepts(stock['code'])print(concept_boards)# 概念板塊htmlconcept_html = """<div class=""><div class="card-header"><h3>核心概念板塊</h3><hr/></div><div class=""><table class="table table-hover" style="table-layout:fixed;word-break:break-all;"><thead><tr><th scope="col" width="8%">#</th><th scope="col" width="10%">概念板塊</th><th scope="col" width="70%">概念解讀</th><th scope="col" width="12%">最新漲幅</th></tr></thead><tbody>{}</tbody></table></div></div>"""trs = ''for i, conenpt in enumerate(concept_boards):trs += """<tr><td>{}</td><td>{}</td><td>{}</td><td style="color: {}">{}%</td></tr>""".format(i+1, conenpt['board_name'], conenpt['board_reason'], 'red' if conenpt['board_yield']>0 else 'green' ,conenpt['board_yield'])concept_html = concept_html.format(trs)return jsonify({'zyzb_table': zyzb_table,'jgyc_table': jgyc_table,'gsjj': gsjj,'gsmc': gsmc,'concept_boards': concept_html})@api_blueprint.route('/limitup_analysis/<trade_date>')
def limitup_analysis(trade_date):"""漲停板熱點分析"""print(trade_date)trade_date = trade_date.replace('-', '')limit_up_stocks = em_spider.get_limit_up_stocks(trade_date=trade_date)print(json.dumps(limit_up_stocks, ensure_ascii=False))trs = ''concept_counts = {}concept_moneys = {}for i, stock in enumerate(limit_up_stocks):if stock['行業板塊'] not in concept_counts:concept_counts[stock['行業板塊']] = 0concept_counts[stock['行業板塊']] += 1if stock['行業板塊'] not in concept_moneys:concept_moneys[stock['行業板塊']] = 0concept_moneys[stock['行業板塊']] += stock['成交額']tr = """<tr><th scope="row">{}</th><td><a href="http://127.0.0.1:5000/stock_info?search={}" target="_blank">{}</a></td><td><a href="http://127.0.0.1:5000/stock_info?search={}" target="_blank">{}</a></td><td style="color:red">{}%</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td></tr>""".format(i+1, stock['證券代碼'], stock['證券代碼'], stock['證券名稱'], stock['證券名稱'],round(stock['漲跌幅'], 2), stock['最新價'], round(stock['成交額'] / 100000000, 3),round(stock['流通市值'] / 100000000, 3), round(stock['換手率'], 2),round(stock['封板資金'] / 100000000, 3), stock['炸板次數'], stock['漲停統計'], stock['行業板塊'], stock['交易日期'])trs += tr# 行業板塊數量分布concept_counts = sorted(concept_counts.items(), key=lambda x: x[1], reverse=True)print(concept_counts)concepts = [c[0] for c in concept_counts]# 行業板塊資金流入占比result = {'tbody': trs,'concept': concepts,'limit_up_count': [c[1] for c in concept_counts],'concept_moneys': [concept_moneys[c] for c in concepts]}return jsonify(result)@api_blueprint.route('/predict_stock_price/<code>/<look_back>/<test_ratio>/<train_epochs>')
def predict_stock_price(code, look_back, test_ratio, train_epochs):"""股票價格預測"""prices_df = em_spider.get_stock_kline_factor_datas(security_code=code, period='day', market_type=None)prices_df = prices_df.sort_values(by='date', ascending=True)print(prices_df.head())test_count = int(float(test_ratio) * prices_df.shape[0])train = prices_df['close'].values.tolist()[:-test_count]test = prices_df['close'].values.tolist()[-test_count:]def create_dataset(prehistory, dataset, look_back):dataX = []dataY = []history = prehistoryfor i in range(len(dataset)):x = history[i:(i + look_back)]y = dataset[i]dataX.append(x)dataY.append(y)history.append(y)return np.array(dataX), np.array(dataY)# 數據集構造look_back = int(look_back)trainX, trainY = create_dataset([train[0]] * look_back, train, look_back)testX, testY = create_dataset(train[-look_back:], test, look_back)print(trainX.shape, testX.shape)# 根據參數構建lstm模型def create_lstm_model():"""單層 LSTM 神經網絡"""d = 0.2model = Sequential()model.add(LSTM(16, input_shape=(look_back, 1), return_sequences=False))model.add(Dropout(d))model.add(Dense(1, activation='relu'))model.compile(loss='mse', metrics=['mae'])return modelmodel = create_lstm_model()train_epochs = int(train_epochs)model.fit(trainX, trainY, epochs=train_epochs, batch_size=4, verbose=1)# predictlstm_predictions = model.predict(testX)lstm_predictions = [float(r[0]) for r in lstm_predictions]lstm_error = mean_absolute_error(testY, lstm_predictions)print('Test MSE: %.3f' % lstm_error)lstm_predictions = train + lstm_predictionsall_time = prices_df['date'].values.tolist()future_x = []pred_price = testY[-1]future_count = 10i = 0test_x = prices_df['close'].values.tolist()[-look_back:]test_x = np.array([test_x])print('test_x:', test_x)print('test_x:', test_x.shape)for future in range(future_count):i += 1# ratio = random.random() / 100 if random.random() > 0.5 else -random.random() / 100# pred_price *= (1 + ratio)pred_price = model.predict(test_x)[0][0]pred_price = float(pred_price)test_x = test_x[0][1:]test_x = np.append(test_x, pred_price)test_x = np.array([test_x])print('test_x:', test_x)future_x.append(pred_price)all_time.append(f'未來{i}個交易日')# print(future_x)all_data = prices_df['close'].values.tolist()all_data += [None] * 5lstm_predictions = lstm_predictions + future_xreturn jsonify({'all_time': all_time,'all_data': all_data,'add_predict': lstm_predictions,'test_count': future_count,'error': lstm_error})
🍅?感興趣的可以先收藏起來,點贊關注不迷路,想學習更多項目可以查看主頁,大家在畢設選題,項目編程以及論文編寫等相關問題都可以給我留言咨詢,希望可以幫助同學們順利畢業!🍅?
5、源碼獲取方式
🍅由于篇幅限制,獲取完整文章或源碼、代做項目的,拉到文章底部即可看到個人聯系方式。🍅
點贊、收藏、關注,不迷路,下方查看👇🏻獲取聯系方式👇🏻




)





)
設備是否連接了指定WiFi)

:RAG工作流程及如何創建一個RAG應用)


)


)