文章目錄
- 一、什么是K近鄰算法
- 二、KNN算法流程總結
- 三、Scikit-learn工具
- 1、安裝
- 2、導入
- 3、簡單使用
- 三、距離度量
- 1、歐式距離
- 2、曼哈頓距離
- 3、切比雪夫距離
- 4、閔可夫斯基距離
- 5、K值的選擇
- 6、KD樹
一、什么是K近鄰算法
如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別。
二、KNN算法流程總結
- 1、計算已知類別數據集中的點與當前點之間的距離
- 2、按距離遞增排序
- 3、選取與當前距離最小的k個點
- 4、統計前k個點所在的類別出現的頻率
- 5、返回前k個點出現頻率最高的類別作為當前點的預測分類
三、Scikit-learn工具
1、安裝
pip3 install scikit-learn
2、導入
import sklearn
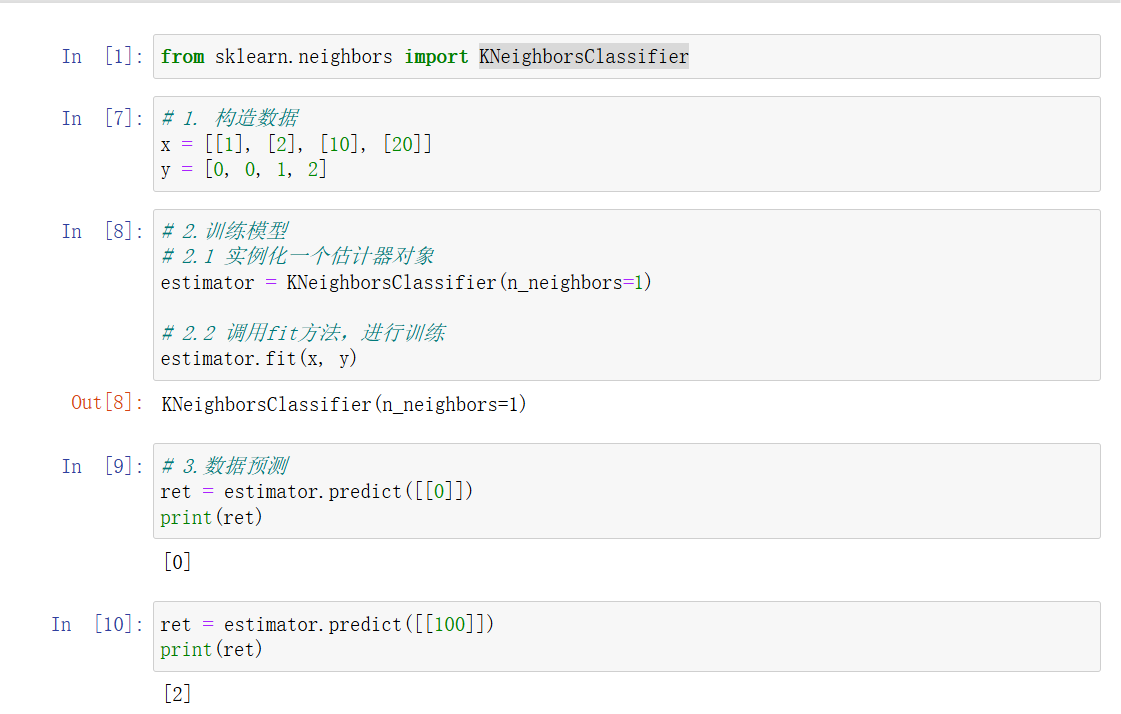
3、簡單使用
三、距離度量
1、歐式距離
歐式距離是最容易直觀理解的距離度量方法,我們小學、初中、高中接觸到的兩個點在空間中的距離一般都是值歐式距離。

2、曼哈頓距離

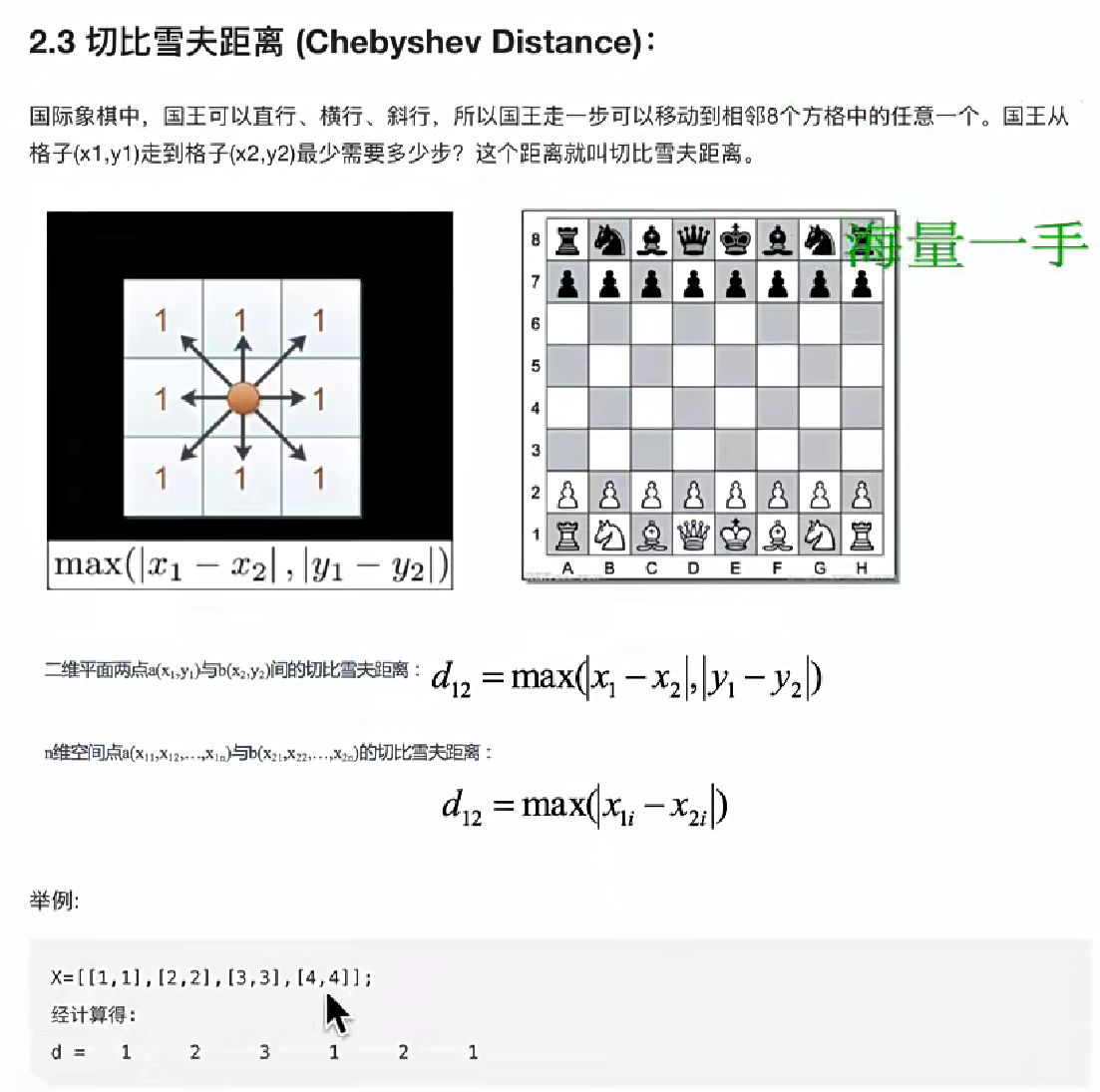
3、切比雪夫距離
4、閔可夫斯基距離

5、K值的選擇

6、KD樹
import numpy as np
# 自己實現kd樹
# 一、構建kd樹
# 1.確定根據哪一個維度進行劃分,求方差,方差越大,數據越分散
# 2.以哪個點為切面,求中位數,離中位數越近的點作為根節點
# 3.比中位數的該維度小的放左邊,大的放右邊
# 4.重復以上步驟,所有的點就都在樹中了
class KdNode(object):def __init__(self, node_data, split_index, left, right):self.node_data = np.array(node_data) # 節點的數據self.split_index = split_index # 分割的維度的序號self.left = left # 左節點self.right = right # 右節點class KdTree(object):split_index_list = np.array([])data = np.array([])rootNode = Nonedef __init__(self, data):self.k = len(data[0]) # 獲取數據的維度self.data = np.array(data) # 所有的數據# 獲取分割的維度順序數組self.getSplitIndexList()# 構建樹self.rootNode = self.createNode(0, self.data)def getSplitIndexList(self):# 獲取方差排序后的下標的數組,最后[::-1來反轉]self.split_index_list = np.argsort([np.var(self.data[:, (i)]) for i in range(self.k)])[::-1]def closest_to_median_index(self, array):median = np.median(array)diff = np.abs(array - median)return diff.argmin() # 返回第一個最小差值的索引def createNode(self, index, dataList):if len(dataList) == 0:return Nonesplit_index = self.split_index_list[index]split_next = (index + 1) % self.k# 獲取分割維度的中位數下標data_index = self.closest_to_median_index(dataList[:,(split_index)])# 獲取該位置的數據rootData = dataList[data_index]# 刪除找到的這個節點dataList = np.delete(dataList, data_index, 0)# 獲取左側的所有數據leftData = dataList[dataList[:,(split_index)] <= rootData[split_index]]# 獲取右側所有的數據rightData = dataList[dataList[:,(split_index)] > rootData[split_index]]return KdNode(rootData, split_index, self.createNode(split_next, leftData), self.createNode(split_next, rightData))









——設計模式)








)
