根據往年考試題,對考點和知識點的一個整理。
校驗編碼
碼距
??一種編碼的最小碼距,其實就是指這種編碼的碼距。碼距有兩種定義:
| 碼距所描述的對象 | 含義 |
|---|---|
| 2 2 2 個特定的碼 | 其二進制表示中不同位的個數 |
| 一種編碼 | 這種編碼中任意 2 2 2 個合法編碼的最小碼距 |
??課本上出現的碼及其碼距歸納如下。
- 奇偶校驗碼的碼距是 2 2 2。
- 能糾 1 1 1 位錯的海明碼的碼距始終是 3 3 3,不管 n , k , r n,k,r n,k,r 如何變化。首先,海明碼的每一個數據位至少位于 2 2 2 個校驗組,這就保證了海明碼的碼距至少是 3 3 3;其次, H 3 H_3 H3? 一定位于且僅位于 G 1 , G 2 G_1,G_2 G1?,G2? 校驗組, H 3 H_3 H3? 的變化引起且只引起 P 1 , P 2 P_1,P_2 P1?,P2? 的變化,從而構造了一對碼距為 3 3 3 的合法編碼,保證海明碼的碼距最多是 3 3 3。
- CRC 編碼的碼距不固定,但是至少是 3 3 3。不同的 ( n , k ) (n,k) (n,k) 和生成多項式對應了不同的碼距。比如下面這張表(來源于這篇博客):
| 總位數 n n n | 數據位數 k k k | 生成多項式 G ( x ) G(x) G(x) | G ( x ) G(x) G(x) 的二進制表示 | 碼距 |
|---|---|---|---|---|
| 7 7 7 | 4 4 4 | x 3 + x + 1 x^3+x+1 x3+x+1 | 1011 1011 1011 | 3 3 3 |
| 7 7 7 | 4 4 4 | x 3 + x 2 + 1 x^3+x^2+1 x3+x2+1 | 1101 1101 1101 | 3 3 3 |
| 7 7 7 | 3 3 3 | x 4 + x 3 + x 2 + 1 x^4+x^3+x^2+1 x4+x3+x2+1 | 11101 11101 11101 | 4 4 4 |
| 7 7 7 | 3 3 3 | x 4 + x 2 + x + 1 x^4+x^2+x+1 x4+x2+x+1 | 10111 10111 10111 | 4 4 4 |
| 15 15 15 | 11 11 11 | x 4 + x + 1 x^4+x+1 x4+x+1 | 10011 10011 10011 | 3 3 3 |
| 15 15 15 | 7 7 7 | x 8 + x 7 + x 6 + x 4 + 1 x^8+x^7+x^6+x^4+1 x8+x7+x6+x4+1 | 111010001 111010001 111010001 | 5 5 5 |
| 31 31 31 | 26 26 26 | x 5 + x 2 + 1 x^{5}+x^{2}+1 x5+x2+1 | 100101 100101 100101 | 3 3 3 |
| 31 31 31 | 21 21 21 | x 10 + x 9 + x 8 + x 6 + x 5 + x 3 + 1 x^{10}+x^{9}+x^{8}+x^{6}+x^{5}+x^{3}+1 x10+x9+x8+x6+x5+x3+1 | 11101101001 11101101001 11101101001 | 5 5 5 |
| 63 63 63 | 57 57 57 | x 6 + x + 1 x^{6}+x+1 x6+x+1 | 1000011 1000011 1000011 | 3 3 3 |
| 63 63 63 | 51 51 51 | x 12 + x 10 + x 5 + x 4 + x 2 + 1 x^{12}+x^{10}+x^{5}+x^{4}+x^{2}+1 x12+x10+x5+x4+x2+1 | 1010000110101 1010000110101 1010000110101 | 5 5 5 |
漢字編碼實驗
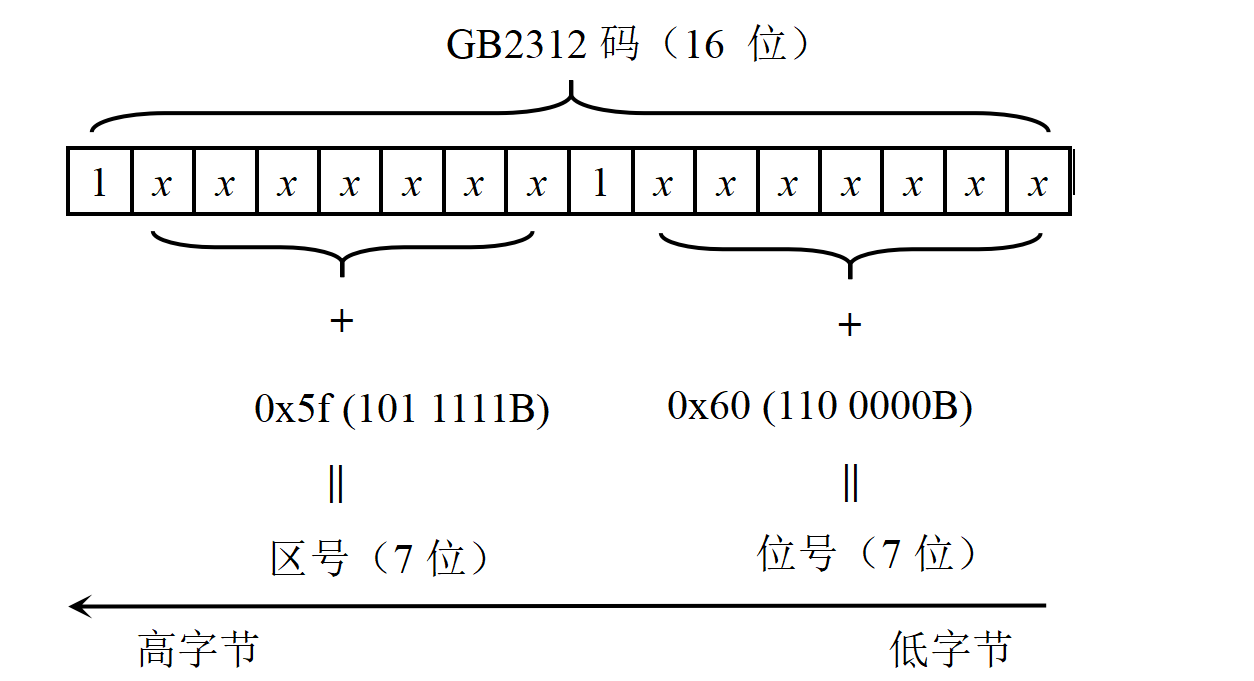
??GB2312 碼:占 2 2 2 個字節,每個字節的最高位都是 1 1 1(為了與 ASCII 碼區分)。
??區號:GB2312 碼高字節的低 7 7 7 位。
??位號:GB2312 碼低字節的低 7 7 7 位。
??國標碼轉區位碼的流程如下:
海明碼流水傳輸實驗
有關海明碼的其它實驗以及海明碼的概念,可以參看這篇博客。這篇博客沒有涉及到海明碼的流水傳輸,在這里回顧一下。CRC 編碼的流水傳輸和海明碼流水傳輸在構成上是相似的。
??流水傳輸的過程如下所示。圖中的~使能/Stall 信號通過各級鎖存器依次向右傳遞,獲取了使能的鎖存器將在下一個時鐘上升沿完成鎖存。當發生兩位錯的時候,前三個鎖存器的值清零,同時地址回滾(減 3 3 3),顯示階段的鎖存器stall接收到的數據 3 3 3 個時鐘周期。

??這是電路復位后的狀態:
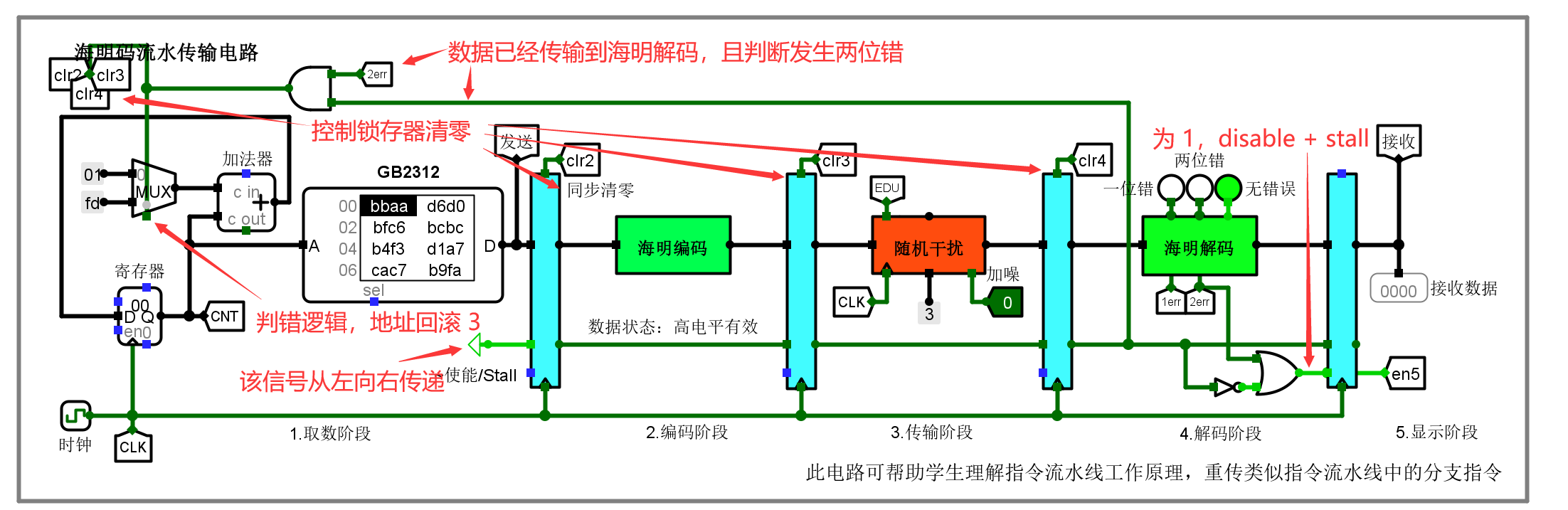
??據此,總結兩位錯時各階段的動作得下表:
| 階段 | 動作 | 備注 |
|---|---|---|
| 取數階段 | 地址回滾 | 地址要回滾 3 3 3 個漢字(ROM 回滾 6 6 6 個字節),出錯了的數據重新傳輸。 |
| 編碼階段 | 數據清零 | 這個清零其實核心是把數據狀態的值置為 0 0 0,其中鎖存的數據可以不用管。 |
| 傳輸階段 | 數據清零 | 和編碼階段清零是一個道理。 |
| 顯示階段 | 數據鎖存 | 出錯的字重傳需要 3 3 3 個時鐘周期才能到達顯示階段的鎖存器,在這段時間內需要維持上一個字的顯示。 |
CRC 編碼解碼
??課本上介紹了 CRC編碼、解碼的時序邏輯實現,原始數據 D k ? D 1 D_k\cdots D_1 Dk??D1? 按位串行輸入進來,然后經過時序系統的處理,每個時鐘周期產出一位余數。但是我們做實驗時用組合邏輯實現,根據 16 16 16 位原始數據 D 1 D_1 D1?~ D 16 D_{16} D16? 直接得到 6 6 6 校驗碼 R 1 R_1 R1?~ R 6 R_6 R6?。
實驗中有兩種思路,一種是采用 6 6 6 位的生成多項式,得到 5 5 5 位余數且 R 6 R_6 R6? 作為總偶校驗位;另一種是采用 7 7 7 位的生成多項式,得到 6 6 6 位的余數,就不設總偶校驗位了。我當時沒有想到后一種,因為它放了個 P P P 作為總偶校驗位,還以為 R 6 R_6 R6? 就是 P P P(心虛)。
??頭歌上蘿卜打表沒打全,能用的 6 6 6 位生成多項式只有下面這個:

??上面的表是課本上的。使用這個生成多項式,直接出現了余數相等的盛況:
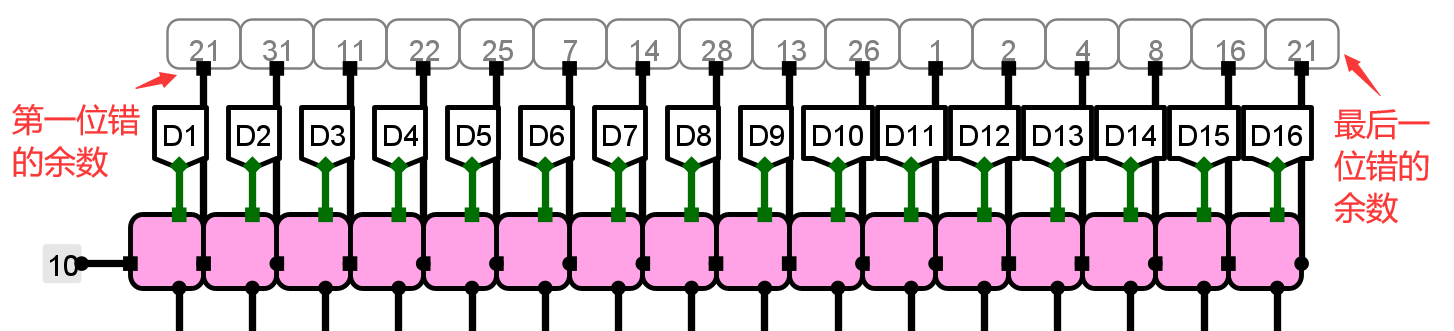
??那么這個生成多項式顯然在這里 ( k = 16 ) (k=16) (k=16) 是不能用的,只有原始數據是 15 15 15 位及以下才能用。其實表格上面的 x 5 + x 3 + 1 ( 0 x 29 ) x^5+x^3+1(0\rm x29) x5+x3+1(0x29) 和 x 5 + x 2 + 1 ( 0 x 25 ) x^5+x^2+1(0\rm x 25) x5+x2+1(0x25) 都可以使用,但是當時做實驗的時候沒有關注到課本,自己捏了一個 x 5 + x 3 + x 2 + x + 1 ( 0 x 2 f ) x^5+x^3+x^2+x+1(0\rm x2f) x5+x3+x2+x+1(0x2f) 來用。
??上面出現的這三個 ( 0 x 29 , 0 x 25 , 0 x 2 f ) (\rm{0x29,0x25,0x2f}) (0x29,0x25,0x2f) 都是可以糾正一位錯的。考題里現在出現了這樣一個問題:
在假定沒有 3 3 3 位以上錯誤發生的前提下,你的生成多項式生成的 CRC 編碼檢錯時能否區分 1 1 1 位錯和 2 2 2 位錯?

??對于我的版本(多項式 6 6 6 位),答案說是不能區分,余數相同。果真余數相同嗎?我們利用下面的代碼,嘗試一下上面三個生成多項式。
#include<iostream> int poly,rest[17] = {0x10};
bool bkt[100]; inline int bitcount(int num){int ret = 0;while(num){ret++;num >>= 1;}return ret;
}inline int getRest(int num){return bitcount(num) == bitcount(poly)?(num ^ poly):num;}int main(){int restnum;scanf("%x",&poly);for(int i = 1;i <= 16;i++){rest[i] = getRest(rest[i-1] << 1);bkt[rest[i]] = true;}for(int i = 1;i <= 16;i++)for(int j = i + 1;j <= 16;j++){restnum = getRest(rest[i] ^ rest[j]);if(bkt[restnum]){printf("%d repeated.",restnum);return 0;} }printf("No repeats.");return 0;
}??結果是:
in: 0x2f out: 17 repeated.
in: 0x29 out: 27 repeated.
in: 0x25 out: 17 repeated.
??那么這三個生成多項式,確實二位錯和一位錯的余數會重復,答案說得對。至于 7 7 7 位生成多項式的情況,一位錯和二位錯的余數是不是真的不相同,那我也不知道。可以將上面代碼的0x10改成0x20,然后輸入 7 7 7 位生成多項式試試。
試過了一個 7 7 7 位生成多項式 0 x 6 f \rm 0x6f 0x6f,確實沒有重復。
Cache 與虛擬存儲系統
?? k ? k- k?路組相連,指的是每一個 cache 組有 k k k 個 cache 行(或者說 k k k 個數據塊)。這里主要說一下 TLB 這個特殊的 cache 是怎么組織的。
??TLB 作為一個 cache,自然也有全相聯、直接相聯和組相聯三種方式。以 k ? k- k?路組相聯為例對比一下 TLB 和內存 cache。
| Cache 類型 | 映射方式 | t a g \mathit{tag} tag 字段來源 | i n d e x \mathit{index} index 字段位數 | 有無塊內偏移 ( o f f s e t ) (\mathit{offset}) (offset)字段 |
|---|---|---|---|---|
| TLB | 標記 t a g \mathit{tag} tag → P P N \mathit{PPN} PPN | V P N \mathit{VPN} VPN | log ? 2 k \log_2k log2?k | 無 |
| 內存 cache | 標記 t a g \mathit{tag} tag → 內存數據塊 | 內存地址 | log ? 2 k \log_2k log2?k | 有 |
??它們最大的區別就是,TLB 中是沒有 o f f s e t \mathit{offset} offset 字段的。內存 cache 是通過 t a g \mathit{tag} tag 字段找到對應的數據塊,然后根據 o f f s e t \mathit{offset} offset 字段尋找對應的字節(或者字,看計算機按什么編址了);TLB 直接通過 t a g \mathit{tag} tag 字段找到對應的 P P N \mathit{PPN} PPN,不需要 o f f s e t \mathit{offset} offset 字段。這也就意味著 TLB 行的開銷比內存 cache 行小很多。

指令系統
??課本是以 MIPS 指令集講解的這一章,而 MIPS 指令集中,R 型指令的操作碼字段 o p \mathit{op} op 一定是為 0 0 0 的,R 型指令中不同功能的指令根據 f u n c t \mathit{funct} funct 字段來區分。

??其中beq屬于上面的 I 型指令,立即數字段時跳轉的偏移量。這里的偏移量指的是從下一條指令開始,偏移多少條指令,而不是多少字節或者多少字。對于 MIPS32 而言,其指令字長是恒定的 32 32 32 位,即 4 B 4\rm B 4B,那么beq中立即數為 i i i 意味著要偏移 4 i 4i 4i 個字節。
CPU 設計
數據通路時間相關問題
??如下圖,總結了就是兩個條件,對于時鐘周期,要求有 T c l o c k > T c l k _ t o _ Q + T m a x + T s e t u p T_{\mathit{clock}}>T_{\mathit{clk\_to\_Q}}+T_\mathit{max}+T_\mathit{setup} Tclock?>Tclk_to_Q?+Tmax?+Tsetup?。對于寄存器的 hold time 也有要求: T h o l d < T c l k _ t o _ Q + T m i n T_\mathit{hold}<T_{\mathit{clk\_to\_Q}}+T_\mathit{min} Thold?<Tclk_to_Q?+Tmin?。


狀態機
這里說的都是無中斷的狀態機。
??傳統的三級時序和現代時序是不一樣的。三級時序中,每個機器周期都包含 4 4 4 個時鐘周期,而現代時序的計算、執行分別為 2 , 3 2,3 2,3 個時鐘周期。它們的電路也是不一樣:

??三級時序中,時序發生器有一個狀態機。硬布線控制器作為一個組合邏輯單元,其輸出不給到時序發生器,所以應該將它和時序發生器割裂開來。這個時序發生器的狀態機如下圖左:


??現代時序中,其實也可以弄一個時序發生器,相比于三級時序的時序發生器,少了 2 2 2 個計算周期和 1 1 1 個執行周期。如上圖右所示。但是如果要用 FSM 狀態機的話,響應的狀態轉換圖如下:

??這個是將 FSM 狀態機和狀態寄存器看作一個整的時序邏輯電路,構造出來的狀態圖;不是 FSM 單獨的狀態圖,組合邏輯電路沒有所謂狀態圖。同時注意一下所有狀態中訪問內存的那些狀態,以及給出的READ/WRITE信號。
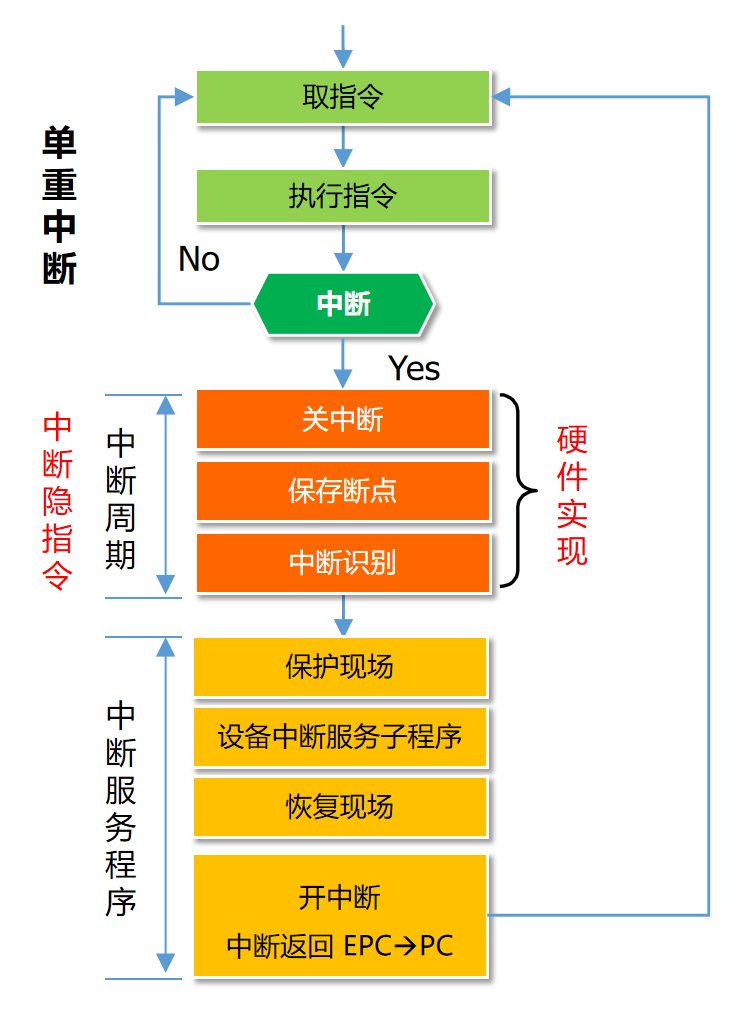
中斷的實現方式
??主要是開中斷和關中斷實現方式的區別:
| 中斷操作 | 實現方式 | 具體 |
|---|---|---|
| 關中斷 | 硬件實現 | 中斷響應周期,由硬件完成 |
| 開中斷 | 軟件實現 | 中斷返回時,eret指令將 I E \mathit{IE} IE 置為 1 1 1 |
??具體可以參考下面這兩張圖。其中中斷響應是由硬件完成的操作,中斷響應不是中斷服務。中斷響應周期結束后, P C \mathit{PC} PC 已然是中斷服務程序的地址了,中斷服務程序通過取指-計算-執行按指令一條條完成。

輸入輸出系統
??DMA 與程序中斷的區別:
1 1 1.中斷通過程序傳送數據,DMA靠硬件來實現。
2 2 2.中斷時機為兩指令之間,DMA響應時機為兩存儲周期之間。
3 3 3.中斷不僅具有數據傳送能力,還能處理異常事件。DMA只能進行數據傳送。
4 4 4.DMA僅挪用了一個存儲周期,不改變CPU現場。
5 5 5.DMA請求的優先權比中斷請求高。CPU優先響應DMA請求,是為了避免DMA所連接的高速外設丟失數據。
6 6 6.DMA利用了中斷技術
】進程程序替換--如何自己實現一個bash解釋器?)







)

)

)

【獨一無二】)

 圖像閾值)


