比賽簡介
「用戶新增預測挑戰賽」是由科大訊飛主辦的一項數據科學競賽,旨在通過機器學習方法預測用戶是否為新增用戶
比賽屬于二分類任務,評價指標采用F1分數,分數越高表示模型性能越好。
如果你有一份帶標簽的表格型數據,只要目標是分類、回歸或排序,那么 LightGBM 都是最強機器學習模型之一,默認首選。
賽題建模的價值
用戶新增預測是分析 用戶使用場景 以及 預測用戶增長情況 的關鍵步驟,有助于進行其后續產品和應用的迭代升級,主要有對行業和技術有如下價值:
行業價值:
-
精準預測用戶增長趨勢,優化產品迭代方向
-
降低用戶獲取成本,提高營銷轉化率
-
為AI能力落地提供量化評估依據
技術價值:
-
解決實際業務場景中的用戶增長預測問題
-
驗證AI在用戶行為分析領域的有效性
-
建立可復用的用戶增長預測方法論
賽題要求:
參與算法賽事,一定要仔細理解賽事的 輸入-輸出 究竟是什么,尤其是提交的格式
輸入數據:
-
用戶行為事件記錄
-
15個原始特征字段
-
關鍵字段:
udmap(JSON)、common_ts(時間戳)
輸出要求:
-
預測用戶是否為新增 (
is_new_did) -
提交格式:CSV文件包含一列,字段名為
is_new_did,值為0/1-
0表示不是新增用戶 -
1表示是新增用戶
-
原始數據初步預覽
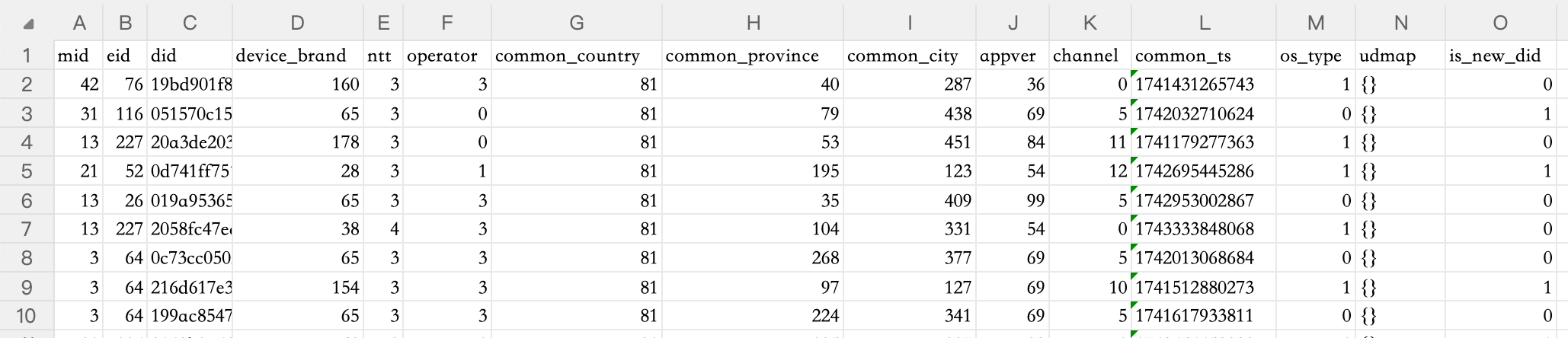
其中:
-
mid為用戶行為模塊id, -
eid為用戶行為事件id,
解析一下兩者的區別:
-
mid(模塊ID):是一類行為的編號,表示用戶在做什么“類型”的事情,比如:-
mid = 1:表示“瀏覽商品模塊”
-
mid = 2:表示“搜索模塊”
-
mid = 3:表示“結算模塊”
所以它更像是一個大分類,告訴我們用戶當前在哪個模塊里操作。
-
-
eid(事件ID):是具體某個行為的編號,它屬于某個模塊(mid),但粒度更細,比如:-
在“瀏覽商品模塊”中(mid=1),可能有:
-
eid = 101:點擊商品詳情
-
eid = 102:滑動商品列表
-
-
在“搜索模塊”中(mid=2),可能有:
-
eid = 201:輸入關鍵詞
-
eid = 202:點擊搜索按鈕
-
-
-
did為用戶id, -
device_brand為設備品牌/廠商, -
ntt為網絡類型, -
operator為運營商, -
common_country為國家, -
common_province為省份, -
common_city為城市, -
appver為應用版本, -
channel為應用渠道, -
common_ts為事件發生時間(毫秒時間戳), -
os_type用于判斷Android還是iOS, -
udmap為事件自定義屬性(標準json文本,內含botId助手ID和pluginId插件ID) -
is_new_did為預測目標,即是否為新增用戶
分析訓練集與測試集用戶重疊度
然后我們可以通過 經驗/資料查閱肉眼觀測/代碼 等手段,對 賽事提供的數據 有大致的理解和把握:
提取了訓練集和測試集中的所有唯一用戶ID,分別組成集合
train_dids = set(train_df['did'].unique())
test_dids = set(test_df['did'].unique())
計算兩者交集
overlap_dids = train_dids & test_dids
統計數量
num_overlap = len(overlap_dids)
num_train = len(train_dids)
num_test = len(test_dids)
計算比例:
ratio_in_train = num_overlap / num_train
ratio_in_test = num_overlap / num_test
我們通過數據探索的代碼,有一些關鍵發現:
-
測試集中93%的用戶出現在訓練集中
-
訓練集中88%的用戶
is_new_did為 0
建模初步思路
-
數據處理與特征工程: 如處理缺失值、異常值,解析JSON字段,從時間戳中提取特征(年、月、日、小時等),以及構造新的特征以提升模型表現。
-
分類模型與集成學習: 了解常用的分類算法(如邏輯回歸、決策樹、隨機森林等),特別是梯度提升樹(如LightGBM)的原理和使用。LightGBM是微軟開發的高效梯度提升框架,具有訓練速度快、內存占用低和精度高等優點。
-
模型評估與指標: 掌握二分類問題的評估指標,如精確率(Precision)、召回率(Recall)和F1分數的定義及計算方法。F1分數是精確率和召回率的調和均值,在正負樣本不均衡時比準確率更有參考意義。
-
交叉驗證: 理解交叉驗證的作用,能夠使用分層K折交叉驗證來評估模型性能,避免因隨機劃分導致的偏差。
-
超參數調優: 熟悉如何調整模型的超參數(如學習率、樹的深度等)以提高模型效果,常用方法包括網格搜索、隨機搜索和貝葉斯優化等。
-
結果提交與分析: 了解競賽提交的格式要求,能夠將模型預測結果生成符合要求的CSV文件提交,并通過排行榜成績分析模型改進方向。
解題 要點和難點
-
用戶行為事件數據 → 用戶級別預測
-
高維稀疏特征(設備/地域/行為ID)
像device_brand,common_city,mid,eid這類字段,有成百上千種取值。用 One-hot 編碼會變成高維稀疏矩陣,容易導致模型訓練慢、過擬合,必須小心處理,比如可以做頻率編碼、embedding、或僅保留Top-N -
正負樣本不均衡(新增用戶占比較少)
is_new_did的 0 和 1 不平衡,大多數是老用戶(0)。這會讓模型“只學會預測0”,所以需要: -
采樣策略(欠采樣、過采樣)
- 比如統計:
- 用戶一共觸發了幾個行為(行為數量)
- 用戶用過哪些網絡、在哪些城市
- 用戶行為的時間分布(首次時間、活躍時段等)
-
這是建模效果優劣的關鍵步驟。
-
合理評價指標(如AUC或F1,而不是Accuracy)
-
使用內置樣本權重的模型(如 LightGBM)
-
用戶行為聚合:如何將事件級數據轉化為用戶特征
數據是以“行為事件”為單位的,比如用戶點擊了某個按鈕,這樣的行為記錄很多,但我們的目標是預測“某個用戶是否是新用戶”,所以我們需要將多條事件數據合并成一個用戶級別的數據,這是一個“從行到列”的特征聚合問題。 -
時間敏感特征:用戶行為模式隨時間變化
比如一個用戶一開始很頻繁,后面沉寂,也許是老用戶;新用戶行為更集中在某幾個小時;時間戳可以提取:- 小時、星期幾、行為密度
- 首次行為和最后一次行為的間隔
- 是否在特定時間段活躍(如晚上活躍)
解題思考過程
關鍵決策點:
-
選擇樹模型而非神經網絡(訓練速度/特征處理)
-
優先構造簡單的時間特征而非復雜特征工程
參考資料:
-
LightGBM官方文檔(分類任務參數配置)
-
時序特征工程最佳實踐(FeatureTools庫)
Baseline方案的設計思路
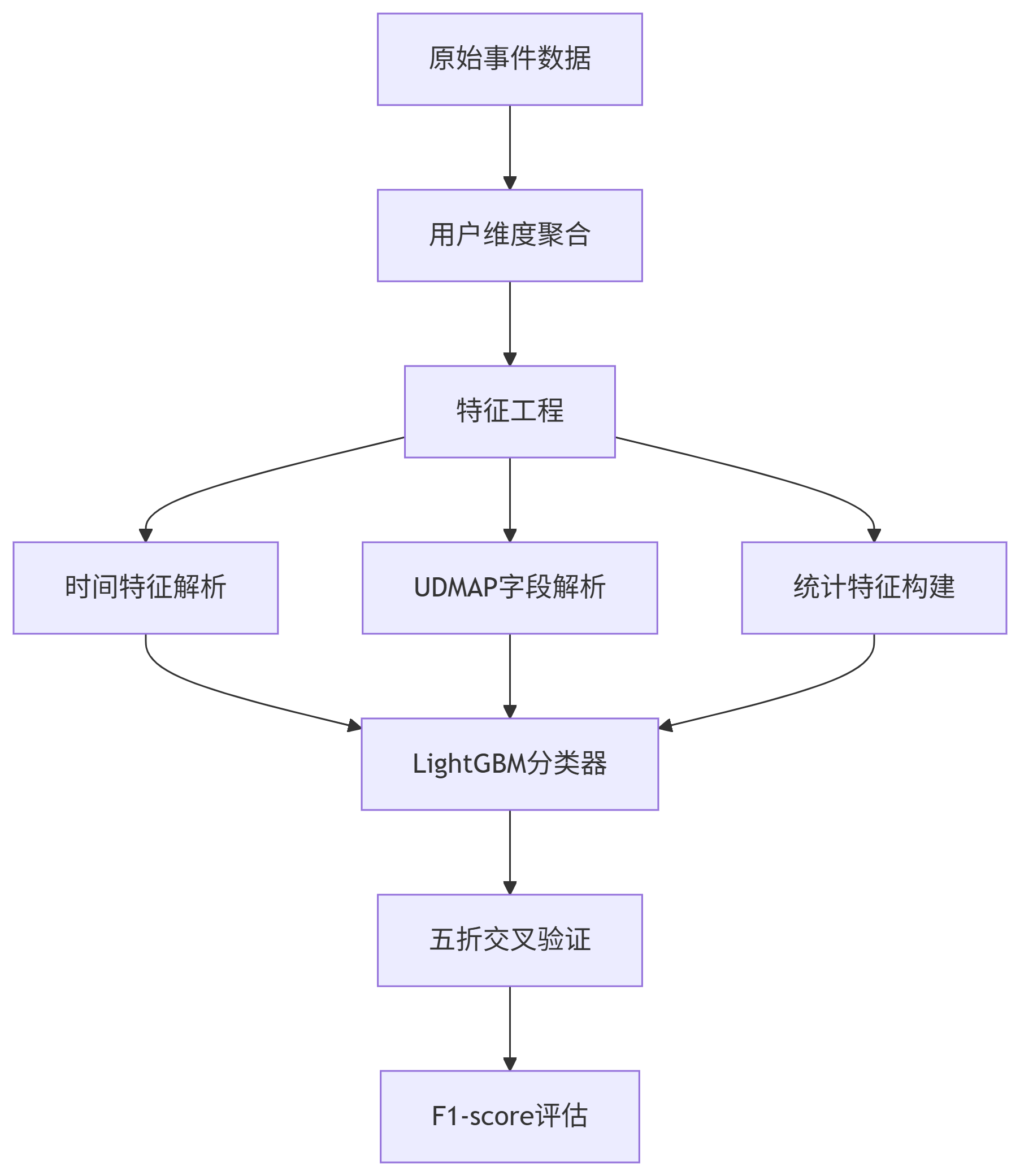
核心函數1:交叉驗證建模
n_folds = 5
kf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=42)for fold, (train_idx, val_idx) in enumerate(kf.split(X_train, y_train)):print(f"\n======= Fold {fold+1}/{n_folds} =======")X_tr, X_val = X_train.iloc[train_idx], X_train.iloc[val_idx]y_tr, y_val = y_train.iloc[train_idx], y_train.iloc[val_idx]# 創建數據集(指定類別特征)train_set = lgb.Dataset(X_tr, label=y_tr)val_set = lgb.Dataset(X_val, label=y_val)# 模型訓練model = lgb.train(params,train_set,num_boost_round=5000,valid_sets=[train_set, val_set],callbacks=[lgb.early_stopping(stopping_rounds=200, verbose=False),lgb.log_evaluation(period=200)])
細節補充(什么是k-fold cross-validation):

根據題型還要有的改進點:
使用StratifiedKFold
如果你在處理的是分類問題,并且正負樣本比例不平衡(比如“新增用戶”只占很少),那你用的 StratifiedKFold 就更進一步了,它在劃分每一份的時候,還會確保正負樣本的比例一致,這能避免某一折驗證集全是負樣本,導致模型評估不準。
核心函數2:目標優化函數
def find_optimal_threshold(y_true, y_pred_proba):"""尋找最大化F1分數的閾值"""best_threshold = 0.5best_f1 = 0for threshold in [0.1,0.15,0.2,0.25,0.3,0.35,0.4]:y_pred = (y_pred_proba >= threshold).astype(int)f1 = f1_score(y_true, y_pred)if f1 > best_f1:best_f1 = f1best_threshold = thresholdreturn best_threshold, best_f1
背景:
在二分類模型中,很多模型(比如 LightGBM、XGBoost)輸出的不是“0”或“1”的標簽,而是一個概率(比如這個樣本屬于正類的概率是 0.73)
但我們最終要做出決策:到底是正類(1)還是負類(0)?這就需要設置一個“閾值”來做轉換
例如:默認是用 0.5,當預測概率大于 0.5 就認為是正類。但這個閾值不是固定的,在樣本不均衡或業務目標特殊時,調整閾值可以顯著提升 F1 等指標。
設計特點:
- 候選范圍選擇
-
聚焦 0.1-0.4:適用于正例稀少的場景(如欺詐檢測)
-
若正例比例高,可擴展范圍至
np.arange(0.05, 0.95, 0.05)
-
- 數值穩定性
-
避免使用
np.ptp等可能受異常值影響的指標 -
離散化搜索簡單高效,復雜度 O(n)
-
合并數據做特征工程(補充)
1. 類別特征編碼一致性
for feature in cat_features:le = LabelEncoder()all_values = pd.concat([train_df[feature], test_df[feature]]).astype(str)le.fit(all_values)# 確保訓練集和測試集使用相同的編碼映射
-
le.fit(values)這一步是“學習”階段:它會掃描values中所有不同的取值,按字典序排序,然后給每個唯一類別分配一個整數標簽(從 0 開始)。這些映射規則保存在le.classes_屬性里。 -
然后用
le.transform(...)把原始列中的每個值,根據這個映射規則變成整數(比如['banana', 'apple']→[1, 0])。 -
最后,這些編碼后的數字會“回填到數據集的原列里”,替換掉原來的字符串
關鍵問題:如果分別編碼,可能出現:
- 訓練集中
device_brand='Apple'編碼為0 - 測試集中
device_brand='Apple'編碼為1 - 導致模型無法正確識別相同的設備品牌
2. 統計特征的完整性
# 基于合并數據計算統計特征
brand_stats = full_df.groupby('device_brand').agg({'did': 'nunique','hour': ['mean', 'std'],'dayofweek': 'mean'
}).reset_index()
優勢:
- 統計更準確(基于更大的樣本)
- 避免訓練集和測試集統計分布不一致
- 提高特征的泛化能力
3. 數據泄露檢查
# 注意:標簽信息只在訓練集中存在
print(f"正樣本比例: {train_df['is_new_did'].mean():.4f}")
安全性:
- 測試集中的
is_new_did列為NaN - 只使用特征信息,不使用標簽信息
- 不會造成數據泄露
聚合的意義(補充)
原始數據的真實結構:
一行 ≠ 一個用戶的所有行為
一行 = 一次用戶行為事件,不是用戶全部行為
從代碼中可以看出:
- 訓練集大小: (3,429,925, 15) - 343萬條記錄
- 唯一用戶數: 270,837 個用戶
- 這意味著:平均每個用戶有 12.7 條記錄
# 證明:每個用戶有多條記錄
print(f"總記錄數: {len(train_df)}") # 3,429,925
print(f"唯一用戶數: {len(train_df['did'].unique())}") # 270,837
print(f"平均每用戶記錄數: {len(train_df) / len(train_df['did'].unique()):.1f}") # 12.7
🔍 具體例子說明
原始數據長這樣:
did eid common_ts device_brand hour is_new_did
0 user001 100 1640000000000 Apple 14 1
1 user001 200 1640000001000 Apple 14 1
2 user001 300 1640000002000 Apple 15 1
3 user001 100 1640000003000 Apple 16 1
4 user002 100 1640000000500 Samsung 10 0
5 user002 150 1640000001500 Samsung 11 0
6 user003 200 1640000002000 Xiaomi 20 1
問題是什么?
每一行只代表用戶的一次行為事件,而不是用戶的全部行為!
- 第0行:用戶001在14:00觸發了事件100
- 第1行:用戶001在14:00觸發了事件200
- 第2行:用戶001在15:00觸發了事件300
- 第3行:用戶001在16:00又觸發了事件100
我們需要用戶級別的特征!
🎯 為什么要聚合?
1. 單行信息不足
- 單行只能告訴我們:這個用戶在某個時間點做了什么
- 無法告訴我們:這個用戶的整體行為模式
2. 用戶級別特征更重要
# 沒有聚合的情況下,我們只知道:
# - 用戶001在14:00觸發了事件100
# - 用戶001使用Apple設備# 有了聚合后,我們還知道:
# - 用戶001總共觸發了4次事件 (frequency)
# - 用戶001使用了3種不同事件類型 (monetary)
# - 用戶001最后一次活動在16:00 (recency)
# - 用戶001的活躍時間跨度是2小時
3. 模型需要用戶畫像
- 活躍用戶: 高頻次、多事件類型、最近活躍
- 不活躍用戶: 低頻次、單一事件、很久沒活躍
💡 實際價值
聚合特征能回答的問題:
- 這個用戶活躍嗎? →
frequency(行為頻次) - 這個用戶最近活躍嗎? →
recency(最近活躍時間) - 這個用戶行為多樣嗎? →
monetary(不同事件類型數) - 這個用戶是重度用戶嗎? → 綜合RFM得分
這些特征對預測"新用戶"很重要:
- 新用戶: 通常頻次低、事件類型少、最近注冊
- 老用戶: 通常頻次高、事件類型多、歷史悠久
🎯 總結
聚合的核心價值:
- 將用戶的多次行為匯總成用戶畫像
- 從事件級別提升到用戶級別的特征
- 為模型提供更豐富的用戶行為信息
沒有聚合:只知道用戶做了什么
有了聚合:知道用戶是什么樣的人
Baseline方案的優缺點
方案優點:
-
數據預處理完整
-
時間特征提取:將毫秒時間戳轉換為
day、dayofweek、hour等可解釋的時序特征,捕捉用戶行為的周期性規律。 -
類別特征編碼:對
device_brand、operator等高基數類別特征使用LabelEncoder進行編碼,避免了獨熱編碼導致的維度爆炸問題。 -
交叉驗證策略:采用
StratifiedKFold分層交叉驗證,確保訓練集和驗證集的類別分布一致性,減少模型偏差。
-
-
模型選擇合理
-
使用LightGBM作為基模型,適合高維稀疏數據,且對類別特征處理友好(如
udmap中的JSON字段)。 -
閾值優化:通過動態調整分類閾值(
find_optimal_threshold)最大化F1分數,適應類別不平衡問題(新增用戶比例較低)。
-
-
特征重要性分析
- 輸出特征重要性(
gain),幫助識別關鍵特征(如udmap中的插件ID或助手ID),為后續特征優化提供方向。
- 輸出特征重要性(
方案不足:
-
特征工程深度不足
-
未充分挖掘
udmap字段中的JSON信息(如botId、pluginId),僅將其作為類別特征處理,未提取組合特征(如botId+pluginId的交互)。 -
忽略用戶行為序列模式(如用戶訪問頻次、事件路徑),未能構建基于時間窗口的統計特征(如24小時內訪問次數、連續登錄天數)。
-
-
模型調參空間有限
-
參數固定(如
max_depth=12、num_leaves=63),未通過網格搜索或貝葉斯優化探索更優參數組合。 -
未嘗試集成模型(如CatBoost、XGBoost)或模型融合策略(如Stacking)提升泛化能力
-
進階要點1:如何挖掘用戶行為信息
時間序列特征:
- 滑動窗口統計:計算用戶在最近7天、30天內的行為頻次(如
eid事件發生次數)、活躍時長(連續登錄天數)。 - 示例代碼:
# 按用戶分組,按時間排序
train_df.sort_values(['did', 'common_ts'], inplace=True)# 計算用戶歷史行為頻次(滑動窗口)
train_df['user_event_count'] = train_df.groupby('did')['eid'].transform('cumcount') + 1
RFM特征:
- Recency(最近一次行為時間):計算用戶最近一次行為距離當前時間的天數。
- Frequency(行為頻率):用戶總行為次數。
- Monetary(行為價值):假設某些事件(如
eid)有經濟價值,可定義虛擬價值字段。 - 示例代碼:
# 計算RFM特征
rfm = train_df.groupby('did').agg(recency=('common_ts', 'max'),frequency=('eid', 'count'),monetary=('eid', 'nunique') # 假設不同事件類型代表不同價值
).reset_index()
train_df = train_df.merge(rfm, on='did', how='left')
組合特征與高階交互
目標:通過特征交叉和非線性組合,捕捉復雜模式。
方法:
- 類別特征交叉:
- 將
device_brand與os_type組合(如Android_Samsung),反映設備-系統的用戶偏好。 - 示例代碼:
- 將
train_df['device_os'] = train_df['device_brand'].astype(str) + '_' + train_df['os_type'].astype(str)
- 數值特征分桶與交叉:
- 將將
common_ts分桶為時間段(如早高峰、晚高峰),與hour特征交叉,分析用戶在特定時段的行為差異。 - 示例代碼:
- 將將
# 分桶:將時間戳轉換為時間段(如0-6: 0, 6-12:1...)
train_df['time_bucket'] = pd.cut(train_df['hour'], bins=[0,6,12,18,24], labels=[0,1,2,3])
進階要點2:選擇什么樣的建模思路
1、按?did?聚合后的分層建模
核心思想:
將問題拆解為兩層:用戶層和事件層,通過分層建模捕捉用戶級特征與事件級特征的交互。
具體步驟:
- 用戶層建模:
- 對每個
did進行特征聚合(如行為頻次、時間分布、RFM特征等),訓練一個用戶級模型(如LightGBM/XGBoost),預測該did的標簽(或概率)。 - 例如:使用每個
did的累計行為次數、最近一次行為時間間隔等作為輸入特征。
- 對每個
- 事件層建模:
- 在事件級別(即原始樣本)引入用戶級預測結果作為特征,構建混合模型。
- 例如:將用戶級模型的輸出(如預測概率)與事件級特征(如
eid、時間戳、設備信息)拼接,輸入到最終模型(如神經網絡或集成樹)中進行預測。
優勢:
- 用戶層模型可捕捉全局用戶行為模式,事件層模型可結合局部事件特征,提升模型魯棒性。
- 對于測試集中重復的
did,用戶層預測結果可直接復用,減少冗余計算。
2、半監督學習策略
核心思想:
利用測試數據中重復的 did (部分標簽已知但不唯一)作為偽標簽,結合訓練數據進行半監督訓練。
具體步驟:
- 篩選偽標簽:
- 對測試集中重復的
did,若其在訓練集中有多個樣本且標簽一致,可直接使用該標簽作為偽標簽。 - 若標簽不一致,可通過以下方式處理:
- 投票機制:選擇訓練集中該
did的多數類標簽。 - 置信度閾值:對預測概率較高的樣本(如閾值>0.95)生成偽標簽。
優勢:
- 投票機制:選擇訓練集中該
- 對測試集中重復的
-
利用測試數據中的隱式信息(重復
did的已知標簽),提升模型泛化能力。 -
對標簽不唯一的場景,通過置信度篩選降低噪聲風險。
3、動態標簽映射與修正
核心思想:
針對測試集中重復的 did ,動態修正其預測標簽,結合訓練數據中的歷史行為模式。
具體步驟:
- 標簽沖突檢測:
-
對于測試集中某個
did,若其在訓練集中有多個標簽,統計標簽分布(如出現次數、時間趨勢)。 -
例如:若某
did在訓練集中同時存在0和1標簽,但1標簽集中在近期事件中,則優先選擇1作為預測值。
-
- 動態修正策略:
-
時間加權平均:根據訓練集中
did的標簽時間分布,加權計算預測值。 -
行為相似度匹配:將測試樣本與訓練集中該
did的相似行為樣本匹配,提取標簽分布。
優勢:
-
-
精細化處理標簽不唯一的場景,避免簡單投票導致的偏差。
-
結合時間動態性和行為相似性,提升預測的合理性。
?)



)








)
)




deep learning(五)--learning rate)