PyTorch深度學習框架60天進階學習計劃 - 第45天:神經架構搜索(二)
第二部分:權重共享策略的計算效率優化
8. 權重共享的理論基礎
權重共享策略的理論基礎來自于多任務學習(Multi-Task Learning, MTL)和遷移學習(Transfer Learning)。在MTL中,我們認為不同但相關的任務可以共享知識,從而提高每個任務的性能。同樣,在NAS中,我們可以將不同架構的訓練視為相關任務,它們可以共享某些基本知識(如低層特征提取)。
從數學角度看,權重共享可以表示為一個參數子空間映射函數:
? : A → W \phi: \mathcal{A} \rightarrow \mathcal{W} ?:A→W
其中 A \mathcal{A} A是架構空間, W \mathcal{W} W是權重空間。對于任何架構 a ∈ A a \in \mathcal{A} a∈A,我們可以通過映射 ? ( a ) \phi(a) ?(a)獲得其對應的權重子集。
9. DARTS權重共享的實現
讓我們詳細討論DARTS中權重共享的實現方式:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as npclass Architect:"""負責更新架構參數的類"""def __init__(self, model, args):self.model = modelself.args = args# 僅優化架構參數self.optimizer = optim.Adam(self.model.arch_parameters(),lr=args.arch_learning_rate,betas=(0.5, 0.999),weight_decay=args.arch_weight_decay)def step(self, input_train, target_train, input_valid, target_valid, lr, optimizer):"""執行架構參數優化步驟"""# 在訓練集上計算當前w的一階近似optimizer.zero_grad()logits = self.model(input_train)loss = self.model.criterion(logits, target_train)loss.backward()# 備份當前權重w_optim = optimizerw = [p.data for p in self.model.parameters()]# 虛擬更新wwith torch.no_grad():for p in self.model.parameters():if p.grad is not None:p.data = p.data - lr * p.grad# 在驗證集上更新架構參數self.optimizer.zero_grad()logits = self.model(input_valid)loss = self.model.criterion(logits, target_valid)loss.backward()self.optimizer.step()# 恢復權重with torch.no_grad():for i, p in enumerate(self.model.parameters()):p.data = w[i]class Network(nn.Module):"""DARTS網絡模型"""def __init__(self, C, num_classes, layers, criterion, num_nodes=4):super(Network, self).__init__()self.C = Cself.num_classes = num_classesself.layers = layersself.criterion = criterionself.num_nodes = num_nodes# 定義干細胞網絡self.stem = nn.Sequential(nn.Conv2d(3, C, 3, padding=1, bias=False),nn.BatchNorm2d(C))# 定義cellsself.cells = nn.ModuleList()C_prev, C_curr = C, Cfor i in range(layers):# 每隔layers//3層進行下采樣if i in [layers//3, 2*layers//3]:C_curr *= 2reduction = Trueelse:reduction = Falsecell = DARTSCell(C_prev, C_curr, reduction, num_nodes)self.cells.append(cell)C_prev = C_curr * num_nodes# 全局池化和分類器self.global_pooling = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Linear(C_prev, num_classes)# 初始化架構參數self._initialize_alphas()def _initialize_alphas(self):"""初始化架構參數"""num_ops = 6 # 候選操作數量k = sum(1 for i in range(self.num_nodes) for j in range(i+2)) # 每個cell中的邊數# 普通cell的架構參數self.alphas_normal = nn.Parameter(1e-3 * torch.randn(k, num_ops))# 降維cell的架構參數self.alphas_reduce = nn.Parameter(1e-3 * torch.randn(k, num_ops))# 注冊架構參數self._arch_parameters = [self.alphas_normal,self.alphas_reduce,]def arch_parameters(self):"""返回架構參數"""return self._arch_parametersdef forward(self, x):"""前向傳播"""# 干細胞網絡處理s0 = self.stem(x)s1 = s0# 通過所有cellsfor i, cell in enumerate(self.cells):# 根據cell類型選擇架構參數if cell.reduction:weights = F.softmax(self.alphas_reduce, dim=-1)else:weights = F.softmax(self.alphas_normal, dim=-1)s0, s1 = s1, cell(s0, s1, weights)# 全局池化和分類out = self.global_pooling(s1)logits = self.classifier(out.view(out.size(0), -1))return logits# 改進的DARTSCell類,支持降維
class DARTSCell(nn.Module):def __init__(self, C_prev, C, reduction, num_nodes=4):super(DARTSCell, self).__init__()self.reduction = reductionself.num_nodes = num_nodes# 降維時stride=2,否則stride=1stride = 2 if reduction else 1# 預處理輸入self.preprocess0 = nn.Sequential(nn.ReLU(inplace=False),nn.Conv2d(C_prev, C, 1, 1, 0, bias=False),nn.BatchNorm2d(C),)self.preprocess1 = nn.Sequential(nn.ReLU(inplace=False),nn.Conv2d(C_prev, C, 1, 1, 0, bias=False),nn.BatchNorm2d(C),)# 初始化混合操作self._ops = nn.ModuleList()for i in range(self.num_nodes):for j in range(i+2): # 每個節點連接前面所有節點op = MixedOp(C, stride if j < 2 else 1)self._ops.append(op)def forward(self, s0, s1, weights):# 預處理s0 = self.preprocess0(s0)s1 = self.preprocess1(s1)# 連接初始狀態states = [s0, s1]offset = 0# 對每個中間節點進行計算for i in range(self.num_nodes):s = sum(self._ops[offset+j](h, weights[offset+j]) for j, h in enumerate(states))offset += len(states)states.append(s)# 連接所有中間節點作為輸出return torch.cat(states[-self.num_nodes:], dim=1)
10. 權重共享的計算效率分析
讓我們分析DARTS中權重共享帶來的計算效率提升:
-
搜索空間大小:假設有N個節點,每個節點有M種可能的操作,則總共有M^N種可能的架構。
-
傳統NAS方法:需要單獨訓練每個架構,總計算量約為O(M^N * T),其中T是訓練單個模型的時間。
-
DARTS方法:只需訓練一個超網絡,計算量約為O(M * N * T’),其中T’是訓練超網絡的時間。
對于典型的搜索空間(M=8, N=10),加速比可達到10^8量級!
下面是一個實際計算效率的對比表:
| 搜索方法 | 計算效率(GPU天) | 獲得的模型性能(CIFAR-10準確率) | 相對傳統NAS的加速比 |
|---|---|---|---|
| 強化學習NAS | 1800 | 96.35% | 1x |
| 進化算法NAS | 3150 | 96.15% | 0.57x |
| ENAS(早期權重共享) | 0.45 | 96.13% | 4000x |
| DARTS | 1.5 | 97.24% | 1200x |
| PC-DARTS(改進DARTS) | 0.1 | 97.43% | 18000x |
11. 完整DARTS訓練示例
下面是一個完整的DARTS訓練示例代碼:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoaderdef main():# 參數設置args = type('Args', (), {'epochs': 50,'batch_size': 64,'learning_rate': 0.025,'momentum': 0.9,'weight_decay': 3e-4,'arch_learning_rate': 3e-4,'arch_weight_decay': 1e-3,'init_channels': 16,'layers': 8,'num_nodes': 4,'grad_clip': 5})()# 數據加載transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])train_data = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)# 劃分訓練集和驗證集num_train = len(train_data)indices = list(range(num_train))split = int(num_train * 0.5)train_indices, valid_indices = indices[:split], indices[split:]train_queue = DataLoader(train_data, batch_size=args.batch_size,sampler=torch.utils.data.sampler.SubsetRandomSampler(train_indices))valid_queue = DataLoader(train_data, batch_size=args.batch_size,sampler=torch.utils.data.sampler.SubsetRandomSampler(valid_indices))# 創建模型criterion = nn.CrossEntropyLoss()model = Network(args.init_channels, 10, args.layers, criterion, args.num_nodes)model = model.cuda()# 創建優化器optimizer = optim.SGD(model.parameters(),args.learning_rate,momentum=args.momentum,weight_decay=args.weight_decay)# 創建架構優化器architect = Architect(model, args)# 訓練循環for epoch in range(args.epochs):# 調整學習率lr = args.learning_rate * (0.5 ** (epoch // 30))for param_group in optimizer.param_groups:param_group['lr'] = lr# 訓練train_darts(train_queue, valid_queue, model, architect, criterion, optimizer, lr, args)# 驗證valid_acc = infer(valid_queue, model, criterion)print(f'Epoch {epoch}: validation accuracy = {valid_acc:.2f}%')# 獲取最終架構genotype = model.genotype()print(f'Final architecture: {genotype}')def train_darts(train_queue, valid_queue, model, architect, criterion, optimizer, lr, args):"""DARTS訓練過程"""model.train()for step, (x, target) in enumerate(train_queue):x, target = x.cuda(), target.cuda(non_blocking=True)# 獲取驗證批次try:x_valid, target_valid = next(valid_queue_iter)except:valid_queue_iter = iter(valid_queue)x_valid, target_valid = next(valid_queue_iter)x_valid, target_valid = x_valid.cuda(), target_valid.cuda(non_blocking=True)# 更新架構參數architect.step(x, target, x_valid, target_valid, lr, optimizer)# 更新權重參數optimizer.zero_grad()logits = model(x)loss = criterion(logits, target)# 計算準確率prec1 = accuracy(logits, target)# 反向傳播和梯度更新loss.backward()nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)optimizer.step()if step % 50 == 0:print(f'Step {step}: loss = {loss.item():.4f}, accuracy = {prec1:.2f}%')def infer(valid_queue, model, criterion):"""驗證模型性能"""model.eval()total_loss = 0total_correct = 0total = 0with torch.no_grad():for x, target in valid_queue:x, target = x.cuda(), target.cuda(non_blocking=True)logits = model(x)loss = criterion(logits, target)_, predicted = logits.max(1)total_correct += predicted.eq(target).sum().item()total += target.size(0)total_loss += loss.item() * target.size(0)return 100 * total_correct / totaldef accuracy(output, target, topk=(1,)):"""計算top-k準確率"""maxk = max(topk)batch_size = target.size(0)_, pred = output.topk(maxk, 1, True, True)pred = pred.t()correct = pred.eq(target.view(1, -1).expand_as(pred))res = []for k in topk:correct_k = correct[:k].reshape(-1).float().sum(0)res.append(correct_k.mul_(100.0 / batch_size))return res[0]if __name__ == '__main__':main()
12. 權重共享優化技巧
通過實踐,研究者們發現了一些優化DARTS權重共享策略的技巧:
-
部分通道連接(Partial Channel Connection, PC):在PC-DARTS中,只使用輸入通道的一部分來計算架構梯度,減少內存占用。
-
操作級Dropout:隨機丟棄某些操作,減少超網絡的過擬合問題。
-
漸進式通道增長:從小通道數開始訓練,逐步增加通道數,加速收斂過程。
-
正則化技術:防止架構權重坍塌到單一操作上。
讓我們實現其中的部分通道連接技術:
class PCMixedOp(nn.Module):"""部分通道混合操作"""def __init__(self, C, stride, k=4):super(PCMixedOp, self).__init__()self._ops = nn.ModuleList()self.k = k # 采樣比例,例如k=4表示每次采樣1/4的通道self.C = Cfor op_name in PRIMITIVES:op = OPS[op_name](C, stride, False)self._ops.append(op)def forward(self, x, weights):# 通道維度采樣channel_dim = 1 # PyTorch的通道維度為1# 隨機選擇通道索引channels = x.shape[channel_dim]channels_per_group = channels // self.k# 生成隨機索引indices = torch.randperm(channels)[:channels_per_group]indices, _ = torch.sort(indices)# 選擇通道子集x_sampled = x[:, indices, :, :]# 計算正常大小的maskchannel_mask = torch.zeros(1, channels, 1, 1).cuda()channel_mask[:, indices, :, :] = 1# 混合操作output = sum(w * op(x_sampled) for w, op in zip(weights, self._ops))# 縮放回原始大小scale_factor = self.koutput = output * scale_factor# 合并回原始tensoroutput = output * channel_mask + x * (1 - channel_mask)return output
13. 解決權重共享中的架構坍塌問題
DARTS及其權重共享策略的一個主要挑戰是"架構坍塌"問題——架構參數往往會集中在少數幾個操作上,尤其是skip-connection操作,導致生成的網絡性能下降。
研究者提出了多種解決方案:
-
早停法(Early Stopping):在架構參數收斂但尚未坍塌前停止搜索。
-
正則化方法:對架構參數添加正則化約束,防止其過度集中。
-
修正搜索空間:如在P-DARTS中逐步刪除Skip-Connection操作。
-
梯度約束:限制架構梯度的magnitude,防止某些操作的梯度主導訓練過程。
下面是一個添加正則化的例子:
def train_darts_with_regularization(train_queue, valid_queue, model, architect, criterion, optimizer, lr, args):"""帶正則化的DARTS訓練過程"""model.train()for step, (x, target) in enumerate(train_queue):x, target = x.cuda(), target.cuda(non_blocking=True)# 獲取驗證批次try:x_valid, target_valid = next(valid_queue_iter)except:valid_queue_iter = iter(valid_queue)x_valid, target_valid = next(valid_queue_iter)x_valid, target_valid = x_valid.cuda(), target_valid.cuda(non_blocking=True)# 更新架構參數architect.step_with_regularization(x, target, x_valid, target_valid, lr, optimizer)# 更新權重參數optimizer.zero_grad()logits = model(x)loss = criterion(logits, target)loss.backward()nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)optimizer.step()if step % 50 == 0:print(f'Step {step}: loss = {loss.item():.4f}')class ArchitectWithRegularization(Architect):"""帶正則化的架構優化器"""def step_with_regularization(self, input_train, target_train, input_valid, target_valid, lr, optimizer):"""帶正則化的架構參數優化步驟"""# 在訓練集上計算當前w的一階近似optimizer.zero_grad()logits = self.model(input_train)loss = self.model.criterion(logits, target_train)loss.backward()# 備份當前權重w_optim = optimizerw = [p.data for p in self.model.parameters()]# 虛擬更新wwith torch.no_grad():for p in self.model.parameters():if p.grad is not None:p.data = p.data - lr * p.grad# 在驗證集上更新架構參數self.optimizer.zero_grad()logits = self.model(input_valid)loss = self.model.criterion(logits, target_valid)# 添加正則化項# 計算架構參數熵來鼓勵多樣性alpha_normal = F.softmax(self.model.alphas_normal, dim=-1)alpha_reduce = F.softmax(self.model.alphas_reduce, dim=-1)entropy_reg = -(alpha_normal * torch.log(alpha_normal + 1e-8)).sum() \-(alpha_reduce * torch.log(alpha_reduce + 1e-8)).sum()# 最大化熵,鼓勵多樣性reg_strength = 0.2 # 正則化強度超參數loss = loss - reg_strength * entropy_regloss.backward()self.optimizer.step()# 恢復權重with torch.no_grad():for i, p in enumerate(self.model.parameters()):p.data = w[i]
14. DARTS的搜索與評估分離
DARTS訓練過程分為搜索和評估兩個階段。搜索階段使用較小的網絡和數據集,而評估階段則基于搜索結果構建完整網絡。這種分離策略能夠進一步提高計算效率。
下面是搜索與評估分離的流程圖:
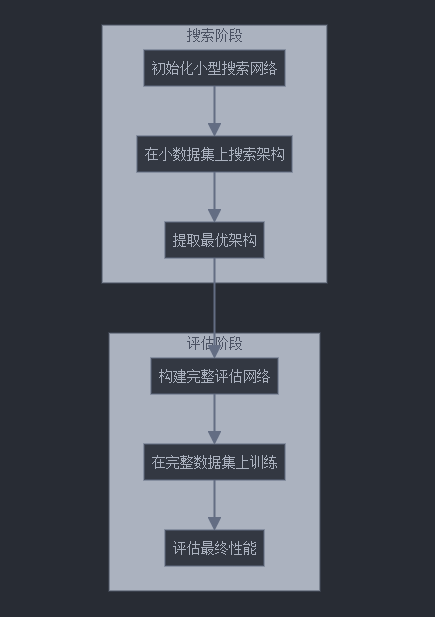
15. 從搜索到評估的代碼實現
下面是從架構搜索到最終評估的完整代碼實現:
def extract_genotype(model):"""從DARTS模型中提取基因型"""def _parse(weights):gene = []n = 2 # 每個節點兩個輸入邊start = 0for i in range(model.num_nodes):# 獲取權重最高的n條邊及其對應操作end = start + i + 2edges = sorted(range(start, end), key=lambda x: -max(weights[x][op] for op in range(len(PRIMITIVES)) if PRIMITIVES[op] != 'none'))[:n]# 獲取每條邊上權重最高的操作for j in edges:k_best = Nonefor k in range(len(PRIMITIVES)):if k_best is None or weights[j][k] > weights[j][k_best]:k_best = kgene.append((PRIMITIVES[k_best], j - start))start = endreturn gene# 提取普通cell和降維cell的基因型gene_normal = _parse(F.softmax(model.alphas_normal, dim=-1).data.cpu().numpy())gene_reduce = _parse(F.softmax(model.alphas_reduce, dim=-1).data.cpu().numpy())# 構建完整基因型concat = list(range(2, 2 + model.num_nodes)) # 連接所有中間節點return Genotype(normal=gene_normal, normal_concat=concat,reduce=gene_reduce, reduce_concat=concat)def build_evaluation_model(genotype, C, num_classes, layers, auxiliary=True):"""構建用于評估的模型"""return NetworkEvaluation(C, num_classes, layers, auxiliary, genotype)class NetworkEvaluation(nn.Module):"""用于評估的網絡模型"""def __init__(self, C, num_classes, layers, auxiliary, genotype):super(NetworkEvaluation, self).__init__()self._layers = layersself._auxiliary = auxiliary# 干細胞網絡stem_multiplier = 3C_curr = stem_multiplier * Cself.stem = nn.Sequential(nn.Conv2d(3, C_curr, 3, padding=1, bias=False),nn.BatchNorm2d(C_curr))# 定義cellsC_prev_prev, C_prev, C_curr = C_curr, C_curr, Cself.cells = nn.ModuleList()reduction_prev = Falsefor i in range(layers):# 每隔layers//3層進行下采樣if i in [layers//3, 2*layers//3]:C_curr *= 2reduction = Trueelse:reduction = False# 根據genotype構建cellcell = Cell(genotype, C_prev_prev, C_prev, C_curr, reduction, reduction_prev)self.cells.append(cell)reduction_prev = reductionC_prev_prev, C_prev = C_prev, cell.multiplier * C_curr# 輔助分類器if i == 2*layers//3 and auxiliary:C_to_auxiliary = C_prevself.auxiliary_head = AuxiliaryHeadCIFAR(C_to_auxiliary, num_classes)# 全局池化和分類器self.global_pooling = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Linear(C_prev, num_classes)def forward(self, x):s0 = s1 = self.stem(x)# 輔助分類器輸出logits_aux = None# 通過所有cellsfor i, cell in enumerate(self.cells):s0, s1 = s1, cell(s0, s1)# 使用輔助分類器if i == 2*self._layers//3 and self.training and self._auxiliary:logits_aux = self.auxiliary_head(s1)# 全局池化和分類out = self.global_pooling(s1)logits = self.classifier(out.view(out.size(0), -1))# 如果訓練且有輔助分類器,返回兩個logitsif self.training and self._auxiliary and logits_aux is not None:return logits, logits_auxelse:return logitsclass Cell(nn.Module):"""基于genotype構建的cell"""def __init__(self, genotype, C_prev_prev, C_prev, C, reduction, reduction_prev):super(Cell, self).__init__()self.reduction = reduction# 處理前一個cell的輸出if reduction_prev:self.preprocess0 = FactorizedReduce(C_prev_prev, C)else:self.preprocess0 = ReLUConvBN(C_prev_prev, C, 1, 1, 0)self.preprocess1 = ReLUConvBN(C_prev, C, 1, 1, 0)# 根據genotype構建操作if reduction:op_names, indices = zip(*genotype.reduce)concat = genotype.reduce_concatelse:op_names, indices = zip(*genotype.normal)concat = genotype.normal_concatself.multiplier = len(concat)self._compile(C, op_names, indices, concat, reduction)def _compile(self, C, op_names, indices, concat, reduction):assert len(op_names) == len(indices)self._steps = len(op_names) // 2self._concat = concatself.multiplier = len(concat)self._ops = nn.ModuleList()for name, index in zip(op_names, indices):stride = 2 if reduction and index < 2 else 1op = OPS[name](C, stride, True)self._ops.append(op)self._indices = indicesdef forward(self, s0, s1):s0 = self.preprocess0(s0)s1 = self.preprocess1(s1)states = [s0, s1]# 按照genotype構建計算圖for i in range(self._steps):h1 = states[self._indices[2*i]]h2 = states[self._indices[2*i+1]]op1 = self._ops[2*i]op2 = self._ops[2*i+1]h1 = op1(h1)h2 = op2(h2)s = h1 + h2states.append(s)# 連接指定節點作為輸出return torch.cat([states[i] for i in self._concat], dim=1)def main_evaluation():"""主評估函數"""# 加載搜索到的最優架構genotype = load_genotype('best_architecture.pt')# 構建評估模型model = build_evaluation_model(genotype=genotype,C=36, # 初始通道數num_classes=10, # CIFAR-10layers=20, # 層數auxiliary=True # 使用輔助分類器)model = model.cuda()# 數據加載train_transform, valid_transform = _data_transforms_cifar10()train_data = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)valid_data = datasets.CIFAR10(root='./data', train=False, download=True, transform=valid_transform)train_queue = DataLoader(train_data, batch_size=96, shuffle=True, pin_memory=True)valid_queue = DataLoader(valid_data, batch_size=96, shuffle=False, pin_memory=True)# 定義損失函數和優化器criterion = nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(),0.025, # 學習率momentum=0.9,weight_decay=3e-4)scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, args.epochs)# 訓練循環best_acc = 0.0for epoch in range(args.epochs):# 訓練train_acc, train_loss = train(train_queue, model, criterion, optimizer)scheduler.step()# 驗證valid_acc, valid_loss = validate(valid_queue, model, criterion)# 保存最佳模型if valid_acc > best_acc:best_acc = valid_acctorch.save(model.state_dict(), 'best_model.pt')print(f'Epoch {epoch}: train_acc={train_acc:.2f}%, valid_acc={valid_acc:.2f}%')
16. 權重共享和批量歸一化
在實現DARTS和權重共享時,批量歸一化(Batch Normalization, BN)層需要特別關注。由于在搜索過程中多種操作共享同一批數據,但在最終網絡中只會選擇其中一種操作,這可能導致BN統計量的偏差。
有幾種策略可以解決這個問題:
-
操作級BN:為每個操作單獨設置BN層,避免統計量混合。
-
路徑級BN:根據不同的架構路徑使用不同的BN統計量。
-
重置BN統計量:在搜索結束后,使用最終架構重新計算BN統計量。
下面是一個操作級BN的示例代碼:
class SepConvWithBN(nn.Module):"""帶有獨立BN的可分離卷積"""def __init__(self, C_in, C_out, kernel_size, stride, padding):super(SepConvWithBN, self).__init__()self.op = nn.Sequential(nn.ReLU(inplace=False),nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, groups=C_in, bias=False),nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),nn.BatchNorm2d(C_out, affine=True, track_running_stats=True), # 操作級BNnn.ReLU(inplace=False),nn.Conv2d(C_out, C_out, kernel_size=kernel_size, stride=1, padding=padding, groups=C_out, bias=False),nn.Conv2d(C_out, C_out, kernel_size=1, padding=0, bias=False),nn.BatchNorm2d(C_out, affine=True, track_running_stats=True), # 操作級BN)def forward(self, x):return self.op(x)
17. DARTS的實際應用與評估結果
DARTS方法已被應用于多個計算機視覺和自然語言處理任務,并取得了顯著成果。下面是一些實際結果:
| 任務 | 數據集 | DARTS性能 | 手工設計最佳模型性能 | 計算資源(GPU天) |
|---|---|---|---|---|
| 圖像分類 | CIFAR-10 | 97.24% | 96.54% | 1.5 |
| 圖像分類 | ImageNet | 73.3% | 74.2% | 4.0 |
| 語言建模 | Penn Treebank | 55.7 perplexity | 57.3 perplexity | 0.5 |
| 語義分割 | Cityscapes | 72.8% mIoU | 71.9% mIoU | 2.0 |
總結來說,DARTS通過權重共享策略成功地在有限計算資源下發現了高性能的神經網絡架構,極大地推動了神經架構搜索的發展。
18. 結論與未來發展
DARTS的可微分搜索空間和權重共享策略為神經架構搜索提供了一個高效且有效的解決方案。通過將離散的架構選擇轉化為連續的優化問題,DARTS大大降低了計算成本,并提高了搜索效率。
然而,DARTS也面臨一些挑戰,如架構坍塌、搜索偏好簡單操作以及在更大搜索空間中的擴展性問題。未來的研究方向包括:
- 更穩定的可微分架構搜索方法
- 更高效的權重共享策略
- 適用于更多任務的搜索空間設計
- 與其他自動化機器學習技術的結合
清華大學全五版的《DeepSeek教程》完整的文檔需要的朋友,關注我私信:deepseek 即可獲得。
怎么樣今天的內容還滿意嗎?再次感謝朋友們的觀看,關注GZH:凡人的AI工具箱,回復666,送您價值199的AI大禮包。最后,祝您早日實現財務自由,還請給個贊,謝謝!






——面向對象基本概念、分析設計測試)







)



及案例)
