目錄
1. ?引言與背景總結?
2. ?方法框架總結?
3. ?訓練策略總結?
4. ?實驗驗證總結?
核心代碼實現(PyTorch框架)
?1. SNN特征提取器(多尺度卷積模塊)
?結論與未來工作總結?
?
1. ?引言與背景總結?
- ?問題陳述?:電機軸承是工業設備中的關鍵組件,其故障可能導致嚴重安全和經濟損失。傳統深度學習故障診斷方法依賴大量高質量數據,但在實際工業場景中,故障樣本往往稀缺(小樣本問題),且正常樣本遠多于故障樣本(數據不平衡問題),導致模型性能下降。現有方法如遷移學習(transfer learning)、生成對抗網絡(GAN)和過采樣技術(如SMOTE)存在局限性,例如需要輔助數據或生成樣本質量低。
- ?解決方案動機?:論文提出使用Siamese Neural Networks(SNNs)處理小樣本問題。SNNs通過比較樣本對(sample pairs)來學習特征相似性,減少了對大量數據的依賴。然而,SNNs易受訓練停滯(training stagnation)問題影響,導致特征提取不足。為此,方法引入多階段訓練策略和多源特征融合,以提升魯棒性。
- ?主要貢獻?:論文的創新點包括:(1) 提出多階段訓練策略緩解SNNs的訓練停滯;(2) 設計多源特征融合網絡,整合振動、電流等多傳感器數據;(3) 驗證方法在兩個真實數據集上的有效性,證明其在小樣本場景的優越性。
2. ?方法框架總結?
方法分為兩個核心框架:SNN-based特征提取框架和multi-source特征融合框架。整體結構如圖2所示: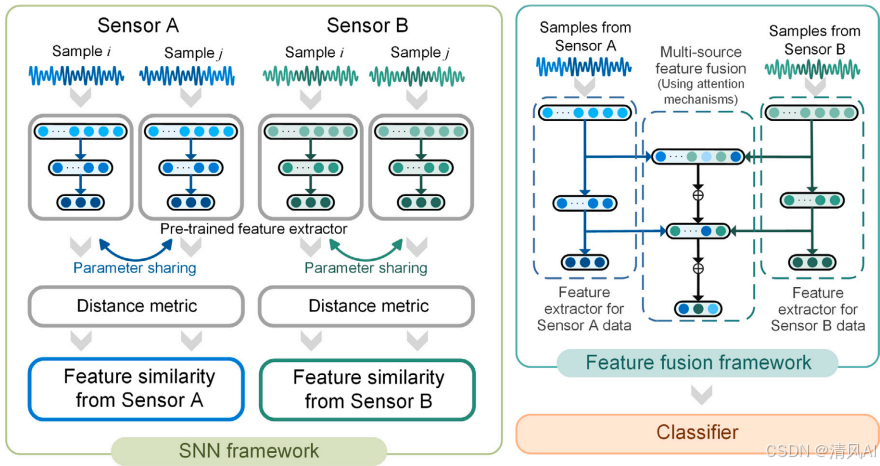
NN-based特征提取框架?:
- ?結構描述?:SNN由兩個對稱子網絡組成,共享權重(如圖1)。輸入樣本對(如?Xa??和?Xb?) 被映射到特征空間,計算歐氏距離?Ew?=∥Gw?(Xa?)?Gw?(Xb?)∥?作為相似性度量。距離小表示同類樣本,距離大表示不同類樣本。
?
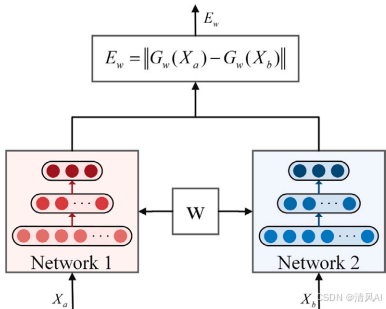
圖1?
特征提取器設計?:子網絡采用基于Inception模塊的多尺度卷積模塊(Multi-scale Convolution Module, MCM),如圖3和圖4。MCM使用不同尺寸卷積核(如1x1、1x3、1x7)捕獲多尺度特征,減少參數同時豐富信息。例如:?
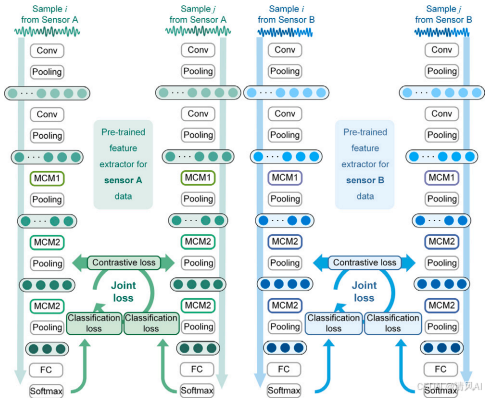
圖3?
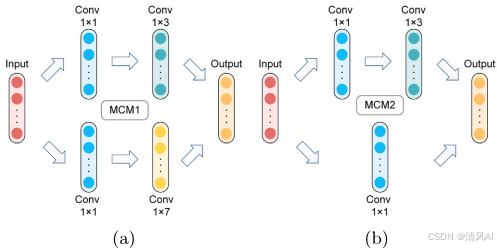
圖4?
?
-
- 優勢?:SNN通過樣本對輸入(n個樣本生成n(n-1)個樣本對),有效擴增樣本量,緩解小樣本問題。
-
?Multi-source特征融合框架?:
- ?結構描述?:融合網絡整合來自多個傳感器(如振動和電流)的特征。如圖5,特征提取器輸出通過注意力機制(attention mechanism)融合,結合殘差連接保留原始信息。
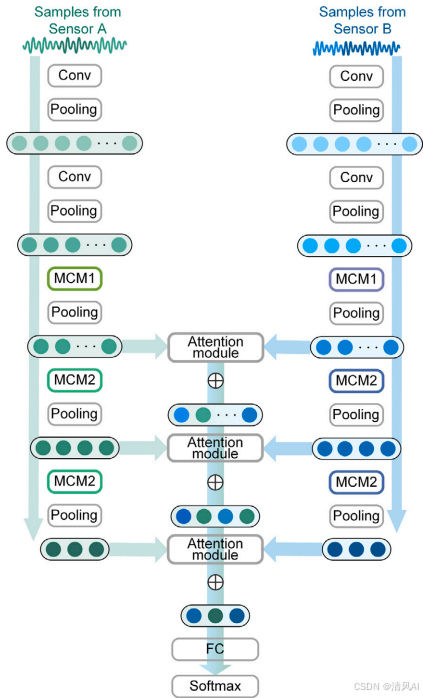
圖5?
?融合策略?:采用通道注意力機制(如圖6)。步驟包括:(1) 對傳感器特征(如?FA??和?FB?) 進行全局平均池化和最大池化;(2) 生成全局表示?Fg?;(3) 通過SoftMax生成激勵信號?PA??和?PB?;(4) 門控機制融合特征:F=(PA??FA?+FA?)+(PB??FB?+FB?),其中???表示點積。
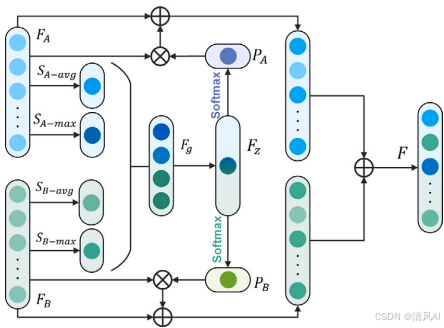
圖6?
?
3. ?訓練策略總結?
- ?多階段訓練過程?:緩解SNN訓練停滯問題,分三個階段:
- ?階段1(特征提取器預訓練)??:單獨訓練特征提取器(使用振動或電流數據),采用交叉熵損失函數(Cross-Entropy Loss)和Adam優化器。輸出SoftMax分類結果,初始化權重。
- ?階段2(SNN訓練)??:初始化SNN與預訓練權重。輸入樣本對,標簽?YL?(Xa?,Xb?)=δXa?,Xb??(同類為1,不同類為0)。損失函數為聯合損失(Joint Loss):LJ?=λ1?Lctr?+λ2?(Lcls?a?+Lcls?b?),其中?Lctr??是對比損失(Contrastive Loss),最小化同類距離并最大化異類距離;Lcls??是分類損失。超參數設置:批大小128、學習率0.001。
- ?階段3(特征融合網絡訓練)??:使用階段2的權重初始化融合網絡,整合多源特征用于最終分類。
- ?訓練效果?:如圖9所示,多階段訓練顯著提升準確率。例如,預訓練階段單個傳感器準確率僅65-76%,SNN階段提升至80-83%,融合階段達94%。
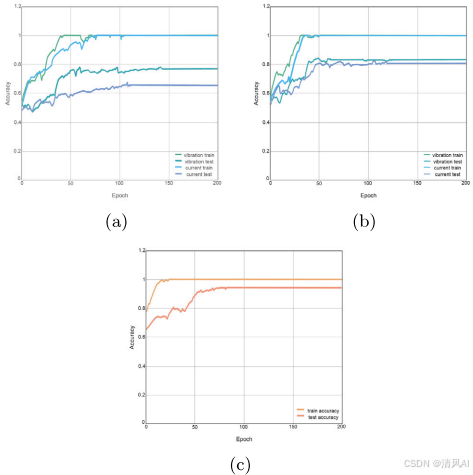
?圖9
4. ?實驗驗證總結?
實驗在兩個數據集上進行:Case 1(公共數據集)和Case 2(實驗室數據集),評估方法在小樣本和數據不平衡場景的性能。
-
?數據預處理?:如圖7,包括滑動窗口分割、域變換(如離散余弦S變換和包絡譜變換),將時域、頻域和時頻域數據融合,豐富輸入信息。
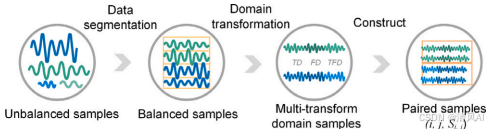
圖7?
Case 1(Paderborn大學數據集)??:
- ?數據集?:包括健康軸承和5種故障類型(如表1),在不同工況(轉速、負載)下收集振動和電流數據。樣本按比例?λ(健康樣本與故障樣本比)分組,模擬不平衡(如表2)。
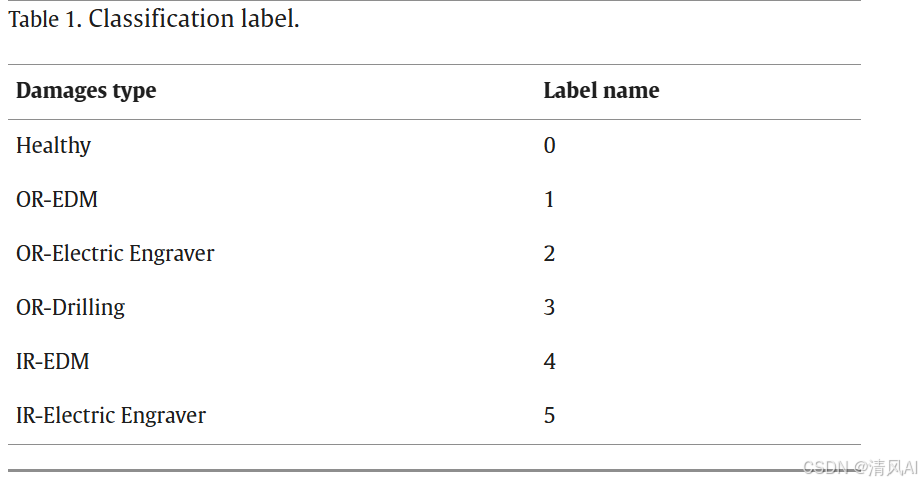 ?
?
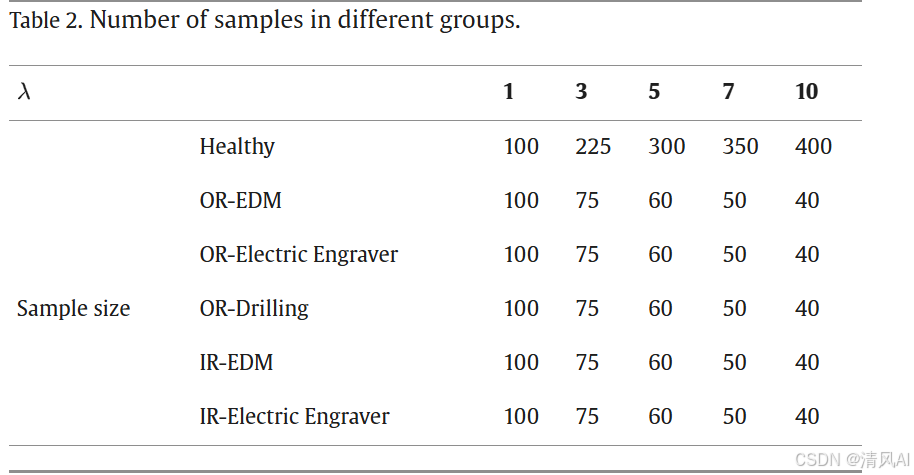 ?
?
?

圖8?
結果?:
- ?準確率?:當?λ=10(高度不平衡),方法準確率達94%(圖10e),遠高于傳統方法(如CNN、SVM僅50%)。混淆矩陣顯示(圖10),方法在各類故障上均表現穩健。
?
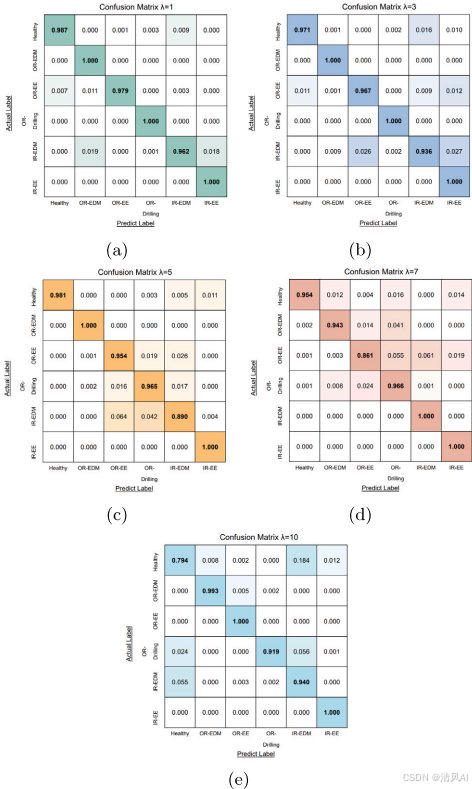
圖10?
消融實驗?:圖11比較各訓練階段。單傳感器預訓練(Vib-FET)在?λ<3?時準確率90%,但?λ=10?時降至75%;直接融合(FFT)在平衡時達96%,但不穩定;多階段訓練(Proposed)保持一致性(λ=10?時94%)。?
?
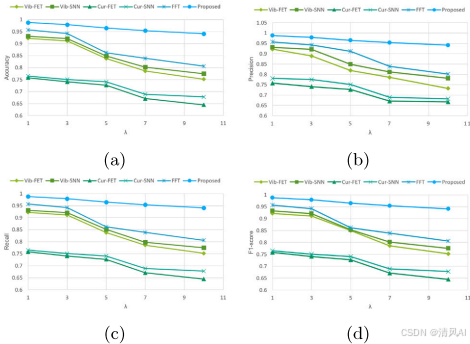
圖11?
與傳統方法比較?:圖12顯示,方法優于CNN、LSTM、SMOTE和DCGAN,尤其在?λ=10?時F1-score達0.93。?
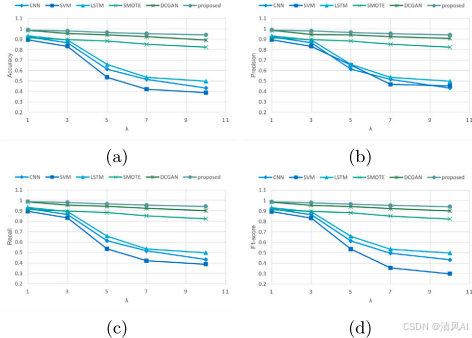
圖12?
??特征可視化?:圖13顯示t-SNE降維后,各類故障特征聚類明顯,證明方法特征提取能力。

圖13?
?
Case 2(實驗室數據集)??:
- ?數據集?:收集振動和電壓數據(如圖15),包括4種故障類型(如表7)。實驗組按傳感器通道分組(如表6)。
?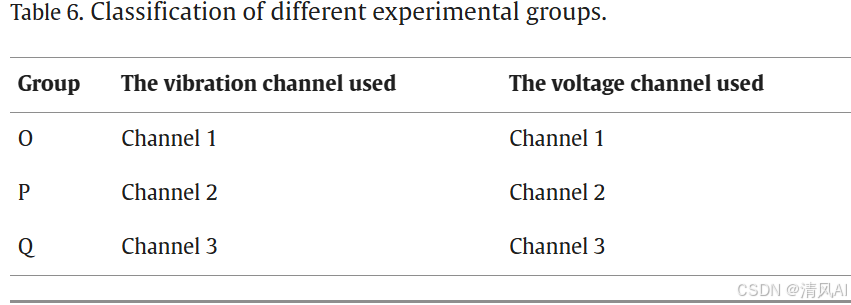
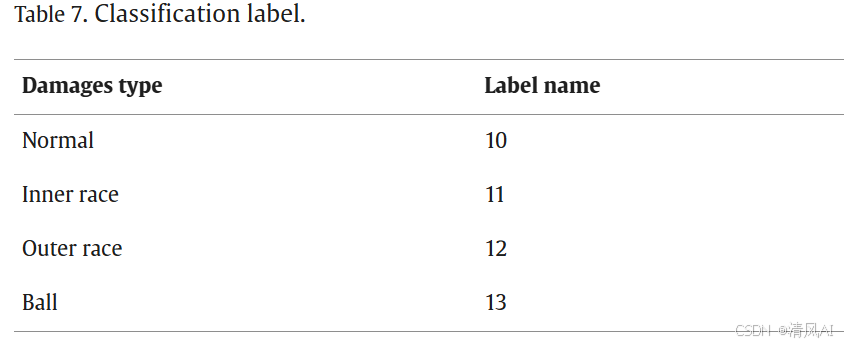
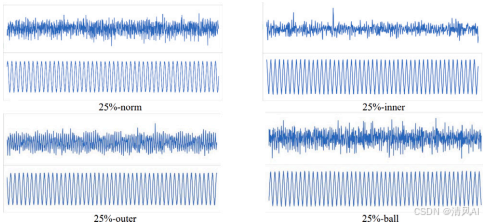
圖15?
結果?:類似Case 1,方法在?λ=10?時準確率93%(圖18e)。消融實驗(圖19)和比較實驗(圖20)證實多階段訓練和融合的優越性,傳統方法(如SVM)準確率降至40%。?
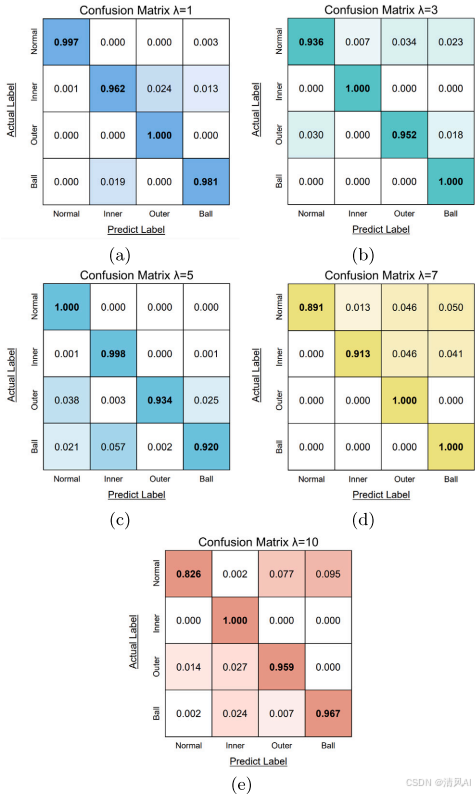
圖18?
?
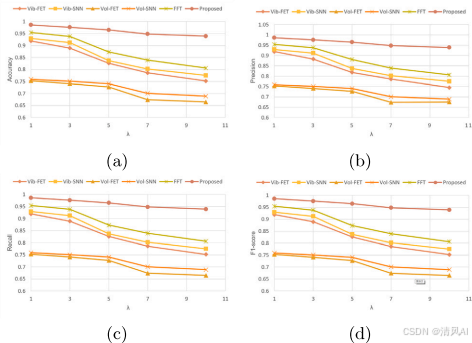
圖19?
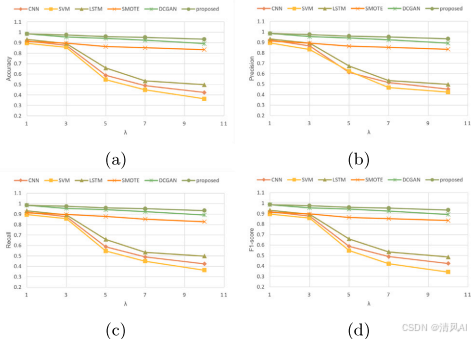
圖20?
?
核心代碼實現(PyTorch框架)
?1. SNN特征提取器(多尺度卷積模塊)
import torch
import torch.nn as nnclass MultiScaleConvModule(nn.Module):def __init__(self, in_channels):super().__init__()# MCM1結構(圖4a)self.branch1 = nn.Conv1d(in_channels, 16, kernel_size=1)self.branch3 = nn.Conv1d(in_channels, 32, kernel_size=3, padding=1)self.branch7 = nn.Conv1d(in_channels, 32, kernel_size=7, padding=3)# MCM2結構(圖4b)self.branch1x1 = nn.Conv1d(80, 64, kernel_size=1) # 輸入通道=16+32+32self.branch1x3 = nn.Conv1d(80, 64, kernel_size=3, padding=1)def forward(self, x):# 多尺度特征并聯x1 = nn.ReLU()(self.branch1(x))x3 = nn.ReLU()(self.branch3(x))x7 = nn.ReLU()(self.branch7(x))x_concat = torch.cat([x1, x3, x7], dim=1) # 沿通道維度拼接# 多尺度特征融合x1x1 = nn.ReLU()(self.branch1x1(x_concat))x1x3 = nn.ReLU()(self.branch1x3(x_concat))return x1x1 + x1x3 # 殘差連接class FeatureExtractor(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv1d(1, 16, kernel_size=16, stride=1)self.conv2 = nn.Conv1d(16, 32, kernel_size=32, stride=2)self.mcm1 = MultiScaleConvModule(32)self.mcm2 = MultiScaleConvModule(64) # 輸入通道與MCM1輸出一致self.pool = nn.AdaptiveAvgPool1d(1) # 全局池化def forward(self, x):x = nn.ReLU()(self.conv1(x))x = nn.ReLU()(self.conv2(x))x = self.mcm1(x)x = self.mcm2(x)return self.pool(x).squeeze(-1) # 移除時間維度?2. 多源特征融合網絡(帶注意力機制)?
class AttentionFusion(nn.Module):def __init__(self, feature_dim, reduction_ratio=16):super().__init__()self.compression = nn.Sequential(nn.Linear(feature_dim * 4, feature_dim // reduction_ratio), # 公式(4)nn.ReLU(),nn.Linear(feature_dim // reduction_ratio, feature_dim))self.softmax = nn.Softmax(dim=1)def forward(self, feat_a, feat_b):# 全局平均池化與最大池化(公式2-3)avg_a = torch.mean(feat_a, dim=1)max_a, _ = torch.max(feat_a, dim=1)avg_b = torch.mean(feat_b, dim=1)max_b, _ = torch.max(feat_b, dim=1)# 全局特征拼接(公式4)global_feat = torch.cat([avg_a, max_a, avg_b, max_b], dim=1)compact_feat = self.compression(global_feat)# 通道注意力權重(公式5)pa = self.softmax(compact_feat[:, :feat_a.shape[1]]) # 分割激勵信號pb = self.softmax(compact_feat[:, feat_a.shape[1]:])# 特征融合(公式6)fused = (pa.unsqueeze(-1) * feat_a + feat_a) + \(pb.unsqueeze(-1) * feat_b + feat_b)return fused?結論與未來工作總結?
- ?主要結論?:方法有效解決了電機軸承故障診斷中的小樣本和數據不平衡問題。SNN的多階段訓練緩解了訓練停滯,特征融合提升了多源數據利用率。實驗證明,在兩個數據集上,方法在高度不平衡(λ=10)時準確率均超93%,優于傳統方法。
- ?貢獻強調?:(1) 多階段訓練策略為SNNs提供新優化路徑;(2) 多源融合網絡增強特征表示;(3) 方法通用性強,適用于不同傳感器和工況。
- ?未來工作?:包括(1) 擴展至其他故障診斷任務;(2) 結合優化算法(如遺傳算法)調參;(3) 開發深度融合方法處理極端場景;(4) 整合模型驅動方法提升魯棒性。

![洛谷 P10264 [GESP202403 八級] 接竹竿 普及+/提高](http://pic.xiahunao.cn/洛谷 P10264 [GESP202403 八級] 接竹竿 普及+/提高)


)












如何排查原因和處理?)
)
