The rock can talk — not interesting. The rock can read — that’s interesting.
(石頭能說話,不稀奇。稀奇的是石頭能讀懂。)
----硅谷知名創業孵化器 YC 的總裁 Gar Tan
目錄
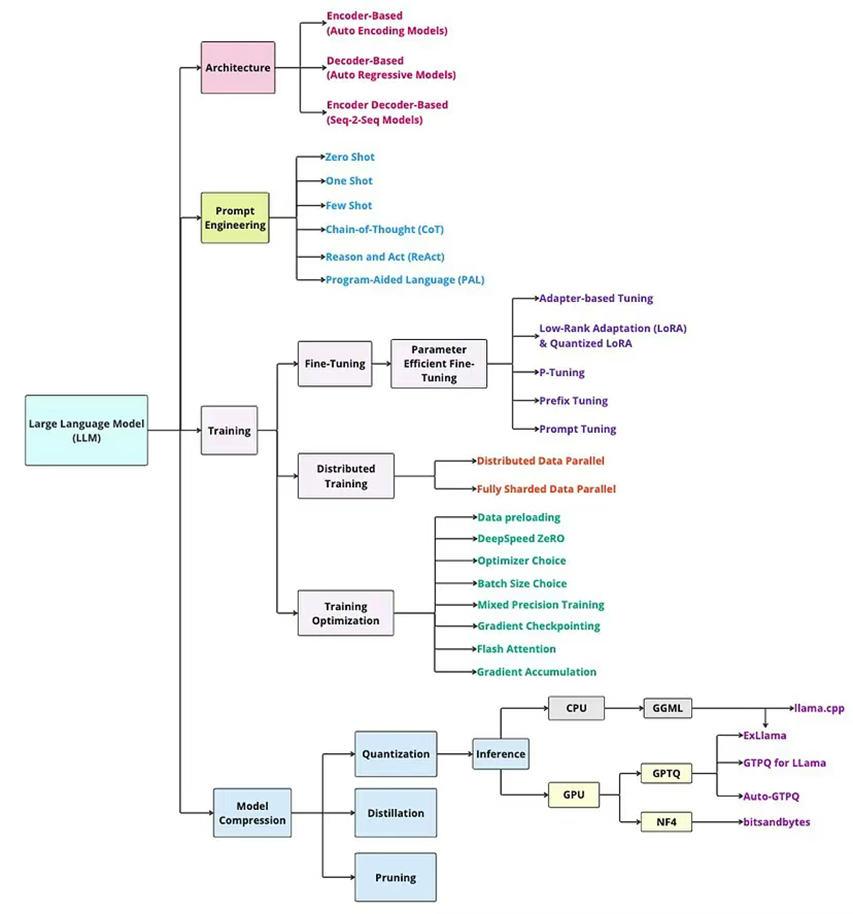
1. 什么是大語言模型?
2. 語言建模(LM):
3. 基礎模型和大語言模型:
4. 大語言模型的架構:
5. 預訓練:
6. 數據并行訓練技術:
6.1 分布式數據并行(DDP)
6.2 全分片數據并行(FSDP)
7. 微調:
7.1 PEFT
7.2 遷移學習
7.3 Adapters 適配器
7.4 LoRA——低秩自適應
7.5 QLoRA
7.6 IA3
7.7 P-Tuning
7.8 Prefix Tuning
7.9 Prompt Tuning(并非提示工程)
7.10 LoRA與Prompt Tuning對比
7.11 LoRA和PEFT與全量微調對比
8. 大語言模型推理:
9. 提示工程:
9.1 思維鏈(CoT)提示
9.2 PAL(程序輔助語言模型)
9.3 ReAct提示
10. 模型優化技術:
10.1 量化
10.2 蒸餾
10.3 剪枝
結論:
References:
1. 什么是大語言模型?
大語言模型(LLM)是非常龐大的深度學習模型,它們在大量數據上進行預訓練。其底層的Transformer是一組神經網絡,由具有自注意力能力的編碼器和解碼器組成。編碼器和解碼器從文本序列中提取含義,并理解其中單詞和短語之間的關系。
Transformer神經網絡架構允許使用非常大的模型,這些模型通常包含數千億個參數。如此大規模的模型可以攝取大量數據,這些數據通常來自互聯網,也可以來自如包含超過500億個網頁的Common Crawl,以及約有5700萬頁面的維基百科等來源。
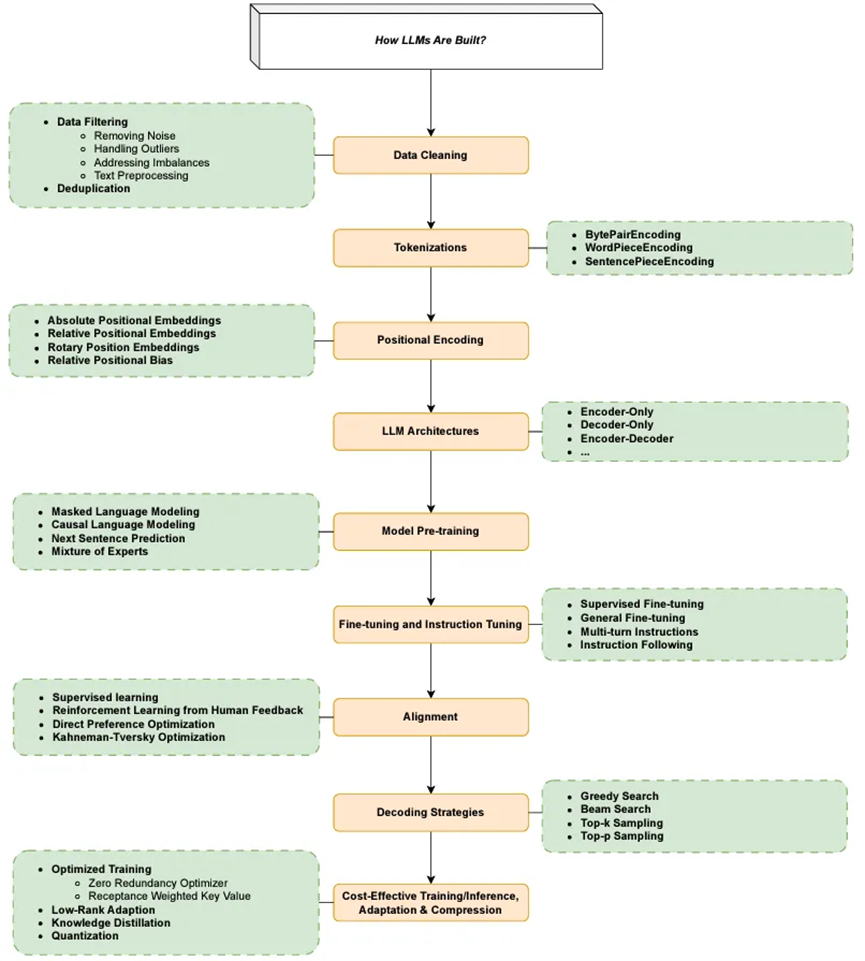
2. 語言建模(LM):
語言和交流的過程可以簡化為計算嗎?
語言模型通過從一個或多個文本語料庫中學習來生成概率。文本語料庫是一種語言資源,由一種或多種語言的大量結構化文本組成。文本語料庫可以包含一種或多種語言的文本,并且通常帶有注釋。
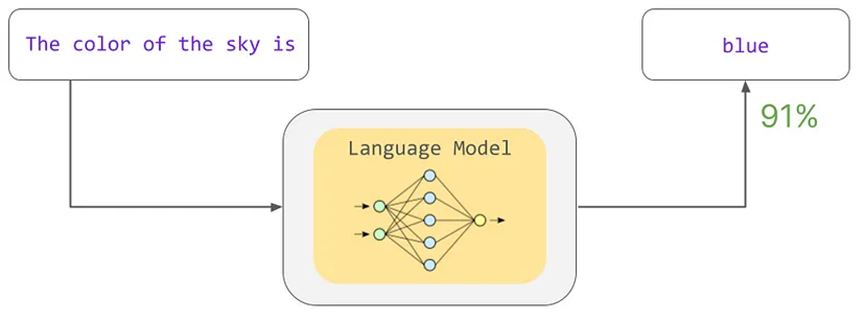
語言模型可以根據其在訓練過程中學習到的統計模式,預測最可能跟隨某個短語的單詞(或多個單詞)。在圖中,語言模型可能會估計“天空的顏色是”這個短語后面跟著“藍色”一詞的概率為91%。
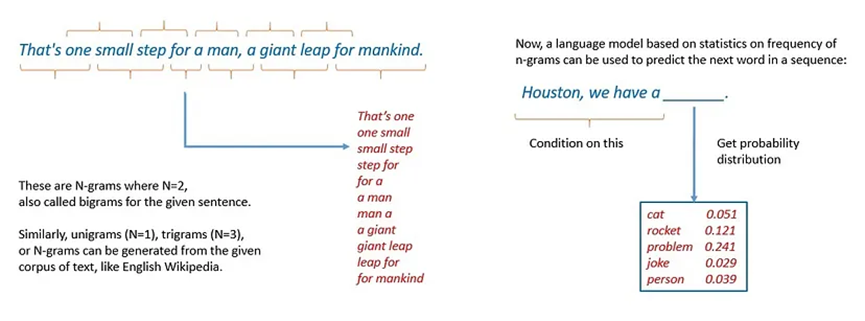
構建語言模型的最早方法之一是基于n - gram。n - gram是從給定文本樣本中連續的n個項目組成的序列。在這里,模型假設序列中下一個單詞的概率僅取決于前面固定數量的單詞:
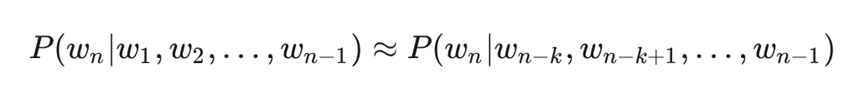
其中,wi表示單詞,k是窗口大小。
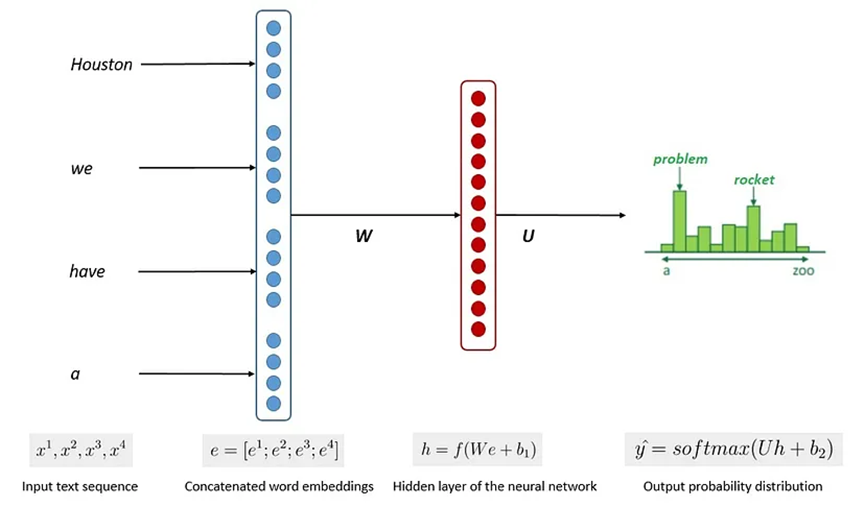
然而,n - gram語言模型在很大程度上已被神經語言模型所取代。神經語言模型基于神經網絡,這是一種受生物神經網絡啟發的計算系統。這些模型利用單詞的連續表示或嵌入來進行預測:

神經網絡將單詞表示為權重的非線性組合。因此,它可以避免語言建模中的維度災難問題。已經有幾種神經網絡架構被提出用于語言建模。
3. 基礎模型和大語言模型:
這與自然語言處理(NLP)應用程序早期的方法有很大不同,早期是訓練專門的語言模型來執行特定任務。相反,研究人員在大語言模型中觀察到了許多涌現能力,這些能力是模型從未接受過訓練的。
例如,大語言模型已被證明能夠執行多步算術運算、解亂序單詞的字母,以及識別口語中的冒犯性內容。最近,基于OpenAPI的GPT系列大語言模型構建的流行聊天機器人ChatGPT,通過了美國醫學執照考試等專業考試。
基礎模型通常是指在廣泛數據上進行訓練的任何模型,它可以適應各種下游任務。這些模型通常使用深度神經網絡創建,并使用自監督學習在大量未標記數據上進行訓練。
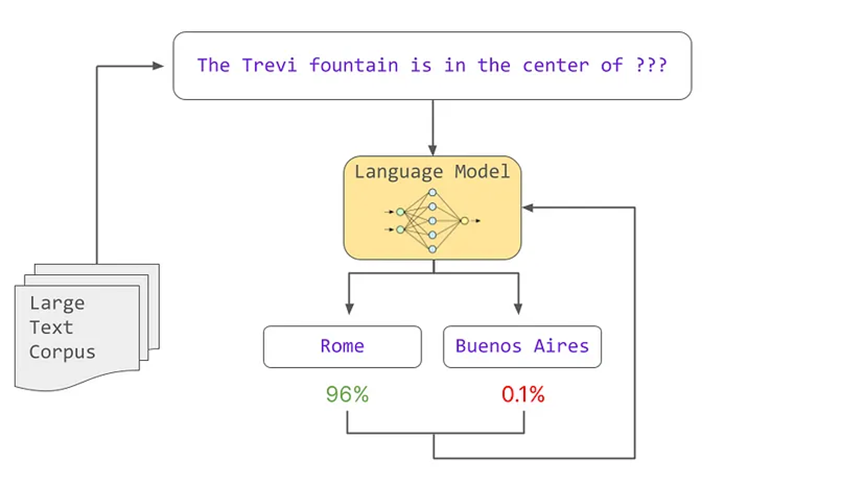
在訓練過程中,從語料庫中提取文本序列并進行截斷。語言模型計算缺失單詞的概率,然后通過基于梯度下降的優化機制對這些概率進行微調,并反饋給模型以匹配真實情況。這個過程在整個文本語料庫上重復進行。
盡管如此,大語言模型通常在與語言相關的數據(如文本)上進行訓練。而基礎模型通常在多模態數據(文本、圖像、音頻等的混合)上進行訓練。更重要的是,基礎模型旨在作為更特定任務的基礎或基石:
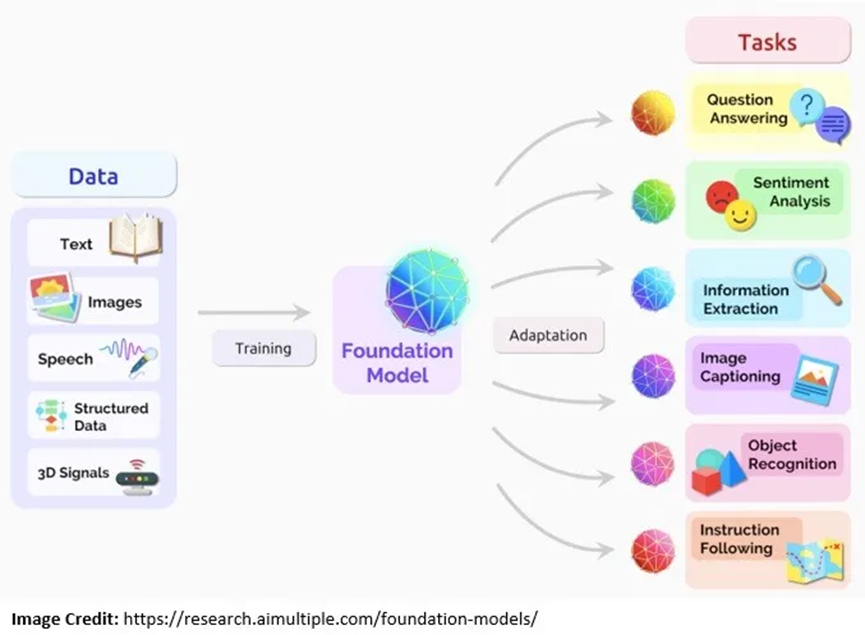
基礎模型通常通過進一步訓練進行微調,以完成各種下游認知任務。微調是指采用預訓練的語言模型,并使用特定數據針對不同但相關的任務進行訓練的過程。這個過程也被稱為遷移學習。
4. 大語言模型的架構:
早期的大語言模型大多是使用帶有長短期記憶網絡(LSTM)和門控循環單元(GRU)的循環神經網絡(RNN)模型創建的。然而,它們面臨挑戰,主要是在大規模執行NLP任務方面。但這正是大語言模型預期要發揮作用的領域。這就促使了Transformer的誕生!
一開始,大語言模型主要是使用自監督學習算法創建的。自監督學習是指處理未標記數據以獲得有用的表示,這些表示可以幫助下游的學習任務。
通常,自監督學習算法使用基于人工神經網絡(ANN)的模型。我們可以使用幾種架構來創建人工神經網絡,但大語言模型中使用最廣泛的架構是循環神經網絡(RNN)。
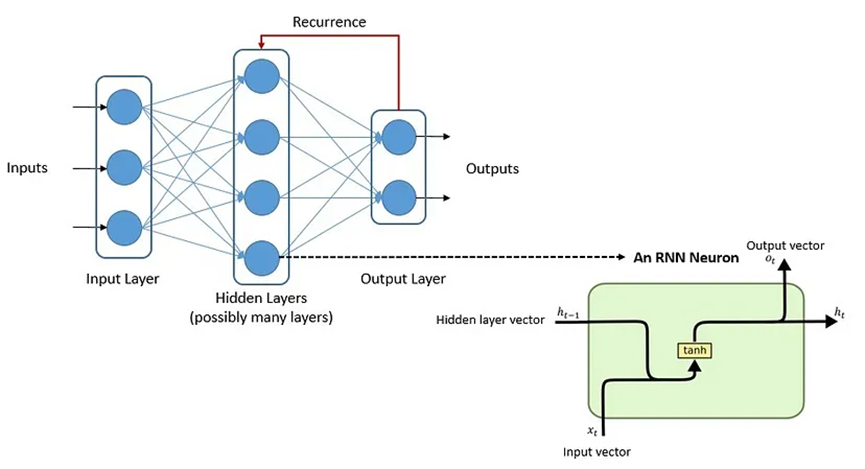
RNN可以利用其內部狀態來處理可變長度的輸入序列。RNN具有長期記憶和短期記憶。RNN有一些變體,如長短期記憶網絡(LSTM)和門控循環單元(GRU)。
使用LSTM單元的RNN訓練速度非常慢。此外,對于這樣的架構,我們需要按順序或串行地輸入數據。這就無法進行并行化處理,也無法利用可用的處理器核心。
或者,使用GRU的RNN模型訓練速度更快,但在更大的數據集上表現較差。盡管如此,在很長一段時間里,LSTM和GRU仍然是構建復雜NLP系統的首選。然而,這樣的模型也存在梯度消失問題:
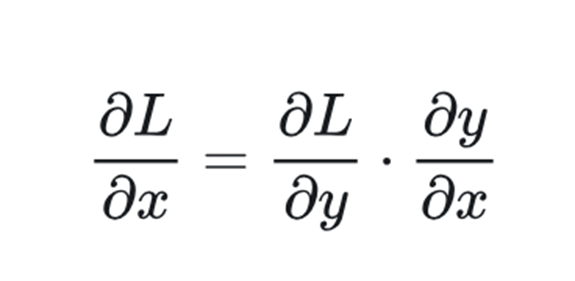
當反向傳播多層時,梯度可能會變得非常小,導致訓練困難。
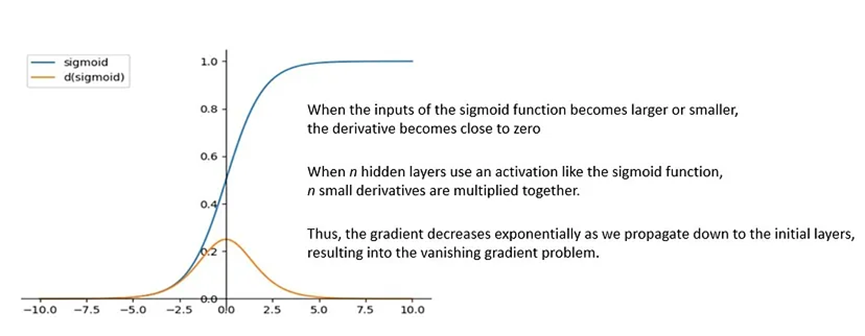
RNN的一些問題通過在其架構中添加注意力機制得到了部分解決。在像LSTM這樣的循環架構中,可以傳播的信息量是有限的,并且保留信息的窗口較短。
然而,有了注意力機制,這個信息窗口可以顯著增加。注意力是一種增強輸入數據某些部分,同時削弱其他部分的技術。其背后的動機是網絡應該更多地關注數據的重要部分:
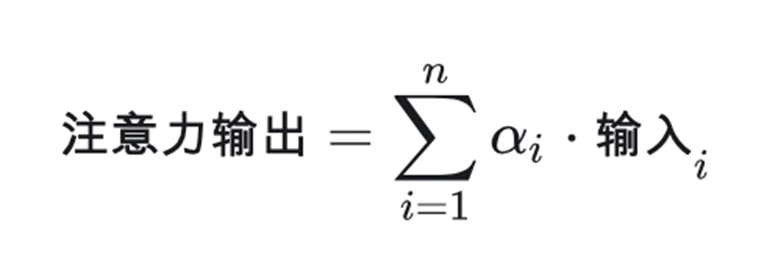
其中,ai是注意力權重,表示對每個輸入部分的關注程度。
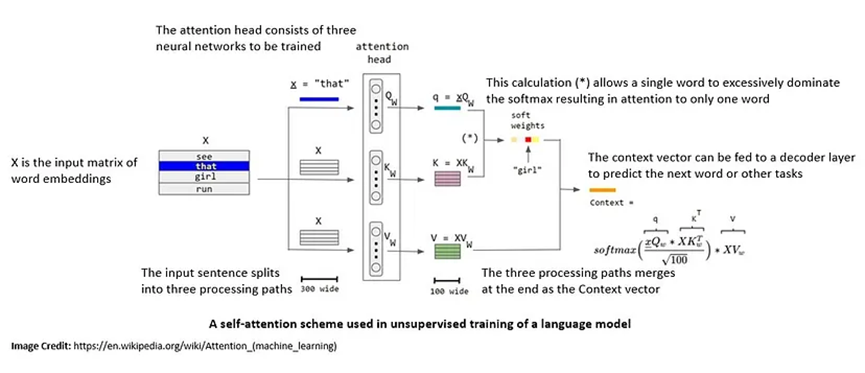
注意力和自注意力之間有一個微妙的區別,但它們的動機是相同的。注意力機制是指關注另一個序列不同部分的能力,而自注意力是指關注當前序列不同部分的能力。
自注意力允許模型訪問來自任何輸入序列元素的信息。在NLP應用中,這提供了關于遠距離標記的相關信息。因此,模型可以捕獲整個序列中的依賴關系,而無需固定或滑動窗口。
帶有注意力機制的RNN模型在性能上有了顯著提升。然而,循環模型本質上很難擴展。但是,自注意力機制很快被證明非常強大,以至于它甚至不需要循環順序處理。
2017年,谷歌大腦團隊推出的Transformer可能是大語言模型歷史上最重要的轉折點之一。Transformer是一種深度學習模型,它采用自注意力機制,并一次性處理整個輸入:

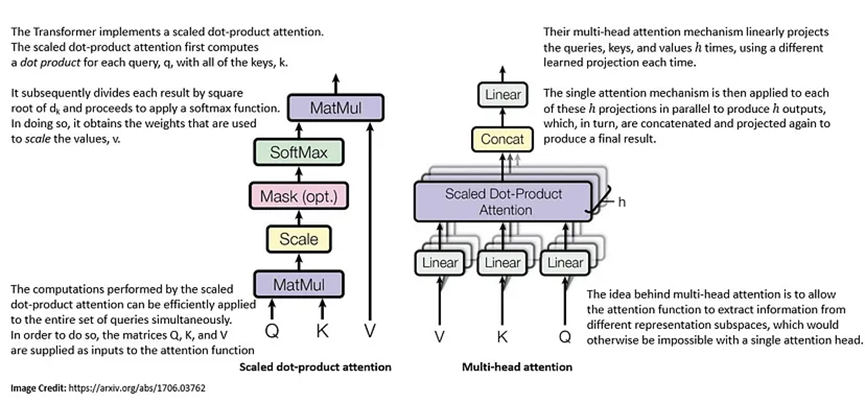
與早期基于RNN的模型相比,Transformer有一個重大變化,即它沒有循環結構。在有足夠訓練數據的情況下,Transformer架構中的注意力機制本身就可以與帶有注意力機制的RNN模型相媲美。
使用Transformer模型的另一個顯著優勢是它們具有更高的并行化程度,并且需要的訓練時間大大減少。這正是我們利用可用資源在大量基于文本的數據上構建大語言模型所需要的優勢。
許多基于人工神經網絡的自然語言處理模型都是使用編碼器 - 解碼器架構構建的。例如,seq2seq是谷歌最初開發的一系列算法。它通過使用帶有LSTM或GRU的RNN將一個序列轉換為另一個序列。
最初的Transformer模型也使用了編碼器 - 解碼器架構。編碼器由編碼層組成,這些層逐層迭代處理輸入。解碼器由解碼層組成,對編碼器的輸出進行同樣的處理:
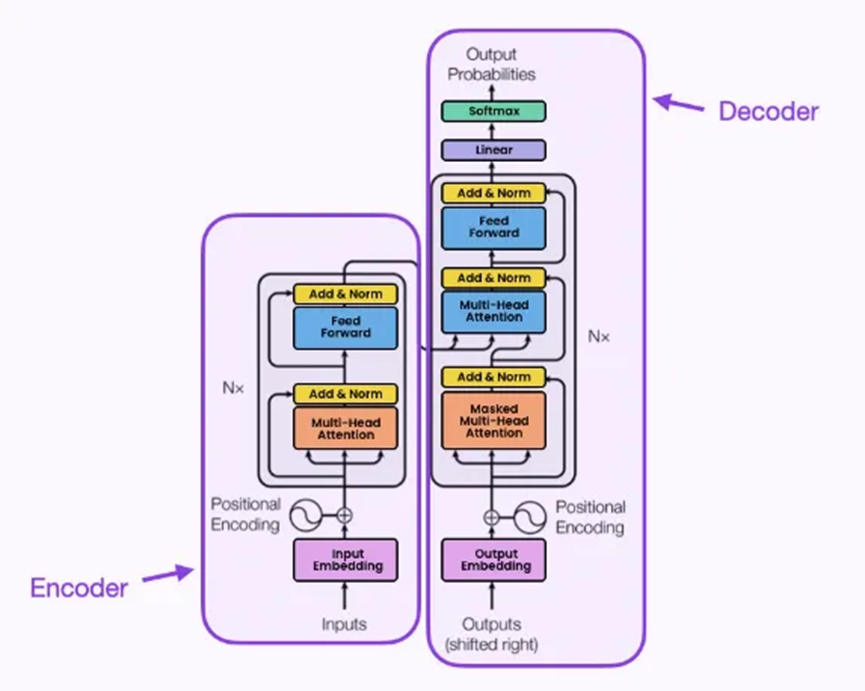
每個編碼器層的功能是生成編碼,其中包含關于輸入中哪些部分相互相關的信息。輸出編碼隨后作為輸入傳遞給下一個編碼器。每個編碼器由一個自注意力機制和一個前饋神經網絡組成。
此外,每個解碼器層獲取所有編碼,并利用其中包含的上下文信息生成輸出序列。與編碼器一樣,每個解碼器由一個自注意力機制、一個對編碼的注意力機制和一個前饋神經網絡組成。
5. 預訓練:
在這個階段,模型以自監督的方式在大量非結構化文本數據集上進行預訓練。預訓練的主要挑戰是計算成本。
存儲10億參數模型所需的GPU內存:
- 1個參數 -> 4字節(32位浮點數)
- 10億參數 -> 4×10^9 字節 = 4GB
- 存儲10億參數模型所需的GPU內存 = 4GB(32位全精度)
讓我們計算訓練10億參數模型所需的內存:
- 模型參數
- 梯度
- ADAM優化器(2個狀態)
- 激活值和臨時內存(大小可變)
-> 4字節參數 + 每個參數額外20字節
所以,訓練所需的內存大約是存儲模型所需內存的20倍。
存儲10億參數模型所需內存 = 4GB(32位全精度)
訓練10億參數模型所需內存 = 80GB(32位全精度)
6. 數據并行訓練技術:
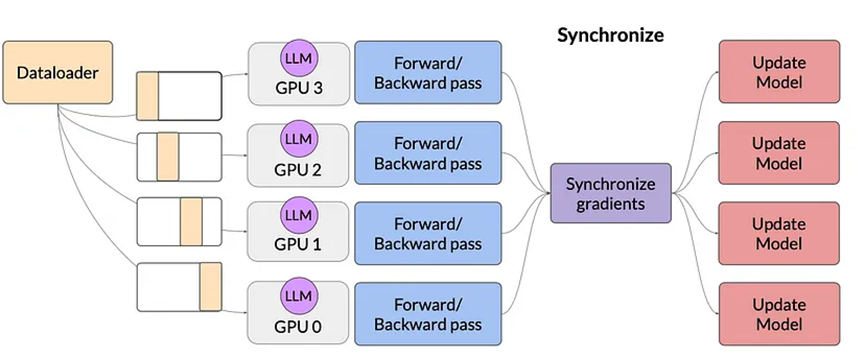
6.1 分布式數據并行(DDP)
分布式數據并行(DDP)要求模型權重以及訓練所需的所有其他額外參數、梯度和優化器狀態都能在單個GPU中容納。如果模型太大,則應使用模型分片。
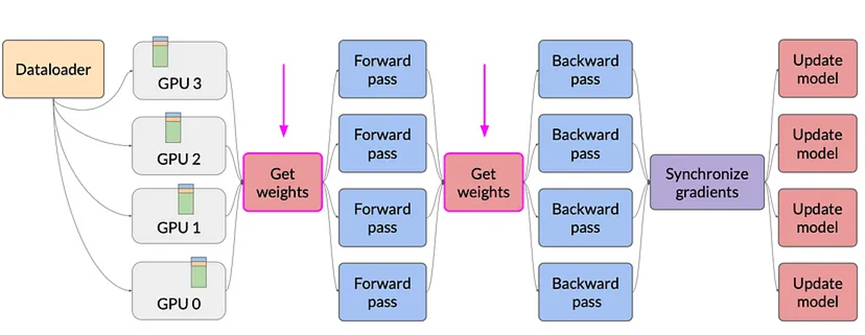
6.2 全分片數據并行(FSDP)
全分片數據并行(FSDP)通過在多個GPU之間分布(分片)模型參數、梯度和優化器狀態來減少內存使用。
7. 微調:
微調有助于我們通過調整預訓練的大語言模型(LLM)的權重,使其更好地適應特定任務或領域,從而充分發揮這些模型的潛力。這意味著與單純的提示工程相比,你可以用更低的成本和延遲獲得更高質量的結果。
與提示相比,微調通常在引導大語言模型的行為方面要有效得多。通過在一組示例上訓練模型,你可以縮短精心設計的提示,節省寶貴的輸入令牌,同時不犧牲質量。你通常還可以使用小得多的模型,這反過來又可以減少延遲和推理成本。
例如,經過微調的Llama 7B模型在每個令牌的基礎上,成本效益比現成的模型(如GPT-3.5)高得多(大約50倍),且性能相當。
如前所述,微調是針對其他任務對已經訓練好的模型進行調整。其工作方式是獲取原始模型的權重,并對其進行調整以適應新任務。
模型在訓練時會學習完成特定任務,例如,GPT-3在大量數據集上進行了訓練,因此它學會了生成故事、詩歌、歌曲、信件等。人們可以利用GPT-3的這種能力,并針對特定任務(如以特定方式生成客戶查詢的答案)對其進行微調。
有多種方法和技術可以對模型進行微調,其中最流行的是遷移學習。遷移學習源自計算機視覺領域,它是指凍結網絡初始層的權重,只更新后面層的權重的過程。這是因為較底層(更接近輸入的層)負責學習訓練數據集的通用特征,而較上層(更接近輸出的層)學習更具體的信息,這些信息直接與生成正確的輸出相關。
7.1 PEFT
PEFT,即參數高效微調(Parameter Efficient Fine-Tuning),是一組以最節省計算資源和時間的方式微調大型模型的技術或方法,同時不會出現我們可能在全量微調中看到的性能損失。之所以采用這些技術,是因為隨著模型越來越大,例如擁有1760億參數的BLOOM模型,在不花費數萬美元的情況下對其進行微調幾乎是不可能的。但有時為了獲得更好的性能,使用這樣的大型模型又幾乎是必要的。這就是PEFT發揮作用的地方,它可以幫助解決在處理這類大型模型時遇到的問題。
以下是一些PEFT技術:

7.2 遷移學習
遷移學習是指我們獲取模型的一些已學習參數,并將其用于其他任務。這聽起來與微調相似,但實際上有所不同。在微調中,我們重新調整模型的所有參數,或者凍結一些權重并調整其余參數。但在遷移學習中,我們從一個模型中獲取一些已學習參數,并將其用于其他網絡。這在我們的操作上給予了更大的靈活性。例如,在微調時我們無法改變模型的架構,這在很多方面限制了我們。但在使用遷移學習時,我們只使用訓練好的模型的一部分,然后可以將其附加到任何具有不同架構的其他模型上。
遷移學習在使用大語言模型的NLP任務中經常出現,人們會使用像T5這樣的預訓練模型中Transformer網絡的編碼器部分,并訓練后面的層。
7.3 Adapters 適配器
適配器是最早發布的參數高效微調技術之一。相關論文Parameter-Efficient Transfer Learning for NLP表明,我們可以在現有的Transformer架構上添加更多層,并且只對這些層進行微調,而不是對整個模型進行微調。他們發現,與完全微調相比,這種技術可以產生相似的性能。
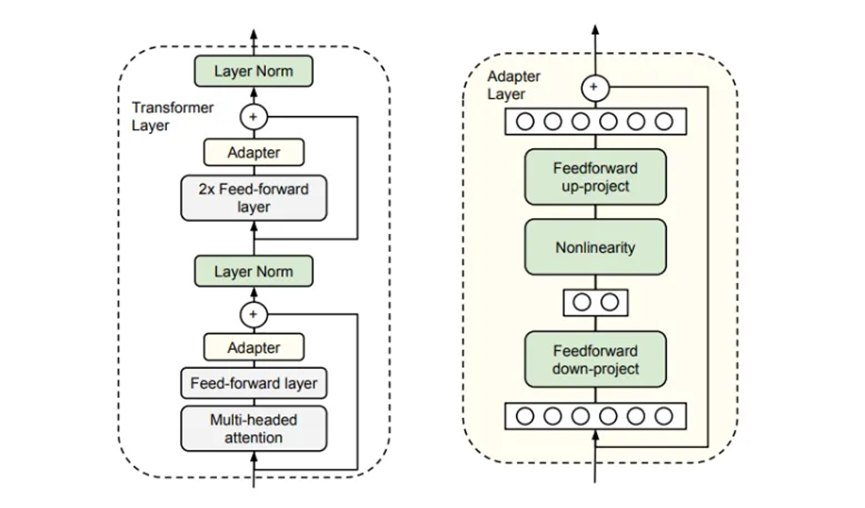
在左邊,是添加了適配器層的修改后的Transformer架構。我們可以看到適配器層添加在注意力堆棧和前饋堆棧之后。在右邊,是適配器層本身的架構。適配器層采用瓶頸架構,它將輸入縮小到較小維度的表示,然后通過非線性激活函數,再將其放大到輸入的維度。這確保了Transformer堆棧中的下一層能夠接收適配器層生成的輸出。
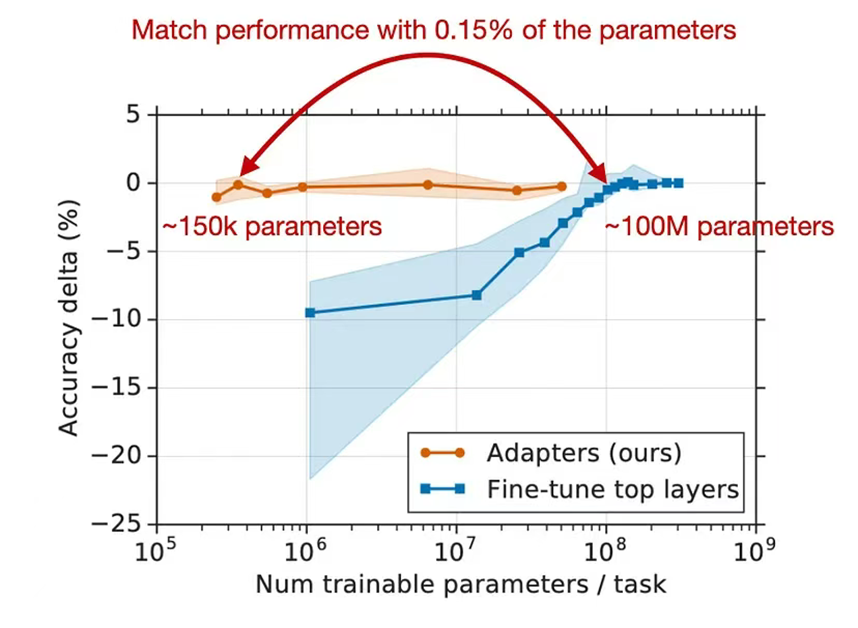
論文作者表明,這種微調方法在消耗更少計算資源和訓練時間的同時,性能可與完全微調相媲美。他們在GLUE基準測試中,僅增加3.6%的參數,就能達到全量微調0.4%的效果。
7.4 LoRA——低秩自適應
LoRA是一種與適配器層類似的策略,但它旨在進一步減少可訓練參數的數量。它采用了更嚴謹的數學方法。LoRA通過修改神經網絡中可更新參數的訓練和更新方式來工作。
從數學角度解釋,我們知道預訓練神經網絡的權重矩陣是滿秩的,這意味著每個權重都是唯一的,不能通過組合其他權重得到。但在這篇論文Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning中,作者表明,當預訓練語言模型針對新任務進行調整時,權重具有較低的“內在維度”。這意味著權重可以用更小的矩陣表示,即它具有較低的秩。反過來,這意味著在反向傳播過程中,權重更新矩陣的秩較低,因為大部分必要信息已經在預訓練過程中被捕獲,在微調過程中只進行特定任務的調整。
更簡單的解釋是,在微調過程中,只有極少數權重會有較大的更新,因為神經網絡的大部分學習是在預訓練階段完成的。LoRA利用這一信息來減少可訓練參數的數量。
以GPT-3 175B為例,LoRA研究團隊證明,即使全秩(即d)高達12288,非常低的秩(即圖1中的r可以是1或2)也足夠了,這使得LoRA在存儲和計算上都非常高效。
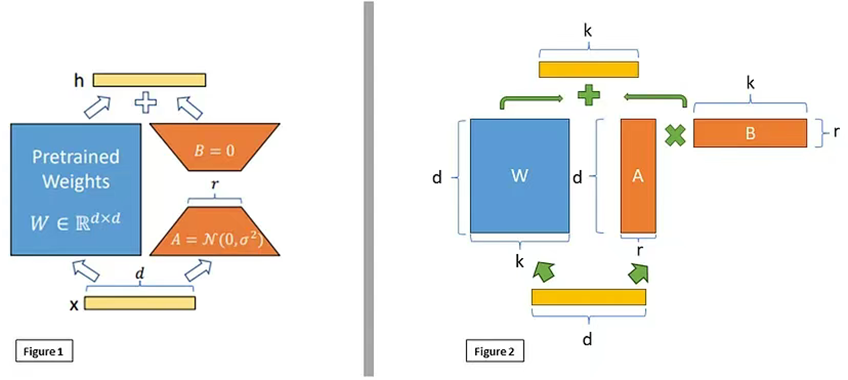
圖2展示了矩陣??和??的維度為??,而我們可以改變 r 的值。 r 值越小,需要調整的參數就越少。雖然這會縮短訓練時間,但r值過小時也可能導致信息丟失并降低模型性能。然而,使用LoRA時,即使秩較低,性能也能與完全訓練的模型相當甚至更好。
用HuggingFace實現LoRA微調
要使用HuggingFace實現LoRA微調,你需要使用PEFT庫將LoRA適配器注入模型,并將它們用作更新矩陣。
from transformers import AutoModelForCausalLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", trust_remote_code=True)
peft_config = LoraConfig(task_type=TaskType.CAUSAL_LM, inference_mode=False, r=32, lora_alpha=16, lora_dropout=0.1,target_modules=['query_key_value']
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
完成這些后,你就可以像平常一樣訓練模型了。但這一次,它將比平常花費更少的時間和計算資源。
LoRA的效率
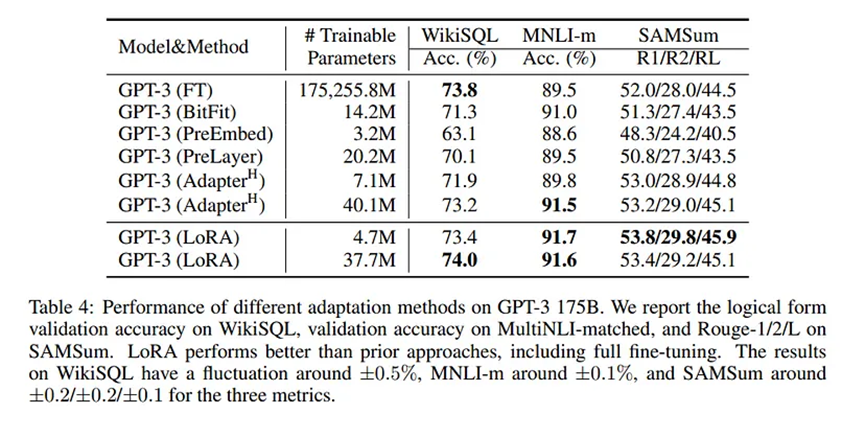
論文的作者表明,LoRA僅用總可訓練參數的2%就能超越全量微調的效果。
至于它訓練的參數數量,我們可以通過秩r參數在很大程度上進行控制。例如,假設權重更新矩陣有100,000個參數,A為200,B為500。權重更新矩陣可以分解為較低維度的較小矩陣,A為200×3,B為3×500。這樣我們就只有200×3 + 3×500 = 2100個可訓練參數,僅占總參數數量的2.1%。如果我們決定只將LoRA應用于特定層,這個數量還可以進一步減少。
由于訓練和應用的參數數量比實際模型少得多,文件大小可以小至8MB。這使得加載、應用和傳輸學習到的模型變得更加容易和快速。
7.5 QLoRA
QLoRA如何與LoRA不同?它是一種4位Transformer。
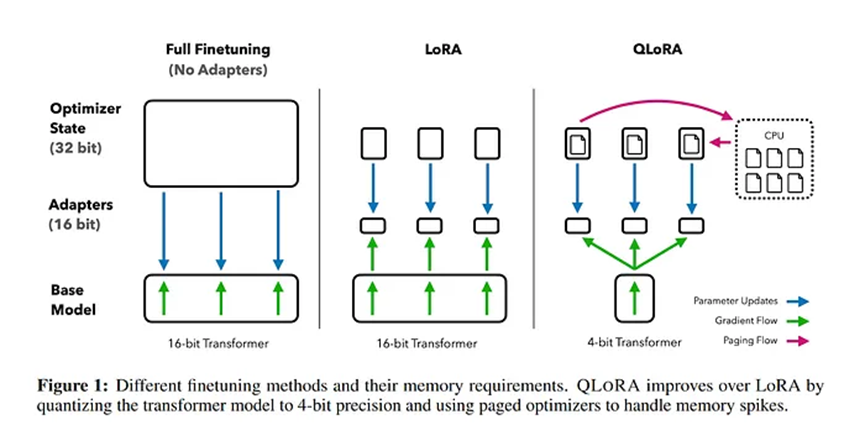
QLoRA是一種微調技術,它將高精度計算技術與低精度存儲方法相結合。這有助于在保持模型高性能和準確性的同時,使模型大小保持較小。
QLoRA使用LoRA作為輔助手段來修復量化過程中引入的誤差。
QLoRA的工作原理
QLoRA通過引入3個新概念來幫助減少內存使用,同時保持相同的性能質量。它們是4位Normal Float、雙重量化和分頁優化器。
4位Normal Float(NF4)
4位NormalFloat是一種新的數據類型,是保持16位性能水平的關鍵因素。它的主要特性是:數據類型中的任何位組合,例如0011或0101,都會從輸入張量中分配到數量相等的元素。
QLoRA對權重進行4位量化,并以32位精度訓練注入的適配器權重(LORA)。
QLoRA有一種存儲數據類型(NF4)和一種計算數據類型(16位BrainFloat)。
我們將存儲數據類型反量化為計算數據類型以進行前向和反向傳遞,但我們只對使用16位BrainFloat的LORA參數計算權重梯度。
1.歸一化:首先對模型的權重進行歸一化,使其具有零均值和單位方差。這確保了權重分布在零附近,并落在一定范圍內。
2.量化:然后將歸一化后的權重量化為4位。這涉及將原始的高精度權重映射到一組較小的低精度值。對于NF4,量化級別被選擇為在歸一化權重的范圍內均勻分布。
3.反量化:在前向傳遞和反向傳播過程中,量化后的權重被反量化回全精度。這是通過將4位量化值映射回其原始范圍來完成的。反量化后的權重用于計算,但它們以4位量化形式存儲在內存中。
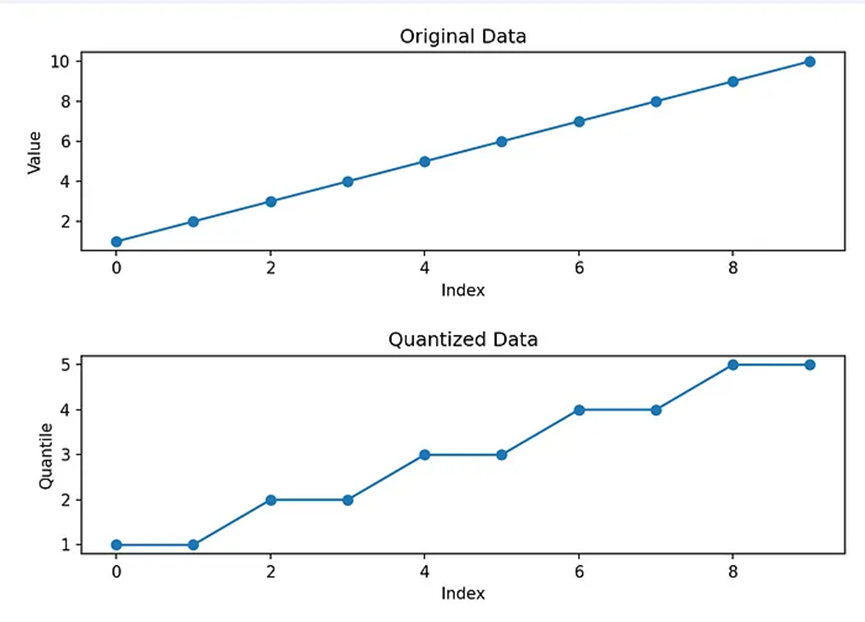
數據會被量化到“桶”或“箱”中。數字2和3都落入相同的量化區間2。這種量化過程通過“四舍五入”到最接近的量化區間,讓你可以使用更少的數字。
雙重量化
雙重量化是指對4位NF量化過程中使用的量化常數進行量化的獨特做法。雖然這看起來不太起眼,但相關研究論文指出,這種方法有可能平均每個參數節省0.5位。這種優化在采用塊wise k位量化的QLoRA中特別有用。與對所有權重一起進行量化不同,這種方法將權重分成不同的塊或片段,分別進行量化。
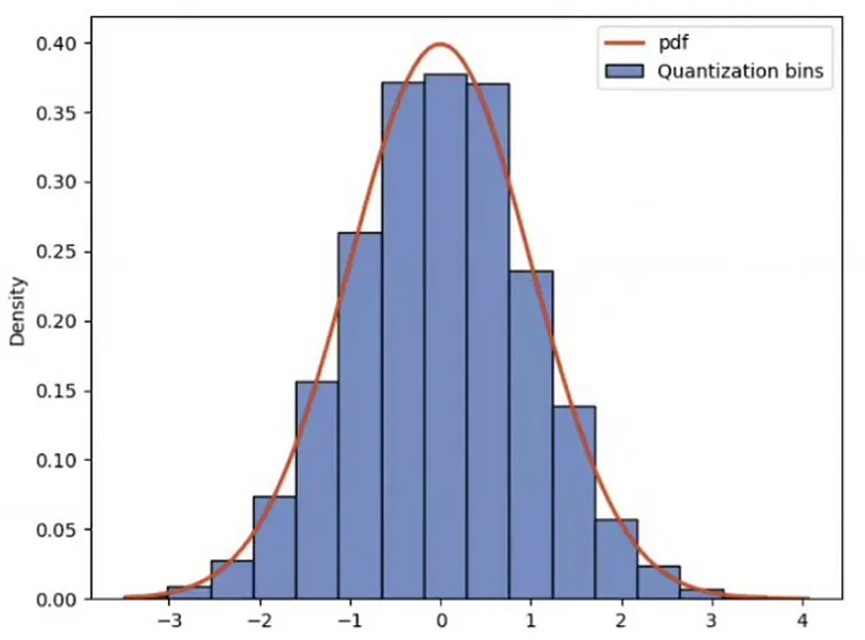
塊wise量化方法會生成多個量化常數。有趣的是,這些常數可以進行第二輪量化,從而提供了額外的節省空間的機會。由于量化常數的數量有限,這種策略仍然有效,減輕了與該過程相關的計算和存儲需求。
分頁優化器
如前所述,分位數量化涉及創建桶或箱來涵蓋廣泛的數值范圍。這個過程會導致多個不同的數字被映射到同一個桶中,例如在量化過程中,2和3都被轉換為值3。因此,權重的反量化會引入1的誤差。
在神經網絡中更廣泛的權重分布上可視化這些誤差,就可以看出分位數量化的固有挑戰。這種差異凸顯了為什么QLoRA更像是一種微調機制,而不是一種獨立的量化策略,盡管它適用于4位推理。在使用QLoRA進行微調時,LoRA調整機制就會發揮作用,包括創建兩個較小的權重更新矩陣。這些矩陣以更高精度的格式(如腦浮點16或浮點16)維護,然后用于更新神經網絡的權重。
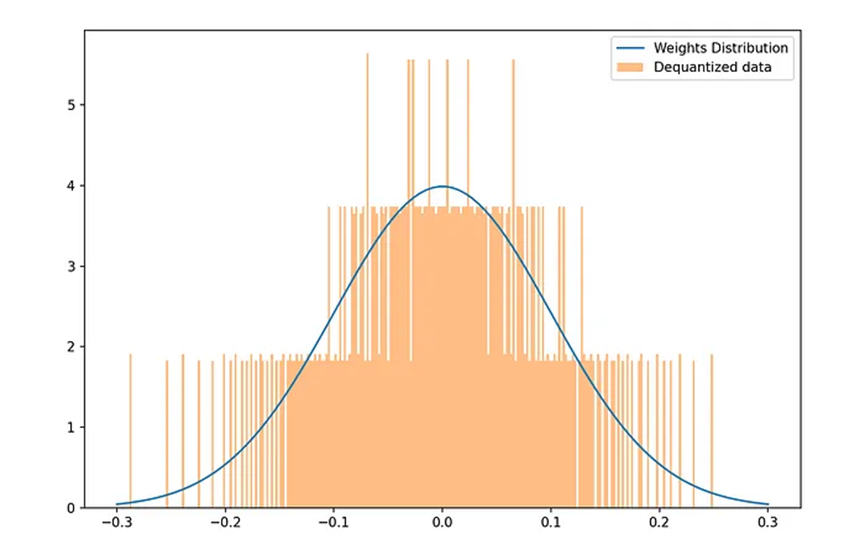
值得注意的是,在反向傳播和前向傳遞過程中,網絡的權重會進行反量化,以確保實際訓練是以更高精度格式進行的。雖然存儲仍然采用較低精度,但這種有意的選擇會引入量化誤差。然而,模型訓練過程本身具有適應和減輕量化過程中這些低效性的能力。從本質上講,采用更高精度的LoRA訓練方法有助于模型學習并積極減少量化誤差。
用HuggingFace進行QLoRA微調
要使用HuggingFace進行QLoRA微調,你需要同時安裝BitsandBytes庫和PEFT庫。BitsandBytes庫負責4位量化以及整個低精度存儲和高精度計算部分。PEFT庫將用于LoRA微調部分。
import torch
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "EleutherAI/gpt-neox-20b"
bnb_config = BitsAndBytesConfig(load_in_4bit=True,lbnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
config = LoraConfig(r=8,lora_alpha=32,target_modules=["query_key_value"],lora_dropout=0.05,bias="none",task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
7.6 IA3
IA3(通過抑制和放大內部激活注入適配器,Infused Adapter by Inhibiting and Amplifying Inner Activations)是一種基于適配器的技術,與LoRA有些相似。作者的目標是在避免上下文學習(ICL,in context learning或Few-Shot prompting)相關問題的同時,復制其優勢。ICL在成本和推理方面可能會變得復雜,因為它需要用示例來提示模型。更長的提示需要更多的時間和計算資源來處理。但ICL可能是開始使用模型的最簡單方法。
IA3通過引入針對模型激活的縮放向量來工作。總共引入了3個向量,lv、ik和lff。這些向量分別針對注意力層中的值、鍵以及密集層中的非線性層。這些向量與模型中的默認值進行逐元素相乘。一旦注入,這些參數在訓練過程中就會被學習,而模型的其余部分保持凍結。這些學習到的向量本質上是針對手頭的任務對預訓練模型的權重進行縮放或優化。
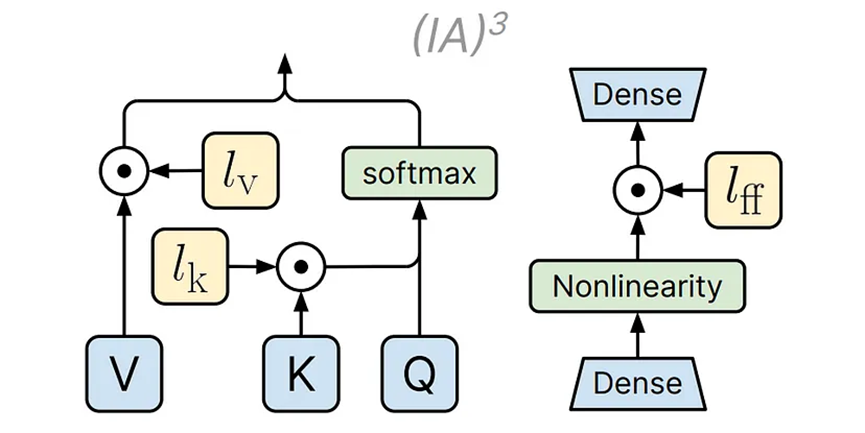
到目前為止,這似乎是一種基本的基于適配器的參數高效微調(PEFT)方法。但不止如此。作者還使用了3個損失項來增強學習過程。這3個損失項是LLM、LUL和LLN。LLM是標準的交叉熵損失,它增加了生成正確響應的可能性。然后是LUL,即非似然損失(Unlikelihood Loss)。這個損失項通過等級分類(Rank Classification)來降低錯誤輸出的概率。最后是LLN,它是一種長度歸一化損失,對所有輸出選擇的長度歸一化對數概率應用軟max交叉熵損失。這里使用多個損失項是為了確保模型更快、更好地學習。因為我們試圖通過少樣本示例進行學習,這些損失是必要的。
現在讓我們談談IA3中的兩個非常重要的概念:等級分類和長度歸一化。
在等級分類中,模型被要求根據正確性對一組響應進行排序。這是通過計算潛在響應的概率得分來完成的。然后使用LUL來降低錯誤響應的概率,從而增加正確響應的概率。但是在等級分類中,我們面臨一個關鍵問題,即由于概率的計算方式,令牌較少的響應會排名更高。生成的令牌數量越少,概率就越高,因為每個生成令牌的概率都小于1。為了解決這個問題,作者提出將響應的得分除以響應中的令牌數量。這樣做將對得分進行歸一化。這里需要非常注意的一點是,歸一化是在對數概率上進行的,而不是原始概率。對數概率是負數,且在0到1之間。
示例用法對于序列分類任務,可以按如下方式為Llama模型初始化IA3配置:
peft_config = IA3Config(task_type=TaskType.SEQ_CLS, target_modules=["k_proj", "v_proj", "down_proj"], feedforward_modules=["down_proj"]
)
7.7 P-Tuning
P-Tuning方法旨在優化傳遞給模型的提示的表示。在P-Tuning論文中,作者強調了提示工程在使用大語言模型時是一種非常強大的技術。P-Tuning方法建立在提示工程的基礎上,并試圖進一步提高優質提示的有效性。
P-Tuning通過為你的提示創建一個小型編碼器網絡來工作,該網絡為傳入的提示創建一個軟提示。要使用P-Tuning調整你的大語言模型,你應該創建一個表示你的提示的提示模板。還有一個上下文x,用于模板中以獲得標簽y。這是論文中提到的方法。提示模板中使用的令牌是可訓練和可學習的參數,這些被稱為偽令牌。我們還添加了一個提示編碼器,它幫助我們針對手頭的特定任務更新偽令牌。提示編碼器通常是一個雙向LSTM網絡,它為模型學習提示的最佳表示,然后將該表示傳遞給模型。LSTM網絡連接到原始模型。這里只有編碼器網絡和偽令牌被訓練,原始網絡的權重不受影響。訓練完成后,LSTM頭部被丟棄,因為我們有可以直接使用的hi。
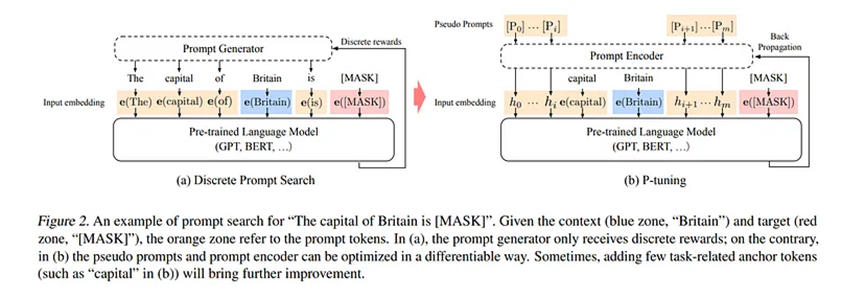
簡而言之,提示編碼器只改變傳入提示的嵌入,以更好地表示任務,其他一切都保持不變。
7.8 Prefix Tuning
Prefix Tuning可以被視為P-Tuning的下一個版本。P-Tuning的作者發表了一篇關于P-Tuning V-2的論文,解決了P-Tuning的問題。在這篇論文中,他們實現了本文中介紹的Prefix Tuning。Prefix Tuning和P-Tuning沒有太大區別,但仍然可能導致不同的結果。讓我們深入解釋一下。
在P-Tuning中,我們只在輸入嵌入中添加可學習參數,而在Prefix Tuning中,我們在網絡的所有層中添加這些參數。這確保了模型本身更多地了解它正在被微調的任務。我們在提示以及Transformer層的每一層激活中附加可學習參數。與P-Tuning的不同之處在于,我們不是完全修改提示嵌入,而是只在每一層提示的開頭添加很少的可學習參數。
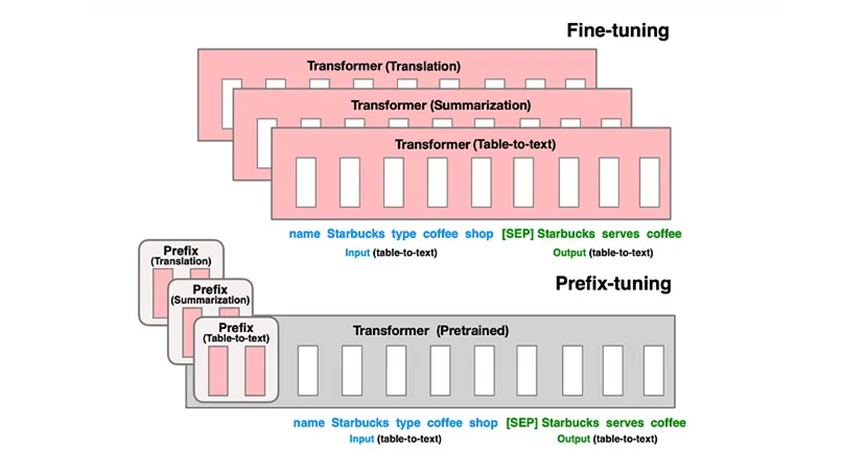
在Transformer的每一層,我們將一個帶有可學習參數的軟提示與輸入連接起來。這些可學習參數通過一個非常小的MLP(只有2個全連接層)進行調整。這樣做是因為論文的作者指出,直接更新這些提示令牌對學習率和初始化非常敏感。軟提示增加了可訓練參數的數量,但也大大提高了模型的學習能力。MLP或全連接層稍后可以去掉,因為我們只關心軟提示,在推理時,軟提示將被附加到輸入序列中,引導模型。
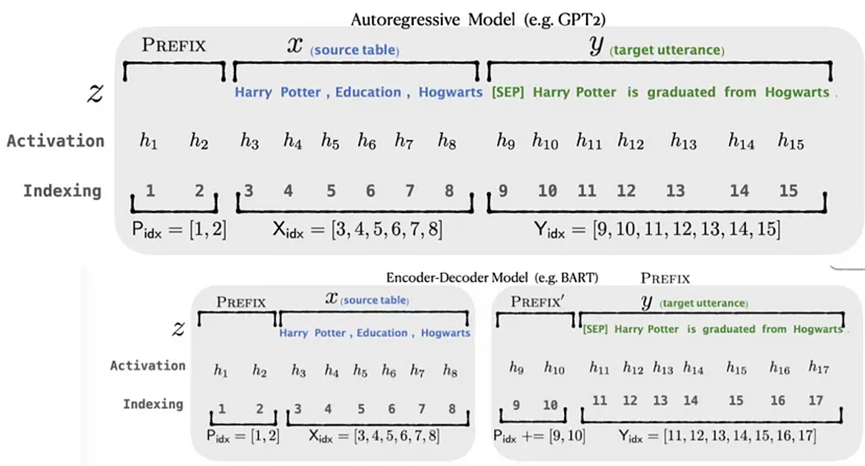
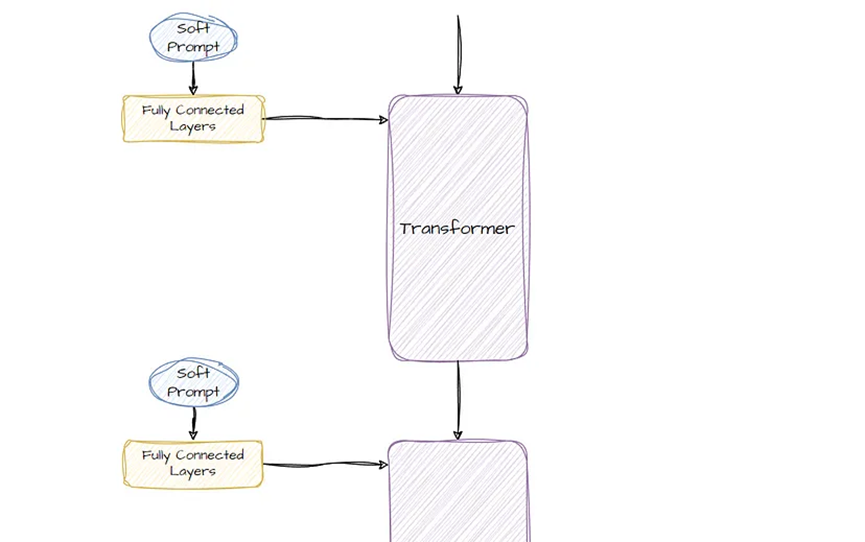
7.9 Prompt Tuning(并非提示工程)
Prompt Tuning是最早基于僅使用軟提示進行微調這一想法的論文之一。Prompt Tuning是一個非常簡單且易于實現的想法。它包括在輸入前添加一個特定的提示,并為該特定提示使用虛擬令牌或新的可訓練令牌。在這個過程中,可以對這些新的虛擬令牌進行微調,以更好地表示提示。這意味著模型被調整為更好地理解提示。以下是論文中Prompt Tuning與全量微調的比較:
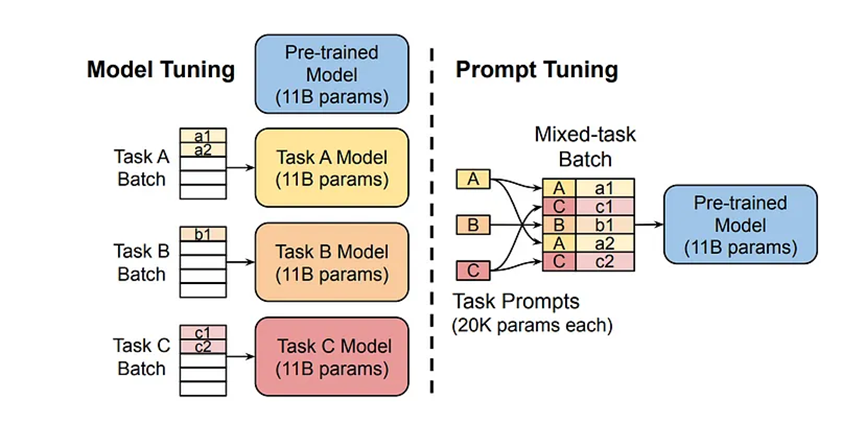
從圖中可以看到,如果我們想將模型用于多個任務,全模型微調需要存在多個模型副本。但使用Prompt Tuning,你只需要存儲學習到的提示令牌的虛擬令牌。例如,如果你使用“對這條推文進行分類:{tweet}”這樣的提示,目標將是為該提示學習新的更好的嵌入。在推理時,只有這些新的嵌入將用于生成輸出。這使得模型能夠調整提示,以幫助自己在推理時生成更好的輸出。
Prompt Tuning的效率
使用Prompt Tuning的最大優點是學習到的參數規模很小。文件大小可能只有KB級別。由于我們可以確定新令牌的維度大小和使用的參數數量,因此可以極大地控制要學習的參數數量。論文作者展示了,即使可訓練令牌的數量非常少,該方法的表現也相當出色。并且隨著使用更大的模型,性能只會進一步提升。
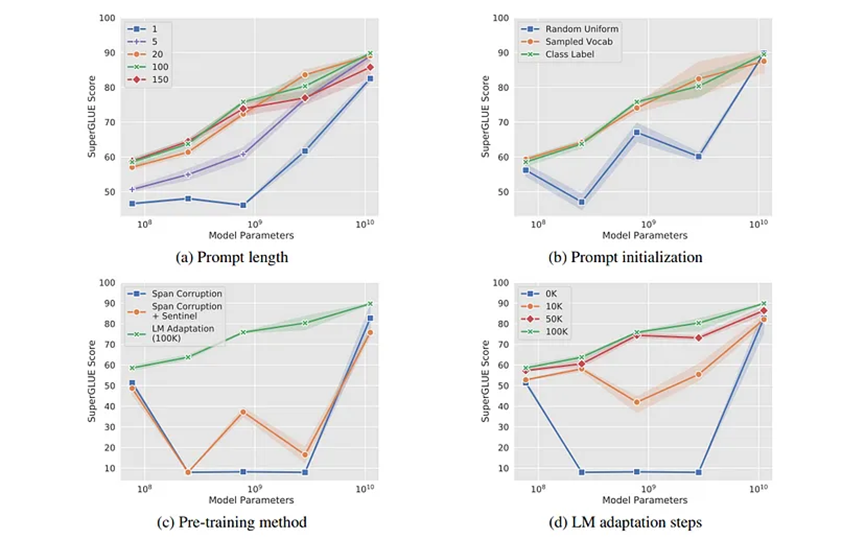
另一個很大的優點是,我們可以在不做任何修改的情況下,將同一個模型用于多個任務,因為唯一被更新的只是提示令牌的嵌入。這意味著,只要模型足夠大且足夠復雜,能夠執行這些任務,你就可以將同一個模型用于推文分類任務和語言生成任務,而無需對模型本身進行任何修改。但一個很大的限制是,模型本身不會學到任何新東西。這純粹是一個提示優化任務。這意味著,如果模型從未在情感分類數據集上進行過訓練,Prompt Tuning可能不會有任何幫助。需要特別注意的是,這種方法優化的是提示,而不是模型。所以,如果你無法手工制作一個能較好完成任務的硬提示,那么嘗試使用提示優化技術來優化軟提示就沒有任何意義。
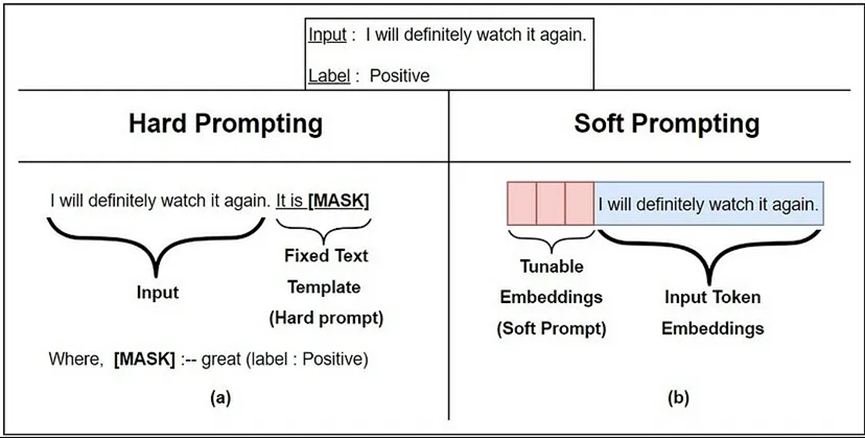
硬提示與軟提示:
硬提示可以被看作是一個定義明確的提示,它是靜態的,或者充其量是一個模板。一個生成式人工智能應用程序也可以使用多個提示模板。
提示模板允許提示被存儲、重復使用、共享和編程。生成式提示可以被整合到程序中,用于編程、存儲和重復使用。
軟提示是在Prompt Tuning過程中創建的。
與硬提示不同,軟提示無法在文本中查看和編輯。提示由嵌入(一串數字)組成,它從更大的模型中獲取知識。
可以肯定的是,軟提示的一個缺點是缺乏可解釋性。人工智能發現了與特定任務相關的提示,但無法解釋為什么選擇這些嵌入。就像深度學習模型本身一樣,軟提示是不透明的。
軟提示可作為額外訓練數據的替代品。
7.10 LoRA與Prompt Tuning對比
現在我們已經探索了各種參數高效微調(PEFT)技術。那么問題來了,是使用像適配器(Adapter )和LoRA這樣的添加式技術,還是使用像P-Tuning和Prefix Tuning這樣基于提示的技術呢?
在比較LoRA與P-Tuning和Prefix Tuning時,可以肯定地說,就充分發揮模型性能而言,LoRA是最佳策略。但根據你的需求,它可能不是最有效的。如果你想在與模型預訓練任務差異很大的任務上訓練模型,毫無疑問,LoRA是有效調整模型的最佳策略。但如果你的任務或多或少是模型已經理解的,只是挑戰在于如何正確地向模型提供提示,那么你應該使用Prompt Tuning技術。Prompt Tuning不會修改模型中的許多參數,主要側重于傳入的提示。
需要注意的一個重要點是,LoRA將權重更新矩陣分解為較小的低秩矩陣,并使用它們來更新模型的權重。即使可訓練參數較少,LoRA也會更新神經網絡目標部分中的所有參數。而在Prompt Tuning技術中,只是向模型添加了一些可訓練參數,這通常有助于模型更好地適應和理解任務,但并不能幫助模型很好地學習新特性。
7.11 LoRA和PEFT與全量微調對比
參數高效微調(PEFT)是作為全量微調的替代方案被提出的。在大多數任務中,已有論文表明,像LoRA這樣的PEFT技術即使不比全量微調更好,也與之相當。但是,如果你希望模型適應的新任務與模型預訓練的任務完全不同,PEFT可能并不夠。在這種情況下,有限數量的可訓練參數可能會導致嚴重問題。
如果我們試圖使用像LLaMA或Alpaca這樣基于文本的模型構建一個代碼生成模型,我們可能應該考慮對整個模型進行微調,而不是使用LoRA來調整模型。這是因為這個任務與模型已知和預訓練的內容差異太大。另一個典型的例子是訓練一個只懂英語的模型來生成尼泊爾語的文本。
8. 大語言模型推理:
在使用大語言模型(LLM)進行推理時,我們通常可以配置各種參數來微調其輸出和性能。以下是一些關鍵參數的詳細介紹:
- Top-k采樣:在每一步只對可能性最高的k個詞元進行采樣,這樣可以增加多樣性并避免重復。k值越高,輸出的多樣性越強,但可能連貫性會變差。
- 溫度參數:影響下一個可能詞元的概率分布,用于控制隨機性和 “創造性”。較低的溫度會生成更可能出現但可能重復的文本,而較高的溫度則會鼓勵多樣性,產生更不可預測的輸出。
- Top-P(核)采樣:Top-P或核采樣將詞元的選擇限制在累計概率達到某個閾值的詞匯子集內,有助于控制生成輸出的多樣性。
- 最大長度:設置大語言模型生成的最大詞元數,防止輸出過長。
- 上下文提示:通過提供特定的上下文提示或輸入,可以引導模型生成與該上下文一致的文本,確保生成的輸出在給定的上下文中相關且連貫。
- 重復懲罰:對出現重復n - gram的序列進行懲罰,鼓勵多樣性和新穎性。
- 采樣方式:在確定性(貪心)和基于隨機采樣的生成方式中選擇。貪心模式在每一步選擇最可能的詞元,而隨機采樣則引入隨機性。貪心模式優先考慮準確性,而隨機采樣鼓勵多樣性和創造性。
- 束搜索:保留多個潛在序列,在每一步擴展最有希望的序列,與Top-k采樣相比,旨在生成更連貫、更準確的輸出。
9. 提示工程:
提示工程,也稱為上下文提示,是指在不更新模型權重的情況下,與大語言模型進行溝通,引導其行為以獲得期望結果的方法。這是一門實證科學,提示工程方法的效果在不同模型之間可能差異很大,因此需要大量的實驗和探索。
什么是提示?
我們與大語言模型交互時使用的自然語言指令被稱為提示。構建提示的過程稱為提示工程。
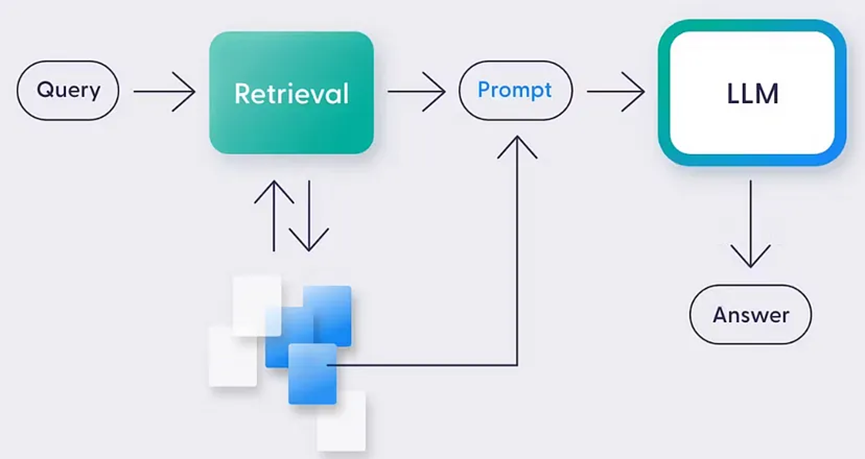
提示的作用
大語言模型根據提示中的指令進行推理并完成任務的過程被稱為上下文學習。
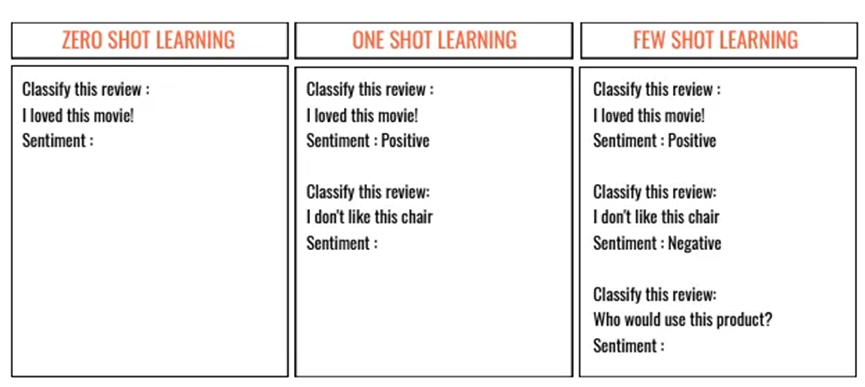
少樣本提示
大語言模型在沒有任何示例的情況下響應提示指令的能力稱為零樣本學習。
當提供單個示例時,稱為單樣本學習。
如果提供多個示例,則稱為少樣本學習。
上下文窗口,即大語言模型可以提供和推理的最大詞元數,在零樣本/單樣本/少樣本學習中至關重要。
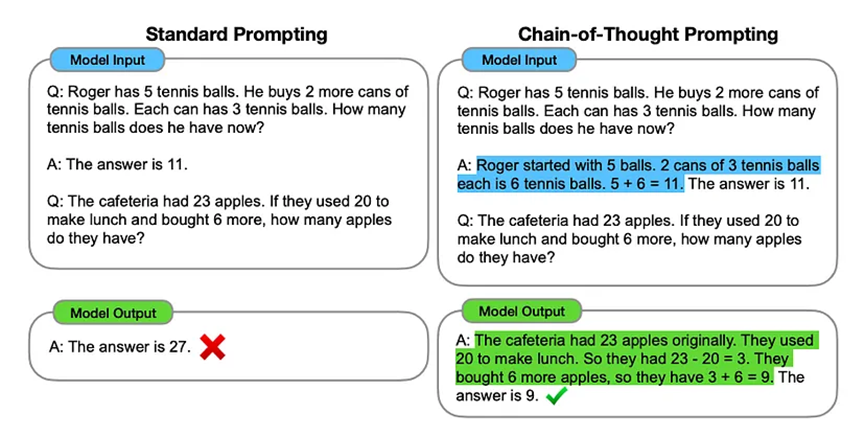
9.1 思維鏈(CoT)提示
思維鏈(CoT)提示(Wei等人,2022)會生成一系列短句子,逐步描述推理邏輯,即推理鏈或推理依據,最終得出答案。在使用大型模型(例如參數超過500億的模型)處理復雜推理任務時,CoT的優勢更為明顯。而簡單任務使用CoT提示的受益則相對較小。
9.2 PAL(程序輔助語言模型)
Gao等人(2022)PAL: Program-aided Language Models提出了一種方法,使用大語言模型讀取自然語言問題,并生成程序作為中間推理步驟。這種方法被稱為程序輔助語言模型(PAL),它與思維鏈提示的不同之處在于,它不是使用自由形式的文本獲取解決方案,而是將解決方案步驟交給諸如Python解釋器這樣的程序運行時處理。

9.3 ReAct提示
ReAct的靈感來自于 “行動” 和 “推理” 之間的協同作用,這種協同作用使人類能夠學習新任務并做出決策或進行推理。
CoT由于無法訪問外部世界或更新自身知識,可能會導致事實幻覺和錯誤傳播等問題。
ReAct是一種將推理和行動與大語言模型相結合的通用范式。ReAct促使大語言模型為任務生成語言推理軌跡和行動。這使系統能夠進行動態推理,創建、維護和調整行動方案,同時還能與外部環境(例如維基百科)進行交互,將更多信息納入推理過程。下圖展示了ReAct的一個示例以及執行問答任務所涉及的不同步驟。

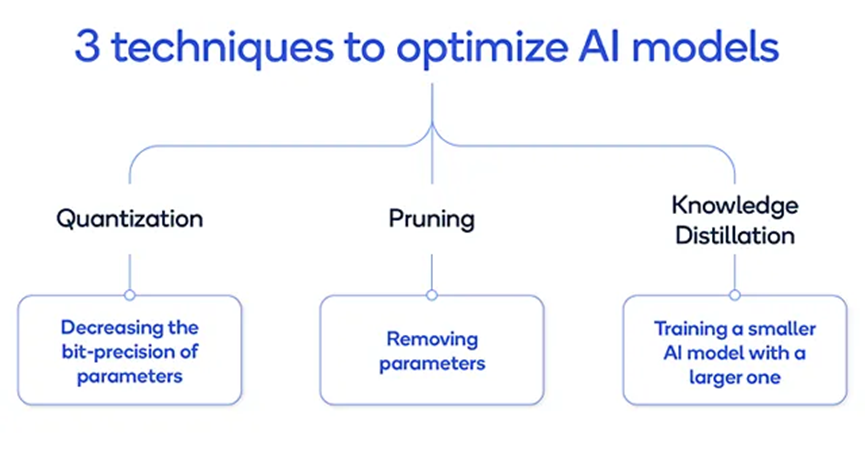
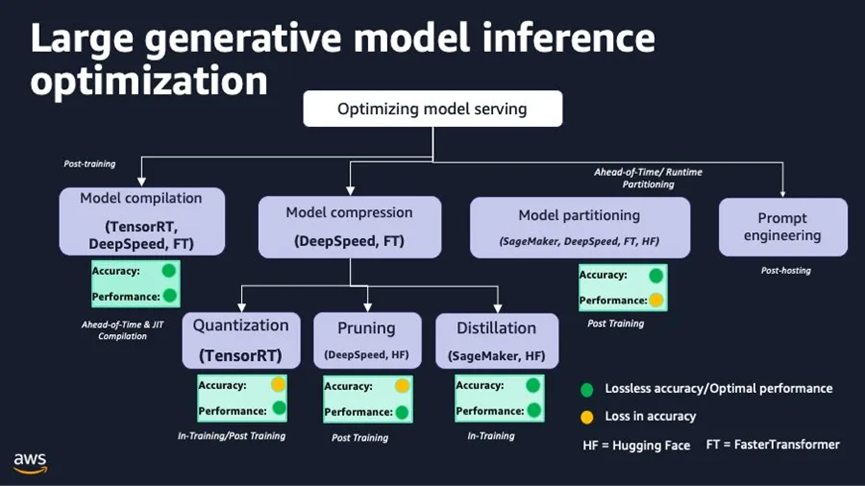
10. 模型優化技術:
模型壓縮方法包括:(a)剪枝、(b)量化和(c)知識蒸餾。
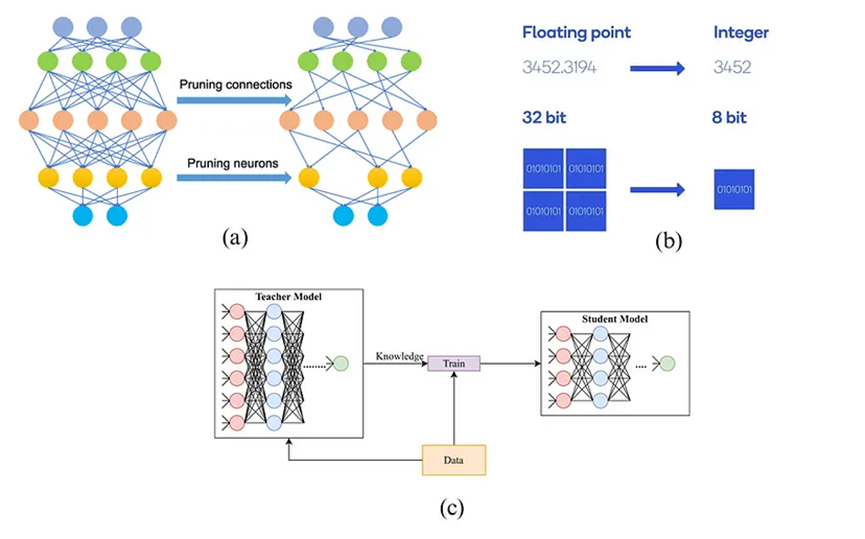
10.1 量化
模型量化是一種用于減小大型神經網絡(包括大語言模型LLM)大小的技術,通過修改其權重的精度來實現。大語言模型的量化之所以可行,是因為實證結果表明,雖然神經網絡訓練和推理的某些操作必須使用高精度,但在某些情況下,可以使用低得多的精度(例如float16),這可以減小模型的整體大小,使其能夠在性能和準確性可接受的情況下,在性能較弱的硬件上運行。
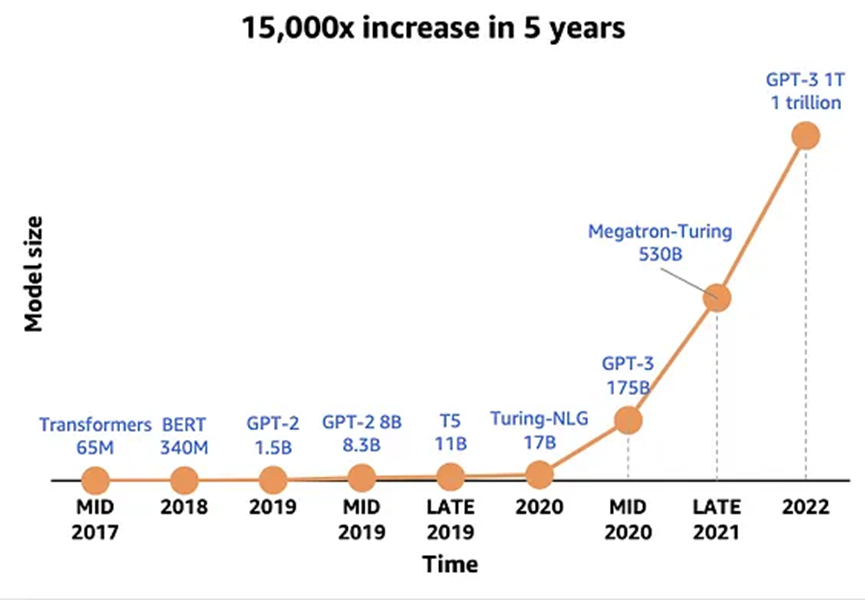
一般來說,在神經網絡中使用高精度與更高的準確性和更穩定的訓練相關。使用高精度在計算上也更為昂貴,因為它需要更多且更昂貴的硬件。谷歌和英偉達的相關研究表明,神經網絡的某些訓練和推理操作可以使用較低的精度。
除了研究之外,這兩家公司還開發了支持低精度操作的硬件和框架。例如,英偉達的T4加速器是低精度GPU,其張量核心技術比K80的效率要高得多。谷歌的TPU引入了bfloat16的概念,這是一種為神經網絡優化的特殊基本數據類型。低精度的基本思想是,神經網絡并不總是需要使用64位浮點數的全部范圍才能表現良好。

隨著神經網絡越來越大,利用低精度的重要性對使用它們的能力產生了重大影響。對于大語言模型來說,這一點更為關鍵。
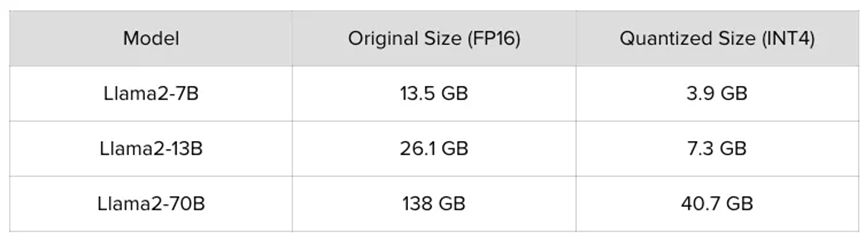
英偉達的A100 GPU最先進的版本有80GB內存。在下面的表格中可以看到,LLama2 - 70B模型大約需要138GB內存,這意味著要部署它,我們需要多個A100 GPU。在多個GPU上分布模型不僅意味著要購買更多的GPU,還需要額外的基礎設施開銷。另一方面,量化版本大約需要40GB內存,因此可以輕松地在一個A100上運行,顯著降低了推理成本。這個例子甚至還沒有提到在單個A100中,使用量化模型會使大多數單個計算操作執行得更快。
使用llama.cpp進行4位量化的示例,大小可能會因方法略有不同。
1.量化如何縮小模型?:量化通過減少每個模型權重所需的比特數來顯著減小模型的大小。一個典型的場景是將權重從FP16(16位浮點數)減少到INT4(4位整數)。這使得模型可以在更便宜的硬件上運行,并且 / 或者運行速度更快。然而,降低權重的精度也會對大語言模型的整體質量產生一定影響。研究表明,這種影響因使用的技術而異,并且較大的模型對精度變化的影響較小。較大的模型(超過約700億參數)即使轉換為4位,也能保持其性能,像NF4這樣的一些技術表明對其性能沒有影響。因此,對于這些較大的模型,4位似乎是在性能與大小 / 速度之間的最佳折衷,而6位或8位可能更適合較小的模型。
2.大語言模型量化的類型:獲得量化模型的技術可以分為兩類。
- 訓練后量化(PTQ):將已經訓練好的模型的權重轉換為較低精度,而無需任何重新訓練。雖然這種方法簡單直接且易于實現,但由于權重值精度的損失,可能會使模型性能略有下降。
- 量化感知訓練(QAT):與PTQ不同,QAT在訓練階段就整合了權重轉換過程。這通常會帶來更好的模型性能,但計算要求更高。一種常用的QAT技術是QLoRA。
本文將只關注PTQ策略及其關鍵區別。
- 更大的量化模型與更小的未量化模型:我們知道降低精度會降低模型的準確性,那么你會選擇較小的全精度模型,還是選擇推理成本相當的更大的量化模型呢?盡管理想的選擇可能因多種因素而異,但Meta的最新研究提供了一些有見地的指導。雖然我們預期降低精度會導致準確性下降,但Meta的研究人員已經證明,在某些情況下,量化模型不僅表現更優,而且還能減少延遲并提高吞吐量。在比較8位的130億參數模型和16位的70億參數模型時,也可以觀察到相同的趨勢。本質上,在比較推理成本相似的模型時,更大的量化模型可以超越更小的未量化模型。隨著網絡規模的增大,這種優勢更加明顯,因為大型網絡在量化時質量損失較小。
- 在哪里可以找到已經量化的模型?:幸運的是,在Hugging Face Hub上可以找到許多已經使用GPTQ(有些與ExLLama兼容)、NF4或GGML進行量化的模型版本。快速瀏覽一下就會發現,這些模型中有很大一部分是由大語言模型社區中一位有影響力且備受尊敬的人物TheBloke量化的。該用戶發布了多個使用不同量化方法的模型,因此人們可以根據具體的用例選擇最合適的模型。要輕松試用這些模型,可以打開一個Google Colab,并確保將運行時更改為GPU(有免費的GPU可供使用)。首先安裝Hugging Face維護的transformers庫以及所有必要的庫。由于我們將使用由Auto - GPTQ量化的模型,因此還需要安裝相應的庫:
- 你可能需要重新啟動運行時,以便安裝的庫可用。然后,只需加載已經量化的模型,這里我們加載一個之前使用Auto - GPTQ量化的Llama - 2 - 7B - Chat模型,如下所示:
#pip install transformers
#pip install accelerate
#pip install optimum
#pip install auto - gptqfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torchmodel_id = "TheBloke/Llama-2-7b-Chat-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
量化大語言模型:如前所述,Hugging Face Hub上已經有大量量化模型,在許多情況下,無需自己壓縮模型。然而,在某些情況下,你可能希望使用尚未量化的模型,或者你可能希望自己壓縮模型。這可以通過使用適合你特定領域的數據集來實現。為了演示如何使用AutoGPTQ和Transformers庫輕松量化模型,我們采用了Optimum(Hugging Face用于優化訓練和推理的解決方案)中簡化版的AutoGPTQ接口:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfigmodel_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)
模型壓縮可能很耗時。例如,一個1750億參數的模型至少需要4個GPU小時,尤其是使用像 “c4” 這樣的大型數據集時。值得注意的是,量化過程中的比特數或數據集可以通過GPTQConfig的參數輕松修改。更改數據集會影響量化的方式,因此,如果可能的話,使用與推理時看到的數據相似的數據集,以最大化性能。
- 量化技術:在模型量化領域已經出現了幾種最先進的方法。讓我們深入了解一些突出的方法:
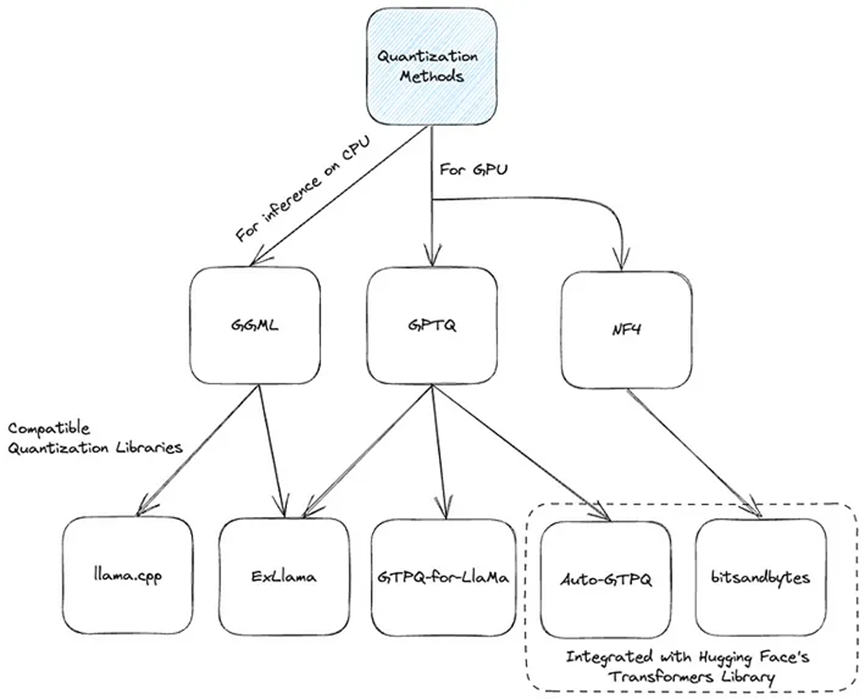
- GPTQ:有一些實現選項,如AutoGPTQ、ExLlama和GPTQ - for - LLaMa,這種方法主要側重于GPU執行。
- NF4:在bitsandbytes庫中實現,它與Hugging Face的transformers庫緊密合作。它主要被QLoRA方法使用,以4位精度加載模型進行微調。
- GGML:這個C庫與llama.cpp庫緊密合作。它為大語言模型提供了一種獨特的二進制格式,允許快速加載和易于讀取。值得注意的是,它最近轉換為GGUF格式,以確保未來的可擴展性和兼容性。
許多量化庫支持多種不同的量化策略(例如4位、5位和8位量化),每種策略在效率和性能之間都提供了不同的權衡。
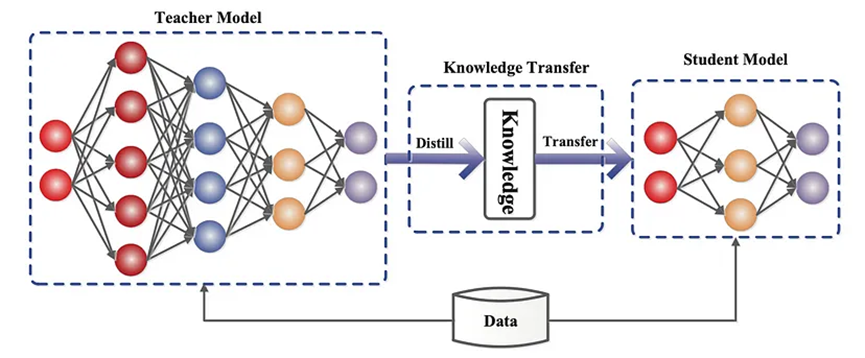
10.2 蒸餾
知識蒸餾(KD; Hinton等人,2015年;Gou等人,2020年)Distilling the Knowledge in a Neural Network是一種構建更小、成本更低模型(“學生模型”)的直接方法,通過將預訓練的高成本模型(“教師模型”)的能力轉移到學生模型中,來加快推理速度。除了要求學生模型的輸出空間與教師模型匹配,以便構建合適的學習目標之外,對學生模型的架構構建方式并沒有太多限制。
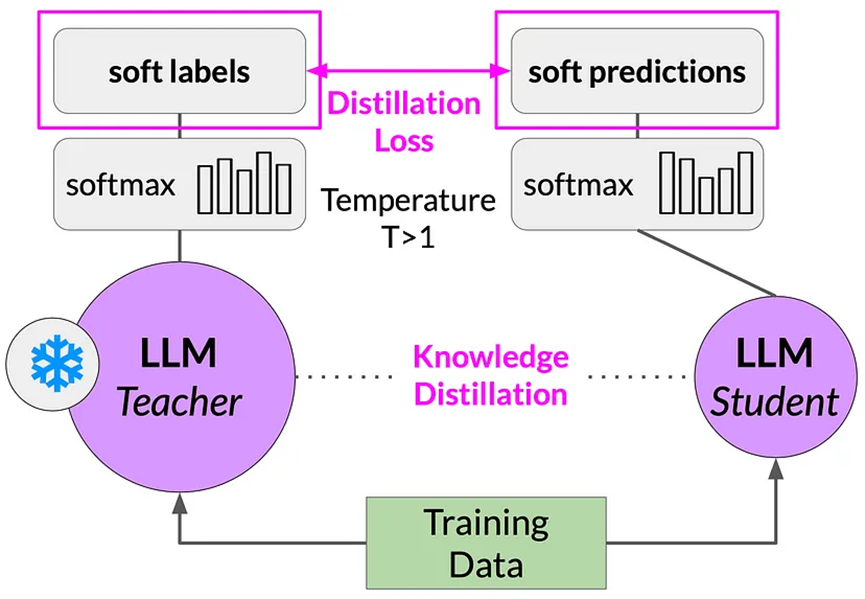
教師模型已經在訓練數據上進行了微調,因此,其概率分布可能與真實數據非常接近,并且在生成的token上不會有太多變化。
當溫度>1時,概率分布會變得更寬泛。
- T > 1時 => 教師模型的輸出 -> 軟標簽 學生模型的輸出 -> 軟預測
- T = 1時 => 教師模型的輸出 -> 硬標簽 學生模型的輸出 -> 硬預測
蒸餾對于生成式解碼器模型的效果并不顯著,它對僅編碼器模型(如BERT)更為有效,因為這類模型存在大量的表示冗余。
10.3 剪枝
網絡剪枝是指在保持模型能力的同時,通過修剪不重要的模型權重或連接來減小模型大小。這一過程可能需要也可能不需要重新訓練。剪枝可分為非結構化剪枝和結構化剪枝。
非結構化剪枝允許刪除任何權重或連接,因此不會保留原始網絡架構。非結構化剪枝通常與現代硬件的適配性不佳,并且無法真正加快推理速度。
結構化剪枝旨在保持矩陣乘法中部分元素為零的密集形式。為了適配硬件內核的支持,它們可能需要遵循特定的模式限制。這里我們主要關注結構化剪枝,以在Transformer模型中實現高稀疏性。
構建剪枝網絡的常規工作流程包含三個步驟:
- 訓練一個密集網絡直至收斂;
- 對網絡進行剪枝,去除不需要的結構;
- 可選步驟,重新訓練網絡,通過新的權重恢復模型性能 。
通過網絡剪枝在密集模型中發現稀疏結構,同時使稀疏網絡仍能保持相似性能,這一想法的靈感來源于彩票假設(LTH):一個隨機初始化的、密集的前饋網絡包含多個子網絡,其中只有一部分(稀疏網絡)是 “中獎彩票”,當單獨訓練時,這些子網絡能夠達到最佳性能。
結論:
在本篇文章中,我們探索了檢索增強生成(RAG)應用中的文本生成部分,重點介紹了大語言模型(LLM)的使用。內容涵蓋了語言建模、預訓練面臨的挑戰、量化技術、分布式訓練方法,以及大語言模型的微調。此外,還討論了參數高效微調(PEFT)技術,包括適配器、LoRA和QLoRA;介紹了提示策略、模型壓縮方法(如剪枝和量化),以及各種量化技術(GPTQ、NF4、GGML)。最后,對用于減小模型大小的蒸餾和剪枝技術進行了講解。
References:
[1]Transformer: https://arxiv.org/abs/1706.03762
[2]BLOOM: https://huggingface.co/docs/transformers/model_doc/bloom
[3]Parameter-Efficient Transfer Learning for NLP: https://arxiv.org/abs/1902.00751
[4]Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning: https://arxiv.org/abs/2012.13255
[5]Infused Adapter by Inhibiting and Amplifying Inner Activations: https://arxiv.org/abs/2205.05638
[6]P-Tuning論文: https://arxiv.org/abs/2103.10385
[7]P-Tuning V-2: https://arxiv.org/abs/2110.07602
[8]思維鏈(CoT)提示: https://arxiv.org/abs/2201.11903
[9]PAL: Program-aided Language Models: https://arxiv.org/abs/2211.10435
[10]Distilling the Knowledge in a Neural Network: https://arxiv.org/abs/1503.02531






)






——面向對象基本概念、分析設計測試)





