????????在使用 lxml 庫解析網頁數據時,每次都需要編寫和測試 XPath 的路徑表達式,顯得非常
煩瑣。為了解決這個問題, Python 還提供了 Beautiful Soup 庫提取 HTML 文檔或 XML 文檔的
節點。 Beautiful Soup 使用起來很便捷,受到了開發人員的推崇。接下來,本節先帶領大家認
識 Beautiful Soup ,再為大家介紹如何使用 Beautiful Soup 解析網頁數據。
一、Beautiful Soup 簡介
????????Beautiful Soup 是一個用于從 HTML 文檔或 XML 文檔中提取目標數據的 Python 庫。它歷
經了眾多版本,其中 Beautiful Soup 3 已經停止開發與維護,官方推薦使用 Beautiful Soup 4 (簡
稱 bs4 )進行程序開發。截至本書完稿時, Beautiful Soup 的最新版本是 4.4.0 。
????????為了快速解析 HTML 文檔或 XML 文檔的數據, bs4 不僅提供了多種類型的解析器,還支
持 CSS 選擇器。 bs4 通過解析器可以將 HTML 或 XML 文檔、片段轉換成節點樹,節點樹中
的每個節點對應一個 Python 類的對象。 bs4 庫或 bs4.element 模塊中提供了 Tag 類、
NavigableString 類、 BeautifulSoup 類、 Comment 類等 4 個比較重要的類。關于這 4 個類的具
體介紹如下。
- ?bs4.element.Tag 類:表示 HTML 或 XML 中的元素,是最基本的信息組織單元。它有 兩個非常重要的屬性:表示元素名稱的 name 和表示元素屬性的 attrs。
- ?bs4.element.NavigableString 類:表示 HTML 或 XML 元素中的文本(非屬性字符串)。
- ?bs4.BeautifulSoup 類:表示 HTML 或 XML 節點樹中的全部內容,支持遍歷節點樹和 搜索節點樹的大部分方法。
- ?bs4.element.Comment類:表示元素內字符串的注釋部分,是一種特殊的NavigableString 類的對象。
????????bs4 的用法非常簡單,一般分為如下 3 個步驟。
( 1 )根據 HTML 或 XML 文檔、片段創建 BeautifulSoup 類的對象。
( 2 )通過 BeautifulSoup 類的對象的查找方法或 CSS 選擇器定位節點。
( 3 )通過訪問節點的屬性或節點的名稱提取文本。
二、創建 BeautifulSoup 類的對象
????????要想使用 bs4 解析網頁數據,需要先使用構造方法創建 BeautifulSoup 類的對象。
BeautifulSoup 類的構造方法的聲明如下。
BeautifulSoup(markup="", features=None, builder=None, parse_only=None, from_encoding=None, exclude_encodings=None, element_classes=None, **kwargs) ????????上述方法中常用參數的含義如下。
- ?markup:必選參數,表示待解析的內容,可以取值為字符串或類似文件的對象。
- features:可選參數,表示指定的解析器。該參數可以接收解析器名稱或標記類型。其 中,解析器名稱包括 lxml、lxml-xml、html.parser 和 html5lib,標記類型包括 html、html5 和 xml。
- parse_only:可選參數,指定只解析部分文檔。該參數需要接收一個 SoupStrainer 類的 對象。當文檔太大而無法全部放入內存時,便可以考慮只解析一部分文檔。
- from_encoding:可選參數,指定待解析文檔的編碼格式。 值得一提的是,如果我們只需要解析 HTML 文檔,那么在創建 BeautifulSoup 類的對象時 可以不用指定解析器。此時 Beautiful Soup 會根據當前系統安裝的庫自動選擇解析器。解析器 的選擇順序為 lxml→html5lib→Python 標準庫,但在以下兩種情況下會發生變化。
- 要解析的文檔是什么類型?目前支持 html、xml 和 html5。
- 指定使用哪種解析器?目前支持 lxml、html5lib 和 html.parser。
????????如果指定的解析器沒有安裝,那么 Beautiful Soup 會自動選擇其他方案。不過,目前只有
解析器 lxml 支持 XML 文檔的解析。在當前系統中沒有安裝解析器 lxml 的情況下,即使創建
BeautifulSoup 對象時明確指定使用解析器 lxml ,也無法得到解析后的內容。
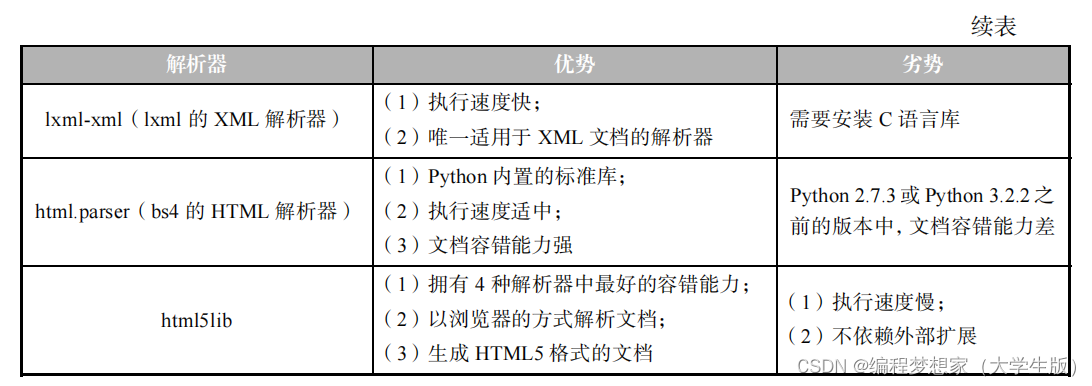
下面通過一張表來區分上述 4 種解析器的優勢與劣勢,具體如表 4-7 所示。

 ?????????接下來,通過一個例子來演示如何創建 BeautifulSoup 類的對象,具體代碼如下。
?????????接下來,通過一個例子來演示如何創建 BeautifulSoup 類的對象,具體代碼如下。
1 from bs4 import BeautifulSoup
2 html_doc = """<html><head><title>The Dormouse's story</title></head>
3 <body>
4 <p class="title"><b>The Dormouse's story</b></p>
5 <p class="story">Once upon a time there were three little sisters;
6 and their names were
7 <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
8 <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
9 <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
10 and they lived at the bottom of a well.</p>
11 <p class="story">...</p>
12 """
13 # 根據 html_doc 創建 BeautifulSoup 類的對象,并指定使用 lxml 解析器解析文檔
14 soup = BeautifulSoup(html_doc, features='lxml')
15 print(soup.prettify()) ????????在上述示例代碼中,第 1 行代碼導入了 BeautifulSoup 類,第 2 ~ 12 行定義了變量 html_doc
保存 HTML 代碼片段,第 14 行代碼根據 html_doc 創建了一個 BeautifulSoup 類的對象,并指
定使用解析器 lxml 來解析 HTML 文檔,第 15 行代碼輸出了 soup.prettify() 執行的結果,其中
prettify() 方法會對 HTML 代碼片段進行格式化處理,友好地顯示 HTML 代碼。
運行代碼,輸出如下結果。
<html> <head> <title> The Dormouse's story </title> </head> <body> <p class="title"> <b> The Dormouse's story </b> </p> ……</body>
</html>?
?
?










)






--LCD1602)

)