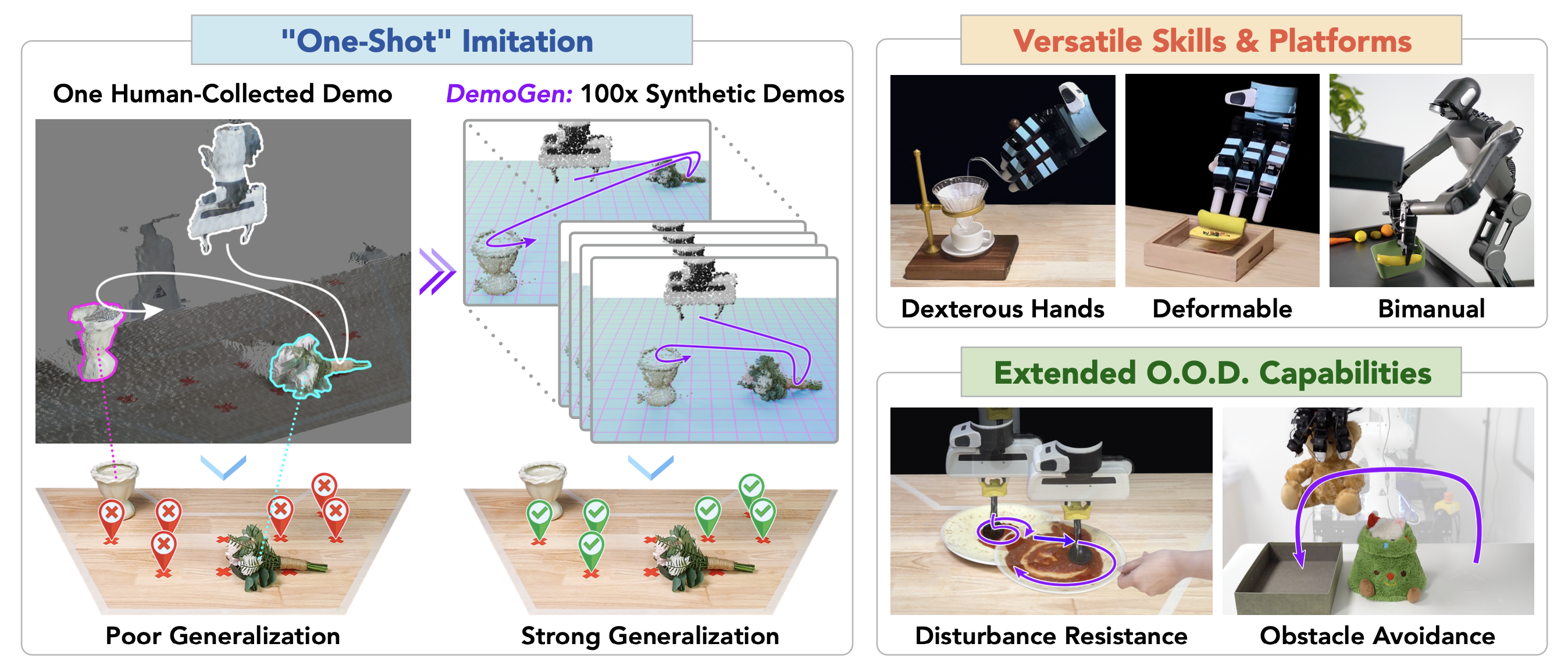
25年2月來自清華、上海姚期智研究院和上海AI實驗室的論文“DemoGen: Synthetic Demonstration Generation for Data-Efficient Visuomotor Policy Learning”。
視覺運動策略在機器人操控中展現出巨大潛力,但通常需要大量人工采集的數據才能有效執行。驅動高數據需求的一個關鍵因素,是其有限的空間泛化能力,這需要跨不同物體配置收集大量數據。本研究提出 DemoGen,一種低成本、完全合成的自動演示生成方法。DemoGen 每個任務僅使用一個人工采集的演示,通過將演示的動作軌跡調整到新的物體配置來生成空間增強的演示。通過利用 3D 點云作為模態并通過 3D 編輯重新排列場景中的主體來合成視覺觀測。經驗表明,DemoGen 顯著提升各種現實世界操控任務的策略性能,即使在涉及可變形體、靈巧手末端執行器和雙手平臺的挑戰性場景中也表現出其適用性。此外,DemoGen 可以擴展以實現額外的分布外(OOD)能力,包括抗干擾和避障。
視覺運動策略學習已在機器人操控任務中展現出卓越的能力 [7, 61, 16, 59],但它通常需要大量人工收集的數據。最先進的方法通常需要數十到數百次演示才能在復雜任務上取得一定程度的成功,
例如在披薩上涂抹醬汁 [7] 或用靈巧的手制作卷餅 [59]。更復雜、更長遠的任務可能需要數千次演示 [62]。
導致這些方法數據密集型特性的一個關鍵因素,是其有限的空間泛化能力 [41, 43]。實證研究表明,即使與預訓練或 3D 視覺編碼器 [33, 39, 34, 59] 結合使用,視覺運動策略 [7] 也表現出有限的空間容量,通常局限于與演示的物體配置相鄰的區域。這種限制需要反復收集重定位物體的數據,直到演示的配置充分覆蓋整個桌面工作空間。這就產生了一個悖論:雖然實現靈巧操作的關鍵動作集中在一小部分接觸豐富的片段中,但人類的大量精力卻花在了教機器人接近自由空間中的物體上。
減少重復人工勞動的一個潛在解決方案,是用自動演示生成來取代繁瑣的重定位和重新收集過程。MimicGen [32] 及其后續擴展 [20, 18, 22] 等最新進展提出,通過基于物體交互對演示軌跡進行分段來生成演示。然后,這些以物體為中心的片段被轉換并插值到適合所需空間增強物體配置的執行規劃中。之后,生成的規劃通過機器人上的開環部署(稱為機器人上部署)來執行,以驗證其正確性并同時捕獲策略訓練所需的視覺觀察結果。
盡管 MimicGen 式策略在模擬環境中取得成功,但將其應用于現實環境卻受到高昂的機器人部署成本的阻礙,其成本幾乎與收集原始演示的成本相當。另一種方法是通過模擬-到-現實的遷移進行部署 [36, 44, 56],盡管彌合模擬到現實的差距仍然是機器人技術領域的一項重大挑戰。
本研究介紹 DemoGen,這是一個數據生成系統,可以無縫地接入模擬和物理世界中的策略學習工作流程中。如圖所示:
空間有效范圍可視化
空間泛化,是指策略執行涉及訓練期間未見過物體任務的能力。為了直觀地理解空間泛化,將視覺運動策略的空間有效范圍與演示數據的空間分布之間的關系可視化。
任務。評估改編自 MetaWorld [54] 基準的“Button-Large”任務,其中機器人接近一個按鈕并按下。物體隨機化范圍修改為桌面工作空間上 30cm × 40cm = 1200cm2 的區域,覆蓋末端執行器的大部分可觸及空間。注意到即使按下動作沒有精確擊中按鈕中心,按鈕的尺寸也較大,因此還研究一個對精度要求更高的變型“Button-Small”,其中按鈕尺寸縮小 4 倍。
策略。采用 3D 擴散策略 (DP3) [59] 作為研究策略,因為基準測試結果表明,3D 觀測比 2D 方法具有更出色的空間泛化能力。
評估。為了可視化空間有效范圍,在工作空間內沿每個軸均勻采樣 21 個點,共得到 441 個不同的按鈕位置。演示是使用腳本策略生成的,具有 4 種不同的空間分布,從 single 到 full。在 441 個位置上評估每種配置的性能,從而可以全面評估空間泛化能力。可視化結果如圖所示。
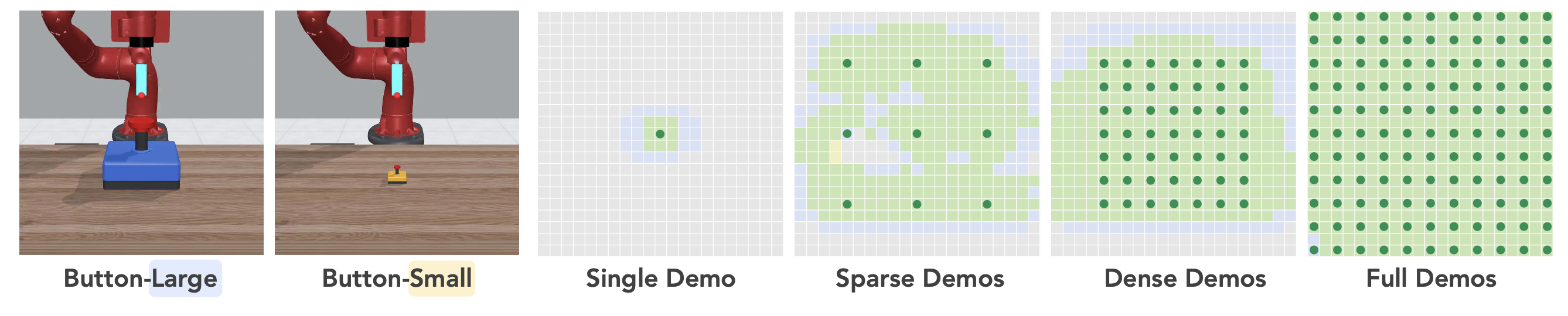
主要發現。總體而言,視覺運動策略的空間有效范圍與演示中看到的物體配置分布密切相關。具體而言,有效范圍可以通過演示物體位置周圍區域的并集來近似。因此,為了訓練一個能夠在整個目標隨機化范圍內良好泛化的策略,演示必須覆蓋整個工作空間,這將導致巨大的數據收集成本。此外,隨著任務精度要求的提高,有效范圍會縮小到更局部的區域,因此需要進行更多次演示才能充分覆蓋整個工作空間。
空間泛化能力基準測試
空間泛化能力的實際表現,體現在有效策略學習所需的演示次數上。在接下來的基準測試中,將探討演示次數與策略性能之間的關系,以確定多少次演示足以進行有效的訓練。
任務。為了抑制策略部署不準確但成功的情況,設計一個精確插釘任務,該任務在拾取和插入階段均強制執行 1 厘米的嚴格容錯,要求達到毫米級精度。插釘和插座在40厘米×20厘米的區域內隨機分布,從而產生40厘米×40厘米=1600平方厘米的有效工作空間。為了檢驗目標隨機化的影響,還考慮半工作空間(其中兩個目標的隨機化范圍減半)和固定設置(其中目標位置保持不變)。
策略。除了從頭訓練的擴散策略 (DP) [7] 和 3D 擴散策略 (DP3) [59] 之外,還探索預訓練視覺表征在增強空間泛化方面的潛力。具體而言,將 DP 中從頭訓練的 ResNet [19] 編碼器替換為預訓練的編碼器,包括 R3M [33]、DINOv2 [34] 和 CLIP [39]。
演示。將演示的數量從 25 到 400 不等。目標配置是從比評估工作區略大的范圍隨機采樣的,以避免在工作區邊界附近性能下降。
評估。在完整工作區中,將釘子和插座放置在 45 個均勻采樣的坐標上,從而產生 2025 種不同的配置用于評估。對于半值設置和固定設置,評估的配置數量分別為 225 和 1。結果如圖所示。
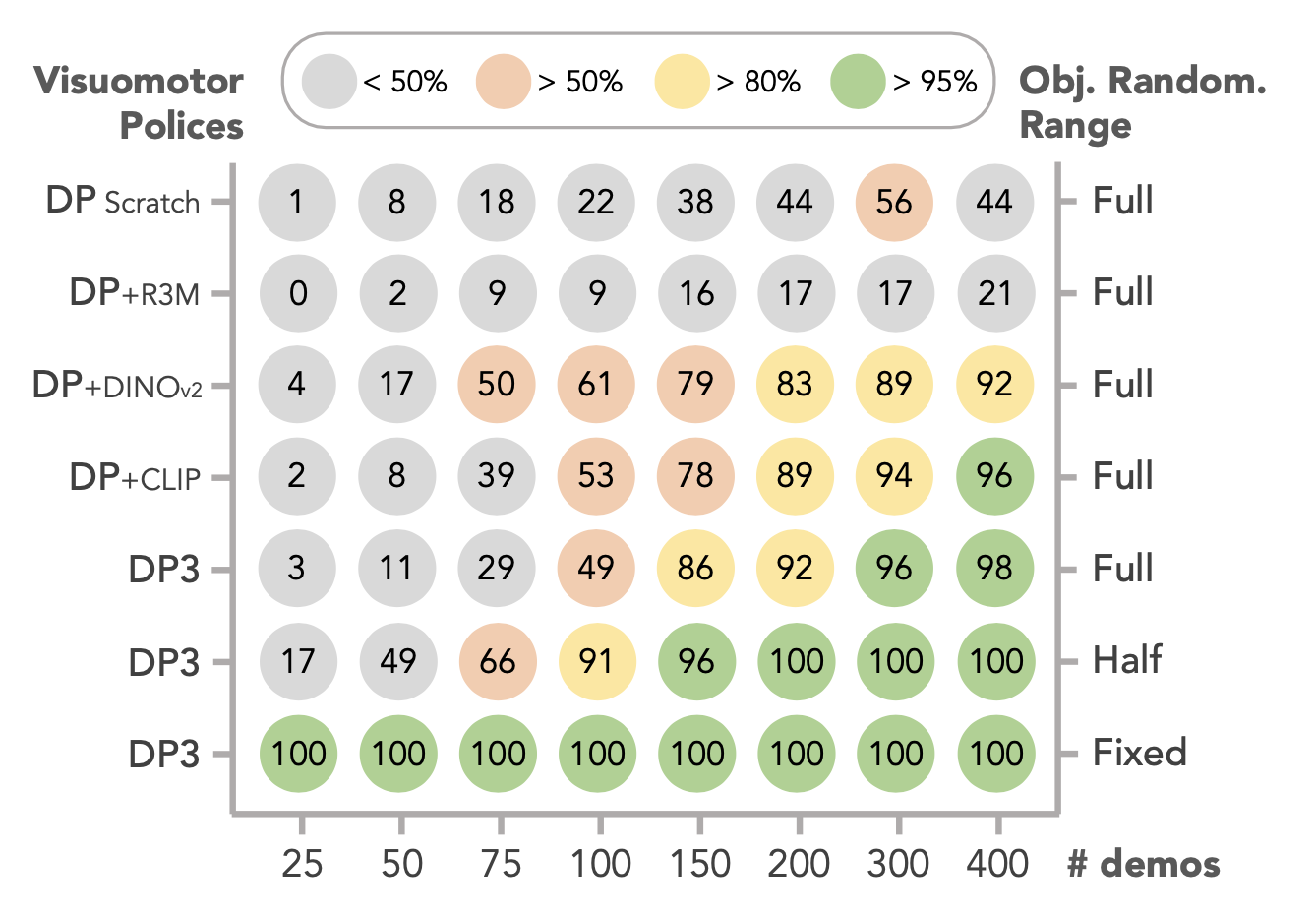
主要發現。物體隨機化的程度顯著影響所需的演示。因此,有效的視覺運動策略評估協議必須包含足夠大的工作空間,以提供足夠的物體隨機化。另一方面,3D 表征和預訓練的 2D 視覺編碼器都有助于提升空間泛化能力。然而,這些方法均未從根本上解決空間泛化問題。這表明,智體的空間能力并非源于策略本身,而是通過對給定演示中工作空間的廣泛遍歷而發展起來的。
DemoGen 旨在解決視覺運動策略的海量數據需求與人工采集演示的高昂成本之間的矛盾,它通過少量源演示生成空間增強的觀察-動作對。對于動作,DemoGen 將源軌跡解析為以目標為中心的運動和技能片段,并應用基于 TAMP (任務和運動規劃)的自適應算法。對于觀察,DemoGen 使用分割-和-變換策略高效地合成機器人和目標的點云。
視覺運動策略 π 直接將視覺觀察 o 映射到預測動作 a。為了訓練這樣的策略,必須準備一個包含演示的數據集 D。DemoGen 旨在通過生成基于不同初始目標配置的新演示來增強人工收集的源演示。
源演示的預處理
分割點云觀測值。為了提高在實際場景中的實用性,使用單視角 RGBD 相機采集點云。首先對原始點云觀測值進行預處理,從背景和桌面裁剪掉多余的點。假設保留的點與被操作物體或機器人的末端執行器相關。然后應用聚類操作 [14] 濾除嘈雜實際觀測值中的異常點。隨后,使用最遠點采樣將點云下采樣到固定數量的點(例如 512 或 1024),以促進策略學習 [38]。
對于軌跡的第一幀,使用 Grounded SAM [40] 從 RGB 圖像中獲取被操作物體的分割掩碼。然后將這些掩碼應用于像素對齊的深度圖像,并投影到 3D 點云上,如圖所示。
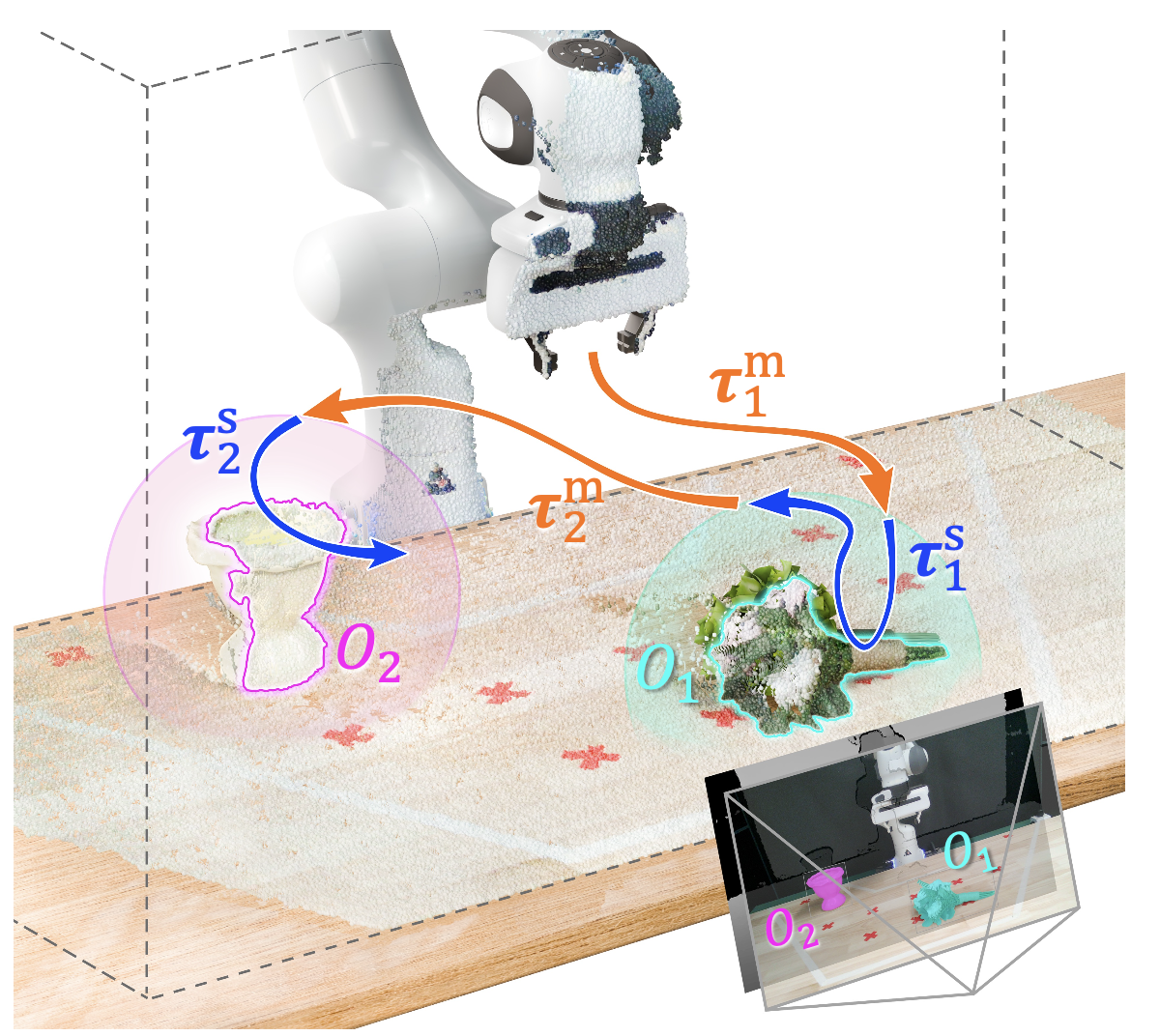
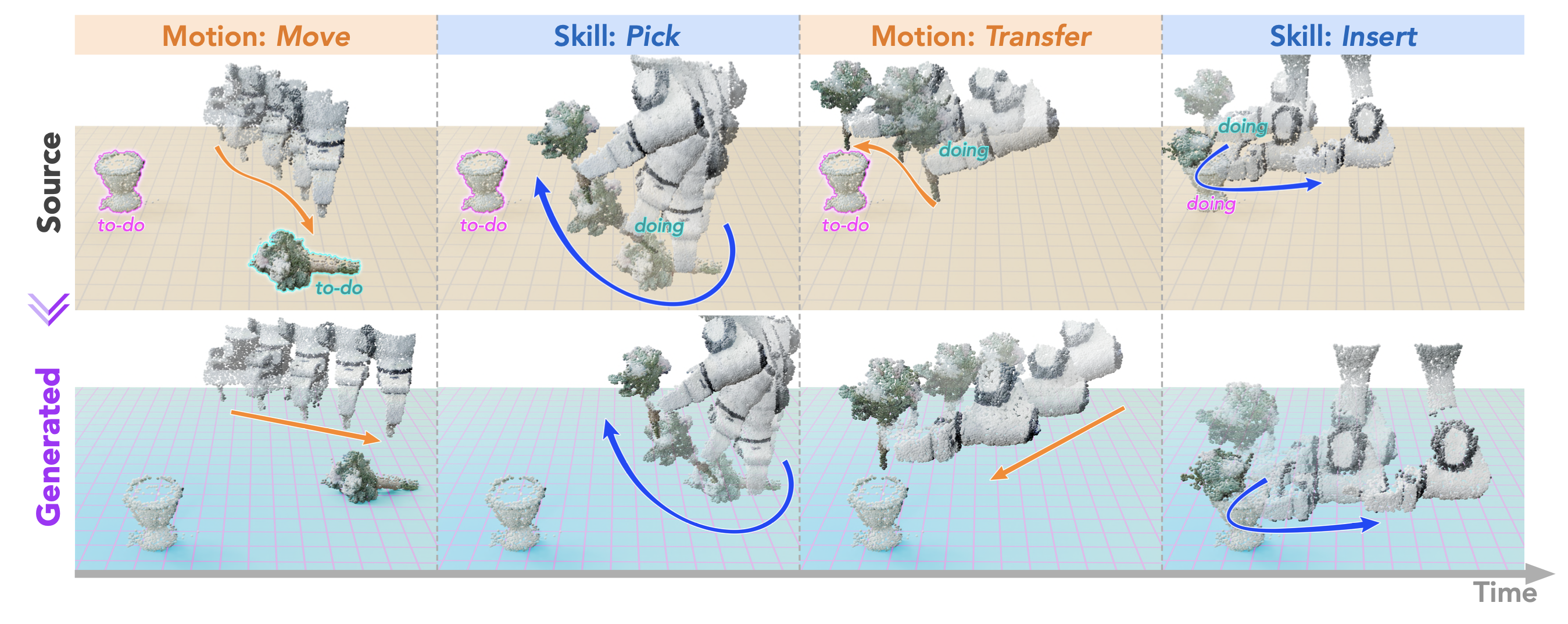
解析源軌跡。根據先前的研究 [32, 18],假設執行軌跡可以解析為一系列以物體為中心的片段。注意到機器人必須首先在自由空間中接近物體,然后才能通過接觸進行物體操作,因此每個以物體為中心的片段可以進一步細分為兩個階段:運動階段和技能階段。例如,在如圖所示的任務中,軌跡分為四個階段:1) 移向花朵,2) 拿起花朵,3) 將花朵移入花瓶,4) 將花朵插入花瓶。
通過檢查物體點云的幾何中心和機器人末端執行器之間的距離是否在預定義的閾值內,可以輕松識別與給定物體相關的技能段,如圖中的球體所示。兩個技能段之間的中間軌跡被歸類為運動段。
基于 TAMP 的動作生成
使動作適應新的配置。生成過程首先選擇一個目標初始配置 s′_0 = {T’_0O1, T’_0O2, …, T’_0^OK}。在 4 × 4 齊次矩陣表示下,計算目標配置和源配置之間的空間變換。
回想一下,這些動作由機械臂和機械手命令組成。機械手命令定義與物體的交互動作,例如,用夾持器夾住花朵,或者用靈巧的手卷起面團。由于它們不隨空間變換而變化,因此無論物體配置如何,a_t^hand 都應保持不變。
相反,機械臂命令,應與物體運動在空間上等變,以便根據改變的配置調整軌跡。具體來說,對于涉及第 k 個目標的運動和技能片段,按照基于 TAMP 的程序調整機械臂命令 AEE [τ_km ]、AEE [τ_k^s ],如圖所示。

對于具有靈巧的物體行為技能段,末端執行器與物體之間的空間關系必須保持相對靜態。因此,整個技能段會跟隨相應的物體進行變換。
對于在自由空間中移動的運動段,目標是將相鄰的技能段串聯起來。因此,通過運動規劃來規劃運動階段的機械臂指令。
對于簡單整潔的工作空間,線性插值即可。對于需要避障的復雜環境,采用現成的運動規劃方法 [26]。
無故障動作執行。為了確保無需機器人上展開(以過濾失敗的軌跡)的合成演示有效性,要求動作執行無故障。與以往[32, 18]依賴操作空間控制器和增量末端執行器位姿控制的研究不同,我們采用逆運動學 (IK) 控制器 [57],并以絕對末端執行器位姿為目標。經驗表明,這些調整有助于最大限度地減少復合控制誤差,從而有助于成功執行生成的動作。
完全合成觀測生成
自適應本體感受狀態。觀測數據由點云數據和本體感受狀態組成。由于本體感受狀態與動作具有相同的語義,因此它們應該經歷相同的轉換。
注:直接用下一個目標姿態動作(即 o?_tarm ← a?_t+1^arm)替換當前手臂狀態可能會影響性能,因為反向運動控制器可能無法始終達到精確的目標姿態。
合成點云觀測值。為了合成機器人和物體的空間增強點云,采用一種簡單的分割-和-變換策略。除了目標變換之外,合成唯一需要的信息是源演示第一幀中 K 個物體的分割掩碼。
對于每個物體,定義 3 個階段。在待完成(to-do)階段,物體處于靜止狀態且不受機器人影響,其點云根據初始物體配置進行變換 (T_oO_k)?1 · T_0^O_k′。在執行(doing)階段,物體與機器人接觸,其點云與末端執行器的點云合并。在完成(done)階段,物體保持其最終狀態。通過參考軌跡級運動和技能段,可以輕松識別這些階段。
對于機器人的末端執行器,其點云經歷與本體感受狀態相同的變換,即 (A_tEE)?1·A?_t^EE。假設工作空間被裁剪,可以通過從場景點云中減去待執行和完成階段的物體點云,來分離執行階段的機器人點云和物體點云。
此過程的具體示例如圖所示。
策略訓練與實施細節
選擇三維擴散策略 (DP3) [59] 作為用于真實世界和模擬實驗的視覺運動策略。在第三部分中,我們將它的性能與二維擴散策略 (DP) [7] 進行實證研究比較。訓練與實施細節如下。
- 策略訓練細節:為了公平比較,將所有評估設置中按“觀察-動作”對計數的總訓練步數固定為 2M,這樣無論數據集大小如何,訓練成本都相同。為了穩定訓練過程,使用 AdamW [30] 優化器,并將學習率設置為 1e?4,并進行 500 步預熱。
在實際實驗中,使用 DBSCAN [14] 聚類算法丟棄異常點,并將點云觀測中的點數下采樣至 1024。在模擬器中,跳過聚類階段,將點云下采樣至 512 個點。
遵循擴散策略 [7] 論文中的符號,其中 To 表示觀測范圍,Tp 表示動作預測范圍,Ta 表示動作執行范圍。在實際實驗中,設置 To = 2、Tp = 8、Ta = 5。以 10Hz 的頻率運行視覺運動策略。由于 Ta 表示無需重規劃即可在機器人上執行的動作步驟,因此范圍設置可使閉環重規劃延遲為 0.5 秒,足以響應靈巧的重試行為并具有抗干擾能力。在模擬器中,由于任務比較簡單,設定To = 2,Tp = 4,Ta = 3。
2)用于擴散策略的預訓練編碼器:為了替換原始擴散策略架構中從頭開始訓練的ResNet18 [19]視覺編碼器,考慮3個具有代表性的預訓練編碼器:R3M [33]、DINOv2 [34]和CLIP [39]。R3M采用ResNet [19]架構,并針對機器人特定任務進行預訓練。DINOv2和CLIP采用ViT [13]架構,并針對開放世界視覺任務進行預訓練。這些編碼器在先前的研究[8, 29]中被廣泛用于提升策略性能。

![Muduo網絡庫實現 [十六] - HttpServer模塊](http://pic.xiahunao.cn/Muduo網絡庫實現 [十六] - HttpServer模塊)







)


---【AniYaGUI1.2.0、AV_Evasion_Tool掩日、FoxBypass_V1.0】)

)

框架基礎)


