在使用大模型處理書籍?PDF?時,有時你會遇到掃描版?PDF,也就是說每一頁其實是圖像形式。這時,大模型需要先從圖片中提取文本,而這就需要借助?OCR(光學字符識別)技術。
像?Gemini 2.5?這樣的強大模型,具備非常強的從圖片中提取文本的能力。實際上,我們完全可以利用它來執行?OCR?任務。
利用這樣的大模型進行?OCR,不僅能處理復雜的圖像場景,還能理解文本的結構,保留格式,并正確處理表格、標題等內容,為后續的文本分析、自動化處理和智能搜索提供強大的支持。這種結合?OCR?和?NLP?的智能文檔處理方式,正在成為解決實際問題的強大工具。
然而,像?Gemini?這樣的強大模型只能通過遠程訪問,且存在?API?受限和高成本的問題。那么,是否有可能在本地部署類似的大模型來完成這一任務呢?
雖然本地部署或直接安裝已經有很多方案,后期文章中我們也將逐一比較。但我們更想自己手擼一個,想著將來大模型不斷升級之中我們也能緊隨其后直接升級是不。
一 多模態
首先,我們去?Hugging Face?找找具有這種本事的大模型。
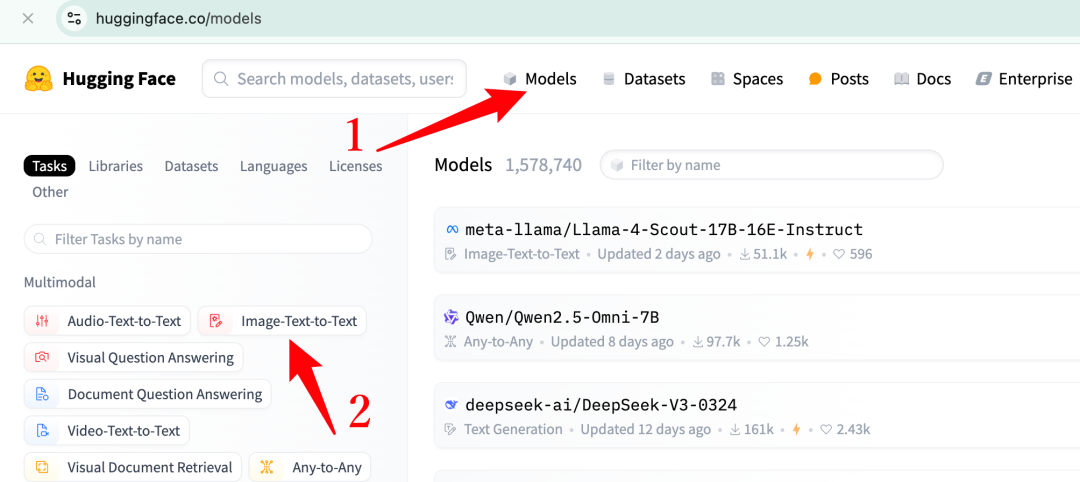
看到?Image-Text-to-Text?沒有,它表示模型能夠處理圖像和文本輸入,符合我們的任務要求。點擊進去,首先看到的是一批新發布的模型,
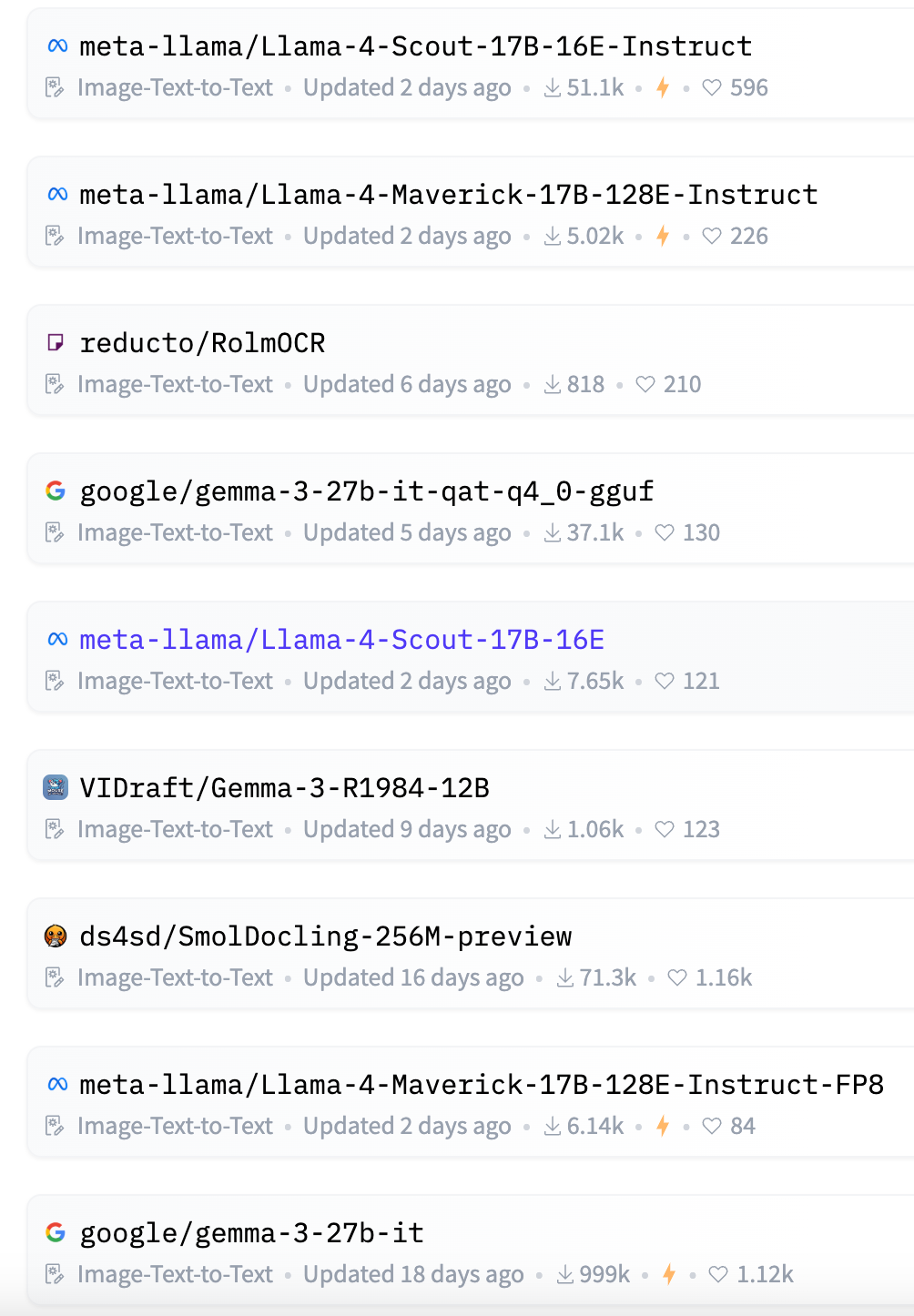
我們往后翻,找到下面這個?https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct。
選這個模型的主要原因是想在筆記本上也能跑起來,所以參數量不能太多。先用我的?Macbook Air?試試本地大模型的?OCR?能力,然后再部署到顯卡好一點的電腦上去干活。
代碼放在?github?倉庫:https://github.com/mathinml/pdf2md
二 項目任務
本項目的任務明確如下:實現一個本地部署的多模態大語言模型,如?Qwen2.5-VL,用于從?PDF?文件中提取文字內容并完成?OCR?任務,最好保留表格形式,并將其轉換為?Markdown?文檔。模型是可選的,只需調整參數即可切換到其他模型。盡管這個功能看似簡單,但它為后續更復雜任務奠定了基礎。
我們使用兩款電腦來測試:Macbook Air M3?處理器,16G?內存;Ubuntu,V100 32G?顯存。
三 用到的庫
該項目主要涉及三部分,即?Transformers,?vLLM?以及具體的大模型如?QWen2.5-VL。這個模型是基于?Transformer?架構開發的多模態模型。具體通過?Hugging Face?的?Transformers?庫來加載和使用它,并選擇使用?vLLM?來優化?Qwen2.5-VL?模型的推理性能。考慮到后期可能會實際部署到高性能電腦上,因此選擇?vLLM,而不是?Ollama。
Transformers,?vLLM?以及?QWen2.5-VL?之間的關系如下圖所示。
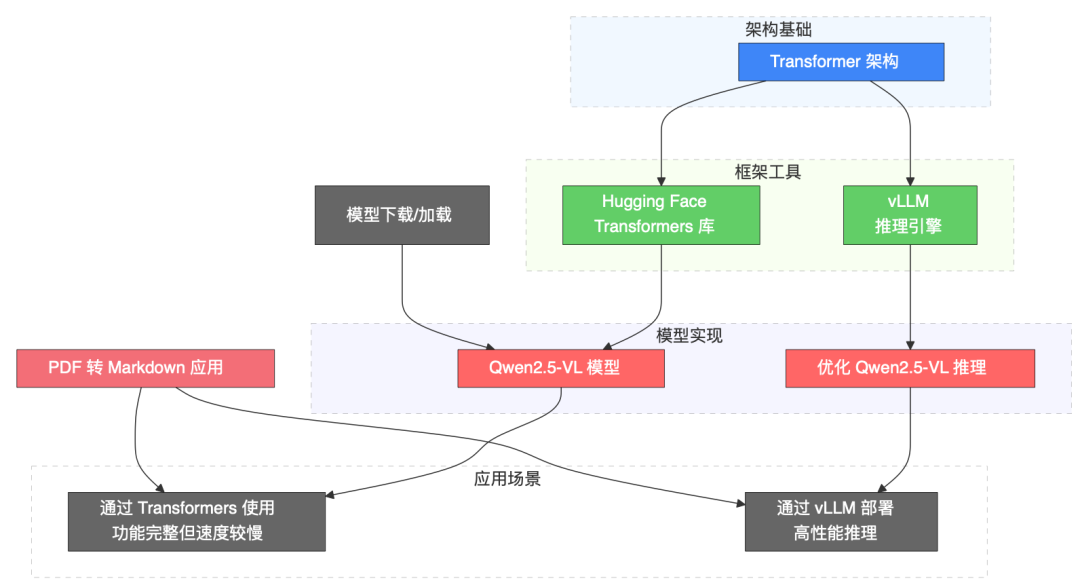
這個關系圖展示了三者之間的依賴和協作,具體如下,
-
Transformers?是基礎框架:QWen2.5-VL?的代碼和模型結構依賴于?Hugging Face Transformers?庫。開發者和用戶需要安裝最新版本的?Transformers?來加載和運行?QWen2.5-VL。 -
vLLM?是推理優化引擎:vLLM?增強了?QWen2.5-VL?的推理性能,尤其是在處理視覺和視頻任務時。它通過張量并行、動態內存管理等技術,使?QWen2.5-VL?能夠在生產環境中高效運行。vLLM?需要與?Transformers?配合使用,并確保版本兼容(例如,某些版本的?Transformers?可能需要從源代碼安裝)。 -
QWen2.5-VL?是應用模型:它是具體的多模態模型,利用?Transformers?提供的架構和?vLLM?的推理優化來實現其功能。換句話說,QWen2.5-VL?的設計目標是處理復雜的視覺語言任務,而?Transformers?和?vLLM?則是其技術支撐。
四 程序流程
程序流程以及幾個主要 Python 文件之間的關系如下圖所示。
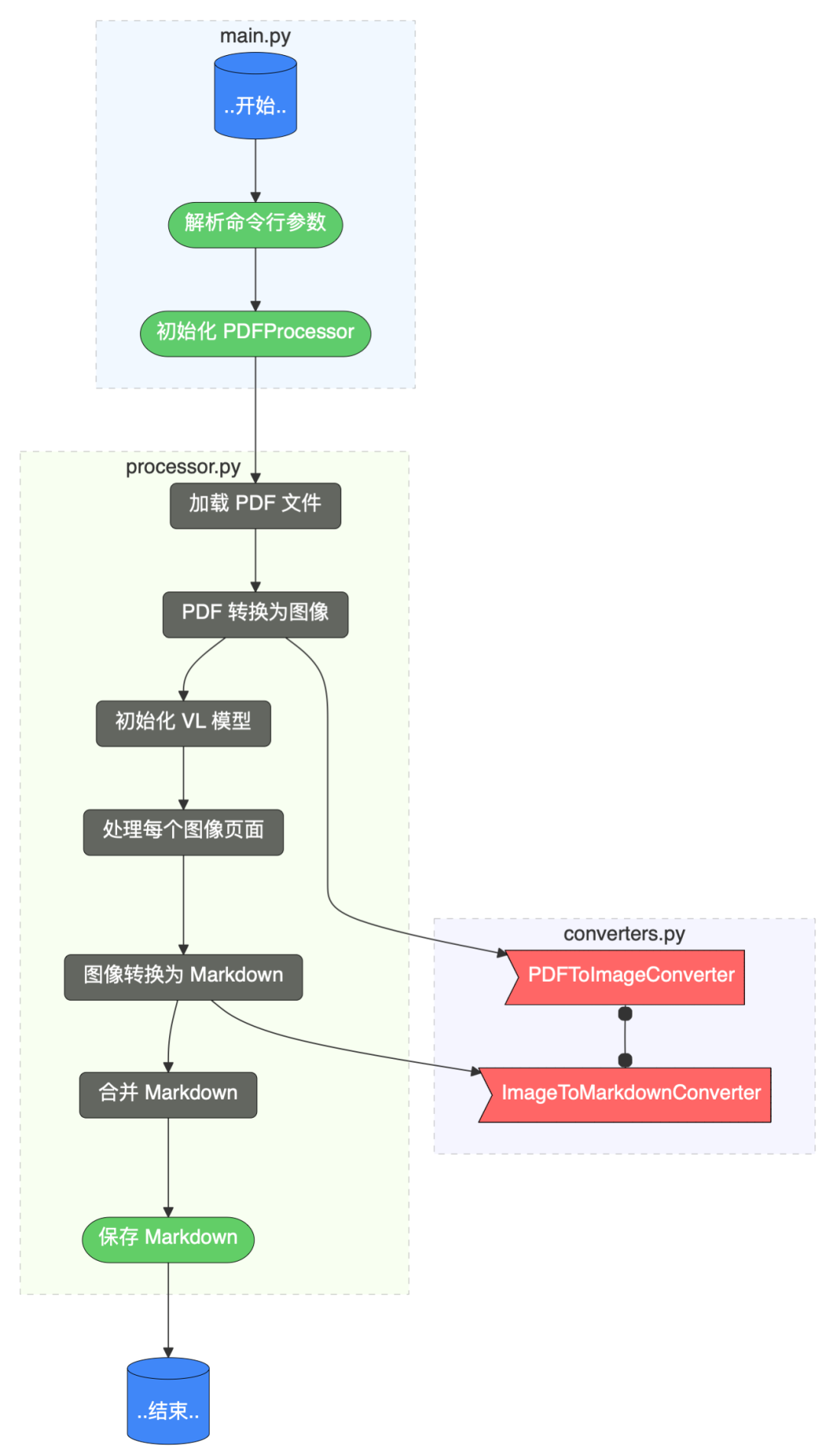
這個程序的主要功能是將?PDF?文件轉換為?Markdown?格式,整個流程可以總結如下:
1、命令行參數解析:通過?cli.py?中的?parse_args?函數解析用戶輸入的命令行參數;主要參數包括:PDF 文件路徑、模型路徑、輸出文件路徑等。
2、初始化處理器:在?main.py?中初始化?PDFMarkdownProcessor?處理器;該處理器是整個轉換過程的核心控制器。
3、PDF?處理階段:加載指定的?PDF?文件;使用?PDFToImageConverter?將?PDF?文件轉換為圖像序列,圖像分辨率默認為?1024?寬。
4、模型初始化:加載指定的視覺語言模型(如?Qwen2.5-VL-3B-Instruct);該模型需要提前下載到本地指定目錄。
5、圖像處理與轉換:對每個?PDF?頁面生成的圖像進行處理;使用?ImageToMarkdownConverter?將圖像內容轉換為?Markdown?文本;這一步利用視覺語言模型識別圖像中的文本、表格、圖片等內容。
6、結果整合與輸出:合并所有頁面轉換得到的?Markdown?內容;將最終的?Markdown?文本保存到指定的輸出文件中。
整個流程體現了模塊化設計思想,各個組件職責明確,便于維護和擴展。用戶只需通過簡單的命令行參數即可完成從?PDF?到?Markdown?的轉換過程。
五 模型下載
可以通過命令?huggingface-cli download?來下載?Qwen2.5-VL,但如果?huggingface?不方便使用,可以選擇用?modelscope。
比如我們要使用的這個模型文件放在這里:https://modelscope.cn/models/Qwen/Qwen2.5-VL-3B-Instruct/files
先安裝?modelscope:
pip install modelscope
然后用以下命令,
modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir ../local_models/Qwen2.5-VL-3B-Instruct
將完整模型庫文件下載到指定的本地目錄?../local_models/Qwen2.5-VL-3B-Instruct?中。
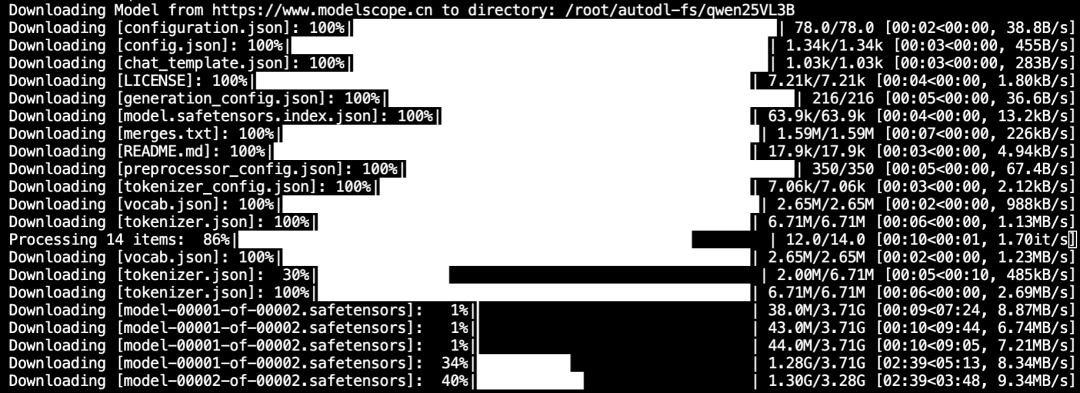
?轉化效果
對于?1024?分辨率的圖像,在?Macbook Air?上轉化一頁需要六、七分鐘,雖然有點久,但至少也能跑起來了,而在?V100?上只需要?10?秒+。
如果頁面較清晰,可以降低分辨率,那樣自然會提高轉化效率。另外,程序中有個參數?quantization=None?表明沒有啟用量化,保持了模型的完整精度。如果想進一步提高效率,可以使用量化版本,即?Qwen/Qwen2.5-VL-3B-Instruct-AWQ。
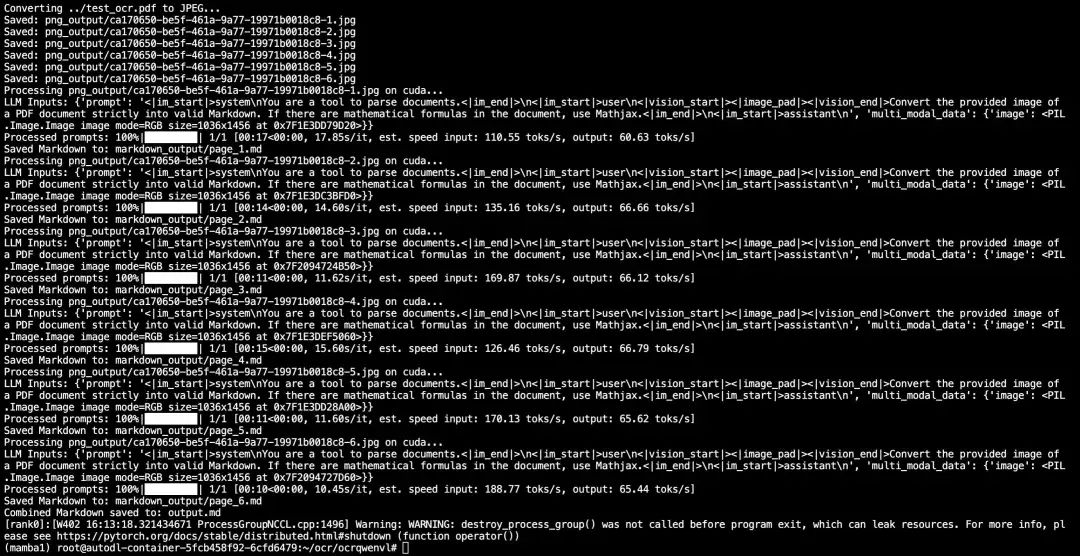
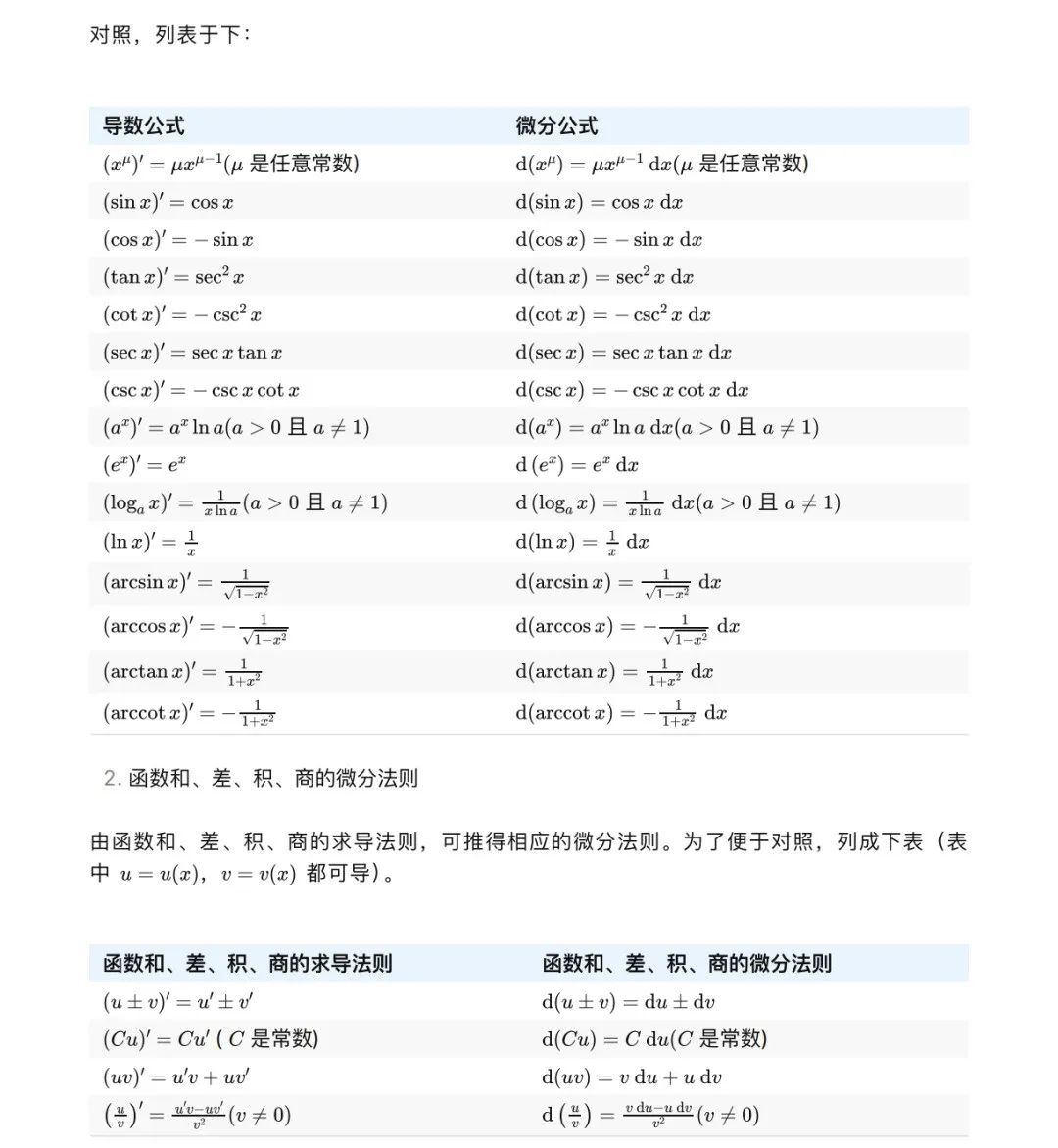
六 轉化效果
從?PDF?文件中提取的圖像,

轉化為?Markdown?后,效果如下圖所示。是不是文字、表格和數學公式都還保持的不錯。
代碼:https://github.com/mathinml/pdf2md





)
)





Java/python/JavaScript/C++/C語言/GO六種最佳實現)




圖像濾波-----分離過濾器函數sepFilter())

