引言
2025年4月16日,OpenAI發布了全新的o系列推理模型:o3和o4-mini,這兩款模型被官方稱為“迎今為止最智能、最強大的大語言模型(LLM)”。它們不僅在AI推理能力上實現了質的飛躍,更首次具備了全面的工具使用能力,可以自主決定何時以及如何使用工具來解決復雜問題。本文將深入分析這兩款新一代AI推理模型的技術特點、性能表現、應用場景,并與當前主流大模型(如Claude 3.7、Gemini 2.5、DeepSeek R1)進行對比,幫助讀者全面了解這一人工智能領域的重大突破。
o3與o4-mini的核心技術特點與突破
參數規模與先進架構設計
雖然OpenAI并未公開o3和o4-mini的確切參數量,但業界普遍猜測o3的參數規模可能達到萬億級別。相比之下,o4-mini作為"小型版本",其參數量可能較小,但通過架構優化實現了驚人的性能。
o3模型可能延續了GPT-4的大模型架構,采用了密集Transformer架構,而非Mixture-of-Experts(MoE)混合專家架構。這意味著所有參數在每次推理中全程參與計算,雖然計算開銷大,但能保證推理質量的一致性。
o4-mini則被設計為"高速、低成本的推理模型",可能通過新的架構優化或專家路由,讓一個相對小的模型也能表現出媲美百億級模型的效果。這種"以小搏大"的設計哲學使o4-mini在性能與成本平衡上極具競爭力。
強化學習與鏈式思考突破
o3和o4-mini最顯著的技術突破在于強化學習的大規模應用。OpenAI在官方博客中表示,他們在o系列模型中重走了與GPT系列類似的擴展路徑——這次是在強化學習領域。通過增加訓練計算量和推理時間的思考步驟,模型性能獲得了明顯提升。
這種"鏈式思考"(Chain of Thought)能力使模型可以像人類一樣,在給出最終答案前先進行多步推理。模型會將復雜問題分解為子問題,逐步解決,最后綜合得出結論。這種方法大大提高了模型處理復雜任務的能力,尤其是在數學、編程和科學推理等領域。
多模態AI與高級工具使用能力
o3和o4-mini是OpenAI首次宣布能夠"帶著圖像去思考"的模型。不同于以往只是描述圖像,這些模型能在內部使用圖像內容來推理,解決視覺+文本混合的問題。用戶可以上傳照片、手繪草圖、圖表等,模型會將這些圖像納入其推理鏈條,結合文字一同分析。
更重要的是,這兩款模型具備了前所未有的工具使用能力。它們經過強化學習訓練,學會了遇到復雜任務時,如何調用外部工具(函數)完成子步驟,然后將結果納入推理再繼續回答。ChatGPT已經集成的工具包括:瀏覽器搜索、Python運行環境、文件讀取、圖像生成和編輯等。
例如,面對"加州今年夏天的能源使用相比去年如何"這樣的問題,模型會自行拆解任務:先用搜索工具獲取公共能源數據,然后用Python工具載入數據、計算趨勢,接著生成圖表,最后用自然語言結合圖表解釋預測結果。整個過程中模型會鏈式地調用多個工具,并根據中間結果動態調整策略。
性能表現與基準測試對比
AI推理能力的突破性進展
在多項權威基準測試中,o3和o4-mini都展現出了卓越的性能。根據OpenAI官方數據,o3在代碼能力評測SWE-bench上得分69.1%,略高于o4-mini的68.1%,這一成績遠超上一代o3-mini(49.3%)。
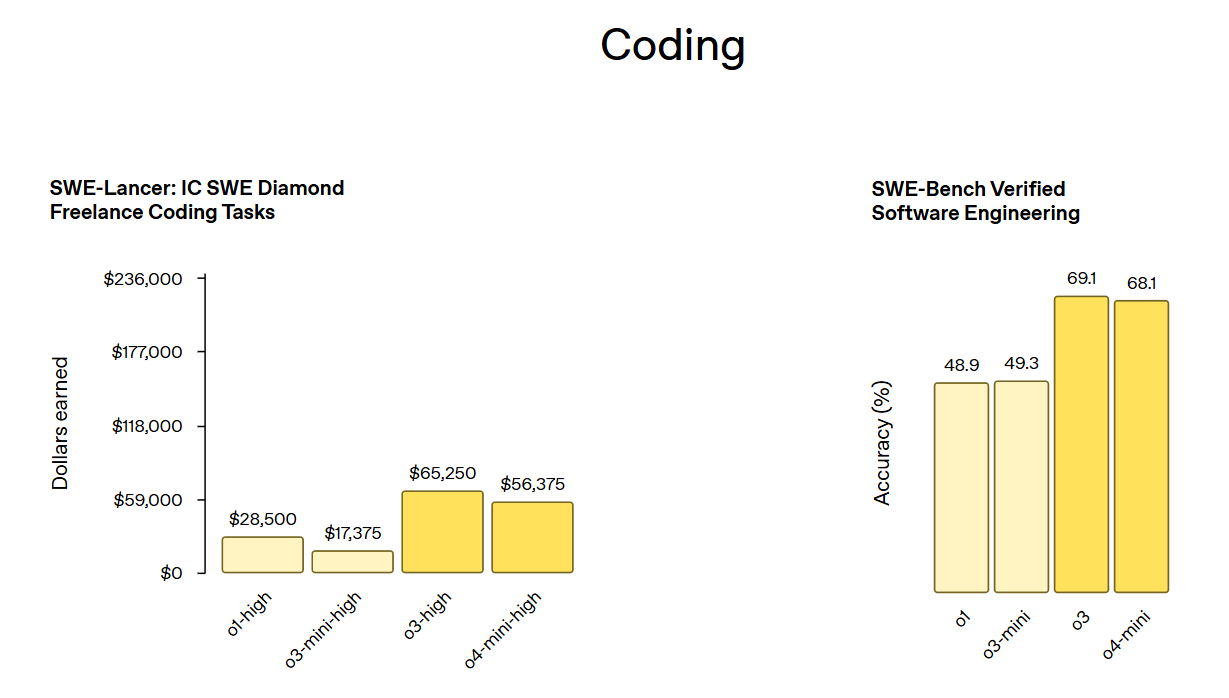
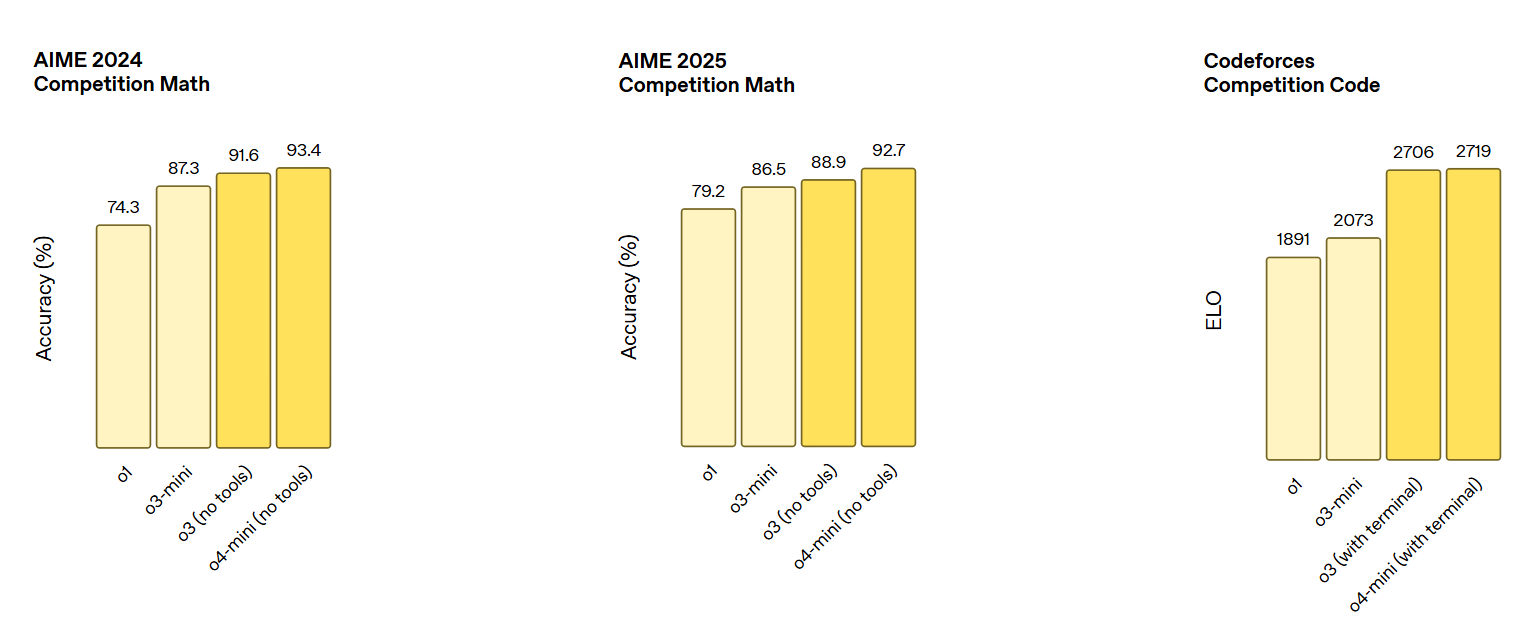
在數學方面,o4-mini在AIME 2024/2025等數學競賽基準上取得了目前已測最優成績,達到了93.4%/92.7%的準確率。
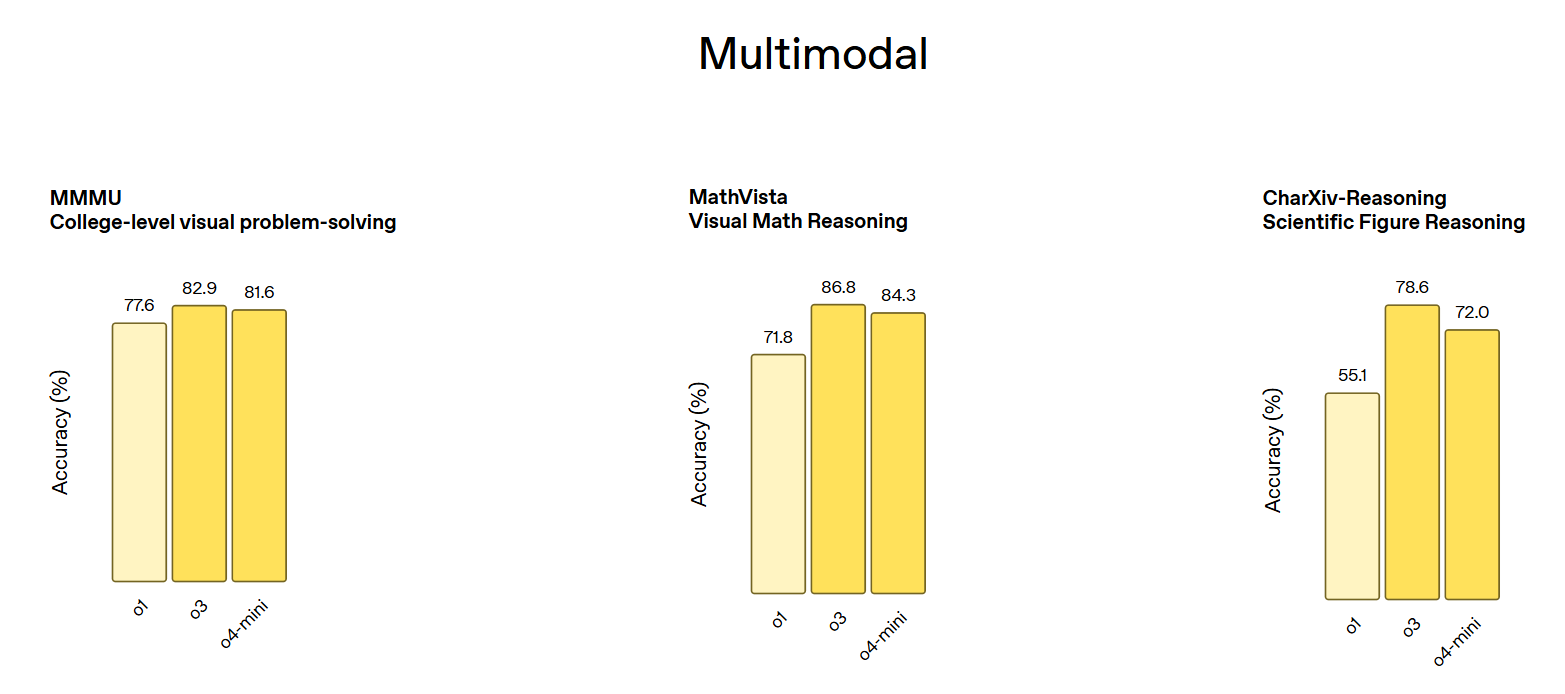
在多模態任務上,o3在MathVista(視覺數學推理)測試中達到了86.8%的準確率,在CharXiv-Reasoning(科學圖表推理)上達到了78.6%,均顯著超過了前代模型。
大語言模型推理速度與效率對比
o4-mini的一個核心賣點是速度快、吞吐高。OpenAI稱其是"高吞吐、高并發的理想選擇"。據體驗,o4-mini在復雜查詢上通常幾秒內即可給出初步結果,而o3由于會"思考"更多步驟,可能需要幾十秒甚至接近一分鐘才能得到最終答復。
不過值得注意的是,o3可以在相同延遲下勝過o1,如果允許更長推理時間,性能還會繼續提升——這表明o3的架構已經過優化,在給定算力下盡可能高效。
成本效益比
OpenAI在推出o3和o4-mini時,宣布了極具競爭力的API價格。按照官方公布,o3的API費用為每百萬輸入tokens $10.00,輸出tokens每百萬40.00美金。這個價格相對于GPT-4早期的定價大幅下降。
而更令人驚訝的是o4-mini,其API價格與舊款的o3-mini相同,僅為每百萬輸入tokens 1.10美金,輸出每百萬4.40美金。這個價位已經接近OpenAI最便宜的模型:ChatGPT-3.5 Turbo。如此低的成本,大大降低了高級推理AI的大規模應用門檻。
o3與o4-mini的實際應用場景與案例
復雜業務分析與決策支持
o3因其深度推理和工具使用能力,非常適合復雜業務場景。例如金融分析助手,輸入海量財報數據讓它自行檢索計算后給出建議;又比如科研助手,讓它自己查找文獻、作圖、提出假說。一些初創公司已經在用o3構建AI顧問,幫助律師整理案情、幫醫生分析最新研究。
高并發服務與批量處理
o4-mini則因為高效低成本,常被用于規模化的任務。比如電商網站用一組o4-mini模型同時為成千上萬商品生成描述,或客服系統用它批量處理用戶咨詢。由于其效率高,企業用戶可以用它處理海量任務而不用擔心超額。
多模態內容創作與分析
兩款模型的多模態能力開辟了新的應用可能。設計師可以上傳草圖,讓模型理解設計意圖并給出改進建議;數據分析師可以上傳復雜圖表,讓模型解讀趨勢并預測未來走勢;教育工作者可以上傳教材插圖,讓模型生成針對性的教學內容。
社區評測結果
Aider polyglot coding leaderboard
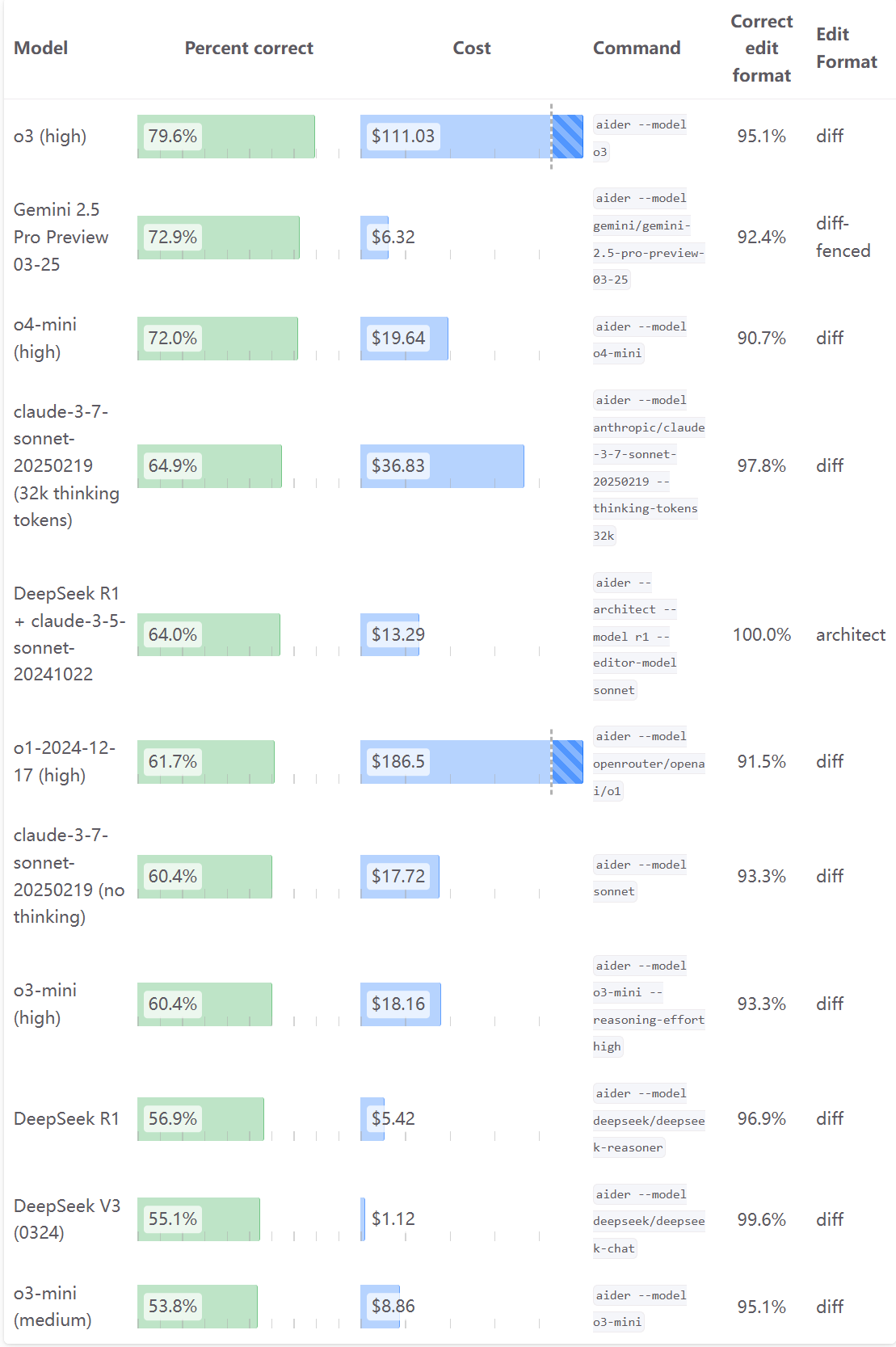
如上圖所示,在Aider polyglot coding leaderboard測試中,o3和o4-mini均展現出色的編程能力:
-
o3模型:以79.6%的正確率位居榜首,遠超其他模型。雖然其成本較高($111.03),但在復雜編程任務中展現出卓越的推理能力和代碼生成準確性。其正確編輯格式率達到95.1%,使用diff格式進行代碼編輯。
-
o4-mini模型:以72.0%的正確率排名第三,僅次于o3和Gemini 2.5 Pro Preview。其最大優勢在于高性價比,成本僅為$19.64,約為o3的1/5,雖相比 Gemini 2.5 Pro Preview略貴,但是和目前主流編程模型Claude 3.7 Sonnet相比已經具備相當的競爭力。正確編輯格式率為90.7%,同樣采用diff格式。
這些數據表明,o3適合對代碼質量要求極高的場景,而o4-mini則是日常編程輔助的理想選擇,能以合理成本提供接近頂級的編程能力。
LiveBench
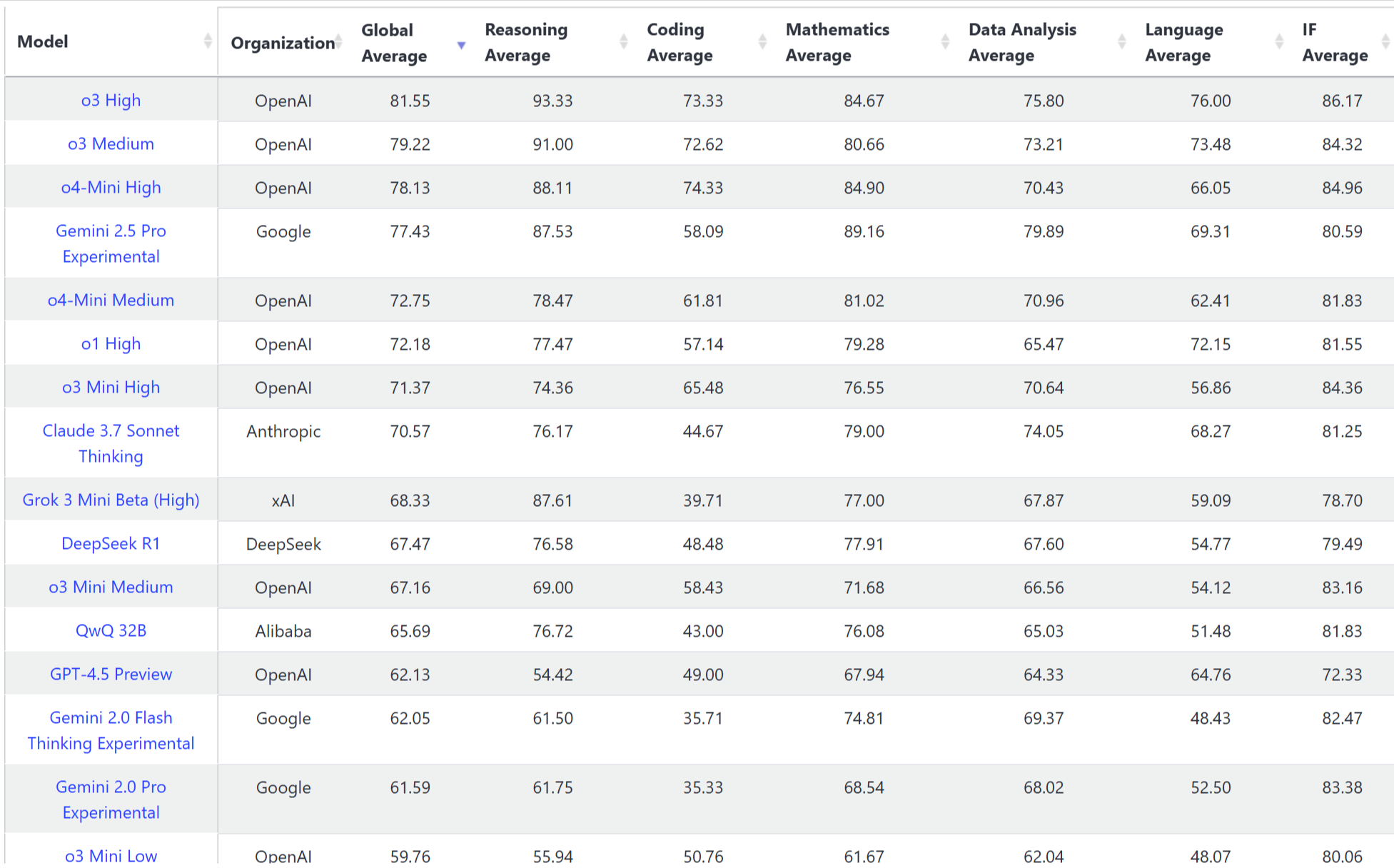
如上圖所示,LiveBench評測結果進一步驗證了o3和o4-mini模型的強大能力:
-
o3 High版本:以81.55的全球平均分位居榜首,在各項能力中表現均衡出色。特別是在推理能力(93.33分)方面遙遙領先,展示了其深度思考和復雜問題解決能力。在編程(73.33分)、數學(84.67分)和數據分析(75.80分)等技術領域同樣表現突出,IF平均分86.17為所有模型最高。
-
o3 Medium版本:以79.22的全球平均分緊隨其后,雖然各項指標略低于High版本,但整體實力依然強勁,保持了o3系列的高水準。
-
o4-Mini High版本:以78.13的全球平均分排名第三,僅次于兩個o3版本,展示了小型模型的驚人潛力。值得注意的是,其編程能力得分(74.33)甚至略高于o3 High,數學能力(84.90)也與o3 High相當。這表明在特定技術任務上,o4-mini能夠媲美甚至超越更大的模型。
這些評測數據清晰地表明,o3系列在整體性能上領先市場,而o4-mini系列則在保持高性能的同時實現了模型小型化的重大突破,尤其在編程和數學等技術領域表現出色,為資源受限場景提供了高性價比的解決方案。兩者出色的性能和性價比,標志著OpenAI的模型重新回到頂級模型行列,而我們作為用戶,在使用模型時也有了更多選擇和更廣泛的適用場景。
結論:OpenAI推理模型的未來展望
OpenAI的o3和o4-mini模型代表了當前通用人工智能模型的最新高度:o3在復雜AI推理和自主工具使用上取得突破,而o4-mini以小型模型身姿展現驚人的推理能力。它們不僅在性能上超越了前代大語言模型,更在成本效益上實現了質的飛躍,使高級AI推理技術變得更加平民化。
o3和o4-mini的閃耀登場,標志著人工智能從單純的對話機器人向真正的智能助手轉變。這些模型能夠通過鏈式思考進行自主推理、靈活調用各類外部工具、處理多模態AI輸入,并給出結構化的解決方案。這種能力的提升,將為各行各業帶來革命性的變革,從復雜業務分析到創意內容創作,從科學研究到日常生活輔助,AI推理模型的應用場景將更加廣泛。
隨著OpenAI這些模型能力的進一步開放和優化,我們可以預見,“大語言模型全民化”的時代正在加速到來,人工智能與人類協作的方式也將更加深入和自然。正如OpenAI所言,AI推理模型的黃金時代才剛剛開始,更精彩的競爭與創新還在后頭。









)





)

 —— 上篇)

