溫馨提示:
本篇文章已同步至"AI專題精講" DeepSeekMath:突破開源語言模型在數學推理中的極限
摘要
數學推理由于其復雜且結構化的特性,對語言模型構成了重大挑戰。本文介紹了 DeepSeekMath 7B,該模型在 DeepSeek-Coder-Base-v1.5 7B 的基礎上繼續進行了預訓練,使用了來自 Common Crawl 的 120B 數學相關 token,同時包含自然語言和代碼數據。DeepSeekMath 7B 在無需依賴外部工具包和投票技術的情況下,在競賽級 MATH 基準上取得了 51.7% 的優異成績,接近 Gemini-Ultra 和 GPT-4 的表現。DeepSeekMath 7B 在 64 個樣本上的自洽性得分為 60.9%。DeepSeekMath 的數學推理能力歸因于兩個關鍵因素:其一,我們通過精心設計的數據篩選流程,充分挖掘了公開網頁數據的巨大潛力;其二,我們提出了一種稱為 Group Relative Policy Optimization(GRPO)的 Proximal Policy Optimization(PPO)變體,該方法在提升數學推理能力的同時優化了 PPO 的內存使用。
1. 引言
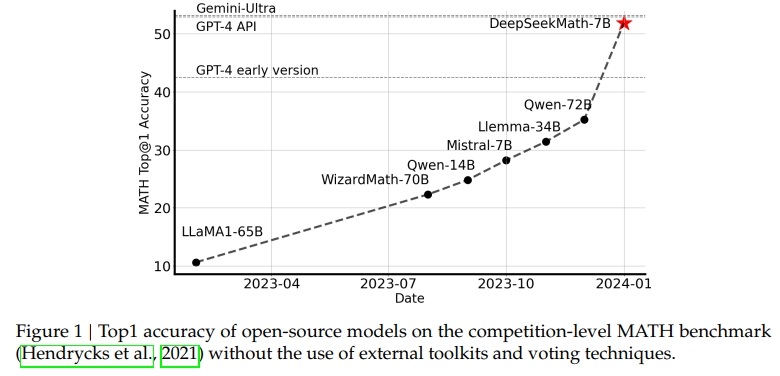
大型語言模型(LLM)徹底改變了人工智能中的數學推理方式,推動了定量推理基準(Hendrycks et al., 2021)和幾何推理基準(Trinh et al., 2024)的重大進展。此外,這些模型在協助人類解決復雜數學問題方面也發揮了關鍵作用(Tao, 2023)。然而,最先進的模型如 GPT-4(OpenAI, 2023)和 Gemini-Ultra(Anil et al., 2023)尚未公開,而當前可用的開源模型在性能上仍遠遠落后。
在本研究中,我們提出了 DeepSeekMath,這是一個特定領域的語言模型,在數學能力上顯著超過了開源模型,并在學術基準上接近 GPT-4 的性能。為實現這一目標,我們構建了 DeepSeekMath Corpus,這是一個大規模高質量預訓練語料庫,包含 120B 個數學相關 token。該數據集通過 fastText 分類器(Joulin et al., 2016)從 Common Crawl(CC)中提取。在初始迭代中,分類器使用來自 OpenWebMath(Paster et al., 2023)的樣本作為正例,輔以多樣化的網頁作為負例進行訓練。隨后,我們使用該分類器從 CC 中挖掘更多正樣本,并通過人工標注進一步精煉這些數據。分類器隨后用增強后的數據集更新,以提高其性能。評估結果表明,這一大規模語料庫具有較高質量,因為我們的基礎模型 DeepSeekMath-Base 7B 在 GSM8K(Cobbe et al., 2021)上達到了 64.2%,在競賽級 MATH 數據集(Hendrycks et al., 2021)上達到了 36.2%,優于 Minerva 540B(Lewkowycz et al., 2022a)。此外,DeepSeekMath Corpus 是多語言的,因此我們也觀察到其在中文數學基準(Wei et al., 2023;Zhong et al., 2023)上的性能提升。我們認為,我們在數學數據處理方面的經驗為研究社區提供了一個起點,未來還有大量提升空間。
DeepSeekMath-Base 以 DeepSeek-Coder-Base-v1.5 7B(Guo et al., 2024)為初始化模型,因為我們注意到,相較于通用 LLM,從代碼訓練模型出發是更優的選擇。此外,我們觀察到數學訓練也提升了模型在 MMLU(Hendrycks et al., 2020)和 BBH 基準(Suzgun et al., 2022)上的能力,表明它不僅增強了模型的數學能力,也放大了其通用推理能力。
在預訓練之后,我們對 DeepSeekMath-Base 進行了數學指令微調,使用了 chain-of-thought(Wei et al., 2022)、program-of-thought(Chen et al., 2022;Gao et al., 2023)和 tool-integrated reasoning(Gou et al., 2023)數據。最終模型 DeepSeekMath-Instruct 7B 超越了所有同類 7B 模型,并可與 70B 的開源指令微調模型相媲美。
此外,我們提出了 Group Relative Policy Optimization(GRPO),這是一種基于 Proximal Policy Optimization(PPO)(Schulman et al., 2017)的變體強化學習算法。GRPO 省去了 critic 模型,而是從 group scores 中估計 baseline,從而顯著降低了訓練資源的消耗。僅使用部分英文指令微調數據,GRPO 在強化學習階段就使強基線模型 DeepSeekMath-Instruct 獲得了顯著提升,包括在同域任務(如 GSM8K: 82.9% → 88.2%,MATH: 46.8% → 51.7%)和異域數學任務(如 CMATH: 84.6% → 88.8%)上的表現。
我們還提供了一個統一范式來理解不同方法,例如 Rejection Sampling Fine-Tuning(RFT)(Yuan et al., 2023a)、Direct Preference Optimization(DPO)(Rafailov et al., 2023)、PPO 和 GRPO。在此統一范式下,我們發現這些方法都可被概念化為直接或簡化的強化學習技術。我們還進行了大量實驗,如 online 與 offline 訓練、結果監督與過程監督、單輪強化學習與迭代強化學習等,以深入探究該范式的關鍵組成要素。最后,我們解釋了為何我們的強化學習方法能夠提升指令微調模型的性能,并進一步總結了在此統一范式下實現更高效強化學習的潛在方向。
1.1 貢獻
我們的貢獻包括可擴展的數學預訓練,以及對強化學習的探索與分析。
可擴展的數學預訓練
- 我們的研究提供了有力證據,表明公開的 Common Crawl 數據中蘊含著對數學任務有價值的信息。通過精心設計的數據篩選流程,我們成功構建了 DeepSeekMath Corpus,這是一個包含 120B token 的高質量網頁數學數據集,規模約為 Minerva 使用的數學網頁數據的 7 倍,是最近發布的 OpenWebMath(Paster et al., 2023)的 9 倍。
- 我們預訓練的基礎模型 DeepSeekMath-Base 7B 在性能上可與 Minerva 540B 相媲美,說明參數數量并不是數學推理能力的唯一關鍵因素。一個規模較小但在高質量數據上訓練的模型同樣可以達到較強的性能。
- 我們分享了數學訓練實驗中的發現。代碼訓練在數學訓練前能夠提升模型解決數學問題的能力,無論是否使用工具。這為一個長期存在的問題提供了部分答案:代碼訓練是否能提升推理能力?我們認為,至少在數學推理方面,答案是肯定的。
- 雖然在許多數學相關論文中,使用 arXiv 論文進行訓練已非常普遍,但在本研究采用的所有數學基準上,這并未帶來顯著的性能提升。
強化學習的探索與分析
- 我們提出了 Group Relative Policy Optimization(GRPO),這是一種高效而有效的強化學習算法。GRPO 省略了 critic 模型,而是通過 group scores 估計 baseline,相較于 Proximal Policy Optimization(PPO)顯著降低了訓練資源消耗。
- 我們展示了 GRPO 僅使用指令微調數據即可顯著提升模型 DeepSeekMath-Instruct 的性能。此外,我們還觀察到,在強化學習過程中,模型在異域任務上的表現也有所提升。
- 我們提出了一個統一范式來理解不同方法,如 RFT、DPO、PPO 和 GRPO。我們還進行了大量實驗,例如 online 與 offline 訓練、結果監督與過程監督、單輪強化學習與多輪強化學習等,以深入研究這一范式的關鍵要素。
- 基于我們的統一范式,我們探索了強化學習之所以有效的原因,并總結了若干方向,以實現對 LLM 更高效的強化學習。
1.2. 評估與指標總結
? 英文與中文數學推理:我們在英文與中文的基準數據集上對模型進行了全面評估,涵蓋從小學到大學階段的數學問題。英文基準包括 GSM8K(Cobbe et al., 2021)、MATH(Hendrycks et al., 2021)、SAT(Azerbayev et al., 2023)、OCW Courses(Lewkowycz et al., 2022a)、MMLU-STEM(Hendrycks et al., 2020)。中文基準包括 MGSM-zh(Shi et al., 2023)、CMATH(Wei et al., 2023)、Gaokao-MathCloze(Zhong et al., 2023)和 Gaokao-MathQA(Zhong et al., 2023)。我們評估模型在不使用工具的情況下生成自包含文本解答的能力,以及使用 Python 解決問題的能力。
在英文基準上,DeepSeekMath-Base 可與閉源模型 Minerva 540B(Lewkowycz et al., 2022a)相媲美,并顯著優于所有開源基礎模型(例如 Mistral 7B(Jiang et al., 2023)和 Llemma-34B(Azerbayev et al., 2023)),無論是否進行過數學預訓練。值得注意的是,DeepSeekMath-Base 在中文基準上表現更優,這可能是因為我們沒有像之前的工作(Azerbayev et al., 2023;Lewkowycz et al., 2022a)那樣僅收集英文數學預訓練數據,而是同時納入了高質量的非英文數據。通過數學指令微調和強化學習,最終模型 DeepSeekMath-Instruct 和 DeepSeekMath-RL 表現強勁,首次在開源社區中在競賽級別的 MATH 數據集上達到了超過 50% 的準確率。
? 形式化數學:我們使用來自(Jiang et al., 2022)的非正式到正式定理證明任務,在 miniF2F(Zheng et al., 2021)上評估 DeepSeekMath-Base,并選用 Isabelle(Wenzel et al., 2008)作為證明助手。DeepSeekMath-Base 展現了強大的 few-shot 自動形式化能力。
? 自然語言理解、推理與代碼:為了全面評估模型在通用理解、推理和編程方面的能力,我們在 Massive Multitask Language Understanding(MMLU)(Hendrycks et al., 2020)基準上對 DeepSeekMath-Base 進行了評估,該基準涵蓋了 57 個涉及多個領域的多項選擇題任務;BIG-Bench Hard(BBH)(Suzgun et al., 2022),包含 23 個主要依賴多步推理的挑戰任務;HumanEval(Chen et al., 2021)和 MBPP(Austin et al., 2021)是廣泛用于評估代碼語言模型的基準。數學預訓練同時提升了語言理解與推理表現。
2. 數學預訓練
2.1. 數據收集與去污染
本節將概述如何從 Common Crawl 構建 DeepSeekMath Corpus 的過程。如圖 2 所示,我們展示了一個迭代式的數據管道,說明如何系統地從 Common Crawl 中收集大規模數學語料庫,其起點為一個種子語料庫(例如一小部分高質量的數學相關數據集)。值得注意的是,該方法同樣適用于其他領域,例如代碼領域。
我們首先選擇 OpenWebMath(Paster et al., 2023)作為初始種子語料庫,該語料庫是一個高質量數學網頁文本的集合。我們使用該語料訓練一個 fastText 模型(Joulin et al., 2016),以召回更多類似 OpenWebMath 的數學網頁。具體來說,我們從種子語料中隨機選擇 500,000 個數據點作為正樣本,從 Common Crawl 中選取另外 500,000 個網頁作為負樣本。我們使用一個開源庫1進行訓練,訓練配置為向量維度 256、學習率 0.1、最大 word n-gram 長度為 3、詞最小出現次數為 3、訓練輪數為 3。
為縮小原始 Common Crawl 的規模,我們采用基于 URL 的去重和近似去重技術,得到約 400 億個 HTML 網頁。然后,我們利用 fastText 模型從去重后的 Common Crawl 中召回數學網頁。為過濾低質量數學內容,我們根據 fastText 模型預測的得分對收集到的網頁進行排序,并僅保留得分最高的部分。通過對 top 40B、80B、120B 和 160B tokens 的預訓練實驗來評估所保留數據的質量和規模。在第一輪中,我們選擇保留 top 40B tokens。
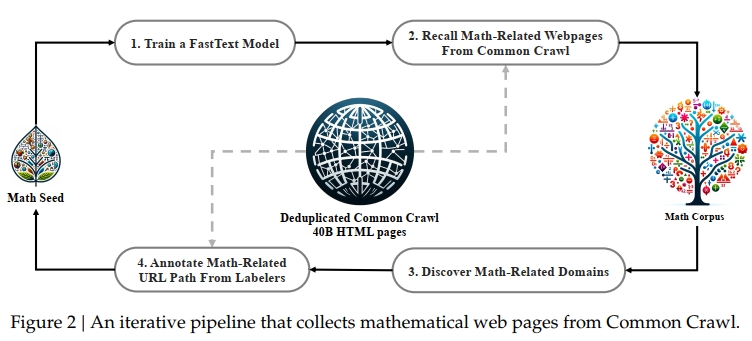
在第一輪數據收集中,仍有大量數學網頁未被召回,主要原因在于 fastText 模型所使用的正樣本集缺乏足夠的多樣性。因此,我們進一步識別其他數學相關的網頁來源,以豐富種子語料庫,從而優化 fastText 模型。具體而言,我們首先將整個 Common Crawl 按照不同的域進行劃分;一個域被定義為具有相同基礎 URL 的網頁集合。對于每個域,我們計算第一輪中被召回網頁所占的比例。若某一域中超過 10% 的網頁被召回,我們將該域標記為數學相關(例如 mathoverflow.net)。
隨后,我們對這些被標記為數學相關的域中的 URL(例如 mathoverflow.net/questions)進行人工標注,以識別其中包含數學內容的鏈接。與這些 URL 相關但未被召回的網頁將被加入到種子語料庫中。此方法使我們能夠獲取更多正樣本,從而訓練出更優的 fastText 模型,在隨后的迭代中召回更多數學數據。經過四輪的數據收集后,我們共獲得了 3550 萬個數學網頁,總計 120B tokens。在第四輪中我們觀察到,約 98% 的數據在第三輪中已被召回,因此我們決定停止進一步收集。
為了避免基準污染,我們遵循 Guo et al. (2024) 的方法,從語料中過濾掉包含英文數學基準(如 GSM8K(Cobbe et al., 2021)和 MATH(Hendrycks et al., 2021))和中文基準(如 CMATH(Wei et al., 2023)和 AGIEval(Zhong et al., 2023))中的問題或答案的網頁。過濾標準如下:若某段文本中包含與評估基準中的任意子字符串完全匹配的 10-gram 字符串,則該文本將從訓練語料中移除。對于長度不足 10-gram、但至少包含 3-gram 的基準文本,我們也采用精確匹配的方式過濾掉被污染的網頁。
2.2. 驗證 DeepSeekMath 語料庫的質量
我們運行預訓練實驗,以比較 DeepSeekMath 語料庫與近期發布的數學訓練語料庫的效果:
? MathPile(Wang et al., 2023c):一個多來源語料庫(8.9B tokens),聚合自教科書、Wikipedia、ProofWiki、CommonCrawl、StackExchange 和 arXiv,其中超過 85% 的數據來自 arXiv;
? OpenWebMath(Paster et al., 2023):從 CommonCrawl 中篩選出的數學內容,總量為 13.6B tokens;
? Proof-Pile-2(Azerbayev et al., 2023):一個數學語料庫,由 OpenWebMath、AlgebraicStack(10.3B tokens 的數學代碼)和 arXiv 論文(28.0B tokens)組成。在使用 Proof-Pile-2 進行實驗時,我們遵循 Azerbayev et al.(2023)的做法,采用 arXiv:Web:Code 的比例為 2:4:1。
2.2.1. 訓練設置
我們將數學訓練應用于一個具有 1.3B 參數的通用預訓練語言模型,其框架與 DeepSeek LLMs(DeepSeek-AI, 2024)一致,記作 DeepSeekLLM 1.3B。我們在每個數學語料庫上分別訓練一個模型,訓練總量為 150B tokens。所有實驗均使用高效且輕量的 HAI-LLM(High-flyer, 2023)訓練框架進行。按照 DeepSeek LLMs 的訓練實踐,我們使用 AdamW 優化器(Loshchilov and Hutter, 2017),設置參數為 Font metrics not found for font: .,weight_decay = 0.1,并使用多階段學習率調度策略:在 2,000 個 warmup 步驟后學習率達到峰值,在訓練過程的 80% 時衰減至峰值的 31.6%,在 90% 時進一步衰減至峰值的 10.0%。我們將最大學習率設為 5.3e-4,batch size 為 4M tokens,context length 為 4K。
2.2.2. 評估結果
DeepSeekMath 語料庫具有高質量、多語言覆蓋,并且規模最大。
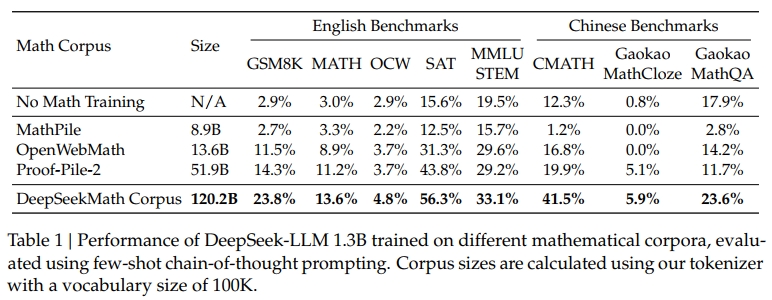
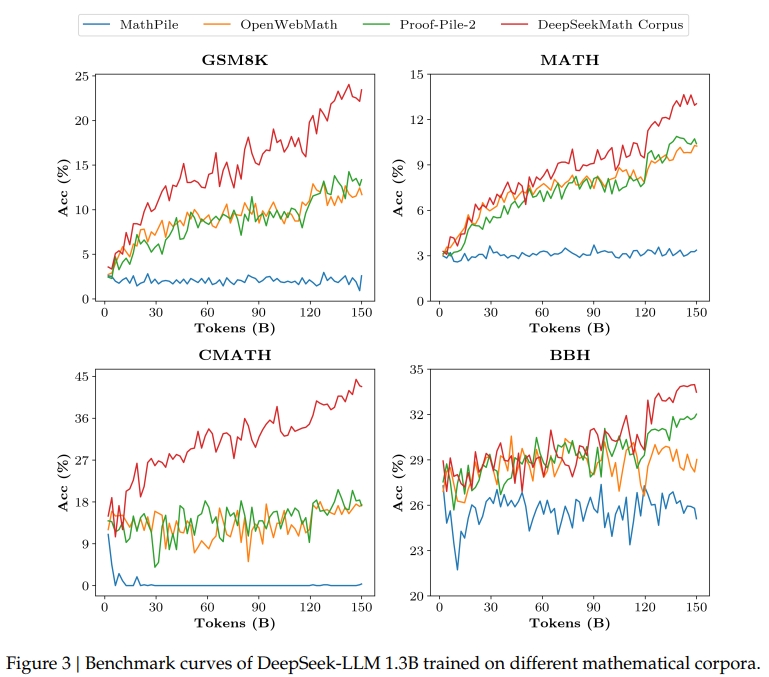
? 高質量:我們使用 few-shot chain-of-thought prompting(Wei et al., 2022)在 8 個數學基準測試上評估下游性能。如表 1 所示,基于 DeepSeekMath 語料庫訓練的模型在性能上有明顯優勢。圖 3 顯示,使用 DeepSeekMath 語料庫訓練的模型在 50B tokens(即 Proof-Pile-2 完整訓練一個 epoch 的量)時的表現優于 Proof-Pile-2,這表明 DeepSeekMath 語料庫的平均質量更高。
? 多語言:DeepSeekMath 語料庫包含多種語言的數據,其中英語和中文是出現頻率最高的兩種語言。如表 1 所示,在 DeepSeekMath 語料庫上進行訓練,可以提升模型在英文和中文數學推理任務上的表現。相比之下,現有的數學語料庫以英語為主,在中文數學推理上的提升效果有限,甚至可能產生負面影響。
? 大規模:DeepSeekMath 語料庫的規模是現有數學語料庫的數倍。如圖 3 所示,DeepSeek-LLM 1.3B 在使用 DeepSeekMath 語料庫進行訓練時,其學習曲線更陡峭,性能提升更加持久。相比之下,基線語料庫的規模小得多,在訓練過程中已經被重復使用多輪,模型性能很快就達到瓶頸。
溫馨提示:
閱讀全文請訪問"AI深語解構" DeepSeekMath:突破開源語言模型在數學推理中的極限
)

![[黑馬頭條]-登錄實現思路](http://pic.xiahunao.cn/[黑馬頭條]-登錄實現思路)


)




—首頁性能提升實踐)



)

的三維標簽位置解算,可自適應基站數量。附下載鏈接)


