4月18日復盤
一、深度學習概述
? 傳統機器學習算法依賴人工設計特征、提取特征,而深度學習依賴算法自動提取特征。深度學習模仿人類大腦的運行方式,從大量數據中學習特征,這也是深度學習被看做黑盒子、可解釋性差的原因。
? 隨著算力的提升,深度學習可以處理圖像,文本,音頻,視頻等各種內容,主要應用領域有:
- 圖像處理:分類、目標檢測、圖像分割(語義分割)
- 自然語言處理:LLM、NLP、Transformer
- 語音識別:對話機器人、智能客服(語音+NLP)
- 自動駕駛:語義分割(行人、車輛、實線等)
- LLM:大Large語言Language模型Model
- 機器人:非常火的行業
? 深度學習其實并不是新的事物,深度學習所需要的神經網絡技術起源于20世紀50年代,叫做感知機。當時使用單層感知機,因為只能學習線性可分函數,連簡單的異或(XOR)等線性不可分問題都無能為力,1969年Marvin Minsky寫了一本叫做《Perceptrons》的書,他提出了著名的兩個觀點:1.單層感知機沒用,我們需要多層感知機來解決復雜問題 2.沒有有效的訓練算法。
? 20世紀80年代末期,用于人工神經網絡的反向傳播算法(也叫Back Propagation算法或者BP算法)的發明,給機器學習帶來了希望,掀起了基于統計模型的機器學習熱潮。這個熱潮一直持續到今天。人們發現,利用BP算法可以讓一個人工神經網絡模型從大量訓練樣本中學習統計規律,從而對未知事件做預測。這種基于統計的機器學習方法比起過去基于人工規則的系統,在很多方面顯出優越性。這個時候的人工神經網絡,雖也被稱作多層感知機(Multi-layer Perceptron),但實際是種只含有一層隱層節點的淺層模型。
2006年,杰弗里·辛頓以及他的學生魯斯蘭·薩拉赫丁諾夫正式提出了深度學習的概念。
2012年,在著名的ImageNet圖像識別大賽中,杰弗里·辛頓領導的小組采用深度學習模型AlexNet一舉奪冠。AlexNet采用ReLU激活函數,從根本上解決了梯度消失問題,并采用GPU極大的提高了模型的運算速度。
同年,吳恩達教授和Jeff Dean主導的深度神經網絡DNN技術在ImageNet評測中把錯誤率從26%降低到15%,再一次吸引了學術界和工業界對于深度學習領域的關注。
2016年,隨著谷歌公司基于深度學習開發的AlphaGo以4:1的比分戰勝了國際頂尖圍棋高手李世石,深度學習的熱度一時無兩。后來,AlphaGo又接連和眾多世界級圍棋高手過招,均取得了完勝。這也證明了在圍棋界,基于深度學習技術的機器人已經超越了人類。
2017年,基于強化學習算法的AlphaGo升級版AlphaGo Zero橫空出世。其采用“從零開始”、“無師自通”的學習模式,以100:0的比分輕而易舉打敗了之前的AlphaGo。除了圍棋,它還精通國際象棋等其它棋類游戲,可以說是真正的棋類“天才”。此外在這一年,深度學習的相關算法在醫療、金融、藝術、無人駕駛等多個領域均取得了顯著的成果。所以,也有專家把2017年看作是深度學習甚至是人工智能發展最為突飛猛進的一年。
2019年,基于Transformer 的自然語言模型的持續增長和擴散,這是一種語言建模神經網絡模型,可以在幾乎所有任務上提高NLP的質量。Google甚至將其用作相關性的主要信號之一,這是多年來最重要的更新。
2020年,深度學習擴展到更多的應用場景,比如積水識別,路面塌陷等,而且疫情期間,在智能外呼系統,人群測溫系統,口罩人臉識別等都有深度學習的應用。
二、神經網絡
? 我們要學習的深度學習(Deep Learning)是神經網絡的一個子領域,主要關注更深層次的神經網絡結構,也就是深層神經網絡(Deep Neural Networks,DNNs)。所以,我們需要先搞清楚什么是神經網絡!
1. 感知神經網絡
神經網絡(Neural Networks)是一種模擬人腦神經元網絡結構的計算模型,用于處理復雜的模式識別、分類和預測等任務。生物神經元如下圖:
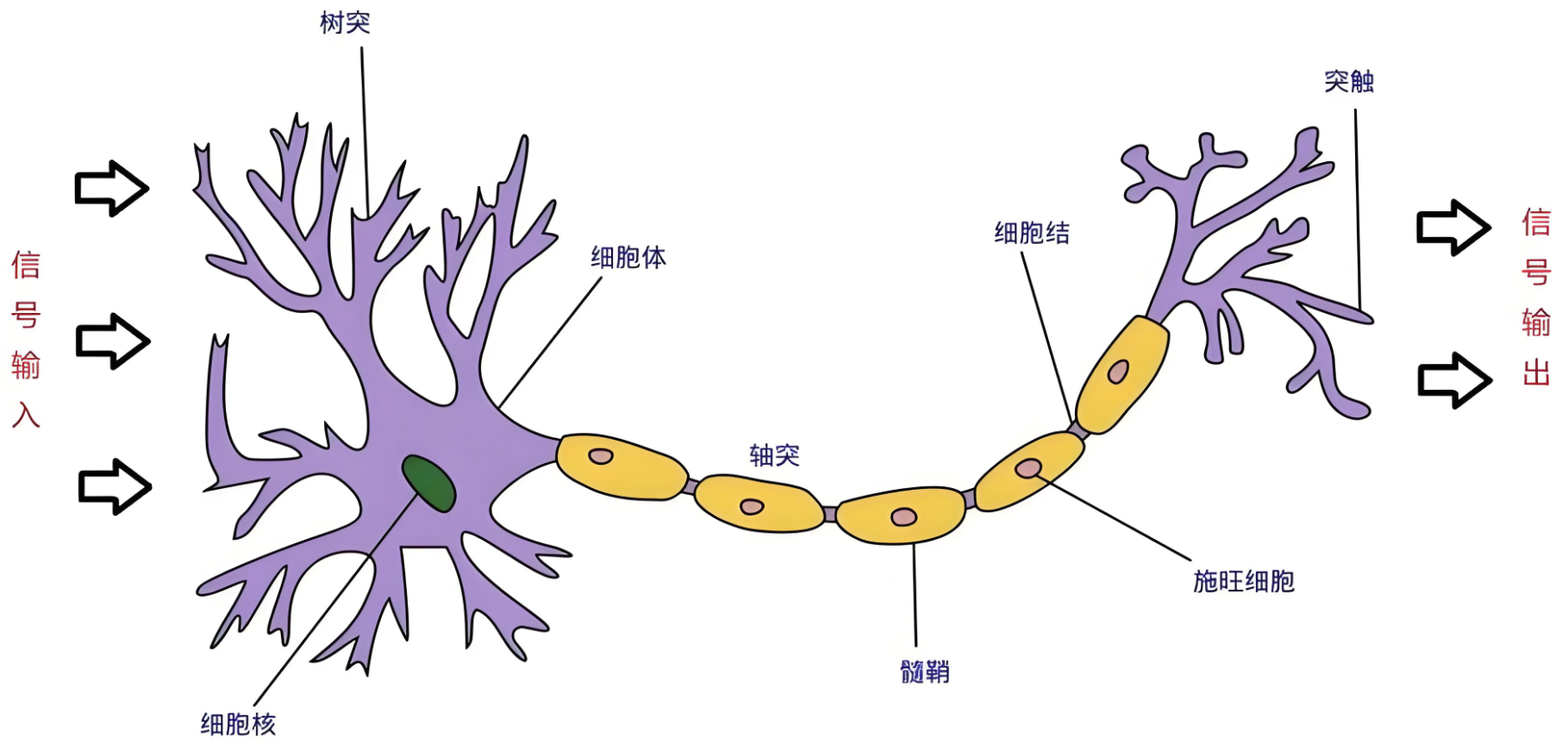
生物學:
人腦可以看做是一個生物神經網絡,由眾多的神經元連接而成
- 樹突:從其他神經元接收信息的分支
- 細胞核:處理從樹突接收到的信息
- 軸突:被神經元用來傳遞信息的生物電纜
- 突觸:軸突和其他神經元樹突之間的連接
人腦神經元處理信息的過程:
- 多個信號到達樹突,然后整合到細胞體的細胞核中
- 當積累的信號超過某個閾值,細胞就會被激活
- 產生一個輸出信號,由軸突傳遞。
神經網絡由多個互相連接的節點(即人工神經元)組成。
2. 人工神經元
? 人工神經元(Artificial Neuron)是神經網絡的基本構建單元,模仿了生物神經元的工作原理。其核心功能是接收輸入信號,經過加權求和和非線性激活函數處理后,輸出結果。
2.1 構建人工神經元
人工神經元接受多個輸入信息,對它們進行加權求和,再經過激活函數處理,最后將這個結果輸出。
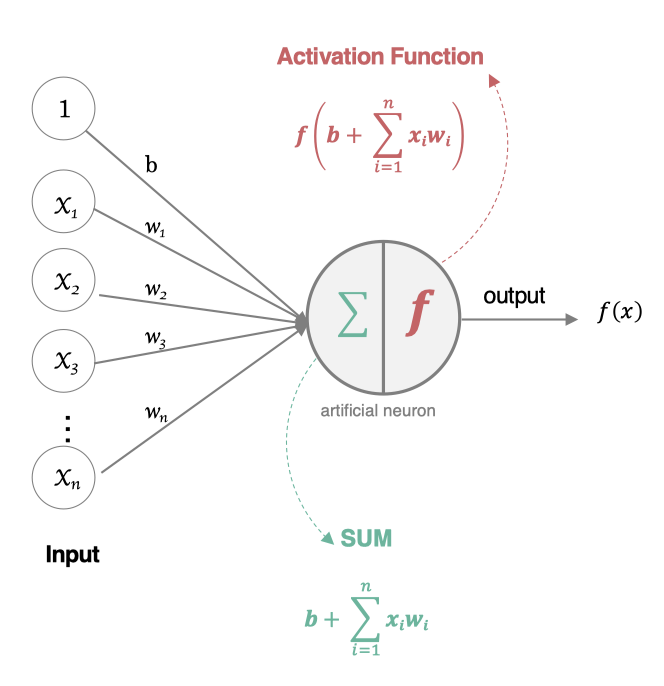
2.2 組成部分
- 輸入(Inputs): 代表輸入數據,通常用向量表示,每個輸入值對應一個權重。
- 權重(Weights): 每個輸入數據都有一個權重,表示該輸入對最終結果的重要性。
- 偏置(Bias): 一個額外的可調參數,作用類似于線性方程中的截距,幫助調整模型的輸出。
- 加權求和: 神經元將輸入乘以對應的權重后求和,再加上偏置。
- 激活函數(Activation Function): 用于將加權求和后的結果轉換為輸出結果,引入非線性特性,使神經網絡能夠處理復雜的任務。常見的激活函數有Sigmoid、ReLU(Rectified Linear Unit)、Tanh等。
2.3 數學表示
如果有 n 個輸入 x 1 , x 2 , … , x n x_1, x_2, \ldots, x_n x1?,x2?,…,xn?,權重分別為 w 1 , w 2 , … , w n w_1, w_2, \ldots, w_n w1?,w2?,…,wn?,偏置為 b b b,則神經元的輸出 y y y 表示為:
z = ∑ i = 1 n w i ? x i + b y = σ ( z ) z=\sum_{i=1}^nw_i\cdot x_i+b \\ y=\sigma(z) z=i=1∑n?wi??xi?+by=σ(z)
其中, σ ( z ) \sigma(z) σ(z) 是激活函數。
例如:
線性回歸:
y = ∑ i = 1 n w i ? x i + b y=\sum_{i=1}^nw_i\cdot x_i+b \\ y=i=1∑n?wi??xi?+b
線性回歸不需要激活函數
邏輯回歸:
z = ∑ i = 1 n w i ? x i + b y = σ ( z ) = s i g m o i d ( z ) = 1 1 + e ? z z=\sum_{i=1}^nw_i\cdot x_i+b \\ y=\sigma(z)=sigmoid(z)=\frac{1}{1+e^{-z}} z=i=1∑n?wi??xi?+by=σ(z)=sigmoid(z)=1+e?z1?
2.4 對比生物神經元
人工神經元和生物神經元對比如下表:
| 生物神經元 | 人工神經元 |
|---|---|
| 細胞核 | 節點 (加權求和 + 激活函數) |
| 樹突 | 輸入 |
| 軸突 | 帶權重的連接 |
| 突觸 | 輸出 |
3. 深入神經網絡
神經網絡是由大量人工神經元按層次結構連接而成的計算模型。每一層神經元的輸出作為下一層的輸入,最終得到網絡的輸出。
3.1 基本結構
神經網絡有下面三個基礎層(Layer)構建而成:
-
輸入層(Input): 神經網絡的第一層,負責接收外部數據,不進行計算。
-
隱藏層(Hidden): 位于輸入層和輸出層之間,進行特征提取和轉換。隱藏層一般有多層,每一層有多個神經元。
-
輸出層(Output): 網絡的最后一層,產生最終的預測結果或分類結果
3.2 網絡構建
我們使用多個神經元來構建神經網絡,相鄰層之間的神經元相互連接,并給每一個連接分配一個權重,經典如下:
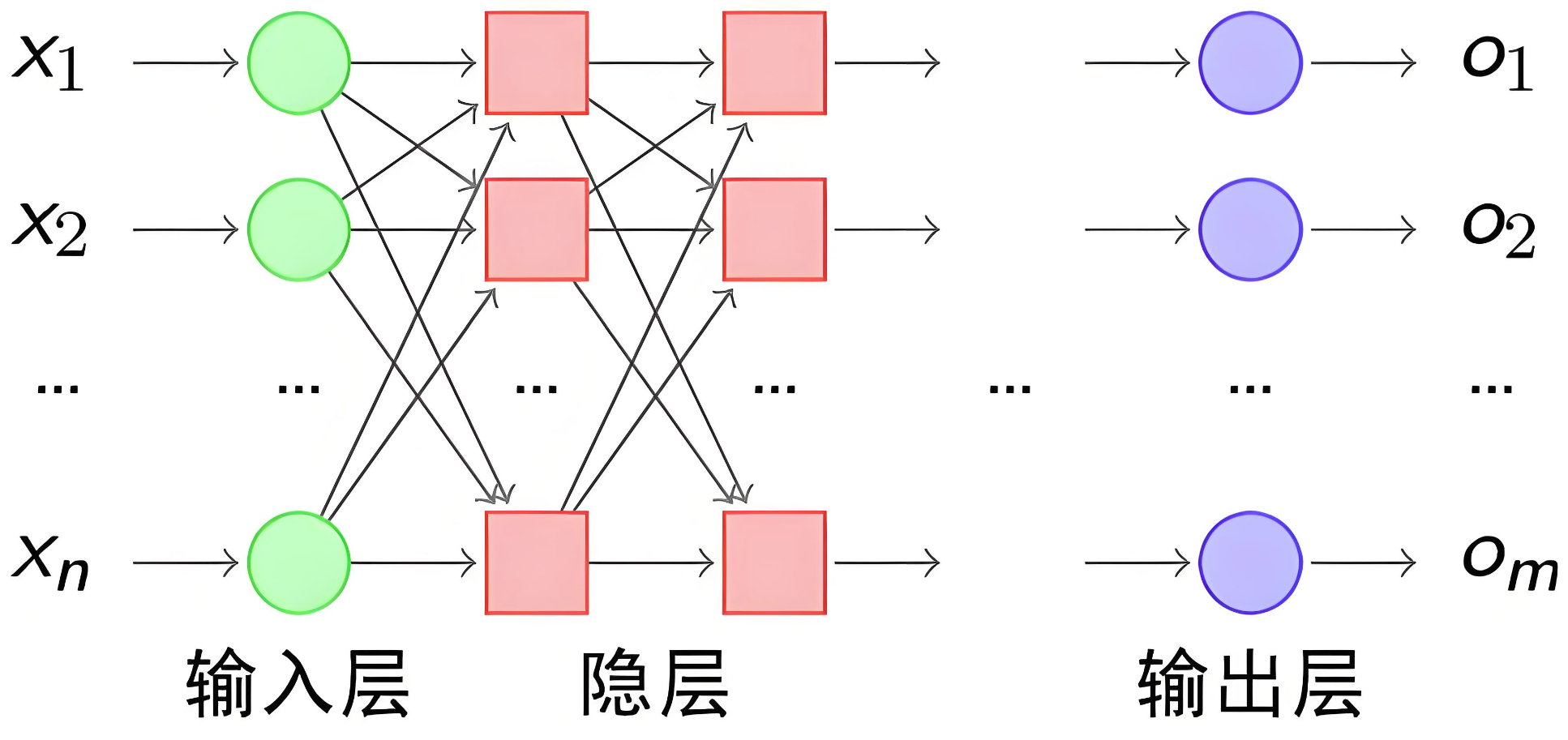
注意:同一層的各個神經元之間是沒有連接的。
3.3 全連接神經網絡
前饋神經網絡(Feedforward Neural Network,FNN)是一種最基本的神經網絡結構,其特點是信息從輸入層經過隱藏層單向傳遞到輸出層,沒有反饋或循環連接。
全連接神經網絡(Fully Connected Neural Network,FCNN)是前饋神經網絡的一種,每一層的神經元與上一層的所有神經元全連接,常用于圖像分類、文本分類等任務。
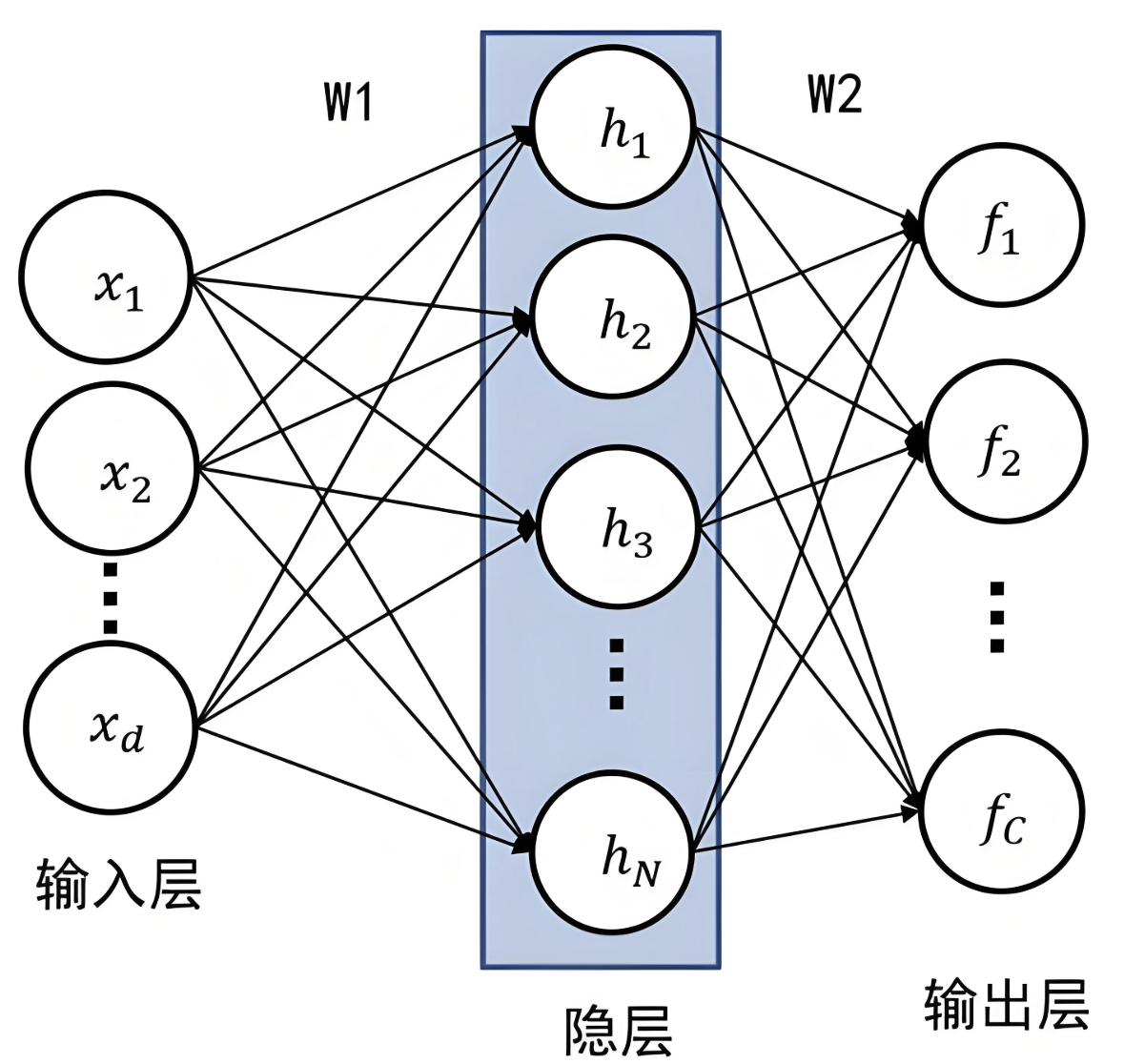
外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳
如上圖,網絡中每個神經元:
z 1 = x 1 ? w 1 + x 2 ? w 2 + b 1 z 2 = x 1 ? w 1 + x 2 ? w 2 + b 2 z 3 = x 1 ? w 1 + x 2 ? w 2 + b 3 z_1 = x_1*w_1 + x_2*w_2+b_1 \\ z_2 = x_1*w_1 + x_2*w_2+b_2 \\ z_3 = x_1*w_1 + x_2*w_2+b_3 z1?=x1??w1?+x2??w2?+b1?z2?=x1??w1?+x2??w2?+b2?z3?=x1??w1?+x2??w2?+b3?
說明:三個等式中的w1和w2在這里只是為了方便表示對應x1和x2的權重,實際三個等式中的w值是不同的。
向量x為: [ x 1 , x 2 ] [x_1,x_2] [x1?,x2?]
向量w: ( w 1 , w 2 w 1 , w 2 w 1 , w 2 ) \begin{pmatrix}w_1,w_2\\w_1,w_2\\w_1,w_2 \end{pmatrix} ?w1?,w2?w1?,w2?w1?,w2?? ?,其形狀為(3,2),3是神經元節點個數,2是向量x的個數
向量z: [ z 1 , z 2 , z 3 ] [z_1,z_2,z_3] [z1?,z2?,z3?]
向量b: [ b 1 , b 2 , b 3 ] [b_1,b_2,b_3] [b1?,b2?,b3?]
所以用向量表示為:
z = ( z 1 , z 2 , z 3 ) = ( x 1 , x 2 ) ( w 1 , w 1 , w 1 w 2 , w 2 , w 2 ) + ( b 1 , b 2 , b 3 ) = ( x 1 , x 2 ) ( w 1 , w 2 w 1 , w 2 w 1 , w 2 ) T + ( b 1 , b 2 , b 3 ) = x w T + b z = \begin{pmatrix}z_1,z_2,z_3 \end{pmatrix}=\begin{pmatrix}x_1,x_2 \end{pmatrix}\begin{pmatrix}w_1,w_1,w_1\\w_2,w_2,w_2\end{pmatrix}+\begin{pmatrix}b_1,b_2,b_3 \end{pmatrix}=\begin{pmatrix}x_1,x_2 \end{pmatrix}\begin{pmatrix}w_1,w_2\\w_1,w_2\\w_1,w_2 \end{pmatrix}^T + \begin{pmatrix}b_1,b_2,b_3 \end{pmatrix}=xw^T+b z=(z1?,z2?,z3??)=(x1?,x2??)(w1?,w1?,w1?w2?,w2?,w2??)+(b1?,b2?,b3??)=(x1?,x2??) ?w1?,w2?w1?,w2?w1?,w2?? ?T+(b1?,b2?,b3??)=xwT+b
3.3.1 特點
- 全連接層: 層與層之間的每個神經元都與前一層的所有神經元相連。
- 權重數量: 由于全連接的特點,權重數量較大,容易導致計算量大、模型復雜度高。
- 學習能力: 能夠學習輸入數據的全局特征,但對于高維數據卻不擅長捕捉局部特征(如圖像就需要CNN)。
3.3.2 計算步驟
- 數據傳遞: 輸入數據經過每一層的計算,逐層傳遞到輸出層。
- 激活函數: 每一層的輸出通過激活函數處理。
- 損失計算: 在輸出層計算預測值與真實值之間的差距,即損失函數值。
- 反向傳播(Back Propagation): 通過反向傳播算法計算損失函數對每個權重的梯度,并更新權重以最小化損失。
3.3.3 創建全連接神經網絡
創建一個最基本的全連接神經網絡(也稱為多層感知機,MLP)通常需要以下步驟和方法:
- 定義網絡結構
- 輸入層:確定輸入數據的維度。例如,對于一個簡單的圖像分類任務,輸入層的維度可能是圖像的像素數量。
- 隱藏層:定義一個或多個隱藏層,每個隱藏層包含一定數量的神經元。隱藏層的數量和每個隱藏層的神經元數量可以根據任務需求調整。
- 輸出層:根據任務目標確定輸出層的神經元數量。例如,對于一個二分類問題,輸出層通常有一個神經元;對于多分類問題,輸出層的神經元數量等于類別數。
- 選擇激活函數
- 隱藏層激活函數:常用的激活函數有ReLU(Rectified Linear Unit)、Sigmoid、Tanh等。ReLU是最常用的激活函數,因為它可以有效緩解梯度消失問題。
- 輸出層激活函數:根據任務類型選擇合適的激活函數。例如,對于二分類任務,輸出層通常使用Sigmoid函數;對于多分類任務,輸出層使用Softmax函數。
- 初始化權重和偏置
- 權重初始化:權重的初始化方法對網絡的訓練效果有重要影響。常見的初始化方法包括隨機初始化(如Xavier初始化或He初始化)和零初始化(通常不推薦,因為會導致梯度消失)。
- 偏置初始化:偏置通常初始化為0或小的常數。
- 定義損失函數
- 二分類任務:通常使用二元交叉熵損失函數(Binary Cross-Entropy Loss)。
- 多分類任務:通常使用多類交叉熵損失函數(Categorical Cross-Entropy Loss)。
- 回歸任務:通常使用均方誤差損失函數(Mean Squared Error, MSE)。
- 選擇優化器
- SGD(隨機梯度下降):最簡單的優化器,通過計算梯度來更新權重。
- Adam:一種自適應學習率的優化器,結合了RMSprop和Momentum的優點,通常在訓練深度神經網絡時表現良好。
- 其他優化器:如RMSprop、Adagrad等。
- 前向傳播
- 在前向傳播過程中,輸入數據通過每一層的線性變換(權重乘法和偏置加法)和非線性激活函數,最終得到輸出結果。
- 計算損失
- 使用定義的損失函數計算模型的輸出與真實標簽之間的差異。
- 反向傳播
- 通過計算損失函數對每個權重和偏置的梯度,利用鏈式法則反向傳播這些梯度,更新網絡的權重和偏置。
- 訓練模型
- 迭代地執行前向傳播、計算損失和反向傳播,直到模型的性能不再提升或達到預定的訓練輪數。
示例:創建一個全連接神經網絡,主要步驟包括:
- 定義模型結構。
- 初始化模型、損失函數和優化器。
- 準備數據。
- 訓練模型。
- (可選)評估模型。
你可以根據實際任務調整網絡結構、損失函數和優化器等。
import torch
from torch import nn
from torch import optim
from torch.nn import functional as Ftorch.manual_seed(42)# 定義全連接神經網絡模型
class MyFcnn(nn.Module):def __init__(self, input_size):# 父類初始化super(MyFcnn, self).__init__()# 定義線性層1self.fc1 = nn.Linear(input_size, 64)# 初始化w權重nn.init.kaiming_uniform_(self.fc1.weight)# 初始化b偏置nn.init.zeros_(self.fc1.bias)# 定義線性層2,輸入要和第一層的輸出一致self.fc2 = nn.Linear(64, 32)# 初始化w權重nn.init.kaiming_uniform_(self.fc2.weight)# 初始化b偏置nn.init.zeros_(self.fc2.bias)# 定義線性層3,輸入要和第二層的輸出一致self.fc3 = nn.Linear(32, 1)# 初始化w權重nn.init.xavier_uniform_(self.fc3.weight)# 初始化b偏置nn.init.zeros_(self.fc3.bias)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = F.sigmoid(self.fc3(x))return x# 初始化模型
input_size = 10
model = MyFcnn(input_size)
print(model)
# 定義損失函數
criterion = nn.BCELoss()
# 定義優化器
optimizer = optim.Adam(model.parameters(), lr=0.01)# 訓練模型
def train():model.train()# 數據準備# 100個樣本,每個樣本10個特征x = torch.randn(100, input_size)# 隨機生成二分類標簽y = torch.randint(0, 2, (100, 1)).float()# 迭代次數epochs = 10for epoch in range(epochs):# 前向傳播y_pred = model(x)# 計算損失loss = criterion(y_pred, y)# 梯度清零optimizer.zero_grad()# 反向傳播loss.backward()# 更新梯度optimizer.step()# 打印訓練信息print(f"Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}")# 模型驗證
X_test = torch.randn(20, input_size) # 20個測試樣本
y_test = torch.randint(0, 2, (20, 1)).float() # 測試標簽def eval():model.eval()with torch.no_grad():y_pred = model(X_test)y_pred = (y_pred > 0.5).float()accuracy = (y_pred == y_test).float().mean().item()print(f"Test Accuracy: {accuracy:.4f}")if __name__ == '__main__':train()eval()
三、 激活函數
激活函數的作用是在隱藏層引入非線性,使得神經網絡能夠學習和表示復雜的函數關系,使網絡具備非線性能力,增強其表達能力。
1. 基礎概念
通過認識線性和非線性的基礎概念,深刻理解激活函數存在的價值。
1.1 線性理解
如果在隱藏層不使用激活函數,那么整個神經網絡會表現為一個線性模型。我們可以通過數學推導來展示這一點。
假設:
- 神經網絡有 L L L 層,每層的輸出為 a ( l ) \mathbf{a}^{(l)} a(l)。
- 每層的權重矩陣為 W ( l ) \mathbf{W}^{(l)} W(l),偏置向量為 b ( l ) \mathbf{b}^{(l)} b(l)。
- 輸入數據為 x \mathbf{x} x,輸出為 a ( L ) \mathbf{a}^{(L)} a(L)。
一層網絡的情況
對于單層網絡(輸入層到輸出層),如果沒有激活函數,輸出 a ( 1 ) \mathbf{a}^{(1)} a(1) 可以表示為:
a ( 1 ) = W ( 1 ) x + b ( 1 ) \mathbf{a}^{(1)} = \mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)} a(1)=W(1)x+b(1)
兩層網絡的情況
假設我們有兩層網絡,且每層都沒有激活函數,則:
- 第一層的輸出: a ( 1 ) = W ( 1 ) x + b ( 1 ) \mathbf{a}^{(1)} = \mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)} a(1)=W(1)x+b(1)
- 第二層的輸出: a ( 2 ) = W ( 2 ) a ( 1 ) + b ( 2 ) \mathbf{a}^{(2)} = \mathbf{W}^{(2)} \mathbf{a}^{(1)} + \mathbf{b}^{(2)} a(2)=W(2)a(1)+b(2)
將 a ( 1 ) \mathbf{a}^{(1)} a(1)代入到 a ( 2 ) \mathbf{a}^{(2)} a(2)中,可以得到:
a ( 2 ) = W ( 2 ) ( W ( 1 ) x + b ( 1 ) ) + b ( 2 ) \mathbf{a}^{(2)} = \mathbf{W}^{(2)} (\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}) + \mathbf{b}^{(2)} a(2)=W(2)(W(1)x+b(1))+b(2)
a ( 2 ) = W ( 2 ) W ( 1 ) x + W ( 2 ) b ( 1 ) + b ( 2 ) \mathbf{a}^{(2)} = \mathbf{W}^{(2)} \mathbf{W}^{(1)} \mathbf{x} + \mathbf{W}^{(2)} \mathbf{b}^{(1)} + \mathbf{b}^{(2)} a(2)=W(2)W(1)x+W(2)b(1)+b(2)
我們可以看到,輸出 a ( 2 ) \mathbf{a}^{(2)} a(2)是輸入 x \mathbf{x} x的線性變換,因為: a ( 2 ) = W ′ x + b ′ \mathbf{a}^{(2)} = \mathbf{W}' \mathbf{x} + \mathbf{b}' a(2)=W′x+b′
其中 W ′ = W ( 2 ) W ( 1 ) \mathbf{W}' = \mathbf{W}^{(2)} \mathbf{W}^{(1)} W′=W(2)W(1), b ′ = W ( 2 ) b ( 1 ) + b ( 2 ) \mathbf{b}' = \mathbf{W}^{(2)} \mathbf{b}^{(1)} + \mathbf{b}^{(2)} b′=W(2)b(1)+b(2)。
多層網絡的情況
如果有 L L L層,每層都沒有激活函數,則第 l l l層的輸出為: a ( l ) = W ( l ) a ( l ? 1 ) + b ( l ) \mathbf{a}^{(l)} = \mathbf{W}^{(l)} \mathbf{a}^{(l-1)} + \mathbf{b}^{(l)} a(l)=W(l)a(l?1)+b(l)
通過遞歸代入,可以得到:
a ( L ) = W ( L ) W ( L ? 1 ) ? W ( 1 ) x + W ( L ) W ( L ? 1 ) ? W ( 2 ) b ( 1 ) + W ( L ) W ( L ? 1 ) ? W ( 3 ) b ( 2 ) + ? + b ( L ) \mathbf{a}^{(L)} = \mathbf{W}^{(L)} \mathbf{W}^{(L-1)} \cdots \mathbf{W}^{(1)} \mathbf{x} + \mathbf{W}^{(L)} \mathbf{W}^{(L-1)} \cdots \mathbf{W}^{(2)} \mathbf{b}^{(1)} + \mathbf{W}^{(L)} \mathbf{W}^{(L-1)} \cdots \mathbf{W}^{(3)} \mathbf{b}^{(2)} + \cdots + \mathbf{b}^{(L)} a(L)=W(L)W(L?1)?W(1)x+W(L)W(L?1)?W(2)b(1)+W(L)W(L?1)?W(3)b(2)+?+b(L)
表達式可簡化為:
a ( L ) = W ′ ′ x + b ′ ′ \mathbf{a}^{(L)} = \mathbf{W}'' \mathbf{x} + \mathbf{b}'' a(L)=W′′x+b′′
其中, W ′ ′ \mathbf{W}'' W′′ 是所有權重矩陣的乘積, b ′ ′ \mathbf{b}'' b′′是所有偏置項的線性組合。
如此可以看得出來,無論網絡多少層,意味著:
整個網絡就是線性模型,無法捕捉數據中的非線性關系。
激活函數是引入非線性特性、使神經網絡能夠處理復雜問題的關鍵。
1.2 非線性可視化
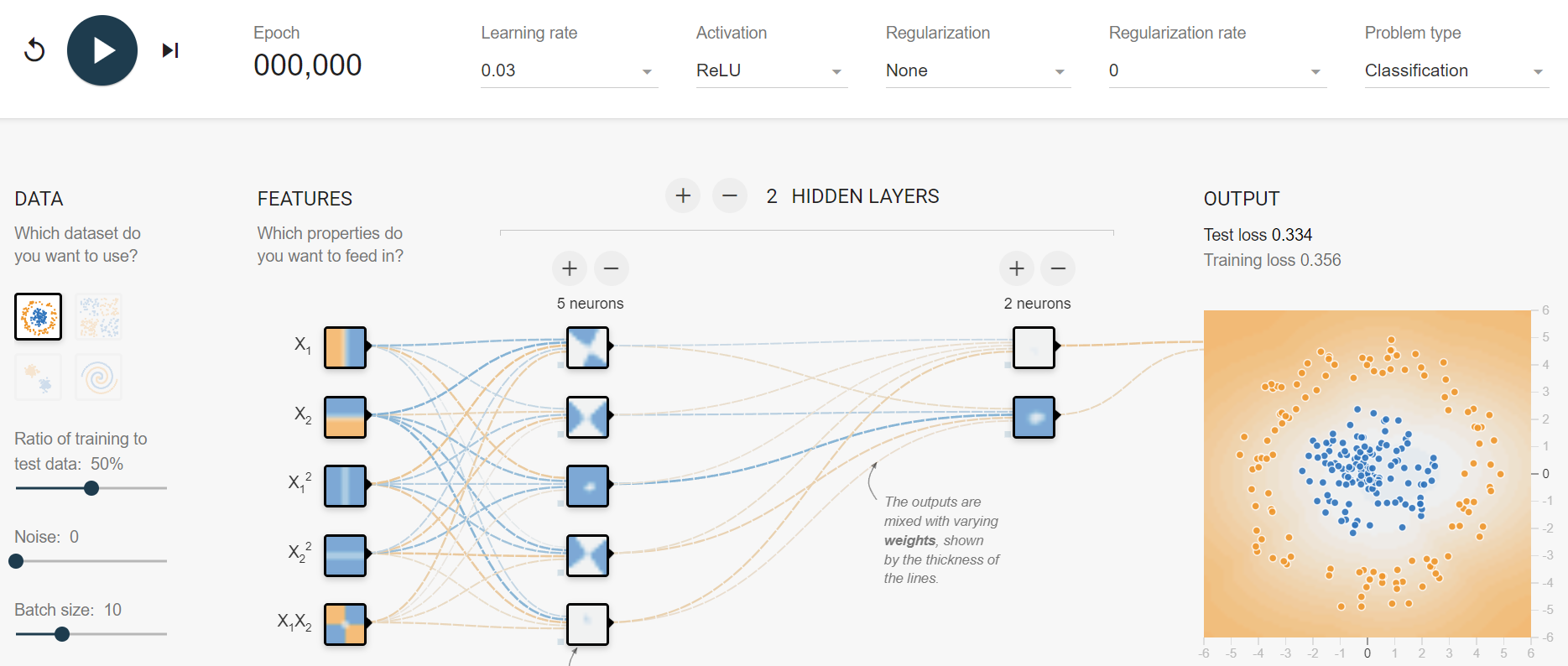
我們可以通過可視化的方式去理解非線性的擬合能力:https://playground.tensorflow.org/
2. 常見激活函數
激活函數通過引入非線性來增強神經網絡的表達能力,對于解決線性模型的局限性至關重要。由于反向傳播算法(BP)用于更新網絡參數,因此激活函數必須是可微的,也就是說能夠求導的。
2.1 sigmoid
Sigmoid激活函數是一種常見的非線性激活函數,特別是在早期神經網絡中應用廣泛。它將輸入映射到0到1之間的值,因此非常適合處理概率問題。
2.1.1 公式
Sigmoid函數的數學表達式為:
f ( x ) = σ ( x ) = 1 1 + e ? x f(x) = \sigma(x) = \frac{1}{1 + e^{-x}} f(x)=σ(x)=1+e?x1?
其中, e e e 是自然常數(約等于2.718), x x x 是輸入。
2.1.2 特征
-
將任意實數輸入映射到 (0, 1)之間,因此非常適合處理概率場景。
-
sigmoid函數一般只用于二分類的輸出層。
-
微分性質: 導數計算比較方便,可以用自身表達式來表示:
σ ′ ( x ) = σ ( x ) ? ( 1 ? σ ( x ) ) \sigma'(x)=\sigma(x)\cdot(1-\sigma(x)) σ′(x)=σ(x)?(1?σ(x))
2.1.3 缺點
- 梯度消失:
- 在輸入非常大或非常小時,Sigmoid函數的梯度會變得非常小,接近于0。這導致在反向傳播過程中,梯度逐漸衰減。
- 最終使得早期層的權重更新非常緩慢,進而導致訓練速度變慢甚至停滯。
- 信息丟失:輸入100和輸入10000經過sigmoid的激活值幾乎都是等于 1 的,但是輸入的數據卻相差 100 倍。
- 計算成本高: 由于涉及指數運算,Sigmoid的計算比ReLU等函數更復雜,盡管差異并不顯著。
2.1.4 函數繪制
通過代碼實現函數和導函數繪制:
import torch
import matplotlib.pyplot as plt# plt支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test001():# 一行兩列繪制圖像_, ax = plt.subplots(1, 2)# 繪制函數圖像x = torch.linspace(-10, 10, 100)y = torch.sigmoid(x)# 網格ax[0].grid(True)ax[0].set_title("sigmoid 函數曲線圖")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 在第一行第一列繪制sigmoid函數曲線圖ax[0].plot(x, y)# 繪制sigmoid導數曲線圖x = torch.linspace(-10, 10, 100, requires_grad=True)# y = torch.sigmoid(x) * (1 - torch.sigmoid(x))# 自動求導torch.sigmoid(x).sum().backward()ax[1].grid(True)ax[1].set_title("sigmoid 函數導數曲線圖", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("y")# ax[1].plot(x.detach().numpy(), y.detach())# 用自動求導的結果繪制曲線圖ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())# 設置曲線顏色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test001()2.2 tanh
tanh(雙曲正切)是一種常見的非線性激活函數,常用于神經網絡的隱藏層。tanh 函數也是一種S形曲線,輸出范圍為 ( ? 1 , 1 ) (?1,1) (?1,1)。
2.2.1 公式
tanh數學表達式為:
t a n h ( x ) = e x ? e ? x e x + e ? x {tanh}(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e?xex?e?x?
2.2.2 特征
-
輸出范圍: 將輸入映射到 ( ? 1 , 1 ) (-1, 1) (?1,1)之間,因此輸出是零中心的。相比于Sigmoid函數,這種零中心化的輸出有助于加速收斂。
-
對稱性: Tanh函數是關于原點對稱的奇函數,因此在輸入為0時,輸出也為0。這種對稱性有助于在訓練神經網絡時使數據更平衡。
-
平滑性: Tanh函數在整個輸入范圍內都是連續且可微的,這使其非常適合于使用梯度下降法進行優化。
d d x tanh ( x ) = 1 ? tanh 2 ( x ) \frac{d}{dx} \text{tanh}(x) = 1 - \text{tanh}^2(x) dxd?tanh(x)=1?tanh2(x)
2.2.3 缺點
- 梯度消失: 雖然一定程度上改善了梯度消失問題,但在輸入值非常大或非常小時導數還是非常小,這在深層網絡中仍然是個問題。這是因為每一層的梯度都會乘以一個小于1的值,經過多層乘積后,梯度會變得非常小,導致訓練過程變得非常緩慢,甚至無法收斂。
- 計算成本: 由于涉及指數運算,Tanh的計算成本還是略高,盡管差異不大。
2.2.4 函數繪制
繪制代碼:
import torch
import matplotlib.pyplot as plt# plt支持中文
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test001():# 一行兩列繪制圖像_, ax = plt.subplots(1, 2)# 繪制函數圖像x = torch.linspace(-10, 10, 100)y = torch.tanh(x)# 網格ax[0].grid(True)ax[0].set_title("tanh 函數曲線圖")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 在第一行第一列繪制tanh函數曲線圖ax[0].plot(x, y)# 繪制tanh導數曲線圖x = torch.linspace(-10, 10, 100, requires_grad=True)# y = torch.tanh(x) * (1 - torch.tanh(x))# 自動求導:需要標量才能反向傳播torch.tanh(x).sum().backward()ax[1].grid(True)ax[1].set_title("tanh 函數導數曲線圖", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")# ax[1].plot(x.detach().numpy(), y.detach())# 用自動求導的結果繪制曲線圖ax[1].plot(x.detach().numpy(), x.grad.detach().numpy())# 設置曲線顏色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test001()2.3 ReLU
ReLU(Rectified Linear Unit)是深度學習中最常用的激活函數之一,它的全稱是修正線性單元。ReLU 激活函數的定義非常簡單,但在實踐中效果非常好。
2.3.1 公式
ReLU 函數定義如下:
ReLU ( x ) = max ? ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
即 R e L U ReLU ReLU對輸入 x x x進行非線性變換:
? 當? x > 0 時,ReLU ( x ) = x ? 當? x ≤ 0 時,ReLU ( x ) = 0 \bullet\quad\text{當 }x>0\text{ 時,ReLU}(x)=x\text{}\\\bullet\quad\text{當 }x\leq0\text{ 時,ReLU}(x)=0\text{} ?當?x>0?時,ReLU(x)=x?當?x≤0?時,ReLU(x)=0
2.3.2 特征
-
計算簡單:ReLU 的計算非常簡單,只需要對輸入進行一次比較運算,這在實際應用中大大加速了神經網絡的訓練。
-
ReLU 函數的導數是分段函數:
ReLU ′ ( x ) = { 1 , if? x > 0 0 , if? x ≤ 0 \text{ReLU}'(x)=\begin{cases}1,&\text{if } x>0\\0,&\text{if }x\leq0\end{cases} ReLU′(x)={1,0,?if?x>0if?x≤0? -
緩解梯度消失問題:相比于 Sigmoid 和 Tanh 激活函數,ReLU 在正半區的導數恒為 1,這使得深度神經網絡在訓練過程中可以更好地傳播梯度,不存在飽和問題。
-
稀疏激活:ReLU在輸入小于等于 0 時輸出為 0,這使得 ReLU 可以在神經網絡中引入稀疏性(即一些神經元不被激活),這種稀疏性可以減少網絡中的冗余信息,提高網絡的效率和泛化能力。
2.3.3 缺點
神經元死亡:由于 R e L U ReLU ReLU在 x ≤ 0 x≤0 x≤0時輸出為 0 0 0,如果某個神經元輸入值是負,那么該神經元將永遠不再激活,成為“死亡”神經元。隨著訓練的進行,網絡中可能會出現大量死亡神經元,從而會降低模型的表達能力。
2.3.4 函數繪圖
參考代碼如下:
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 中文問題
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test006():# 輸入數據xx = torch.linspace(-20, 20, 1000)y = F.relu(x)# 繪制一行2列_, ax = plt.subplots(1, 2)ax[0].plot(x.numpy(), y.numpy())# 顯示坐標格子ax[0].grid()ax[0].set_title("relu 激活函數")ax[0].set_xlabel("x")ax[0].set_ylabel("y")# 繪制導數函數x = torch.linspace(-20, 20, 1000, requires_grad=True)F.relu(x).sum().backward()ax[1].plot(x.detach().numpy(), x.grad.numpy())ax[1].grid()ax[1].set_title("relu 激活函數導數", color="red")# 設置繪制線色顏色ax[1].lines[0].set_color("red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")plt.show()if __name__ == "__main__":test006()2.4 LeakyReLU
Leaky ReLU是一種對 ReLU 函數的改進,旨在解決 ReLU 的一些缺點,特別是Dying ReLU 問題。Leaky ReLU 通過在輸入為負時引入一個小的負斜率來改善這一問題。
2.4.1 公式
Leaky ReLU 函數的定義如下:
Leaky?ReLU ( x ) = { x , if? x > 0 α x , if? x ≤ 0 \text{Leaky ReLU}(x)=\begin{cases}x,&\text{if } x>0\\\alpha x,&\text{if } x\leq0\end{cases} Leaky?ReLU(x)={x,αx,?if?x>0if?x≤0?
其中, α \alpha α 是一個非常小的常數(如 0.01),它控制負半軸的斜率。這個常數 α \alpha α是一個超參數,可以在訓練過程中可自行進行調整。
2.4.2 特征
- 避免神經元死亡:通過在 x ≤ 0 x\leq 0 x≤0 區域引入一個小的負斜率,這樣即使輸入值小于等于零,Leaky ReLU仍然會有梯度,允許神經元繼續更新權重,避免神經元在訓練過程中完全“死亡”的問題。
- 計算簡單:Leaky ReLU 的計算與 ReLU 相似,只需簡單的比較和線性運算,計算開銷低。
2.4.3 缺點
- 參數選擇: α \alpha α 是一個需要調整的超參數,選擇合適的 α \alpha α 值可能需要實驗和調優。
- 出現負激活:如果 α \alpha α 設定得不當,仍然可能導致激活值過低。
2.4.4 函數繪制
參考代碼:
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt# 中文設置
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef test006():x = torch.linspace(-5, 5, 200)# 設置leaky_relu的負斜率超參數slope = 0.03y = F.leaky_relu(x, slope)# 一行兩列_, ax = plt.subplots(1, 2)# 開始繪制函數曲線圖ax[0].plot(x, y)ax[0].set_title("Leaky ReLU 函數曲線圖")ax[0].set_xlabel("x")ax[0].set_ylabel("y")ax[0].grid(True)# 繪制leaky_relu的梯度曲線圖x = torch.linspace(-5, 5, 200, requires_grad=True)F.leaky_relu(x, slope).sum().backward()ax[1].plot(x.detach().numpy(), x.grad)ax[1].set_title("Leaky ReLU 梯度曲線圖", color="red")ax[1].set_xlabel("x")ax[1].set_ylabel("x.grad")ax[1].grid(True)# 設置線的顏色ax[1].lines[0].set_color("red")plt.show()if __name__ == "__main__":test006()2.5 softmax
Softmax激活函數通常用于分類問題的輸出層,它能夠將網絡的輸出轉換為概率分布,使得輸出的各個類別的概率之和為 1。Softmax 特別適合用于多分類問題。
2.5.1 公式
假設神經網絡的輸出層有 n n n個節點,每個節點的輸入為 z i z_i zi?,則 Softmax 函數的定義如下:
S o f t m a x ( z i ) = e z i ∑ j = 1 n e z j \mathrm{Softmax}(z_i)=\frac{e^{z_i}}{\sum_{j=1}^ne^{z_j}} Softmax(zi?)=∑j=1n?ezj?ezi??
給定輸入向量 z = [ z 1 , z 2 , … , z n ] z=[z_1,z_2,…,z_n] z=[z1?,z2?,…,zn?]
1.指數變換:對每個 z i z_i zi?進行指數變換,得到 t = [ e z 1 , e z 2 , . . . , e z n ] t = [e^{z_1},e^{z_2},...,e^{z_n}] t=[ez1?,ez2?,...,ezn?],使z的取值區間從 ( ? ∞ , + ∞ ) (-\infty,+\infty) (?∞,+∞)變為 ( 0 , + ∞ ) (0,+\infty) (0,+∞)
2.將所有指數變換后的值求和,得到 s = e z 1 + e z 2 + . . . + e z n = Σ j = 1 n e z j s = e^{z_1} + e^{z_2} + ... + e^{z_n} = \Sigma_{j=1}^ne^{z_j} s=ez1?+ez2?+...+ezn?=Σj=1n?ezj?
3.將t中每個 e z i e^{z_i} ezi?除以歸一化因子s,得到概率分布:
s o f t m a x ( z ) = [ e z 1 s , e z 2 s , . . . , e z n s ] = [ e z 1 Σ j = 1 n e z j , e z 2 Σ j = 1 n e z j , . . . , e z n Σ j = 1 n e z j ] softmax(z) =[\frac{e^{z_1}}{s},\frac{e^{z_2}}{s},...,\frac{e^{z_n}}{s}]=[\frac{e^{z_1}}{\Sigma_{j=1}^ne^{z_j}},\frac{e^{z_2}}{\Sigma_{j=1}^ne^{z_j}},...,\frac{e^{z_n}}{\Sigma_{j=1}^ne^{z_j}}] softmax(z)=[sez1??,sez2??,...,sezn??]=[Σj=1n?ezj?ez1??,Σj=1n?ezj?ez2??,...,Σj=1n?ezj?ezn??]
即:
S o f t m a x ( z i ) = e z i ∑ j = 1 n e z j \mathrm{Softmax}(z_i)=\frac{e^{z_i}}{\sum_{j=1}^ne^{z_j}} Softmax(zi?)=∑j=1n?ezj?ezi??
從上述公式可以看出:
-
每個輸出值在 (0,1)之間
-
Softmax()對向量的值做了改變,但其位置不變
-
所有輸出值之和為1,即
s u m ( s o f t m a x ( z ) ) = e z 1 s + e z 2 s + . . . + e z n s = s s = 1 sum(softmax(z)) =\frac{e^{z_1}}{s}+\frac{e^{z_2}}{s}+...+\frac{e^{z_n}}{s}=\frac{s}{s}=1 sum(softmax(z))=sez1??+sez2??+...+sezn??=ss?=1
2.5.2 特征
-
將輸出轉化為概率:通過 S o f t m a x Softmax Softmax,可以將網絡的原始輸出轉化為各個類別的概率,從而可以根據這些概率進行分類決策。
-
概率分布: S o f t m a x Softmax Softmax的輸出是一個概率分布,即每個輸出值 Softmax ( z i ) \text{Softmax}(z_i) Softmax(zi?)都是一個介于 0 0 0和 1 1 1之間的數,并且所有輸出值的和為 1:
∑ i = 1 n Softmax ( z i ) = 1 \sum_{i=1}^n\text{Softmax}(z_i)=1 i=1∑n?Softmax(zi?)=1 -
突出差異: S o f t m a x Softmax Softmax會放大差異,使得概率最大的類別的輸出值更接近 1 1 1,而其他類別更接近 0 0 0。
-
在實際應用中, S o f t m a x Softmax Softmax常與交叉熵損失函數Cross-Entropy Loss結合使用,用于多分類問題。在反向傳播中, S o f t m a x Softmax Softmax的導數計算是必需的。
設? p i = S o f t m a x ( z i ) ,則對于? z i 的導數為: ? 當? i = j 時: ? p i ? z i = e z i ( Σ j = 1 n e z j ) ? e z i e z i ( Σ j = 1 n e z j ) 2 = p i ( 1 ? p i ) ? 當? i ≠ j 時 : ? p i ? z j = 0 ( Σ j = 1 n e z j ) ? e z i e z j ( Σ j = 1 n e z j ) 2 = ? p i p j \begin{aligned} &\text{設 }p_i=\mathrm{Softmax}(z_i)\text{,則對于 }z_i\text{ 的導數為:} \\ &\bullet\text{ 當 }i=j\text{ 時:} \\ &&&\frac{\partial p_i}{\partial z_i}=\frac{e^{z_i}(\Sigma_{j=1}^ne^{z_j})-e^{z_i}e^{z_i}}{(\Sigma_{j=1}^ne^{z_j})^2}=p_i(1-p_i) \\ & \bullet\text{ 當 }i\neq j\text{ 時}: \\ &&&\frac{\partial p_i}{\partial z_j}=\frac{0(\Sigma_{j=1}^ne^{z_j})-e^{z_i}e^{z_j}}{(\Sigma_{j=1}^ne^{z_j})^2} =-p_{i}p_{j} \end{aligned} ?設?pi?=Softmax(zi?),則對于?zi??的導數為:??當?i=j?時:??當?i=j?時:???zi??pi??=(Σj=1n?ezj?)2ezi?(Σj=1n?ezj?)?ezi?ezi??=pi?(1?pi?)?zj??pi??=(Σj=1n?ezj?)20(Σj=1n?ezj?)?ezi?ezj??=?pi?pj??
2.5.3 缺點
- 數值不穩定性:在計算過程中,如果 z i z_i zi?的數值過大, e z i e^{z_i} ezi?可能會導致數值溢出。因此在實際應用中,經常會對 z i z_i zi?進行調整,如減去最大值以確保數值穩定。
S o f t m a x ( z i ) = e z i ? max ? ( z ) ∑ j = 1 n e z j ? max ? ( z ) \mathrm{Softmax}(z_i)=\frac{e^{z_i-\max(z)}}{\sum_{j=1}^ne^{z_j-\max(z)}} Softmax(zi?)=∑j=1n?ezj??max(z)ezi??max(z)?
解釋:
z i ? max ? ( z ) z_i-\max(z) zi??max(z)是一個非正數,由于 e z i ? m a x ( z ) e^{z_i?max(z)} ezi??max(z) 的形式,當 z i z_i zi? 接近 max(z) 時, e z i ? m a x ( z ) e^{z_i?max(z)} ezi??max(z) 的值會接近 1,而當 z i z_i zi? 遠小于 max(z) 時, e z i ? m a x ( z ) e^{z_i?max(z)} ezi??max(z) 的值會接近 0。這使得 Softmax 函數的輸出中,最大值對應的概率會相對較大,而其他值對應的概率會相對較小,從而提高數值穩定性。
這種調整不會改變 S o f t m a x Softmax Softmax的概率分布結果,因為從數學的角度講相當于分子、分母都除以了 e max ? ( z ) e^{\max(z)} emax(z)。
在 PyTorch 中,torch.nn.functional.softmax 函數就自動處理了數值穩定性問題。
- 難以處理大量類別: S o f t m a x Softmax Softmax在處理類別數非常多的情況下(如大模型中的詞匯表)計算開銷會較大。
2.5.4 代碼實現
代碼參考如下:
import torch
import torch.nn as nn# 表示4分類,每個樣本全連接后得到4個得分,下面示例模擬的是兩個樣本的得分
input_tensor = torch.tensor([[-1.0, 2.0, -3.0, 4.0], [-2, 3, -3, 9]])softmax = nn.Softmax()
output_tensor = softmax(input_tensor)
# 關閉科學計數法
torch.set_printoptions(sci_mode=False)
print("輸入張量:", input_tensor)
print("輸出張量:", output_tensor)輸出結果:
輸入張量: tensor([[-1., 2., -3., 4.],[-2., 3., -3., 9.]])
輸出張量: tensor([[ 0.0059, 0.1184, 0.0008, 0.8749],[ 0.0000, 0.0025, 0.0000, 0.9975]])
3. 如何選擇
更多激活函數可以查看官方文檔:https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
那這么多激活函數應該如何選擇呢?實際沒那么糾結
3.1 隱藏層
- 優先選ReLU;
- 如果ReLU效果不咋地,那么嘗試其他激活,如Leaky ReLU等;
- 使用ReLU時注意神經元死亡問題, 避免出現過多神經元死亡;
- 不使用sigmoid,嘗試使用tanh;
3.2 輸出層
- 二分類問題選擇sigmoid激活函數;
- 多分類問題選擇softmax激活函數

)






——面向對象基本概念、分析設計測試)







)


