
????前邊我們已經講解了使用cv2進行圖像預處理與邊緣檢測等方面的知識,這里我們以車牌號碼識別這一案例來實操一下。
大致思路
????????車牌號碼識別的大致流程可以分為這三步:圖像預處理-尋找車牌輪廓-車牌OCR識別
接下來我們按照這三步來進行講解。
圖像預處理
首先,在網上隨便找一張車牌照:

讀取圖像?
#讀取原始圖像
import cv2
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
src_path=r'LicensePlate.jpg'
src_image=cv2.imread(filename=src_path,flags=cv2.IMREAD_COLOR_RGB)
print(src_image.shape)
plt.title('原始圖像')
plt.imshow(src_image)
????????這里我使用matplotlib的imshow函數來顯示圖像,這樣在jupyter環境中可以不打開任何彈窗直接顯示圖像,比較方便。
轉為灰度圖
#轉為灰度圖
gray_image=cv2.cvtColor(src=src_image,code=cv2.COLOR_RGB2GRAY)
plt.title('原始圖像(灰度圖)')
plt.imshow(gray_image,cmap='gray')
????????將原始圖像轉化為灰度圖是為了后續的檢測等操作,在計算機視覺任務中,基本上所有的操作都是針對灰度圖來進行的,灰度圖是將原始圖像的多個通道按照一定權重求和疊加而來,這樣一來多通道變成了單通道(),在計算量上也會比較友好。
?閾值化
#閾值化
thresh,binary_image=cv2.threshold(src=gray_image,thresh=128,maxval=255,type=cv2.THRESH_OTSU+cv2.THRESH_BINARY)
plt.imshow(binary_image,cmap='gray')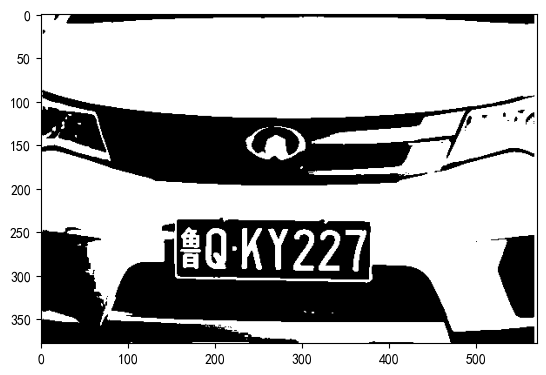
????????閾值化是為了后續的邊緣檢測,通常在邊緣檢測前都需要對圖像進行閾值化操作,這樣識別出來的邊緣相對準確。這里閾值化我們使用cv2.THRESH+cv2.THRESH-OTSU方法來自動對圖像進行二值化閾值分割。?
邊緣檢測
#canny邊緣檢測
edges=cv2.Canny(image=binary_image,threshold1=0.5*thresh,threshold2=thresh,apertureSize=5,L2gradient=True)
plt.imshow(edges,cmap='gray')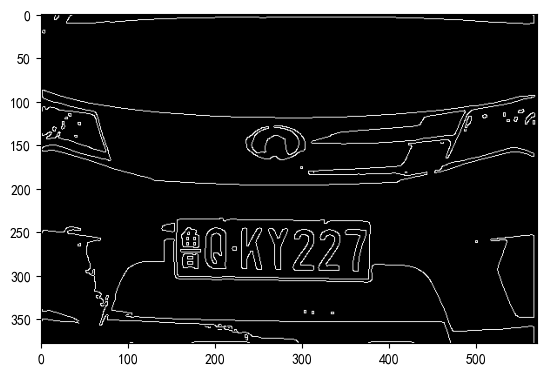
????????邊緣檢測是為了初步提取出車牌的輪廓,便于后續的輪廓查找。常用的邊緣檢測算法有Canny、Sobel、Prewitt等,其中Canny算法具有較高的準確性和魯棒性,因此在本系統中采用Canny算法進行邊緣檢測。不太熟悉邊緣檢測的小伙伴可以去看看我的往期文章:
https://blog.csdn.net/weixin_73953650/article/details/146284620?sharetype=blogdetail&sharerId=146284620&sharerefer=PC&sharesource=weixin_73953650&spm=1011.2480.3001.8118![]() https://blog.csdn.net/weixin_73953650/article/details/146284620?sharetype=blogdetail&sharerId=146284620&sharerefer=PC&sharesource=weixin_73953650&spm=1011.2480.3001.8118
https://blog.csdn.net/weixin_73953650/article/details/146284620?sharetype=blogdetail&sharerId=146284620&sharerefer=PC&sharesource=weixin_73953650&spm=1011.2480.3001.8118
?車牌輪廓查找
#尋找矩形區域輪廓
contours,hiercahy=cv2.findContours(edges,mode=cv2.RETR_TREE,method=cv2.CHAIN_APPROX_SIMPLE)
contours=sorted(contours,key=cv2.contourArea,reverse=True)[:10]
rectangle=None
for point in contours:peri=cv2.arcLength(point,True)polygons=cv2.approxPolyDP(curve=point,epsilon=0.018*peri,closed=True)if len(polygons)==4:rectangle=polygonsplateArea=pointbreak
gray_image_copy=gray_image.copy()
src_image_copy=src_image.copy()
cv2.drawContours(image=src_image_copy,contours=[rectangle],contourIdx=0,color=(255,0,0),thickness=5)
cv2.drawContours(image=gray_image_copy,contours=[rectangle],contourIdx=0,color=255,thickness=5)
figure=plt.figure(figsize=(10,10),dpi=100)
plt.subplot(1,2,1),plt.imshow(src_image_copy),plt.title('車牌定位結果(原始圖像)')
plt.subplot(1,2,2),plt.imshow(gray_image_copy,cmap='gray'),plt.title('車牌定位結果(灰度圖)')?
 ?
?
?????????查找輪廓時我們通常使用findContours函數來進行查找(返回值為所有可能的輪廓點contours以及這些點之間的拓撲結構hierachy),考慮到車牌是矩形區域,因此我們可以在查找到的輪廓點中使用cv2.approxPolyDP函數來對查找到的輪廓進行多邊形擬合(返回值為各個頂點的坐標構成的列表)只要擬合出的多邊形頂點個數為4,那么必然是車牌位置。
? ? ? ?然后,我們再使用cv2.drawContours函數將其在原始圖像中標記出來即可。
車牌分割
# #分割提取車牌
x=[location[0][0] for location in plateArea]
y=[location[0][1] for location in plateArea]
Licenseplate=gray_image[min(y):max(y),min(x):max(x)]#切片圖像
plt.imshow(Licenseplate,cmap='gray')
cv2.imwrite('Plate.jpg',Licenseplate)?

?
????????將車牌從原始圖像中分割出來的思路也很簡單,就是根據我們查找到的輪廓點,來查找其在圖像中的位置。PlatArea是矩形車牌輪廓點構成的列表,其內部為各個點的坐標,其中對于任意一點location來說,location[0][0]表示x坐標,location[0][1]表示y坐標。那么,我們只需找到所有x坐標中的最小值與最大值,y坐標中的最小值與最大值,即可確定這個矩形區域在原圖像中的范圍。?
?最后,我們還需將這個車牌號碼保存一下以便后續的字符識別
OCR識別
????????考慮到車牌是標準的印刷體,這里我們使用現成的OCR字符識別庫,這里我使用的是ddddocr
獲取方式
pip install ddddocrOCR識別
#使用ddddocr進行光學識別
import ddddocr
ocr=ddddocr.DdddOcr(show_ad=False,beta=True)
image=open('Plate.jpg','rb')
answer=ocr.classification(image.read())
image.close()
print(f'車牌號為:{answer.upper()}')
plt.imshow(src_image,cmap='gray')
plt.text(x=src_image.shape[1]//4,y=src_image.shape[0]/2,s=f'車牌號為:{answer.upper()}',size=20,color='red')?

????????使用ddddocr時需要傳入的圖像數據是Bytes類型,因此我們使用open(‘.jpg’,'rb').read()語句即可實現讀取圖像的bytes數據,最后我們再將得到的結果其標注在原始圖像上。?
?
完整代碼
#讀取原始圖像
import cv2
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
src_path=r'LicensePlate.jpg'
src_image=cv2.imread(filename=src_path,flags=cv2.IMREAD_COLOR_RGB)
print(src_image.shape)
plt.title('原始圖像')
plt.imshow(src_image)
#轉為灰度圖
gray_image=cv2.cvtColor(src=src_image,code=cv2.COLOR_RGB2GRAY)
plt.title('原始圖像(灰度圖)')
plt.imshow(gray_image,cmap='gray')
#閾值化
thresh,binary_image=cv2.threshold(src=gray_image,thresh=128,maxval=255,type=cv2.THRESH_OTSU+cv2.THRESH_BINARY)
plt.imshow(binary_image,cmap='gray')
#canny邊緣檢測
edges=cv2.Canny(image=binary_image,threshold1=0.5*thresh,threshold2=thresh,apertureSize=5,L2gradient=True)
plt.imshow(edges,cmap='gray')
#尋找矩形區域輪廓
contours,hiercahy=cv2.findContours(edges,mode=cv2.RETR_TREE,method=cv2.CHAIN_APPROX_SIMPLE)
contours=sorted(contours,key=cv2.contourArea,reverse=True)[:10]
rectangle=None
for point in contours:peri=cv2.arcLength(point,True)polygons=cv2.approxPolyDP(curve=point,epsilon=0.018*peri,closed=True)if len(polygons)==4:rectangle=polygonsplateArea=pointbreak
gray_image_copy=gray_image.copy()
src_image_copy=src_image.copy()
cv2.drawContours(image=src_image_copy,contours=[rectangle],contourIdx=0,color=(255,0,0),thickness=5)
cv2.drawContours(image=gray_image_copy,contours=[rectangle],contourIdx=0,color=255,thickness=5)
figure=plt.figure(figsize=(10,10),dpi=100)
plt.subplot(1,2,1),plt.imshow(src_image_copy),plt.title('車牌定位結果(原始圖像)')
plt.subplot(1,2,2),plt.imshow(gray_image_copy,cmap='gray'),plt.title('車牌定位結果(灰度圖)')
# #分割提取車牌
x=[location[0][0] for location in plateArea]
y=[location[0][1] for location in plateArea]
Licenseplate=gray_image[min(y):max(y),min(x):max(x)]#切片圖像
plt.imshow(Licenseplate,cmap='gray')
cv2.imwrite('Plate.jpg',Licenseplate)
#使用ddddocr進行光學識別
import ddddocr
ocr=ddddocr.DdddOcr(show_ad=False,beta=True)
image=open('Plate.jpg','rb')
answer=ocr.classification(image.read())
image.close()
print(f'車牌號為:{answer.upper()}')
plt.imshow(src_image,cmap='gray')
plt.text(x=src_image.shape[1]//4,y=src_image.shape[0]/2,s=f'車牌號為:{answer.upper()}',size=20,color='red')總結?

?
????????以上便是計算機視覺cv2入門之車牌號碼識別的所有內容,如果本文對你有用,還勞駕各位一鍵三連支持一下博主。



)



——測試原則、階段、測試用例設計、調試)

:分布式訓練(DP/DDP/Deepspeed)實戰)









