視頻 url: https://www.bilibili.com/video/BV1du17YfE5G?spm_id_from=333.788.videopod.sections&vd_source=7a1a0bc74158c6993c7355c5490fc600&p=2
大佬筆記 url: https://zhuanlan.zhihu.com/p/8129089606
先看視頻:
Lecture 0 ~ 28min 的內容基本就是 cache,本科體系結構學過的東西。
sinx例子:串行版本
一個例子貫穿全課(使用泰勒展開計算 sinx):
該程序使用泰勒展開實現 sinx() 函數。為每一個 x (x數組中的每一個元素) 計算一個 y (y 數組中的每一個元素)。這是一個串行程序
void sinx(int N, int terms, float* x, float* y)
{for (int i = 0; i < N; i++){float value = x[i];float numer = x[i] * x[i] * x[i];int denom = 6; // 3!int sign = -1;for (int j = 1; j < terms; j++){value += sign * numer / denom;numer *= x[i] * x[i];denom *= (2 * j + 2) * (2 * j + 3);sign *= -1;}y[i] = value;}
}
sinx例子:C++ thread 雙線程版本
上面這個程序可以通過改變程序的方式來實現并行,比如,我們可以通過 C++ thread,增加一個線程幫助我們實現并行:(下面這個代碼應該是有 bug 的,但是無傷大雅)
但下面的代碼有個問題:如果我的硬件有4個 CPU cores,那么下面的代碼只能利用到我的兩個 CPU cores,而非四個。
#include <thread>void sinx(int N, int terms, float* x, float* y)
{for (int i = 0; i < N; i++){float value = x[i];float numer = x[i] * x[i] * x[i];int denom = 6; // 3!int sign = -1;for (int j = 1; j < terms; j++){value += sign * numer / denom;numer *= x[i] * x[i];denom *= (2 * j + 2) * (2 * j + 3);sign *= -1;}y[i] = value;}
}typedef struct {int N;int terms;float* x;float* y;
} my_args;void my_thread_func(my_args* args)
{sinx(args->N, args->terms, args->x, args->y); // do work
}void parallel_sinx(int N, int terms, float* x, float* y)
{std::thread my_thread;my_args args;args.N = N/2;args.terms = terms;args.x = x;args.y = y;my_thread = std::thread(my_thread_func, &args); // launch threadsinx(N - args.N, terms, x + args.N, y + args.N); // do work on main threadmy_thread.join(); // wait for thread to complete
}
sinx例子:高級語言循環并行化版本
事實上,現代高級編程語言幾乎都有這么一種抽象語義,來表示一個循環的每次迭代都是相互獨立的,比如 C+OpenMP, pyTorch 等等,如下:
高級編程語言會根據硬件 cores 的數量,自動創建合適數量的線程去并行執行下面的代碼。也就是說,如果我有 16 個 CPU cores,那么通常高級編程語言會幫助我把計算任務平均地分配給 16 個 CPU cores。

sinx例子:SIMD 版本
這個課堂給出的 SIMD 例子需要硬件和編譯器的支持。
硬件上,要求一個 core 里有多個 ALU 元件,如下:

使用一個 ALU 的程序叫做 scalar program (標量程序)。
如下,使用 AVX 指令的代碼則叫做 vector program (矢量程序)
#include <immintrin.h>void sinx(int N, int terms, float* x, float* y)
{float three_fact = 6; // 3!for (int i = 0; i < N; i += 8){__m256 origx = _mm256_load_ps(&x[i]);__m256 value = origx;__m256 numer = _mm256_mul_ps(origx, _mm256_mul_ps(origx, origx));__m256 denom = _mm256_broadcast_ss(&three_fact);int sign = -1;for (int j = 1; j < terms; j++){// value += sign * numer / denom__m256 tmp = _mm256_div_ps(_mm256_mul_ps(_mm256_set1_ps(sign), numer), denom);value = _mm256_add_ps(value, tmp);numer = _mm256_mul_ps(numer, _mm256_mul_ps(origx, origx));denom = _mm256_mul_ps(denom, _mm256_set1_ps((2*j+2) * (2*j+3)));sign *= -1;}_mm256_store_ps(&y[i], value);}
}
上面的 SIMD 源碼會被編譯器編譯成下面的 SIMD 匯編指令,一個指令處理 256-bit 數據,從而加速

一個問題是,為什么選擇在單核中增加 ALU,而不是直接增加核數?
回答:一個 ALU 相比一個完整的 CPU core 便宜很多
SIMD遇到分支判斷結構怎么辦?(使用掩碼濾除)
如下圖,當 SIMD 代碼遇到分支判斷結構時,可能無法同時執行 SIMD 指令。因為每次循環執行的指令流并不一致。(這種情況也叫做 “線程分化”)
此時有一種很直接的做法:讓 CPU core 使用 SIMD 指令同時執行 if-else 中的所有代碼,隨后根據 if 判斷的結果掩蓋掉部分計算結果。

一個具體的例子如下:
源碼:
// 偽代碼:每個線程處理一個元素
if (data[i] > 5) {data[i] *= 2; // 分支導致線程分化
}
生成掩碼:
mask = (data > 5) # 例如:mask = [1, 0, 1, ...]
應用掩碼:
// 偽代碼:所有線程執行相同指令,但僅掩碼為1的通道生效
data = data * (2 * mask + (1 - mask)) // 滿足條件時乘2,否則乘1(即不變)
更具體的例子:
Intel AVX512 指令集的掩碼操作
// 示例:Intel AVX512 指令集的掩碼操作
__mmask16 mask = _mm512_cmp_ps_mask(vec, threshold, _CMP_GT_OS);
result = _mm512_mask_mul_ps(vec, mask, vec, factor); // 僅掩碼為1的通道執行乘法
CUDA 中使用掩碼選擇活躍線程
// 示例:CUDA 中使用掩碼選擇活躍線程
unsigned int mask = __ballot_sync(0xFFFFFFFF, data[i] > 5);
if (threadIdx.x % 32 < __popc(mask)) {// 僅滿足條件的線程執行后續操作
}
在課堂例子中,極端情況下只有 1/8 的效率。
比如,只有線程1執行 if-True 的情況,其它7個線程執行 if-False的情況。
而 if-True 包含 expensive 的代碼,if-False 包含 cheap 的代碼。
那么,哪怕使用了上述掩碼技術,效率仍然接近 1/8
指令流一致性和發散執行
指令流一致性:多個計算單元執行的指令序列是一致的
對于SIMD并行來說,指令流一致性是必要的
但對于多核并行來說,指令流一致性不必要,因為每個 core 有自己的 IFU 和 IDU。
發散執行:指的是一個程序中缺少 “指令流一致性”

SIMD 需要 CPU硬件支持、編譯器支持、以及程序員的參與

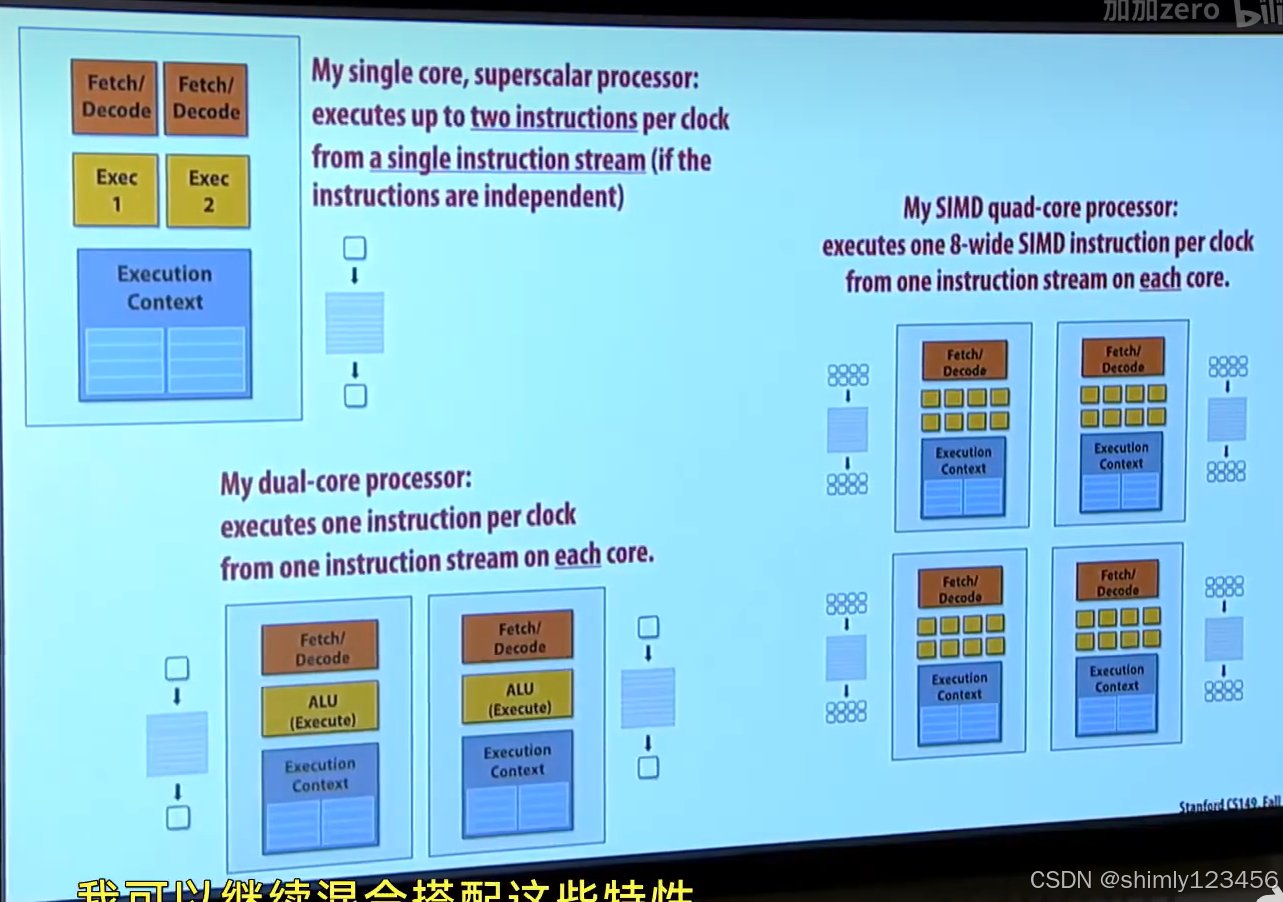
三種不同的并行形式
1.超標量:例如 nutshell 的順序雙發、以及BOOM的亂序多發處理器,這種并行由CPU自己執行,沒有編譯器和程序員的參與。
2.SIMD:利用一個 CPU core 上多個 ALU,需要硬件、編譯器和程序員的支持。
3.多核:在多個 CPU core 上運行同一個程序的多個線程。需要硬件、編譯器和程序員的支持。

下圖很好地介紹了三種并行的區別
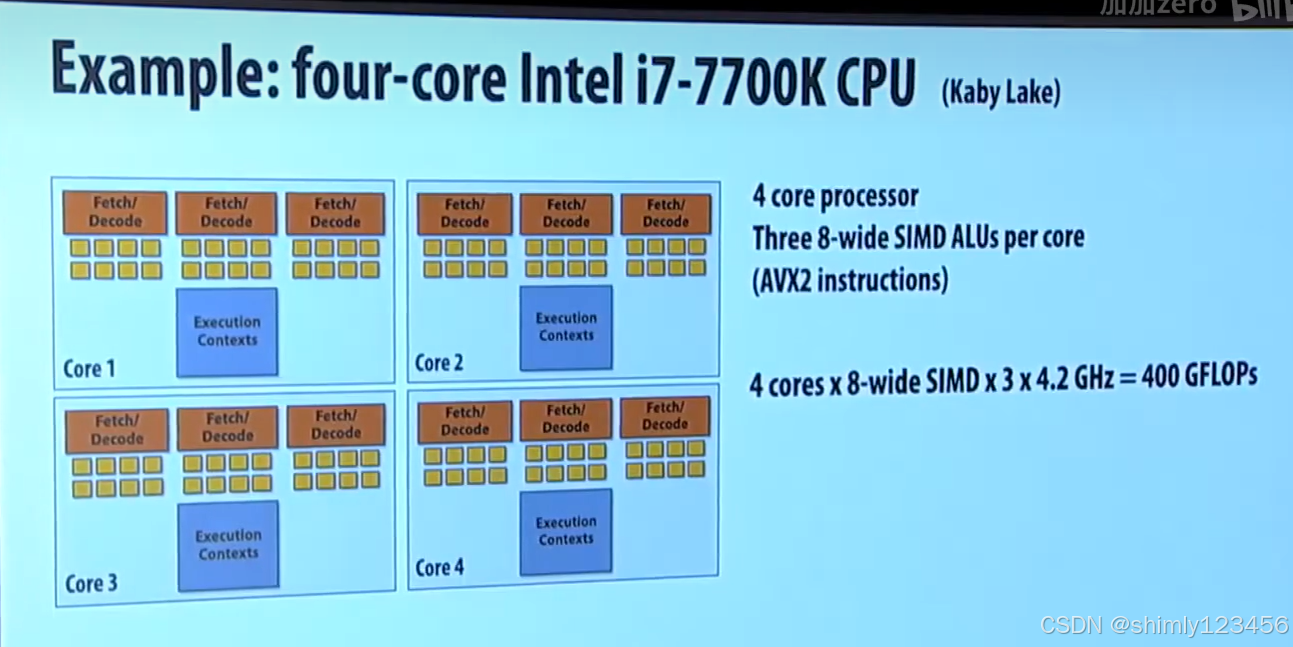
這些并行形式可以混合,如下:

數據預取(緩解內存IO開銷)
內存訪問仍然是一個大的性能瓶頸,除了緩存外,還有數據預取,如下

超線程技術(緩解IO開銷)
還有一種解決內存瓶頸的方式:在 CPU core 里實現多個 execution context。(也叫超線程技術)
當遇到內存讀取 cache miss 時,CPU 知道自己要等待很久,于是切換到第二個 thread 的 execution context 去執行第二個 thread
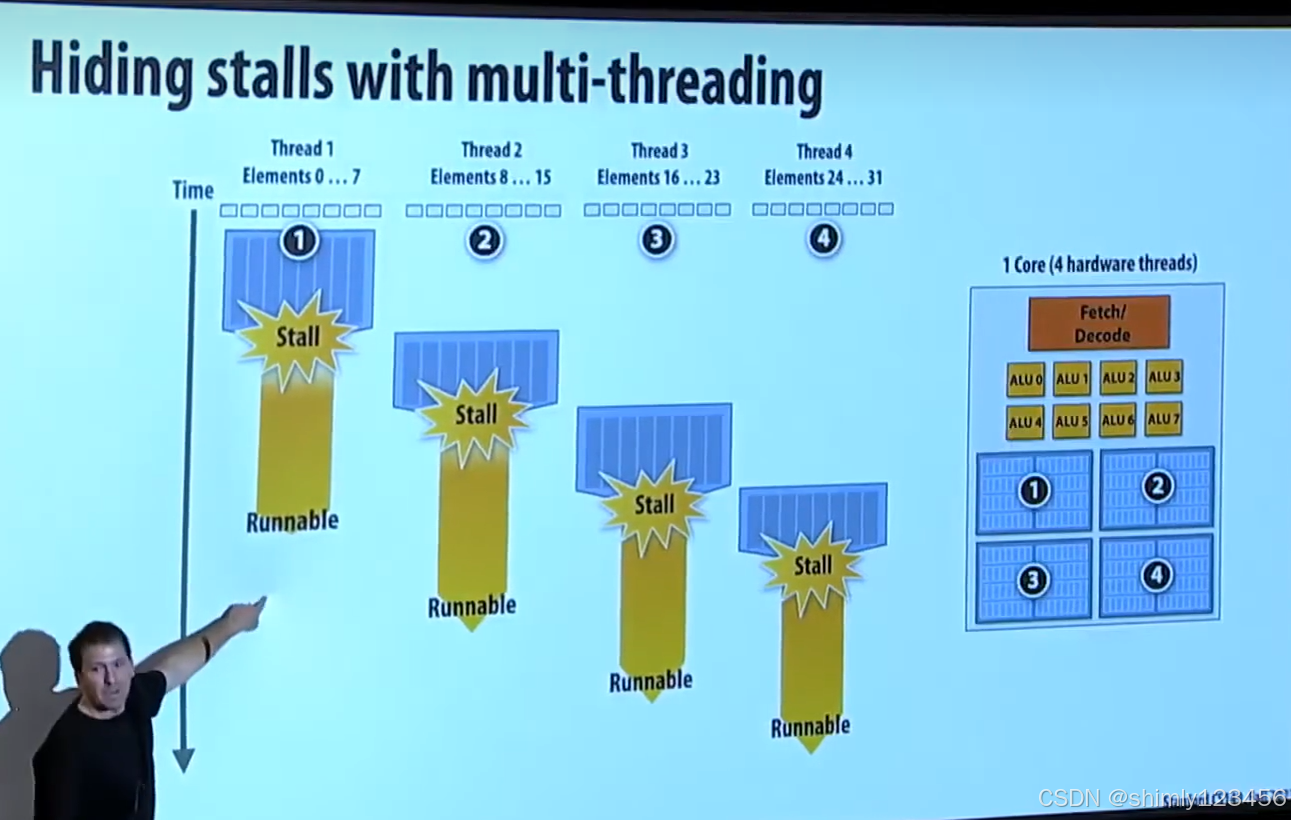
需要注意的是,上述方法提高了 overall system throughput,但實際上降低了單個線程的執行速度。(因為單個線程在內存數據讀取完畢后,CPU core 并沒有立刻切換回來執行)

再來看大佬筆記補充
3 實現SIMD的AVX2案例代碼
SIMD這一思想對應的指令集就是我們常常在硬件評測類視頻或文章中提到的AVXxxx系列指令集。AVX2是目前使用最廣泛的SIMD指令集。AVX512支持的SIMD指令集的寬度更大, 但是目前還沒有普及, 而且因為發熱過大還在Intel最近幾代CPU被移除了, 這里的案例代碼也是基于AVX2的, 其支持的SIMD指令寬度為256位。
查看個人PC是否支持AVX2指令集的方法:
cat /proc/cpuinfo | grep avx2
3.1 中常用的函數總結
3.1.1 浮點運算函數
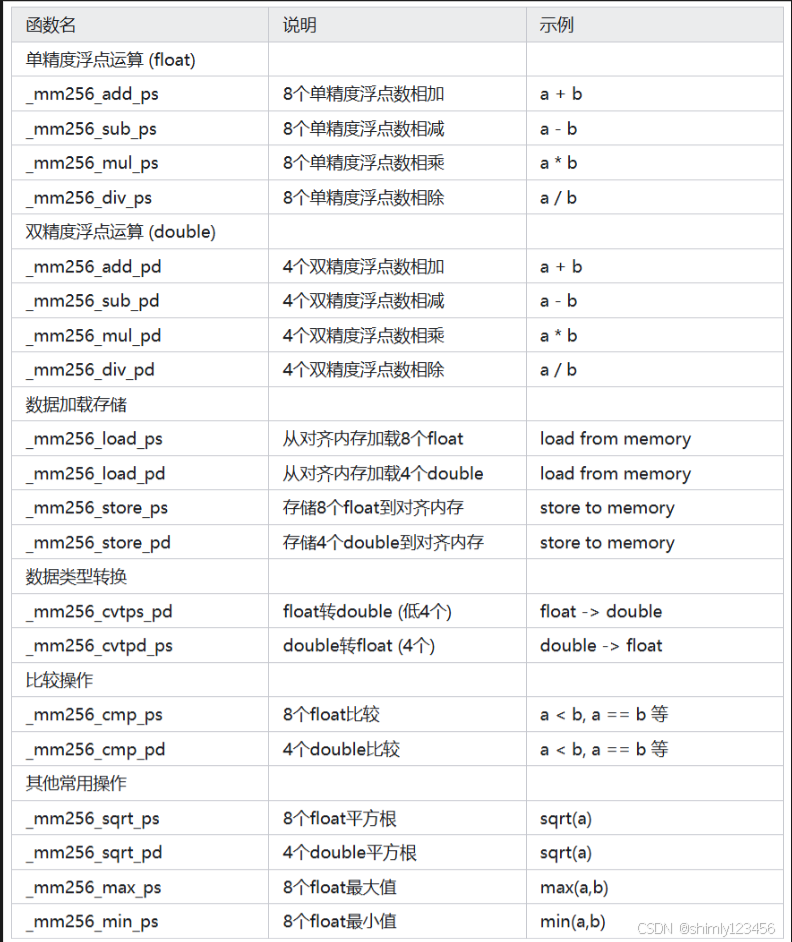
注意事項: 1. 函數名中的 ps 表示 packed single (單精度浮點) 2. 函數名中的 pd 表示 packed double (雙精度浮點) 3. 256 表示使用 256 位寄存器 4. 單精度運算一次處理 8 個數 (256/32=8) 5. 雙精度運算一次處理 4 個數 (256/64=4)





)





![P1025 [NOIP 2001 提高組] 數的劃分(DFS)](http://pic.xiahunao.cn/P1025 [NOIP 2001 提高組] 數的劃分(DFS))
工廠模式)





)
