目錄
前言
一、LoRA 的核心思想
二、LoRA 為什么高效?
? 1. 參數效率
? 2. 內存友好
? 3. 即插即用
三、LoRA 適用場景
四、LoRA 實踐建議
五、LoRA 和全參數微調對比
六、?LoRA的具體定位
📌 總結
🔗 延伸閱讀

前言
在大模型時代,微調(Fine-tuning)已成為模型落地的關鍵手段之一。但面對動輒幾十億甚至千億參數的模型,全量微調往往意味著高昂的計算成本與資源消耗。這時,LoRA(Low-Rank Adaptation)應運而生,成為一種高效、輕量、即插即用的微調利器。
一、LoRA 的核心思想
LoRA 的設計哲學是:不要動大模型的原始參數,而是“加點小東西”來改變行為。
在傳統微調中,我們需要對整個預訓練模型中的權重進行更新,而 LoRA 提出了一個創新的思路:
只訓練兩個小矩陣 A 和 B,并將它們嵌入原有的線性層中。
其數學表達如下:
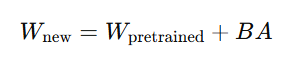
其中:
-
WpretrainedW_{\text{pretrained}}Wpretrained?:凍結的大模型原始權重;
-
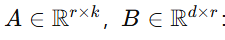 :新增的可訓練參數;
:新增的可訓練參數; -
r?d,k:秩遠小于原始維度(通常 r=8~64),這就是“Low-Rank”的由來。
這樣做的核心優勢是:不動原始模型,僅通過“添加低秩擾動”進行模型適配。
二、LoRA 為什么高效?
? 1. 參數效率
LoRA 只需訓練少量參數(A 和 B)。比如一個 70B 的大模型,僅需訓練約 0.1%~1% 的參數:
💡 舉例:70B 模型約 7000M 參數,LoRA 僅需訓練約 70M 參數。
這極大地減輕了訓練負擔。
? 2. 內存友好
由于只訓練 A、B 小矩陣,前向傳播時計算量大幅下降,反向傳播時僅對小矩陣求梯度,因此顯存消耗顯著降低:
📉 通常顯存降低 35 倍,適用于 12 張消費級顯卡。
? 3. 即插即用
訓練好的 A、B 矩陣可以單獨保存為 adapter 權重(如 adapter_model.bin),后續加載時可按需組合:
-
原始模型保持不變;
-
多個 LoRA 模塊可根據不同任務動態加載;
-
便于模型管理、部署與復用。
? LoRA 權重可以直接被本地預訓練模型加載使用,只要你用的是支持 LoRA 的加載方式(如
peft),并確保模型架構一致。這也是 LoRA 的核心優勢之一:即插即用、任務解耦、部署靈活。
三、LoRA 適用場景
LoRA 尤其適用于以下場景:
| 應用類型 | 描述說明 |
|---|---|
| 🎙? 指令跟隨 | 訓練模型理解并響應自然語言指令,如 ChatGPT 樣式交互 |
| 🧑?💼 角色扮演 | 給模型注入特定角色或個性,如“AI 女友”、“法律顧問” |
| 📚 知識注入 | 為模型注入特定領域知識,如金融、醫療、工業文檔 |
| 🗣? 多語言適配 | 將英文基礎模型遷移到小語種領域 |
| 📱 邊緣部署 | 將微調后的小 LoRA 模塊應用于低算力設備 |
四、LoRA 實踐建議
-
推薦工具鏈:🤖 Hugging Face +
peft(Parameter-Efficient Fine-Tuning)庫; -
推薦秩(rank)值:r=8 或 16 通常效果已足夠;
-
保存方式:adapter 格式保存,原模型可復用,便于熱加載;
-
部署模式:多個 LoRA 模型可組合,如“醫生 + 指令精調”。
五、LoRA 和全參數微調對比
| 項目 | 全量微調 | LoRA 微調 |
|---|---|---|
| 參數量 | 100% | 0.1% ~ 1% |
| 顯存占用 | 高 | 低 |
| 訓練速度 | 慢 | 快 |
| 遷移性 | 差 | 高,可組合多個 LoRA |
| 原模型改動 | 修改原始權重 | 不修改原模型結構 |
六、?LoRA的具體定位
LoRA是**參數高效微調(PEFT)**的一個典型代表,屬于局部微調的子類。它的核心特點是:
- 凍結原始模型:不修改 W,保證原始模型的完整性。
- 新增少量參數:通過 A 和 B 矩陣引入少量可訓練參數。
- 任務特定適配:為特定任務(如指令跟隨、領域知識注入)快速調整模型行為。
- 模塊化設計:LoRA適配器獨立于原始模型,易于保存、加載和切換。
這些特性使LoRA與局部微調的理念高度契合,而與增量微調的“持續更新全模型”目標有所不同。
LoRA被歸為局部微調,因為它通過引入少量可訓練參數(低秩矩陣 A ?和 B )來實現任務適配,而不修改原始模型參數。盡管它凍結了全部原始參數,這與某些增量微調的場景有表面相似之處,但LoRA的模塊化設計、參數效率和任務特定適配的特性使其更符合局部微調的定義。增量微調更側重于通過持續訓練更新模型的整體能力,通常涉及直接修改原始參數,這與LoRA的機制不同。
術語 狹義解釋 廣義解釋(更通用) LoRA 屬于哪類 局部微調 微調原模型部分參數 凍結原模型,僅訓練少量參數(包括新增參數) ? 屬于 增量微調 持續更新原模型參數 對原模型進行“數據/任務”驅動的全模型增強 ? 不屬于
【舉例說明】
- 局部微調(LoRA):假設你有一個70億參數的模型,想讓它適配客服對話任務。使用LoRA,你凍結原始模型,添加并訓練低秩矩陣(約7000萬參數),生成一個小型適配器文件。這個適配器可以快速加載到原始模型,用于客服任務,且不影響原始模型的其他能力。
- 增量微調:如果你想讓同一個模型通過大量新數據(例如多語言語料)來提升其多語言能力,可能需要對全部或大部分參數進行持續訓練。這會直接修改原始模型權重,屬于增量微調。
📌 總結
LoRA 的提出,為我們提供了一種高效、靈活、可組合的大模型微調方式。它將復雜的全參微調問題簡化為“小模塊+大模型”的組合形式,大大降低了訓練門檻,是當前最流行的參數高效微調方案之一。
在大模型應用爆發的當下,掌握 LoRA,不僅能節省資源,還能提升開發效率,是每一個 AI 開發者必備的技能!
🔗 延伸閱讀
-
Hugging Face PEFT 官方文檔
-
原始論文:LoRA: Low-Rank Adaptation of Large Language Models
-
實戰推薦:在 llama2、Qwen、ChatGLM 等模型中使用 LoRA 微調

)



)









)



