目錄
初識HTTP協議
認識URL
HTTP協議的宏觀格式
Socket封裝
TcpServer?
HttpServer
整體設計
接收請求
web根目錄與默認首頁
發送應答
完善頁面
HTTP常見Header
HTTP狀態碼
HTTP請求方法
Connection
抓包
初識HTTP協議
應用層協議一定是基于UDP/TCP的,HTTP協議是基于TCP的。只要基于TCP,就就是全雙工、面面向字節流、在應用層就需要進行協議定制和序列化。
雖然我們說,應用層協議是我們程序員自己定的。但實際上,已經有大佬們針對各種應用場景定義了一些現成的,又非常好用的應用層協議,供我們直接參考使用.HTTP(超文本傳輸協議)就是其中之一。.在互聯網世界中,HTTP是一個至關重要的協議。它定義了客戶端(如瀏覽器)與服務器之間如何通信,以交換或傳輸超文本(如HTML文檔)。也就是說,TP協議是進行網頁交換的,之前我們的協議是在交換Request、Response。
HTTP協議是客戶端與服務器之間通信的基礎。客戶端通過HTTP協議向服務器HTTP初議是一個無連接無狀態的協議,即每次請求都需要建立新的連接,且服務器不會保存客戶端的狀態信息。
認識URL
URL就是統一資源定位符。就是我們俗稱的網址。現如今互聯網中應用的較廣泛的已經是https了

https是服務端與客戶端通信所采用的協議;接下來是域名,未來會被解析成公網IP地址,用于標識服務端所在的主機;接下來就是目標文件在服務端所在主機的位置;再接下來就是目標文件的名稱。目標文件是HTML、CSS、JS等。所以:
- 網絡請求的資源本質上就是一個文件
- 上面的路徑是通過”/"進行分隔的,就是Linux下的路徑結構
所謂HTTP請求,就是將指定主機下的指定文件的內容發送給客戶端。當然文件的種類很多,有圖片、視頻、音頻、腳本文件等等。
前置背景理解:
1. 我們上網的所有行為其實就是將我的數據給別人,或者將別人的數據給我,就是IO。我們刷短視頻時,就是將服務器上的短視頻推送到手機上,在本地播放;瀏覽購物平臺時,就是將網頁、圖片、視頻等資源推送到手機上。登錄、注冊就是在將我們自己的信息推送給服務器。
2 .作為獲取數據的、視頻、音頻、文本等,現在,我們將這些圖片、視頻、音頻、文本等,統一稱為資源。只要是有用的,且是有限的,就叫做資源。
3. 對于這些資源,一定是在互聯網的某一些機器上放著的,當我們要獲取這些資源時,第一步肯定是先要知道這些資源在那一臺服務器上。而要在網絡中確定一臺服務器,就是要知道它的IP地址。另外,除了要知道資源文件在那一臺服務器上,還要知道在這個服務器的哪一個路徑下。所以,確定一份資源,就需要IP地址+路徑,這就是URL。服務器通過URL找到目標資源后,就會將目標資源打開,并通過端口號推送給客戶端。
4. 我們會發現URL中路徑是從/開始的,但是這里的/不一定是Linux中的根目錄。叫做web根目錄,兩者不一定一樣。
服務器通過URL找到目標資源后,打開目標資源,然后需要通過端口號推送給客戶端,但是URL中并沒有體現出端口號。這是因為很多成熟的應用層協議,往往和端口號是強關聯的。也就是只要知道應用層協議名,它的端口號就是默認的。HTTP的端口號默認就是80,HTTPS的端口號默認就是443。并且端口號一般都是1024以內的數。所以,URL中并不需要體現端口號。

這里的登錄信息在現在是省略的。端口號也是省略的。我們知道,要訪問目標服務器一定要有端口號,URL中沒有端口號只是我們看到的,未來瀏覽器會根據協議名將端口號添加上的。HTTP是可以傳參的,?的左邊是要訪問的資源,右邊是要傳遞的參數,參數是格式是key=value。#是片段標識符,不用管。
假設我們現在在瀏覽器上搜索"CSDN",得到的網址是:
https://cn.bing.com/search?q=CSDN&qs=n&form=QBRE&sp=-1&lq=0&pq=csdn&sc=12-4&sk=&cvid=DDBF6D513D3C49C8B465378F2F67B52D?可以看到,有一個q = CSDN,表示的就是搜索時傳遞的參數。
urlencode和urldecode
URL中為了保證格式,是有非常多的特殊字符的,如果我們搜索的關鍵詞中就包含這些特殊字符呢?我們現在搜索一下"://=?/&",得到的網址是:
https://cn.bing.com/search?q=%3A%2F%2F%3D%3F%2F%26&qs=n&form=QBRE&sp=-1&lq=0&pq=%3A%2F%2F%3D%3F%2F%26&sc=12-7&sk=&cvid=770AE2C40DF34124BE46EC996A163494會發現我們搜索的東西變成了這個,這是將我們搜索的關鍵詞進行了編碼,為了避免我們搜索的關鍵詞中的特殊字符與URL中的特殊字符互相影響,導致URL格式解析失敗。這個過程稱為urlencode。服務器端收到URL后,會先將URL解析出來,得到編碼后的URL,需要將編碼后的URL轉換成原先的格式,將編碼后的URL轉換成原先的格式的過程稱為urldecode。
uelencode和urldecode是如何轉換的呢?每一個字符都有ASCII值,實際上就是將其轉成這個特殊字符對應的ASCIl的十六進制。然后從右到左,取4位(不足4位直接處理),每2位做一位,前面加上%,編碼成%XY格式。對于漢字的轉換,就不是使用ASCII值了,可能是根據utf8等進行轉換的
HTTP協議的宏觀格式
http協議是應用層協議,是基于TCP協議的。對于http協議,需要知道兩個問題:
- 協議的格式是什么?
- 如何保證收發完整性?因為TCP是面向字節流的。

請求方法表示的是想向服務器上傳數據,還是從服務器中獲取數據,畢竟我們通過服務器既可以訪問東西,也可以下載東西。請求行的url一般是請求路徑,就是/后面的內容。這里的換行符一般是\r\n。這個HTTP REQUEST實際上就是一個結構體或類。這個結構體或類要進行序列化時,只需要一行一行進行拼接即可。大字符串的分隔符是\r\n。反序列化時,只需要一行一行讀,直到讀到空行,就代表報頭部分讀完了,接下來就是正文了。不過請求正文部分并不一定是/r/n結束,反序列化時要怎么知道正文部分有多長呢?在請求報頭中有一行是Content-Length:XXX\r\n,代表的就是正文部分的長度。所以,HTTP協議自己就能完成序列化和反序列化。HTTP協議為什么要自己完成,而不使用jsoncpp等庫呢?因為HTTP協議是一個獨立協議,它不想依賴任何庫。

響應的格式與請求是十分類似的,可能有些字段不一樣,但是整體的結構是一樣的,這樣兩者可以使用一套序列化和反序列化方法。這個響應正文就是html/css/js、圖片、視頻、音頻等資源!!!
無論什么請求,都會有應答,是有可能請求的資源根本就不存在的,狀態碼表示的是請求時的一些狀態。404就表示請求的資源不存在。404的狀態碼描述就是Not Found。瀏覽器就是一個HTTP協議,或者HTTPS協議的客戶端。未來我們可以寫一個服務器,并按照HTTP的宏觀格式來構建請求和應答,就可以把我們想要的信息直接構建到瀏覽器上了。?
Socket封裝
因為套接字有TCP、UDP,有Linux、Windows的,所以,我們不僅僅簡單地封裝成類,而是使用模板方法模式封裝。
// 基類:提供創建socket的方法
class Socket
{
public:virtual ~Socket() = default;virtual void SocketOrDie() = 0; // 創建套接字virtual void SetSocketOpt() = 0; // 設置套接字選項virtual bool BindOrDie(int port) = 0; // 綁定virtual bool ListenOrDie() = 0; // 設置套接字為監聽狀態virtual int Accept() = 0; // 接受連接virtual void Close(int fd) = 0; // 關閉套接字virtual int Recv(std::string* out) = 0; // virtual int Send(const std::string& in) = 0; // 發送消息
#ifdef WIN// 提供一個創建listensockfd的固定套路void BuildTcpSocket(int port){SocketOrDie();SetSocketOpt();BindOrDie(port);ListenOrDie();}// 提供一個創建listensockfd的固定套路void BuildUdpSocket(){}
#else // Linux// 提供一個創建listensockfd的固定套路void BuildTcpSocket(int port){SocketOrDie();SetSocketOpt();BindOrDie(port);ListenOrDie();}// 提供一個創建listensockfd的固定套路void BuildUdpSocket(){}
#endif
};后序由子類自己實現創建套接字的細節,然后統一調用基類中創建套接字的固定模板接口。我們今天就簡單一點,我們只創建Linux下的TCP套接字。
// 基類:提供創建socket的方法
class Socket
{
public:virtual ~Socket() = default;virtual void SocketOrDie() = 0; // 創建套接字virtual void SetSocketOpt() = 0; // 設置套接字選項virtual bool BindOrDie(int port) = 0; // 綁定virtual bool ListenOrDie() = 0; // 設置套接字為監聽狀態virtual int Accept() = 0; // 接受連接virtual void Close() = 0; // 關閉套接字virtual int Recv(std::string* out) = 0; // 接收消息virtual int Send(const std::string& in) = 0; // 發送消息// 提供一個創建listensockfd的固定套路void BuildTcpSocket(int port){SocketOrDie();SetSocketOpt();BindOrDie(port);ListenOrDie();}
};const int gdefaultsockfd = -1;
const int gbacklog = 8;class TcpSocket : public Socket
{
public:TcpSocket(int sockfd = gdefaultsockfd):_sockfd(sockfd){}virtual ~TcpSocket(){}virtual void SocketOrDie() override{_sockfd = ::socket(AF_INET, SOCK_STREAM, 0);if (_sockfd < 0){LOG(LogLevel::ERROR) << "socket error";exit(SOCKET_ERR);}LOG(LogLevel::DEBUG) << "socket create success: " << _sockfd;}virtual void SetSocketOpt() override{// 暫時為空}virtual bool BindOrDie(int port) override{if (_sockfd == gdefaultsockfd) return false;InetAddr addr(port);int n = ::bind(_sockfd, addr.NetAddr(), addr.NetAddrLen());if (n < 0){LOG(LogLevel::ERROR) << "bind error";exit(SOCKET_ERR);}LOG(LogLevel::DEBUG) << "bind create success: " << _sockfd;return true;}virtual bool ListenOrDie() override{if (_sockfd == gdefaultsockfd) return false;int n = ::listen(_sockfd, gbacklog);if (n < 0){LOG(LogLevel::ERROR) << "listen error";exit(LISTEN_ERR);}LOG(LogLevel::DEBUG) << "listen create success: " << _sockfd;return true;}virtual int Recv(std::string* out) override{char buffer[1024 * 8];auto size = ::recv(_sockfd, buffer, sizeof(buffer) - 1, 0);if (size > 0){buffer[size] = '\0';*out = buffer;}return size;}virtual int Send(const std::string& in) override{auto size = ::send(_sockfd, in.c_str(), in.size(), 0);return size;}virtual int Accept() override{return 0;}virtual void Close() override{if (_sockfd == gdefaultsockfd) return;::close(_sockfd);}
private:int _sockfd;
};int main(int argc, char* argv[])
{if(argc != 2){std::cout << "Usage: " << argv[0] << " port" << std::endl;return 1;}Socket* sk = new TcpSocket();sk->BuildTcpSocket(std::stoi(argv[1]));return 0;
}我們會發現,對于套接字,有時候綁定能成功,有時候會失敗。因為我們在退出服務器時,瀏覽器作為客戶端可能還連著,服務器作為主動退出的哪一方,在TCP協議處會進行四次揮手,在揮手時,服務器端就會處于TIME_WAIT,持續時間一般是60秒到120秒,要想解決這個問題,可以使用系統調用setsockopt。
#include <sys/types.h> /* 基本系統數據類型 */
#include <sys/socket.h> /* Socket 相關頭文件 */int setsockopt(int sockfd, // 套接字文件描述符int level, // 選項的協議層(如 SOL_SOCKET、IPPROTO_TCP)int optname, // 選項名稱(如 SO_REUSEADDR、TCP_NODELAY)const void *optval, // 指向選項值的指針socklen_t optlen // 選項值的長度(字節數)
);virtual void SetSocketOpt() override
{// 保證我們的服務器,在異常斷開之后,可以立即重啟,不會有Bind問題int opt = 1;int n = ::setsockopt(_sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
}未來創建時,統一使用Socket,這種模式成為模板方法模式。我們這里并沒有實現Accept,后面實現。因為HTTP是基于TCP的,所以要有一個TCP服務器。
TcpServer?
TcpServer只負責接收來自客戶端的請求,對請求進行處理通過回調的方法交給HttpServer處理。因為客戶端發過來的報文是根據HTTP的協議的格式的,所以將IO處理交給HttpServer更好。也就是說,TcpServer只負責接收請求,接收到了請求就直接通知HttpServer,由HttpServer去接收客戶端的消息,處理完成后再發送回客戶端。
namespace TcpServerModule
{using namespace SocketModule;using namespace LogMoudule;class TcpServer{private:TcpServer(int port):_listensockp(std::make_unique<TcpSocket>()), _port(port), _running(false){_listensockp->BuildTcpSocket(port);}void Loop(){_running = true;while(_running){// 1. Accept_listensockp->Accept();// 2. 通過回調讓HttpServer去處理請求}_running = false;}~TcpServer(){_listensockp->Close();}private:std::unique_ptr<Socket> _listensockp;int _port;bool _running;};
}接下來完成Accept接口,我們讓這個接口返回套接字類型。因為有一些套接字是負責獲取新連接的,有一些套接字是負責進行IO的。通過Accept接口要獲取兩個信息,一個是進行lO的文件描述符,一個是客戶端的信息。
class Socket; // 聲明using SockPtr = std::shared_ptr<Socket>;因為類Socket中有使用到SockPtr,所以要先聲明,然后將類型SockPtr定義出來。
virtual SockPtr Accept(InetAddr* client) override
{if (!client) return nullptr;struct sockaddr_in peer;socklen_t len = sizeof(peer);int newsockfd = ::accept(_sockfd, CONV(&peer), &len);if (newsockfd < 0){LOG(LogLevel::WARNING) << "accept error";return nullptr;}client->SetAddr(peer, len);return std::make_shared<TcpSocket>(newsockfd);
}void Loop()
{_running = true;while (_running){// 1. AcceptInetAddr clientaddr; // 從Accept接口中獲取客戶端的信息auto sockfd = _listensockp->Accept(&clientaddr);if (sockfd == nullptr) continue;LOG(LogLevel::DEBUG) << "get a new client, info is: " << clientaddr.Addr();// 2. 通過回調讓HttpServer去處理請求}_running = false;
}需要給類InetAddr增加一個使用sockaddr_in構造InetAddr的接口
void SetAddr(const sockaddr_in& client, socklen_t& len)
{_net_addr = client;IpNet2Host();
}接下來就來完成Loop中的回調,因為TcpServer只負責接收請求,所以需要有一個回調函數
namespace TcpServerModule
{using namespace SocketModule;using namespace LogMoudule;// 第一個參數是客戶端的套接字,第二個參數是客戶端信息using tcphandler_t = std::function<bool(SockPtr, InetAddr)>;class TcpServer{public:TcpServer(int port):_listensockp(std::make_unique<TcpSocket>()), _port(port), _running(false){}void InitServer(tcphandler_t handler){_handler = handler;_listensockp->BuildTcpSocket(_port);}void Loop(){_running = true;while(_running){// 1. AcceptInetAddr clientaddr; // 從Accept接口中獲取客戶端的信息auto sockfd = _listensockp->Accept(&clientaddr);if(sockfd == nullptr) continue;LOG(LogLevel::DEBUG) << "get a new client, info is: " << clientaddr.Addr();// 2. 通過回調讓HttpServer去處理請求// 多進程pid_t id = fork();if(id == 0){_listensockp->Close();if(fork() > 0) exit(0);// 將客戶端的文件描述符和信息交給了上層,通過回調由上層進行處理_handler(sockfd, clientaddr);exit(0);}sockfd->Close();waitpid(id, nullptr, 0);}_running = false;}~TcpServer(){_listensockp->Close();}private:std::unique_ptr<Socket> _listensockp;int _port;bool _running;tcphandler_t _handler; // 回調方法};
}HttpServer
整體設計
class HttpServer
{
public:HttpServer(int port):_tsvr(std::make_unique<TcpServer>(port)){}// 處理HTTP請求,這就是回調bool HandlerHttpRequest(SockPtr sockfd, InetAddr client){LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();return true;}// 啟動HTTP服務器void Start(){_tsvr->InitServer([this](SockPtr sockfd, InetAddr client){return this->HandlerHttpRequest(sockfd, client);});_tsvr->Loop();}~HttpServer() {}
private:std::unique_ptr<TcpServer> _tsvr;
};給類Sockfd增加一個成員函數,用于獲取套接字
virtual int Fd() override
{return _sockfd;
}int main(int argc, char* argv[])
{if(argc != 2){std::cout << "Usage: " << argv[0] << " port" << std::endl;return 1;}auto httpserver = std::make_unique<HttpServer>(std::stoi(argv[1]));httpserver->Start();return 0;
}這樣,未來只需要創建好HTTP服務器,然后啟動,就會將HTTP請求處理函數作為TCP服務器的處理函數,然后進入到TCP內部的循環,獲取新連接,一旦有連接了,就會回調HTTP內部處理請求的方法。我們使用瀏覽器去訪問我們的HTTP服務器。

此時http請求處理函數只是簡單打印一下,但是確實是可以看到接收到了請求。
TCP服務器接收到請求后,就會調用HTTP服務器的請求處理函數后,請求處理函數接收客戶端的消息,首先應該檢查報文的完整性,然后再反序列化。但是這里確保完整性之前已經做過了,不是重點,所以我們這里不實現了,只進行反序列化。也就是說,我們直接認為接收到的就是一個完整的請求。在進行反序列化之前,我們先看看TCP服務器接收到的來自客戶端的請求序列化后是什么樣的。
// 處理HTTP請求,這就是回調
bool HandlerHttpRequest(SockPtr sockfd, InetAddr client)
{LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();// 接收客戶端消息,并打印std::string http_request;sockfd->Recv(&http_request);std::cout << http_request; // 字節流請求return true;
}
雖然看起來有很多行,但是實際上Http服務器接收到的就是一個大字符串。其中有一個空行,并且請求正文是空的。現在對里面的一些字段做出簡略的敘述。第一行是請求行,第一個字段是請求方法,常見的就是GET/POST,GET表示請求指定資源,POST表示向服務器提交數據。URI表示的是請求的服務器的資源的路徑,HTTP版本格式一般是HTTP/1.0,HTTP/1.1等。Host表示的是這個請求發給的是那一臺主機上的哪一個端口。Connection表示長鏈接。Upgrade-Insecure-Requests我們不關心。Accept:我們發起HTTP請求是瀏覽器發的,瀏覽器就告訴服務器能接收
什么。我們重點看User-Agent,User-Agent表示的是發起請求的客戶端的信息。使用Windows計算機搜索微信時,看到的就是Windows版的,正是因為有User-Agent。

我們現在先來嘗試返回給客戶端一些信息,也就是服務器作出響應。我們這里直接返回固定格式,無論客戶端請求什么,都返回一個hello world。正確的應該是請求什么返回什么,所以需要對HTTP協議進行定制,這個工作我們后面再做。
const std::string Sep = "\r\n"; // 換行符
const std::string BlankLine = Sep; // 空行class HttpServer
{
public:HttpServer(int port) : _tsvr(std::make_unique<TcpServer>(port)){}// 處理HTTP請求,這就是回調bool HandlerHttpRequest(SockPtr sockfd, InetAddr client){LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();// 接收TCP服務器接收到的客戶端消息,并打印std::string http_request;sockfd->Recv(&http_request);std::cout << http_request; // 字節流請求std::string status_line = "HTTP/1.1 200 OK" + Sep + BlankLine;// 直接返回一個html網頁std::string body = "<!DOCTYPE html>\<html>\<head>\<meta charset = \"UTF-8\">\<title> Hello World</title>\</head>\<body>\<p> Hello World</ p>\</body> </html>";// 將報頭與正文進行拼接std::string httpresponse = status_line + body;// 發送給客戶端sockfd->Send(httpresponse);return true;}// 啟動HTTP服務器void Start(){_tsvr->InitServer([this](SockPtr sockfd, InetAddr client){ return this->HandlerHttpRequest(sockfd, client); });_tsvr->Loop();}~HttpServer() {}private:std::unique_ptr<TcpServer> _tsvr;
};這樣,就完成了一個http的請求和應答。實際上前端的代碼肯定不會混合到C++的代碼中,會將其寫到一個文件當中,然后C++的代碼再去讀取文件。

可以看到,此時客戶端就能夠拿到一個Hello World了。但是現在無論客戶端發送什么請求,都是都是得到一個固定的應答,若想要根據客戶端的要求返回應答,就需要進行協議定制。
接收請求
現在來進行協議定制,我們先來看實現HttpRequest,這個類首先需要提供一個反序列化的函數,因為我們接收到的來自客戶端的消息是字節流的,需要將其反序列化后才能進行處理。并且要注意,我們在反序列化時,除了要進行一行一行分離,對于某些行,特別是第一行內的詳細信息,也是需要分離出來的。我們定義一個字符串截取函數。
// 字符串截取函數,根據sep去截取str,并將截取得到的結果放到out中
// 1. 正常字符串 2. out空串&&返回值是true 3. out空串&&返回值是false
bool ParseOneLine(std::string& str, std::string* out, const std::string& sep)
{auto pos = str.find(sep);if(pos == std::string::npos) return false;*out = str.substr(0, pos);str.erase(0, pos + sep.size());return true;
}這個截取函數主要用它來截取一行。這個字符串截取函數有3種返回結果, 當out不為空串時,說明截取是成功的,當out為空串時,若返回值為true,說明截取到空行了,若返回值為false,說明截取出錯了。
const std::string Sep = "\r\n"; // 換行符
const std::string BlankLine = Sep; // 空行
const std::string LineSep = " "; // 空格
const std::string HeaderLineSep = ": "; // 報頭中k、v的分隔符class HttpRequest
{
private:// 細化請求行的字段void ParseReqLine(std::string& _req_line, const std::string sep){std::stringstream ss(_req_line);ss >> _method >> _uri >> _version;}bool SplistString(const std::string& header, const std::string& sep, std::string* key, std::string* value){auto pos = header.find(sep);if(pos == std::string::npos) return false;*key = header.substr(0, pos);*value = header.substr(pos + sep.size());return true;}bool ParseHeaderkv(){std::string key, value;for(auto& header : _req_header){if(SplistString(header, HeaderLineSep, &key, &value)){_headerkv.insert({key, value});}}return true;}// 解析請求報頭,這里是將每一行數據提取出來bool ParseHeader(std::string& request_str){std::string line;while(true){bool r = ParseOneLine(request_str, &line, Sep);if(r && !line.empty()){_req_header.push_back(line);}else if(r && line.empty()) // 讀到空行了{_blank_line = Sep;break;}else{return false;}}// 現在_req_header中保存的是一行一行的請求報頭,我們要對其進行細化ParseHeaderkv();return true;}
public:HttpRequest() {}~HttpRequest() {}void Deserialize(std::string& request_str) // 反序列化{// 提取出第一行,并細化解析出的字段if(ParseOneLine(request_str, &_req_line, Sep)){// 提取請求行中的詳細字段ParseReqLine(_req_line, LineSep);// 提取出請求報頭中的詳細字段ParseHeader(request_str);// 請求報頭和空行提取完成之后,剩下的就是正文了_body = request_str; }}void Print(){std::cout << "_method: " << _method << std::endl;std::cout << "_uri: " << _uri << std::endl;std::cout << "_version: " << _version << std::endl;for(auto& kv : _headerkv){std::cout << kv.first << " # " << kv.second << std::endl;}std::cout << "_blank_line: " << _blank_line << std::endl;std::cout << "_body: " << _body << std::endl;}
private:std::string _req_line; // 保存請求行std::vector<std::string> _req_header; // 保存請求報頭,這里是一行一行保存std::string _blank_line; // 保存空行std::string _body; // 保存請求正文// 細化我們解析出來的字段std::string _method; // 請求方法std::string _uri; // uristd::string _version;// HTTP版本std::unordered_map<std::string, std::string> _headerkv; // 請求行的k、v結構
};
// 處理HTTP請求,這就是回調
bool HandlerHttpRequest(SockPtr sockfd, InetAddr client)
{LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();// 接收客戶端消息std::string http_request;sockfd->Recv(&http_request); // 字節流消息// 對接收到的字節流消息進行反序列化,并打印HttpRequest req;req.Deserialize(http_request);req.Print();return true;
}現在我們使用瀏覽器訪問我們的服務器,看看能否反序列化成功。

可以看到,反序列化成功了。
web根目錄與默認首頁
一個HTTP協議要被具體實現的話,是需要有web根目錄和默認首頁的。現在,HTTP服務器已經成功地將拿到的請求進行了反序列化。請求的資源是uri的路徑決定的,之前說過,uri中的/稱為web根目錄。對于HTTP協議,如果有人想將HTTP協議寫成服務,就需要構建一個HttpServer自己的家目錄。然后將屬于這個服務的網頁信息放到家目錄里面。
我們在HttpServer下面創建一個目錄wwwroot,這個wwwroot就是這個HttpServer所對應的家目錄。任何的網站,或者站點形式的后端服務,若想被別人訪問,這個站點就必須要有一個默認首頁,叫做index.html。這里的wwwroot就是web根目錄,是被隱藏的,名字可以隨便取。index.html這個名字一般是約定俗成的。會發現,www.baidu.com和www.baidu.com/index.html進入的都是百度的首頁所以,百度的首頁就叫index.html。
我們之前在進行響應時,直接將前端代碼寫這肯定是不對的,我們需要一些專門的網頁內容。我們給index.html中寫入HTML的代碼:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Hello World</title>
</head>
<body><h1>Hello World</h1>
</body>
</html>當客戶端發起請求時,只請求/,或請求首頁,就需要將文件中的內容發過去。現在完成了反序列化,用戶需要的東西在uri中。所以,在反序列化完成之后,我們將uri打印出來。
// HttpRequest成員函數
std::string Uri()
{return _uri;
}// 處理HTTP請求,這就是回調
bool HandlerHttpRequest(SockPtr sockfd, InetAddr client)
{LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();// 接收客戶端消息std::string http_request;sockfd->Recv(&http_request); // 字節流消息// 對接收到的字節流消息進行反序列化,并打印HttpRequest req;req.Deserialize(http_request);std::cout << "用戶想要: " << req.Uri() << std::endl;return true;
}此時可以在瀏覽器中 IP地址:端口號/...,加入想要資源的路徑。所以,這個uri就是客戶端想通過這次HTTP請求獲取服務器上的什么資源。如果只有/,就是請求默認首頁,也就是wwwroot/index.html,如果傳入的路徑是/a/b/c.html的話,需要將wwwroot/a/b/c.html交給客戶端。注意:返回的是網頁的內容。所以,我們需要給uri拼接上web根目錄的路徑,在這里就是wwwroot。
const std::string defaulthomepage = "wwwroot"; // web根目錄名稱// 細化請求行的字段
void ParseReqLine(std::string& _req_line, const std::string sep)
{std::stringstream ss(_req_line);ss >> _method >> _uri >> _version;// 給uri添加上web根目錄_uri = defaulthomepage + _uri;
}這樣,我們的服務往后找所有的資源,都不會到Linux根目錄下找了,而是到wwwroot下面找了?
發送應答
想要響應客戶端的請求,HttpRequest就需要有一個獲取客戶端想要的資源的接口。
// 讀取_uri路徑下的網頁信息
std::string GetContent()
{std::string content;std::ifstream in(_uri);if (!in.is_open()) return std::string();std::string line;while (std::getline(in, line)){content += line;}in.close();return content;
}const std::string http_version = "HTTP/1.0"; // HTTP版本?對于HTTP版本一般是固定的
class HttpResponse
{
public:HttpResponse():_version(http_version), _blank_line(Sep){}~HttpResponse() {}// 建立應答void Build(HttpRequest& req){// 獲取用戶想要的資源std::string content = req.GetContent();if(content.empty()){// 用戶請求的資源不存在}else{}}
private:std::string _resp_line; // 狀態行std::vector<std::string> _resp_header; // 響應報頭std::string _blank_line; // 空行std::string _body; // 響應正文// 細化我們解析出來的字段std::string _version; // HTTP版本int _status_code; // 狀態碼std::string _status_desc; // 狀態碼描述
};無論用戶請求的資源是否存在,都需要設置狀態碼,所以我們需要先了解一下狀態碼。

對于具體的狀態碼,我們這里只看兩個,后序再詳細介紹。

打開文件成功,就是200;打開文件失敗,可能會有多個原因,今天我們就認為是資源不存在,狀態碼是404。
class HttpResponse
{
private:std::string Code2Desc(int code){switch(code){case 200:return "OK";case 404:return "Not Found";default:return std::string();}}
public:HttpResponse():_version(http_version), _blank_line(Sep){}~HttpResponse() {}// 建立應答void Build(HttpRequest& req){// 獲取用戶想要的資源std::string content = req.GetContent();if(content.empty()){// 用戶請求的資源不存在_status_code = 404;}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);}
private:std::string _resp_line; // 狀態行std::vector<std::string> _resp_header; // 響應報頭std::string _blank_line; // 空行std::string _body; // 響應正文// 細化我們解析出來的字段std::string _version; // HTTP版本int _status_code; // 狀態碼std::string _status_desc; // 狀態碼描述
};可以看到,請求和應答中都要HTTP版本,它們分別是什么意思呢?請求中的HTTP版本指的是瀏覽器中采用的HTTP協議的版本,應答中的HTTP版本指的是服務器中采用的HTTP協議的版本。HTTP作為一個成熟的協議,雙方在進行請求和應答交換時,也要交換一下雙方的版本信息,因為雙方客戶端和服務器的版本可能不一致。以微信舉例,假設微信1.0的客戶端只有聊天功能,2.0的客戶端有朋友圈功能,3.0的客戶端有語言聊天功能,微信有非常多的用戶群體,這些用戶的版本必然不可能完全一致,服務器在更新的過程中,一定要保證新老版本的客戶端的兼容性。所謂兼容性,就是1.0的客戶端向服務器發出請求時,服務器不應該給它提供朋友圈和語言聊天功能。所以,雙方交換一下版本,就能讓服務器知道客戶端的這個請求是否合法。所以,雙方在協議中交換一下版本是對客戶端版本進行保護的一個非常重要的做法。當然,版本對我們今天來說并不重要。
我們現在需要一個404的頁面,就是在目錄wwwroot下面創建一個文件404.html。
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>404 Not Found</title><style>body {font-family: Arial, sans-serif;text-align: center;padding: 50px;background-color: #f9f9f9;color: #333;}h1 {font-size: 50px;margin-bottom: 20px;}p {font-size: 20px;margin-bottom: 30px;}a {color: #0066cc;text-decoration: none;}a:hover {text-decoration: underline;}</style>
</head>
<body><h1>404</h1><p>Oops! The page you're looking for doesn't exist.</p><p>You may have mistyped the address or the page has been moved.</p><p><a href="/">Go back to the homepage</a></p>
</body>
</html>當訪問資源不存在時,我們就將要訪問資源的路徑改為404頁面的路徑。給HttpRequest增加一個成員函數,用于修改_uri。
void SetUri(const std::string newuri)
{_uri = newuri;
}const std::string page404 = "wwwroot/404.html";// 404頁面的路徑給HttpResponse增加一個成員變量,表示要給客戶端返回的內容。
std::string _content; // 要給客戶端返回的內容// 建立應答
void Build(HttpRequest& req)
{// 獲取用戶想要的資源_content = req.GetContent();if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent();}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);
}HttpResponse需要的內容基本上都有了,現在就可以來完成序列化的工作了。
void Serialize(std::string* resp_str)
{// 拼接狀態行_resp_line = _version + LineSep + std::to_string(_status_code) + LineSep + _status_desc + Sep;_body = _content;// 序列化*resp_str = _resp_line;for (auto& line : _resp_header){*resp_str += (line + Sep);}*resp_str += _blank_line;*resp_str += _body;
}有了應答,并且序列化完成后,就可以發送給客戶端了。?
// 處理HTTP請求,這就是回調
bool HandlerHttpRequest(SockPtr sockfd, InetAddr client)
{LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();// 接收客戶端消息std::string http_request;sockfd->Recv(&http_request); // 字節流消息// 對接收到的字節流消息進行反序列化,并打印HttpRequest req;req.Deserialize(http_request);HttpResponse resp;resp.Build(req);std::string resp_str;resp.Serialize(&resp_str);// 將序列化后的應答發送給客戶端sockfd->Send(resp_str);return true;
}現在,我們使用瀏覽器訪問一下我們的服務器。

![]()
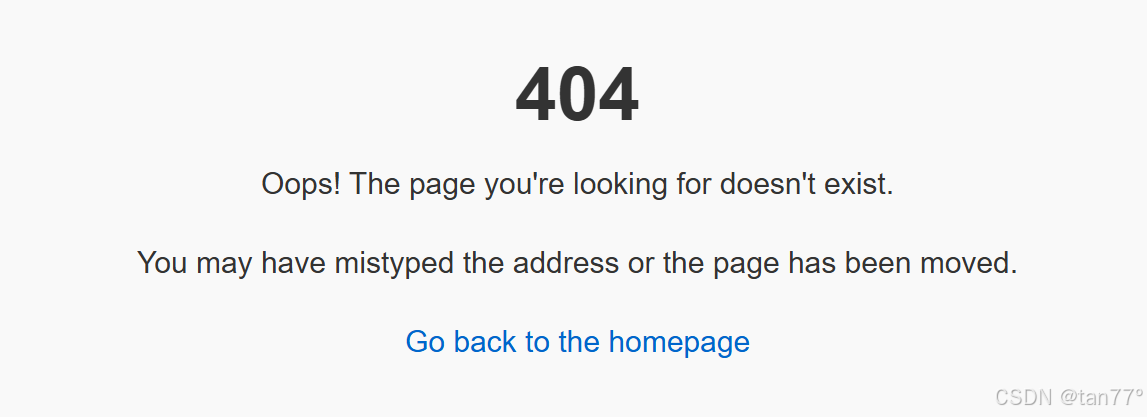
此時就可以拿到網頁信息了。所以,拿到的所有網頁信息,都是從文件中來的。當用戶訪問的資源路徑是/時,其實就是訪問首頁,所以我們要對/進行特殊處理。另外,在wwwroot這個目錄中,除了有網頁之外,還可能有圖片、目錄等,對于每一個子目錄,里面也應該要有index.html。所以,我們只要判斷一下_uri的最后使用是/,若是,即可在后面加上一個index.html。
const std::string firstpage = "index.html"; // 默認首頁名稱// 建立應答
void Build(HttpRequest& req)
{// 對_uri末尾是 / 進行特殊處理std::string uri = req.Uri();if (uri.back() == '/'){uri += firstpage;req.SetUri(uri);}// 獲取用戶想要的資源_content = req.GetContent();if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent();}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);
}
完善頁面
在這里,我們會使用一些前端的代碼讓我們的Http服務器更加完善。
現在已經使用代碼將HTTP一個完整的過程走完了。前端開發就是在寫wwwroot里面的內容,后端開發是寫wwroot外面的內容。wwwroot里面的內容雖然上傳到了Linux服務器上,但是最終是要發送給瀏覽器,由瀏覽器對頁面進行解釋或渲染呈現給用戶的。我們在訪問一個網站時,并不會在搜索框內搜索uri,而是點擊網頁上的內容,瀏覽器會根據點擊的內容形成新的uri,然后向目標服務器發送請求。這是怎么完成的呢?我們使用我們的代碼模擬一下這個過程HTML會指導瀏覽器做出很多的解釋動作,我們現在來看看HTML中的A標簽。
<a href="目標URL">可點擊的文本或圖像</a>這個URL將來填的就是/后面的內容,其實就是uri。瀏覽器會對這個HTML語句做解釋,變成一個可以點擊的鏈接。點擊后,瀏覽器會將當前網頁的目標服務器的IP地址和端口號拼在前面,URL寫在后面,形成一個完整的請求,并發送給服務器。就可以拿到另一個網頁了。所以我們要訪問其他網頁時,不需要一直輸入。所以,所有的跳轉就是向HTTP服務發起HTTP請求。
我們將我們的首頁修改一下,讓其變成一個電商網站的首頁。
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>簡單電商網站</title><style>body {font-family: Arial, sans-serif;margin: 0;padding: 0;background-color: #f7f7f7;}.header {background-color: #333;color: #fff;padding: 10px 20px;display: flex;justify-content: space-between;align-items: center;}.header h1 {margin: 0;font-size: 2em;}.header nav ul {list-style: none;margin: 0;padding: 0;display: flex;}.header nav ul li {margin-left: 20px;}.header nav ul li a {color: #fff;text-decoration: none;font-size: 1.2em;}.header nav ul li a:hover {text-decoration: underline;}.main {padding: 20px;}.product-grid {display: grid;grid-template-columns: repeat(auto-fit, minmax(200px, 1fr));gap: 20px;}.product-card {background-color: #fff;padding: 10px;border: 1px solid #ddd;border-radius: 5px;text-align: center;}.product-card img {max-width: 100%;height: auto;border-radius: 5px;}.product-card h3 {margin: 10px 0;font-size: 1.2em;}.product-card p {color: #666;font-size: 0.9em;margin-bottom: 10px;}.product-card button {padding: 5px 10px;background-color: #007bff;color: #fff;border: none;border-radius: 5px;cursor: pointer;font-size: 1em;}.product-card button:hover {background-color: #0056b3;}.footer {background-color: #333;color: #fff;padding: 10px 20px;text-align: center;}</style>
</head>
<body><header class="header"><h1>簡單電商網站</h1><nav><ul><li><a href="#">首頁</a></li><li><a href="#">產品分類</a></li><li><a href="#">登錄</a></li><li><a href="#">注冊</a></li></ul></nav></header><main class="main"><h2>熱門產品</h2><div class="product-grid"><div class="product-card"><img src="#" alt="產品1"><h3>產品1</h3><p>這是產品1的描述信息。</p><button>加入購物車</button></div><div class="product-card"><img src="#" alt="產品2"><h3>產品2</h3><p>這是產品2的描述信息。</p><button>加入購物車</button></div><div class="product-card"><img src="#" alt="產品3"><h3>產品3</h3><p>這是產品3的描述信息。</p><button>加入購物車</button></div><!-- 可以繼續添加更多產品卡片 --></div></main><footer class="footer"><p>版權所有 ? 2025 簡單電商網站</p></footer>
</body>
</html>再設計一個登錄頁面和一個注冊頁面,分別保存在login.html和register.html。
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>登錄頁面</title><style>body {font-family: Arial, sans-serif;background-color: #f7f7f7;margin: 0;padding: 0;}.login-container {width: 300px;margin: 100px auto;padding: 20px;background-color: #fff;border: 1px solid #ddd;border-radius: 5px;box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);}.login-container h2 {text-align: center;margin-bottom: 20px;}.login-container form {display: flex;flex-direction: column;}.login-container form label {margin-bottom: 5px;}.login-container form input[type="text"],.login-container form input[type="password"] {padding: 10px;margin-bottom: 10px;border: 1px solid #ddd;border-radius: 5px;}.login-container form button {padding: 10px;background-color: #007bff;color: #fff;border: none;border-radius: 5px;cursor: pointer;}.login-container form button:hover {background-color: #0056b3;}.register-link {text-align: center;margin-top: 20px;}.register-link a {color: #007bff;text-decoration: none;}.register-link a:hover {text-decoration: underline;}</style>
</head>
<body><div class="login-container"><h2>登錄</h2><!-- http://8.137.19.140:8999/login --><form action="/login" method="POST"><label for="username">用戶名:</label><input type="text" id="username" name="username" required><label for="password">密碼:</label><input type="password" id="password" name="password" required><button type="submit">登錄</button></form><div class="register-link">沒有賬號?<a href="/register.html">立即注冊</a></br><a href="/">回到首頁</a></div></div>
</body>
</html><!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>注冊頁面</title><style>body {font-family: Arial, sans-serif;background-color: #f7f7f7;margin: 0;padding: 0;}.register-container {width: 300px;margin: 100px auto;padding: 20px;background-color: #fff;border: 1px solid #ddd;border-radius: 5px;box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);}.register-container h2 {text-align: center;margin-bottom: 20px;}.register-container form {display: flex;flex-direction: column;}.register-container form label {margin-bottom: 5px;}.register-container form input[type="text"],.register-container form input[type="password"],.register-container form input[type="email"] {padding: 10px;margin-bottom: 10px;border: 1px solid #ddd;border-radius: 5px;}.register-container form button {padding: 10px;background-color: #007bff;color: #fff;border: none;border-radius: 5px;cursor: pointer;}.register-container form button:hover {background-color: #0056b3;}.login-link {text-align: center;margin-top: 20px;}.login-link a {color: #007bff;text-decoration: none;}.login-link a:hover {text-decoration: underline;}</style>
</head>
<body><div class="register-container"><h2>注冊</h2><form action="/register" method="post"><label for="username">用戶名:</label><input type="text" id="username" name="username" required><label for="email">郵箱:</label><input type="email" id="email" name="email" required><label for="password">密碼:</label><input type="password" id="password" name="password" required><label for="confirm-password">確認密碼:</label><input type="password" id="confirm-password" name="confirm-password" required><button type="submit">注冊</button></form><div class="login-link">已有賬號?<a href="/login">立即登錄</a><br/><a href="/">回到首頁</a></div></div>
</body>
</html>現在,我們修改一下上面的部分代碼,讓它們能夠通過A標簽實現頁面轉換。
<h1>簡單電商網站< / h1>
<nav><ul><li><a href = "#">首頁< / a>< / li><li><a href = "#">產品分類< / a>< / li><li><a href = "/login.html">登錄< / a>< / li><li><a href = "/register.html">注冊< / a>< / li></ul>
</nav></form>
<div class="register-link">沒有賬號?<a href="/register.html">立即注冊</a></br><a href="/">回到首頁</a>
</div></form>
<div class="login-link">已有賬號?<a href="/login.html">立即登錄</a><br/><a href="/">回到首頁</a>
</div>修改了網頁信息后,不需要重啟服務器,只需要刷新一下頁面即可。現在,我們就可以點擊頁面的內容進行頁面跳轉了。每次點擊后,瀏覽器就會向服務器發送一個新頁面的請求。HTTP協議叫做超文本傳輸協議,其實就是將一個特定目錄下的內容進行返回。
HTTP常見Header
- Content-Type:數據類型(text/html 等)
- Content-Length:Body的長度
- Host:客戶端告知服務器,所請求的資源是在哪個主機的哪個端口上;
- User-Agent:聲明用戶的操作系統和瀏覽器版本信息;
- referer:當前頁面是從哪個頁面跳轉過來的;
- Location:搭配3xx狀態碼使用,告訴客戶端接下來要去哪里訪問;
- Cookie:用于在客戶端存儲少量信息.通常用于實現會話(session)的功能;
接下來,我們要結合代碼,對HTTP進行細化認識了。實際上就是完善應答中的報頭。我們給Response增加一個成員變量和成員函數。
std::unordered_map<std::string, std::string> _header_kv; // 保存報頭void SetHeader(const std::string& k, const std::string& v)
{_header_kv[k] = v;
}往后只要我們定義好了一個報頭,就調用SetHeader函數將其放到_header_kv中,然后在構建應答時,也就是Build函數中,再統一將所有的報頭放到_resp_header中。
Content-Length
當有正文時,一定要帶Content-Length,無論是請求,還是應答。我們剛剛的代碼中,應答中并沒有這個字段,那瀏覽器是怎么成功讀取到服務器上的網頁的呢?瀏覽器是一個非常大,非常完善的項目,所以,即使應答時不帶上正文長度的字段,瀏覽器也是可以將正文全部讀完的。但是我們還是要盡量規范,所以,我們給我們的應答加上Content-Length字段。
// 建立應答
void Build(HttpRequest& req)
{// 對_uri末尾是 / 進行特殊處理std::string uri = req.Uri();if (uri.back() == '/'){uri += firstpage;req.SetUri(uri);}// 獲取用戶想要的資源_content = req.GetContent();if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent();}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);// 構建報頭if (!_content.empty()){SetHeader("Content-Length", std::to_string(_content.size()));}// 將報頭放到_resp_header中for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}
}Content-Type

我們會發現,我們的首頁是加載不出來圖片的。這是因為我們的服務器中并沒有圖片,我們給我們的服務器添加上幾張圖片,看看不能把顯示出來。在wwwroot中創建一個目錄image,將圖片放到image中。然后,我們只需要在首頁的HTML代碼中找到img標簽,將圖片的路徑填入即可。
<img src="/image/1.jpg" alt="產品1"><img src="/image/2.jpg" alt="產品2"><img src="/image/3.jpg" alt="產品3">未來瀏覽器除了要請求網頁,還會請求圖片,請求圖片的請求由瀏覽器自己發起。此時會發現還是無法顯示出來。
瀏覽器客戶端向服務器發起請求后,得到了一個網頁信息,然后瀏覽器就會根據網頁信息進行渲染,也就是對網頁中的標簽進行解釋,當這個網頁中有圖片時,也就是說這張圖片是瀏覽器需要的,但是瀏覽器本地并沒有這幾張圖片,所以瀏覽器會自動地發起請求圖片的請求,因為有3張圖片,所以要構建3個請求。
http://8.137.19.140:8888/image/1.jpg
http://8.137.19.140:8888/image/2.jpg
http://8.137.19.140:8888/image/3.jpg然后將請求得到的3張圖片加上原先的網頁,構成一個新的網頁,然后顯示出來。所以,一張網頁,不是一個簡單的html文件,而是可能有多張資源構成(html+圖片視頻等!)。
可是有了請求,為什么看不到圖片呢?
1.?在GetContent中,是以文本方式直接讀的而圖片是所以對于二進制的數據,不能按照字符串來讀。
// 讀取_uri路徑下的網頁信息, 以二進制形式讀取
std::string GetContent()
{std::string content;std::ifstream in(_uri, std::ios::binary);if (!in.is_open()) return std::string();in.seekg(0, in.end);int filesize = in.tellg();in.seekg(0, in.beg);content.resize(filesize);in.read((char*)content.c_str(), filesize);in.close();return content;
}此時就可以看到圖片了。通過發送圖片,我們知道了瀏覽器可能接收到的內容包括:
- html、css、js
- 圖片
- 視頻、可執行程序(下載任務)
所以,HTTP叫做超文本協議,意思就是不僅僅可以發送文本。既然瀏覽器可能受到這么多的內容,剛剛的應答中只有一個Content-Length,正文的長度,并沒有告訴客戶端正文是什么東西。瀏覽器比較強,它能夠識別出發送過來的內容,但是作為HTTP服務器,還是告訴客戶端發送過去的是圖片,還是視頻,還是html。所以,應答中需要帶Content-Type字段。當然,如果沒有正文,Content-Length和Content-Type都可以不用帶。HTTP服務器是根據打開的文件的后綴知道的。
Content-Type中的內容需要根據HTTP Content-type對照表來填寫,我們這里就看幾個常見的。

Http服務器是根據要發送的資源的后綴來決定Content-Tyoe中填寫什么的。所以,我們可以定義一個函數,來獲取要訪問資源的后追。
// 獲取要訪問資源的后綴
std::string Suffix()
{auto pos = _uri.rfind(".");if (pos == std::string::npos) return std::string(".html");else return _uri.substr(pos);
}// 確定Content-Type要填寫什么
std::string Suffix2Desc(const std::string& suffix)
{if (suffix == ".html")return "text/html";else if (suffix == ".jpg")return "application/x-jpg";elsereturn "text/html";
}// 建立應答
void Build(HttpRequest& req)
{// 對_uri末尾是 / 進行特殊處理std::string uri = req.Uri();if (uri.back() == '/'){uri += firstpage;req.SetUri(uri);}// 獲取用戶想要的資源_content = req.GetContent();if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent();}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);// 構建報頭// Content-Lengthif (!_content.empty()){SetHeader("Content-Length", std::to_string(_content.size()));}// Content-Typestd::string mime_type = Suffix2Desc(req.Suffix());SetHeader("Content-Type", mime_type);// 將報頭放到_resp_header中for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}
}Host
當客戶端向一個Http服務器發送請求時,有可能請求的這個資源并不在接收到請求的這個Http服務器上,而在另一臺Http服務器上,此時接收到請求的Http服務器就會有客戶端的功能,給提供資源的Http服務器發送請求,拿到資源后再發送給客戶端。我們稱接收到請求的這個服務器稱為代理服務器。代理服務器在這個過程中,只負責接收客戶端發過來的請求,以及最后將應答發送回去。所以,Host這個Header是有必要存在的,有了它才能讓代理服務器找到提供資源的服務器。在一些大公司中,提供資源的Http服務器可能會有非常多,此時就可以弄一臺代理服務器,再弄一臺服務器專門保存提供資源的這些服務器的信息,如IP地址和端口號等,當提供資源的服務器上線了,就將自己的端口號等信息交給保存信息的服務器,這樣代理服務器需要資源時,就可以采用一些策略,有選擇性地從保存信息的服務器中獲取提供資源的服務器的IP地址和端口號,就可以拿到資源了。這樣可以實現轉發和負載均衡。這些服務器統稱為集群或機房。這與進程池是類似的,代理服務器就相當于進程池的父進程,進程池中父進程與子進程通信是基于管道的,管道就有文件描述符,現在代理服務器與提供資源的服務器通信時,是基于套接字的,也是文件描述符,所以,是可以復用之前進程池的代碼的。
結論:Http服務器可以給別人提供服務,也可以作為代理服務器發起請求。
當我們向文件當中寫入和讀取結構化數據時,其實也是可以使用序列化和反序列化的。管道也是一個文件,所以也是可以進行序列化和反序列化的。對于數據塊,就是將數據保存到文件當中,當要使用到里面的數據時,就會將數據從文件中重新讀出來,所以,數據庫軟件是需要設計自己的序列化和反序列化方案的。這就是數據庫的原理。
這個代理服務器不僅僅可以在公司的后端,也可以在客戶端。正常客戶端請求時直接向服務器發送請求,當代理服務器在客戶端時,客戶端發出的請求會被這個代理服務器劫持,由這個代理服務器去請求。代理服務器只做業務處理,不做轉發,所以代?理服務器的壓力將較于做業務處理的服務器會小一些,但是一些大公司仍然可能會有多個代理服務器。www.baidu.com是百度的域名,未來域名解析后,會隨機獲得一個代理服務器的IP地址和端口號。Host存在的意義就是當接收到請求的這個Http服務器可能不做業務處理,此時就會根據客戶端發過來的Host進行二次請求。
Referer
假設我們當前在首頁,然后我們點擊登錄,此時就會向服務器發起請求,請求登錄頁面的頁面信息,在這個請求中,請求報文中就會有Referer,內容就是/wwwroot/index.html,表示上一個頁面是首頁。有了Referer之后,就可以做一些權限管理了,比方說某一些頁面只允許從某些特定的頁面跳轉過去。這個字段只有請求報頭中有。
Location
只有在應答報頭中有。因為它需要搭配3xx的狀態碼使用,所以我們看看狀態碼。
HTTP狀態碼
Http的狀態碼是服務器應答回去的一個數字,表示本次請求的情況。Http請求無論結果如何,都會有狀態碼。為了表示各種錯誤,所以狀態碼分為了5個類別。這里只看一些常見的狀態碼。

| 狀態碼 | 含義 | 應用樣例 |
|---|---|---|
| 100 | Continue | 上傳大文件時,服務器告訴客戶端可以繼續上傳 |
| 200 | OK | 訪問網站首頁,服務器返回網頁內容 |
| 201 | Created | 發布新文章,服務器返回文章創建成功的信息 |
| 204 | No Content | 刪除文章后,服務器返回"無內容"表示操作成功 |
| 301 | Moved Permanently | 網站換域名后,自動跳轉到新域名;搜索引擎更新網站鏈接時使用 |
| 302 | Found 或 See Other | 用戶登錄成功后,重定向到用戶首頁 |
| 304 | Not Modified | 瀏覽器緩存機制,對未修改的資源返回 304 狀態碼 |
| 307 | Temporary Redirect | 臨時重定向資源到新的位置(較少使用) |
| 308 | Permanent Redirect | 永久重定向資源到新的位置(較少使用) |
| 400 | Bad Request | 填寫表單時,格式不正確導致提交失敗 |
| 401 | Unauthorized | 訪問需要登錄的頁面時,未登錄或認證失敗 |
| 403 | Forbidden | 嘗試訪問你沒有權限查看的頁面 |
| 404 | Not Found | 訪問不存在的網頁鏈接 |
| 500 | Internal Server Error | 服務器崩潰或數據庫錯誤導致頁面無法加載 |
| 502 | Bad Gateway | 使用代理服務器時,代理服務器無法從上游服務器獲取有效響應 |
| 503 | Service Unavailable | 服務器維護或過載,暫時無法處理請求 |
1xx:假設瀏覽器要向服務器上傳一個大文件,不可能將大文件和請求一起發送給服務器,而是先告訴服務器自己要上傳一個大文件,服務器就會有應答,比分說服務器的應答是同意客戶端上傳,應答中的狀態碼就可以設置為100。瀏覽器受到應答,發現狀態碼是100后,就會上傳大文件。
Http規定的狀態碼非常詳細,但是很多情況下,請求正常處理完畢時,返回的都是200,即使文章發布成功,也可能并不會使用專門的201,而是使用200。
重定向的場景:
- 一些視頻網站在試看結束時,可能會自動跳轉到付費頁面
- 沒有登錄就去訪問某個網站時,當點擊了某些選項后,會自動跳轉到登錄頁面
- 有時候我們在訪問A網站,會突然跳轉到B網站
4xx::服務端的資源肯定是有限的,當客戶端提出了一個非法請求時,這時候錯誤是在于客戶端的。因為并不是服務端不給客戶端提供服務。
5xx:服務器的錯誤可能就是構建應答失敗了、序列化失敗了、創建進程失敗了、打開文件失敗了等等。
為什么瀏覽器,或者說前端對于這些狀態碼的遵守并不是特別好?現在我們上網基本上都是使用APP,每個人通過自己的APP就可以定向地訪問到自己需要的服務了。在以前,大部分人上網使用的都是瀏覽器,打開瀏覽器后,打開的第一個軟件是搜索引擎,并且使用的也是搜索引擎。所以,以電腦為主要上網方式的情況下,瀏覽器就是一個非常重要的軟件。在全球范圍內,擁有流量入口的服務叫做搜索引擎。在當時,瀏覽器所帶來的流量是僅次于OS的。所以當時很多的互聯網公司都會做自己的瀏覽器,等到瀏覽器有了一定量的用戶規模之后,再做自己的搜索引擎。 瀏覽器的主要功能是對html、css、js、http請求等做出解釋的一個客戶端,既然是一個客戶端,所以它也要參與網絡協議。 網絡協議是需要比較權威的公司去制定的, 但是在瀏覽器這里,并沒有比較權威的公司,所以對于http的狀態碼定制不同瀏覽器是不完全相同的。所以前端工程師在寫完前端代碼(HTML)后都要做一個工作,兼容性測試。測試不同瀏覽器之下這份代碼是否都能達到預期。也可能會根據不同的瀏覽器寫出不同的代碼。對于HTML都是如此,對于http的狀態碼就更不用說了。所以,有一些后端工程師并不關心狀態碼,可能返回的狀態碼都是200,因為瀏覽器并不關心狀態碼,只關心應答的正文部分。
我們重點看重定向狀態碼。因為只要重定向狀態碼會搭配報頭Location使用。
| 狀態碼 | 含義 | 是否為臨時重定向 | 應用場景 |
|---|---|---|---|
| 301 | Moved Permanently | 否 (永久重定向) | 網站換域名后,自 動跳轉到新域名; 搜索引擎更新網站 鏈接時使用 |
| 302 | Found或See Other | 是 (臨時重定向) | 用戶登錄成功后, 重定向到用戶首頁 |
| 307 | Temporary Redirect | 是 (臨時重定向) | 臨時重定向資源到 新的位置(較少使 用) |
| 308 | Permanent Redirect | 否 (永久重定向) | 永久重定向資源到 新的位置(較少使 用) |
有一批狀態碼是所有瀏覽器都要支持的,即3開頭的狀態碼。我們重點看301和302。
什么是臨時重定向,什么是永久重定向呢?
我們舉一個例子幫助理解。假設現在學校的東門有一家包子店,從學校到這家包子店要經過一條馬路,現在,馬路在維修,有很多煙塵,所以包子店的老板臨時將包子店搬到了西門,并且在原來包子店的門口貼了一個告示,說明包子店臨時搬到西門。過了2個月,東門的路修好了,包子店老板發現搬到西門后生意比原先在東門時還要好,所以就又到原先東門的點門口貼了一張告示,說明包子店永久搬到西門。包子店臨時搬到西門時,想吃包子的同學第一時間去的店肯定是東門的店,因為只說了是臨時,不確定什么時候搬回來,這叫臨時重定向,也就是提供服務的人只是臨時搬過去了,每次請求時還是要請求老的服務,如果老服務恢復了就直接進行,否則就跳轉過去即可;而永久搬到西門后,想吃包子的同學第一時間肯定是去西門的店,這叫永久重定向。
我們來驗證一下重定向的功能。之前代碼中的Build函數是根據客戶端的請求HttpRequest構建應答HttpResponse的。HttpResponse中有很多字段,現在我們不那么麻煩,對于任何請求,我們都直接添加一個重定向的報頭。
std::string Code2Desc(int code)
{switch (code){case 200:return "OK";case 404:return "Not Found";case 301:return "Moved Permanently";case 302:return "Found";default:return std::string();}
}HTTP狀態碼301和302都依賴于Location選項。
// 建立應答
void Build(HttpRequest& req)
{// 不管req是什么,直接構建一個重定向的應答_status_code = 302;_status_desc = Code2Desc(_status_code);SetHeader("Location", "https://www.baidu.com");for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}
}會發現,此時無論是訪問這個服務端之下的哪一個網頁,都會直接跳轉到百度的首頁。所以,當瀏覽器發現接收到的應答中狀態碼是302時,就會自動跳轉到Location對應的地址處。原理:當瀏覽器向我的服務器發送請求時,接收到的應答中的狀態碼是302,此時瀏覽器會自動發起二次請求,這是根據Location發送的,此時是請求百度的服務器上的數據,所以看到的就是百度的首頁。
我們也可以重定向到我們自己的網頁,但是要注意,重定向時網頁的路徑一定要帶全。
// 建立應答
void Build(HttpRequest& req)
{// 不管req是什么,直接構建一個重定向的應答_status_code = 302;_status_desc = Code2Desc(_status_code);SetHeader("Location", "http://47.113.120.114:8080/register.html");for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}
}重定向到我們自己的網頁這樣寫是有問題的。這樣會導致重定向次數太多。這里重定向到我們自己的服務器是會造成類似于遞歸的錯誤的,因為重定向到register.html后,就會建立應答,建立應答時又會重定向到register.html,導致重定向次數太多。
若想讓其重定向到我們服務器自己的頁面,可以這樣:
// 建立應答
void Build(HttpRequest& req)
{// 只有當請求的是首頁時,才進行重定向,并且重定向后直接returnstd::string uri = req.Uri();if (uri.back() == '/'){_status_code = 302;_status_desc = Code2Desc(_status_code);SetHeader("Location", "http://47.113.120.114:8080/register.html");for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}return;}// 對_uri末尾是 / 進行特殊處理uri = req.Uri();if (uri.back() == '/'){uri += firstpage;req.SetUri(uri);}// 獲取用戶想要的資源_content = req.GetContent();if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent();}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);// 構建報頭// Content-Lengthif (!_content.empty()){SetHeader("Content-Length", std::to_string(_content.size()));}// Content-Typestd::string mime_type = Suffix2Desc(req.Suffix());SetHeader("Content-Type", mime_type);// 將報頭放到_resp_header中for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}
}此時當我們訪問我們服務器的首頁時,就可以重定向到注冊頁面了。并且我們會發現,301和302使用起來是沒有區別的。
HTTP狀態碼301(永久重定向):
- 當服務器返回HTTP 301狀態碼時,表示請求的資源已經被永久移動到新的位置。
- 在這種情況下,服務器會在響應中添加一個Location 頭部,用于指定資源的新位置。這個Location 頭部包含了新的URL 地址,瀏覽器會自動重定向到該地址。
HTTP狀態碼302(臨時重定向):
- 當服務器返回HTTP302狀態碼時,表示請求的資源臨時被移動到新的位置。
- 同樣地,服務器也會在響應中添加一個Location頭部來指定資源的新位置。瀏覽器會暫時使用新的URL進行后續的請求,但不會緩存這個重定向。
總結:無論是HTTP 301還是HTTP 302 重定向,都需要依賴Location 選項來指定資源的新位置。這個Location選項是一個標準的HTTP響應頭部,用于告訴瀏覽器應該將請求重定向到哪個新的URL地址。
注意上面的應用場景。永久重定向主要是給搜索引擎使用的。
HTTP請求方法

對于HTTP服務器而言,有靜態資源和動態資源之分。
- 文件內容在服務器上預先存在,直接返回給客戶端,無需服務器端實時處理或計算。
- 內容由服務器端程序實時生成,通常依賴數據庫查詢、用戶輸入或業務邏輯處理。
從最先開始,我們的HTTP服務器返回的都是網頁、圖片,也可以是視頻。但是無論是圖片,網頁,css,js,視頻等,都是我獲取的靜態資源!!!因為這些資源都是預先放到服務器上,客戶端請求時,只需要將這些文件打開,發送給客戶端即可,這些資源稱為靜態資源。如果資源需要服務器實時生成,那么就是動態資源。
我們之前說過,上網的行為就兩種,獲取資源(input)、上傳數據(output),而我們現在做的所有操作都是在獲取資源,。如果我們想上傳數據,將數據上傳到服務器,那么服務器就要對數據進行處理,一個網站能對用戶上傳的數據進行處理,那么這個網站就稱為交互式網站。例如百度首頁,我們搜索一個內容,能夠得到相應的內容,這就是交互式。那要如何將數據上傳到服務器呢?
客戶端在訪問某個網站時,會向這個網站的服務器發送請求,服務器會返回一個頁面,如果這是一個交互式網站,可能會返回一個登錄頁面,這個頁面當中是有輸入框的,并且會有一個提交的按鈕。填完輸入框后,點擊提交的按鈕,信息就會提交到服務器上。在手機上會直接顯示一個二維碼,掃碼成功之后就可以登錄上了,提交之后的過程都是一樣的。客戶端要想向服務器上傳數據時,需要先拿到服務器帶有輸入框的一個網頁。我們之前的登錄和注冊頁面就是有輸入框的。我們看一下我們的登錄頁面的部分HTML代碼。
<form action="/login" method="POST"><label for="username">用戶名:</label><input type="text" id="username" name="username" required><label for="password">密碼:</label><input type="password" id="password" name="password" required><button type="submit">登錄</button>
</form>這是一個from表單,action就表示點擊登錄后要將填入的信息提交給誰。點擊登錄后,會自動拼接到http://IP地址:端口號/的后面,即http://IP地址:端口號/login,然后將填入的數據作為參數的一部分,然后構建HTTP請求,就可以完成數據上傳了。這個method表示的是這次HTTP請求使用的是什么方法。GET也是可以上傳數據的,只是功能不如POST。我們先來試試使用GET上傳數據。
<form action="/login" method="GET"><label for="username">用戶名:</label><input type="text" id="username" name="username" required><label for="password">密碼:</label><input type="password" id="password" name="password" required><button type="submit">登錄</button>
</form>我們在構建應答時,將用戶想要獲取的資源打印出來。看看GET和POST兩種請求方式發送給服務器的請求有什么不同。
// 建立應答
void Build(HttpRequest& req)
{// 對_uri末尾是 / 進行特殊處理std::string uri = req.Uri();if (uri.back() == '/'){uri += firstpage;req.SetUri(uri);}LOG(LogLevel::DEBUG) << "-------客戶端請求-------";req.Print();LOG(LogLevel::DEBUG) << "-----------------------";// 獲取用戶想要的資源_content = req.GetContent();if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent();}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);// 構建報頭// Content-Lengthif (!_content.empty()){SetHeader("Content-Length", std::to_string(_content.size()));}// Content-Typestd::string mime_type = Suffix2Desc(req.Suffix());SetHeader("Content-Type", mime_type);// 將報頭放到_resp_header中for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}
}到達登錄頁面后,填入登錄信息,點擊登錄,會跳轉到這個頁面:
http://47.113.120.114:8888/login?username=zhangsan&password=1234567HTTP服務器接收到的請求是:

我們再將請求方法改為POST。
到達登錄頁面后,填入登錄信息,點擊登錄,會跳轉到這個頁面:
http://47.113.120.114:8888/loginHTTP服務器接收到的請求是:

所以,GET方法會將用戶輸入的參數拼接到url的后面,以?為分隔符。然后交給HTTP服務。而POST方法的傳參是通過正文傳參的,此時請求報頭中就會有Content-Length和Content-Type了
總結:區別:
- GET方法通常用于獲取網頁,POST方法通常用于上傳數據
- GET方法也可用于傳參,它的傳參通過uri,POST方法的傳參通過正文傳參
所以,我們現在已經可以通過一個網頁將數據提交給服務器了,只是現在服務器并沒有進行處理。我們上傳數據時,最好使用POST,使用GET容易將用戶名和密碼暴露出來。另外,URL的長度肯定是有上限的,所以使用GET沒辦法傳太長的數據,而正文的長度可以非常長。一定不能說POST方法比GET方法更安全。只能說POST方法傳參比因為當前都是明文傳參,即使在HTTP請求的正文部分,也是可以通過一些抓包工具拿到的其實無論是使用GET,還是POST,都是在傳參就是GET。
當客戶端將參數提交給服務器,服務器應該如何處理這個參數呢?目前我們的服務器只能處理靜態網頁的返回,沒有動態的功能,如何讓服務器能夠支持動態功能呢?
我們的代碼是TcpServer接收到客戶端發來的請求后,就通過回調的方式調用HttpServer中的Http請求處理函數處理請求,這個Http請求處理函數是接收客戶端發來的字節流信息、反序列化、構建應答、序列化,發送應答給客戶端。這是之前沒有考慮動態資源時的處理方式,現在考慮了動態資源,就不能這樣了。
在反序列化時,要判斷一下這個請求是否帶參數。所以,給HttpRequest增加三個成員函數。
bool _isexec = false; // 是否有參數,默認沒有
std::string _path; // 請求資源的路徑
std::string _args; // 請求資源的參數bool IsHasArgs() { return _isexec; }
std::string Path() { return _path; }
std::string Args() { return _args; }void Deserialize(std::string& request_str) // 反序列化
{// 提取出第一行,并細化解析出的字段if (ParseOneLine(request_str, &_req_line, Sep)){// 提取請求行中的詳細字段ParseReqLine(_req_line, LineSep);// 提取出請求報頭中的詳細字段ParseHeader(request_str);// 請求報頭和空行提取完成之后,剩下的就是正文了_body = request_str;// 分析請求中是否含有參數if (_method == "POST"){// 請求方法是POST一定有參數,且參數位于正文_isexec = true;_args = _body;_path = _uri;}else if (_method == "GET"){auto pos = _uri.find("?");if (pos != std::string::npos){// 參數在uri當中_path = _uri.substr(0, pos);_args = _uri.substr(pos + 1);}}}
}這里要說明一下,POST也可能沒有正文,這就是請求出錯了,這里我們直接不管了。
現在反序列化已經能夠判斷出請求是否攜帶參數了,在HttpServer中,構建應答時就需要對齊進行判斷,若沒有請求,走原來的Build,直接構建應答;當有請求時,根據路徑,將參數交給上層業務。所以,我們需要在HttpServer中,增加一個成員變量。用來進行路由。
using http_handler_t = std::function<void (HttpRequest&, HttpResponse&)>;class HttpServer
{
public:HttpServer(int port) : _tsvr(std::make_unique<TcpServer>(port)){}// 處理HTTP請求,這就是回調bool HandlerHttpRequest(SockPtr sockfd, InetAddr client){LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();// 接收客戶端消息std::string http_request;sockfd->Recv(&http_request); // 字節流消息// 對接收到的字節流消息進行反序列化,并打印HttpRequest req;req.Deserialize(http_request);HttpResponse resp;resp.Build(req);std::string resp_str;resp.Serialize(&resp_str);// 將序列化后的應答發送給客戶端sockfd->Send(resp_str);// std::cout << "用戶想要: " << req.Uri() << std::endl;return true;}// 注冊服務void Resgiter(std::string funcname, http_handler_t func){_route[funcname] = func;}// 啟動HTTP服務器void Start(){_tsvr->InitServer([this](SockPtr sockfd, InetAddr client){ return this->HandlerHttpRequest(sockfd, client); });_tsvr->Loop();}~HttpServer() {}private:std::unique_ptr<TcpServer> _tsvr;std::unordered_map<std::string, http_handler_t> _route; // 路由功能
};這樣,我們未來在創建好Http服務器后,可以先向這個服務器注冊服務,然后再啟動服務器。注冊的這些服務,就是根據傳入的HttpRequest,構建出HttpResponse。
void Login(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入登錄模塊" << req.Path() << ", " << req.Args();
}
void Register(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入注冊模塊" << req.Path() << ", " << req.Args();
}
void Search(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入搜索模塊" << req.Path() << ", " << req.Args();
}
void Test(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入測試模塊" << req.Path() << ", " << req.Args();
}int main(int argc, char* argv[])
{if(argc != 2){std::cout << "Usage: " << argv[0] << " port" << std::endl;return 1;}auto httpserver = std::make_unique<HttpServer>(std::stoi(argv[1]));// 向服務器注冊服務httpserver->Resgiter("/login", Login);httpserver->Resgiter("/register", Register);httpserver->Resgiter("/search", Search);httpserver->Resgiter("/test", Test);httpserver->Start();return 0;
}我們這里先采用打印日志的形式,因為我們待會想看到的是可以進入到登錄模塊。
現在就需要改一下HttpServer中處理Http請求的函數了,根據是否攜帶參數,采用不同的處理方案
// 判斷服務是否注冊過
bool SafeCheck(const std::string& service)
{auto iter = _route.find(service);return iter != _route.end();
}
// 處理HTTP請求,這就是回調
bool HandlerHttpRequest(SockPtr sockfd, InetAddr client)
{LOG(LogLevel::DEBUG) << "HttpServer: get a new client: " << sockfd->Fd() << " addr info: " << client.Addr();// 接收客戶端消息std::string http_request;sockfd->Recv(&http_request); // 字節流消息// 對接收到的字節流消息進行反序列化,并打印HttpRequest req;req.Deserialize(http_request);HttpResponse resp;// 根據是否攜帶參數,將請求分為兩類if (req.IsHasArgs()){// 攜帶參數std::string service = req.Path();if (SafeCheck(service))_route[req.Path()](req, resp); // 方法注冊過了,直接調用elseresp.Build(req); // 方法未注冊,通過Build拿到404頁面}else{// 沒有攜帶參數resp.Build(req);}std::string resp_str;resp.Serialize(&resp_str);// 將序列化后的應答發送給客戶端sockfd->Send(resp_str);// std::cout << "用戶想要: " << req.Uri() << std::endl;return true;
}現在代碼中還有一個問題,我們之前都是處理靜態資源,這些靜態資源都在wwwroot目錄下,所以我們細化請求行字段時,在uri前面添加上了wwwroot,現在不能這樣了,只有到Build中才需要加
// 細化請求行的字段
void ParseReqLine(std::string& _req_line, const std::string sep)
{std::stringstream ss(_req_line);ss >> _method >> _uri >> _version;// 給uri添加上web根目錄// _uri = defaulthomepage + _uri;
}// 讀取path路徑下的網頁信息, 以二進制形式讀取
std::string GetContent(const std::string path)
{std::string content;std::ifstream in(path, std::ios::binary);if (!in.is_open()) return std::string();in.seekg(0, in.end);int filesize = in.tellg();in.seekg(0, in.beg);content.resize(filesize);in.read((char*)content.c_str(), filesize);in.close();return content;
}// 建立應答
void Build(HttpRequest& req)
{// 對_uri末尾是 / 進行特殊處理std::string uri = defaulthomepage + req.Uri();if (uri.back() == '/'){uri += firstpage;// req.SetUri(uri);}LOG(LogLevel::DEBUG) << "-------客戶端請求-------";req.Print();LOG(LogLevel::DEBUG) << "-----------------------";// 獲取用戶想要的資源_content = req.GetContent(uri);if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;// req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent(page404);}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);// 構建報頭// Content-Lengthif (!_content.empty()){SetHeader("Content-Length", std::to_string(_content.size()));}// Content-Typestd::string mime_type = Suffix2Desc(req.Suffix());SetHeader("Content-Type", mime_type);// 將報頭放到_resp_header中for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}
}
可以看到,此時已經能夠進入到注冊模塊了。無論是GET還是POST都可以。接下來就是要在路由方法中,通過req構建出resp。需要對HttpResponse做出一些調整。增加2個成員函數:
void SetCode(int code)
{_status_code = code;_status_desc = Code2Desc(_status_code);
}
void SetBody(const std::string& body)
{_body = body;
}將遍歷從Build調整到序列化當中,并將拼接正文從序列化放到Build的最后。
// 建立應答
void Build(HttpRequest& req)
{// 對_uri末尾是 / 進行特殊處理std::string uri = defaulthomepage + req.Uri();if (uri.back() == '/'){uri += firstpage;// req.SetUri(uri);}// LOG(LogLevel::DEBUG) << "-------客戶端請求-------";// req.Print();// LOG(LogLevel::DEBUG) << "-----------------------";// 獲取用戶想要的資源_content = req.GetContent(uri);if (_content.empty()){// 用戶請求的資源不存在_status_code = 404;// req.SetUri(page404);// 重新獲取一次資源_content = req.GetContent(page404);}else{// 用戶請求的資源存在_status_code = 200;}_status_desc = Code2Desc(_status_code);// 構建報頭// Content-Lengthif (!_content.empty()){SetHeader("Content-Length", std::to_string(_content.size()));}// Content-Typestd::string mime_type = Suffix2Desc(req.Suffix());SetHeader("Content-Type", mime_type);_body = _content;
}
void Serialize(std::string* resp_str)
{// 將報頭放到_resp_header中for (auto& header : _header_kv){_resp_header.push_back(header.first + HeaderLineSep + header.second);}// 拼接狀態行_resp_line = _version + LineSep + std::to_string(_status_code) + LineSep + _status_desc + Sep;// 序列化*resp_str = _resp_line;for (auto& line : _resp_header){*resp_str += (line + Sep);}*resp_str += _blank_line;*resp_str += _body;
}void Login(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入登錄模塊" << req.Path() << ", " << req.Args();std::string req_args = req.Args();// 1. 解析參數格式,得到想要的參數// 2. 訪問數據塊,驗證對應的用戶是否是合法的用戶,其他工作...// 3. 登錄成功(構建應答)std::string body = "<html><body><p>Login Success!</p></body></html>";resp.SetCode(200);resp.SetHeader("Content-Length", std::to_string(body.size()));resp.SetHeader("Content-Type", "text/html");resp.SetBody(body);
}正常來說,登錄成功一般是跳轉到某個頁面,這里就直接展現出一個登錄成功的頁面。

此時就可以看到登錄成功的頁面了。但是,我們現在只能夠看到頁面,看不到服務器給客戶端返回的正文等信息,因為會被瀏覽器解釋,此時可以使用一個軟件postman。postman是一個模擬HTTP客戶端的工具。當然也可以使用telnet模擬。




可以看到,此時就可以拿到服務器發送過來的信息了。
現在,客戶端將請求提交上來,HTTP服務器已經能夠執行注冊的服務了。未來就可以基于這個HTTP服務器再寫很多的應用,比方說也可以再定義協議,對提交的數據定義協議。我們這種以功能路由執行服務的形式,稱為restfuI風格的網絡請求接口。如果將各個服務分別放到不同的服務器當中,這就是微服務了。我們登錄成功時,最好是直接跳轉到首頁。
void Login(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入登錄模塊" << req.Path() << ", " << req.Args();std::string req_args = req.Args();// 1. 解析參數格式,得到想要的參數// 2. 訪問數據塊,驗證對應的用戶是否是合法的用戶,其他工作...// 3. 登錄成功(構建應答)resp.SetCode(302);resp.SetHeader("Location", "/");
}cookie與session
當客戶端向服務器發送請求時,服務器除了會返回應答,還可能想向客戶端寫入一些內容。這涉及到一個概念叫會話保持。
我們會發現,我們登錄了一次B站后,下一次訪問B站就不需要登錄了。這是因為客戶端在登錄服務器時,服務器會對登錄時輸入的信息進行認證,認證成功之后,服務器會向客戶端寫入一些登錄有關的信息,比如說用戶名和密碼,寫入到了客戶端的某一個位置,我們以瀏覽器為例。后序瀏覽器向HTTP服務器發送請求時,會自動攜帶上服務器曾經寫入的消息。服務器寫入瀏覽器的這部分信息,瀏覽器會進行保存,我們將這部分信息稱為cookie。cookie在瀏覽器中會有兩種存在形式,一種是內存級的,一種是文件級的。可以查看cookie:

將這些cookie全部刪除后,刷新網頁,B站就需要登錄了。
我們沒刪除時,每次發送請求都會攜帶上cookie,所以實際上每次請求都會有認證,不只有登錄時才進行認證。當我們刪除后,請求時就沒辦法再攜帶上cookie了,服務器就不認識這個客戶端了。這個功能就稱為基于cookie的會話保持功能。
服務端怎么向客戶端寫入cookie呢?在應答報頭中添加Set-Cookie,就會將后面的內容添加到瀏覽器的cookie中。
void Login(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入登錄模塊" << req.Path() << ", " << req.Args();std::string req_args = req.Args();// 1. 解析參數格式,得到想要的參數// 2. 訪問數據塊,驗證對應的用戶是否是合法的用戶,其他工作...// 3. 登錄成功(構建應答)resp.SetCode(302);resp.SetHeader("Location", "/");resp.SetHeader("Set-Cookie", "usrname=zhangsan");resp.SetHeader("Set-Cookie", "password=1234567");
}
此時我們登錄我們的服務器,就可以看到cookie了。請求和應答中都是可以有多條Set-Cookie的,但是我們今天保存這些鍵值使用的是unordered_map,所以沒辦法弄多條。可以使用一個vector來保存鍵值,這樣就可以弄多條了,但是這個工作我們今天就不做了。我們修改成一條Set-Cookie。?
void Login(HttpRequest& req, HttpResponse& resp)
{LOG(LogLevel::DEBUG) << "進入登錄模塊" << req.Path() << ", " << req.Args();std::string req_args = req.Args();// 1. 解析參數格式,得到想要的參數// 2. 訪問數據塊,驗證對應的用戶是否是合法的用戶,其他工作...// 3. 登錄成功(構建應答)resp.SetCode(302);resp.SetHeader("Location", "/");resp.SetHeader("Set-Cookie", "usrname=zhangsan&password=1234567");
}當然,我們這里是硬編碼的,實際上可以根據輸入來設置。
HTTP協議是無連接、無狀態的協議。它是直接發送請求,直接發送應答的,鏈接由TCP來做。連續請求兩次首頁,第二次HTTP請求時,HTTP客戶端是不知道剛剛才請求過一次的,這叫無狀態。正因為HTTP協議是無狀態的,所以我們訪問某一個網站時,登錄后,又想訪問這個網站的其他網頁時,就需要再登錄,這樣每訪問一個網頁就需要登錄一次,顯然是不合理的。所以,cookie的存在是很有必要的。
將我們的個人信息保存在了cookie當中,如果這個cookie泄漏了,我們的個人信息也就泄漏了。所以光有一個cookie是不夠的。真實的情況是當客戶端登錄時,若登錄成功,服務器會為這個客戶端創建一個session對象,并維護在服務器內部,這個對象中有session_id,以及用戶的一些私密信息。然后服務器通過應答,Set-Cookie返回一個session_id。瀏覽器會將這個session_id寫到瀏覽器的cookie文件當中。現在,客戶端在請求時總是會攜帶session_id。服務端就會根據session_id對用戶進行認證。這樣,客戶端就再也不需要保存用戶的私密信息了。
可是即使是這樣,也還是避免不了cookie信息被盜取啊!這種做法:
- 不會再造成用戶信息的泄漏了
- 現在私密信息保存在了服務器,服務器就可以設計各種策略,來防止黑客進行惡意操作。例如讓服務器每次認證時都檢查一下IP地址,若IP地址發生了變化,就將服務器上的session對象釋放掉。另外,也可以對用戶的行為進行判斷等。
所以,cookie+session是HTTP中會話保持的一個常見做法。
在代碼中要如何設計這個session呢?
class Session
{
private:std::string name;bool islogin;uint64_t session_id;// 其他信息
};class SessionManager
{
public:void CreateSession(uint64_t session_id){}void DeleteSession(uint64_t session_id){}void SearchSession(uint64_t session_id){}
private:std::unordered_map<uint64_t, Session*> _session;
};Connection
請求報頭中還有一個字段Connection。我們現在的服務器,發送一個請求只會獲得一個資源,例如首頁中有3張圖片,瀏覽器會向服務器發送4個請求,每個請求只獲取一個資源。建立一次鏈接,只幫助用戶獲取一個資源,就叫做短鏈接。這種短鏈接肯定是不好的,如果一個網頁內有非常多資源呢?這樣服務器的壓力是非常大的。HTTP在1.0及以前時,只支持短鏈接,因為那時候資源比較少。1.1之后,新增了一個字段Connection。HTTP中的connection字段是HTTP報頭的一部分,它主要用于控制和管理客戶端與服務器之間的連接狀態。在HTTP1.1之后,默認使用的就是長連接
核心作用:管理持久連接。Connection 字段還用于管理持久連接(也稱為長連接)。持久連接允許客戶端和服務器在請求/響應完成后不立即關閉TCP連接,以便在同一個連接上發送多個請求和接收多個響應。
語法格式:
- Connection:keep-alive:表示希望保持連接以復用TCP連接。
- Connection:close:表示請求/響應完成后,應該關閉TCP連接。
我們當時寫網絡版本計算器時,使用的就是長連接。建立連接之后,一直允許客戶端發送計算的請求。我們現在也是很容易實現的,只要讀取時一行一行讀,直到讀到空行,再根據報頭中指明的報文長度,讀取報文,根據這個構建HttpResponse,序列化之后,發送,再讀取另外一個即可。所以,要實現長連接,關鍵問題是服務器能否處理TCP的字節流問題。
抓包
Fiddler是一個本地抓包工具。我們之前都是瀏覽器或其他應用向服務器發送請求。若是在瀏覽器所在的主機上裝一個Fiddler,Fiddler會劫取瀏覽器發出的請求,相當于瀏覽器將請求發送給了Fiddler,然后由Fiddler再向服務器發送請求,服務器會將應答發送給Fiddler,Fiddler再將應答發送給瀏覽器。所以,Fiddler就是一種代理。Fiddler是專門抓取HTTP請求的。

只要開啟Fiddler,并使用瀏覽器去訪問服務器,就會被抓包。

所以,無論是GET,還是POST,都是明文傳參,在網絡通信中都是不安全的。所以,HTTP本身是不安全的,因為它沒有加密。
HTTPS協議就是在HTTP協議的基礎上,增加了一個加密層,發送請求時,HTTP處理好的HttpResquest,會交給這個加密層,主要是對正文部分加密,再發送給服務器,服務器收到后,也需要先解密,然后再進行處理。
我們講HTTP協議主要是以后可以仿照HTTP自定義一些協議。其次,HTTPS有加密和解密,這就意味著發送請求、接收請求、發送應答、接收應答等都會比較慢,所以在公司內網中,是可以保證數據安全的,此時是可以使用HTTP協議進行通信的。

deep learning(五)--learning rate)






)

![[黑馬頭條]-登錄實現思路](http://pic.xiahunao.cn/[黑馬頭條]-登錄實現思路)


)




—首頁性能提升實踐)
