??所屬專欄:Linux??
??作者主頁:嶔某??

Linux:線程概念于控制
var code = “d7e241ae-ed4d-475f-aa3d-8d78f873fdca”
概念
在一個程序里的一個執行路線就叫做線程
thread。更準確一點:線程是“一個進程內部的控制序列”一切進程都至少有一個線程
線程在進程內部運行,本質是在進程地址空間運行
在
Linux系統中,在CPU眼中,看到的PCB都要比傳統的要輕量化透過進程虛擬地址空間,可以看到進程的大部分資源,將進程資源合理分配給每個執行流,就形成了線程執行流。
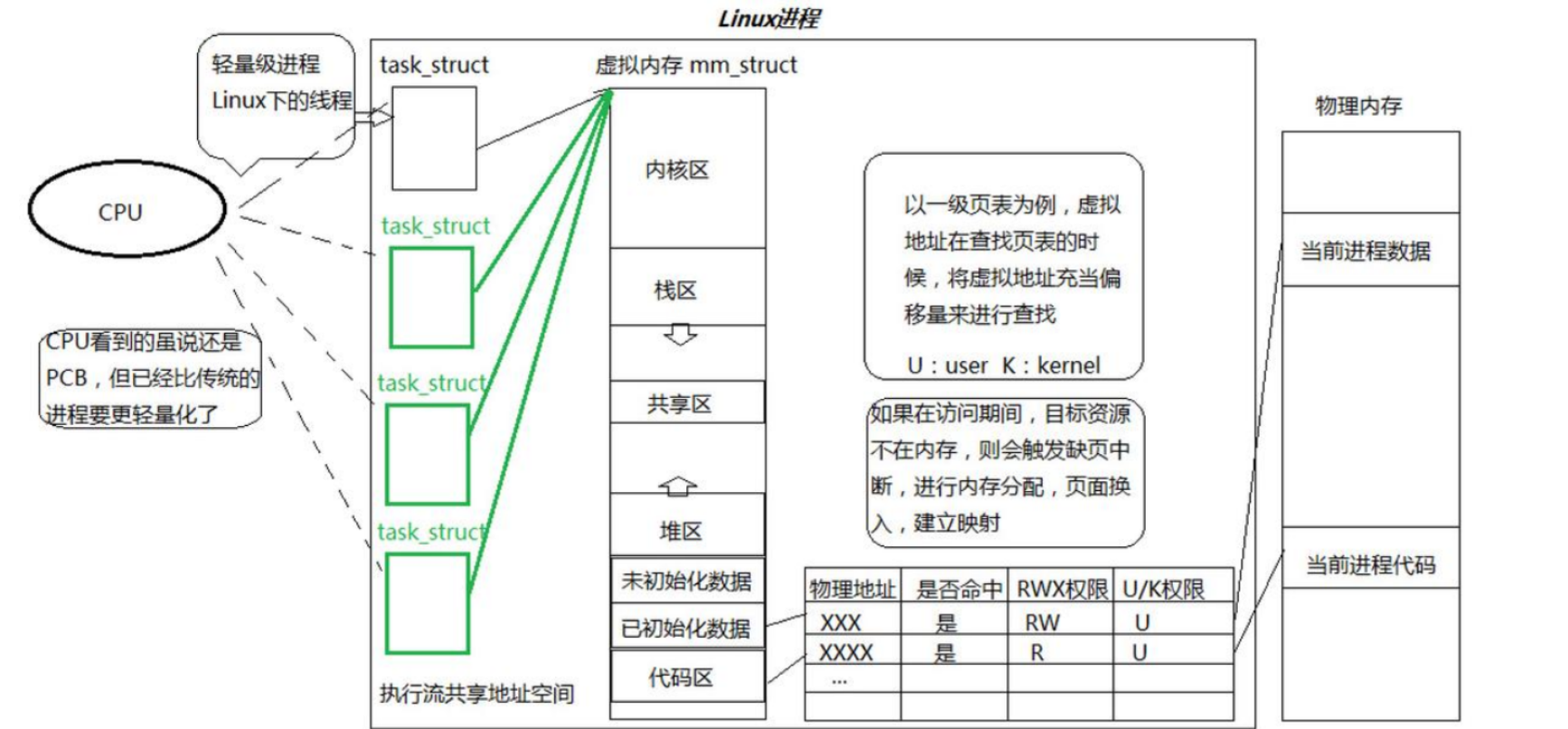
分頁式儲存管理
如果沒有虛擬內存和分頁機制,每一個用戶在物理內存上的空間必須是連續的,如下圖
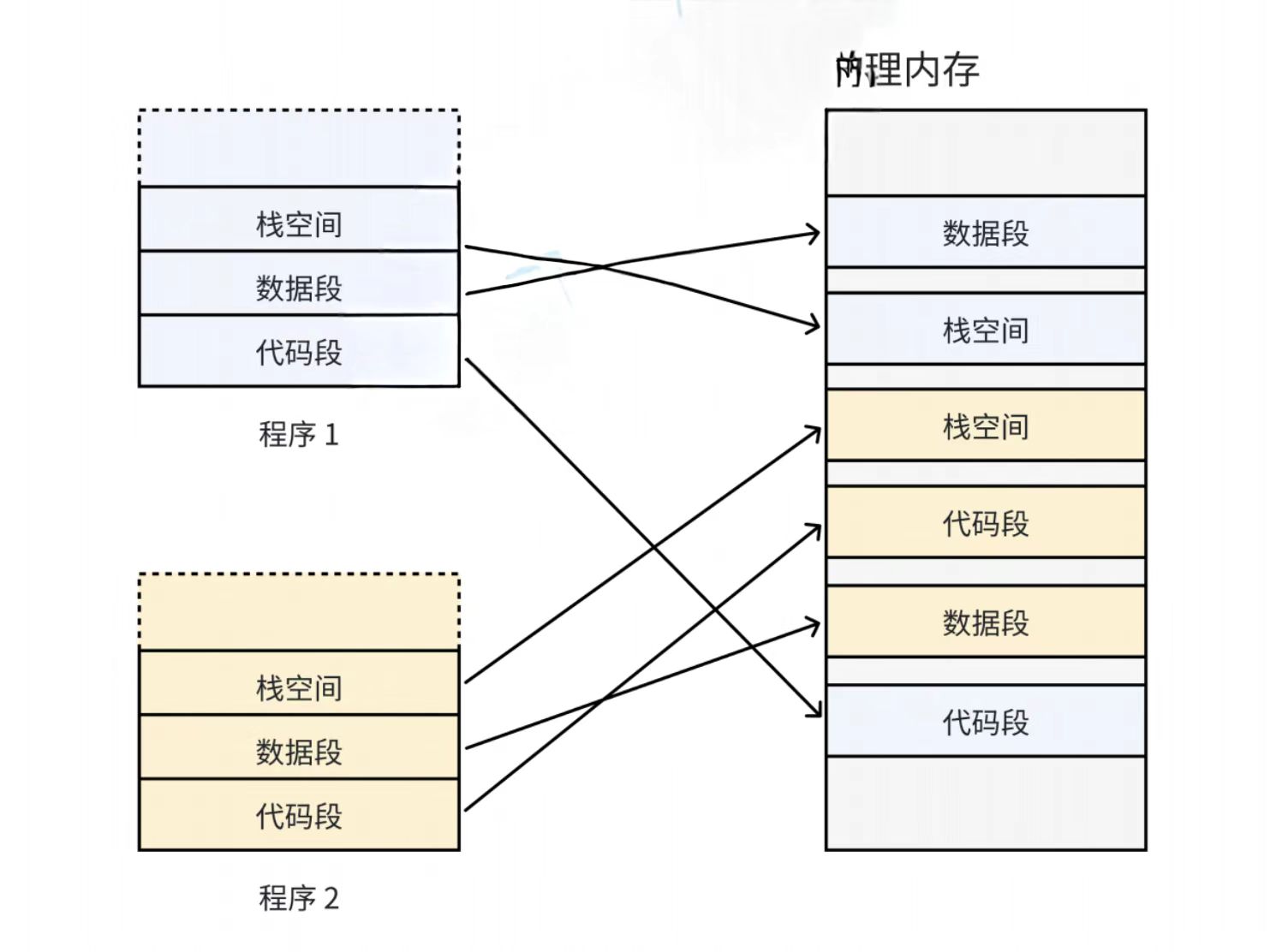
因為每一個程序的代碼、數據長度都是不一樣的,按照這樣的映射方式,物理內存會被分成各種離散的大小不同的塊。有些程序會退出,它們占據的物理內存會被回收,一段時間過后,物理內存就變得非常碎片化,不易管理了。
所以我們希望操作系統給用戶的空間是連續的,但是物理內存最好不要連續,那么虛擬內存和分頁就出現了。
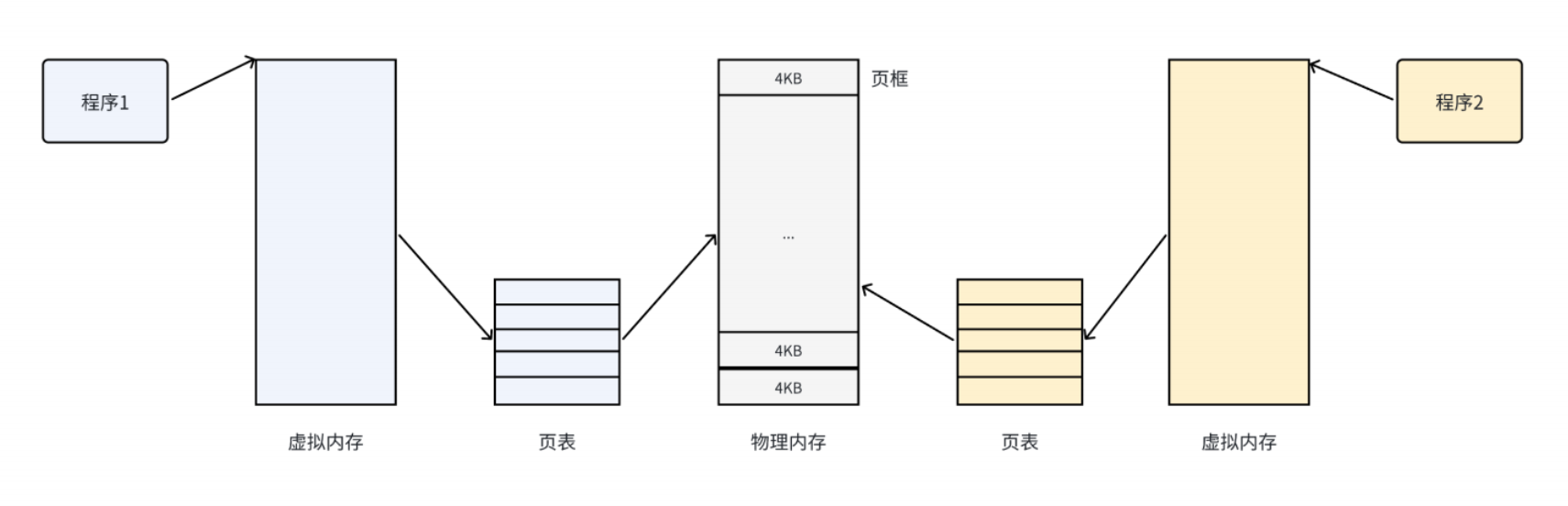
把物理內存按照一個固定的長度頁框進行分割,叫做物理頁。每一個頁框包含一個物理頁page。頁的大小就是頁框的大小。32位機器支持4kb的頁,64位機器支持8kb的頁。
- 頁框是一個儲存區域
- 頁是一個數據塊,可以存放在任何頁框中,或者磁盤中
有了這種機制,CPU并非直接訪問物理地址,而是通過虛擬地址空間來間接的訪問物理內存地址。所謂的虛擬地址空間,是操作系統位每一個在執行的進程分配的一個邏輯地址,32位機器上其范圍為0-4GB。
操作系統通過將虛擬地址空間與物理地址間建立映射關系:頁表,這張表上記錄了每一對頁和頁框的映射關系,能讓CPU間接訪問物理內存地址。
其思想就是**將虛擬內存下的邏輯地址空間分為若干的頁,將物理內存空間分為若干頁框,通過頁表將連續的虛擬內存,映射到若干個不連續的物理內存頁。**這樣就解決了使用連續的物理內存造成的碎片問題。
物理內存管理
假設一個可用的物理內存有4GB的空間。按照一個頁框的大小4KB劃分,4GB的空間就是4GB/4KB = 1048576個頁框。有這么多的物理頁,操作系統肯定是要對它們進行管理的,OS要知道哪些頁被使用,哪些頁在空閑。
Linux內核里面使用了struct page結構描述系統中的每個物理頁,為了節省內存(這個結構體本身也是在內核,也是在內存里面的)這里面使用了大量的聯合體union
/* include/linux/mm_types.h */
struct page
{/* 原?標志,有些情況下會異步更新 */unsigned long flags;union{struct{/* 換出?列表,例如由zone->lru_lock保護的active_list */struct list_head lru;/* 如果最低為為0,則指向inode* address_space,或為NULL* 如果?映射為匿名內存,最低為置位* ?且該指針指向anon_vma對象*/struct address_space *mapping;/* 在映射內的偏移量 */pgoff_t index;/** 由映射私有,不透明數據* 如果設置了PagePrivate,通常?于buffer_heads* 如果設置了PageSwapCache,則?于swp_entry_t* 如果設置了PG_buddy,則?于表?伙伴系統中的階*/unsigned long private;};struct{ /* slab, slob and slub */union{struct list_head slab_list; /* uses lru */struct{ /* Partial pages */struct page *next;
#ifdef CONFIG_64BITint pages; /* Nr of pages left */int pobjects; /* Approximate count */
#elseshort int pages;short int pobjects;
#endif};};struct kmem_cache *slab_cache; /* not slob *//* Double-word boundary */void *freelist; /* first free object */union{void *s_mem; /* slab: first object */unsigned long counters; /* SLUB */struct{ /* SLUB */unsigned inuse : 16; /* ?于SLUB分配器:對象的數? */unsigned objects : 15;unsigned frozen : 1;};};};...};union{/* 內存管理?系統中映射的?表項計數,?于表??是否已經映射,還?于限制逆向映射搜索*/atomic_t _mapcount;unsigned int page_type;unsigned int active; /* SLAB */int units; /* SLOB */};...
#if defined(WANT_PAGE_VIRTUAL)/* 內核虛擬地址(如果沒有映射則為NULL,即?端內存) */void *virtual;
#endif /* WANT_PAGE_VIRTUAL */...
}
重要參數
flags:用來存放頁的狀態。包括是不是臟的,是不是被鎖定在內存中等等。flags的每一位單獨表示一種狀態,所以他至少可以同時表示出32種不同的狀態。這些標志定義在<linux/page-flags.h>中。其中?些比特位非常重要,如PG_locked?于指定頁是否鎖定,PG_uptodate?于表示頁的數據已經從塊設備讀取并且沒有出現錯誤。_mapcount:表示在頁表中有多少項指向該頁,也就是這一頁被引?了多少次。當計數值變為-1時,就說明當前內核并沒有引?這一頁,于是在新的分配中就可以使用它。virtual:是頁的虛擬地址。通常情況下,它就是頁在虛擬內存中的地址。有些內存(即所謂的?端內存)并不永久地映射到內核地址空間上。在這種情況下,這個域的值為NULL,需要的時候,必須動態地映射這些頁。
要注意的是struct page與物理頁相關,?并非與虛擬頁相關。?系統中的每個物理頁都要分配?個這樣的結構體,讓我們來算算對所有這些頁都這么做,到底要消耗掉多少內存。
算struct page占40個字節的內存吧,假定系統的物理頁為 4KB ??,系統有 4GB 物理內存。那么系統中共有頁面 1048576 個(1兆個),所以描述這么多??的page結構體消耗的內存只不過40MB ,相對系統 4GB 內存而言,僅是很小的?部分罷了。因此,要管理系統中這么多物理??,這個代價并不算太大。
要知道的是,頁的大小對于內存利?和系統開銷來說非常重要,頁太大,頁必然會剩余較?不能利?的空間(頁內碎片)。頁太小,雖然可以減小頁內碎片的大小,但是頁太多,會使得頁表太長而占?內存,同時系統頻繁地進行頁轉化,加重系統開銷。因此,頁的大小應該適中,通常為 512B -8KB ,windows系統的頁框大小為4KB。
頁表
頁表中的每一個表項都指向一個物理頁的起始地址。在32位機器上要將4GB的空間全部用頁表指向的話需要4GB/4KB = 1048576個表項。
頁表中的物理地址,和真實的物理頁之間是隨機映射關系,哪里可用就指向哪里。**最終使用的物理內存是離散的,但是虛擬地址是連續的。**處理器在訪問數據、獲取指令都是用的虛擬地址,最終都能通過頁表找到物理地址。
我們可以算一下,在32位機器上,地址長度為4字節,頁表占用的空間為1048576 * 4 = 4MB,映射頁表本身就要消耗4MB / 4KB = 1024個物理頁。每次新起一個進程,都要將這占用了1024個物理頁的頁表加載映射到內存,但是根據局部性原理,一個進程在一段時間內只需要訪問某幾個頁就可以正常運行了。所以根本沒有必要將所有的物理頁都常駐內存。
解決這一問題的方法就是對頁表再次分頁,即多級頁表。
我們將單一的一個頁表再次拆分為1024個更小的映射表。1024(每個表中的表項數)* 1024(表的個數)仍然可以覆蓋4GB的物理內存空間。
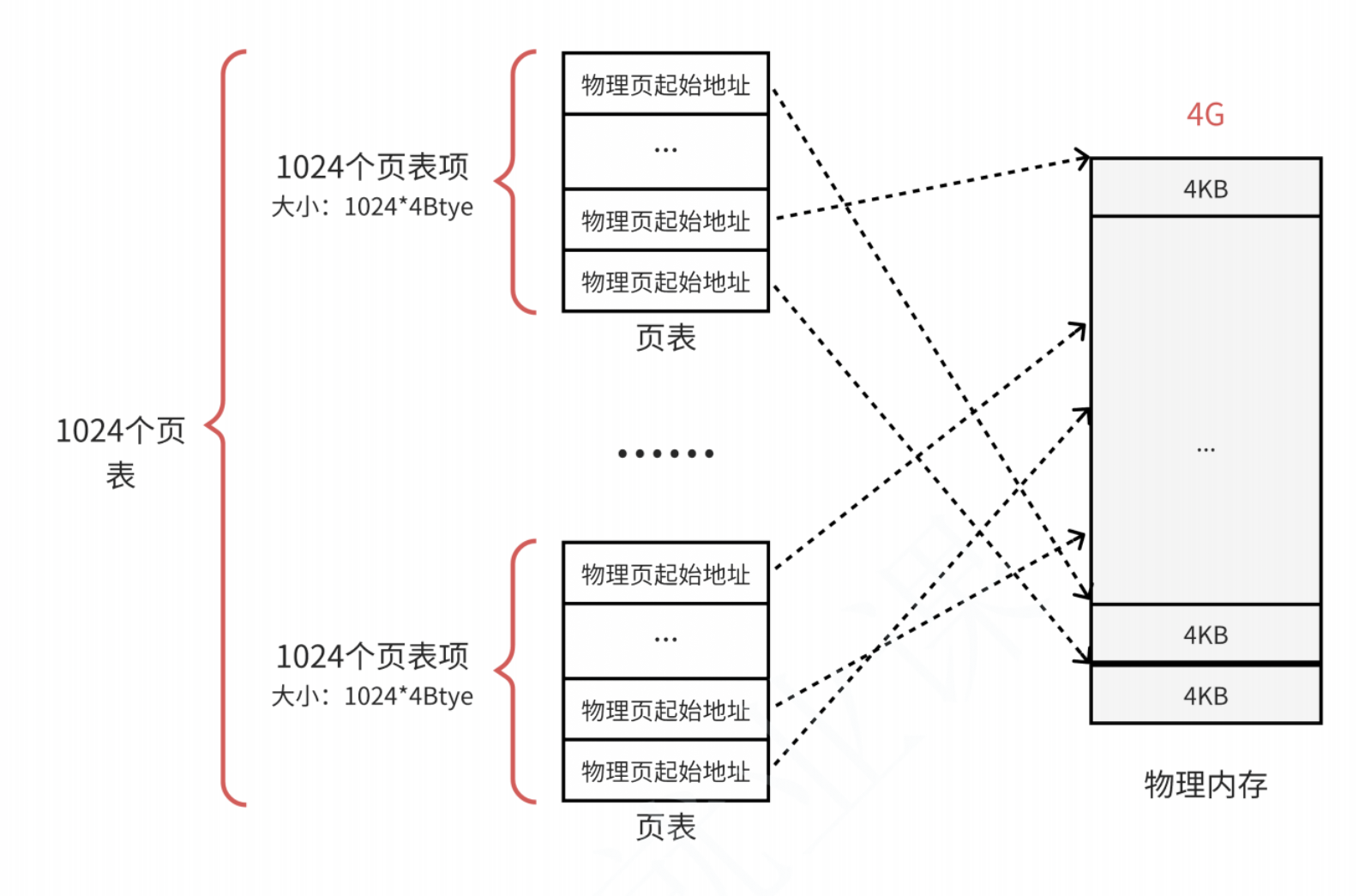
這里的每一個頁表就是真正的頁表了,一共有1024個頁表,一個頁表占用4KB,一共也就是4MB。雖然和之前沒區別,但是一個應用程序不可能把這些頁表全部用完的,這樣設計方便用多少,開多少。例如:一個程序的代碼段、數據段、棧、一共只需要10MB的空間,那么使用3個頁表就夠用了。(一個頁表能覆蓋4MB的物理空間)
頁目錄結構
那么每一個頁框都有一個頁表項來指向,這1024個頁表也需要被管理起來。管理頁表的表稱為頁目錄表,形成了二級頁表:
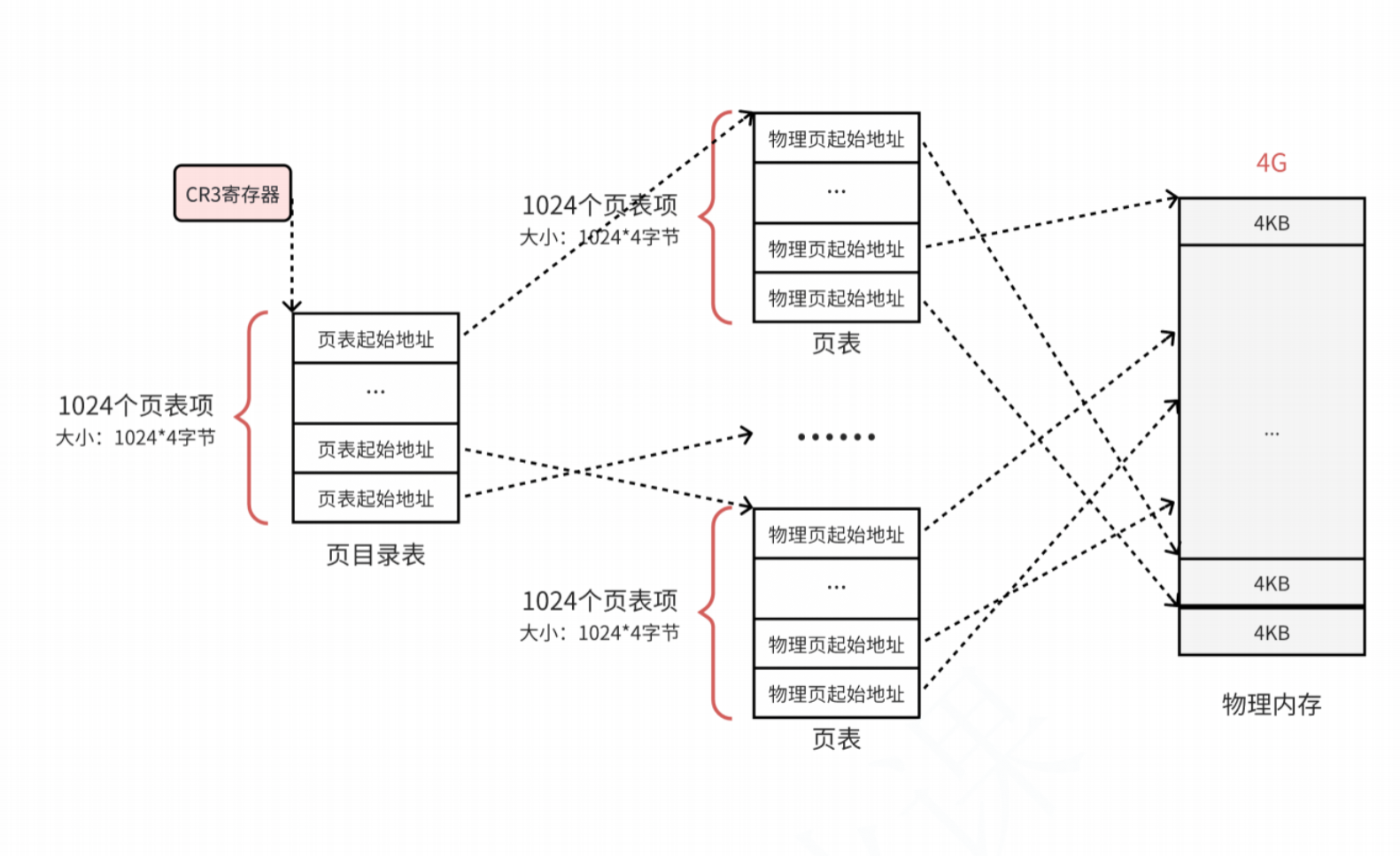
所有頁表的物理地址都被頁目錄表指向
頁目錄的物理地址被
CR3寄存器指向,此寄存器保存了當前正在執行任務的頁目錄地址。
所以在程序被加載的時候,不僅要為程序的內容分配物理內存,還需要為保存程序物理地址和虛擬地址映射的頁目錄和頁表分配物理內存。
兩級頁表的地址轉換
下面以一個邏輯地址為例。將邏輯地址0000000000,0000000001,111111111111轉化為物理地址的過程:
- 在32為處理器中,采用4KB頁大小,則虛擬地址中的低12為為頁偏移,剩下的高20位給頁表分成兩級,每個級占10位。
CR3寄存器讀取頁目錄起始地址,再根據一級頁號查頁目錄表,找到下一級頁表在物理內存中存放位置。- 根據二級頁號查表,找到最終想要訪問的內存塊號。
- 結合頁內偏移量得到物理地址。
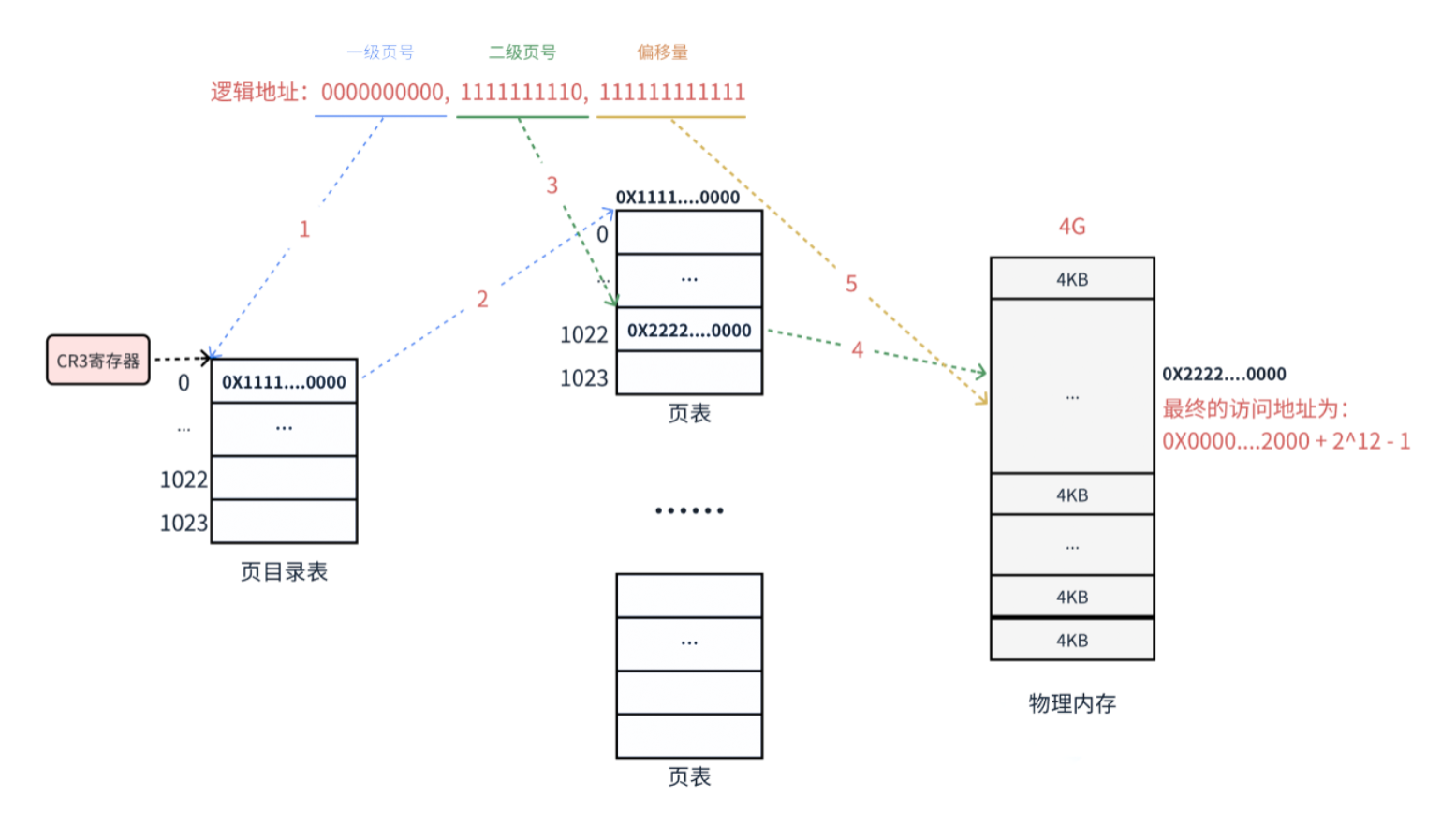
- 一個物理頁的地址,一定是對齊4KB的(最后的12位全為0),所以其實只需要記錄物理頁地址的高20位即可。
- 以上就是
MMU的工作流程,Memory Manage Unit是一種硬件電路,其速度很快,主要工作是做內存管理,地址轉換只是其工作之一。
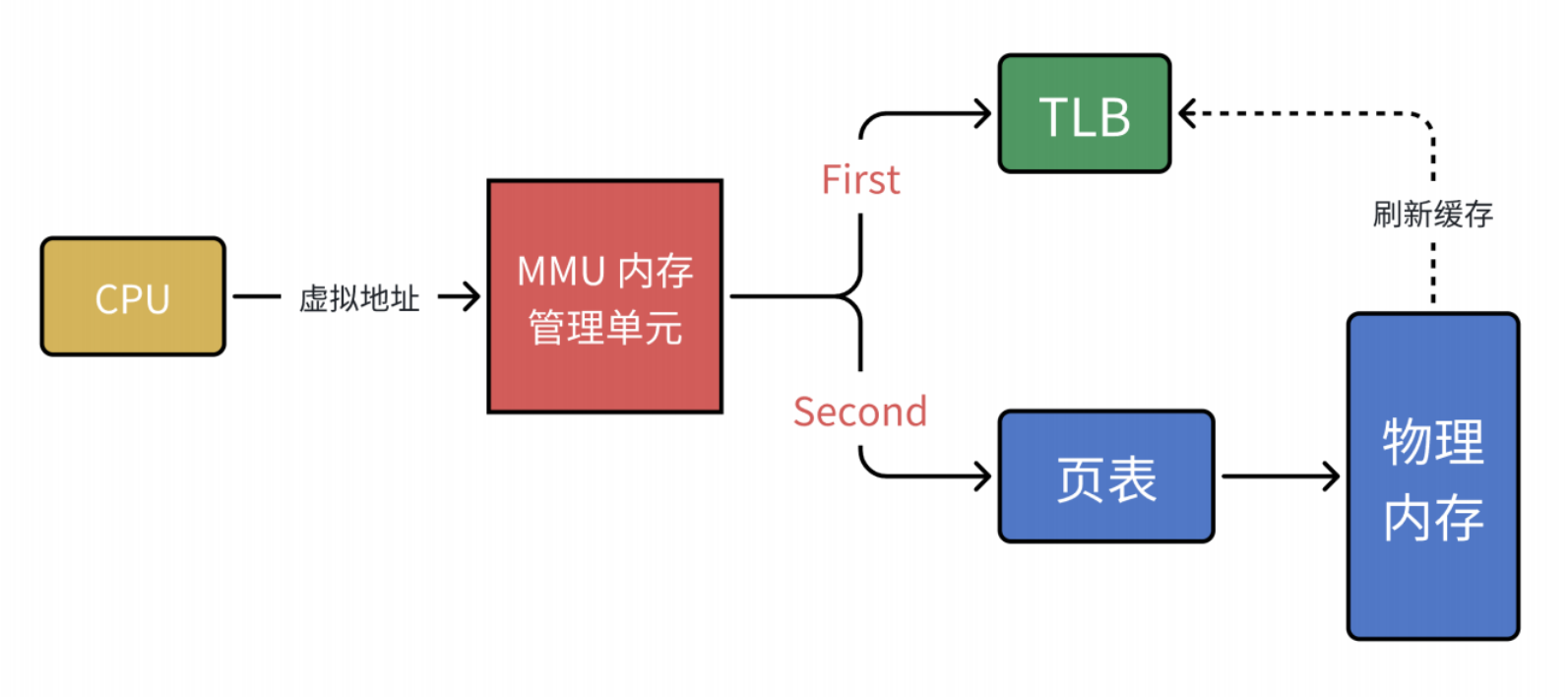
那么這個工作流就沒有缺點了嗎?當然是有的!MMU進行兩次查詢確定物理地址,在確認了權限問題后,將這個物理地址發到總線,內存收到后開始讀取數據并返回。當頁表變為N級時需要經過N次檢索+1次讀寫,查詢效率就會變低。
那么有沒有提升效率的方法呢?有的,那就是添加一層中間層也就是TLB江湖人稱“快表”,其實也就是緩存。當 CPU 給 MMU 傳新虛擬地址之后, MMU 先去問 TLB 那邊有沒有,如果有就直接拿到物理地址發到總線給內存,?活。但 TLB 容量比較小,難免發生 Cache Miss ,這時候 MMU 還有保底的?武器頁表,在頁表中找到之后 MMU 除了把地址發到總線傳給內存,還把這條映射關系給到TLB,讓它記錄?下刷新緩存。
缺頁異常
設想,CPU 給 MMU 的虛擬地址,在 TLB 和頁表都沒有找到對應的物理頁,該怎么辦呢?其實這就是缺頁異常 Page Fault ,它是?個由硬件中斷觸發的可以由軟件邏輯糾正的錯誤。假如目標內存頁在物理內存中沒有對應的物理頁或者存在但?對應權限,CPU 就?法獲取數據,這種情況下CPU就會報告?個缺頁錯誤。由于 CPU 沒有數據就無法進行計算,CPU罷工了用戶進程也就出現了缺頁中斷,進程會從用戶態切換到內核態,并將缺頁中斷交給內核的 Page Fault Handler 處理。
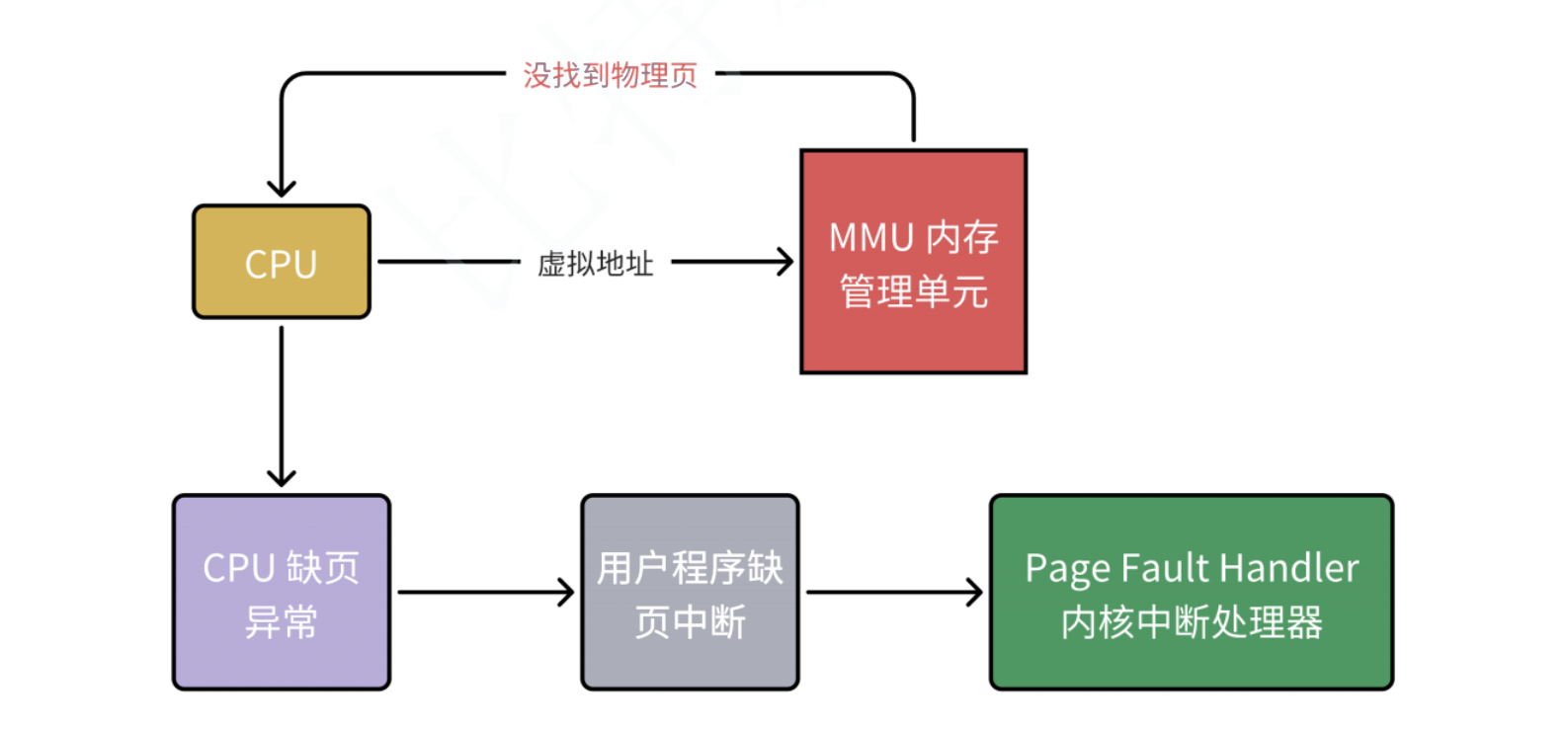
缺頁中斷會交給PageFaultHandler處理,其根據缺頁中斷的不同類型進行不同的處理:
Hard Page Fault也被稱為Major Page Fault,翻譯為硬缺頁錯誤/主要缺頁錯誤,這時物理內存中沒有對應的物理頁,需要CPU打開磁盤設備讀取到物理內存中,再讓MMU建立虛擬地址和物理地址的映射。Soft Page Fault也被稱為Minor Page Fault,翻譯為軟缺頁錯誤/次要缺頁錯誤,這時物理內存中是存在對應物理頁的,只不過可能是其他進程調入的,發出缺頁異常的進程不知道?已,此時MMU只需要建立映射即可,無需從磁盤讀取寫入內存,?般出現在多進程共享內存區域。Invalid Page Fault翻譯為無效缺頁錯誤,比如進程訪問的內存地址越界訪問,?比如對空指針解引用內核就會報segment fault錯誤中斷進程直接掛掉。
Linux進程VS線程
線程優點
- 創建?個新線程的代價要比創建?個新進程小得多
- 與進程之間的切換相比,線程之間的切換需要操作系統做的?作要少很多
- 最主要的區別是線程的切換虛擬內存空間依然是相同的,但是進程切換是不同的。這兩種上下文切換的處理都是通過操作系統內核來完成的。內核的這種切換過程伴隨的最顯著的性能損耗是將寄存器中的內容切換出。
- 另外?個隱藏的損耗是上下文的切換會擾亂處理器的緩存機制。簡單的說,?旦去切換上下文,處理器中所有已經緩存的內存地址?瞬間都作廢了。還有?個顯著的區別是當你改變虛擬內存空間的時候,處理的頁表緩沖
TLB(快表)會被全部刷新,這將導致內存的訪問在?段時間內相當的低效。但是在線程的切換中,不會出現這個問題,當然還有硬件cache。 - 線程占?的資源要比進程少很多
- 能充分利用多處理器的可并行數量
- 在等待慢速
I/O操作結束的同時,程序可執?其他的計算任務 - 計算密集型應用,為了能在多處理器系統上運行,將計算分解到多個線程中實現
I/O密集型應?,為了提高性能,將I/O操作重疊。線程可以同時等待不同的I/O操作。
線程缺點
- 性能損失
?個很少被外部事件阻塞的計算密集型線程往往?法與其它線程共享同?個處理器。如果計算密集型線程的數量比可用的處理器多,那么可能會有較大的性能損失,這里的性能損失指的是增加了額外的同步和調度開銷,而可?的資源不變。
- 健壯性降低
編寫多線程需要更全?更深入的考慮,在?個多線程程序?,因時間分配上的細微偏差或者因共享了不該共享的變量?造成不良影響的可能性是很大的,換句話說線程之間是缺乏保護的。
- 缺乏訪問控制
進程是訪問控制的基本粒度,在?個線程中調?某些
OS函數會對整個進程造成影響。
- 編程難度提高
編寫與調試?個多線程程序比單線程程序困難得多
線程異常
- 單個線程如果出現除零,野指針問題導致線程崩潰,進程也會隨著崩潰
- 線程是進程的執?分?,線程出異常,就類似進程出異常,進而觸發信號機制,終止進程,進程終止,該進程內的所有線程也就隨即退出
用途
- 合理的使用多線程,能提高
CPU密集型程序的執行效率 - 合理的使用多線程,能提高IO密集型程序的用戶體驗(如生活中我們?邊寫代碼?邊下載開發?具,就是多線程運行的?種表現)
進程和線程
- 進程是資源分配的基本單位
- 線程是調度的基本單位
- 線程共享進程數據,但也擁有??的?部分數據: 1、線程
ID2、?組寄存器 3、棧 4、errno5、信號屏蔽字 6、調度優先級
進程的多個線程共享
同?地址空間,因此Text Segment、Data Segment都是共享的,如果定義?個函數,在各線程中都可以調?,如果定義?個全局變量,在各線程中都可以訪問到,除此之外,各線程還共享以下進程資源和環境:
- 文件描述符表
- 每種信號的處理?式(
SIG_IGN、SIG_DFL或者?定義的信號處理函數) - 當前工作目錄
- 用戶
id和組id
進程和線程的關系如下圖:
對于之前學習的進程和這個線程是相悖的嗎?并不是,進程就可以看作一個有一個線程執行流的進程。
Linux線程控制
POSIX線程庫
- 與線程有關的函數構成了?個完整的系列,絕大多數函數的名字都是以“
pthread_”打頭的 - 要使用這些函數庫,要通過引入頭文件
<pthread.h> - 鏈接這些線程函數庫時要使用編譯器命令的
-lpthread選項
創建線程
功能:創建?個新的線程原型:int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void*), void *arg);
參數:thread:返回線程IDattr:設置線程的屬性,attr為NULL表示使用默認屬性start_routine:是個函數地址,線程啟動后要執行的函數arg:傳給線程啟動函數的參數返回值:成功返回0;失敗返回錯誤碼
錯誤檢查:
- 傳統的?些函數是,成功返回0,失敗返回-1,并且對全局變量
errno賦值以指示錯誤 pthreads函數出錯時不會設置全局變量errno(??部分其他POSIX函數會這樣做)。?是將錯誤代碼通過返回值返回pthreads同樣也提供了線程內的errno變量,以支持其它使用errno的代碼。對于pthreads函數的錯誤,建議通過返回值來判定,因為讀取返回值要比讀取線程內的errno變量的開銷更小
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <pthread.h>
void *rout(void *arg) {int i;for( ; ; ) {printf("I'am thread 1\n");sleep(1);}
}
int main( void )
{pthread_t tid;int ret;if ( (ret=pthread_create(&tid, NULL, rout, NULL)) != 0 ) {fprintf(stderr, "pthread_create : %s\n", strerror(ret));exit(EXIT_FAILURE);}int i;for(; ; ) {printf("I'am main thread\n");sleep(1);}
}
#include <pthread.h>
// 獲取線程ID
pthread_t pthread_self(void);
這個函數返回pthread_t類型的值,指代的是調用pthread_self函數的線程id。這個id是pthread庫給每個線程定義的進程內唯一標識,是pthread庫維持的。沒錯,在內核層面根本沒有“線程”這個概念,有的只是進程,只是PCB其它的東西都是庫給我們封裝的。Linux下是根據進程PCB重復利用,搞成了線程,windows下則是另起爐灶,搞出來了一套新的東西。
由于每個進程都有自己獨立的內存空間,故這個id的作用域是進程級的而不是系統級(內核不認識)。
其實pthread庫中也是通過內核提供的系統調用clone...來創建線程的,而內核會為每個線程創建系統全局唯一的id來唯一標識這個線程。
我們可以使用PS命令查看線程信息:
$ ps -aL | head -1 && ps -aL | grep mythreadPID LWP TTY TIME CMD
2711838 2711838 pts/235 00:00:00 mythread
2711838 2711839 pts/235 00:00:00 mythread-L 選項:打印線程信息
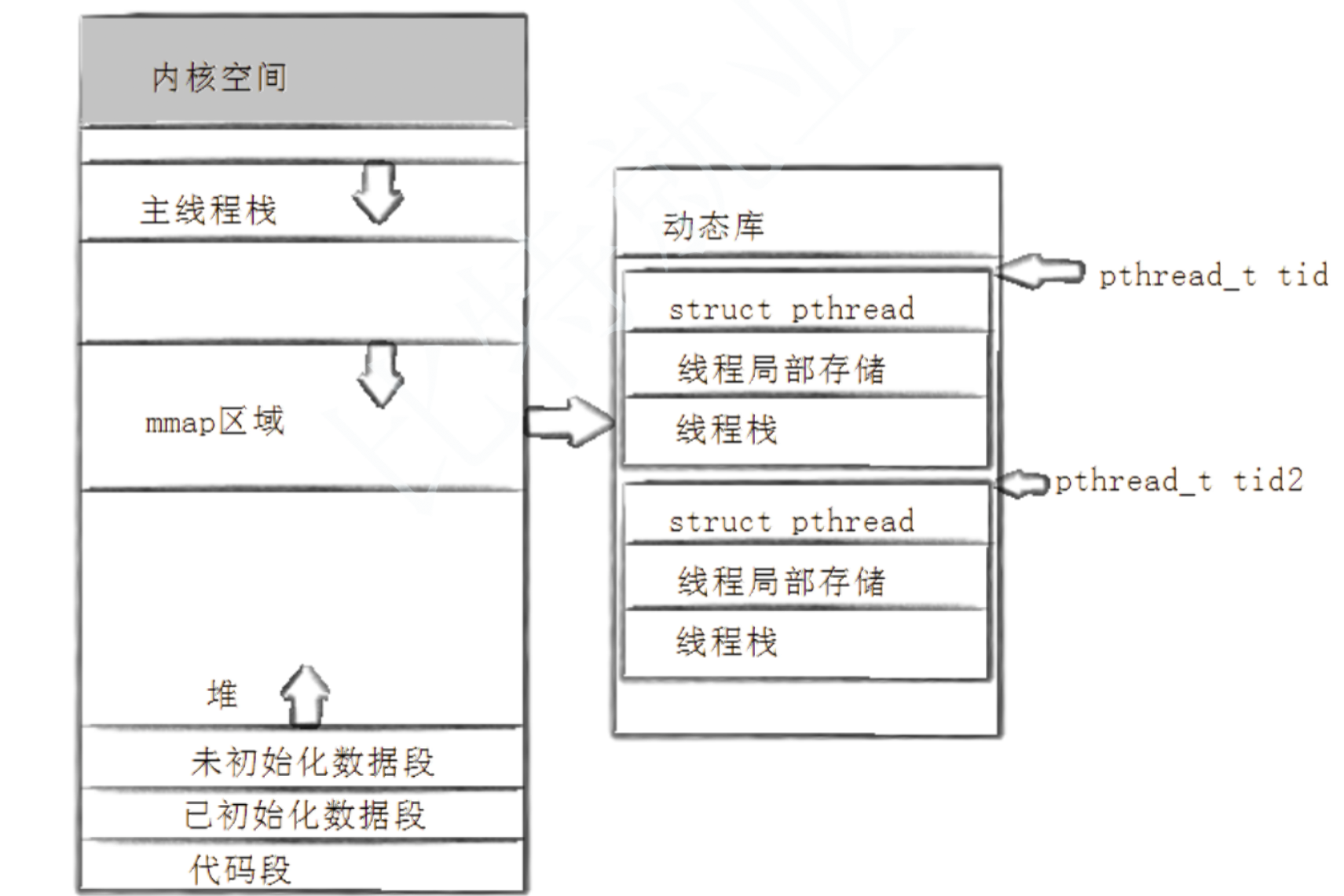
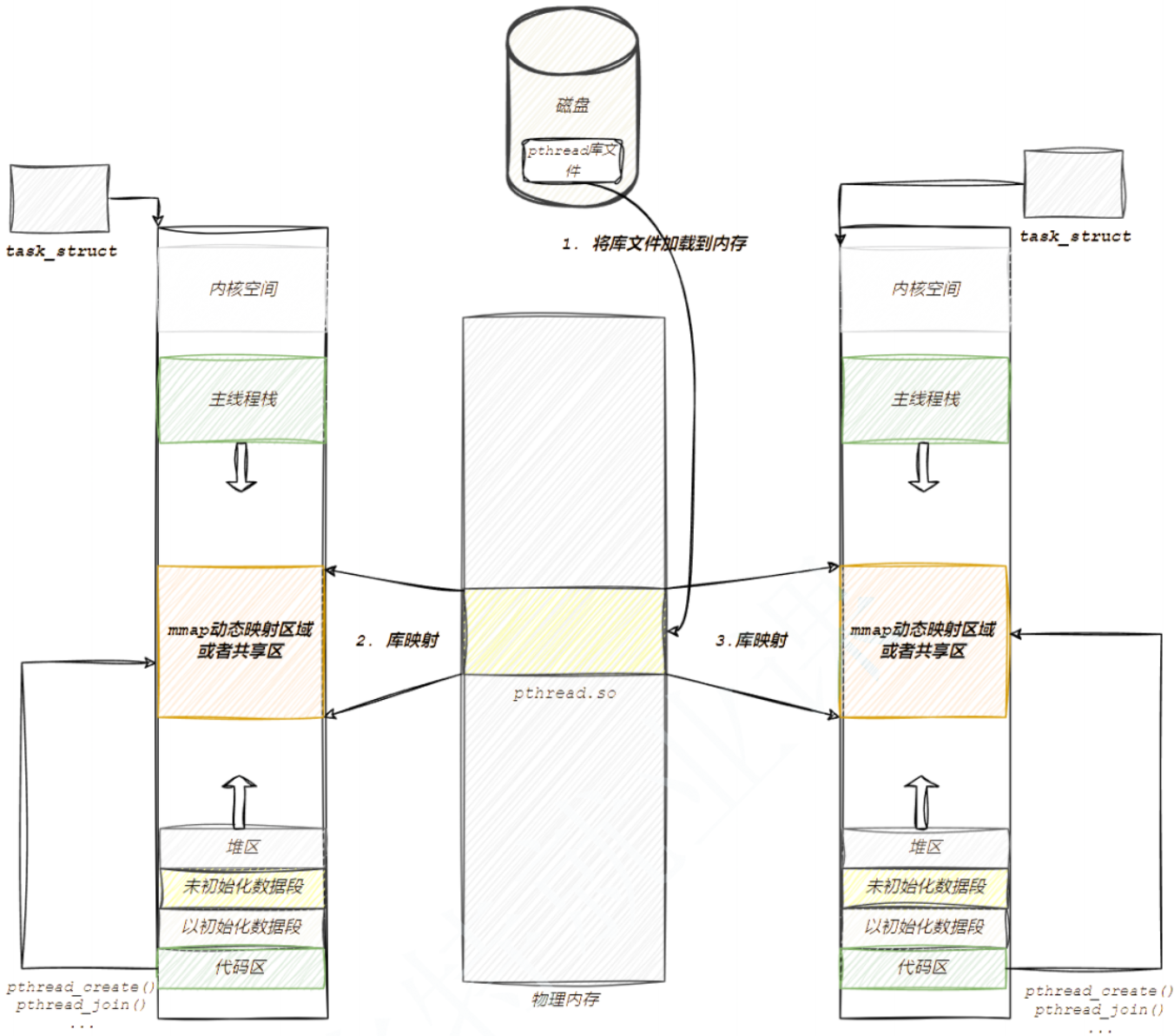
其中LWP就是真正的線程id可以使用gettid()調用,之前使用 pthread_self 得到的這個數實際上是一個地址,在虛擬地址空間上的一個地址,通過這個地址,可以找到關于這個線程的基本信息,包括線程ID,線程棧,寄存器等屬性。
在 ps -aL 得到的線程ID,有?個線程ID和進程ID相同,這個線程就是主線程,主線程的棧在虛擬地址空間的棧上,而其他線程的棧在是在共享區(堆棧之間),因為pthread系列函數都是pthread庫提供給我們的。而pthread庫是在共享區的。所以除了主線程之外的其他線程的棧都在共享區。
線程終止
如果需要止終止某個線程而不終止整個進程,可以有三種方法:
- 從線程函數
return。這種方法對主線程不適?,從main函數return相當于調用exit。 - 線程可以調用
pthread_exit終止自己。 - ?個線程可以調用
pthread_cancel終止同一進程中的另?個線程
pthread_exit函數
功能:線程終?
原型:void pthread_exit(void *value_ptr);
參數:value_ptr:value_ptr不要指向一個局部變量。
返回值:無返回值,跟進程一樣,線程結束的時候無法返回到它的調用者(自身)
注意:pthread_exit函數中的輸出型參數指向的內存必須是全局的,或者用malloc在堆上開辟的空間,不能指向在線程函數的棧上分配的空間,因為當其他線程得到這個返回值時,這個線程已經退出,會導致非法訪問等內存問題。
pehread_cancel函數
功能:取消?個執行中的線程
原型:int pthread_cancel(pthread_t thread);
參數:thread:線程ID
返回值:成功返回0; 失敗返回錯誤碼
線程等待
已經退出的線程,其地址空間沒有被釋放,仍然在進程地址空間內占據位置,新起來的線程也需要空間,所以需要回收退出線程的空間。
功能:等待線程結束
原型:int pthread_join(pthread_t thread, void **value_ptr);
參數:thread:線程IDvalue_ptr:它指向?個指針,后者指向線程的返回值
返回值:成功返回0; 失敗返回錯誤碼
調用該函數的線程將掛起等待,直到要join的線程終止。被join的線程以不同的方法終止,通過pthread_join得到的終止狀態時不同的,總結如下:
- 如果
thread線程通過return返回,value_ptr所指向的單元?存放的是thread線程函數的返回值。 - 如果
thread線程被別的線程調?pthread_cancel異常終掉,value_ptr所指向的單元?存放的是常數PTHREAD_CANCELED。 - 如果
thread線程是自己調用pthread_exit終?的,value_ptr所指向的單元存放的是傳給pthread_exit的參數。 - 如果對
thread線程的終止狀態不感興趣,可以傳NULL給value_ptr參數。
分離線程
默認情況下,新創建的線程是joinable的,線程退出后,需要對其進行pthread_join操作,否則無法釋放資源,從而造成系統泄漏。
如果不關心線程的返回值,join是?種負擔,這個時候,我們可以告訴系統,當線程退出時,自動釋放線程資源。
int pthread_detach(pthread_t thread);
可以是線程組內對其它線程進行分離,亦可以是線程自己分離
pthread_detach(pthread_self());
線程被分離了就不是joinable的了
線程ID及進程地址空間布局
pthread_create函數會產??個線程ID,存放在第?個參數指向的地址中。該線程ID和前?說的線程ID不是?回事。前面講的線程ID(LWP)屬于進程調度的范疇。因為線程是輕量級進程,是操作系統調度器的最小單位,所以需要?個數值來唯?表示該線程。pthread_create函數第?個參數指向?個虛擬內存單元,該內存單元的地址即為新創建線程的線程ID,屬于NPTL線程庫的范疇。- 線程庫的后續操作,就是根據該線程ID來操作線程的。線程庫
NPTL提供了pthread_self函數,可以獲得線程??的ID:
pthread_t pthread_self(void);
| 特征 | LWP | pthread_self()返回值 |
|---|---|---|
| 作用范圍 | 內核空間(系統級調度) | 用戶空間(線程庫級操作) |
| 唯一性 | 全局唯一(整個系統) | 進程內唯一 |
| 數據類型 | pid_t(通常為整數) | pthread_t(具體實現依賴系統) |
| 獲取方式 | syscall(SYS_gettid) 或 gettid() | pthread_self() |
| 用途 | 內核調度、系統調用、信號處理 | 線程庫函數參數(如pthread_equal) |
關于pthread_t的類型,取決于具體實現,對于Linux目前實現的NPTL而言,pthread_t類型的線程ID,本質就是一個進程地址空間上的一個地址。
線程封裝
最新線程封裝具體參考:
25/Udp/chat/thread.hpp · 欽某/Code - 碼云 - 開源中國 (gitee.com)
Code/25/Udp/chat/thread.hpp at master · QinMou000/Code (github.com)
沒什么好說的,注意detach的順序就行,造一次輪子就行了。
_t`類型的線程ID,本質就是一個進程地址空間上的一個地址。**
















)
)

