一、研究背景
近年來,隨著全球氣候變化的加劇,天氣預報和氣象預測變得越來越重要。準確的天氣預測不僅能夠幫助人們做好日常生活的安排,還能在農業生產、防災減災等方面起到關鍵作用。隨著大數據技術和機器學習算法的快速發展,利用數據驅動的方法進行天氣類型預測已經成為一種趨勢。本研究基于歷史氣象數據,利用多種氣象指標,如溫度、濕度、風速、降水量、云量、氣壓、紫外線指數等,通過機器學習算法對天氣類型進行預測,以期提高天氣預報的準確性和實用性。
二、研究意義
本研究的意義主要體現在以下幾個方面:
- 提升天氣預報的準確性:通過機器學習算法對歷史氣象數據進行分析,可以發現數據中的潛在模式,從而提高天氣預報的準確性。
- 增強防災減災能力:準確的天氣預報可以幫助政府和相關部門提前采取防災減災措施,減少因惡劣天氣造成的損失。
- 促進農業生產:精準的氣象預測能夠幫助農民合理安排播種、施肥和收獲等農業活動,提高農業生產效率。
- 推動氣象數據應用:通過對氣象數據的深入分析和應用,可以促進氣象數據在更多領域的應用,推動相關技術的發展。
三、實證分析
代碼和數據集
首先導入數據包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import osimport pandas as pd
import numpy as npimport matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score# Classification models
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNBimport warnings
warnings.filterwarnings('ignore') ?讀取展示數據集
data=pd.read_csv('weather_classification_data.csv')
data.head(5) ?查看數據類型
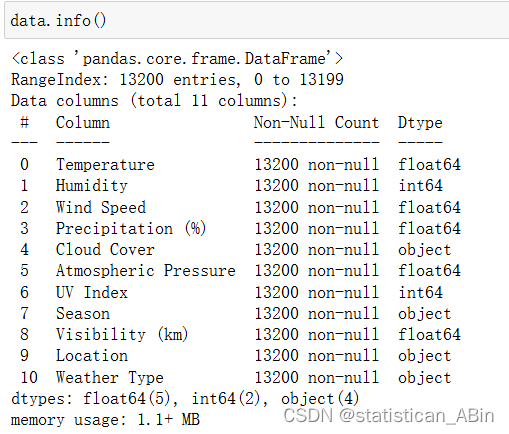
?查看數據類型
描述性統計分析
data.describe()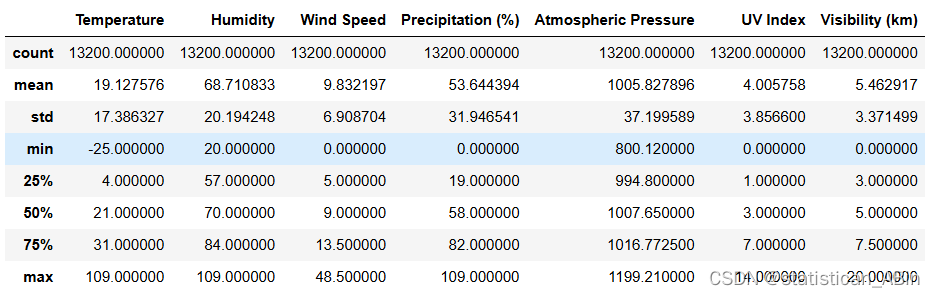 ?查看分類變量匯總
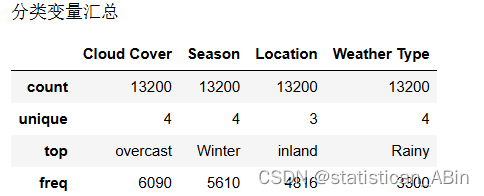
?查看分類變量匯總
接下來對數據可視化
plt.figure(figsize=(12, 8))plt.subplot(2, 2, 1)
sns.histplot(data['Temperature'], bins=20, kde=True, color='#835C3B', alpha=0.7)
plt.title('Distribution of Temperature')
plt.xlabel('Temperature (Celsius)')
plt.ylabel('Count')plt.subplot(2, 2, 2)
sns.histplot(data['Humidity'], bins=20, kde=True, color='#3F000F', alpha=0.7)
plt.title('Distribution of Humidity')
plt.xlabel('Humidity (%)')
plt.ylabel('Count')plt.subplot(2, 2, 3)
sns.histplot(data['Wind Speed'], bins=20, kde=True, color='#1F6357', alpha=0.7)
plt.title('Distribution of Wind Speed')
plt.xlabel('Wind Speed (km/h)')
plt.ylabel('Count')plt.subplot(2, 2, 4)
sns.histplot(data['Precipitation (%)'], bins=20, kde=True, color='#3C565B', alpha=0.7)
plt.title('Distribution of Precipitation')
plt.xlabel('Precipitation (%)')
plt.ylabel('Count')plt.tight_layout()
plt.show()?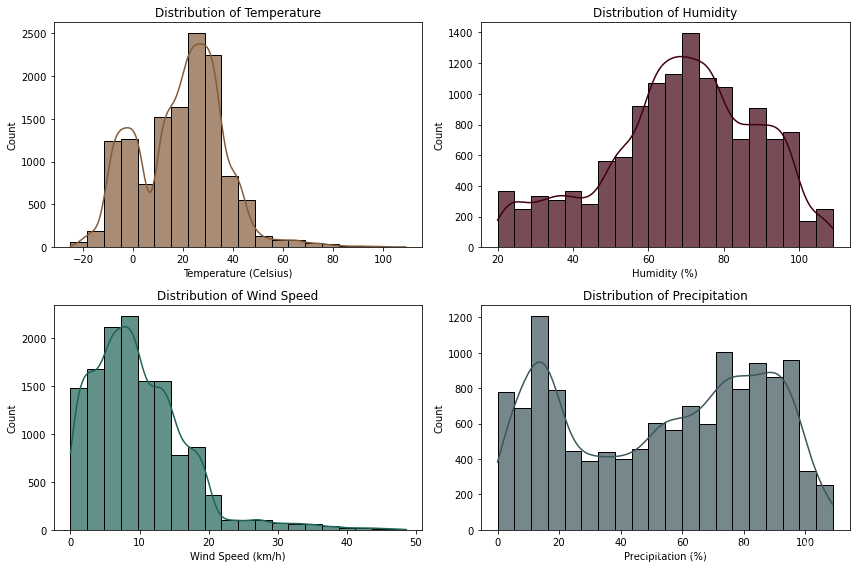
可以發現
溫度:溫度分布向右傾斜,這意味著對較高溫度的觀測值多于對較低溫度的觀測值。最常見的溫度在 20 到 40 攝氏度之間。
濕度:最常見的濕度水平在 60% 到 100% 之間。
風速:風速分布向右傾斜,最常見的觀測值在0到20(km/h)之間。
降水:最常見的降水量在0%至20%之間。
對分類變量的圖進行計數
plt.figure(figsize=(16, 10))
plt.subplot(2, 2, 1)
sns.countplot(x='Cloud Cover', data=data, palette='Set2')
plt.title('Count of Cloud Cover')
plt.subplot(2, 2, 2)
sns.countplot(x='Season', data=data, palette='Set1')
plt.title('Count of Season')
plt.subplot(2, 2, 3)
sns.countplot(x='Location', data=data, palette='Set3')
plt.title('Count of Location')
plt.subplot(2, 2, 4)
sns.countplot(x='Weather Type', data=data, palette='Pastel1')
plt.title('Count of Weather Type')
plt.tight_layout()
plt.show()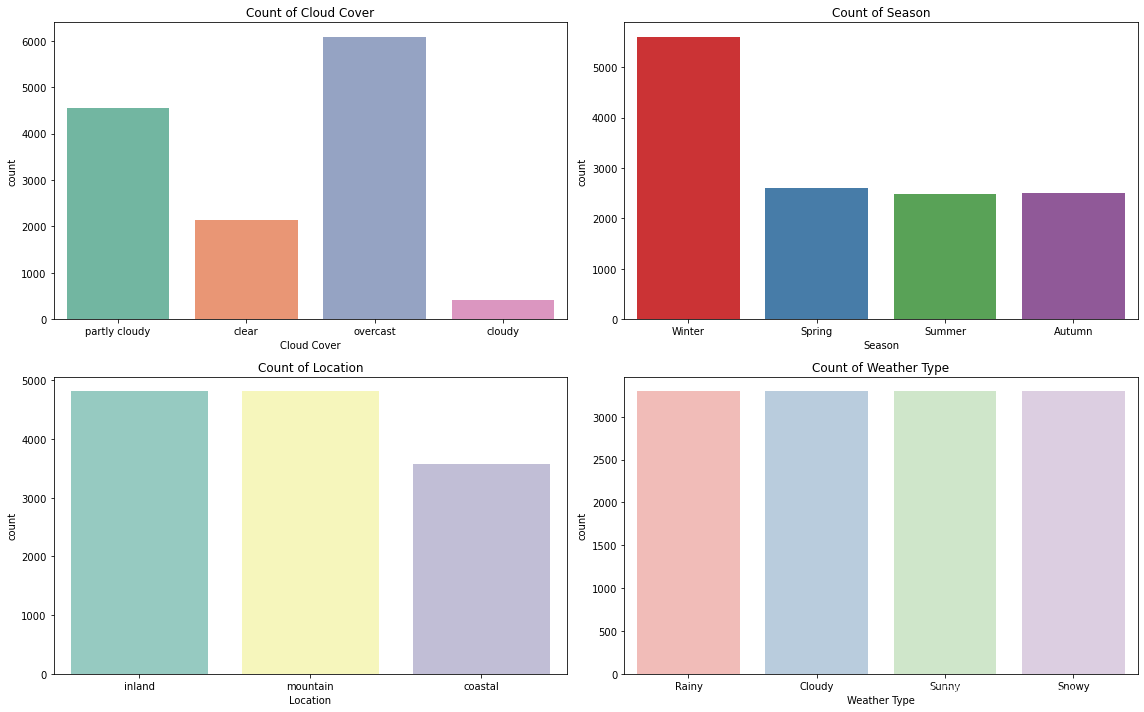
接下來進行數據清洗和預處理
# # 定義標準縮放的數值特征
numeric_features = ['Temperature', 'Humidity', 'Wind Speed', 'Precipitation (%)', 'Atmospheric Pressure', 'UV Index', 'Visibility (km)']# 標準化
scaler = StandardScaler()X_train_scaled = X_train.copy()
X_train_scaled[numeric_features] = scaler.fit_transform(X_train[numeric_features])用于相關性分析的獨立數值特征
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))plt.figure(figsize=(8,6))
sns.heatmap(corr_matrix, mask=mask, annot=True, cmap='copper', fmt='.2f', linewidths=0.5)
plt.title('Correlation Matrix Heatmap (Numerical Features)')
plt.show()?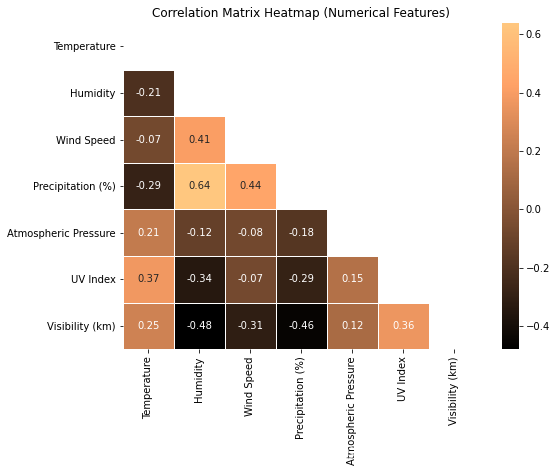
溫度與大氣壓力、紫外線指數和能見度呈正相關。降水量和濕度之間最正相關。最負相關的是濕度和能見度。?
接下來建立模型和對模型評價
classifiers = {'Logistic Regression': LogisticRegression(random_state=42),'Decision Tree': DecisionTreeClassifier(random_state=42),'Random Forest': RandomForestClassifier(random_state=42),'Gradient Boosting': GradientBoostingClassifier(random_state=42),'SVM': SVC(random_state=42),'KNN': KNeighborsClassifier(),'Naive Bayes': GaussianNB()
}for clf_name, clf in classifiers.items():print(f"Training {clf_name}...")clf.fit(X_train_scaled, y_train)y_pred = clf.predict(X_test_scaled)?邏輯回歸
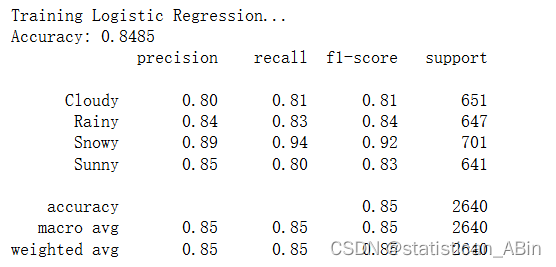
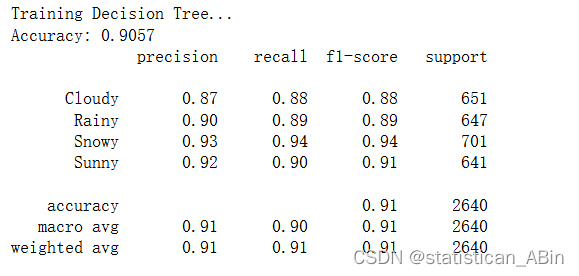
決策樹
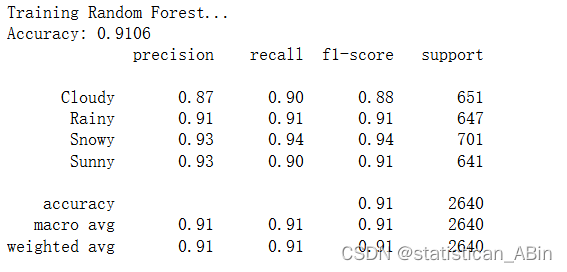
隨機森林
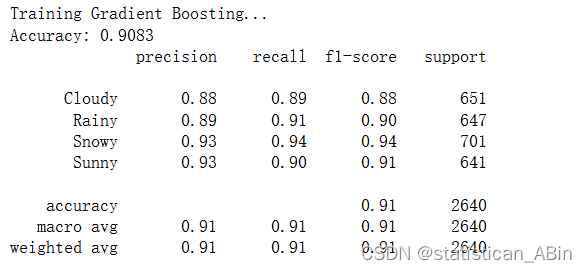
梯度提升
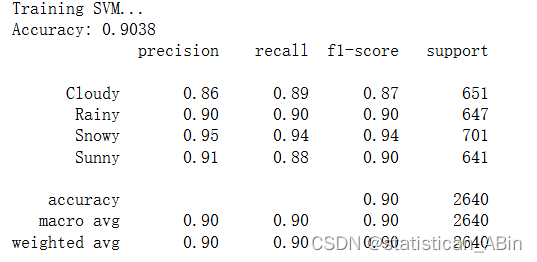
支持向量機
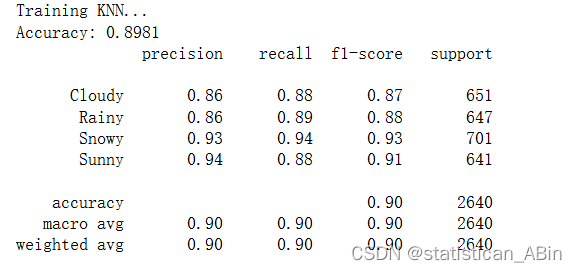
KNN
樸素貝葉斯
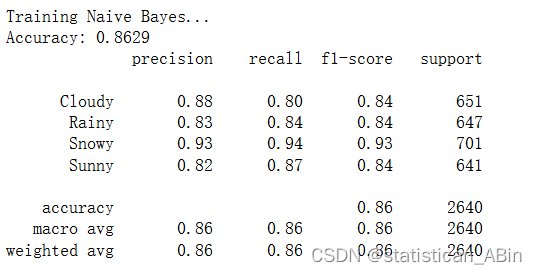
決策樹、隨機森林和梯度提升分類器可實現最高的準確度和 F1 分數,表明在所有天氣類型下都具有強大的性能。大多數分類器在不同類別(多云、雨天、下雪、晴天)中表現出平衡的精度和召回率,這表明它們可以很好地泛化到數據集中的所有天氣類型。
接下來查看特征重要性
importance = rf_classifier.feature_importances_
feature_names = X.columnsfeature_importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': importance})
feature_importance_df = feature_importance_df.sort_values(by='Importance', ascending=False)print("Feature Importance (Random Forest):")
feature_importance_df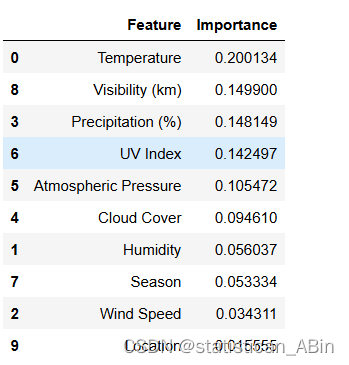
畫出特征重要性圖
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=feature_importance_df, palette='copper')
plt.title('Feature Importance - Random Forest Classifier')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show() ?溫度的重要性最高,表明它對天氣類型的預測有很大影響。這與溫度在決定天氣條件方面起著關鍵作用的常識相一致。 能見度(km)和降水量(%)的重要性緊隨其后,表明這些因素對天氣分類有重大貢獻,特別是在確定降水的清晰度和存在方面。 紫外線指數和大氣壓力也顯示出顯著的重要性,表明它們在預測某些天氣模式中的作用。 與此模型中的其他要素相比,云量、濕度、季節、風速和位置的重要性值相對較低。這并不一定意味著它們總體上不那么重要,但表明它們對這個特定模型的預測影響較小。
?溫度的重要性最高,表明它對天氣類型的預測有很大影響。這與溫度在決定天氣條件方面起著關鍵作用的常識相一致。 能見度(km)和降水量(%)的重要性緊隨其后,表明這些因素對天氣分類有重大貢獻,特別是在確定降水的清晰度和存在方面。 紫外線指數和大氣壓力也顯示出顯著的重要性,表明它們在預測某些天氣模式中的作用。 與此模型中的其他要素相比,云量、濕度、季節、風速和位置的重要性值相對較低。這并不一定意味著它們總體上不那么重要,但表明它們對這個特定模型的預測影響較小。
四、結論
通過本研究,我們利用包含溫度、濕度、風速、降水量、云量、氣壓、紫外線指數、能見度等多個氣象指標的數據集,采用機器學習算法對天氣類型進行了預測。研究結果表明,所采用的機器學習模型能夠有效地識別和預測不同類型的天氣。具體結論如下:
- 模型的有效性:所使用的模型在訓練數據和測試數據上均表現出較高的預測準確性,證明了模型在天氣類型預測中的有效性。
- 特征重要性分析:通過對模型特征的重要性進行分析,發現溫度、濕度和降水量是影響天氣類型的主要因素,而云量和氣壓在某些天氣類型中也具有顯著的影響。
- 應用前景:本研究的方法和結果為實際應用提供了參考,可以應用于更大規模的數據集和更多種類的天氣類型預測中,為提升天氣預報的精準度提供了新的途徑。
總之,本研究通過數據驅動的方法對天氣類型進行了有效預測,為天氣預報和相關應用提供了重要參考和借鑒。未來,可以進一步結合更為復雜的氣象數據和更先進的機器學習算法,提升預測模型的性能和適用性。
?創作不易,希望大家多點贊關注評論!!!(類似代碼或報告定制可以私信)
)
)


![[AI 大模型] Meta LLaMA-2](http://pic.xiahunao.cn/[AI 大模型] Meta LLaMA-2)
詳解)




![[大師C語言(第四十一篇)]C語言指針數組與數組指針技術詳解](http://pic.xiahunao.cn/[大師C語言(第四十一篇)]C語言指針數組與數組指針技術詳解)








