文章目錄
- 一、前言
- 二、Delta Lake
- 三、Apache Hudi
- 四、Apache Iceberg
- 五、Apache Paimon
- 六、對比
- 七、筆者觀點
- 八、總結
- 八、參考資料
一、前言
在上一篇從數據倉庫到數據湖(上):數據湖導論文章中,我們簡單講述了數據湖的起源、使用原因及其本質。本篇文章將著重介紹市面上熱門的數據湖開源框架,并分享筆者對當前數據湖技術的理解和看法。
截至目前,在數據湖領域,Delta Lake、Apache Iceberg 和 Apache Hudi 無疑是三大熱門開源框架。此外,Apache Paimon 最初是 Flink 的子項目,后來獨立發展成為一個獨立的框架,可以說是后起之秀。
二、Delta Lake
由于 Apache Spark 在商業化上取得巨大成功,由其背后的商業公司 Databricks 推出的 Delta Lake 也顯得格外亮眼。Delta Lake 是一個流批一體的數據湖存儲層,支持更新、刪除和合并操作。
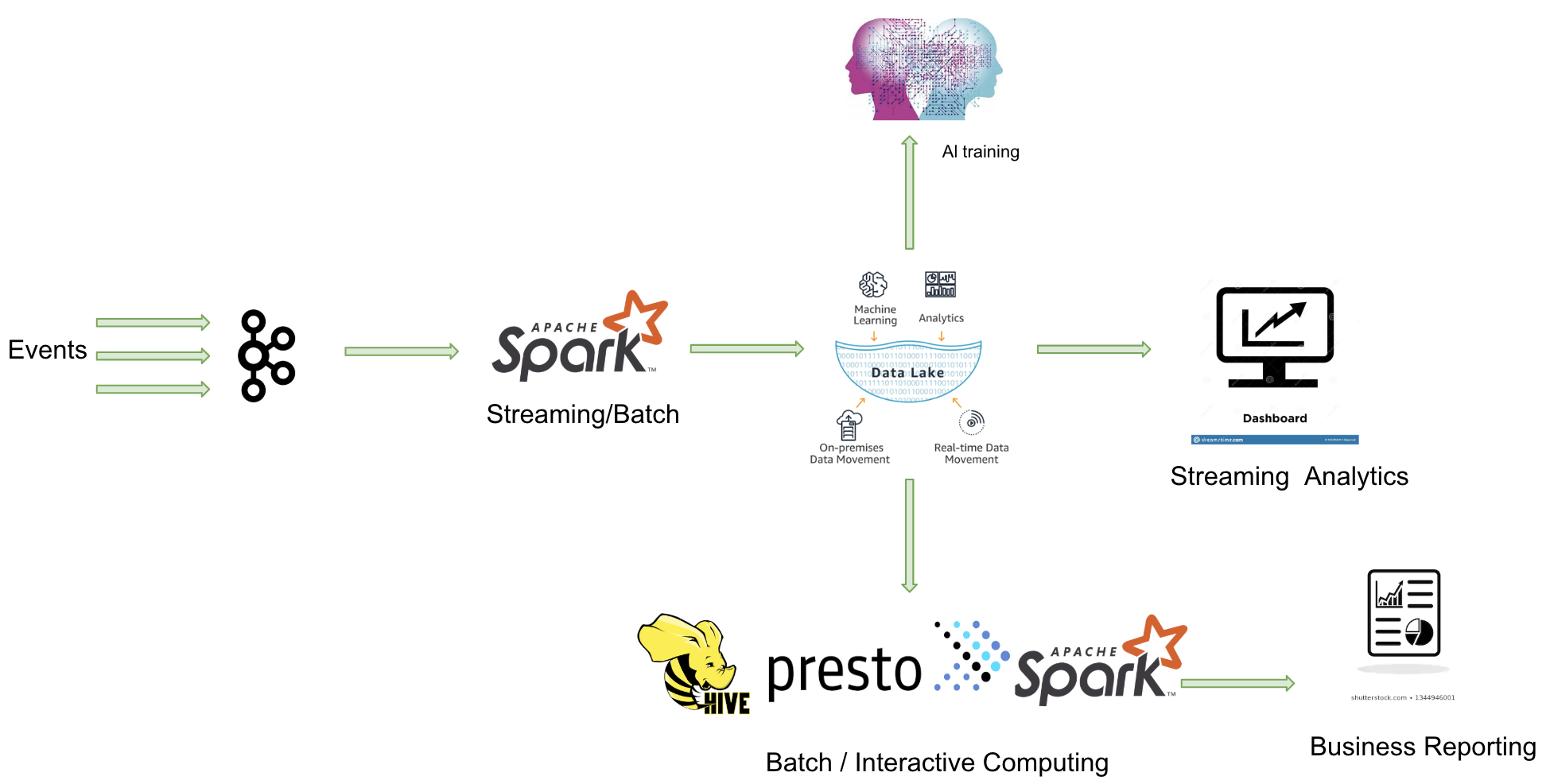
主要特點:
- 由于出自 Databricks,Delta Lake 與 Spark 的所有數據寫入方式完全兼容,包括基于 DataFrame 的批處理、流處理,以及 SQL 的 Insert、Insert Overwrite 等操作(開源版本暫不支持 SQL 寫入,EMR 已做支持)。
- 在數據寫入方面,Delta Lake 與 Spark 強綁定;在查詢方面,開源 Delta Lake 目前支持 Spark 和 Presto,但處理 delta log 需要使用 Spark。
核心能力:

三、Apache Hudi
Apache Hudi 是 Uber 公司開源的數據湖架構,用于管理存儲在 HDFS 上的數據。其設計目標如其名所示,即 Hadoop Upserts Deletes and Incrementals。Hudi 提供了“COW vs MOR”兩種數據模型,以適應不同的業務需求。此外,Hudi 還提供了豐富的插件生態,可以方便地與其他大數據組件集成。

核心能力:

四、Apache Iceberg
Apache Iceberg 是一種用于跟蹤超大規模表的新格式,專門為對象存儲(如 S3)而設計。盡管社區關注度暫時不如 Delta Lake,功能也不如 Hudi 豐富,但 Iceberg 是一個野心勃勃的項目,具有高度抽象和優雅的設計,為成為一個通用的數據湖方案奠定了良好基礎。
Iceberg 為大數據帶來了 SQL 表的可靠性和簡單性,同時讓 Spark、Trino、Flink、Presto 和 Hive 等引擎能夠同時安全地使用相同的表。
五、Apache Paimon
Apache Paimon 是一種湖泊格式,可以使用 Flink 和 Spark 構建實時湖屋架構,用于流和批處理操作。Paimon 創新地結合了湖泊格式和 LSM(日志結構合并樹)結構,將實時流更新引入湖泊架構。
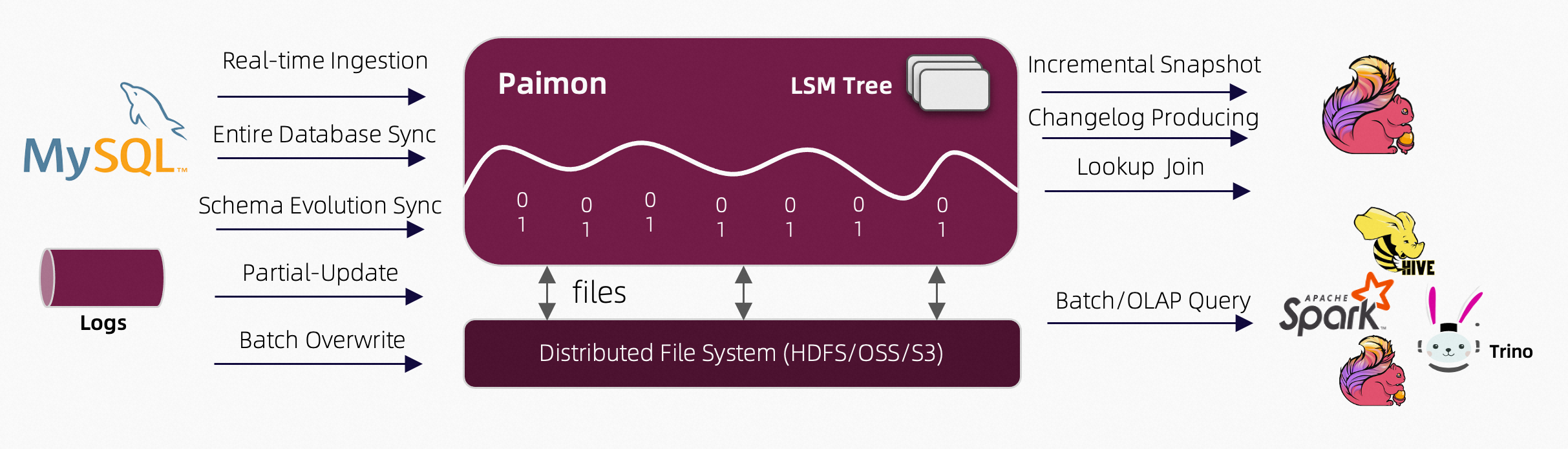
核心能力:
- 實時更新:
- 主鍵表支持大規模更新,具有高性能,通常通過 Flink 流實現。
- 支持定義合并引擎,靈活更新記錄。可重復保存最后一行,部分更新,或聚合記錄。
- 支持定義變更日志生成器,在合并引擎的更新中產生正確和完整的變更日志,簡化流分析。
- 大規模數據處理:
- 附加表(無主鍵)提供大規模批處理和流處理能力,并自動進行小文件合并。
- 支持通過 z 順序排序進行數據壓縮,以優化文件布局,并使用 minmax 等索引提供快速查詢。
- 數據湖功能:
- 可伸縮元數據:支持存儲 Petabyte 級別的大數據集和大量分區。
- 支持 ACID 事務、時間旅行和模式演化。
六、對比
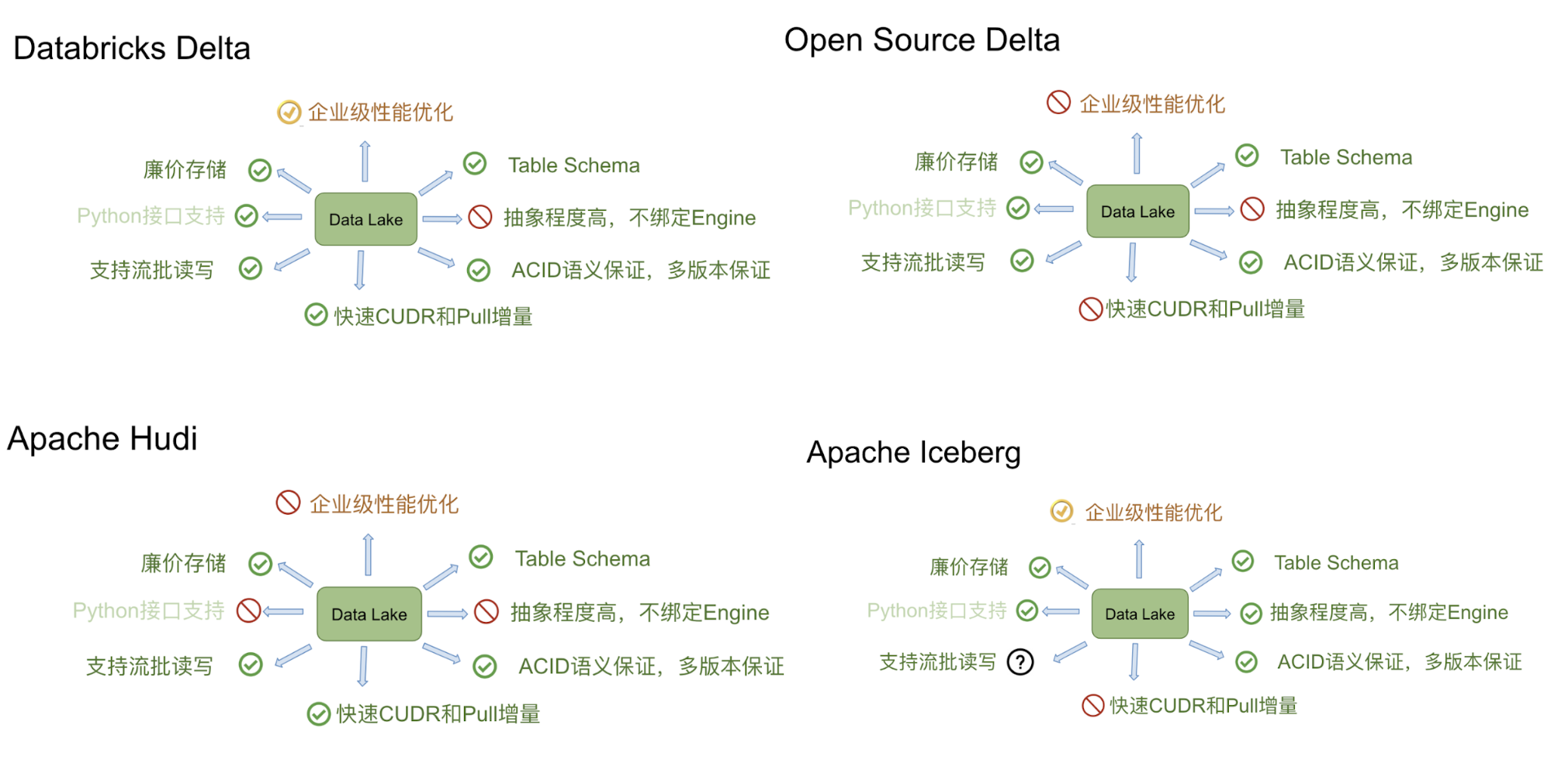
Delta、Iceberg、Hudi 和 Hive 四者的差異可以用建房子的比喻來說明。由于開源的 Delta 是 Databricks 閉源 Delta 的簡化版本,主要提供 table format 的技術標準,而閉源版本的 Delta 基于這個標準實現了諸多優化,因此我們主要用閉源的 Delta 來做對比。
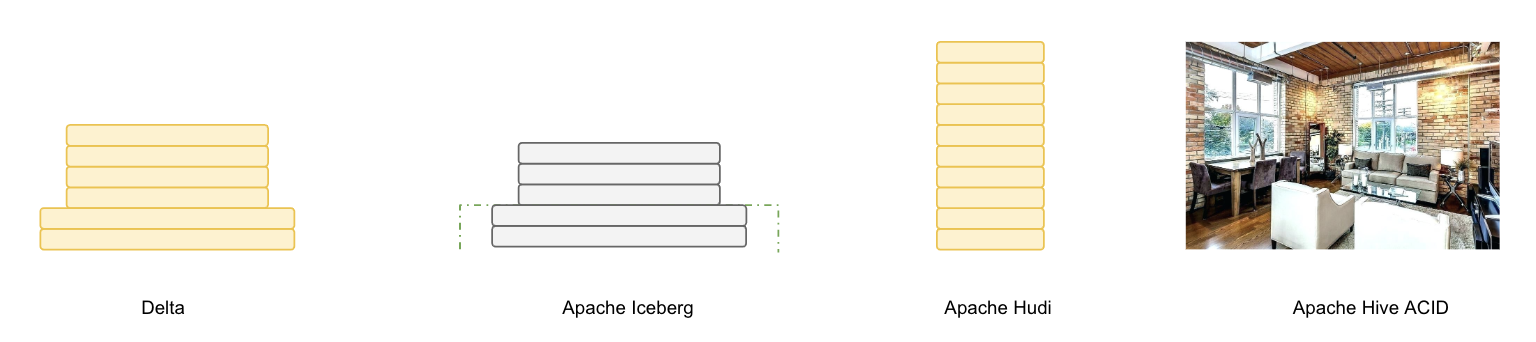
Delta 的房子基礎相對結實,功能樓層也建得比較高,但這個房子可以說是 Databricks 的,本質上是為了更好地壯大 Spark 生態。在 Delta 上,其他計算引擎難以替代 Spark 的位置,尤其是在寫入路徑方面。Iceberg 的建筑基礎非常扎實,擴展到新的計算引擎或文件系統都很方便,但目前功能樓層相對低一點,最缺的功能是 upsert 和 compaction。Iceberg 社區正在優先推動這兩個功能的實現。Hudi 的情況不同,它的建筑基礎設計不如 Iceberg 結實。例如,要接入 Flink 作為 Sink,需要從底向上重新設計房子,把接口抽象出來,并且考慮不影響其他功能。盡管如此,Hudi 的功能樓層還是比較完善的,提供的 upsert 和 compaction 功能直接命中用戶的痛點。Hive 看起來像是一棟豪宅,絕大部分功能都有,但作為數據湖有點像靠著豪宅的一堵墻建房子,顯得相對笨重。此外,正如 Netflix 的分析,細看這棟豪宅的墻面其實有一些問題。
七、筆者觀點
雖然上述四款熱門開源框架都宣稱自己是數據湖解決方案,但根據我的了解和使用體驗,這幾款產品均不能完全滿足數據湖所應具備的能力。
在前一篇文章中,筆者提到數據湖的本質是由數據存儲架構和數據處理工具組成的解決方案。然而,這四款開源框架均沿用了傳統數據庫建表的思想,對數據有較強的 schema 約束,這與數據湖原始定義中的集成各類非結構化數據的要求相悖。
通過對這幾款產品的使用和體驗,我認為目前熱門的數據湖技術均依賴于分布式文件系統的存儲能力。它們的功能介于分布式文件系統與普通數據庫之間,繼承了文件系統中數據文件和目錄對用戶直觀可見,以及數據庫對數據使用表結構的管理、元數據管理和事務管理的優點,可以被稱為一種數據管理中間件的開源產品。
這些產品的使用并不需要安裝部署任何軟件,也不需要啟動額外的服務和端口,只需增加一個 jar 包,以插件的形式嵌入到計算引擎中,從而實現對分布式文件系統中數據的讀寫和各種數據管理功能。它們為計算引擎提供了一種數據組織和管理方式,但并非真正意義上的數據湖。
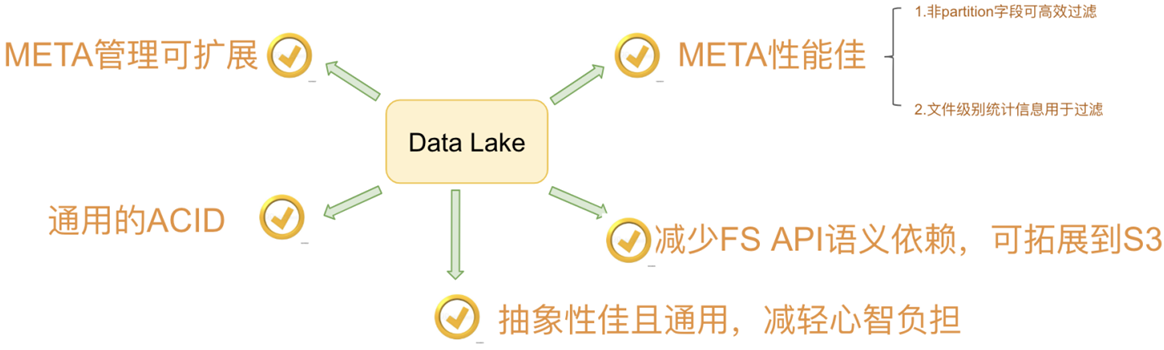
真正意義上的數據湖應該具備數據抽取 (ETL)、元數據管理、數據分析三大功能,如下圖所示:

八、總結
數據湖就像其他新興技術一樣,在剛出現時往往受到廣泛關注,成為熱門話題。然而,很多新興技術詞匯大多是作為一個泛化的理論概念,但往往具有很大的吸引力,其實際應用還存在諸多挑戰和局限性。
根據對當前幾款熱門開源框架(如Delta Lake、Apache Iceberg、Apache Hudi、Hive-ACID)的使用體驗,這些產品均無法完全滿足數據湖應具備的能力。數據湖的本質是由數據存儲架構和數據處理工具組成的解決方案,但上述框架在設計上仍然沿用了傳統數據庫的schema約束,與數據湖集成各類非結構化數據的初衷相悖。
總體來說,數據湖等新興技術在理論上提供了一個理想的解決方案,但在實際應用中,仍需不斷發展和完善,以滿足企業對數據存儲、管理和分析的需求。這一過程需要時間和技術的積累,才能真正實現理論與實踐的統一。
八、參考資料
- 從數據庫到數據倉庫:數據倉庫導論
- 從數據倉庫到數據湖(上):數據湖導論
- 深度對比 Delta、Iceberg 和 Hudi 三大開源數據湖方案
- Hidi
- Delta Lake
- Iceberg
- Paimon








)





和Docker Compose本質區別)
)

 and ByteRace 2024)

