本文:關注 檢索器與上下文的子鏈、父鏈;即檢索器也需要上下文內容。
RAG是一種增強LLM知識的方法,通過引入額外的數據來實現。
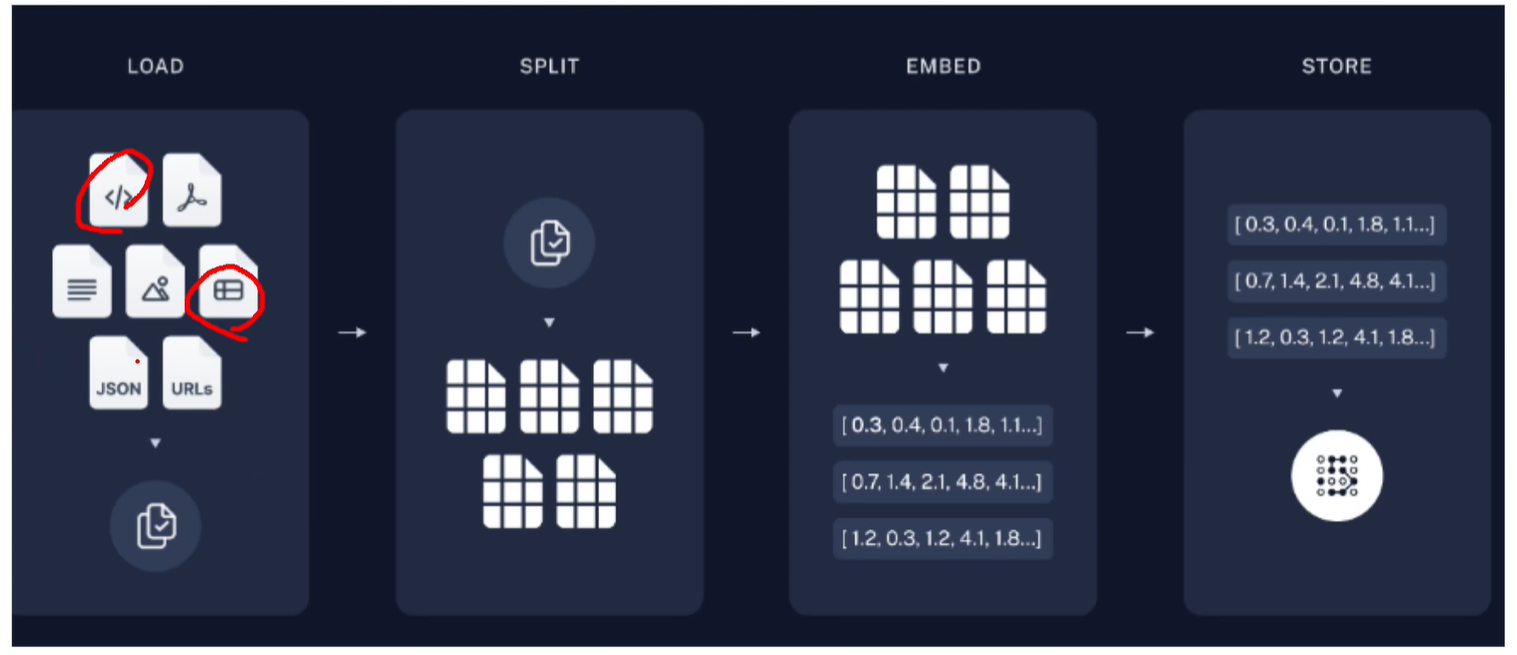
實現思路:加載—》分割—》存儲—》檢索—》生成。

初始化
import os import bs4 from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains.history_aware_retriever import create_history_aware_retriever from langchain.chains.retrieval import create_retrieval_chain from langchain_chroma import Chroma from langchain_community.document_loaders import WebBaseLoader from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from langchain_core.runnables import RunnableWithMessageHistory from langchain_text_splitters import RecursiveCharacterTextSplitter from langchain_community.chat_message_histories import ChatMessageHistory from langchain_openai import ChatOpenAI, OpenAIEmbeddingsos.environ['http_proxy'] = '127.0.0.1:7890' os.environ['https_proxy'] = '127.0.0.1:7890'os.environ["LANGCHAIN_TRACING_V2"] = "true" os.environ["LANGCHAIN_PROJECT"] = "LangchainDemo" os.environ["LANGCHAIN_API_KEY"] = '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' # os.environ["TAVILY_API_KEY"] = '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'# 聊天機器人案例 # 創建模型 model = ChatOpenAI(model='gpt-4-turbo')
加載數據
通過angchain_community..document_loaders import WebBaseLoader加載博客內容數據
返回一個Document列表,每個Document包含web元數據(metadata)、內容(page_content);
##?angchain_community.包含大量工具。
#WebBaseLoader 相當于一個爬蟲,可以爬取多個網頁。
# Beautiful Soup的SoupStrainer用于解析HTML文檔時僅提取特定(class_)的部分
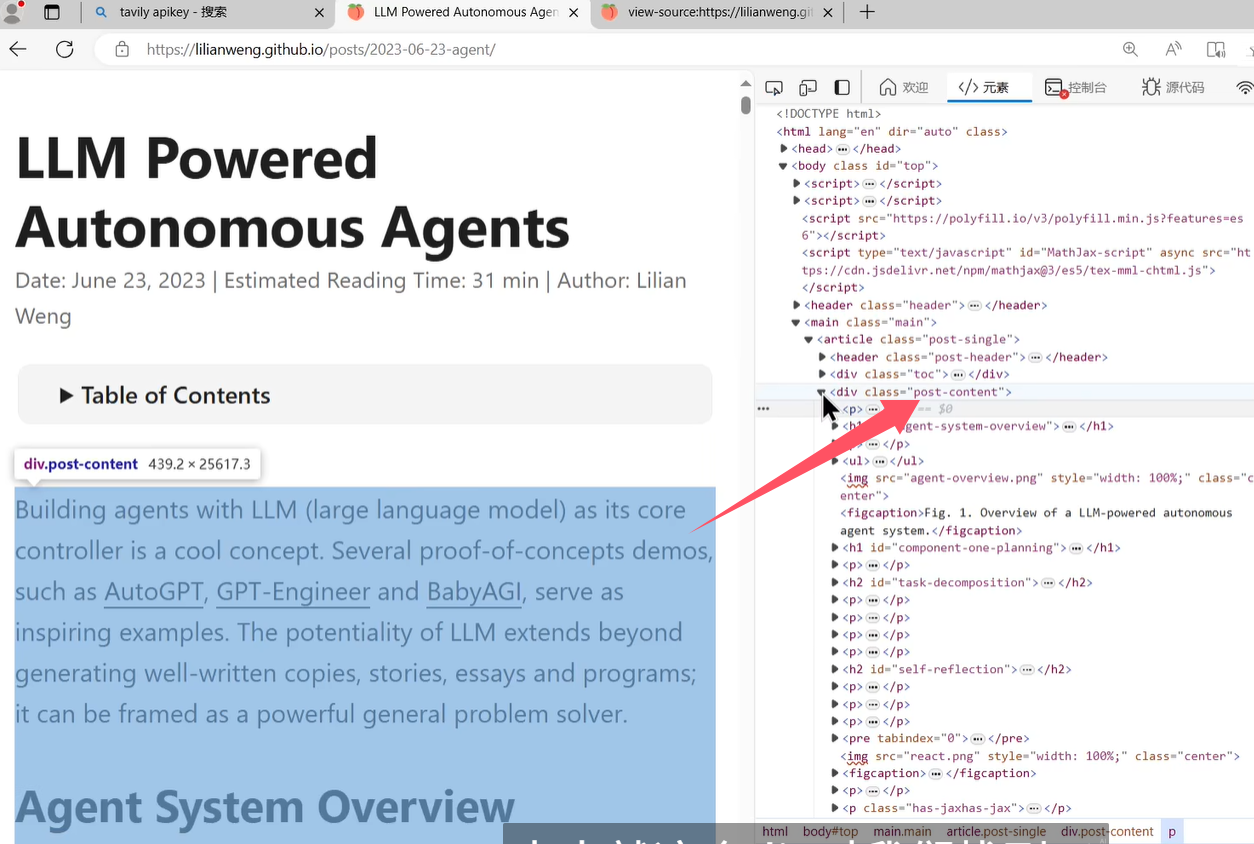
# 1、加載數據: 一篇博客內容數據 loader = WebBaseLoader(web_paths=['https://lilianweng.github.io/posts/2023-06-23-agent/'],bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=('post-header', 'post-title', 'post-content'))) )docs = loader.load()# print(len(docs)) # print(docs)




切割
可以看到,上述Document的內容非常大;因此要進行切割。
# from langchain_text_splitters import RecursiveCharacterTextSplitter
##?chunk_size:分割塊大小;chunk_overlap:允許重復字符(保證語句完整性)
# splitter包含多種切割,還有split_text:切割string、bytes
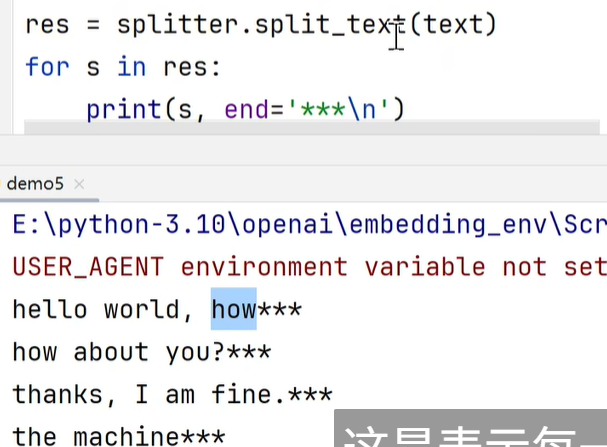
# 2、大文本的切割 # text = "hello world, how about you? thanks, I am fine. the machine learning class. So what I wanna do today is just spend a little time going over the logistics of the class, and then we'll start to talk a bit about machine learning" splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = splitter.split_documents(docs)test示例
#可以看到第一塊,和第二塊末尾都有how。第一塊 how因補充chunk_size;第二塊how因語序完整性及chunk_overlap而存在。
存儲與檢索
# 根據切割結果,創建向量數據庫
# 2、存儲 vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())# 檢索器
# 3、檢索器 retriever = vectorstore.as_retriever()
創建Prompt和chain
# 創PromptTemplate:系統定位、聊天歷史、用戶輸入。
# 創 chain:create_stuff_documents_chain(model, prompt) :創建多文本的chain
# 創建一個問題的模板 system_prompt = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, say that you don't know. Use three sentences maximum and keep the answer concise.\n{context} """ prompt = ChatPromptTemplate.from_messages( # 提問和回答的 歷史記錄 模板[("system", system_prompt),MessagesPlaceholder("chat_history"), #("human", "{input}"),] )chain1 = create_stuff_documents_chain(model, prompt)# 下述測試,因為沒有 chat_history,因此會報錯。 ### 將檢索器和已有chain鏈接 # chain2 = create_retrieval_chain(retriever, chain1)# resp = chain2.invoke({'input': "What is Task Decomposition?"}) ### resp包含多個key,只取answer。 # print(resp['answer'])
子鏈-歷史記錄
'''注意:
一般情況下,我們構建的鏈(chain)直接使用輸入問答記錄來關聯上下文。但在此案例中,查詢檢索器也需要 對話上下文 才能被理解。
#解決辦法:
添加一個子鏈(chain),它采用最新用戶問題和聊天歷史,并在它引用歷史信息中的任何信息時重新表述問題。這可以被簡單地認為是構建一個新的“歷史感知”檢索器。
這個子鏈的目的:讓檢索過程融入了對話的上下文。#eg:HumanMessage:它的方法有哪些;這里的‘?它?’即需要結合上下文,才能理解。”
# 子鏈提示詞模板:重新定義子鏈AI的定位(根據用戶新問題和上下文,分析并返回最新真實問題)。
##create_history_aware_retriever(模型、檢索器、子鏈Prompt):用于創建一種??能夠感知對話歷史??的檢索器(Retriever)。它的核心作用是讓檢索過程動態結合之前的對話上下文,從而使當前查詢的檢索結果更精準、更相關。
##create_retrieval_chain(history_chain, chain1):整合倆個鏈。
# 創建一個子鏈 # 子鏈的提示模板 contextualize_q_system_prompt = """Given a chat history and the latest user question which might reference context in the chat history, formulate a standalone question which can be understood without the chat history. Do NOT answer the question, just reformulate it if needed and otherwise return it as is."""retriever_history_temp = ChatPromptTemplate.from_messages([('system', contextualize_q_system_prompt),MessagesPlaceholder('chat_history'),("human", "{input}"),] )# 創建一個子鏈 history_chain = create_history_aware_retriever(model, retriever, retriever_history_temp)# 保持問答的歷史記錄 store = {}def get_session_history(session_id: str):if session_id not in store:store[session_id] = ChatMessageHistory()return store[session_id]# 創建父鏈chain: 把前兩個鏈整合 chain = create_retrieval_chain(history_chain, chain1)# 創建攜帶history的Runnable對象 result_chain = RunnableWithMessageHistory(chain,get_session_history,input_messages_key='input',history_messages_key='chat_history',output_messages_key='answer' )1
多輪會話
# 第一輪對話 resp1 = result_chain.invoke({'input': 'What is Task Decomposition?'},config={'configurable': {'session_id': 'zs123456'}} )print(resp1['answer'])# 第二輪對話 resp2 = result_chain.invoke({'input': 'What are common ways of doing it?'},config={'configurable': {'session_id': 'ls123456'}} )print(resp2['answer'])



及案例)
















